
融合显著性与运动信息的相关滤波跟踪算法
2021-08-28 04:55张伟俊钟胜徐文辉WUYing
自动化学报 2021年7期
张伟俊 钟胜 徐文辉 WU Ying
随着越来越多的智能机器的普及应用,计算机视觉作为机器的“眼睛”,担负着感知和理解外部世界的功能,成为一项迫切的需求.视觉目标跟踪[1−2]的主要任务是在视频图像序列中建立目标的运动轨迹,在智能视频监控[3]、自动驾驶[4]、人机交互[5]、机器人导航[6]、医学诊断[7]等领域均有广泛的应用.这些上层算法应用的性能很大程度上受限于目标跟踪算法的性能,因此提高目标跟踪算法的鲁棒性、准确率与实时性,能够为各领域的发展提供必要的技术支撑与理论促进,具有重大的意义.
在视觉目标跟踪技术的众多分支中,针对通用物体的在线目标跟踪技术由于不需要使用预训练的物体模型,对跟踪任务执行的场景、被跟踪物体的类别、形状、运动模式均无特殊的限定与要求,存在极其广泛的应用需求,因此成为众多计算机视觉系统与应用的底层关键技术之一,近十年来一直是计算机视觉领域中一个非常活跃的研究课题.与此同时,由于存在目标及场景先验知识缺乏,物体及环境变化不可预测等诸多因素,与已知物体类别的跟踪[8−9]相比,对建模方法的适应性有着更高的要求.要长时间准确定位目标,算法必须适应目标及场景的各种变化,典型的变化包括目标尺度变化、非刚体形变、背景干扰、快速运动与复杂运动等,这些都给通用物体的在线跟踪任务带来了极大的挑战.尽管近年来在理论和应用上均取得了显著的进展[10−11],在线目标跟踪的研究仍有很多关键问题亟待解决,其中之一是被跟踪物体的表征与建模,即目标表征问题.
无论是经典的生成式模型[12−13](Generative model),还是近年来较为主流的判别式模型[14−15](Discriminative model)以及基于深度学习的方法[16−18]都使用了外接目标区域的矩形模板来表征被跟踪目标.虽然这些算法在刚性物体跟踪上取得了很好的效果,但是大部分缺乏能够十分有效区分目标与背景像素的机制.由于目标模型里包含了一部分背景区域,随着噪声和误差的累积,模型容易慢慢偏移到背景上面去,同时也比较难对目标的形状变化实现自适应调整,在背景干扰、目标形变明显或者复杂运动的场景下容易逐渐丢失目标.
与此不同的是,人类视觉系统能够明确地区分目标与背景的区域,并不以矩形模板的形式表征和建模物体.研究表明,人类的视觉机制具有异常突出的数据筛选能力,能够快速有效地识别复杂场景中的显著性区域,准确定位感兴趣的目标[19−20].人类能够轻松实现对目标的稳定跟踪,视觉注意机制扮演了重要的角色.因此,在目标跟踪算法中建模显著性机制,对其提供的像素级观测信息进行集成利用,以提高跟踪算法的鲁棒性与准确率,具有重要的意义.
人类处理运动物体的另一个特点是具备关于运动的先验知识,知道属于同一个物体的像素有同样的运动趋势.认知与心理学的研究[21−22]表明,几个月大的婴儿就已经有关于自由物体连续和平滑运动的知识,能够根据这些知识辅助预测和判断物体的走向.这些关于物体显著性和运动的知识,目前都没有在目标跟踪方法中被很好地建模与集成利用.
上述像素级先验信息没有被有效利用,一个重要的原因是当前主流的目标跟踪模型使用了基于矩形模板的目标表征模型,无法有效地融合这些像素级的图像观测.因此,本文提出使用像素级概率性目标表征模型,将目标跟踪任务建模为一个像素级目标概率的贝叶斯推断(Bayesian inference)问题,在每一帧使用前后帧的像素关联来向前传递目标概率,再进一步融合当前帧显著性模型和运动观测模型提供的像素级图像证据,递推地产生目标概率图.该模型提供了与当前主流矩形模板目标表征模型互补的信息,可以用来预测目标位置,与使用矩形模板目标表征的算法进行融合决策,提升目标跟踪算法在背景干扰、目标形变、复杂运动等场景下的鲁棒性.同时,像素级的目标概率图也可产生目标分割结果,为视频目标分割、增强现实以及行为分析等应用和研究提供帮助.
1 相关工作
目前较为主流的视觉跟踪算法使用判别式模型,在已跟踪图像序列上采集目标与非目标样本训练分类器,通过对新图像上采样的候选目标矩形框进行分类判决来完成跟踪任务[14−15],也被一些研究者称为检测−跟踪(Tracking-by-detection)框架.其中,基于岭回归(Ridge regression)分类器的算法由于可以利用循环矩阵的特性,将空间域的训练样本转换到频域进行加速计算,得到基于相关滤波(Correlation filter,CF)的算法实现[14],具备算法速度与准确率俱佳的特点,吸引了大量的研究和改进工作[23−25].
为了避免基于矩形模板的目标表征模型受到目标形变、背景噪声以及误差累积的影响,导致算法目标模型偏移的问题,一些跟踪算法[26−27]采用基于子块的模型(Part-based model)来进行目标表征,以减少背景区域对模型的干扰,对目标形变和遮挡等常见挑战性因素具有一定的自适应能力.但是,相对于单个矩形模板的表征方法,基于子块的目标表征模型存在参数较多,模型较为复杂,需要灵活处理如何选择和更新子块等问题,在长时间跟踪(Long-term tracking)过程中仍然无法保持足够的算法鲁棒性,限制了其进一步的应用.
另一类跟踪算法将目标分割引入到跟踪过程中,得到像素级的目标模型,目标表征更为精确.Fan等使用了抠图技术(Image matting)对目标前背景进行分割,并把分割结果反馈到跟踪过程中[28].Godec等使用Grabcut算法进行目标分割,并在每帧使用分割结果指导下一帧的检测[29].Bibby等使用水平集(Level set)进行目标的分割,以处理目标形状变化[30].这一类算法存在的问题是,模型极大依赖于图像分割算法的鲁棒性,在背景干扰严重的情况下,单帧的分割误差对后续操作影响较大,容易循环积累,导致后面的模型出现偏差.
上述基于分割的目标表征方法对每个像素是否在目标物体上做出了确定性的判决,像素级目标概率模型则在此基础上进一步改进,对像素点是否在目标上进行概率性的估计.这样的模型相当于对目标进行了软分割,在建立了像素级目标模型的同时,对于分割误差有更高的容忍度.Oron等对目标进行了像素级的建模,并把像素概率推断融入到Lucas-Kanade目标跟踪框架之中[31].Possegger等针对目标和背景分别建立了颜色直方图来作为分类器,对每个像素给出目标概率推断[32].Son等使用了梯度提升决策树算法(Gradient boosting decision Tree,GBDT)来作为分类器给出目标与背景的分类[33].Duffner等则综合使用霍夫投票(Hough voting)与颜色直方图进行像素分类器的建模[34].
在文献[34−36]中目标跟踪与分割问题被联合建模,不同来源的像素级图像特征由一个贝叶斯推断框架进行融合.虽然这些工作和本文的贝叶斯推断方法有相似之处,但在传递概率和像素级似然概率的建模方式等方面,都和本文提出的方法有很大的区别.此外,贝叶斯推断也被广泛应用到多物体估计[37]、识别[38]与跟踪[39]问题当中.在这些任务中运动信息通常被用来关联不同帧之间检测到的目标.
近年来,视觉显著性检测[19−20]作为一项新兴的课题,吸引了大量的研究,它通过模拟人类视觉注意机制对图像信息进行筛选处理,选取优先处理区域,提供给其他较上层的计算机视觉算法进行使用.显著性检测领域的代表算法包括由Itti等提出的基于空间域的计算模型[40]、Hou等提出的基于频谱域的方法[41]等.此外,基于测地距离(Geodesic distance)和基于最小障碍距离(Minimum barrier distance,MBD)的显著性算法[42−43]使用背景先验和距离度量来衡量像素点的显著性,在数据集上取得了很好的效果,Zhang等在此基础上提出的加速算法[44]由于较快的计算速度和出色的检测效果而受到关注.一些研究者尝试将视觉显著性计算模型引入跟踪系统中,通过模拟人类特有的视觉选择性注意机制为采样提供先验知识,从而提高跟踪效率[45].
目标跟踪领域的另一个近期发展趋势是深度学习与卷积神经网络(Convolutional neural network,CNN)技术的应用.一部分研究者在判别式跟踪模型框架内通过使用对目标表征能力更强的CNN特征,来获得更好的跟踪效果[46−48],其中Choi等通过对CNN特征进行压缩来保证算法的实时性[48].另外一部分研究者则通过构造和训练端对端(End-to-end)的卷积神经网络来完成跟踪任务,其中Ber t inet t o等提出的全卷积孪生神经网络(Fully-convolutional siamese networks,SiamFC)是十分具有代表性的工作[16],Valmadre等提出的CFNet算法在此基础上将相关滤波器建模为深度神经网络的一个层[17],使得算法集成了深度学习与相关滤波技术的优点.此外,Hong等使用卷积神经网络特征通过后向传播(Back-projecting)技术构造目标的显著图[46],Choi等在跟踪算法中通过训练深度回归网络(Deep regression network)建立注意力机制[18],Gladh等在基于深度学习方法的跟踪框架内引入了深度运动特征[49],这些工作虽然采用了与我们截然不同的建模方式,但是与本文具有相似的出发点,认为注意力机制以及基于运动的图像观测能够提供与现有模型呈现互补性的信息,从而有效提升目标跟踪算法的精度与鲁棒性.
2 多目标表征融合跟踪框架
本文使用了基于检测器的目标跟踪框架,其核心思想是根据已跟踪的目标采集正负样本训练检测器,在待跟踪图像上通过一定的预测搜索策略产生大量的候选样本,使用之前训练的检测器对这些样本是目标物体的概率进行估计,选取最佳选项作为跟踪输出结果.
具体的,在第t帧的时候,在图像I t中采集大量候选目标样本形成集合Qt,从中选择一个作为目标矩形框p t,以使得目标函数最大化:
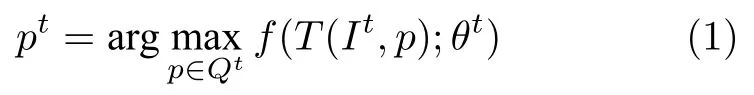
其中,T(I,p) 是一个图像变换,对图像I中的矩形窗口p提取一定的特征描述符,构成目标的视觉表征,评估函数f(T(I,p);θ) 再对视觉表征数据根据模型参数θ赋值一个分数.第t帧的模型参数θt根据之前帧的图像观测与目标位置的集合来进行选择.
在每一帧,目标跟踪问题的核心转化为评估函数f(I,p) 的构造与求解.为了融合互补的跟踪模型,充分利用不同类型图像特征和目标表征方式的优势,把评估函数f(I,p) 设置为两个分数的线性组合,两个分数fpxl(I,p) 和ftmpl(I,p) 分别基于像素级目标表征模型和矩形框表征模型来进行计算,加权系数分别为γ和 1−γ:

图1 给出了多目标表征模型融合跟踪框架的示意图.基于矩形框目标表征的相关滤波器模型、基于像素级概率性目标表征的运动模型和显著性模型均通过上一帧(训练帧It−1) 提供的目标邻域图像数据进行模型训练,在当前帧(测试帧It)对搜索区域中的候选目标框位置进行评估分数的求解.其中,相关滤波器模型与当前帧数据直接进行求解可得到评估分数ftmpl(I t,p);运动模型和显著性模型结合当前帧图像数据求解得到像素级目标似然概率图,再进一步通过本文提出的转化方法得到fpxl(I t,p).两种目标表征模型的评估分数线性融合之后,应用式(1)定位最优的目标位置p t.
2.1 基于像素级目标表征的评估分数
基于像素级的目标表征模型计算候选样本的评估分数fpxl(I,p) 时,可使用该样本矩形框内每个像素的目标概率来进行估计.具体的,对于已知目标位置,矩形目标框p内的像素位置集合记为H ⊂Z2,目标概率函数ψI(x):H →R是从每个像素位置x到目标概率分数的映射,定义评估函数为:
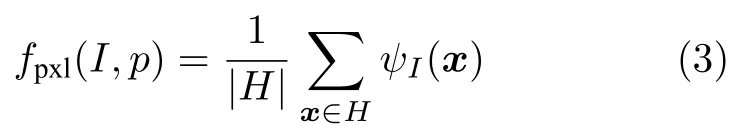
即取目标框内像素目标概率分数的平均值来作为目标框的评估分数.像素点目标概率函数ψI(x)的建模与求解是本方法的重点,具体在第4节进行详细的阐述.
在实际算法实现中,我们取搜索区域 Ω,计算搜索区域上每个像素位置到目标概率分数的函数映射ψI(x). 再通过积分图像[50](Integral image)计算得到密集采样的每个目标框位置的目标函数fpxl(I,p).具体的,在第t帧计算目标函数fpxl(I,p)的时候,根据第t −1 帧已经估算的目标中心位置x[x,y]T以及尺度大小[d1,d2]T,取中心位置为[x,y]T,尺度大小为的矩形区域作为搜索区域 Ω 来进行积分图像的计算(如图1左下图中的黑色虚线框所示),其中系数α控制了搜索区域相对于目标尺度的扩大比例,经验性地设置为 1 .每一帧根据目标函数f(I,p) 和式(1)确定新的目标位置之后,使用判别式尺度空间跟踪器[23](Discriminative scale space tracking,DSST)进行新的目标尺度的估算.
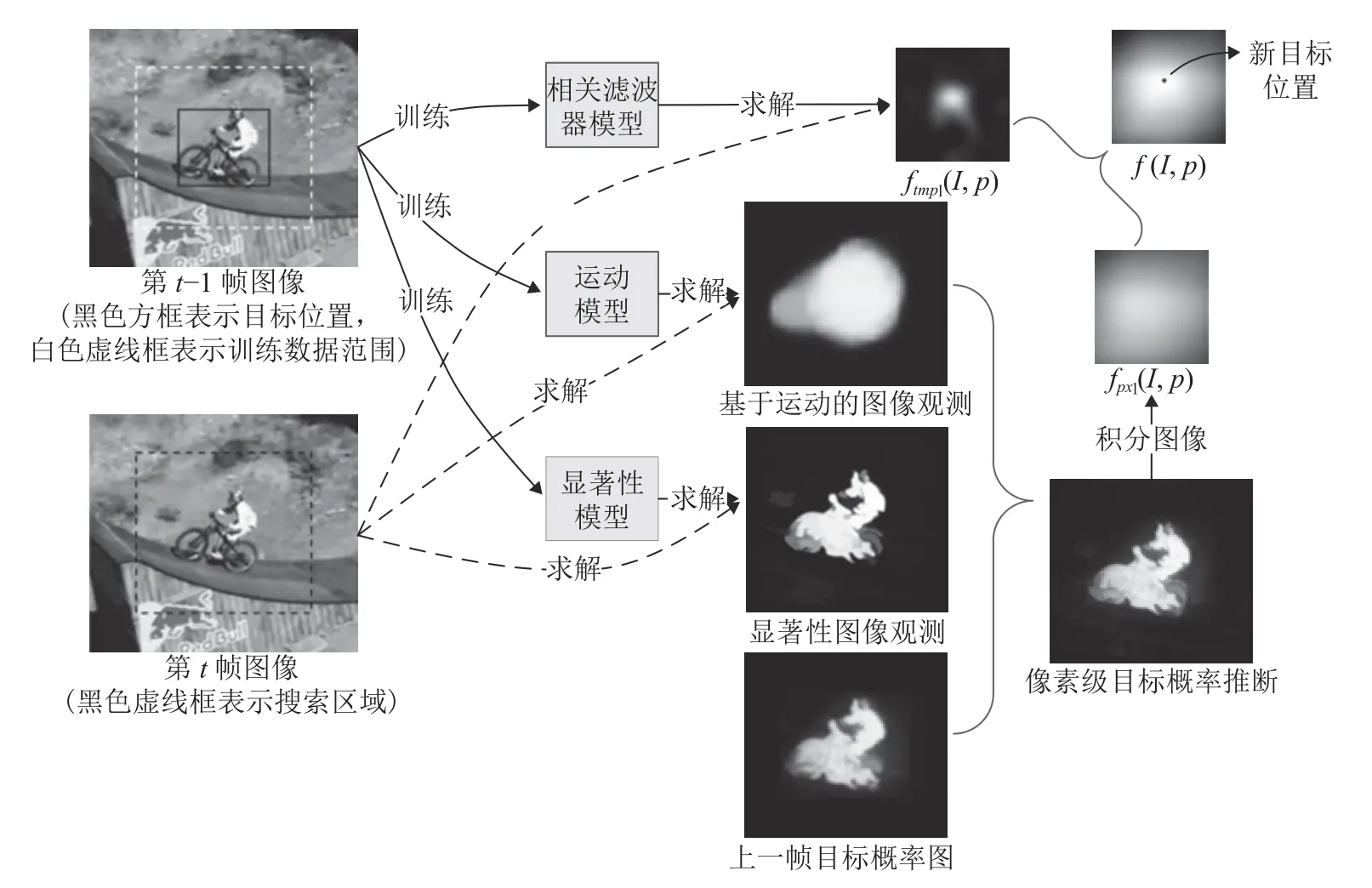
图1 总体跟踪流程图Fig.1 Overall tracking procedure
2.2 基于矩形框目标表征的评估分数
在矩形框目标模型中,对于矩形目标框p内的采样网格点集合T ⊂Z2,定义D通道的特征图像ϕI:T →RD,基于矩形框模型的分数定义为特征图像ϕI的一个线性组合:

在这里使用了常见的基于矩形框目标表征的判别式相关滤波器[23]进行统计建模,参数h ∈R|T|×D对应于模型中的滤波器参数,h[x] 表示其在像素位置x处对应的长度为D的向量.本文使用步长为4的特征网格,提取方向梯度直方图(Histogram of oriented gradient,HOG)特征来与基于矩形框的目标表征模型配合使用.
该算法利用目标图像平移产生的循环样本近似表示密集采样的训练样本,使用循环的样本数据集来训练岭回归分类器.岭回归的本质是一种加入正则化的最小二乘法,对病态数据有很好的拟合能力.假设训练样本特征图像记为f,其第l个通道特征表示为fl,l ∈{1,···,D}.记相关滤波器为h,由D个单通道滤波器h l组成.多通道相关滤波器算法的目标是最小化相关滤波响应结果与期望的输入响应结果g之间的L2残差,即
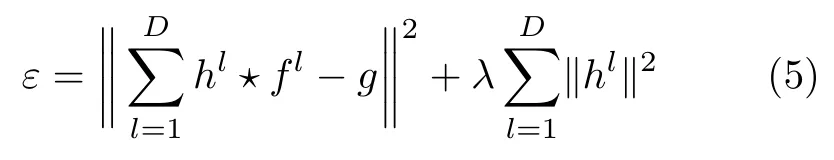
其中,⋆表示循环相关操作,g表示相关滤波训练输入,由一个峰值位于f中心的高斯函数生成,表示通过循环移位得到的训练样本与目标重叠度高的取为正样本,偏离目标较远的取为负样本.公式后半部分是一个权重系数为λ的正则化项,用来防止过拟合.
上式是一个线性最小二乘问题,通过求偏导并化简即可计算得到分类器参数h l,其闭式解为:
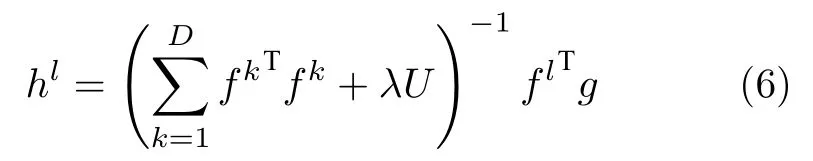
将时域的卷积转化为频域的点乘,能极大地降低计算量,保障算法的实时性.文献[51]通过应用帕塞瓦尔公式(Parseval′s formula)以及离散傅里叶变换的特性,推导得到相关滤波器h l在频域内的闭式解为
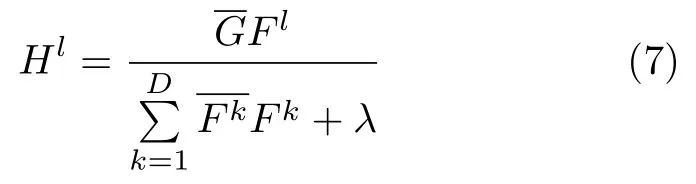
式中,大写字母表示相应变量的离散傅里叶变换,乘法除法均为矩阵对应元素相乘或相除,和分别表示Fk和G的复数共轭形式.
在仅考虑单个目标样本的情况下,式(7)进行离散反傅里叶变换给出了最优滤波器h.在目标跟踪过程中,目标的外观会发生变化,为了能持续跟踪目标,需要考虑不同时刻t的目标样本对滤波器进行在线更新.在第t帧图像上进行目标跟踪时,相关滤波器h在频域内的更新公式为
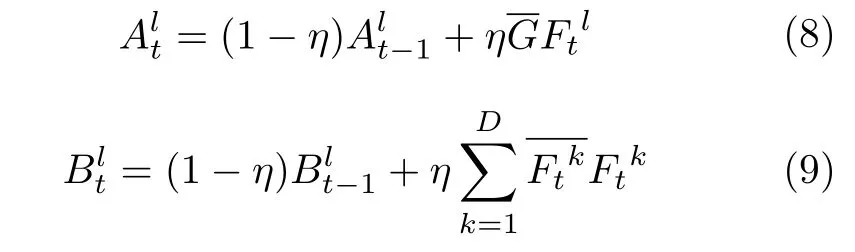
在第t帧的时候,使用密集采样的搜索策略,在搜索区域上采集候选样本,远离目标中心的样本通过目标中心样本循环移位产生,则通过相关滤波器输出可一次性计算每个候选样本的评估分数.对搜索区域提取相应的特征图像,转化成频域特征图像Φt,可以方便地在频域内计算相关滤波器输出,再转换为时域滤波结果,即

3 像素级概率性目标表征模型
第2.1节提出基于像素级概率性目标表征模型ψI(x)来构造评估函数.本节对ψI(x) 的建模与求解进行详细的介绍.
3.1 像素级贝叶斯推断框架
以x[x,y]T记搜索区域 Ω 中的像素位置,使用表示像素位置x在第t帧的图像观测向量,∈{0,1}表示像素位置x在第t帧的类别(以0表示背景,1表示目标),表示从到的图像观测的集合.对于每个像素位置x,属于类别C ∈{0,1}的概率通过当前帧以及之前帧的所有图像观测进行推断.有别于传统的对候选目标框是目标的概率进行估计的做法,像素级概率性目标表征模型对搜索区域的像素点在目标上的概率进行估计,将目标跟踪任务建模为一组并行的像素级目标概率估计问题,如图2所示.概率的推断通过递推的贝叶斯模型完成,分为预测过程和更新过程,分别集成动态模型与观测模型.
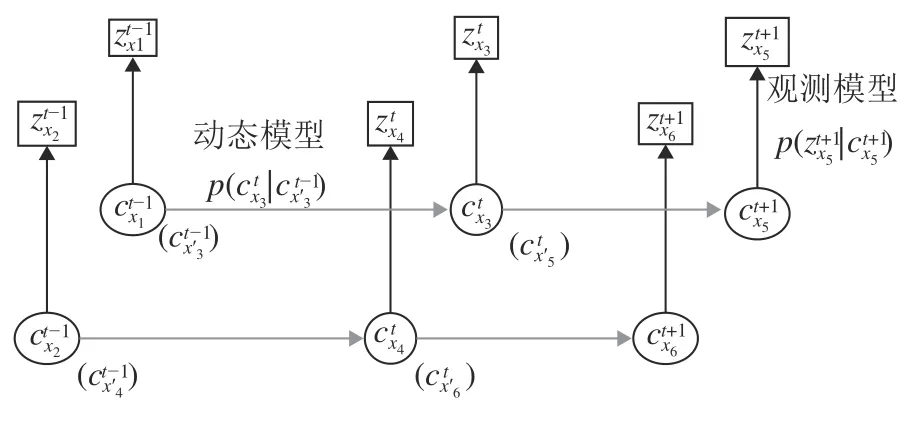
图2 像素级目标概率推断模型的贝叶斯网络示意图Fig.2 Bayesian network representation of pixel-level target probabilistic inference model
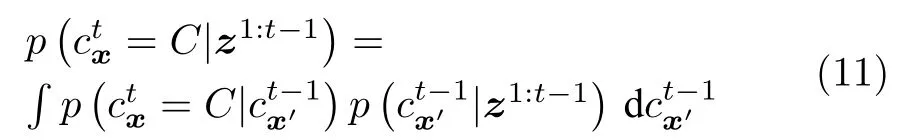
其中,x′表示第t帧的像素位置x在第t −1 帧对应的像素位置.
更新过程是得到当前时刻的观测信息z t之后,将式(11)计算得到的预测概率分布根据目标的观测方程进行更新,得到:


其中,Dt(x) 表示像素位置x在时间t的背景距离测度,Mt(x) 表示像素位置x在时间t的后向光流矢量,分别为两个子观测模型在第t帧的观测量.
本文提出的像素级模型对图像中的运动信息有两个方面的利用.一方面,时间上的运动关联通过动态模型来进行表示,在第3.2节具体阐述;另一方面,空间上的运动关联通过基于运动估计的观测模型来进行建模,在第3.4节具体阐述.另外,基于显著性信息的像素级模型在第3.3节具体展开.这三方面的信息可分别理解为基于时间域运动连续性的显著性估计、基于空间域运动连续性的显著性估计、以及基于本帧空间域信息的显著性估计,三者通过一个统一的贝叶斯推断框架进行融合,构成完整的时空显著性模型.以下对每一部分进行详细介绍.
3.2 动态模型

由于x′可以是亚像素级别的位置,而且对于搜索区域中的(像素x ∈Ω)已经有上一帧的像素级目标概率估计,因此式(11)中像素位置x′的上一帧目标概率可以通过插值来计算获得.
Duffer等提出的方法[34]也使用了像素级贝叶斯模型,不过他们的方法并没有显式地建模帧与帧之间的像素关联,而是假定像素位置之间是独立的,以简化计算复杂度.这样的假设仅仅适用于帧率较高,帧间目标相对位移很小的场景,导致该方法无法很好地处理目标形变、快速运动等更复杂的情况.
3.3 基于显著性的观测模型
在目标跟踪任务中,常见的像素级观测模型是基于颜色特征,对于目标和背景在线地建立统计直方图[32]或者训练分类器[29].这样的模型很容易受到背景噪声的影响(如图3(b)所示),在目标与背景表观特征具有相似性的情况下很难建立有效的判别模型.本方法受到显著性检测文献的启发,综合地考虑空间距离和颜色距离两方面的信息.一方面,和背景区域在空间距离上更远的像素,属于目标的概率更高.另一方面,和背景区域在颜色上差异更大的像素,属于目标的概率也更高.因此,本文提出一种新型的观测模型,综合衡量目标邻域像素与已知背景区域在颜色和空间两个维度的距离,来估计像素的目标概率,在目标和背景颜色特征十分相似的情况下仍然能够给出非常鲁棒的估计结果.图3(a)给出了跟踪图像的样例,黑色虚线框内是目标概率待估计的搜索区域,图3(c)显示了本章模型给出的像素级目标似然概率估计,相比于颜色直方图模型[32]得到的结果,显著性模型给出的估计结果明显对背景噪声的干扰更加鲁棒.

图3 基于颜色与基于显著性的目标似然概率估计结果对比Fig.3 Results of color-based and saliency-based target likelihood estimation
背景先验理论[42]假设大多数图像边界区域是背景,以此为基础的图像边界先验方法已被应用于物体显著性检测任务中,在实验中展示了可靠的结果.本方法在目标跟踪场景中对背景先验进行应用,根据第t −1 帧目标所在位置和尺度取扩大区域作为搜索区域,假设该区域之外的图像为背景区域,当前帧的观测量定义为每个像素点到背景区域的最短距离.
理论上,需要定义待求解区域 Ω 中每个像素点到背景的距离.假定基于二维单通道图像区域来进行计算,把区域中一条从某像素点x到背景种子点的路径记为π〈π(0),···,π(k)〉,其中π(i) 和π(i+1)是区域 Ω 中相邻的两个像素,设F(π) 为路径消耗,S为背景种子像素集合,则要计算的路径图D(·) 定义为:
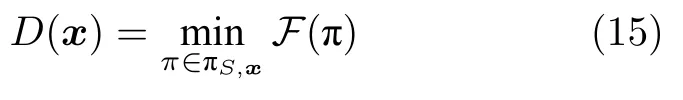
其中,ΠS,x表示连接S和x之间的所有路径.两个像素点x1和x2之间的路径长度有如下性质f(x1→x2)f(x2→x1)≥0.路径消耗的定义取决于不同的应用.一种经典的定义是使用测地距离[42],可以对颜色和空间位置两方面的距离进行综合的衡量.这种方法累加了路径上所有相邻像素点的灰度差作为路径消耗,即
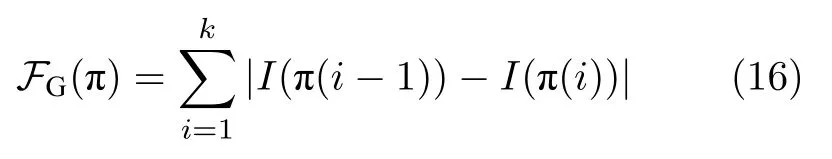
其中,I(·) 表示像素点灰度值.文献[43]提出使用最小障碍距离来进行显著性检测,其路径消耗定义为:
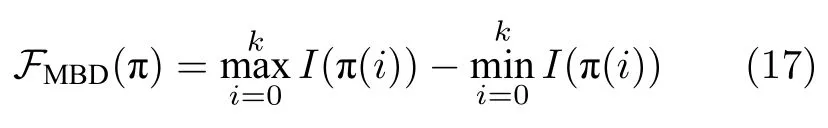
最小障碍距离检测相比于经典的测地距离,可以得出对噪声和分辨率更加鲁棒的显著性检测结果.Zhang等提出了快速最小障碍距离算法[44],利用光栅扫描算法,计算每个像素与邻近像素的距离,累加其中的最大值来进行近似计算,使得算法的实时性得到保证.
将文献[44]计算得到的最小障碍距离图归一化使得最大值为 1,并进一步应用基于对数运算的Sigmoid函数进行对比度拉升操作:

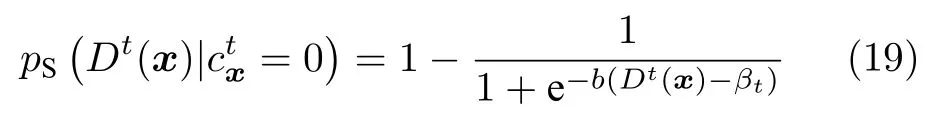
其中,模型参数βt是根据已跟踪图像进行在线统计得到的阈值参数,用于区分目标与背景,b为固定的控制系数,用来控制对比度拉升的程度.
3.4 基于运动估计的观测模型
自由物体的运动具有连续和平滑的属性,属于同个物体的像素通常具有一致的运动趋势,这一先验知识有助于视觉系统有效区分目标和背景的像素区域.本节对目标和背景的运动参数进行解算,基于这一关于运动的先验知识建立观测模型.在图4中,背景区域中存在与目标在颜色特征上十分相似的像素点,传统的基于颜色的分类器很难有效地区分这些像素点,然而由于它们具有和目标明显不同的运动趋势,通过对运动的建模可以很容易被区分开来.对该信息进行建模表达,可以在物体进行复杂运动(比如旋转+平移),其他模型难以适应目标变化的情况下提供有效信息,得到准确的目标定位结果.

图4 基于目标与背景运动模型的似然概率估计示意图Fig.4 Demonstration of likelihood estimation based on motion models of target and background
对于每个类别C ∈{0,1}(其中0代表背景,1代表目标)在每一帧估算其旋转角度θC和位移矢量 [u C,v C]T,所有的运动状态参数记为s[θ0,u0,v0,θ1,u1,v1].记A1和b1分别为目标的旋转矩阵和位移矢量,A0和b0分别为背景的旋转矩阵和位移矢量,已知运动状态参数s的情况下有:
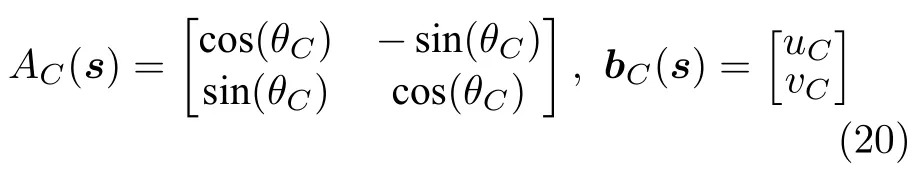
运动参数s计算的时候以本帧为参考帧,即估计的运动参数定义了目标和背景从本帧到上一帧的运动.在理想运动参数s已估计的情况下,M0(x,s)表示位置x属于背景区域假设下理想的后向光流矢量,M0(x,s) 表示位置x属于目标区域假设下理想的后向光流矢量,则有
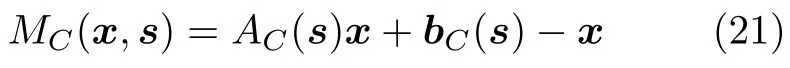
在本模型中观测量为每个像素点的后向光流矢量M(x),在像素点属于目标/背景的条件下,该观测量分别是目标/背景模型理想运动矢量的一个带噪声的观测.假定在这两种条件下,光流矢量两个方向运动分量的观测误差均服从高斯分布且相互独立,即
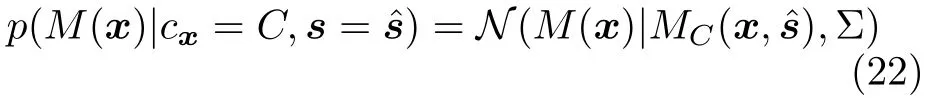
假设对于当前帧得到了s的最佳估计,基于运动估计的像素级似然概率通过下式进行估计:
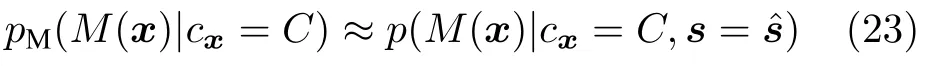
在式(20)~(23)中为了公式的简洁省略掉了上标t.
计算机视觉应用中常用的鲁棒估计算法包括随机抽样一致性(Random sample consensus,RANSAC)算法、M估计抽样一致性(M-estimator sample and consensus,MSAC)算法和随机抽样最大似然估计(Maximum likelihood estimation by sample and consensus,MLESAC)算法等[53].这些算法根据随机表决的原理来计算模型参数,基本思想是选择一个小的数据点集,对其进行拟合,查看有多少其他点可以匹配到拟合的物体上,继续l次迭代直至达到某个终止条件时找到有较大概率的模型参数.
本文使用MLESAC算法,从l次抽样中选择使得似然度最大的那次抽样的模型,得到运动模型参数并进一步通过式(23)得到了基于运动估计的似然概率,提供给像素级贝叶斯推断模型与多目标表征融合跟踪框架进行融合计算,最终得出目标位置.图1详细展示了基于运动估计的像素级似然概率,基于显著性的像素级似然概率,与基于矩形框目标表征的相关滤波器模型响应如何从图像观测中计算产生,并且由一个统一的框架融合,产生最终跟踪结果.
4 实验结果与分析
本节首先选取了几个具有代表性的跟踪序列,和与本文方法相关性较大的最新算法进行了定性的比较,以验证本文的方法动机与所取得的效果.其次,在广泛使用的目标跟踪标准数据集(Object tracking benchmark)OTB-100[10]上定量比较所提出的算法和目前主流目标跟踪算法的性能,对总体性能以及不同挑战性因素影响下的性能分别进行分析,以明确方法的优劣势与适用场景.最后,为进一步客观评估本文算法,使用最近一期视觉物体跟踪挑战赛(Visual object tracking challenge)的数据集VOT 2018[11],与所有参与测试的最新算法进行了比较,对算法的短期跟踪性能进行评估.
本文使用Matlab实现了提出的目标跟踪算法,部分模块使用C++实现,实验在配备有3.1GHz i7 CPU和8GB RAM的计算机上进行,在实验中的平均帧率为21帧每秒(Frames per second,FPS).
4.1 典型序列跟踪结果分析
本节定性比较提出的算法和与本文算法相关度较高的几个主流方法,包括经典的相关滤波器算法DSST[23]和SRDCF[24],深度学习的代表性方法CFNet[17],以及使用深度学习技术建模注意力机制的ACFN[18]方法.本节从OTB-100数据集中选择8个具有代表性的序列进行着重分析,截取样例帧在图5中进行展示分析.这些序列包含了目前最新跟踪算法致力于解决的各种视觉挑战,包括尺度变化、背景复杂、目标形变、平面内旋转等.
图5中的8个序列从上到下总体上按照跟踪难度递增排列,前3个为形状比较规则方正,在跟踪过程中形变不大的序列,前两个尺度变化较平缓,第3个尺度变化较为明显.第4到第6序列包含了明显的目标非刚体形变,跟踪难度明显加大,最后两个序列除了形变还包含持续的平面内旋转运动,是目前主流跟踪方法普遍难以实现鲁棒跟踪的场景.此外,多个跟踪序列包含不同程度的复杂背景干扰.以下针对每个挑战性因素进行分别讨论.
尺度变化通常由相机和目标之间的距离变化引起,是目标跟踪中比较常见的一个视觉挑战,图5中几乎所有的序列都包含了不同程度的尺度变化.从前面3个较为简单的序列可以看出,对于此类形状较为方正,跟踪过程中形变较小的序列,参与比较的几个主流算法几乎都能够较为准确地定位目标位置.而在尺度估计方面,本文算法和DSST算法具备一定的优势,在几乎所有尺度变化的地方都能够及时更新目标框大小.尤其在第2、第3个序列的后面阶段,本文方法与DSST算法的尺度估计明显更为精确合理.由于本文提出了多目标表征融合框架,对基于矩形框和像素级表征的方法进行融合,基于矩形框部分选用DSST作为基线方法,因此继承了该算法在处理尺度变化上的优势.
背景复杂的情况在目标跟踪场景中也十分常见.一种情况是场景里存在和被跟踪目标外观十分相似的其他疑似目标,典型例子是图5第5行的Soccer序列;另一种是背景本身颜色等特征和目标相似,难以通过分类器有效辨识,图5第2、第7和第8行的Singer2、Diving和Motor Rolling序列均在跟踪过程中的部分片段存在此类情况.从图中可以看出,在这些场景里面,本文的算法受益于基于显著性先验和运动先验的观测模型,对背景干扰具有很强的鲁棒性,在其他多个主流算法跟踪失败的情况下仍然获得了十分准确的跟踪结果.
目标形变在非刚性物体的跟踪场景里普遍存在,典型例子是图5第4~7行的Bolt、Soccer、Panda和Diving序列.Bolt序列中的运动员在跟踪过程中存在快速运动,同时伴随有目标形变,在起跑之后SRDCF和CFNet很快丢失目标,ACFN虽然准确定位了目标位置但是尺度估计偏差较大.Soccer序列中除了目标形变,还存在较为明显的背景干扰和运动模糊现象,DSST、ACFN和CFNet跟踪器均在不同阶段出现较大的偏移.Panda序列中SRDCF、DSST和CFNet先后丢失目标,而本文算法在这几个序列中均保持鲁棒而准确的跟踪效果,在此类跟踪场景中具有明显的优势.
目标平面内旋转是目前主流目标跟踪算法面临的难题之一,基于矩形模板的目标表征模型很难对旋转运动导致的目标形状与外观变化进行自适应调整,导致跟踪失败.图5第7和第8行显示了两个典型的例子,序列中的跳水运动员和摩托车均存在持续的平面内旋转和移动,且部分帧存在复杂背景干扰问题,参与比较的几个主流算法(包括本文的基线方法DSST算法)均在目标开始运动不久之后丢失目标,而本文算法对两个序列均做到了对目标的全程跟踪,且具有较高的跟踪精度,说明所提出的像素级模型、集成的显著性与运动信息与现有模型呈现互补性,能够十分有效提高此类场景下的算法跟踪精度和鲁棒性.

图5 本文提出的跟踪算法和DSST[23]、SRDCF[24]、ACFN[18]、CFNet[17]在8个典型OTB序列上的跟踪结果(从上往下分别是David、Singer2、Doll、Bolt、Soccer、Panda、Diving和MotorRolling序列)Fig.5 Tracking results using our proposed method compared with DSST,SRDCF,ACFN and CFNet on 8 OTB image sequences(From top to down:David,Singer2,Doll,Bolt,Soccer,Panda,Diving and Motor Rolling
4.2 OTB-100 数据集实验
OTB-100数据集[10]总共包含有100个测试序列,数据集上的所有图像序列都已经被人工标注,标注的真值在图像上表现为包含有目标的矩形框.数据集本身提供了包括Struck、SCM、TLD等在内的29个经典跟踪算法的跟踪结果,后续提出的主流目标跟踪算法大多数在该数据集上进行了评测并提供了实验结果数据,所以使用该数据集能够很方便地评估跟踪算法的性能.
为了使得评估的效果更加公平有效,选用后续提出的性能更优越的主流算法,以及与本文方法相关度较高的算法进行性能比较,包括相关滤波模型的代表性算法DSST[23]、Staple[25]、SRDCF[24],判别式模型代表性方法DLSSVM[15],使用卷积神经网络特征构造显著图的CNN-SVM[46]算法,结合深度学习与相关滤波模型的CF2[47]、CFNet[17]、ACFN[18]和TRACA[48]算法.其中CFNet方法作者提供了使用深度卷积神经网络不同层特征的多个版本,本文中用于比较的是使用conv3特征的版本,记为CFNet-conv3.
4.2.1 算法评价指标
OTB-100数据集建议采用精度图和成功率图的方式对算法性能进行衡量和比较.精度图和成功率图分别基于中心位置误差指标和重叠率指标进行统计获得,这两个指标也是目前比较主流的衡量跟踪器性能的标准.
中心位置误差(Center location error,CLE)是被广泛使用的一个评价标准,具体指跟踪所得的目标中心位置与基准中心位置之间的欧氏距离,单位为像素,即
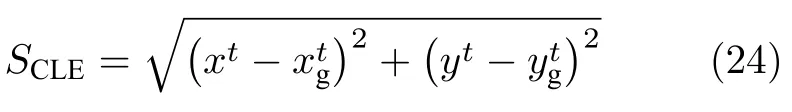
其中,(x t,y t)表示第t帧时跟踪算法计算得到的目标中心位置坐标,表示该时刻视频中目标的基准中心位置坐标.可以看出,中心位置误差仅仅衡量了像素位置的差异,无法反映目标尺度大小上的误差.通常定义SCLE≤20 为跟踪成功.精度图(Precision plots)对中心位置误差指标进行统计,横坐标为中心位置误差,纵坐标为精度(Precision),表示中心位置误差小于某个阈值的视频帧数占总视频帧数的百分比.通常使用SCLE20的精度指标衡量算法在数据集上的综合性能,并对其进行排序.
重叠率(Overlap)是另一个常见的算法评价标准,具体定义为

其中,Rt表示第t帧时算法输出的目标框,是数据集标注的标准目标框,表示两个区域重叠面积,表示两个区域并集的面积.重叠率指标在衡量了跟踪算法输出结果与标准值在像素位置上差异的同时,也反映了目标尺度大小估计上的准确程度,在目标尺度估计不准确的情况下算法很难得到高的重叠率指标.
成功率图(Success plots)对算法在数据集各个序列上的重叠率指标进行统计,横坐标为重叠率,纵坐标为成功率(Success rate),具体表示重叠率大于某个阈值的帧数占视频总帧数的百分比.通常使用成功率图的曲线下方面积(Area under curve,AUC)指标来对算法进行排序比较.
本实验采用一次通过估计(One pass evaluation,OPE)的方式给出跟踪算法的精度图与成功率图.OPE评估方法从视频开头使用标注的基线矩形框进行初始化,对算法在整个视频跟踪过程中的性能指标进行统计,通过考察算法的长期跟踪能力评估其实用价值.
4.2.2 总体性能评估分析
在OTB-100数据集上,本文提出的目标跟踪算法与主流目标跟踪算法的性能比较结果如图6所示.从图6中可以看出,本文提出的算法在融合了运动与显著性信息之后,相比于本文的基线方法,经典的相关滤波器算法DSST,中心位置误差等于20距离精度(即跟踪成功的帧数比例)从 68.0% 大幅提升到 84.4%,成功率图的AUC指标从51.3%提升到 60.4%,充分证明了本文算法融合框架、以及所建模的运动信息与显著性信息的有效性.
图6(a)的精度图曲线充分说明,本文提出的算法不仅相比于传统简单的算法模型有明显的优势,在跟踪精度性能上也优于模型复杂和运行缓慢的SRDCF,以及多类整合利用了深度学习特征,或者使用端对端深度卷积神经网络完成跟踪任务的最新主流方法.图6(b)的成功率图曲线也说明了同样的结论.
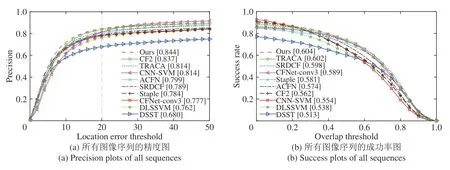
图6 在OTB-100数据集上的一次通过估计曲线Fig.6 One-pass-evaluation(OPE)curves on OTB-100 dataset
4.2.3 不同挑战性因素影响下的性能分析
OTB-100中的100个测试视频涵盖了现实生活中常见的包含各种复杂困难的跟踪场景,具体使用11个挑战性因素属性进行了标注,分别是光照发生变化(Illumination variation,IV)、尺度变化(Scale variation,SV)、目标发生遮挡(Occlusion,OCC)、目标发生形变(Deformation,DEF)、运动模糊(Motion blur,MB)、快速运动(Fast motion,FM)、平面内旋转(In-plane rotation,IPR)、平面外旋转(Out-of-plane rotation,OPR)、跳出视野(Out-of-view,OV)、背景复杂(Background clutter,BC)以及低分辨率(Low resolution,LR).
对这些视频序列按照属性进行统计得到成功率图,可以用于分析算法对于包含不同挑战性因素的跟踪场景的适用性与优缺点.图7(a)~(d)显示了本文的算法最占优势的4个属性,图7(e)~(h)则显示了最不占优势的4个属性.从图7 中可以看出,本文算法对于背景复杂、尺度变化、目标发生形变这3个场景下的目标跟踪,成功率图的AUC 分别高于次优算法 1.3%,1.1%,0.6%,平面内旋转情况下略低于TRACA算法,高于其他算法.实验结果表明,通过本文的算法模型整合的显著性信息能够有效减少复杂背景对于外观模型的干扰,增强算法的鲁棒性,所建立的运动模型也能够有效地捕捉目标与背景的运动,带来有效信息.

图7 在OTB-100数据集不同挑战性因素影响下的成功率图Fig.7 Success plots on sequences with different challenging attributes on OTB-100 dataset
另一方面,在低分辨率、目标发生遮挡、快速运动、运动模糊4个困难场景下,本文算法成功率图的AUC指标均低于SRDCF,且分别低于最优算法 9.1%,2.1%,1.4%和1.2% .由于在上述4种困难场景下,目前的光流估计算法比较难得到非常准确的光流估计,这一实验结果表明,本文算法模型可能会一定程度上受到光流估计算法结果的影响.尽管如此,本文算法在这4个场景下,相对于没有引入显著性与运动信息的基线方法DSST算法,在AUC指标上仍然分别取得了8.5%,9.6%,12.4%和 11.0% 的提升.
4.3 VOT2018 数据集实验
视觉物体跟踪挑战赛从2013年开始,每年在计算机视觉顶级会议上举行.为了将本文算法与目前最先进的方法进行客观的性能比较与分析,我们使用最近一期的VOT挑战赛数据集VOT2018[11],与所有参与测试的最新算法进行比较.该数据集包含60个测试视频,选取的序列与OTB数据集相比具有更高的跟踪难度,所有视频帧上的目标标准位置均经过人工标注.
VOT2018竞赛提交的跟踪器总共有72个,其中包括36个需要高性能GPU设备的算法,以及36个仅需要CPU就可以运行的算法.前者使用表征能力更强的深度神经网络特征,在计算过程中依赖于使用高性能GPU来实现或接近实时效果,总体跟踪精度和鲁棒性较高,而后者由于不依赖于GPU计算,可在各类不配备GPU或GPU算力不足的平台上使用,其应用范围更加广泛.本文致力于通过建模先验知识构造不依赖于GPU计算能力的实时跟踪器,与后者属于同一类方法,因此我们与后者进行了重点比较.
4.3.1 算法评价指标
VOT 数据集基于重叠率(Overlap)指标来评价算法跟踪性能,计算方法与OTB相同,详见式(25),具体测试条件和统计方式与OTB略有不同.OTB侧重于评价算法的长期跟踪能力,且在一次测试中只进行一次初始化,不对跟踪失败的情况进行判断和重新初始化,VOT则选用了一些跟踪难度较大的序列,为充分利用数据集,每次在算法跟踪失败(重叠率小于 0) 5 帧之后对其进行重新初始化,并且在重新初始化 10 帧之后继续统计重叠率.具体使用精确度(Accuracy)和鲁棒性(Robustness)两个指标,精确度计算了有效帧的平均重叠率,鲁棒性则通过统计跟踪失败的次数来计算,使用算法在这两个指标上的排序综合衡量了其跟踪性能.
为了在衡量算法的短期跟踪性能的同时,减少重新初始化带来的统计偏差,VOT挑战赛从2015年引入的另一个算法评价指标是平均重叠率期望(Expected average overlap,EAO),具体统计方法是在测试视频中截取长度较短的片段,采用不重新初始化的方式进行一次性跟踪,统计算法在片段上的平均重叠率,通过对多个不同的长度下的平均重叠率求期望得到.通过跟踪器EAO指标在目前最新算法中的排序,可以比较客观地衡量其短期跟踪性能.
4.3.2 实验结果分析
在VOT2018数据集上,本文提出的目标跟踪算法与主流目标跟踪算法的性能比较结果如图8所示.图8(a)列出了所有参与测试的跟踪器,图8(b)的精确度−鲁棒性图显示了本文算法同类方法(不依赖于GPU设备的方法)在精确度和鲁棒性两个维度上的排名,越靠近图的右上方表明算法总体跟踪性能越好.与目前最先进的方法(包括已正式发表文献的最新方法,以及部分尚未发表文献的方法)相比,本文的方法在精确度上排名第4,在鲁棒性上排名第7,取得较高的综合性能.
为了更进一步客观评估本文算法的性能,呈现与目前最先进跟踪器的比较结果,我们在图8(c)的平均重叠率期望排序图中列出了所有参与测试的跟踪算法,包括36个依赖于GPU计算能力的跟踪算法和36个不需要GPU设备的算法.不需要GPU设备的跟踪器在图的下方使用灰色圆圈进行了标记,从图示中可以看出排名前 30 的跟踪器中仅有 6个即 1/5 不需要GPU设备,说明这一方面的研究有待进一步的加强,以满足此类情况下视觉目标跟踪技术的应用需求.
图8(c)的平均重叠率期望排序图显示,我们的方法在所有参与测试的算法中排名第 31 .在所有不依赖于GPU设备的同类跟踪算法中,本文方法跟踪性能优于大部分(36个中的30个)同类方法.值得一提的是,跟踪性能优于我们的6个同类方法中包括已正式发表文献的方法,也包括尚未公开发表文献的方法,其中排名第4、第12、第20和第27的UPDT[54]、SRCT[55]、MCCT[56]、CSRDCF[57]为已公开发表的方法,在VOT2018竞赛工具包中报告的帧率分别为 0.43,1.12,1.29和 8.75 fps,排名第1和第28的LADCF和DCFCF方法未标注公开发表的文献,报告的帧率分别为 0.52和 0.18 fps,均明显低于本文方法的 21.33 fps.相比之下,本文方法在精确度、鲁棒性和速度方面具有较大的综合优势,具有较高的实用价值.

图8 在VOT2018数据集上的实验结果Fig.8 Experimental results on VOT2018 dataset
5 结论
本文在视觉目标跟踪的应用中,提出了一种像素级概率性目标表征模型,用于集成与主流的矩形框模板表征模型互补的观测信息,并且对多目标表征模型提供的信息进行融合决策.具体建立了感兴趣区域像素目标概率的贝叶斯推断模型,每一帧通过上一帧的估计结果和状态传递概率预测本帧像素点的目标概率,再融合本帧的像素级图像观测进行修正.像素级图像观测部分建模和集成了被主流目标跟踪算法所忽略、而在人类视觉系统中十分重要的显著性信息与运动信息.其中,基于显著性的观测模型具体使用背景先验和最小障碍距离算法进行建模,能够在背景干扰的情况下提供具备高辨识度的图像证据;基于运动信息的观测模型则利用了相机与目标运动的连续性,通过计算目标和背景的运动模式,建立像素级的图像证据,能够为目标复杂运动的场景提供有效决策信息.实验结果表明,提出的模型能够有效地融合像素级的显著性与运动信息,增强跟踪算法在背景干扰、目标形变严重、复杂运动等挑战性跟踪场景下的鲁棒性,与同类跟踪算法相比,在跟踪精度、鲁棒性和运行速度方面具有较大的综合优势,具有较高的实用价值.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
小哥白尼(军事科学)(2022年2期)2022-05-25
汽车工程师(2021年12期)2022-01-17
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
当代陕西(2020年14期)2021-01-08
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
贵州师范学院学报(2016年4期)2016-12-01
