
基于训练大数据的水资源动态配置模型研究
2021-09-05 22:59刘鑫韩宇平
人民黄河 2021年8期
刘鑫 韩宇平

摘 要:在傳统的水资源配置过程中,水库水量平衡计算时水库弃水量巨大,造成大量可利用的水资源被浪费。系统梳理水资源配置模型,分析得到水库弃水量大的主要原因是水资源配置模型存在“水源分割”现象。为了解决这个问题,对传统的模型进行改进,增强模型全局统筹能力,提出水资源动态配置模型,建立区域水资源的全局理念,切实有效地做到区域水资源的统筹管理、统筹调度、统筹配置,实现水资源配置动态平衡的目标。使用机器学习的思想,通过训练大数据使模型自主学习,通过交叉验证最终求解出模型的最佳参数组合。改进湖北漳河水库灌区的水资源合理配置模型,使24座大中型水库年均弃水量减少1 080.54万m3,研究区年均缺水量减少126.58万m3。水资源动态配置模型统筹考虑全部供水源的供水能力,减少了水库的弃水量和区域的缺水量,提高了水资源的利用效率,对水资源高效合理利用具有重要意义。
关键词:水资源配置;水资源动态配置模型;动态平衡;机器学习;训练大数据;交叉验证
中图分类号:TV214 文献标志码:A
doi:10.3969/j.issn.1000-1379.2021.08.010
引用格式:刘鑫,韩宇平.基于训练大数据的水资源动态配置模型研究[J].人民黄河,2021,43(8):52-57.
Abstract: In the traditional allocation process of water resources, the amount of abandoned water in the reservoir is huge when calculating the water balance of the reservoir and it causes a large amount of available water resources to be wasted. Through systematic research of water resources allocation model, we found that the main reason for the large amount of abandoned water in the reservoir was the phenomenon of “water source division” in the water resources allocation model. In order to solve this problem, the traditional model was improved to increase the overall planning ability of the model, we proposed a Dynamic Allocation Model of Water Resources that established a global concept of regional water resources and effectively achieved the overall management, overall scheduling and overall allocation of regional water resources. It realized dynamic allocation and achieved a dynamic balance. We used the idea of machine learning. The model could learn autonomously through training big data, we could finally solve the best parameter combination of the model through cross validation. We improved the rational allocation model of water resources in Zhanghe Reservoir irrigation area in Hubei Province, the model reduced the annually average abandoned water volume of 24 large and medium reservoirs by 10.805 4 million cubic meters and reduced the annually average water shortage in the research area by 1.265 8 million cubic meters. The dynamic allocation model of water resources considered the supply water capacity of all water sources as a whole, reduced the amount of abandoned water in the reservoir and the water shortage in the region, and improved the use efficiency of water resources. It was of great significance to the efficient and reasonable use of water resources.
Key words: allocation of water resources; dynamic allocation model of water resources; dynamic balance; machine learning; training big data; cross validation
随着工业的飞速发展、人口的快速增长,水资源开发利用率高得惊人,水资源过度消耗,生态环境质量严重下降,使得我国水资源面临空前严峻的形势。因此,应创新水资源配置方式,转变水资源配置的传统观念,在水资源量不变的条件下减少水资源浪费、提高水资源利用率,保证水资源合理高效可持续利用。
近年来,很多学者在水资源配置方面进行了大量且深入的研究,Abdulbaki等[1]提出将整数线性规划决策支持模型用于水资源配置。齐学斌等[2]对灌区水资源管理政策、水资源循环转化规律、水资源优化配置模型与方法和水文生态4个方面的研究现状进行了对比分析。Bekri等[3]基于不确定2阶随机规划方法进行了不确定条件下的水资源最优分配。董晓知等[4]基于供需平衡分析构建大系统数学模型,使水资源优化配置更加科学合理。单义明等[5]构建区间两阶段随机鲁棒规划模型,完成吕梁市的水资源优化配置。吴云等[6]基于改进NSGA-Ⅱ算法,搭建水资源多目标优化配置模型。赵燕等[7]基于改进的萤火虫算法求解水资源的优化配置模型。Maiolo等[8]分析Crotone区域水资源分配后,考虑水资源可用性和未来气候变化,提出了水资源优化配制方案。
在水库水量平衡计算时仍存在水库弃水量大的问题,水资源配置存在“水源分割”现象,没有真正实现全部供水源统筹配置是水库弃水量大的主要原因。因此,需要改进水资源配置模型,在供水时统筹考虑全部水源的供水能力,实现水资源的统筹配置。当供水顺序靠后的大型水库水位较高时,应适当减少前置水源的供水量并适当让其多蓄水,让后置水库多供水,这样在水量平衡计算时,就可以减少一定量的弃水。当该水库水位降低到一定值时,可以使前置水源以最大能力供水,供水量不足时再由该水库补齐以实现水资源的动态配置,强调从整个供水体系上进行水资源配置,打破水资源配置中的“水源分割”现象,这样就可以提高整个供水系统的整体性和协调性。笔者以漳河水库灌区为研究对象,建立水资源动态配置模型,采用训练大数据与交叉验证求解模型,计算得到最优模型进行测试,并与过去的数据进行对比来验证模型的有效性。
1 研究區概况与问题描述
1.1 研究区概况
漳河水库灌区面积为5 543.93 km2,灌区地跨荆州市的荆州区、宜昌市的当阳市和荆门市的掇刀区、东宝区、沙洋县、钟祥市。
所用数据来源于各市(县)统计年鉴以及各地的农业统计年报,水库用水量采用水库水量平衡计算得到的数据,降雨蒸发资料来源于研究区资料质量较好的8个水文站和气象站及18个雨量站。对于个别站缺测的月份,用该站前后几年的平均值或气候、地形较一致的相邻站的平均值插补。
1.2 问题描述
由于存在“水源分割”现象,因此每个供水源都是单独配置,前置水源每次供水都是最大能力供水,如果未来一段时间来水比较充足,前置水源可利用的水量较多,供水满足情况较好,就会导致供水顺序靠后的水库尤其是大型水库供水量少,水库水位可能趋近弃水线。一旦有降水,水库很可能要弃水。当水库弃掉大量的水之后,如果未来一段时间来水量较少,前置水源因无法充分蓄水导致可利用水量较少,巨大的缺水量必须由水库来满足,水库的供水量势必出现激增的现象,而水库又会因蓄水不足导致水位下降速度较快。如果下降到死水位,则无法弥补巨大的缺水量,而全部供水源蓄水不足还可能导致本月甚至接下来的1~2个月出现严重缺水的现象。而对于整个供水体系来说,水库在水资源配置中具有不可替代的作用,水库的供水情况在一定程度上影响水资源配置的有效性。
灌区内水库的供水总量占整个灌区供水总量的61.76%,其中漳河水库是最大的水库,漳河水库的供水量占水库供水总量的50.16%。在水库的水量平衡计算中水库弃水量巨大,漳河水库月弃水量的最大值高达43 025.44万m3,24座大中型水库年最大弃水量为65 242.34万m3,而年均生态需水量约2 600万m3,水库弃水量远远超过了生态需水量。因此要科学地审视可持续发展与水资源配置的关系[9],遵循以水资源的可持续利用促进社会经济的可持续发展理念[10]。
灌区传统的水资源配置模型按照塘堰(只供给农业)、小型水库、中型水库、引水工程、提水工程和漳河水库的供水顺序为各用水单元的各需水类别进行供水,包括城镇生活用水、农村生活用水、二三产业用水、农业与生态用水的合理配置,水量在不同区域及不同用水单元的优化配置。表1为研究区大中型水库库容特征参数与弃水量情况。
由表1可见,有9座水库没有弃水现象,其他15座水库都有弃水现象。对于这15座水库,月最大弃水量之和高达54 512.66万m3,最大的是漳河水库,弃水量为43 025.44万m3,占比78.93%;年均弃水量之和为16 484.07万m3,最大的是漳河水库,弃水量为10 430.63万m3,占比63.28%。漳河水库弃水量所占的比重非常大,且漳河水库是最重要的供水源,如何在满足供水的前提下减少漳河水库的弃水量是该研究区水资源配置的关键问题。图1是漳河水库过去43 a供水过程中重要指标的变化情况。
由图1可以发现,漳河水库时段蓄水量呈现一定规律性,弃水的月份相对比较集中,这是因为丰水期雨水比较充足,前置水源供水满足情况较好,漳河水库供水量较小,时段蓄水量持续较大,从而导致弃水较多;而枯水期供水量激增,时段蓄水量减小趋近死蓄水量,弃水量为零,与问题描述中的现象完全吻合。表2是漳河水库过去43 a供水过程中的弃水总量、年最大弃水量及年均弃水量与研究区对应时间的缺水情况对比。
由表2可知,漳河水库弃水总量约为缺水总量的4倍,年最大弃水量约为研究区年最大缺水量的2倍,年均弃水量约为研究区年均缺水量的4倍,如果能减少一部分弃水并合理高效地供水,研究区的缺水情况将会得到缓解。因此,本文以减少漳河水库弃水量、提高水资源的利用效率为目标,以满足生活、生产及农业需水为前提,以保障生态环境需水为出发点,以统筹兼顾全部水源及其供水能力为重心,以期实现水资源的高效可持续利用。
2 模型的思路与改进
2.1 模型思路
陈太政等[11]检索并分析中国知网中关于水资源优化配置的文献,指出水资源配置的创新需要水资源优化配置理论的进一步突破和供水体系结构与关系的深度挖掘。随着大数据、机器学习等先进技术在水利行业的不断应用,极大地推动了水利信息化建设,运用先进的计算机技术,通过大数据来进行计算、分析和应用,使水资源配置流程得到优化。图2是模型建立的思路。
机器学习可以高效地从数据中学习到过去未知的有价值的知识,本文将这种手段用到水资源配置中为水资源配置提供服务。机器学习的思想主要分为训练和验证。将数据进行划分,分为训练数据集、验证数据集,分别用于训练模型和交叉验证。首先用同样的训练数据集分别训练每一种模型,然后将训练好的模型用验证数据集进行验证。验证数据集用于检测构建的模型,此数据集只在模型验证时使用,用于评估模型的满意度,统计它们的误差,找出数据中潜在的规律。而模型训练一直到结果不能更优时停止。
2.2 模型改进
水资源配置模型改进后流程如圖3所示。
农业用水是保障粮食安全的重中之重,因此在模型构建时,塘堰供水只供给农业不设模型参数,每次供水都以最大能力供水。小型水库、中型水库和引提工程在供给农业时,基于同样的考虑也不设置模型参数,以最大能力供水。
在模型改进过程中,最关键的问题就是水库的来水量是未知的,弃水量也只能在每次水量平衡计算后才能得到,且来水和弃水的多少只能根据过去的数据挖掘出一定规律,未来的数据都是不确定的。如果能将不确定的数据转化为确定的数据,则可以将不确定的问题转化为确定的问题,从而可以进行定量研究。模型在实际的应用中能够确切掌握的是水库的水位,而实际上来水量和弃水量与水库当前水位是紧密相关的。例如当漳河水库的当前蓄水量值较大时,可以适当减小前置水源的供水量,增加漳河水库的供水量,这样来水量较多时,漳河水库还可以充分蓄水减少弃水;当来水量较少时,漳河水库的蓄水量会一直下降,模型控制到一定蓄水量阈值,就适当增大前置水源的供水量,阈值越小前置水源供水量增加越多,一直增加到最大供水量以调节漳河水库的当前水位。如果来水量变多使漳河水库的水位上升时,再根据蓄水量阈值增大漳河水库的供水量,减少前置水源的供水量从而实现动态配置。这就不需要考虑不确定的来水与弃水,只要控制好漳河水库的当前蓄水量就相当于控制好了来水和弃水,把不确定的问题转化为确定的问题,只需要求解模型即可。而如何设置蓄水量阈值、如何根据阈值增大或减小各水源的供水量、增大或减小的比重是多少都可以从模型的训练中得到。
3 模型的设计与构建
3.1 模型的设计
3.1.1 目标函数
本文以减少水库弃水量,提高水资源利用效率,供水量最大化为总目标,以减少区域缺水总量为核心,用编程语言Python实现模型并计算。除塘堰和漳河水库外,给每一个供水源分配一个随机的模型参数,供水源的参数都是随漳河水库时段蓄水量动态变化的,在供水时将全部水源进行统一调配,以大数据为依据,求解水资源动态配置的模型参数。漳河水库的供水顺序排在最后,漳河水库的供水量必然要随着前置水源供水量的增大而减小,随着前置水源供水量的减小而增大,因此不设置模型参数依然可以运行模型,还可以简化计算。
模型目标函数如下:
3.1.2 约束条件
(1)用水总量约束条件:各单元各月用水总量不能超过该单元该月塘堰、小型水库、中型水库、引水工程、提水工程和漳河水库的可利用量,引水工程的可利用量不能超过退水量。
(2)生态需水约束条件:水库弃水量要满足生态环境需水量。
(3)其他约束条件:主要包括水库水量平衡约束、各类工程渠系水利用系数约束、水库给各计算单元的分水比例约束及变量非负约束等。
3.2 模型构建
3.2.1 模型训练
本文在训练模型时,利用43 a逐年逐月的统计数据,根据机器学习常规的数据划分比例6∶4,考虑到训练数据集尽可能大的原则,将训练数据集和交叉验证数据集设置为27 a、16 a。验证时采用交叉验证的方式,将验证数据集分为两个8 a分别作为第一次验证的验证数据集和第二次验证的验证数据集。图4为模型建立的流程图。
首先将漳河水库蓄水量阈值及对应的模型参数输入模型完成模型初始化,然后在训练数据集上进行迭代训练,训练结束以后进行交叉验证,根据结果调整输入模型的蓄水量阈值与模型参数继续在训练数据集上训练,直到训练出每组在交叉验证过程中效果最好的模型,将两个模型最后进行一次聚合训练,最终得到最佳模型。
水库每个月的弃水线不是完全一样的,漳河水库最大弃水线是178 600万m3,蓄水量阈值的设置与模型参数是成反比的,漳河水库时段蓄水量越大模型参数越小,时段蓄水量越小模型参数越大。当阈值的间隔增大时,对应参数的间隔也要成比例增大,这样才能合理地供水。通过大量计算发现,最佳的计算起点即蓄水量阈值的最大值设置为170 000万m3,对应的模型参数为0.1,然后将蓄水量阈值的步长设置为1 000万m3,初始阈值间隔设置为5 000万m3,对应模型参数的步长设置为0.01,初始参数间隔设置为0.1。每次调整模型时阈值间隔增加1 000万m3,对应模型参数间隔增加0.01,步长保持不变。蓄水量阈值的下限不能设置为死库容,要留一些余地,因此将下限设置为90 000万m3。当蓄水量间隔增加到16 000万m3就不能再增大,对应集合为{170 000,154 000,138 000,122 000,106 000,90 000},而参数的间隔增加到0.18时就不能再增大了,对应的集合为{0.1,0.28,0.46,0.64,0.82,1.0},一共有108种排列组合。表3列举了5个典型模型的相关数据。
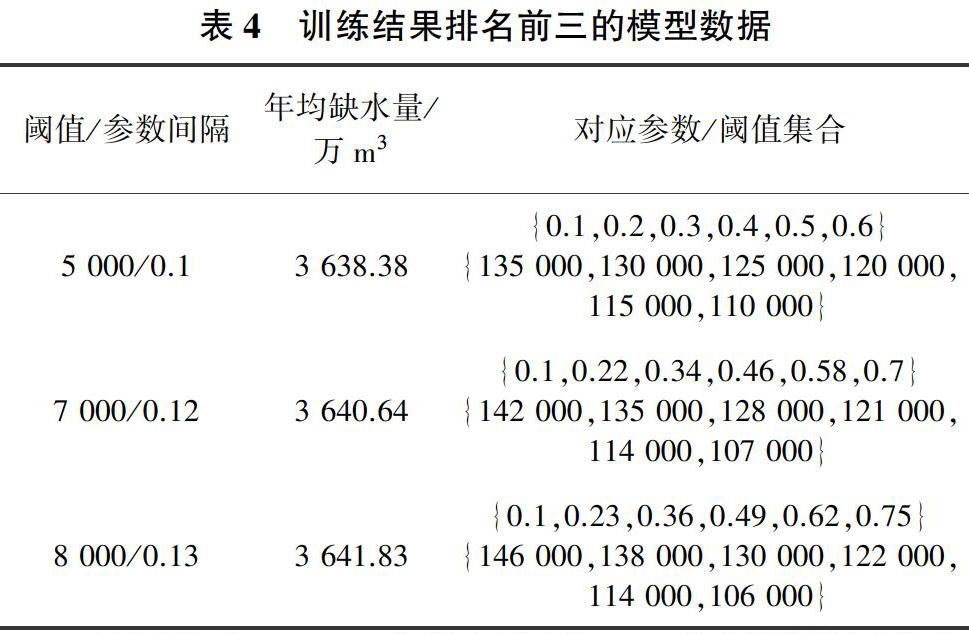
随着阈值与参数间隔的不断增大,候选的阈值与参数集合在不断减小,因此训练次数也在不断减小。表4是训练结果排名前三的模型数据。
以阈值为5 000、参数间隔为0.1为例说明阈值与参数的关系,漳河水库时段蓄水量大于135 000万m3时参数设置为0.1,蓄水量在135 000万~130 000万m3时参数设置为0.2,以此类推,蓄水量小于110 000万m3时,参数设置为1。由表4可见,经过训练之后,模型1年均缺水量最小,为3 638.38万m3。
3.2.2 交叉验证
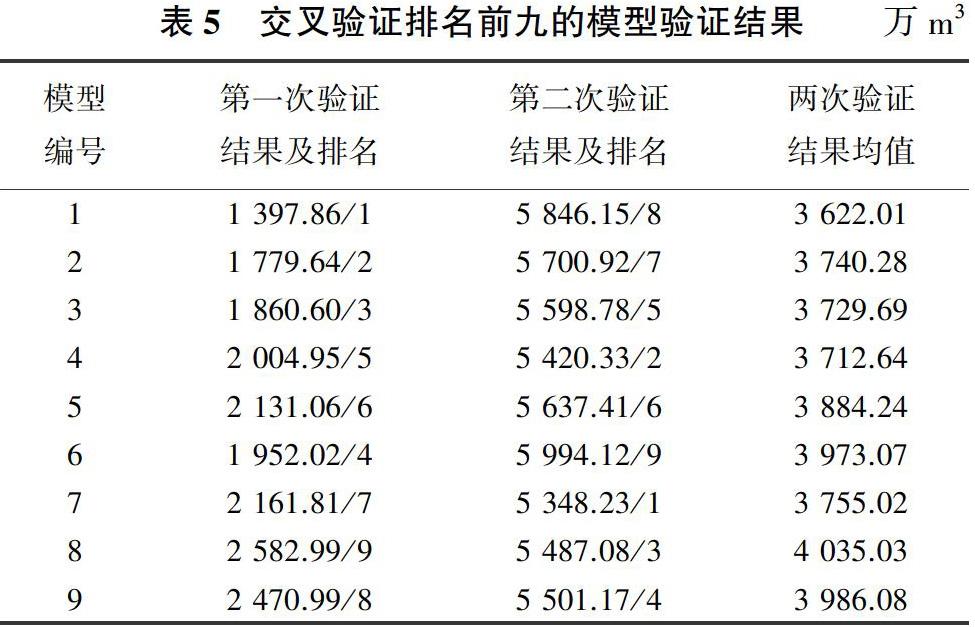
对模型进行交叉验证,列举交叉验证排名前九的模型验证结果见表5,验证结果全部采用年均缺水量来衡量。
由表5可以看出,第一次验证与第二次验证的结果差别很大。这是因为降水变化较大,不同时段生活、生产及农业的需水与水源供水等情况都存在较大变化,这也是采用交叉验证的一个原因。
最后,将每组交叉验证表现最好的两个模型进行一次聚合训练,可以得到最佳模型,模型数据见表6。
4 模型测试与结果对比
将最终训练出来的最佳模型用于供水配制,并與过去的数据进行对比,结果见表7。
由表7可知,漳河水库月最大弃水量减少了2 059.82万m3,漳河水库年均弃水量减少了2 377.99万m3,24座大中型水库年均弃水量减少了1 080.54万m3,研究区年均缺水量减少了126.58万m3。水库弃水量仍然可以满足生态需水,在水资源量不变的条件下减少了研究区的缺水量。漳河水库时段蓄水量与模型参数变化如图5所示。
由图5可以看出,在供水过程中,漳河水库的蓄水量与模型参数成反比关系,即:蓄水量较大(水位较高)时可以多供水,模型参数较小,即前置水源的供水系数较小,供水量将减少;当漳河水库的蓄水量呈上升趋势时,模型参数呈下降趋势,这样就减少前置水源的供水量,增大漳河水库的供水量;当漳河水库蓄水量呈下降趋势时,模型参数呈上升趋势,即增大前置水源的供水量,不足部分由漳河水库补齐;当漳河水库蓄水量持续位于高位时,对应月的模型参数持续位于低位;当漳河水库蓄水量持续位于低位时,对应月的模型参数始终保持为1,即前置水源始终保持最大供水量。
将本文与过去漳河水库的年弃水量与年净供水量进行对比,如图6和图7所示。
由图6和图7可以发现,在供水过程中,本文模型的漳河水库年弃水量只有3 a大于过去的值,有22 a和过去的值相等都为零,有18 a都小于过去的值,弃水减少量最小值是724.19万m3,最大值是11 689.61万m3;本文模型的净供水量有12 a小于过去的值,有2 a和过去的值相等都为零,有29 a都大于过去的值,净供水量增加值最小是84.85万m3,最大是5 709.61万m3。
5 结 论
为了减少漳河水库弃水量,提高水资源利用效率,系统梳理了水资源配置规则,分析出水库弃水量大的原因,进而对传统的模型进行改进,提出了水资源动态配置模型,融合大数据技术,通过训练大数据与交叉验证来求解模型,并在计算中以水库时段蓄水量代替不确定的来水和弃水数据,避免了模型的不确定性,从而使模型更加合理,最后进行了测试与对比分析。水资源动态配置模型打破了“水源分割”的现象,统筹兼顾供水源的供水能力统一调配,在水资源量不变的情况下,减少了区域缺水量,提高了水资源利用效率,也给其他区域的水资源配置提供了参考。
参考文献:
[1] ABDULBAKI D, ALHINDI M, YASSINE A, et al. An Optimization Model for the Allocation of Water Resources[J].Journal of Cleaner Production,2017,164:994-1006.
[2] 齐学斌,黄仲冬,乔冬梅,等.灌区水资源合理配置研究进展[J].水科学进展,2015,26(2):287-295.
[3] BEKRI E, DISSE M, YANNOPOULOS P C. Optimizing Water Allocation Under Uncertain System Conditions in Alfeios River Basin (Greece), Part A:Two-Stage Stochastic Programming Model with Deterministic Boundary Intervals[J].Water,2015,7(10):5305-5344.
[4] 董晓知,徐立荣,徐征和.基于大系统分解协调法的水资源优化配置研究[J].人民黄河,2021,43(4):82-88.
[5] 单义明,杨侃,吴云,等.基于ITSRP模型的吕梁市水资源优化配置研究[J].人民黄河,2020,42(11):42-47.
[6] 吴云,曾超,杨侃,等.基于改进NSGA-Ⅱ算法的水资源多目标优化配置[J].人民黄河,2020,42(5):71-75.
[7] 赵燕,武鹏林,祝雪萍.基于改进萤火虫算法的水资源优化配置[J].人民黄河,2019,41(5):62-66.
[8] MAIOLO M, MENDICINO G, PANTUSA D, et al. Optimization of Drinking Water Distribution Systems in Relation to the Effects of Climate Change[J].Water,2017,9(10):803-816.
[9] 李丽琴,谢新民,韩剑桥,等.面向可持续发展的水资源优化配置研究[J].中国农村水利水电,2013(1):15-18,22.
[10] 王浩,游进军.中国水资源配置30年[J].水利学报,2016,47(3):265-271.
[11] 陈太政,侯景伟,陈准.中国水资源优化配置定量研究进展[J].资源科学,2013,35(1):132-139.
【责任编辑 张 帅】
猜你喜欢
中学物理·高中(2017年12期)2018-03-07
理科考试研究·高中(2017年7期)2017-11-04
新高考·高一物理(2016年11期)2017-07-07
新高考·高一物理(2016年11期)2017-07-07
新课程·中旬(2016年11期)2017-02-10
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
