
基于循环卷积多任务学习的多领域文本分类方法
2021-08-26 08:10谢金宝李嘉辉康守强王庆岩王玉静
电子与信息学报 2021年8期
谢金宝 李嘉辉 康守强 王庆岩 王玉静
①(广东科学技术职业学院机器人学院 珠海 519090)
②(哈尔滨理工大学电气与电子工程学院 哈尔滨 150000)
1 引言
文本分类是自然语言处理中一项重要的基础工作[1],具有广泛的应用场景,例如垃圾邮件过滤、商品情感分类等。过去使用传统的机器学习方法进行文本分类。近年来,循环神经网络(Recurrent Neural Netword,RNN)和卷积神经网络(Convolutional Neural Network,CNN)等深度学习网络在文本分类任务中取得了很好的进展[2]。与传统方法不同的是,深度学习方法能自主学习文本的深层语义特征。长短时记忆网络(Long Short-Term Memory,LSTM)是一种改进的RNN,可以有效地捕获文本的上下文信息,CNN能够捕获文本的局部特征。为每个领域的文本训练效果好的分类模型需要大量标记样本,由于手工注释是很耗时的,因此很难获得。为解决此问题,很多研究者采用域适应方法[3]有效利用标签数据进行文本分类。迁移学习过程中,当源域和目标域数据分布不同但任务相同时,这种特殊的迁移学习为域适应学习。在文本分类任务中,一个领域的数据不足时,利用资源丰富的源域学习到的知识去学习,减少领域之间的差异,提高领域文本分类的准确率。不同的是,假设每个领域的标记数据不足以训练出一个准确的单一领域情感分类器。我们研究多任务学习方法[4],从多个领域中提取共享的特征,把各个任务的信息利用起来,使用有限的标记样本训练一个比单一领域分类器性能更好的分类器。Liu等人[5]开发出一种结合语义分类和信息检索任务的多任务学习模型,采用词袋模型会丢失很多语义信息,共享一个深度神经网络(Deep Neural Network,DNN)隐藏层很难得到文本的高层次语义信息。主流的多任务学习模型采用LST M获取文本表示[6,7],但他们仅仅使用LSTM的最后一个隐藏层的输出作为文本的特征表示,会导致文本特征被文本末尾单词所主导,丢失很多关键的信息。常见的多任务学习模型有完全共享模型和共享私有模型。完全共享模型是多个任务共享一个模型提取共享特征;共享私有模型则是多个任务通过共享一个模型提取共享特征,同时每个任务输入到一个私有层提取特定任务的特征,再将两种特征融合起来,这样会对内存和时间造成更大的消耗。
基于以上结论,本文提出一个基于循环卷积神经网络的多任务学习模型,本文方法中不同领域的文本在一个多任务学习模型中联合训练,能够利用不同领域中的文本信息。考虑时间和内存问题,本文采用完全共享模式,利用一个共享层提取特征,把相关任务的数据信息利用起来学习,而不相关的部分可以作为噪声提升泛化效果。为了更全面地挖掘文本特征,共享模型通过LSTM层获取文本的长短期依赖,再通过CNN层利用不同窗口的卷积核提取句子不同位置的n-gram特征,还可以将LSTM的所有隐藏层输出利用起来,不至于被最后一个单词所主导。模型可以将多任务学习与LSTM,CNN两种深度学习网络的优势结合起来。为了评估本文所提模型性能,本文的实验数据集为:亚马逊的多领域情感分类数据集和电影情感分类数据集。实验结果表明,本文所提模型优于单任务深度学习模型和主流的多任务学习模型,能够有效地对多领域文本情感进行分类。
2 相关工作
2.1 深度学习方法
RNN在一个固定大小的隐藏层中逐字逐句分析文本,保留前面的文本。LSTM作为一种改进的RNN模型可以提取文本的长期依赖关系,并解决传统RNN存在的梯度消失问题[8]。LSTM在文本预测和情感分类等序列任务中取得了不错的效果。CNN最初是为计算机视觉设计的。CNN利用具有卷积滤波器的层去提取局部特征,在图像分类[9]等计算机视觉任务中已经相当成熟,在文本分类等自然语言处理任务中也取得了不错的进展。Kim[2]将卷积神经网络应用于文本分类,提出了一个具有不同窗口大小滤波器的CNN架构。Kalchbrenner等人[10]提出了动态卷积神经网络得到句子的特征表示。他们在不进行任何特征工程的情况下,实现了文本分类任务的高性能,证明了模型的有效性。
2.2 多任务学习
近年来,基于深度学习的多任务学习模型在自然语言处理领域变得非常流行[11],它们提供了一种方便的方式来组合来自多个任务的信息。Collobert等人[12]用多任务学习处理词性标注、命名体识别、语义角色标注等几个传统的自然语言处理任务,只有查找表部分是共享的。在多个领域的文本分类任务中,早期有一些基于分类器组合的研究[13]。在这些方法中,每个领域训练的分类器使用不同的组合方案进行组合。他们的方法没有学习到更高层次的语义信息。Liu等人[6]基于LSTM设计了多任务学习模型,采用了两个多任务共享方式,分别是完全共享方式和共享私有方式。有研究者也在不断地研究新的多任务共享方式,去决定多个任务是如何共享的,比如外部记忆共享模型由多个任务共享的外部内存来增强神经模型[14];图多任务学习框架可以将不同的任务有效地进行通信[15];领域注意机制模型将所有领域的文本共享一个LSTM模型,再以每个领域的表示作为注意力从共享表示中提取与某领域中最相关的特征[16]。
3 提出的模型
本文提出一种用于文本分类的循环卷积多任务学习模型(Recurrent Convolution Multi-Task Learning,MTL-RC),此模型将不同任务在一个共享深度学习模型中训练,共享模型将循环神经网络与卷积神经网络相结合可以从这两种结构中受益。本模型将不同领域的文本输入共享模型中,最后输入不同的Softmax层输出分类结果,模型包括输入层、词嵌入层、共享深度学习网络层和输出层。模型结构如图1所示。
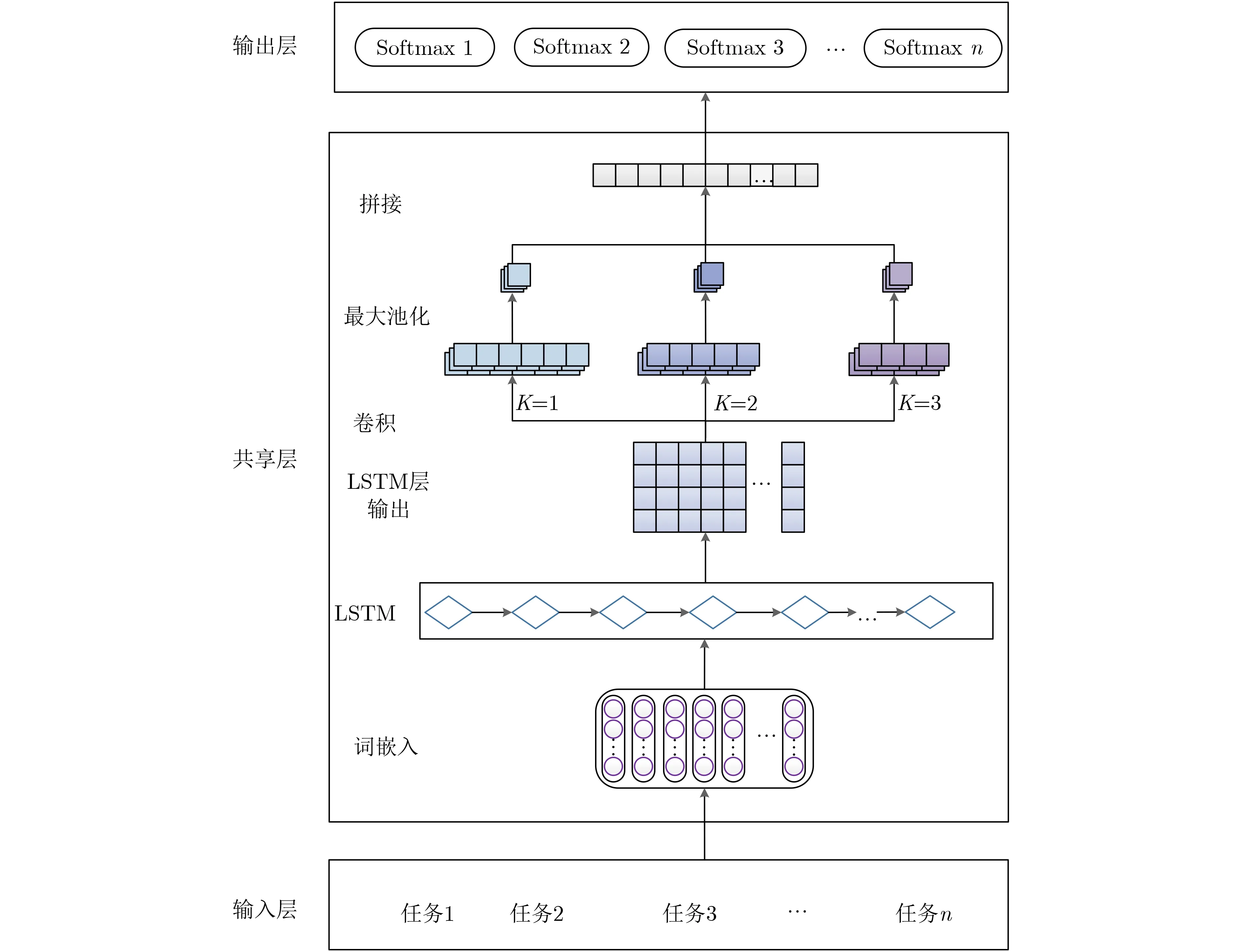
图1 MTL-RC多任务学习模型
3.1 输入层


3.2 词嵌入
考虑到每条训练样本的长度不同,为了保持维度大小一致,通常在词嵌入前通过取长补短把每条样本的长度变成相同的。把其中一个任务的一条数据的单词列表表示为xm=(x1,x2,···,xn),其中n为一个样本单词的数量,xt为这段文本中的第t个单词,所有的单词都来自词汇表V中。在输入到模型之前,通过词向量矩阵W ∈R d×|V|将单词转变为词向量,其中|V|为词汇表中单词的数量,d为词向量的维度。词嵌入后每一条数据变为2维向量X∈R d×n。
3.3 共享LSTM和CNN层
以两个任务为例,把两个任务文本词向量输入到共享LSTM层中,仅仅以LSTM的最后一个隐藏层作为文本表示,不能获取丰富的语义信息,如图2所示。

图2 共享LSTM层
本文将每一个任务的文本生成词向量后,都要经过一个由LSTM和CNN组成的共享层,LSTM是一种链式神经网络结构用来传播历史信息,CNN则是采用多个卷积核并行地提取文本的局部特征,LSTM和CNN结合起来可以更加全面地提取文本的深层语义特征。共享LSTM和CNN层如图3所示。下面主要介绍这两个深度学习网络层。
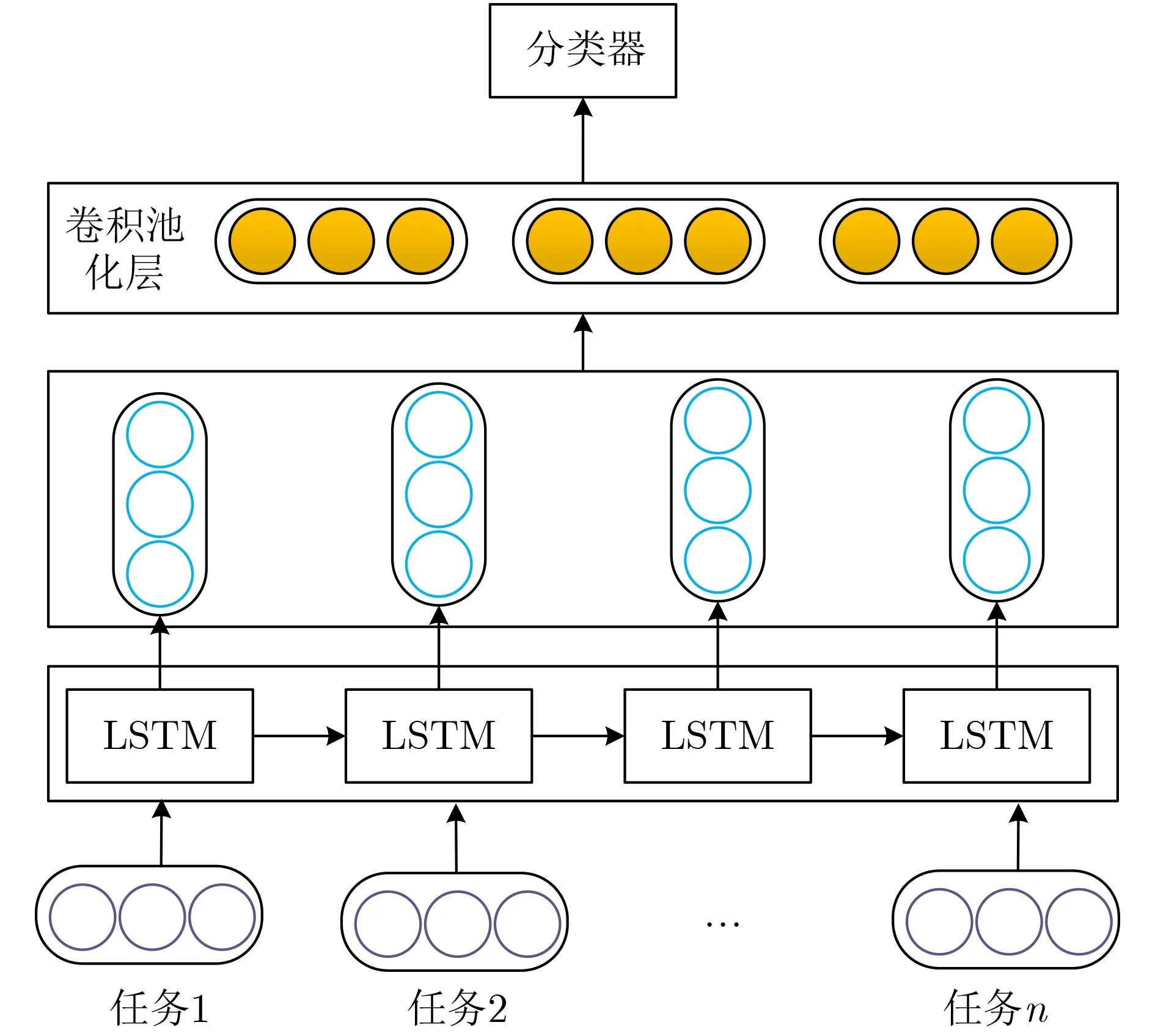
图3 共享LSTM和CNN层
3.3.1 LSTM层
LSTM对历史信息带有记忆功能,能够在长的序列中有好的表现[8]。相比RNN只有一个传递状态,LSTM有两个传输状态,分别是细胞状态ct、隐藏层状态ht。虽然提出了很多LSTM变体,考虑模型的训练时间,在这项工作中采用标准的LSTM结构。
LSTM的核心思想是利用记忆细胞和门机制管理,其中令xt为当前时间步的输入,ht–1为上一时刻隐藏层的输出,每一个LSTM单元包括3个门,分别是遗忘门ft、输入门it、输出门ot。而这3个门的作用就是决定如何更新细胞状态ct、隐藏层状态ht。LSTM每个时间步的计算公式为
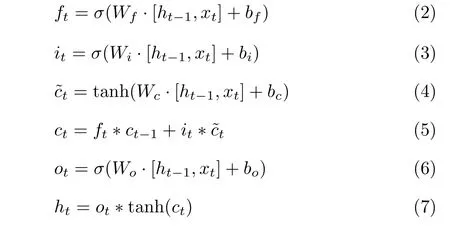
上述公式中,W表示权重矩阵,b表示偏置值。σ是sigmoid函数,输出在[0,1]之间,tanh是双曲正切函数,输出在[–1,1]之间,所有门的值和隐藏层的输出值在[0,1]之间。
3.3.2 CNN层
LSTM的输出矩阵作为卷积层的输入,使用一个包括滤波向量的1维卷积在序列上滑动并在不同的位置检测特征。卷积核的宽度与LSTM输出特征向量的维度一样,本文使用不同窗口的多个卷积核提取丰富的文本局部特征。让hi∈Rd为LSTM输出矩阵的第i个d维向量,F∈Rk×d代表一个滤波器的矩阵。这样,一个特征被表示为

其中,f为非线性激活函数,本文使用ReLU,b为偏置项。
经过卷积操作后,可以得到一个n–k+1维的向量C,形如
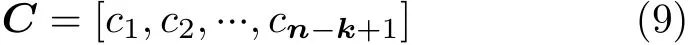
在卷积层后进行池化操作,池化的特点之一就是固定卷积后矩阵维度的大小,还能降低输出结果的维度。本文使用了最大池化得到特征向量中最大的值,以这种方式,对于每个卷积核,得到了最显著的特征

经过池化之后,还需将不同卷积核得到的特征值拼接起来,得到最终的特征向量,表示为
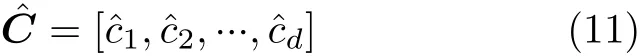
3.4 输出层
最后一层是输出层,每一个任务的文本表示分别输入到特定任务的Softmax层中,进行情感分类。一共有k个任务,因此要输入到k个Softmax层中,令m为其中的第m个任务,利用Softmax函数计算第m个任务的样本每一个情感类别的概率,表示为

其中,W为要学习的权重,b为偏置,C为样本情感分类的类别数。
更新网络参数不断地最小化交叉熵损失值,某任务中某个样本的损失值表示为
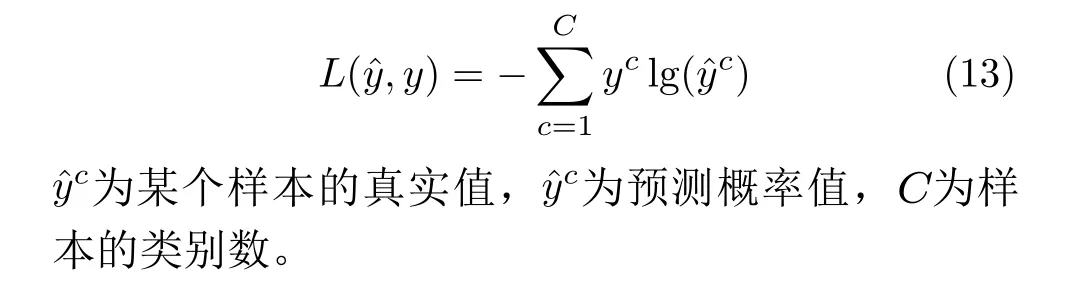
4 实验
4.1 实验设置
为了验证本文所提模型,采用由王鑫等人[9]收集的16个不同的情感分类数据集。其中14个数据集是来自不同领域的亚马逊商品评论,包括books,electronics,DVD,kitchen,appearel,camera,health,music,toys,video,baby,magazines,software,sports,目的是把商品评论情感分为积极的和消极的,这些数据集是根据Blitzer等人[3]的数据集收集的。另外2个数据集是关于电影评论的,包括互联网电影资料库(Internet Movie DataBase,IMDB)和电影评论数据集(Movie Review,MR),IMDB首先被Maas等人[17]提出,它是用于情感分类的一个基准数据集,是一个大型的电影评论数据集,包含完整的评论。MR被Pang等人[18]提出,它包含从“烂番茄网”提取的积极和消极评论。这16个不同任务的数据集,其中每个任务有2000条数据,积极的和消极的分别为1000条。标记样本被随机分为训练集、验证集和测试集,比例分别为70%, 20%和10%。
模型的参数最终根据模型的性能以及训练时间选择。本文使用Collobert等人[12]训练的SENNA词向量,维度是50维的,在实验表现出不错的效果。考虑到时间问题,仅仅使用了最原始的LSTM,隐藏层的维度设为100。本文分别实验了不同的卷积核尺寸和数量,最终卷积核尺寸设为(1,2,3),每一个卷积核的个数为100。把dropout值设为0.7能有效地减小过拟合。使用了Adam优化器和反向传播策略对模型进行训练,样本的批次设置为16,学习率为0.0005。表1展示了本文所实验过的不同参数设置范围以及模型使用的最终的设置。

表1 参数设置
4.2 对比模型
LSTM:长短时记忆网络,单任务的文本分类模型,分别用每个任务的样本进行训练和测试。
CNN:卷积神经网络,它也是单任务文本分类模型,实验设置与本文相同
MTL-DNN:共享DNN模型[5],使用词袋输入,共享一个隐藏层。
MTL-CNN:多任务卷积神经网络模型[12],其中查找表部分是共享的,其他层比如CNN是基于特定任务的。
FS-MTL:完全共享循环神经网络模型(Full Shared Multi-Task Learning,FS-MTL)[6],是将所有的任务共享一个LSTM模型,每个任务从特定的输出层输出。
ASP-MTL:对抗多任务学习模型(Adversarial Multi-Task Learninng,ASP-MTL)[7],使用对抗训练和正交约束,将共享特征和私有特征划分更细。
IC-MTL:间接交流多任务学习框架(Indirect Communciation for Mult i-Task Lear ning,IC-MTL)[15],是一种图多任务学习框架,在这个框架中,不同的任务可以相互通信,共享层可以发送信息到某一任务中。
4.3 实验结果
4.3.1模型对比
本文模型MTL-RC与当前热门的模型对比结果在表2中。为了更好地对比,本文与对比实验采用同样的数据集,分别是14个亚马逊商品评论数据集和2个电影评论数据集。其中比较流行的多任务学习模型ASP-MTL采用200维glove词向量,学习率为0.01,训练最小批次为16。
本文利用分类准确率对实验结果进行评价。其中前两种方法是单任务深度学习模型,分别对每个任务建模进行情感分类。而其他的模型是多任务学习模型,对多个任务的数据集进行共同建模,多任务学习模型的实验结果文献[7,15]。表2展示了16个任务使用不同的模型的准确率,之后的讨论都是以每个模型的平均准确率进行对比。从表2可以看出,除了MR数据集,在其他数据集中,本文所提模型MTL-RC是优于其他模型的。MR的提升之所以不明显,甚至相比有的多任务模型略有下降,是因为MR的每条样本长度仅仅只有21,相对其他数据集太小,不容易获得很好的文本表示。相比单任务模型,多任务模型准确率都有一定的提升,单任务LSTM,CNN方法准确率分别为81.2%和80.1%。多任务FS-MTL和MTL-CNN方法准确率分别为84.7%和84.5%,比单任务模型分别提升3.5%和4.4%,而MTL-RC模型比单任务模型分别提升了8.9%和10.0%,由此可见,将多个任务的文本利用起来,能显著提升模型准确率。多任务模型MTLRC比MTL-DNN,MTL-CNN和FS-MTL都有很大的提升,准确率分别提升了5.8%,5.6%和5.4%,说明采用多任务学习的方法,将LSTM和CNN网络结合起来的有效性,能获得更充分的文本表示,提升模型的性能。
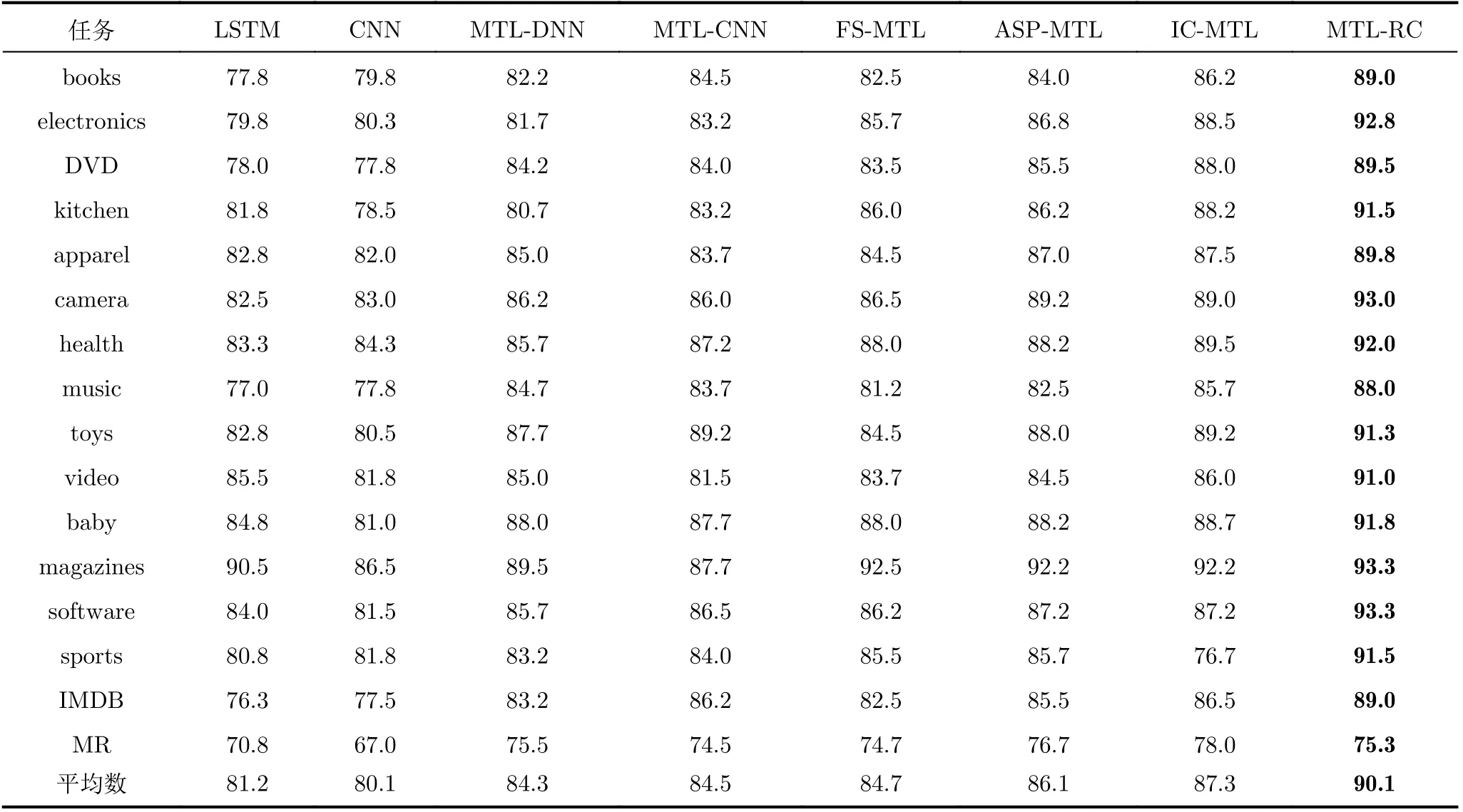
表2 与其它模型准确率对比(%)
在FS-MTL模型中,完全共享一个LSTM层,获取文本表示,每个任务的文本表示分别输入到不同的输出层进行情感分类。可以看出FS-MTL比MTL-DNN和MTL-CNN模型的准确率略有提升,一部分原因是MTL-DNN采用词袋输入丢失了语义信息,MT-CNN仅仅共享了词嵌入部分。ASP-MTL是对FS-MTL的改进,加入了一个私有层提取每个任务的私有特征,并且采用了对抗训练和正交约束将共享层和私有层精确划分,准确率达到了86.1%。与之前模型不同的是IC-MTL可以实现不同任务之间的通信。而本文的模型MTL-RC也是针对FSMTL的改进,在LSTM获取文本表示之后加入了不同窗口的多个卷积核对并行提取文本的局部特征,因为卷积层是并行提取特征,所以模型的训练速度是很快的,MTL-RC的准确率也比FS-MTL,ASPMTL,IC-MTL分别提升了5.4%,4%,2.8%。以上分析表明本文方法优于这些对比方法,证明了本文方法的有效性。
4.3.2多任务学习模型准确率和速度
本节将继续证明多任务学习模型的有效性,为每一个任务构建一个单任务深度学习模型STL-RC,同样在LSTM层之后采用卷积核提取特征,分别对每个任务进行训练,其他的设置保持不变。对STL-LC平均一次训练的所有任务的时间总和与MTL-RC的时间进行对比,同时也将两个模型平均每个任务的准确率进行对比。MTL-RC与STLLC模型时间及准确率对比如表3所示。图4展示了其中4个商品评论数据集和2个电影评论数据集在本文提出模型MTL-RC和单任务学习模型STL-LC准确率的对比。
由表3可知,MTL-RC模型平均每个任务的分类准确率比STL-LC提升6.5%,证明了多任务学习能够提高模型的准确率。本文所提模型平均每次训练的时间比每个任务训练STL-RC模型时间总和快213.1 s,可以证明多任务学习方法能能够提高模型的训练速度。由图4可以看出,相比STL-RC模型,本文所提MTL-RC模型每个任务的准确率都有显著的提升。总之,本文方法在时间和性能上都优于单任务方法。

图4 MTL-RC与STL-LC模型每个领域分类准确率的对比
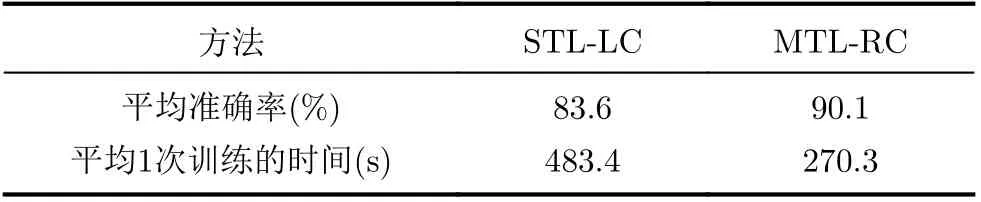
表3 MTL-LC与STL-LC模型准确率与时间比较
4.3.3卷积神经网络的影响
为了避免仅仅输出LSTM最后一个时间步的特征,被最后一个单词主导,本文提出把LSTM的全部隐藏层的输出再通过CNN提取特征的多任务学习模型MTL-RC与仅仅把LSTM最后一个隐藏层输出的模型MTL-LSTM模型进行对比分析,实验结果如图5所示。
由图5可以看出,本文所提模型MTL-RC与改进前的MTL-LSTM相比,每个领域的分类准确率都有一定幅度的提升,只有MR数据集的准确率较低,是因为其文本最短,得到的特征信息较少,改进不是很明显。由此可以说明本文所提模型MTLRC先把LSTM的全部信息输出,再采用CNN提取文本的局部特征,可以有效地防止特征被最后一个单词所主导,同时能分别利用LSTM和CNN的优势,得到深层次的文本语义特征,取得更好的分类效果。
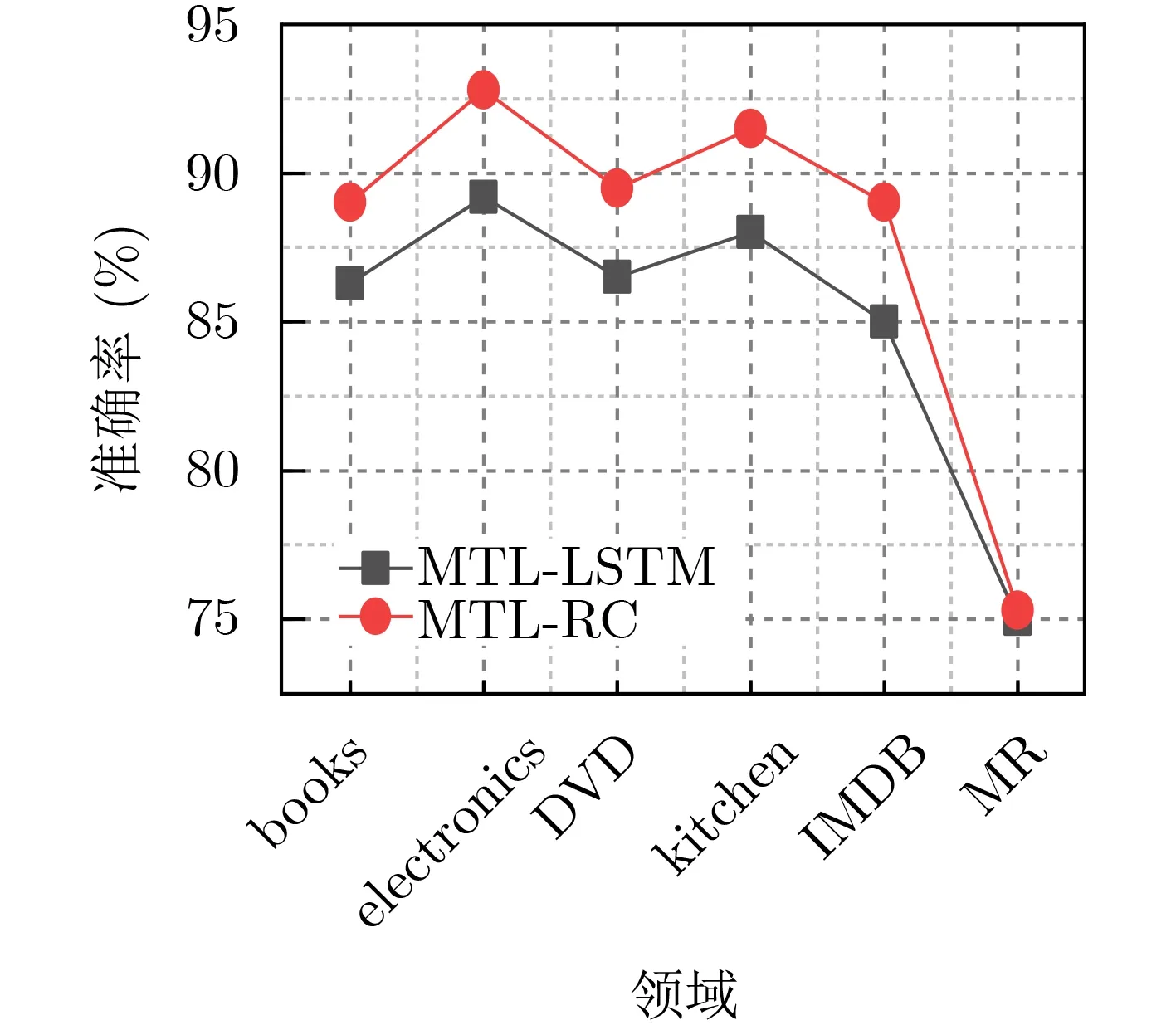
图5 MTL-RC与MTL-LSTM模型每个领域分类准确率的对比
4.3.4模型参数的影响
为了验证不同窗口卷积核对分类效果的影响,本节采用不同的卷积核窗口进行实验,实验结果如表4所示。
由表4可知,采用不同的卷积核窗口比只使用一种卷积核窗口的分类准确率有一定的提升,当窗口大小选(1,2,3)时,比只选用1,2和3准确率分别提升1.5%,0.6%和0.9%,也比其他的不同窗口组合准确率高,因此选择合适的卷积核窗口对模型的分类性能会有一定的提升。卷积核用来提取文本的局部特征,采用具有相同窗口的不同数量的卷积核可以学习互补的特性。实验结果可以说明采用不同窗口的卷积核可以获得不同高度视野下的局部特征,因此可以获取更加丰富的文本特征。

表4 MTL-RC模型使用不同卷积核的准确率对比
4.3.5领域数量对模型性能的影响
本节通过实验探索领域的数量对本文模型性能的影响。在本文实验中,将不同数量领域的文本输入到模型进行训练,以books,electronics,DVD和kitchen这4个领域为基准,领域的数量从1增加到16,步长为3。这4个领域在本文方法的准确率,如图6所示。
由图6所示,随着领域数量的增加,这4个领域的评论分类准确率也在逐渐增加,其中从1个领域到10个领域,准确率上升较为显著。可见领域的数量对本文模型准确率影响很大。因为多任务学习能够起到一个扩充数据量的作用,不同领域的样本很多表达是相似的,具有相关性。领域数量增多,样本的数量也会呈线性增加,可以有效解决有标签样本的问题。多个任务在浅层共享,可以削弱网络的能力,一定程度上防止过拟合。同时多个领域的文本也会有不相关的部分,学习一个任务时与该任务不相关的部分可以作为噪声,提高模型的泛化能力。
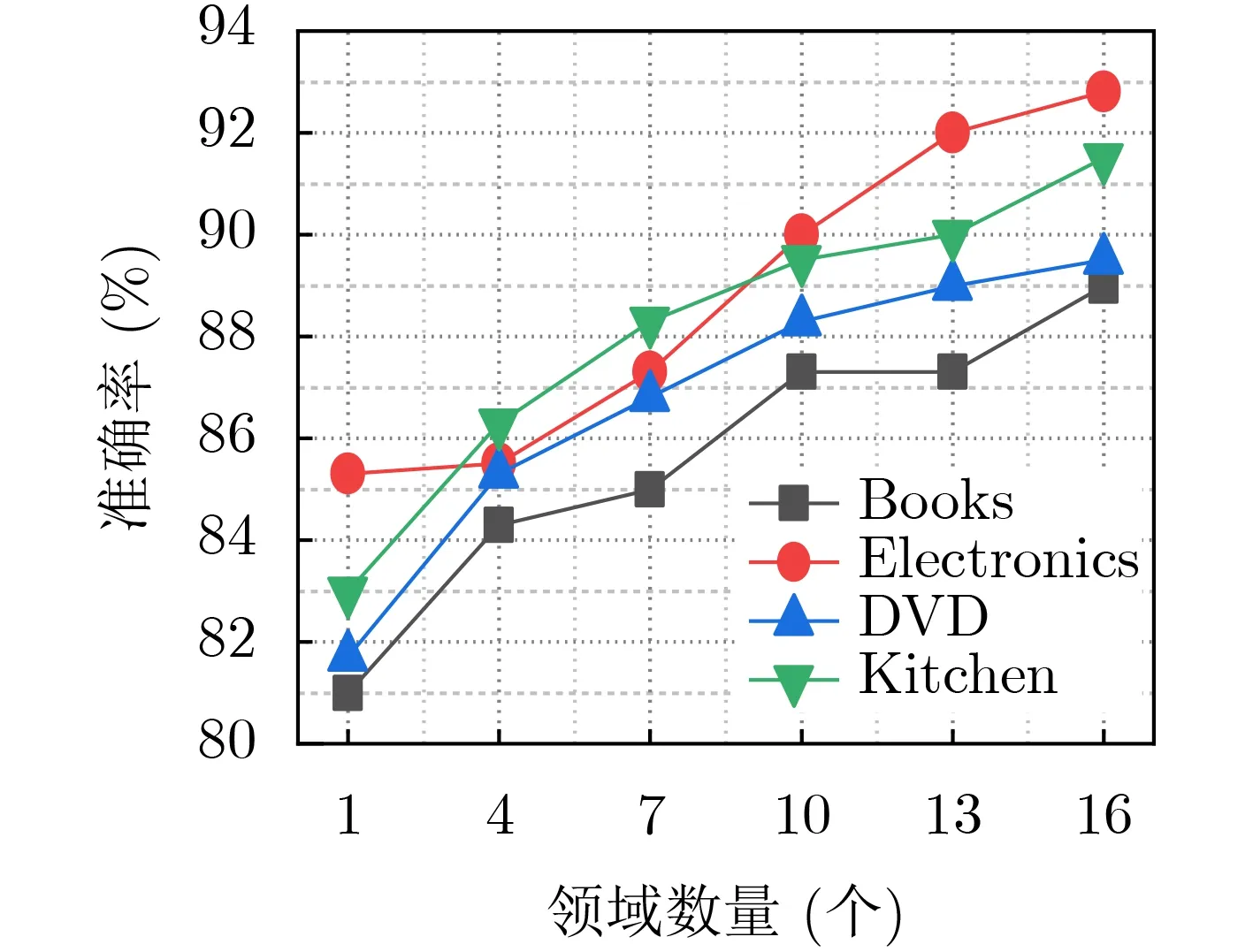
图6 不同领域数量下模型的准确率
5 结论
本文提出一种基于循环卷积神经网络的多任务学习文本分类模型,将多个文本任务在一个深度学习模型中训练。现有常用的多任务学习模型包括完全共享模型和共享私有模型,共享私有模型例如ASP-MTL模型是加入了对抗网络防止共享私有特征混淆,IC-MTL是图多任务学习模型,使得不同任务共享层和私有层之间可以相互通信。完全共享模型例如MTL-DNN,MTL-CNN,FS-MTL则是分别共享不同的深度学习网络构建多任务学习实现不同的自然语言处理任务。本文则考虑内存和时间问题仅仅构建完全共享模型也获得了很好的效果。与过去的完全共享模型不同的是,本文模型通过LSTM和不同尺寸的卷积核提取丰富的语义信息,能够同时利用多任务学习及深度学习模型的优势。在多领域文本分类数据集上的实验结果表明,本文所提MTL-RC模型准确率比单任务STL-LC模型提高了6.5%,训练1次的时间快了213.1 s。单任务学习模型仅仅采用单个小样本数据集,因此标签数据量是比较少的,在同等实验参数和条件下,多任务学习模型比单任务学习准确率提高了很多而且有更快的速度。MTL-RC模型比最新的多任务学习模型FS-MTL,ASP-MTL,IC-MTL分别提升了5.4%,4%和2.8%。因此本文所提模型在解决有标签数据不足的问题上准确率更高,有更好的成效。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国生物医学工程学报(2019年6期)2019-07-16
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2016年3期)2016-08-23
电测与仪表(2016年5期)2016-04-22
