
基于改进NSGA-II算法的多目标生产智能调度
2021-08-27 06:38齐琦,毋涛
计算机技术与发展 2021年8期
齐 琦,毋 涛
(西安工程大学 计算机科学学院,陕西 西安 710048)
1 概 述
随着制造业的快速发展,生产过程中生产时间和成本的冲突变得更加明显。长期以来,生产过程中的平衡问题很大程度上依赖于生产技术人员的个人经验[1],致使生产方案很不理想。通过综合考虑时间、生产成本等多个因数的合理调度策略可以有效提高生产的执行效率。
随着智能算法的发展,许多学者将智能算法应用到机械制造、电子工业领域,以便得到更加有效的解决方案。最开始出现,有基于遗传算法、变邻域搜索[2]、混合人工蜂群[3]、多种群遗传算法[4]、改帝国竞争算法[5]求解最大完工时间的柔性车间调度问题,这种仅以最大完工时间为目标的研究存在实用性较差的问题。后来,文献[6-7]提出最大完工时间、提前/拖期惩罚函数、生产总成本的多目标优化问题。这些多目标问题研究更加符合实际生产需求,但现有的多目标优化调度研究多是为不同的优化目标函数设定不同的权重值,把多目标优化问题转化为一个单目标优化函数来求解[8-9]。这种方法存在的缺点是各权重值难以确定、优化目标之间的非线性相关性导致求解很难得到全局最优[10],且对于多目标优化问题几乎不存在单个全局最优解,而使用多目标函数直接求解得到最优解集的方案将会克服以上问题,并且文献[11-13]研究表明NSGA-II算法在求解多目标优化问题上有着良好的求解能力。
通过对NSGA-II算法的研究,在种群初始化、拥挤度计算、交叉算子选择环节进行优化改进,提高求解能力及解的质量。并将改进的算法用于西装上衣缝制的工序编排中进行测试,为实际生产提供了多种有效解决方案,验证了算法的有效性。
1.1 问题描述
在服装缝制生产环节,一件衣服可分成n个不同的部件,每个部件又包含多道工序,每道工序可以在m台机器中的一台或多台上完成,且各工序有先后顺序,前一道工序做完后一道工序才可以开始,各工序在每台机器上的加工时间已知,各衣服部件在进行组合前互相不影响。以所有部件完成的加工时间和加工成本为优化目标,在不考虑人为因素的前提下,确定所有工序的加工顺序以及使用的机器,得到有效的生产方案。
1.2 数学建模
(1)最小化最大完成时间。
最大完成时间是指所有部件同时进行加工,最后一个部件完成时所花费的时间,时间越短表明方案越好。最小化完成时间的目标函数如式(1)所示。
f(1)=minCmax=min{maxCj|j∈n}
(1)
其中,Cmax表示所有部件加工完成的最大时间;n表示所有的部件总个数;Cj表示部件j的完成时间。
(2)最小化最大生产成本。
机器在加工和待机两种状态都会产生能耗,但其单位能耗值不相同。该文将两种状态下的能耗作为生产成本进行考虑。用runtimei和waittimei分别表示机器i的加工时间和待机时间,PRi表示机器i加工状态的单位能耗;PWi表示机器i待机状态时的单位能耗;m表示机器总个数;得到机器i总的使用时间和生产成本Wi,分别如式(2)、式(3)所示,最小化生产成本的目标函数如式(4)所示:
jj=runtimei+waittimei
(2)
Wi=runtimei*PRi+waittimei*PWi
(3)
(4)
2 算法设计
2.1 编 码
针对柔性车间调度多目标优化的复杂性,该文采用MSOS染色体编码方案,个体基因的编码由两部分组成:机器选择部分(前半部分)、工序排序部分(后半部分)。工序排序部分基因位的值为工件号;工件号第几次出现即表示该工件的第几道工序,机器选择部分的基因位根据工序的排列产生,基因位的编码表示该工序选择的加工机器在可选择机器集中的序号。编码规则如图1所示。
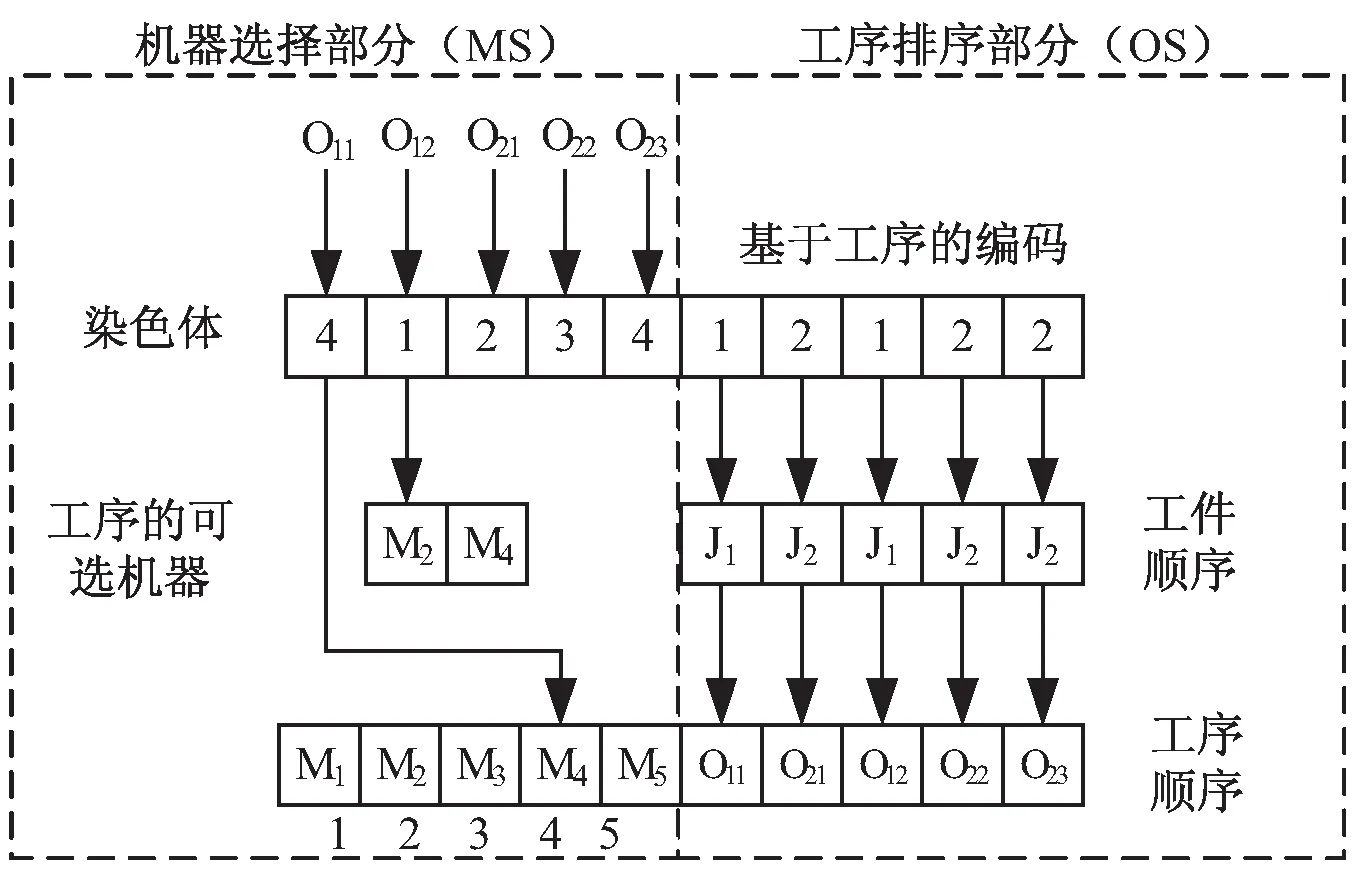
图1 染色体编码示例图
2.2 解 码
对工序排序部分和机器选择部分分别进行解码。
工序排序部分解码方式:创建一个矩阵S[1,n],存放每个工件的出现次数,其中n表示工件个数,如工件2第3次在编码中出现,就将矩阵的S[2]值变成3;创建一个矩阵H[1,m],用于存放工序解码后的信息,其中m表示工序总个数。开始解码:取编码的工序部分基因,从第一位开始遍历:得到基因位基因编码i,给S[i]的i号工件出现次数加1,用工件号乘以100再加上工件已出现的次数,得到对应的解码结果记录到H中。
机器选择部分解码方式:遍历机器编码基因,依次将H中工序解码结果除以100取余数,便得到工序编号,将编码结果减去解出的工序编号,除以100得到工件编号,用工件编号、工序编号以及机器编码位基因值,在对应的加工时间矩阵中找到该工序的加工时间。将该工序的开始时间和上一道工序的完成时间进行比较,如果前一道工序完成时间小于本工序开始时间就取本工序的开始时间,否则取前道工序的结束时间作为本工序的开始时间,将开始时间加上该工序的加工时间得到该工序的结束时间,将开始时间和结束时间存入到一个矩阵G[2,l]中,其中l表示工序总个数。
经过上述的两步解码过程,便得到对应编码所表示的工序加工顺序矩阵H以及工序加工时间矩阵G,完成解码过程。
2.3 种群初始化
NSGA-II算法中,采用随机选择的方式产生初始种群,第一次迭代时相当于一次随机搜索,由于随机搜索时种群越大找到最优解的概率就越大,但考虑到算法的复杂度,种群数量也不能无限加大[14]。文中设计在不影响算法复杂度的前提下,在种群初始化阶段将初始种群数量设置为种群数量的1.5倍,经过适应度计算和拥挤度排序处理得到种群规模的个体进行后续的迭代,来提高初始种群丰富度,减少随机性,加大NSGA_II的求得最优的概率。
2.4 选择操作
根据基因编码得到所有工序的开始时间和完成时间以及每个机器的加工时间,使用1.2节的最大完成时间和最大生产成本目标函数计算适应度函数值。由于机器待机时间等于使用时间减去加工时间,通过加工功率和待机功率乘以对应的加工时间和待机时间可以求得生产成本。在对子代、父代合并后的种群进行快速非支配排序后,改变NSGA-II算法中固定拥挤度计算方式,采用动态计算拥挤度值并按照精英保留策略选择个体组成新父种群。
由于NSGA-II算法的求解特点,在迭代后期会出现Pareto层次较少,采用分层序号以及拥挤度作为比较条件的方式,将变成以个体拥挤度作为主要的影响因素的选择方式[15]。例如,以求解标准测试函数ZDT1为例,某一次迭代后得到的Pareto面上各粒子的分布如图2所示;如果按照固定拥挤度排序,当个体聚集出现时,可能会造成该区域全部个体被淘汰的情况[16],使得Pareto解集多样性降低,解集的分布性较差,筛选后的个体分布如图3所示。实际上,当某一个体被淘汰后,相邻个体的拥挤度将会发生变化,不考虑这种拥挤度变化的排序方式不能够很好地表现解集的分布情况。采用文中的动态拥挤度排序方式选择个体的结果如图4所示。
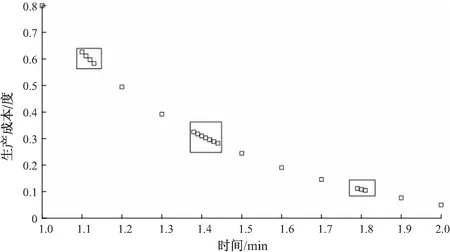
图2 Pareto最优个体集筛选前分布
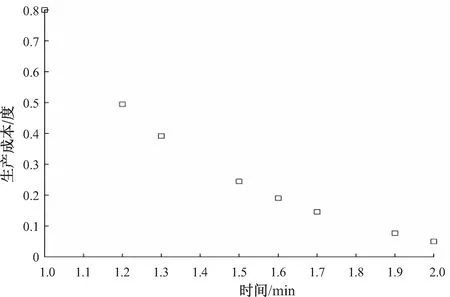
图3 采用固定拥挤度排序方式保留

图4 采用动态拥挤度排序方式保留
文中采用的动态计算个体拥挤度的方式执行流程如图5所示。首先根据个体的拥挤度,删除其中拥挤度系数最小的粒子i,如果没有达到种群数量,则根据删除个体i的位置判断需要重新计算拥挤度的个体,并重新计算该个体的最新拥挤度,更新完成后比较所有个体的拥挤度,删除整个解集中拥挤度系数最小的个体,直到得到种群数量规模。
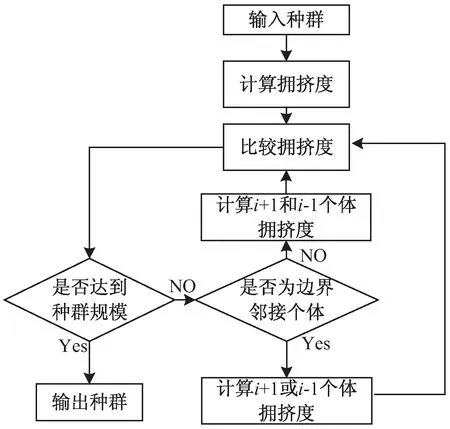
图5 动态拥挤度计算流程
2.5 交叉操作
NSGA-II算法采用的是模拟二进制交叉SBX(simulated binary crossover)对实数编码,优点是实现简单,但是搜索的范围相对较小,容易陷入局部最优解。而NDX(normal distribution crossover)算子比SBX算子的搜索空间要大[13]。NSAG-II算法在迭代初期是主要处于探索阶段,此时个体适应度偏低、种群多样性较高,应促进交叉产生新的基因;在算法后期搜索范围逐渐变小,应保护优良基因不被破坏。
文中提出一种混合交叉算子,通过迭代次数的变化来改变交叉算子使用比例,在迭代初期为了保证种群的多样性,使用较多的NDX算子进行交叉以扩大搜索范围。在迭代后期,由于种群的解集已经趋于一个稳定的区域,可以通过加大SBX算子的使用比例,提高局部搜索性能,保存优秀基因,加快收敛。通过引入基于迭代次数的混合交叉算子,可以保证种群搜索空间的多样性与解集的分布均匀性。交叉方式的选择如式(5)所示。
(5)
其中,Pn表示NDX交叉算子的使用概率;Pb表示SBX算子的使用概率;MAXGen表示最大迭代次数;N表示当前迭代次数。
SBX算子的计算公式如式(6)所示。
(6)
其中,p1、p2表示父代个体,c1、c2表示子代个体,i表示代数;βSBX是由式(7)产生的随机变量,式中令μ为在区间(0,1)上产生的均匀随机数,γ是自己定义的一个非负数;而NDX算子的βNDX生成函数公式见式(8)。
(7)
(8)
综合式(5)~式(8)得到混合算子的计算公式,如公式(9)所示:
(9)
2.6 变异操作
变异操作可以起到扩大随机性的作用,增加算法的搜索能力,在迭代后期可以通过适当增加变异概率的方式来产生多样性,所以在迭代过程中使用随迭代次数递增的线性自适应变异概率可以使变异概率随迭代次数的增加而增大,适当增加迭代后期的多样性。设置初始变异概率值为P0,最大变化概率为ρ,最大迭代次数为MAXGen;当前迭代次数为N,变异概率计算公式见式(10)
(10)
2.7 算法流程
算法实现步骤如下:
步骤1:确定种群规模、最大迭代次数;
步骤2:初始化种群,设置参数生成种群数量1.5倍的个体组成的初始种群,对个体求解适应度,进行非支配排序,如果非支配等级相同则选择拥挤度系数大的,选出种群数量的优秀个体进行后续迭代;
步骤3:将新产生的父代和子代合并成中间种群;
步骤4:选择父代。使用快速非支配排序对种群进行分层,结合动态计算拥挤距离及精英保留方式选择优秀的个体进入下一代种群;
步骤 5:生成子代。采用BSX算子和NDX算子的混合交叉算子进行交叉,采用多项式变异产生新的子代;
步骤6:判断算法是否满足终止条件。满足则结束算法,否则返回步骤3。
算法流程如图6所示。
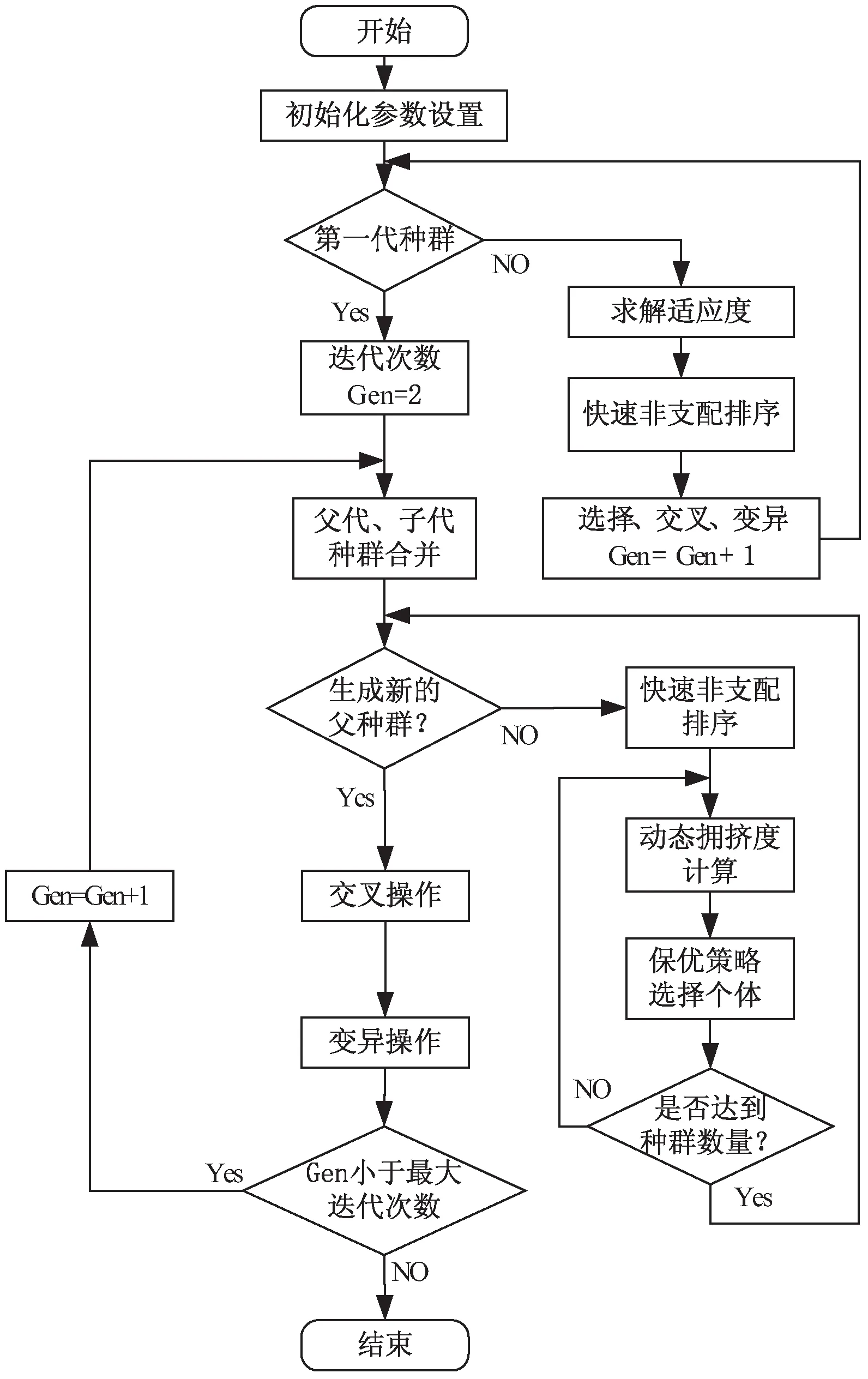
图6 改进NSGA-II算法流程
2.8 算法验证
文中将改进的NSGA-II算法与NSGA-II算法进行对比,采用文献[11]中的机器加工时间以及加工机器和加工成本信息,以最小加工时间和最小生产成本作为优化目标进行实验。实验结果如图7所示,其中星号表示NSGA-II求解的Pareto前沿,圆点表示改进NSGA-II算法的Pareto前沿。可以看出,改进的NSGA-II算法求得的解质量及分布性都优于原算法,说明改进算法在求解多样性方面性能较好,具有更好的求解能力。
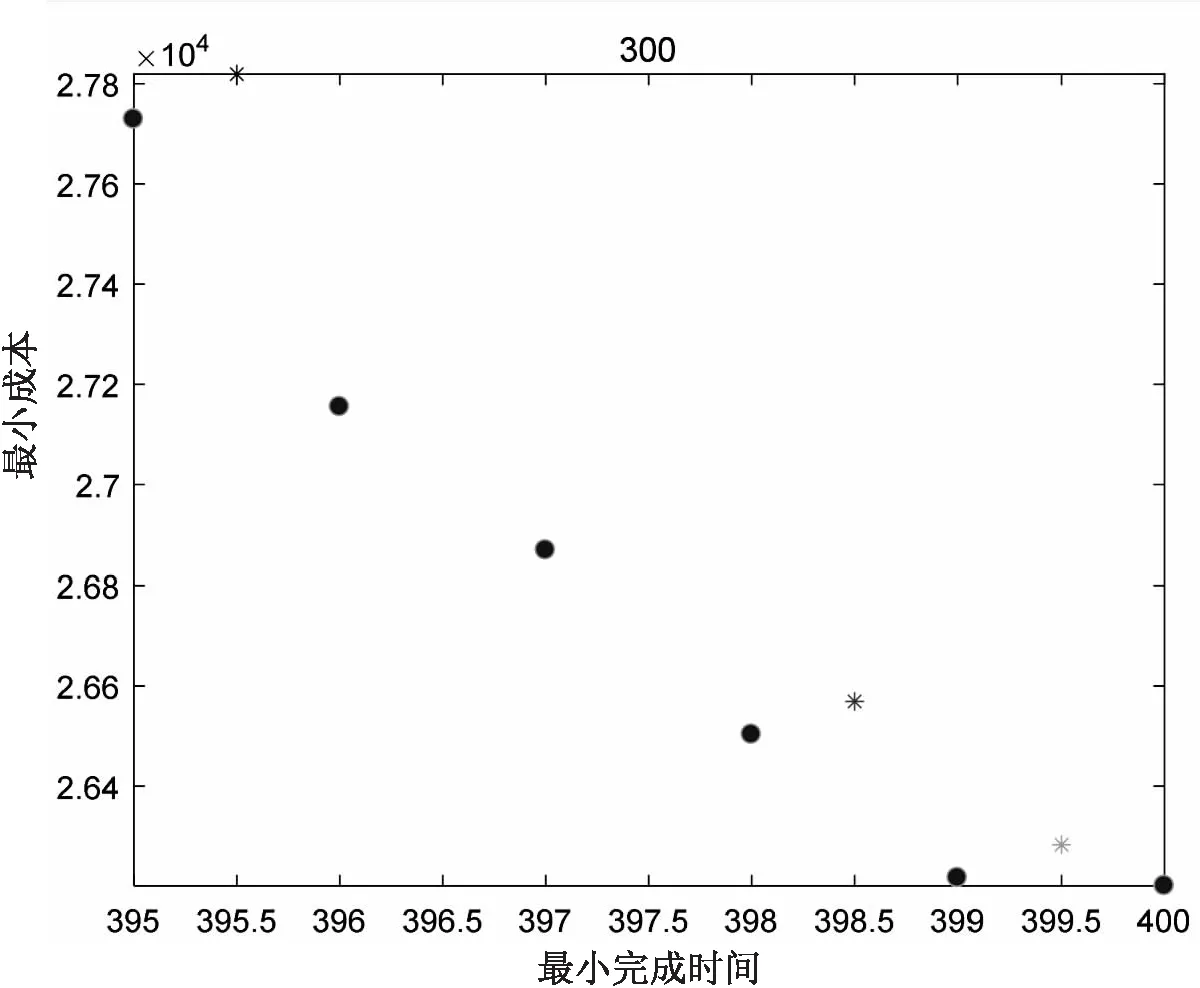
图7 改进NSGA-II算法与NSGA-II优化
3 仿真实例
文中以某西装企业上衣生产缝制环节生产环节为例,对西装各部件的加工工序排列进行研究,验证本算法在缝制环节的有效性。按照工序流程及相邻工序及使用机器的情况分析,对工序进行重新整合,得到西装上衣缝制环节大致工序,如表1所示。

表1 西装上衣生产加工工序
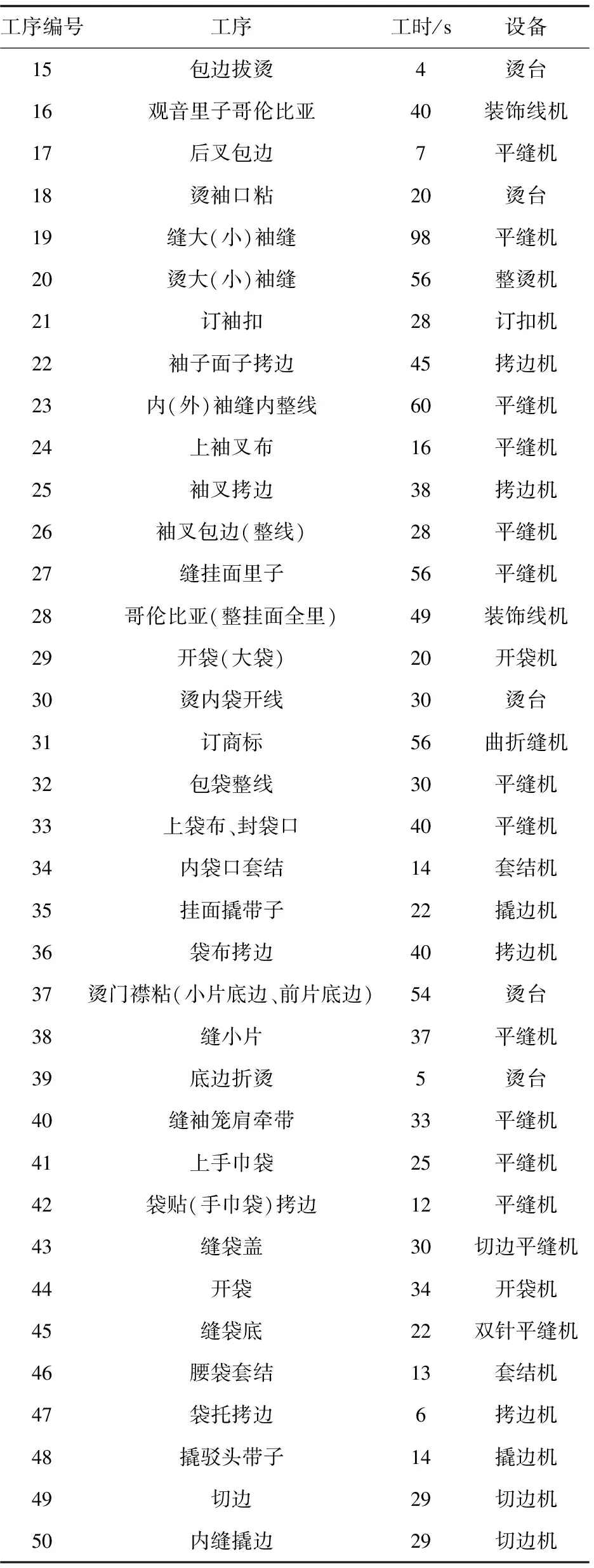
续表1
通过对表1分析整理,将该环节生产问题进行数学建模,按照生产部件划分为:衣领、后背、袖子、挂面、前片5个部件,每个部件划分10道工序,机器数量为20,并对每个机器进行编码,机器名称及编号情况如下(括号中的数表示机器编号,多台机器使用反斜杠分隔):订扣机(1)、定线机(2)、平缝机(3/4)、开袋机(5)、拷边机(6/17)、撬边机(7)、切边机(8)、切边平缝机(9)、曲边缝机(10/18)、烫台(12/13)、双针平缝机(14/20)、套结机(15)、整烫机(16/19)、装饰线机(11)。各机器在使用和待机期间的成本消耗情况如表2所示。每个工序生产可用加工机器信息如表3所示,其中第一行第二列的[3,4]表示工件1的第2道工序可使用的机器编号为3和4。各工序在对应机器上的加工时间的信息如表4所示,其中第一行第二列的[13,13]表示工件1的第2道工序使用机器3生产花费的时间为13 s,使用机器4花费的时间为13 s。

表2 各机器单位时间成本
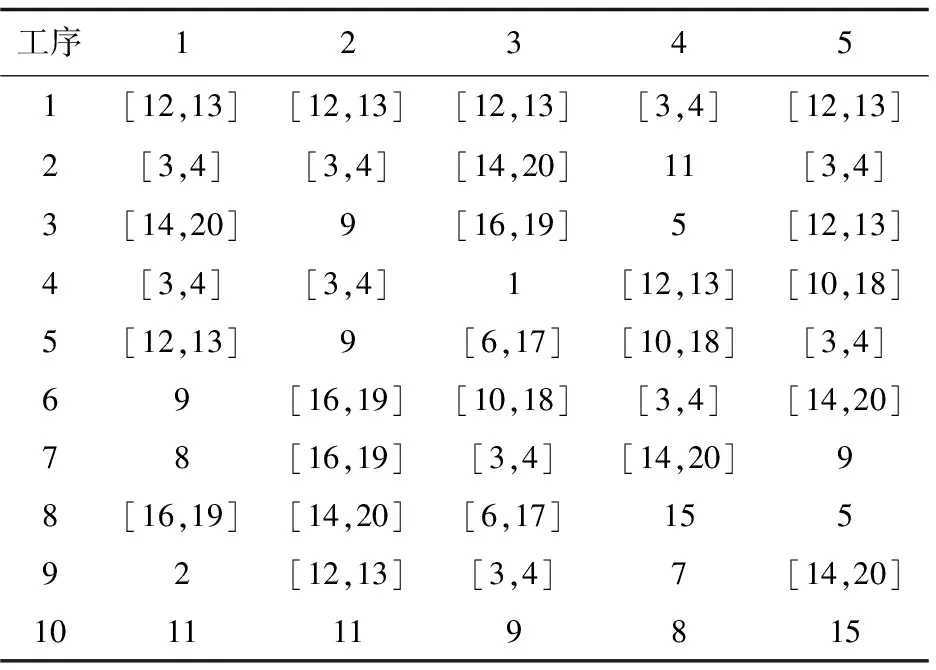
表3 各工序可用机器
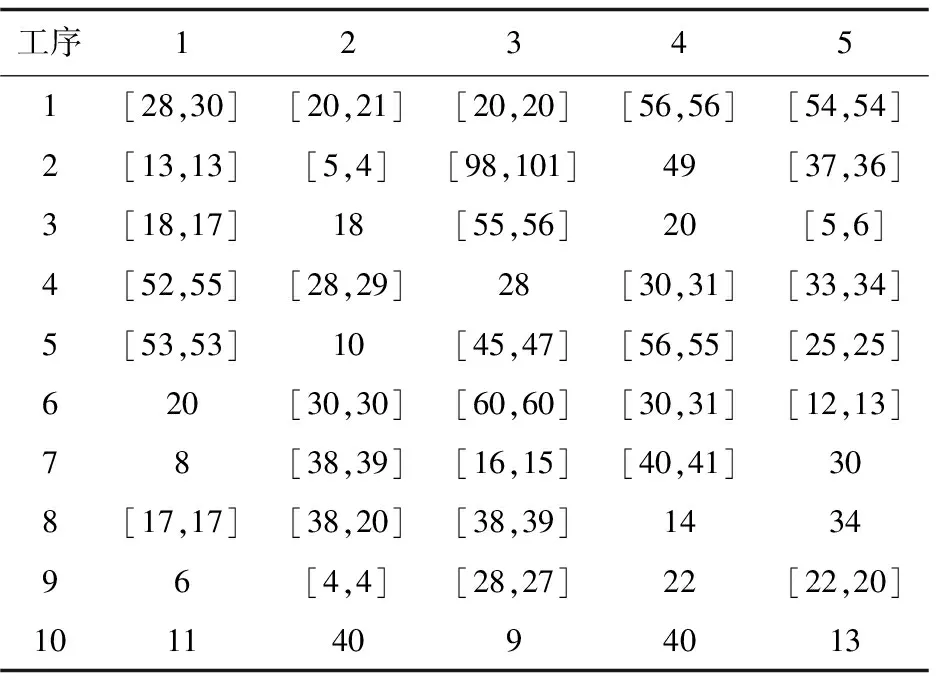
表4 各工序加工时间
在笔记本配置为Intel(R) Core(TM) i7-4510U CPU @2.00 GHz上使用MATLAB R2016b进行上述实例仿真实验。算法参数配置如下:初始种群设置为50,迭代次数为200。实验得到如图8所示的Pareto前端,以及Pareto前端第一个解的甘特图(如图9所示)和各工序加工时间表(表5所示)。从Pareto前端可以看出,综合最小完成时间和最小生产成本两个优化目标得到一个由6个非劣解组成的解集,并且各个解均匀分布,在两个目标函数相互影响下,都存在时间短或者成本低的优势,不能区分出哪个解比其他解所得到的效果好。在实际生产过程中,决策者可以根据实际需求选择合适的方案,根据方案得到的生产甘特图以及各工序的加工时间表来指导生产。
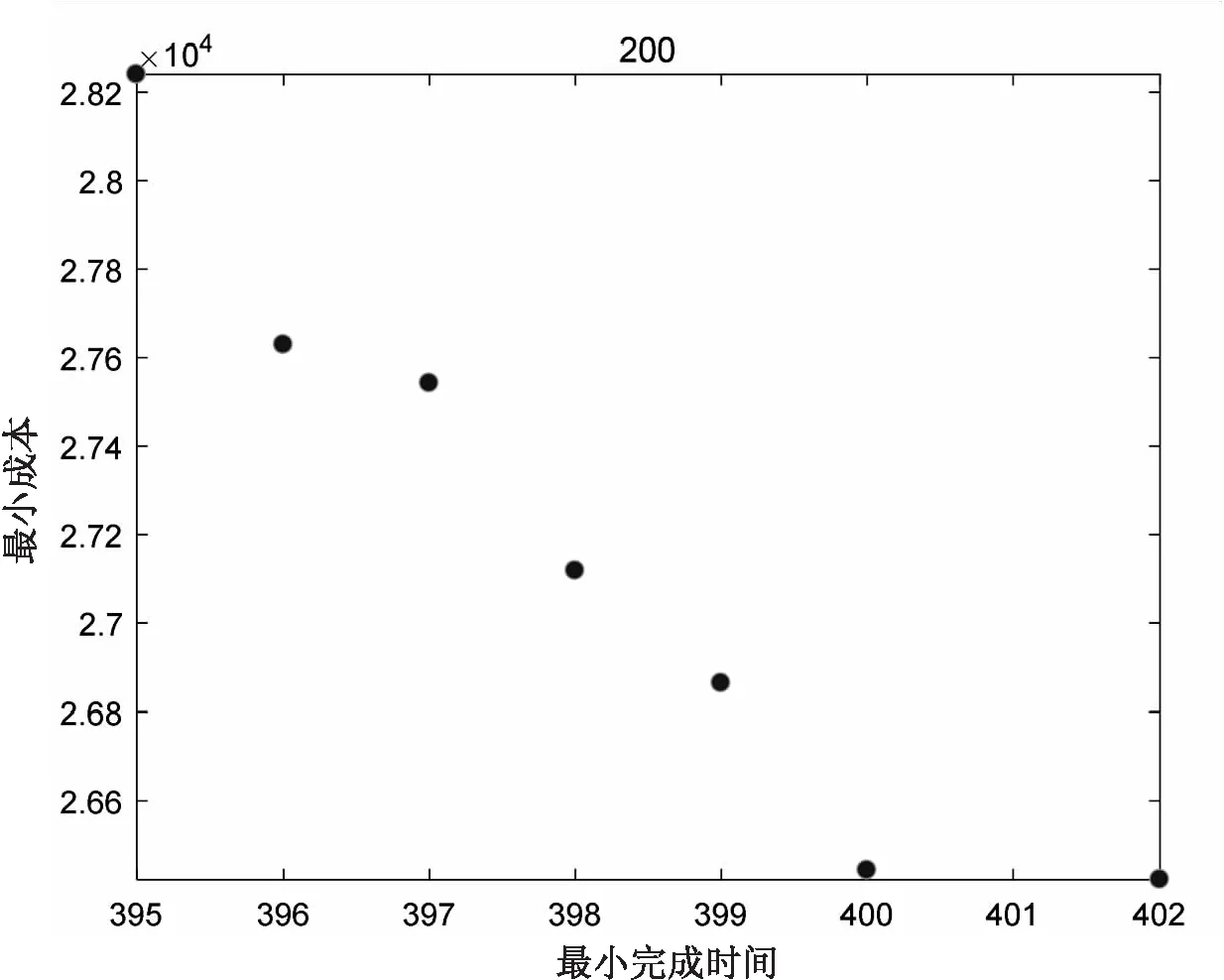
图8 Pareto前端解集
通过实验结果生产的甘特图以及加工时间表可以直观地了解各工序的实际开始加工时间和结束时间。在图9所示的甘特图中,横坐标表示时间(单位是秒),纵坐标表示加工机器,甘特图中的三位数字编码的含义是:前面(除去后面两位)是部位编号,后两位是该部位所对应的工序编号。如编码210,表示工件2的第10道工序。表5中用来记录各工序加工的开始时间和完成时间,其中第1行的第2列[82,95]表示工件1的第2道工序开始加工时间为82 s,结束时间为95 s。
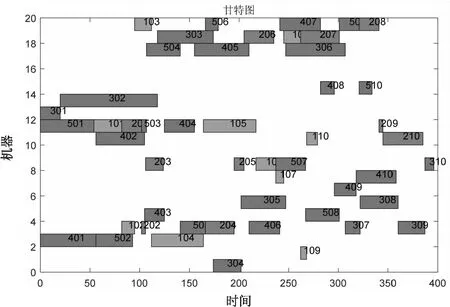
图9 工序加工甘特图
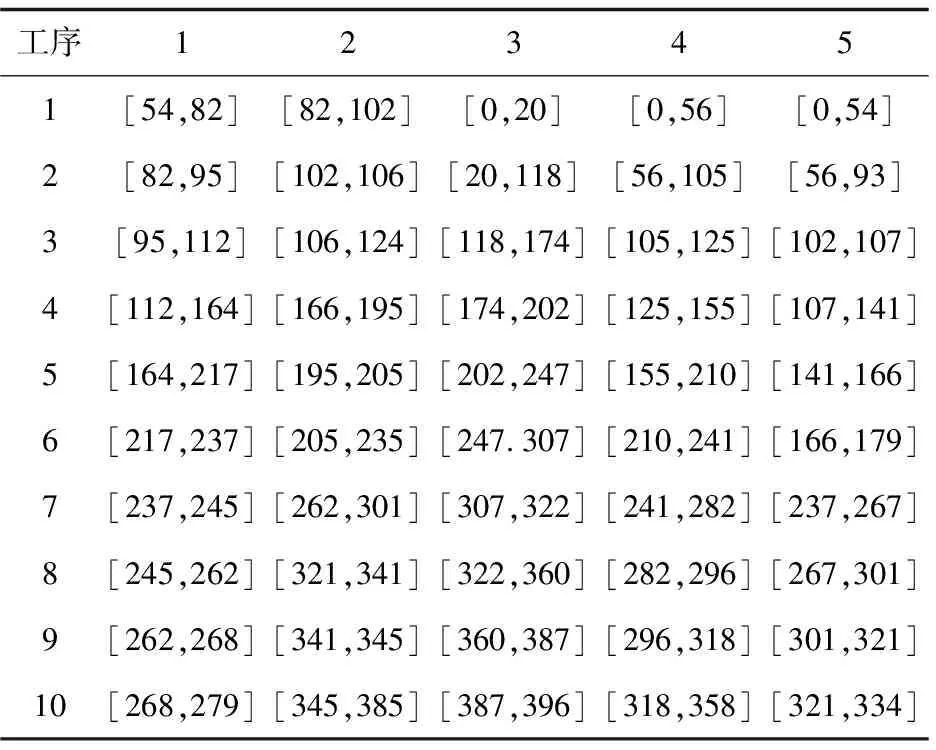
表5 各工序加工时间
4 结束语
文中针对智能生产调度的多目标优化问题,通过将多目标转换成单目标的方式,将多目标问题进行直接求解,减少了前期对各目标函数所占权重的人为制定,充分利用NSGA-II算法的全局收索能力对算法进行改进,通过动态拥挤度以及自适应混合交叉算子保证解的多样性,有效提高解的质量。以西装上衣缝制生产环节作为实例,通过改进的NSGA-II算法进行实验研究,最终得到了有效的工序编排方案。
猜你喜欢
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
机械科学与技术(2022年3期)2022-04-19
科技与创新(2022年6期)2022-03-24
智能制造(2021年4期)2021-11-04
小猕猴智力画刊(2021年2期)2021-02-22
校园英语·上旬(2020年1期)2020-05-09
商情(2020年4期)2020-03-23
大经贸(2018年12期)2018-02-20
卷宗(2017年16期)2017-08-30
科技视界(2016年24期)2016-10-11
