
基于CycleGAN的人脸素描图像生成
2021-08-27 06:38徐志鹏卢官明罗燕晴
计算机技术与发展 2021年8期
徐志鹏,卢官明,罗燕晴
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
图像风格转换是指在保留原图像内容信息的基础上生成具有新风格的图像的一种技术,在艺术创作和社交娱乐等方面有着潜在的应用前景,受到学术界和工业界的高度关注。Gatys L A等人在2016年提出了一种基于卷积神经网络的风格转换方法[1],通过预训练模型VGG-19[2]对图像的内容特征和风格特征进行剥离,实现图像风格转换。通过实验,Gatys等人发现卷积神经网络可以实现图像内容和风格的分离,图像风格转换可以取得较好的效果,但是生成图像的过程非常耗时,并且训练好的生成模型无法应用在其他风格转换的任务上,推广应用受限制。Goodfellow I等人开创性地提出生成对抗网络[3](generative adversarial networks,GAN),对图像风格转换领域有着重大的意义,相继出现了基于GAN的风格转换模型,主要包括Pix2Pix[4]、CycleGAN[5]和StarGAN[6]等模型。其中,Pix2Pix和CycleGAN模型适用于两个不同风格图像域之间的转换,而StarGAN模型则可以实现多个图像域之间的风格转换。Pix2Pix使用U-Net[7]模型,有效地保留不同尺度的特征信息,提升生成图像的细节效果,适合应用于特定的图像风格转换任务。CycleGAN模型通过添加循环一致性损失函数,成功地解决了缺少成对的训练图像的问题。StarGAN模型解决了多个图像域间的风格转换的难题,只需要训练一个生成器模型就可以实现多个图像域间的风格转换。
由于人脸图像具有较多的细节信息,采用原CycleGAN模型很难很好地处理人脸图像的细节信息,导致生成图像的视觉效果较差。文中针对人脸素描图像风格转换任务,在CycleGAN的基础上,通过改进生成器的网络结构,更好地保留人脸图像的细节信息,生成高质量的图像。实验结果表明,使用改进CycleGAN模型可以得到更高质量的图像,验证了该方法的有效性。
1 相关理论
1.1 GAN
GAN是由生成器G(generator)和鉴别器D(discriminator)共同构成的深度学习模型,生成器G负责学习训练图像集的概率分布规律并生成具有相似概率分布规律的图像;鉴别器D负责判别输入图像是生成的图像还是训练图像。通过让生成器G和鉴别器D进行对抗训练,使生成器G生成的图像具有与训练图像相似的风格,鉴别器D判别生成的图像和训练图像的能力也得到不断提高,最终使得生成器G和鉴别器D达到一种稳定平衡状态,又称纳什均衡。GAN的网络结构如图1所示。
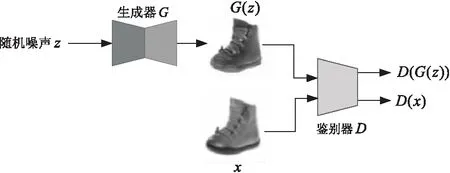
图1 GAN网络结构
随机噪声z是生成器G的输入,x是训练图像,G(z)表示生成图像,D(G(z))表示鉴别器D判定生成的图像G(z)是训练图像的概率,D(x)表示鉴别器D判定图像x是训练图像的概率。
目前,GAN越来越受到学术界和工业界的重视,许多基于GAN的衍生模型已经被广泛应用于图像风格转换[8]、超分辨率[9]、图像修复[10,11]等领域,并不断向着其他领域继续延伸,具有广阔的发展前景[12]。
1.2 CycleGAN
CycleGAN是由Zhu J Y等人提出的风格转换模型,该模型包含两个生成器和两个鉴别器,通过引入循环一致性损失函数,可以在缺少成对训练图像的条件下实现两个不同风格的图像域之间的转换。CycleGAN模型结构如图2所示。
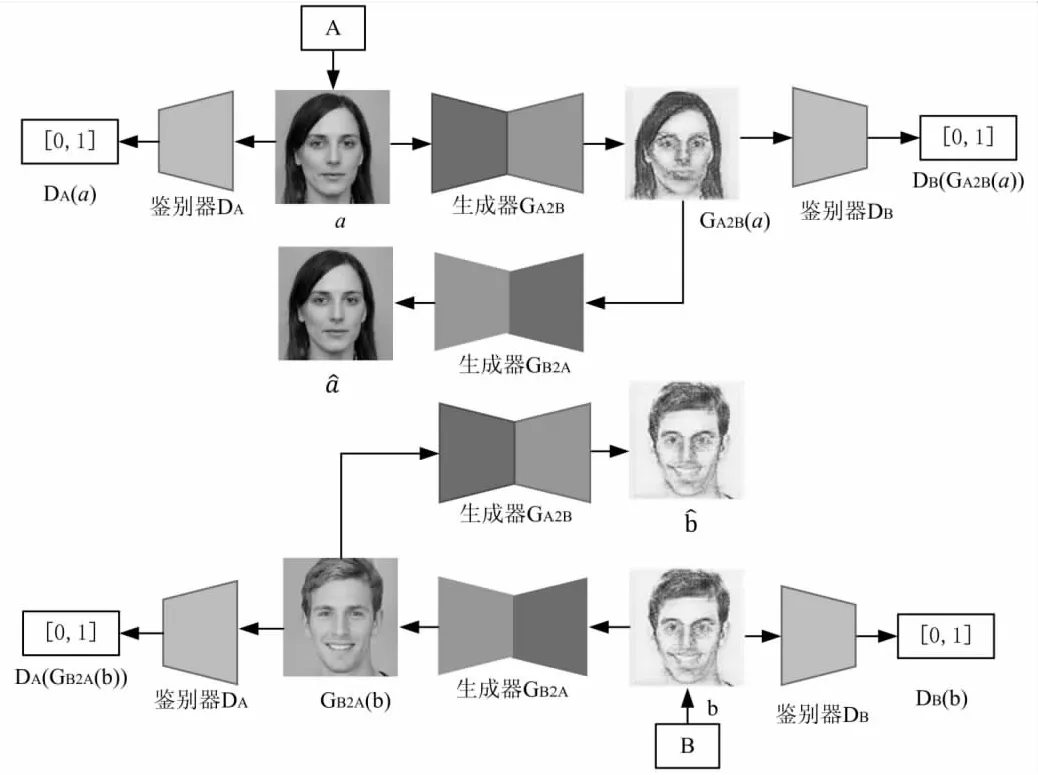
图2 CycleGAN模型结构

1.2.1 损失函数
CycleGAN的损失函数是由对抗性损失和循环一致性损失两部分共同组成。
CycleGAN模型拥有两个生成器和两个鉴别器,分别实现A图像域→B图像域的风格转换和B图像域→A图像域的风格转换,所以CycleGAN的对抗性损失将由两部分构成,将A图像域→B图像域的风格转换的对抗性损失记作LA2B,B图像域→A图像域的风格转换的对抗性损失记作LB2A。
LA2B=Eb~pdata(b)[logDB(b)]+Ea~pdata(a)[log(1-
DB(GA2B(a)))]
(1)
LB2A=Ea~pdata(a)[logDA(a)]+Eb~pdata(b)[log(1-
DA(GB2A(b)))]
(2)
式中,pdata(a)和pdata(b)分别表示A图像域的概率分布和B图像域的概率分布。
CycleGAN的对抗性损失LGAN如下:
LGAN=LA2B+LB2A
(3)
LSGAN[13]证明采用最小二乘损失函数可以加速模型收敛速度,提高生成图像的质量,因此在CycleGAN的实际训练中,将其对抗性损失LGAN中的对数运算优化成平方运算:
LA2B=Eb~pdata(b)[DB(b)]2+Ea~pdata(a)[1-
DB(GA2B(a))]2
(4)
LB2A=Ea~pdata(a)[DA(a)]2+Eb~pdata(b)[1-
DA(GB2A(b))]2
(5)
通过引入对抗性损失函数,使得鉴别器DA无法区分生成图像GA2B(a)和B图像域的概率分布,鉴别器DB无法区分生成图像GB2A(b)和A图像域的概率分布。
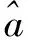
CycleGAN总的损失函数LCycleGAN如下:
LCycleGAN=LGAN+λ×LCycle
(7)
式(7)中,参数λ为循环一致性损失的权重,控制着抗性损失和循环一致性损失的相对重要性。
1.2.2 生成器和鉴别器的网络结构
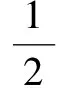
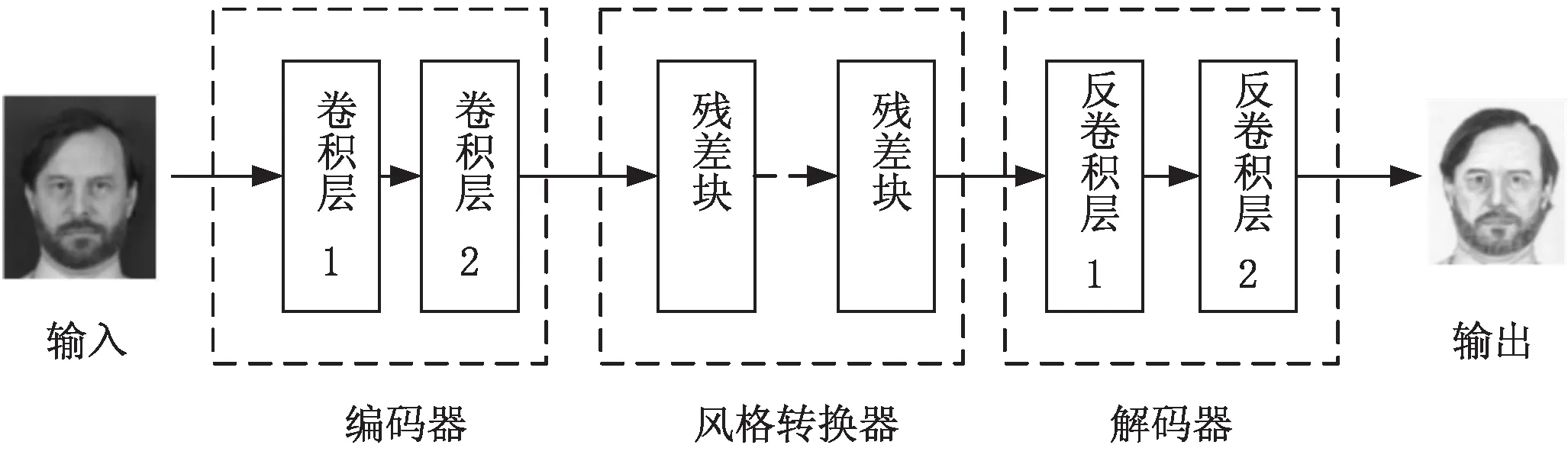
图3 生成器网络结构
CycleGAN的生成器网络采用残差块结构,通过在深层网络上添加一条直连路径,确保了梯度信息能够有效地在深层网络中进行传递,成功地解决深层网络中存在的梯度消失问题,改善深层网络的性能。反卷积(deconvolution)[16]又被称为转置卷积,是卷积的逆运算,用于图像生成。
CycleGAN的鉴别器使用PatchGAN[4]结构,其网络结构如图4所示。

图4 鉴别器网络结构
不同于普通鉴别器,PatchGAN的输出是一个N*N的矩阵,矩阵中的每一个元素值代表着鉴别器对输入图像中的每一个patch的判别结果,再将矩阵的均值作为整幅图像的最终判别结果。这种结构的鉴别器具有更少的参数,可以缩短训练时长,并且适用于任意尺寸的图像,有效地捕捉图像局部的高频特征,使生成的图像保持高分辨率和高细节。
2 基于注意力机制的CycleGAN
注意力机制(attention mechanism,AM)是一种改进神经网络的方法,在近些年得到迅速发展,出现了许多基于注意力机制的深度学习网络,极大地丰富了神经网络的表示能力。注意力机制主要是通过添加权重的方式,强化重要程度高的特征并弱化重要程度较低的特征,从而改善神经网络模型的性能。注意力机制得到的权重可以作用在原始图上[17-18],也可以作用在特征图上[19]。目前,注意力机制已经在图像分类[20-21]和图像分割[22]等计算机视觉任务中取得较好的效果。
从注意力域的角度来分析,可以将注意力机制分为三类:空间域(spatial domain)、通道域(channel domain)和混合域(mixed domain)。空间域注意力机制的代表是spatial transformer networks(STN)[23]。STN通过图像进行空间变换,提取出关键信息,降低图像中无用信息对模型训练的干扰,从而提升网络的性能。空间域注意力机制主要适用于对输入图像的处理。通道域注意力机制的代表是squeeze-and-excitation networks(SENet)[24]。SENet能够计算出特征图的每一个特征通道的权重值,并实现特征通道的权重分配,从而增强重要特征对当前任务所起的作用。将空间域注意力机制和通道域注意力机制进行组合,即混合域注意力机制,可以对特征图中每个元素同时实现空间域和通道域的注意力机制。
文中提出的改进CycleGAN模型主要是将空间域和通道域注意力机制用于生成器网络中,所采用的空间域和通道域注意力机制的结构如图5所示。
假设空间域和通道域注意力机制输入的特征图的尺寸均为c*w*h,中间各层的运算结果如表1和表2所示。

(a)空间域 (b)通道域

表1 空间域注意力机制的各层输出结果

表2 通道域注意力机制的各层输出结果

基于注意力机制的残差块(AM残差块)模型结构如图6所示。AM残差块模型结合残差模块和注意力机制的优点,既可以缓解在深度神经网络中增加网络深度带来的梯度消失问题,又可以在只需要增加较少的计算量的情况下减少无用信息对模型的干扰,提升网络的表现力,改善生成图像的质量。
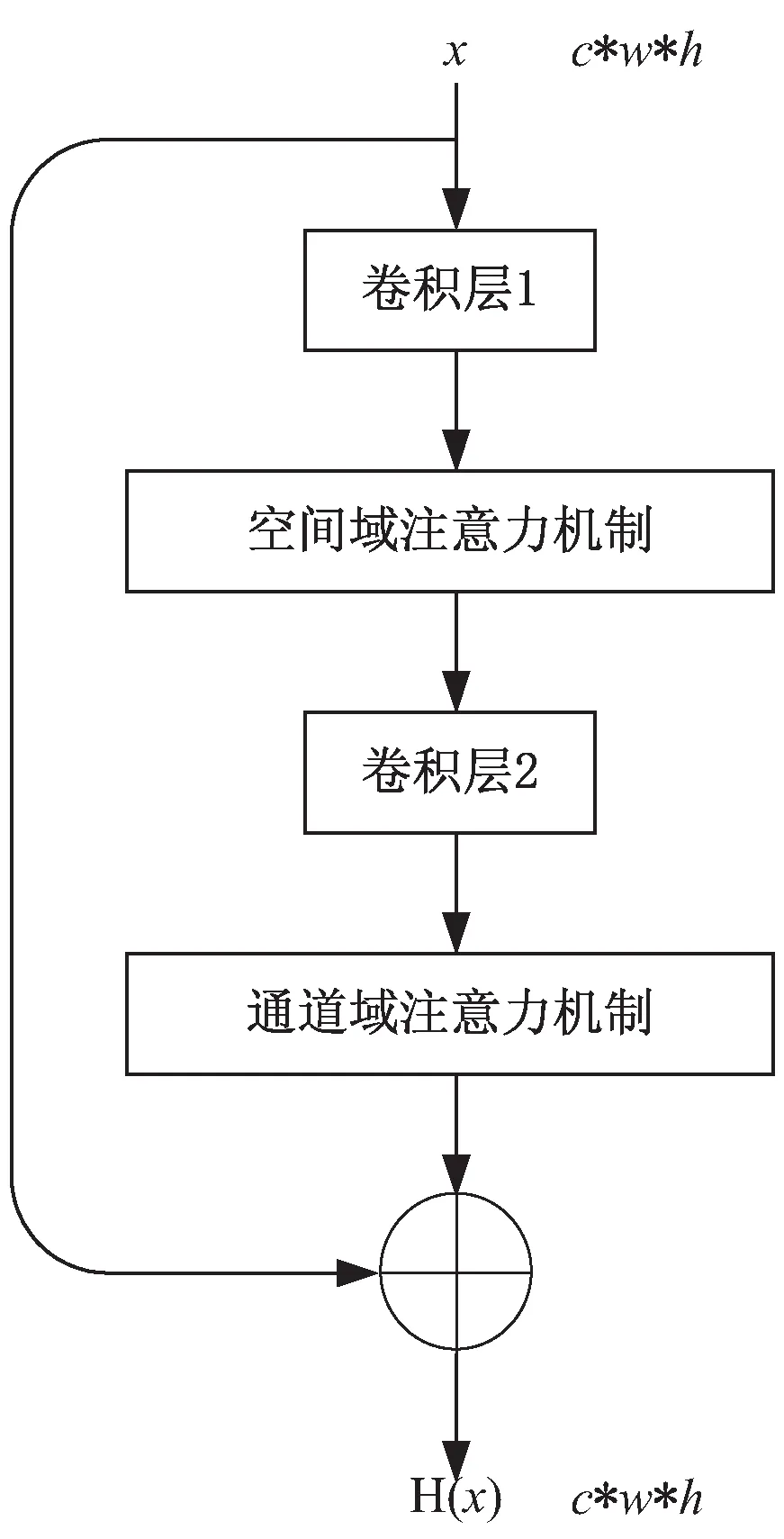
图6 AM残差块
基于注意力机制的CycleGAN生成器网络结构如图7所示。

图7 基于注意力机制的CycleGAN生成器网络结构
文中在CycleGAN的生成器网络中添加跳跃连接机制,实现将编码器中卷积运算得到的特征图传递到解码器中,使得解码器可以学习更多不同尺度的特征信息,改善生成的人脸素描图像质量。文中提出的基于注意力机制的CycleGAN的鉴别器采用图4所示的PatchGAN网络结构。
3 实验与结果分析
实验的硬件平台为Intel Xeon CPU E5-2650 v4,使用NVIDIA GTX 1080 GPU进行加速处理。实验选取从网络上收集到的300张人脸图像和CUFSF数据集[25-26]中1 194张素描人脸图像作为训练数据集;选取CUFS数据集[26]中88张学生人脸图像作为测试图像;将所有训练图像和测试图像的大小缩放为256*256像素。优化器采用性能较好的Adam算法,参数beta1和beta2分别设置为0.5和0.999,学习率lr设置为0.002。
如图8所示,当网络模型进行40个epoch迭代训练之后,已经能够实现通过人脸彩色照片生成黑白人脸图像,初具素描风格,但是生成图像的边缘比较模糊;当进行60个epoch迭代训练之后,生成图像边缘逐渐清晰,具有较明显的素描风格;当进行80个epoch迭代训练之后,可以生成较为逼真的人脸素描图像。通过对比发现,文中提出的改进CycleGAN模型生成的图像比CycleGAN和DualGAN生成的图像更加清晰,在图像边缘处处理地更好,更好地保留了人脸五官特征和表情等有效信息。
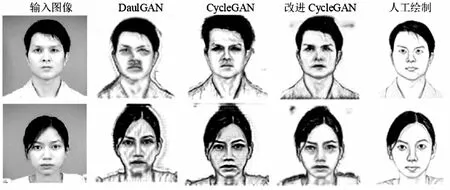
(a)epoch=40

(b)epoch=60
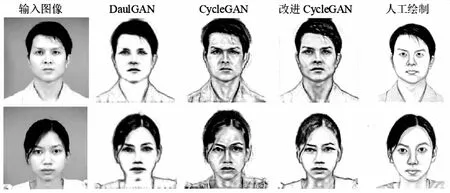
(c)epoch=80
4 结束语
当今网络社交媒体拥有着巨大的用户量,如果可以发布一些关于图像风格转换的手机端应用程序,让用户充分发挥艺术创造力,设计属于自己的特有风格的作品,这会让图像风格转换技术走进人们日常生活。但是,现阶段的图像风格转换领域仍然存在一些问题。首先,目前主流的基于深度学习的图像风格转换算法,存在模型的参数数量过多,训练耗时较长。其次,很难将需要进行风格转换的部分从原图中分割出来,无法实现局部图像风格化,导致一些生成图像质量较低。
文中主要对CycleGAN的生成器模型进行改进,将空间域和通道域注意力机制用于生成器网络中,减小无用信息对生成器的影响,加强生成器对输入图像中的人脸重要部分的学习,提升生成的人脸素描图像的质量。
猜你喜欢
今日农业(2022年15期)2022-09-20
奥秘(2021年5期)2021-06-15
小天使·二年级语数英综合(2019年10期)2019-11-08
小雪花·初中高分作文(2017年9期)2018-05-21
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
米娜·女性大世界(2016年8期)2016-08-17
读者·校园版(2015年19期)2015-05-14
软科学(2014年8期)2015-01-20
奇闻怪事(2014年5期)2014-05-13
