
基于PCA-BP组合模型的股价预测分析
2021-09-04 08:13:40于春蕾李梦悦尹伟石
长春理工大学学报(自然科学版) 2021年4期
于春蕾,李梦悦,尹伟石
(长春理工大学 理学院,长春 130022)
金融业快速发展的同时,股票作为重要的投资渠道引起广泛关注,股票预测的研究也取得了显著成果。然而,面对股票市场越来越复杂的非线性特征,投资者无法得到准确的预测结果[1-3],其原因在于,利用传统算法构建的模型非线性映射能力较弱,且局限性很大,如灰色预测、时间序列等[4-6]。因此若想进一步在投资上规避风险,就必须在已有的理论成果基础上,进行股票预测的技术研究,这就需要将已知算法的不同优势结合起来,构建组合模型[7-10]。本文选择主成分分析法[11]和 BP 神经网络[12-15]来构建模型,主成分分析法在处理数据上具有优势,在保证信息数据最少丢失的同时,消除数据的冗余信息;神经网络则通过对股票历史数据的学习,在神经元的权值中存储股价变化的规律。通过运用训练好的神经网络来预测未来股价,可以较明显地增强系统预测结果的可信度和精确度。然而,不是所有股票都有足够的数据可供PCA-BP组合模型训练,对此,本文还运用了数据拟合的算法来模拟不同数据量的预测效果。
1 模型原理
主成分分析可以用较少的计算量,达到选择最佳变量子集的效果,其作为多变量分析方法被广泛应用;BP神经网络是一种模拟人脑神经网络结构从而具有一定的预测功能的数学模型,可以充分逼近任意复杂的非线性关系,拥有较为强大的容错能力。这两个算法组成了基本的PCA-BP组合模型。
1.1 主成分分析
主成分分析,是考察多个变量间相关性的一种多元统计方法,旨在通过少数几个主成分来揭示多个变量间的内部结构。其中,每个主成分都是原始变量的线性组合,且互不相关。由此,这些主成分能够反映原始变量的绝大部分互不重叠的信息,引进多方面的指标的同时,又将其中复杂的因素归结为几个主成分,使得复杂问题得以简化,并得到更为科学、精准的信息。具体算法步骤如下:
(1)选定估计样本数,选取指标,构建原始数据矩阵。
(2)为消除量纲、正逆指标的影响,进行原始数据矩阵的标准化处理,得到标准化矩阵。
(3)根据标准化矩阵计算协方差矩阵,以此来反映标准化后数据之间的相关关系及密切程度。
(4)根据相关系数矩阵计算出特征根及对应的特征向量。
(5)得到确定后的多个主成分,同时计算各主成分得分。
1.2 BP神经网络
BP神经网络是一种按误差反向传播算法训练的多层前馈神经网络,其结构分为三层:输入层、输出层、隐含层。两层之间通过网络权值连接神经元,且中间层和输出层上的神经元通过加上阀值的形式对前一层神经元传递过来的信息进行整合。神经元之间的学习向误差减小的方向传递,进一步修正各自的权值。
反向传播算法是若干个算法的集合,其过程是:
(1)前向逐层计算直到输出,计算出模型的预测值。
(2)通过损失函数计算预测值与真实值之间的偏离程度。应用到的均方差损失函数公式可表示如下:
陈静(2004)对中国大学生的文化认同状况进行了调查。调查表明,中国涉外大学生对西方文化持开放心态,并对西方文化认同度较高,然而即便如此,他们仍然认为中国文化是“根”,还是认同中国文化[9]。但是他们也存在一些问题,如对西方文化的了解不够客观,对民族文化了解不够深刻等。刘圣明(2007)在高职英语专业学生中发现了“生产性”取向[10]。杨梅(2011)对大一新生的调查表明,生产性变化在极少部分好学生中偶有表现[11]。刘琼、彭艳(2006)提倡将“生产性”学习作为外语教学的目的[12]。

(3)使用梯度下降算法更新最后一层的参数,然后再一层一层往前更新前面几层的参数,直到所有的参数都被更新。迭代公式如下:


其中,通过前向传递时候计算得出,再利用残差逐层更新参数。
1.3 数据拟合
数据拟合,即曲线拟合,是一种把现有数据透过数学方法来代入一条数式的表示方式,其拟合的曲线能大致模拟数据的基本趋势,一般采用最小二乘法来确定数据的系数,公式如下:

最小二乘法通过最小化误差的平方和,为数据匹配最佳函数,在未知数据的求解,以及优化问题的求解方面有着显著效果。
2 模型建立
为验证模型对不同行业股票预测的适用范围,模型选取了不同行业的五只个股:东方财富、中信证券、建设银行、京东方A以及龙津药业进行股价预测。
经网易财经网站下载得到各股2019年1月2日至2019年12月31日期间244个交易日的开盘价、最高价、最低价、收盘价、前收盘、涨跌额、涨跌幅、成交量、成交金额、换手率、总市值这些股票变量。在这些变量中,收盘价作为预测数据,其他10项作为影响收盘价变化的因子(与收盘价非线性相关),这些均作为历史数据供模型使用。
2.1 PCA-BP组合模型
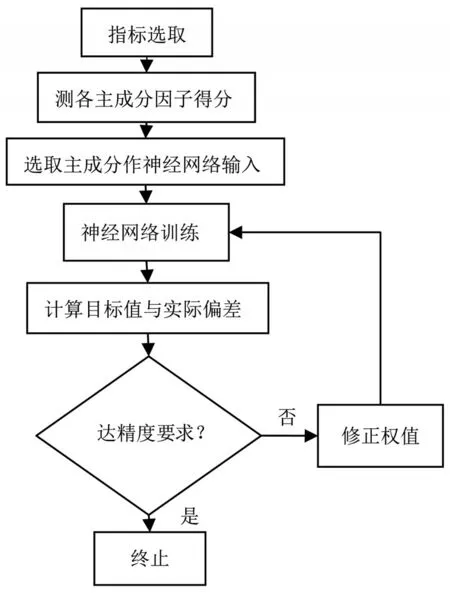
图1 PCA-BP组合模型流程图
依据图1流程图建立PCA-BP组合模型,首先进行指标选取:由于影响收盘价变化的因子不可避免会出现信息的重叠,对此,需要对这些因子进行相关性分析,了解各因子的信息重叠程度。以东方财富为例,选取SPSS统计分析软件,对2019年的这10种影响因子(个案数为244)进行皮尔逊相关性分析,得到相关性分析结果,如表1所示。

表1 相关系数矩阵
表中,涨跌额与涨跌幅相关系数高达0.986;换手率与成交量、换手率与成交金额、成交量与成交金额这三组相关系数分别达到了0.977,0.987,0.973。在保留原有价格信息的基础上,需剔除涨跌额、成交量及成交额这三个关联程度大的因子。余下7个因子之间仍有部分相关系数大于0.8,有必要对这些因子做主成分分析。
将这7个因子作为指标,以月为分析周期,根据主成分分析算法,应用东方财富2019年12月的22个交易日的数据样本,计算指标累积方差贡献率,结果如表2所示。
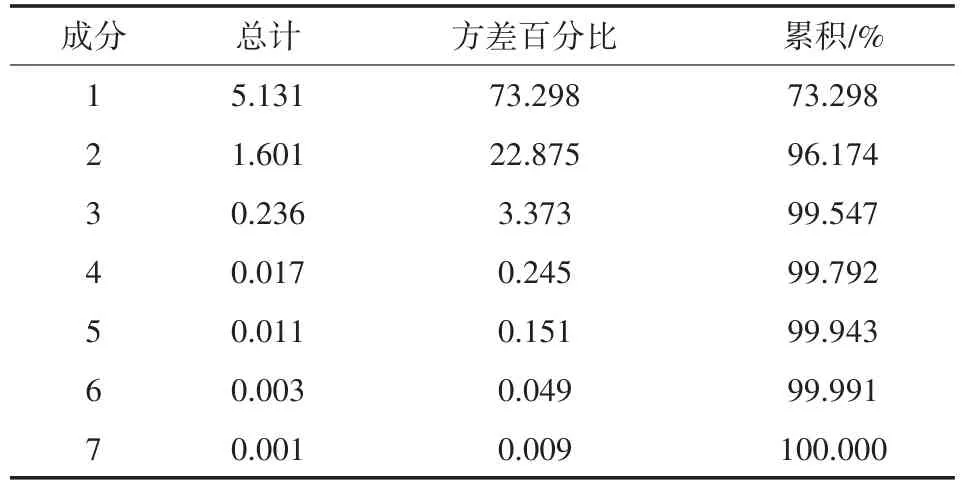
表2 累积贡献率
通过上表可发现两个成分的累积贡献率已达到了96.174%,可选择两个主成分作提取,提取的主成分如表3所示。

表3 成分矩阵
由表3中的数据可得到这两个主成分的得分,将其作为BP神经网络模型的输入向量,将收盘价预测值作输出向量,构建三层BP神经网络模型。首先设定初始参数,并对输入数据进行训练,之后调整相关参数,多次反复训练,不断更正模型结构。通过对长期数据的回测,选择预测值最接近于实际值的参数,最终形成优化的PCA-BP组合模型。
2.2 数据拟合
引入数据拟合的过程可以概括为两步。第一步,目标是通过数据拟合来完成各项指标的预测。其中,拟合步骤为:首先选择Matlab软件中的polyfit函数对指标数据进行曲线拟合,得到拟合数据的系数列表。然后选取ployval函数用来带入自变量的值,并根据数据系数列表,计算数据的值。最后绘制出数据点1至8次拟合的效果图,同时加以比较,选择拟合效果最好的次数,其值即是各项指标的预测值。
第二步,则是将预测到的各项指标输入到训练好的PCA-BP组合模型中,最终得到要预测的某日的收盘价
3 预测结果及分析
依据模型建立过程,研究结果分两个阶段:第一阶段是基于PCA-BP组合模型的回测,进行模型精确度的研究;第二阶段是根据不同时段预测未来某天的收盘价,作实证分析。
3.1 仿真回测
根据下载得到的五只股的2019年数据,以月为分析周期,分别得到每个月的两个主成分得分,并将其输入到训练好的BP神经网络模型,输出得到了各股2019年各月的走势结果。以东方财富为例,将2019年12月2日至6日的模型局部放大回测结果绘制,如图2所示。
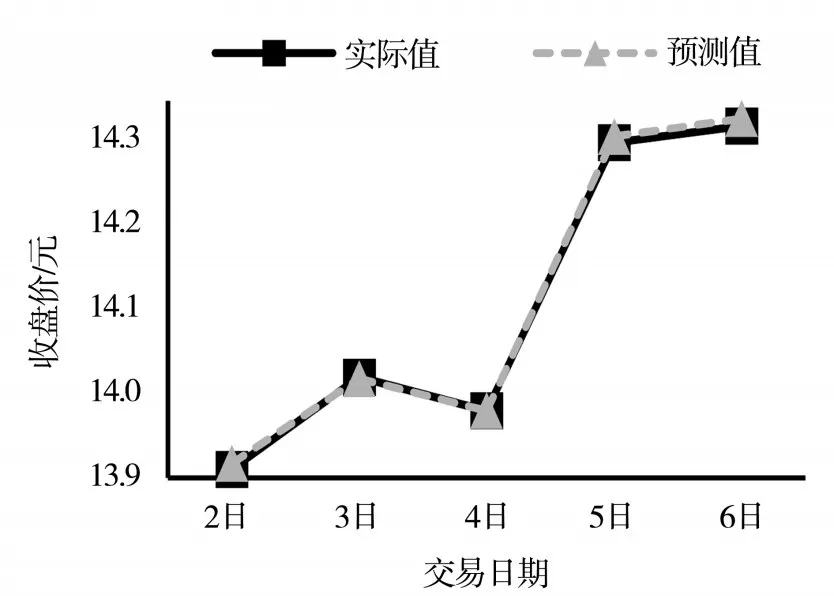
图2 东方财富局部回测结果
通过图2可以看到,预测值和实际值之间仅有微小的差距,为进一步验证模型的预测效果,现计算预测值与真实值间的平均相对误差,并与未经过PCA处理的BP神经网络模型比较,结果如表4所示。

表4 模型对比结果
依据表4数据,可证实主成分分析法与BP神经网络组合模型回测时具有非常高的精确度,且在稳定程度上也高于BP神经网络。然而在实际运用中,PCA-BP组合模型在面对较少的数据量时并没有达到很好的效果,因此下一步需对引入数据拟合算法的模型作实证分析。
3.2 实证分析
分别利用前一周和前一月的数据预测2020年1月2日的的收盘价。首先将这两组数据通过数据拟合的方式分别预测得到当日的最高价、最低价、开盘价、前收盘、涨跌幅、换手率、总市值,并计算各自主成分得分,通过训练好的BP神经网络模型,预测得到1月2日收盘价的不同预测结果,如表5所示。
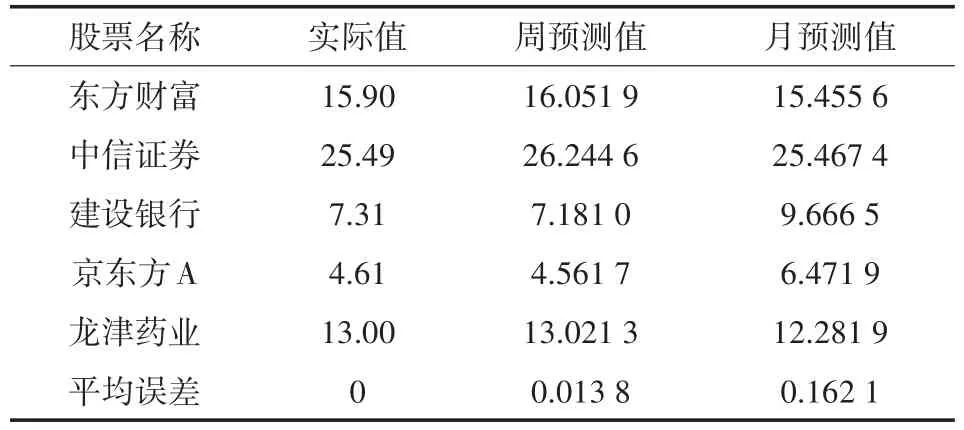
表5 周预测月预测对比结果
由表5数据可以得到,京东方A和建设银行的月预测偏差略大,其他股票预测效果良好。根据此次实验数据,计算得到这五个股的平均相对误差结果,对比周预测与月预测的预测结果,周预测有着更为精准的预测值。分析误差可得,股价在长时间波动较大的情况下,短时间预测得到的结果与近期的股价相关联,不会被之前的大幅度波动干扰,相对结果更为准确。其他三只股长期收盘价稳定,长时间的预测,较多数据使模型的训练结果更加精确,从而更小的缩减偏差。借鉴股票的历史数据变化,能更充分的发挥模型的作用。
4 结论
运用PCA-BP组合模型在大量数据的预测上,得到了与实际值非常接近的预测值,同时,由于数据拟合算法的选取,模型在短时间段的预测上有很大优势。整个股票预测阶段中,研究出与每个阶段都适合的新型方法与技术来建立模型是主要目标,寻找新型的算法,势必经历经验的积累以及思维上的创新,与之相伴的是模型建立和优化时面对不足不断改善的坚持。当今金融行业飞速发展,投资业兴起,股票市场将会愈加复杂多变,为符合当代发展的需要,模型精确度仍需加强,模型复杂度仍需降低,在不同环境下的泛化能力仍需提高,所以,在未来还需要注入更大精力去挖掘神经网络技术在股价预测上的潜力。
猜你喜欢
企业界(2024年8期)2024-07-05 10:59:04
今日农业(2021年19期)2022-01-12 06:16:32
环境保护与循环经济(2021年7期)2021-11-02 08:10:54
国外核新闻(2020年8期)2020-03-14 02:09:19
电子制作(2019年19期)2019-11-23 08:42:00
股市动态分析(2018年21期)2018-06-07 07:42:01
股市动态分析(2017年40期)2017-11-01 09:30:18
股市动态分析(2017年22期)2017-06-19 18:20:25
股市动态分析(2016年32期)2016-10-25 13:45:18
重型机械(2016年1期)2016-03-01 03:42:04
