
一种基于BP神经网络的电影协同过滤算法
2021-08-28 02:08宋曼
电脑与电信 2021年6期
宋曼
(广州城建职业学院,广东 广州 510925)
1 引言
电影协同过滤推荐算法采用最邻近技术计算用户和电影的相似性,根据相似电影评分预测目标电影评分,再根据电影预测评分从高到低对用户进行TOP-N电影推荐[1]。协同过滤推荐算法的推荐精度主要还是新电影的冷启动问题[2],有的算法计算电影的相似性仅仅考虑用户对电影的评分,有的算法只考虑电影的内容信息来衡量电影的相关性,这样既不能有效利用数据集信息又导致最终推荐结果不准确。BP神经网络是一种模拟人脑神经组织的计算系统,具有很好的学习能力和适应能力。BP 神经网络将输入值映射为输出值,适合复杂问题求解。本文提出,在进行电影的协同过滤推荐时,将电影相似性采用BP神经网络进行融合,将各分量相似性作为输入,输出值为两部电影的最终相似性,根据最终相似性得出预测评分,通过比较预测评分和真实评分,不断对BP 模型参数进行调整和优化,最终得到精确可靠的推荐结果。
2 BP神经网络
BP 神经网络的工作过程模拟人脑细胞的工作方式,具有输入层、隐藏层和输出层三层结构[3],如图1 所示,是具有两层隐藏层的BP 神经网络结构。输入层节点接收输入信息,经过隐藏层节点处理后,由输出层节点输出最终结果。BP 神经网络的学习过程是有监督的学习,能对比输出结果和真实值,计算出误差后将结果反向传递给每一层,从而调整所有计算层的参数。
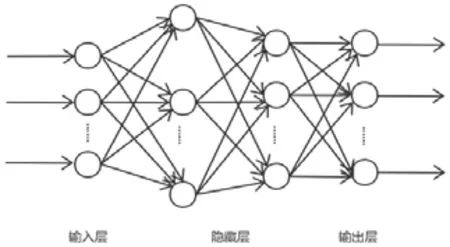
图1 BP神经网络图
现假设输入层节点数是4个,隐藏层节点数是3个,输出层节点数是2 个,学习样本数为M,每个样本的输入向量为I={in1,in2,in3,in4},输出向量为O={out1,out2},期望输出向量E={e1,e2}。输入层和隐藏层间的权重向量表示为:,隐藏层和输出层的权重向量表示为:。BP 神经网络的学习过程步骤如下:
(1)初始化两个权值α1和α2:将两个权值的初始值设定为较小随机数,设定误差精度为β,最大学习次数为N。
(2)设定当前学习样本为i={in1,in2,in3,in4},对M个样本输入学习。
(3)隐藏层节点输入值、输出值计算。
a)隐藏层节点输入值:根据输入层对隐藏层权值和输入向量计算隐藏层输入值,第j个隐藏层节点的输入值计算如公式(1)所示:

其中,yinij的下标i表示输入值,j表示第j个隐藏层节点,指输入层节点x对隐藏层节点j的权值。
b)隐藏层节点输出值:输出值由激活函数计算得来,如公式(2)所示。
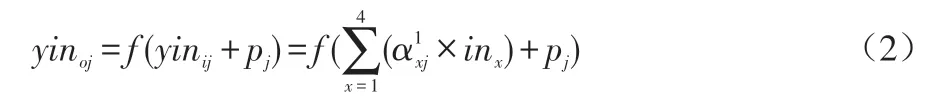
其中,yinoj的下标o表示隐藏层输出值,j表示第j个隐藏层节点。pj表示第j个隐藏节点的偏向值,函数f(x)的计算如公式(3)所示。其中,β为误差精度。

(4)输出层节点输入值、输出值计算。
a)输出层节点输入值:根据隐藏层对输出层权重和隐藏层输出值计算输出层输入值,第k个节点的输入值计算如公式(4)所示:

其中,outik的下标i表示输入值,k表示第k个输出层节点。表示第x个隐藏层节点对第k个输出层节点的权值。b)输出层节点输出值:和隐藏层相同,输出层节点的输出值同样由激活函数计算得来,计算如公式(5)所示。
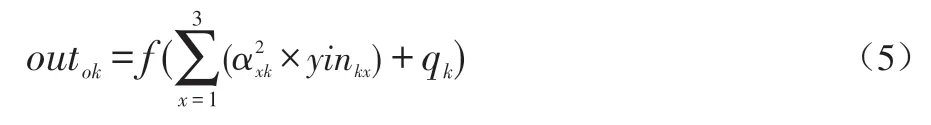
其中,f(x)的计算公式如上面公式(3)所示,outok中的下标o表示输出层的输出值,k表示第k个输出层节点。qk表示第k个节点偏向值。
(5)学习样本训练误差计算。
输出层的误差计算如公式(6)所示。
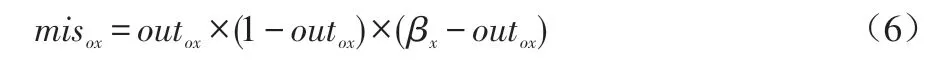
其中,outox指输出层节点x的输出值,βx指节点x的误差精度。
隐藏层的误差计算如公式(7)所示。
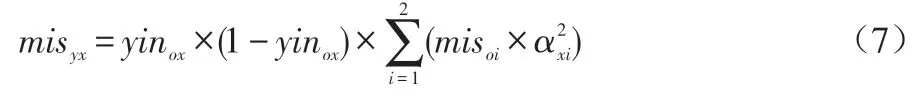
其中,yinox指隐藏层节点x的输出值,misoi指输出层节点i的输出误差,指第x个隐藏层节点对第i个输出层节点的权值。
(6)偏向及权重的调整。
a)偏向值调整
假设调整参数为η,节点偏向值为p,偏向值调整计算如公式(8)所示。

其中,mis指隐藏层节点或输出层节点的误差,每个节点都有自己不同的偏向值。
b)调整权重
参照文献[4]调整权重值,隐藏层权重调整如公式(9)所示,输出层的权重调整如公式(10)所示。
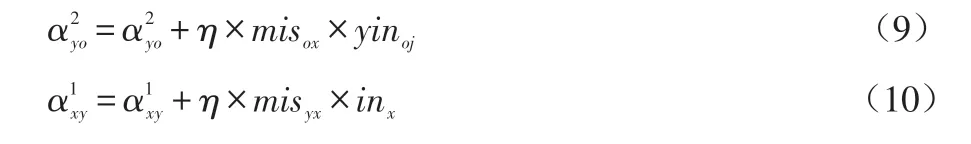
公式(9)中,表示隐藏层节点对输出层节点的权重值,η是调整参数,misox表示第x个节点的输出误差,yinoj表示第j个隐藏层节点的输出值。公式(10)中,指输入层对隐藏层的权重值,misyx指隐藏层节点x的误差值,inx表示第x个学习样本的输入值。
(7)总误差计算。总误差的计算如公式(11)所示:

其中,Mis表示总误差,βx表示第x个节点的误差精度,outox表示第x个输出层节点的输出值。当总误差值Mis小于误差精度β或没有达到最大训练次数时,继续步骤(2),否则停止退出。
3 改进BP神经网络算法
每部电影的属性信息可以直接反映电影的特征,在改进BP 神经网络算法中,主要利用电影的演员、类型、导演和编剧等电影属性,在进行电影协同过滤推荐算法是用于计算电影与电影之间的相似性。在本算法中,将电影属性信息进行直接量化,因为在计算电影之间的相似性时考虑了电影属性信息,所以该算法能有效缓解新物品的冷启动问题。
3.1 电影之间属性相似性计算
先假设任意两部电影i和电影j,从电影演员相似性、导演与编剧相似性和电影类型相似性三个方面来考量两部电影之间的相似性。
3.1.1 电影演员相似性
考虑到大部分电影演员的戏路风格变化不大,例如吴京、成龙擅长于演功夫片,周冬雨、马思纯擅长于演文艺片。或者,有些观众因为喜欢某个演员而喜欢他所有的电影。因此,考虑相同演员对计算电影相似性有一定贡献。而考虑电影演员相似性时,不用考虑所有演员,而是选取4名关键演员来代表该电影的演员信息。假设电影i和电影j的4名关键演员集合分别为Ai和Aj,得出两部电影i和电影j之间的演员相似性SimijA计算公式如(12)所示。

3.1.2 电影导演和编剧相似性
部分观众会因为青睐某位导演或编剧而喜爱这位编剧或导演的电影,而同一个导演指导的电影在很多方面有共性,因此我们认为同一个导演指导的电影有相似性。影响电影相似性的因素考虑两点:电影时间跨度和导演指导电影的数量。当同一个导演指导的电影时间跨度大时,电影相关性会减小。当同一导演指导电影数量增加时,电影之间的相似性也会减小。利用导演信息计算电影i和电影j之间的相似性如公式(13)所示。
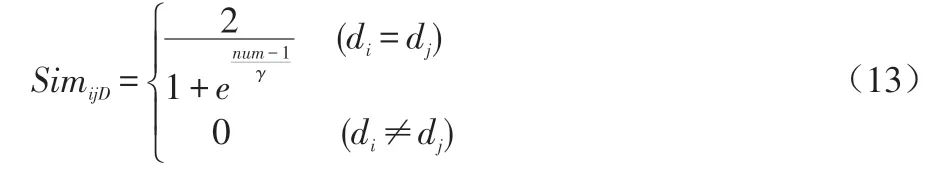
其中,di和dj指电影i和电影j的导演,number表示导演指导的电影数量,γ表示电影数量的影响因子。
同理,编剧相似性采用与导演相似性相同的方式计算,将编剧相似性记为SimijD。
3.1.3 类型相似性
在改进算法中,我们把电影类型相似性纳入电影相似性计算范围,首先对电影集中的所有电影整理得到电影-类型信息矩阵,如表1所示,表中对应值为1表示电影为该类型的电影,为0表示不是该类型的电影。考虑到电影类型是有限的,我们将矩阵的列也就是类型标签控制在二十列以内,这在大数据存储技术上完全可行。

表1 电影-类型信息矩阵
考虑到余弦相似性能更好地体现方向上的相似性和差异性,我们计算电影类型相似性时使用余弦相似性进行计算。根据电影-类型信息表,假设电影i和电影j的类型向量分别为,根据电影类型信息计算得出电影i 和电影j 的相似性如公式(14)所示。
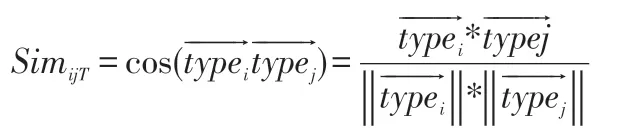

其中,SimijT表示电影i和电影j的类型相似性,typeix指电影i的第x个类型的值,n为电影类型的总数目。
3.2 电影预测模型
根据文献[5]提出的传统基于物品的协同过滤推荐算法的电影相似性衡量方法,得出电影由评价过的用户信息计算出来的相似性,记为Simij-CF,Simij-CF采用余弦相似性量度,计算过程如公式(15)所示:
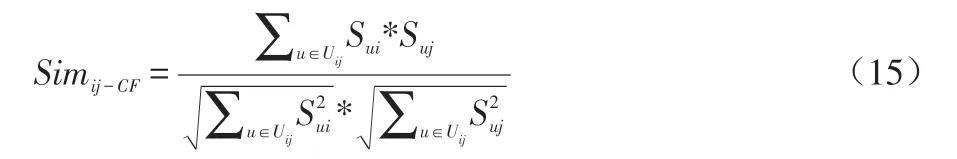
其中,Uij指用户集合,sui表示用户u对电影i的评分,suj表示用户u对电影j的评分。
电影预测模型利用BP 神经网络对任意两部电影i和电影j之间的相似度分量Simij-A,Simij-D,Simij-B,Simij-T和Simij-CF进行优化,得到最终的电影相似性Simij。相似性计算模型如图2所示。

图2 BP网络相似性计算模型
如图2 所示,模型将5 个分量相似性作为神经网络的输入,最终的Simij即为电影i和电影j根据BP 网络模型预测的相似性。其中表示第x个阶段第j个输入节点对第j个输出节点的权重,如指第1个阶段第1个输入节点对第n个输出节点的权重。将5 个分量相似性输入到BP 网络的输入节点后,可以利用公式(1)计算出隐藏层节点的输入值,然后,利用公式(2)计算出这些节点的输出值。使用同样的方法,可以计算出输出层节点的输入值和输出值。最终计算出待遇测电影i与其他电影的相似性计算。
接下来根据预测评分公式计算用户u对电影i的评分。计算预测评分之前,先根据公式(15)余弦相似性计算公式计算出电影i和电影j的相似性Simij-CF,然后,再根据余弦相似性计算用户u对电影i的预测评分scorePui,如公式(16)所示。
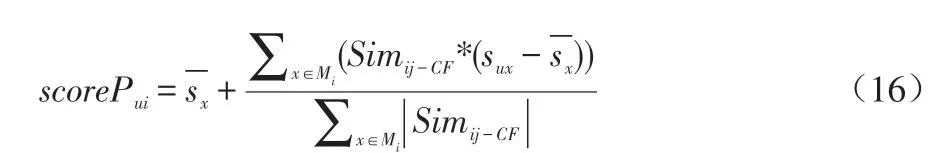
设电影真实评分为scoreRui,预测评分为scorePui。当预测评分低于真实评分时,采用梯度上升法对预测评分进行调整,当预测评分高于真实评分时,使用梯度下降法对预测评分进行调整。以梯度下降法为例,先对BP 模型最终输出的相似度Simij进行求导,如公式(17)所示:

设梯度下降步长为μ,采用梯度下降法调整后的Simij值设为SimijE,SimijE的计算如公式(18)所示:

将公式(18)计算出来的SimijE作为图2中Simij的期望值输出,然后进行后向传播,对权重和进行调整,可求得输出层误差如公式(19)所示:
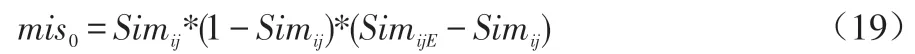
首先使用公式(7)算出隐藏层误差,使用公式(8)和(9)调整隐藏层、输出层的权重偏向,使用相同的方法调整隐藏层与输出层之间的权重和偏向。经过多次迭代后可得最终的推荐模型。本文提出的算法简称IW-CFA,即改进的加权协同过滤算法(Improved Weighted Collaborative Filtering Algorithm)。
4 仿真实验
4.1 实验数据集
本实验采用MovieLens 上1M 的最近电影数据集,共包含4000部电影信息,6000个用户信息和1000500个用户评价信息。数据集由movies.dat、users.dat 和ratings.dat 三个文件组成,分别是电影信息数据、用户信息数据和评论信息数据。其中,movies.dat 包含电影编号、名称、时间和类型等电影属性信息,users.dat包含用户编号、性别、年龄段、职业和压缩包解码等用户属性信息,rating.dat 包含电影编号、用户编号、评分和时间戳等评论信息[6]。MovieLens 数据集的电影数-评价数分布如图3所示。

图3 MovieLens数据集中电影数-评分数对照图
由于本文提出的IW-CFA算法主要解决新电影的冷启动问题,在实验过程中会验证算法在评价数少的电影推荐上的有效性。因此,将MovieLens中评论数少于80的电影单独抽取出来,记为Movie-Little 集合。Movie-Little 集合中包含3300 个用户对2800 部电影的118000 条评论信息。Movie-Little数据集中电影数-评价数分布如图4所示。
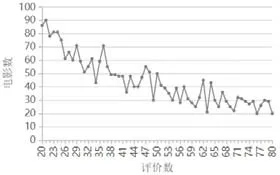
图4 Movie-Little数据集中电影数-评分数对照图
根据本文的电影之间属性相似性计算公式,从电影演员相似性、导演与编剧相似性和电影类型相似性三个方面来考量两部电影之间的相似性。这些数据信息通过Python 爬虫技术,在电影网站中根据电影编号进行爬取并记录在attribute.dat数据集中,attribute.dat数据集中包含电影编号、导演、演员和编剧等信息。
4.2 实验量度标准
本文使用平均绝对误差(Mean Absolute Error)和均方根误差(Root Mean Squared Error)评估算法准确性。测试数据集中,假设预测电影评分为集合为,用户对电影真实评分集合为,则MAE 和RMSE 的计算公式分别如式(20)和式(21)所示。其中,n为测试集的数量。
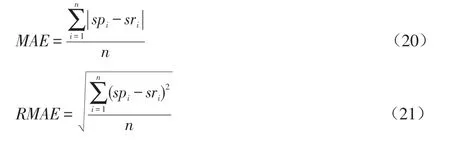
4.3 实验结果分析
为了充分利用数据,得到真实的实验结果验证文本提出的IW-CFA 算法的有效性,实验采用K 折交叉验证法对实验结果进行验证,即将全部数据集分成K份,取1份作测试集,剩余K-1份都作为训练集,经过K次实验后取平均值作为最终实验结果。具体实验时,取K=10。
通过对比本文提出的IW-CFA 算法和其他三种推荐算法,分别是聚类推荐算法(CRA)[7]:Clustering recommendation algorithm、分类推荐算法(CLRA)[8]:Classification recommendation algorithm和特征加权推荐算法(FWRA)[9]:Feature weighted recommendation algorithm,验证两点:(1)IW-CFA算法相比其他推荐算法,能产生更准确的推荐结果;(2)相比其他推荐算法,IW-CFA 算法对解决新电影的冷启动问题更有效。
如图5 和图6 所示,是四种推荐算法在MovieLens 数据集上的实验结果,图5 的纵坐标为平均绝对误差MAE,图6的纵坐标为均方根误差RMSE。图5、图6的横坐标均为相似电影个数。

图5 四种算法在MovieLens数据集上的MAE值

图6 四种算法在MovieLens数据集上的RMSE值
在实验过程中,选取最近邻居数从20到70,以步长10依次递增。从实验结果可以看出,本文提出的IW-CFA 算法优于其他三种算法,具有最小的MAE 和RMSE。当最近邻居数为30时,IW-CFA算法具有最小的MAE和RMSE。可以认为,使用本文提出的IW-CFA算法,当最近邻居数为30时,电影推荐效果最好,充分验证了本文提出的IW-CFA 算法推荐结果的准确性。
图7 和图8 是四种算法在Movie-Little 数据集上的MAE和RMSE 值仿真实验结果,实验结果充分验证了IW-CFA 算法能有效解决新电影冷启动问题。图7的纵坐标为平均绝对误差MAE,图8的纵坐标为均方根误差RMSE。图7、图8的横坐标均为相似电影个数。

图7 四种算法在Movie-Little数据集上的MAE值

图8 四种算法在Movie-Little数据集上的RMSE值
在Movie-Little 数据集上的实验中,我们同样选取最近邻居数从20 到70,以步长10 依次递增。从实验结果可以看出,本文提出的IW-CFA 算法对比其他三种算法具有更小的MAE 和RMSE,在缓解电影的冷启动问题上更优,同样最近邻居数为30时,达到最优解。
5 结论
本文针对新物品的冷启动问题,提出了一种基于BP 神经网络的电影协同过滤推荐算法。针对电影的不同属性,首先计算任意两部电影在该属性上的相似性,利用BP 神经网络计算电影间的最终相似性,预测电影评分,再利用真实评分对相似性和BP 神经网络进行不断调整,得到最终的算法模型。最后,我们通过仿真实验分别在MovieLens和Movie-Little数据集对本文提出的IW-CFA算法进行了验证,实验结果表明本文提出的IW-CFA 算法相比其他推荐算法,能产生更准确的推荐结果,能更有效地解决新电影的冷启动问题。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
现代英语(2021年18期)2021-11-22
电子制作(2019年24期)2019-02-23
中学生数理化(高中版.高一使用)(2018年6期)2018-07-09
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
