
A Contemporary Review on Drought Modeling Using Machine Learning Approaches
2021-08-25 10:26KarpagamSundararajanLalitGargKathiravanSrinivasanAliKashifBashirJayakumarKaliappanGanapathyPattukandanGanapathySenthilKumaranSelvarajandMeena
Karpagam Sundararajan,Lalit Garg,Kathiravan Srinivasan,Ali Kashif Bashir,Jayakumar Kaliappan,Ganapathy Pattukandan Ganapathy,Senthil Kumaran Selvaraj and T.Meena
1School of Information Technology and Engineering,Vellore Institute of Technology,Vellore,632014,India
2Faculty of Information and Communication Technology,University of Malta,Msida,MSD2080,Malta
3Department of Computing and Mathematics,Manchester Metropolitan University,Manchester,M15 6BH,UK
4School of Computer Science and Engineering,Vellore Institute of Technology,Vellore,632014,India
5Centre for Disaster Mitigation and Management,Vellore Institute of Technology,Vellore,632014,India
6Department of Manufacturing Engineering,School of Mechanical Engineering,Vellore Institute of Technology,Vellore,632014,India
7School of Civil Engineering,Vellore Institute of Technology,Vellore,632014,India
ABSTRACT Drought is the least understood natural disaster due to the complex relationship of multiple contributory factors.Its beginning and end are hard to gauge,and they can last for months or even for years.India has faced many droughts in the last few decades.Predicting future droughts is vital for framing drought management plans to sustain natural resources.The data-driven modelling for forecasting the metrological time series prediction is becoming more powerful and flexible with computational intelligence techniques.Machine learning (ML)techniques have demonstrated success in the drought prediction process and are becoming popular to predict the weather,especially the minimum temperature using backpropagation algorithms.The favourite ML techniques for weather forecasting include singular vector machines(SVM),support vector regression,random forest,decision tree,logistic regression,Naive Bayes,linear regression,gradient boosting tree,k-nearest neighbours (KNN),the adaptive neuro-fuzzy inference system,the feed-forward neural networks,Markovian chain,Bayesian network,hidden Markov models,and autoregressive moving averages,evolutionary algorithms,deep learning and many more.This paper presents a recent review of the literature using ML in drought prediction,the drought indices,dataset,and performance metrics.
KEYWORDS Drought forecasting; machine learning; drought indices; stochastic models; fuzzy logic; dynamic method;hybrid method
1 Introduction
An intense and persistent shortage in precipitation causes drought in a specific region.The land becomes barren and uncultivable as it losses its fertility.The hazardous footprints of drought are much higher than any other natural hazard since they exist for a longer time and affect the economy.Further,this disturbs the necessary life activities and,in due course,human deaths due to starvation.
1.1 Definition of Drought
Drought is defined as a weather-related natural disaster.It affects vast regions for months or years.It has an impact on food production,and it reduces life expectancy and the economic performance of large areas or entire countries [1].
1.2 Origin and Flow of Drought
Compared with disasters such as floods,earthquakes,tornados,or volcanic eruptions,drought is a slowly developing phenomenon that needs to propagate through the entire hydrological cycle.It often shows its impact at all levels [2,3].The three main types of physical droughts are:
• Meteorological drought,
• Hydrological drought,
• Agricultural drought.
The origin and flow of drought are shown in Fig.1.The types of drought are metrological drought,hydrological,and agricultural drought.Among these,the agricultural drought significantly impacts our economy,society,and environment.These impacts are termed the socioeconomic drought and ecological drought.The three critical climatic variations occurring are the increase in evaporation,transpiration,and precipitation deficiency [2].The cause for an increase in evaporation and transpiration is due to high temperature,high wind,less cloud cover,and low humidity.The precipitation deficiency reduces infiltration,runoff,deep percolation,and groundwater discharge.This stage is termed a Metrological drought,and it tells us about the degree of dryness.These climatic variations give rise to soil water deficiency,which in turn causes plant water stress,less biomass,and yield,and this stage is termed as agricultural drought.Agricultural drought is the crop’s variable susceptibility during the various crop development stages,from emergence to maturity.The next phase of the drought is the Hydrological drought; wherein,there is reduced streamflow,inflow to reservoirs,lakes,and ponds.Hydrological drought [4] defines the effect of the precipitation period.The problems with the supply and demand of agricultural goods,poultry,fish,and hydroelectric power raise the socio-economic drought.Ecological drought defines the stress created across ecosystems.
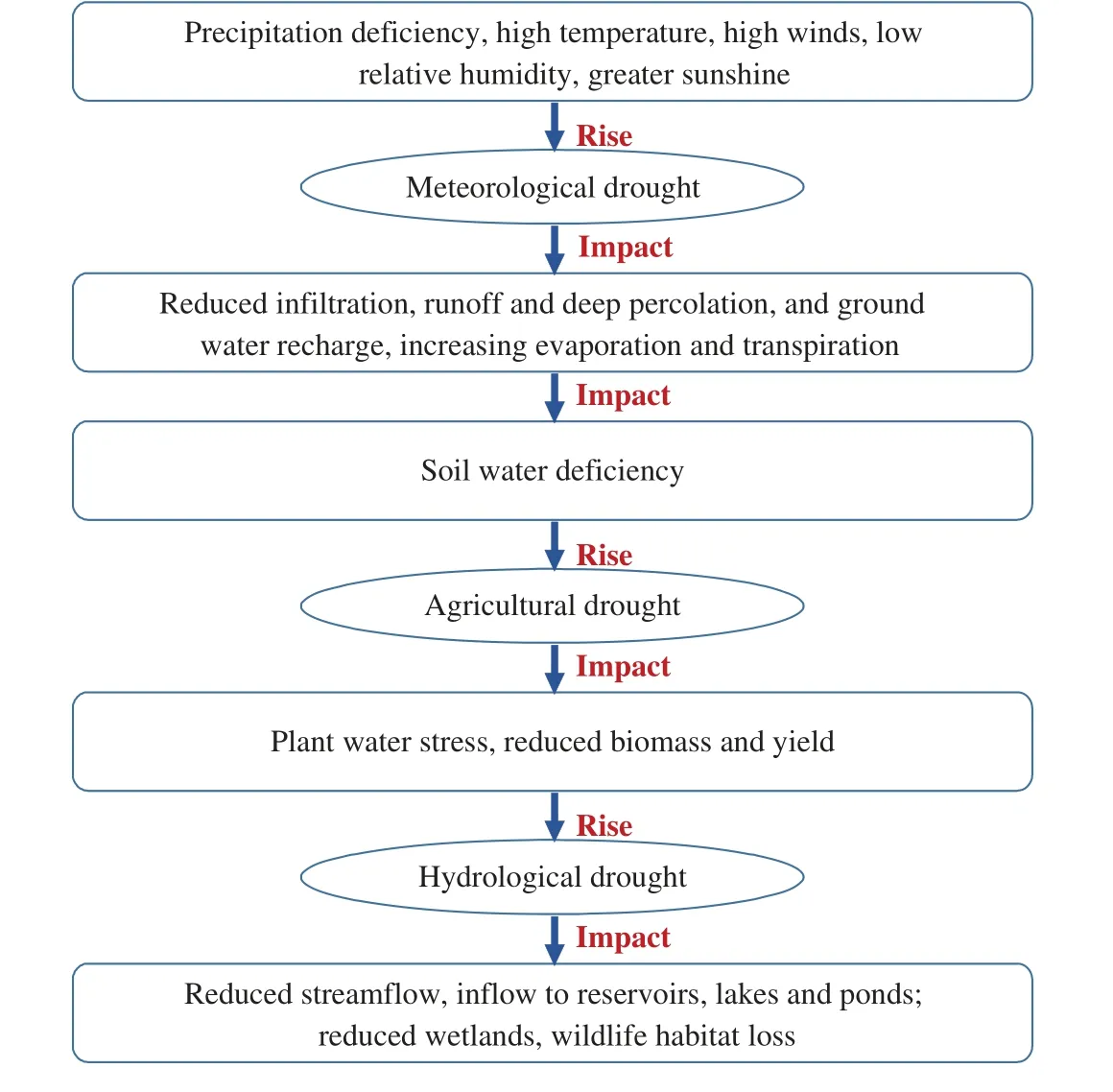
Figure 1:Origin and flow of drought
1.3 Impacts of Drought
The impacts of drought differ based on the causes of its origin [5] and include adverse effects on food production,increasing farmers’suicide rate,excess heat,lower power generation,reduced industrial production,and human and animal health deterioration.In rural areas,it also affects women’s security and education.The three main types of impact are economic,environmental,and social impacts.
1.3.1 Economic Impacts
Plants’growth depends on the surface and groundwater supplies.It is affected by insufficient water,insect infestation,plant disease,and wind erosion.When the plant’s growth is affected,livestock production also gets affected.Farmers lose their income; like a ripple effect,it gets passed on to agro-product retailers and other related business persons.Hence there is a decrease in tax collection of local,state,and central government.It also increases forest fire incidences life-threat to humans and animals.
1.3.2 Environmental Impacts
The damages to the plant and animals will result in a severe environmental impact,including the decrease in water quality and quantity,soil fertility loss,living organisms’biodiversity loss,and many more.Many species recover from these temporary impacts of drought,but few species become extinct.
1.3.3 Social Impact
There arises a threat to public health and safety.The disputes arising in water resource sharing develop huge rivals between the cities,states,and nations.People start migrating into drought-less places,mainly urban areas.Hence it increases the pressure on the social infrastructure of urban sites.
2 Drought Indices
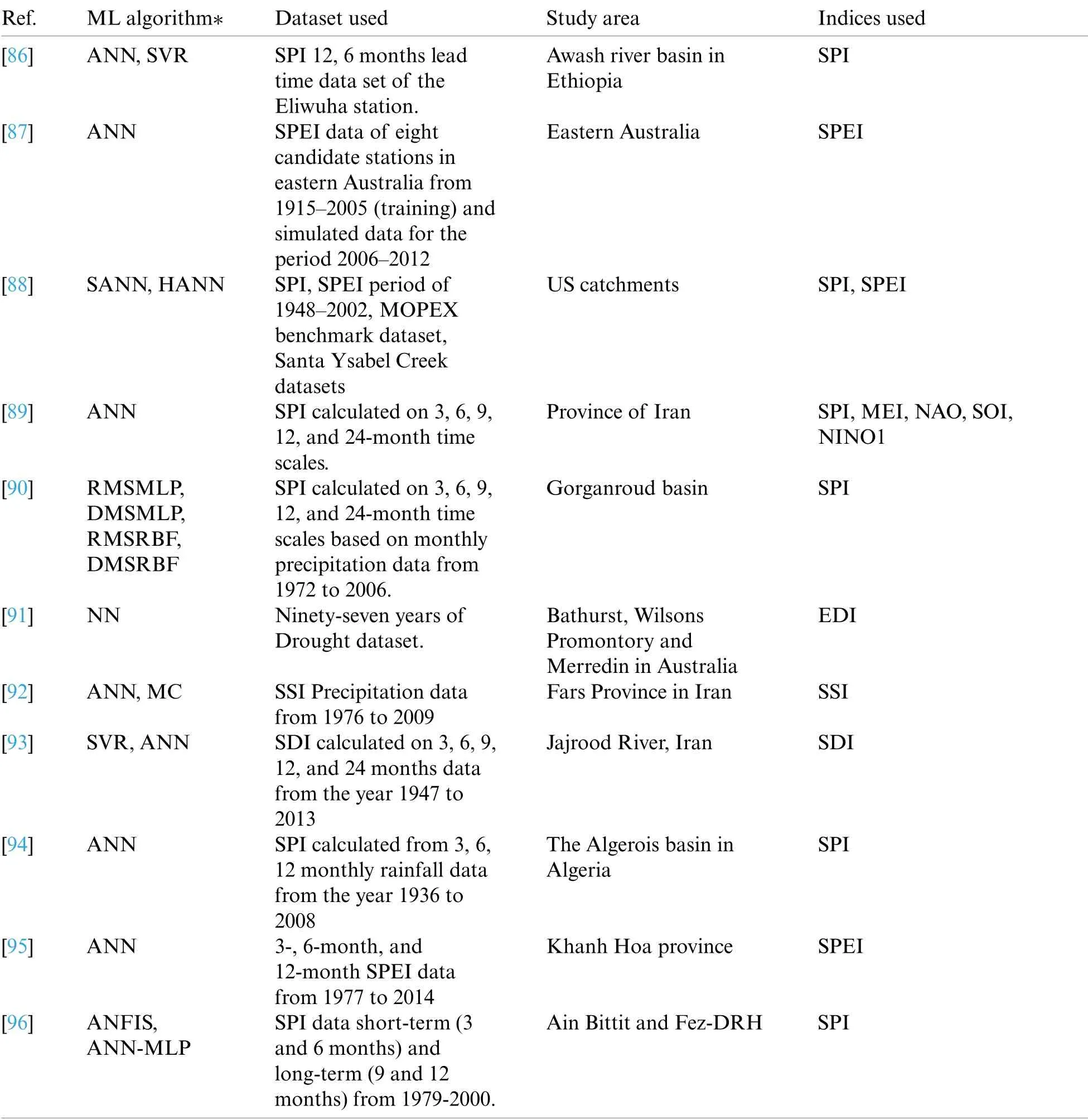
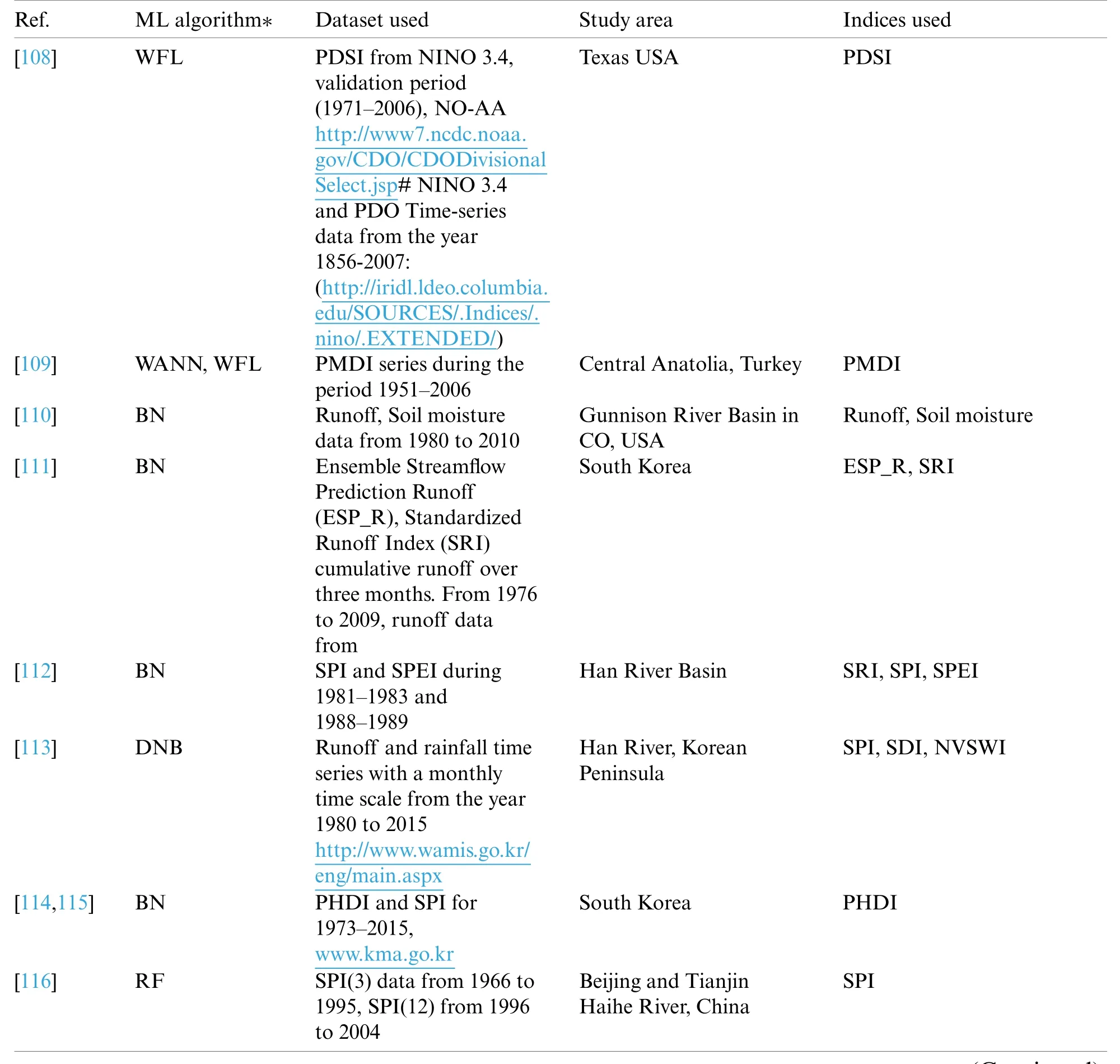
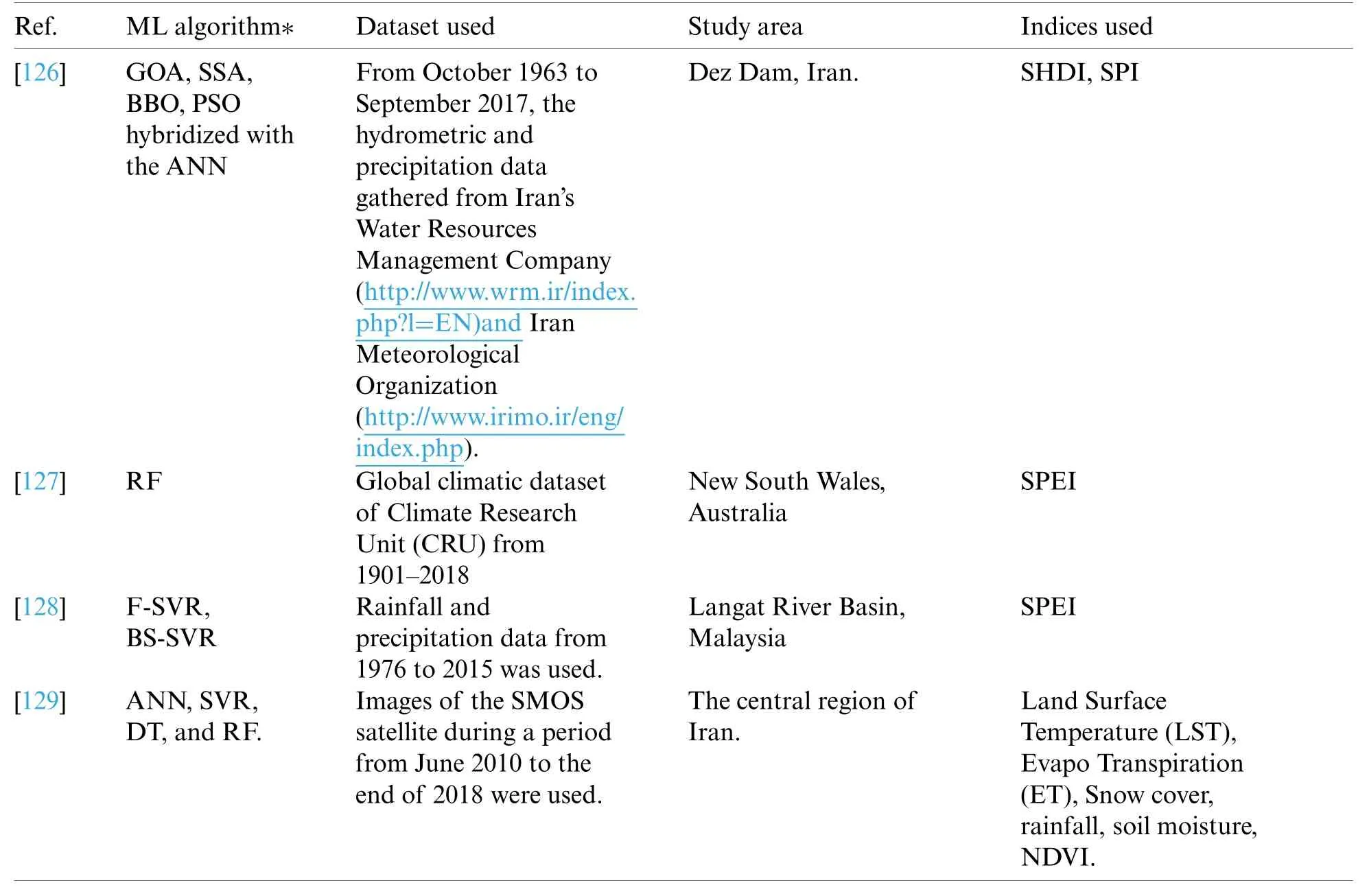
Till now,more than 100 drought indices have been established.These indices help us calculate drought severity,location,start,and end of the drought to help the government issue an early warning to the people and devise contingency plans.Tab.1 lists various drought indices for predicting different types of droughts.Tab.2 lists drought indices with their usage,advantages,and disadvantages.

Table 1:Drought severity levels for calculated SPI values

Table 1(Continued)

Table 1(Continued)

Table 2:Drought indices usage,strength,and weakness

Table 2(Continued)
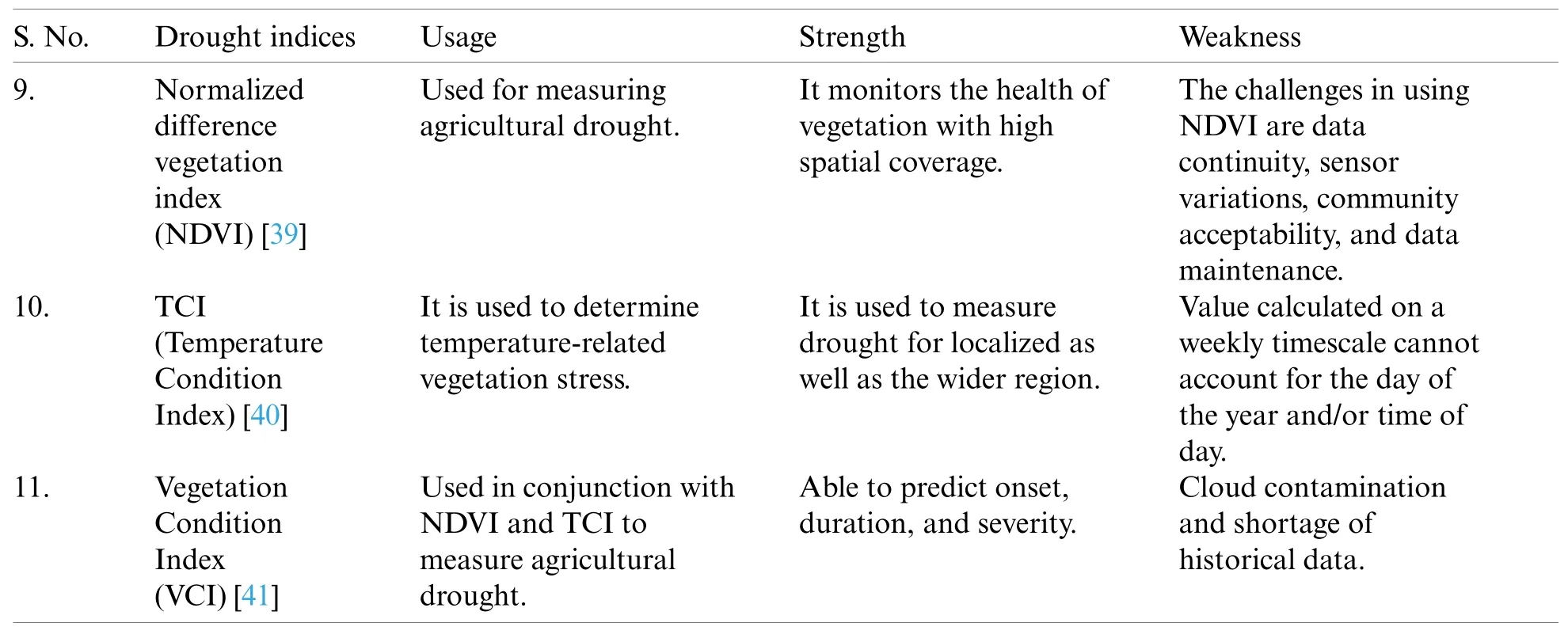
Table 2(Continued)
The general temperature increase of about 0.5-degree celsius to 2-degree Celcius is seen in the last 150 years.So the drought indices calculation has also gone through various evolutions.SPEI considered the top most one since it considered the PET in measuring drought severity [52,53].SRI is needed for measuring socio-economic drought [54].The aridity index is the opposite of the humidity measure [55].The software has been created for the calculation of drought indices NDVI [56],PDSI [17,57],Effective Precipitation [58].
3 Performance Metrics
There are numerous machine learning (ML)-based predictive modelling techniques used in drought forecasting.There is a need to measure each model’s performance and ability to achieve the overall drought forecasting accuracy.The metrics used to assess a model’s effectiveness in predicting the outcome is very important since it can influence the conclusion [59].The performance metrics to identify the error rate between the predicted and observed values are:
• Root Mean Square Error (RMSE)[59]
• Mean Absolute Error (MAE)[59]
• Determination Coefficient (R2)[59]
• The correlation coefficient (r)[60]
• Willmott’s Index (WI)[60]
• Nash-Sutcliffe-Efficiency (NSE)[60].
3.1 Mean Absolute Error
The mean absolute error (MAE)measures the sum of the absolute variation between the forecasted output and the actual output [59].One cannot identify whether it is underpredicting or overpredicting since all the individual variations have equal weight.
The following equation gives the formula to calculateMAE(Eq.(1)).

where,SWLFOR,i-Represents the forecasted output.
SWLOBS,i-Represents the actual output.
N-Represents the total number of data points.
i-Represents a single data from the data points.
3.2 Root Mean Squared Error
Root Mean Squared Error (RMSE)measures the square root of the average squared deviation between the forecasted and actual output [59].It is used when the error is highly nonlinear.RMSE(Eq.(2))reports how much error is generated on average concerning the predicted data.It is a good measure of prediction accuracy.

3.3 Determination Coefficient
The Determination Coefficient (R2)metric shows the percentage variation inyexplained byx-variables,wherexandysignify a data set [59].It finds the likelihood of occurrence of a future event in the predicted outcome (Eq.(3)).

3.4 Willmott’s Index
In 1981,Willmott devised an index of agreement (d),which serves as a standardized measure of the degree of model prediction error [60].The ‘d’value varies between 0 and 1.The agreement value of 1 indicates a perfect match,and 0 indicates no agreement at all.The additive and proportional differences in the observed and simulated means and variances can be detected(Eq.(4)).However,‘d’is overly sensitive to the extreme values due to the squared differences.
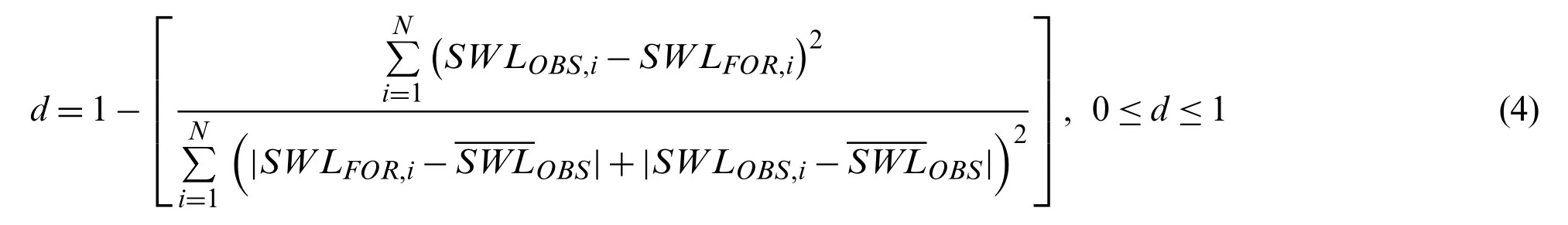
3.5 Nash-Sutcliffe Efficiency
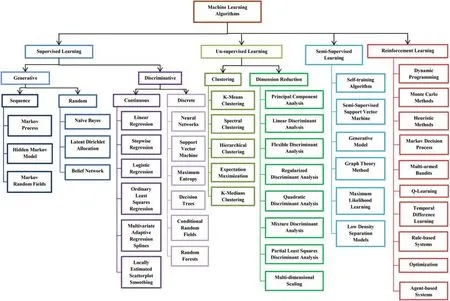
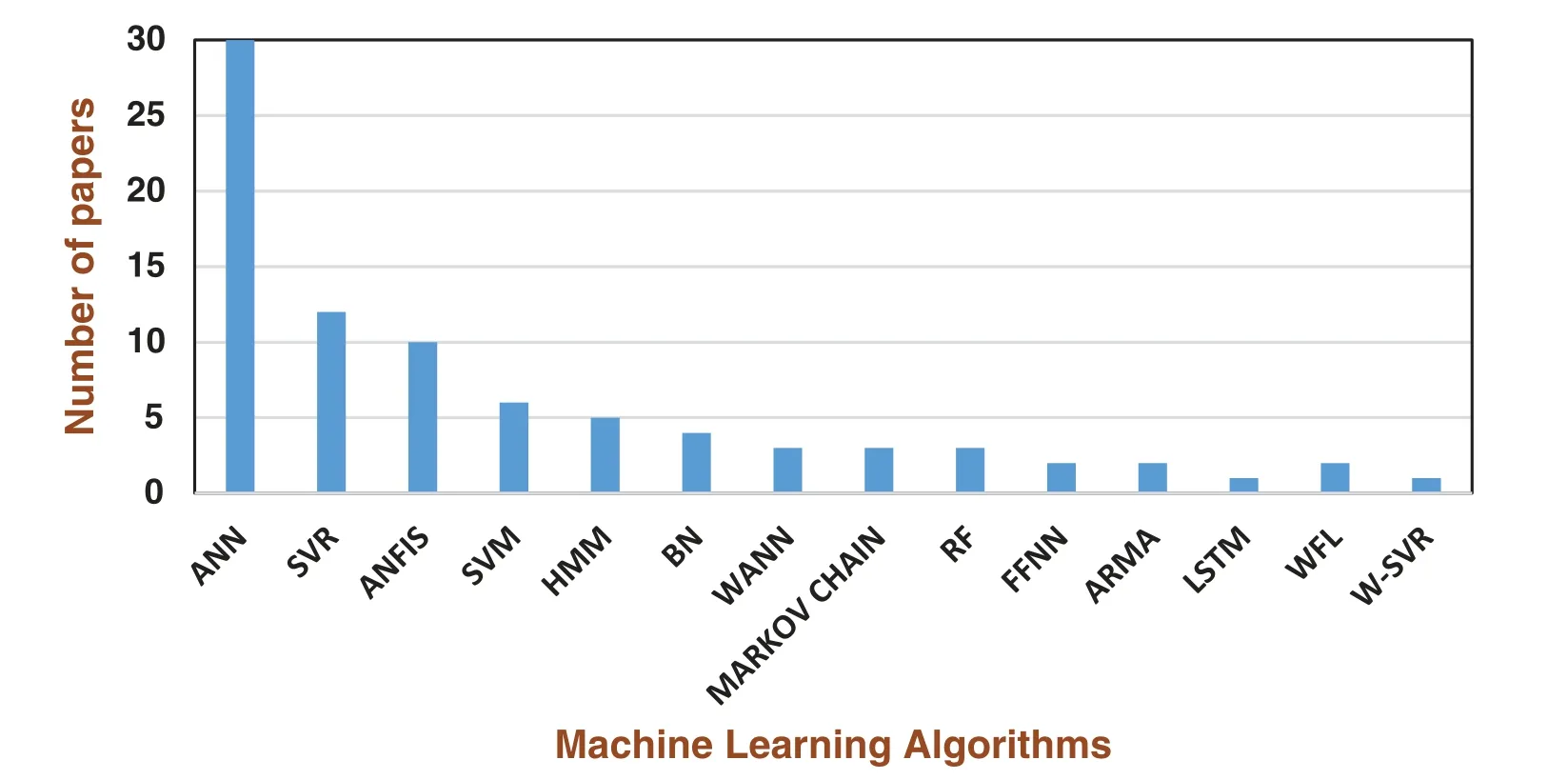
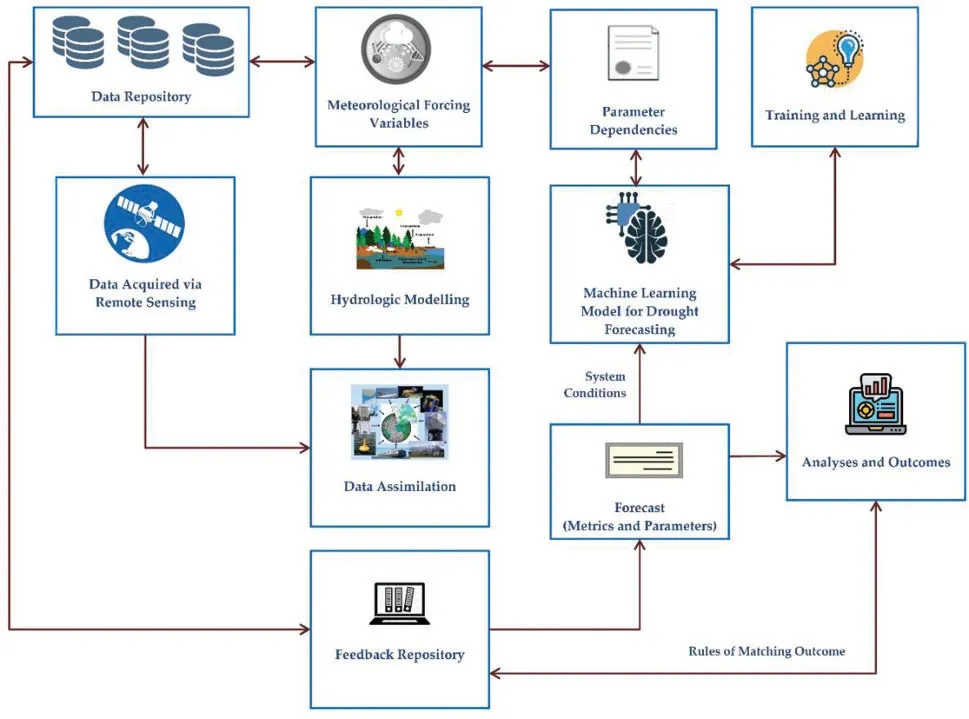
Nash and Sutcliffe devised the Nash-Sutcliffe Efficiency (NSE)(Eq.(5))in 1970.Further,it measures the goodness of fit of hydrological models [60].NSE is a non-dimensional coefficient with a value ranging between −∞and +1.When NSE =1,then it is a perfect match of the model to the observed data.When NSE = 0,the model predictions are as accurate as the empirical data’s mean.When NSE is between infinity (Inf)and 0,that is (Inf Pearson’s correlation coefficient (r)(Eq.(6))measures the strength of the relationship between two variables’relative movements [60].Ther-value ranges between −1.0 and 1.0.A correlation of −1.0 shows a perfect negative correlation,while a correlation with a 1.0 value shows a perfect positive correlation.A correlation with a 0.0 value shows no relationship between the movements of the two variables. ML is an application of Artificial Intelligence (AI).ML algorithms are developed with the capability to learn from past experiences and execute new tasks.These algorithms are mainly classified into two categories,namely Supervised Learning and Unsupervised Learning.Supervised learning takes up the labelled data for training and produces a data output from the previous experience.Unsupervised learning is a challenging one,here the system has only the unlabeled data,but it works on its own to discover the information.Fig.2 shows the taxonomy of the machine algorithms.The Taxonomy of Fig.2 represents only some of the popular machine learning techniques such as Neural Network,Support Vector Machines,Partial Least Square-Discriminant Analysis,Linear Regression,clustering,expectation-maximization,decision trees,maximum likelihood learning,and Markov process.At the same time,many other machine learning methods such as Deep Learning [61],Fuzzy Logic [62,63],k-Nearest Neighbours,Linear Regression,Singular vector decomposition,and Tenson factorization [64,65],mathematical programming,stochastic modelling,game Theory,phase-type distribution [66,67],semi-Markov modelling [68,69],Gaussian Mixture Modeling [70],discrete-time Markov modelling [71],nonhomogeneous Markov modeling [72],Extreme learning machines (ELM)[73] are not included in the figure as there are numerous machine learning methods.It is challenging to have all methods in one figure. Figure 2:Machine Learning (ML)methods–taxonomy Nowadays,Mother Nature is challenging humanity with harsh weather conditions.Natural disasters like floods,hurricanes,and drought are too deadly to sabotage human civilization’s prosperity.It takes years and years for us to recover from the fury of nature.The past weather data is a great treasure.So with that past data and ML models,the scientist can achieve 100% accurate weather forecasting.Tab.3 gives a simple view of the various studies in drought forecasting,describing the ML algorithm used,the dataset used in processing,the area taken for the study,and the drought index used in forecasting.The total number of ML papers considered for review is 83,starting from January 2009 to February 2021.The details of the number of Science Citation Index Expanded (SCIE),Emerging Sources Citation Index (ESCI),and SCOPUS papers are given in the pie-chart shown in Fig.3. Table 3:Comparison of Machine Learning (ML)models in drought forecasting.(∗ ML Algorithm) Table 3(Continued) Table 3(Continued) Table 3(Continued) Table 3(Continued) Figure 3:Journal index distribution Bacanli et al.[74] used the Adaptive Neuro-Fuzzy Inference System (ANFIS)for drought forecasting.The study area taken was Turkey,and the indices used in forecasting were SPI and precipitation.The values from 10 gauging stations of Central Anatolia were taken.ANFIS model was compared with Feed Forward Neural Networks (FFNN)and Multiple Linear Regression(MLR).It has been found that the Adaptive Neuro-Fuzzy Inference System (ANFIS)provides higher accuracy and reliability. Dastorani et al.[76] developed a model to predict the precipitation value-12 months in advance.The precipitation prediction was made for Yazd,Iran.Three models were developed-Recurrent Network (RN),Time Lagged Recurrent Network (TLRN),and ANFIS.The parameters taken were wind speed,wind direction,relative humidity,maximum temperature,normalized rainfall data,seasonal and 3-month average precipitation,and mean temperature for the period 1975 to 2007 for ANFIS five-layer processing was done.The results showed that among the ANN models,TLRN prediction accuracy was very high.They compared the prediction accuracy of TLRN with ANFIS,and it was found that both the methods performed equally well.A new fact found was,when 3-year moving average precipitation was added to the input,best results were achieved,in which case,ANFIS was predicting better than TLRN. Marj et al.[77] predicted the agricultural drought in the Aharchay Basin in Azerbaijan Province in Iran’s northwest.Further,they used the NDVI values with two climatic signals in the ANN model for prediction.The two climatic signals used were the SOI and NAO.From the NDVI,the Anomaly Vegetation Index (AVI)and Vegetation Condition Index (VCI)were calculated.The three months viz.May,June,and July data from 1982 to 1999 were used to train and test the model.May,June and July were agricultural months considered for the study.The results showed that the standard deviation for predicted and observed NDVI was less than 1.This study also suggested a low correlation between the rainfall recorded and NDVI values predicted in this area. Belayneh et al.[79] selected an area with drastic climatic variations year by year.The chosen site was the Awash River Basin of Ethiopia.Since there was a significant difference in this area’s climate,it was divided into Upper Awash Basin and Lower Awash Basin.Three data-driven models were developed for predicting SPI value-ANN,Support Vector Regression (SVR),and Wavelet Neural-networks (WNN).The three models’performance was compared using MAE,RMSE,and R2performance values.The WNN provided a better SPI prediction in all three basin areas.All the models showed greater accuracy in determining SPI 12 than SPI 3. Masinde et al.[83] used ANN to predict the Effective Drought Index (EDI).The study was carried out in Kenya,where rainfall was the only source for agriculture.With the help of 30 years of data from four network stations,the ANN model was developed.Kenya Metrological Department used statistical techniques to predict the rainfall probability as normal,above average,and below average.With these values,one can get only the conceptual indication of drought.However,ANN was deployed to forecast the drought starting period,severity,and duration of drought.EDI is an excellent drought indicator.First,the EDI was calculated using the following procedure.The Java code was used to clean and format the 30 years’data.Subsequently,this data was processed by the EDI Fortran program.Then,the ANN model was constructed.The ANN used the EDI,precipitation,and AWRI values for the years 1980 to 2009.Lead time for a day,month,and year forecast outputs were obtained.The experimental results showed the day lead time forecast with precipitation and provided an accuracy of 98%. Hosseini-Moghari et al.[90] aimed to compare direct multi-step neural networks’performance and recursive multi-step neural networks.The MLP,RBF,and GRNN neural networks were taken for the study.The overall results obtained inferred that the RBF shows good accuracy,followed by MLP and GRNN. Belayneh et al.[81] were the first to experiment with coupled ML methods and ensembling techniques in drought forecasting.Wavelet transformation was applied to ANN and SVR.In wavelet analysis,the original time series was modified into a new time series.A wavelet was used to denoise the time series data,and WANN and WSVR were created.The k-fold bootstrap validation technique was used to construct BANN and BSVR.With the ensembling of boosting methods,BSANN and BSSVR were created.SPI 3,SPI 12,and SPI 24 predictions were accomplished using the models mentioned above for forecasting the meteorological drought.The performance comparison among the models was accomplished using RMSE,MAE,and R2. Prasad et al.[98] integrated the wavelet hybrid ANN with an Iterative Input selection algorithm (IIS)to forecast the streamflow in Australia’s Murray-Darling basin to plan water utilization and redistribution.The new model was the non-decimated Maximum Overlap Discrete Wavelet Transform (MODWT)algorithm using ANN as a primary model.M5 model was used as the benchmark evaluation.IIS was used to select the best predictors since there were many predictors like maximum and minimum temperature,precipitation,solar radiation,vapour pressure,and evaporation. Zhang et al.[100] carried out SPEI prediction in the Shaanxi province of China.Totally three procedures-ANN,DLNM,and XGBoost models were implemented and compared.SPEI 3,SPEI 6,SPEI 9,and SPEI 12 were predicted using the data from 1961 to 2016 with a 1 to 6 months lead time.The results showed that the XGBoost method showed better accuracy than the other two predicting the widespread drought and drought category. Kisi et al.[130] accomplished the SPI prediction using classic ANFIS and conjunctive ANFIS models embedded with meta-heuristic optimization algorithms,namely particle swarm optimization (PSO),Genetic Algorithm (GA),Ant colony Algorithm (ACO),and Butterfly Optimization Algorithm (BOA).SPI-3,SPI-6,SPI-9,and SPI-12 prediction for the three stations in Iran’s Semnan Province were performed.Evolutionary algorithms outperformed classic ANFIS performance in all the stations and for all SPI values prediction.The performance of ANFIS-PSO was outstanding than the other three methods. Mulualem et al.[131] determined the climatic indicators that better calculate SPEI.The study used the 30 years of data from 1986 to 2015 for Ethiopia’s Upper Blue Nile Basin.Totally seven ANN models were designed for predicting SPEI by incorporating the factors like hydro-meteorological,climate,sea surface temperatures,and topographic attributes to forecast the SPEI.Totally 12 climatic indicators were taken,and their various combinations were fed into the seven ANN models.The three climatic indicators,maximum temperature,evapotranspiration,and rainfall,were found to be prominent. Moazenzadeh et al.[132] predicted the evaporation factor.This factor was not measured in most of the metrological stations.However,this factor seemed to be essential for determining the water resource share.The evaporation factor was predicted at two meteorological stations (Rasht and Lahijan)located in Gilan province in northern Iran using SVR and SVR coupled with Firefly.The Pearson correlation coefficient was used in identifying the parameters which had more impact on evaporation prediction.The selected parameters were the maximum air temperature,net solar radiation,mean relative humidity,wind speed,precipitation,sunshine hours,and saturation vapour pressure deficit.Seven parameters were taken,but SVR and SVR-FA prediction reached the best when a more significant number of inputs were used. Streamflow Drought Index (SDI)was introduced in 2008 by Nalbantis [133].Further,this was used to calculate the intensity,duration of drought,for which it needs monthly discharge data.Woli et al.[80] devised methods to forecast SDI using SVR and ANN and studied the best input combinations used in forecasting.The Pearson coefficient of type III was the best statistical for each time scale of monthly discharge intervals of 3,6,9,12,and 24.The gamma test was used in finding the input combination.The SDI was predicted in 3,6,9,12,and 24 month periods for using the corresponding delays of SDIt,SDIt-1,SDIt-2,SDIt-3,and SDIt-4as the primary inputs and SDIt+1as the target variable.Results were taken with all inputs first and then by leaving the input variables one by one.The gamma test found that SDIt(no delay)and SDIt-1(1-month delay)had a high impact on the forecast. Alsumaiei et al.[134] established the Nonlinear Autoregressive Networks (NAR),a unique type of Recurrent Neural Network with the combination of ANN and autoregressive models used to describe processes based on lagged input and output variables for predicting precipitation index.The correlogram test was conducted on the observed precipitation index time series to evaluate adjacent values’correlation and predict the next time step value.NAR was found to be a reliable model for drought forecasting. Ganguli et al.[104] tried the ensemble Support Vector Machine (SVR)with Coupla for predicting metrological drought in Rajasthan.The Least Square SVR model was used in drought index forecasting.Bivariate Coupla functions were used to model the uncertainty associated with drought forecasting.Three types of copulas,namely the Frank,Clayton,and Plackett families,were taken to study drought forecasting.Forecasting was done up to a three-month lead time.From the experimental results,it was found that the prediction performance increased when climatic indices were added. Chiang et al.[105] established the two-stage SVM model for reservoir drought forecasting.First,the single-stage SVM was devised,and then it was compared with the other three models.The 90 days lead time forecast achieved up to 80% accuracy.Both studies forecasted the reservoir drought for the Tsengwen reservoir,the largest reservoir in Southern Taiwan.In a two-stage SVM,four parameters were used as input.They were reservoir storage,inflows,the critical limit of operation rule curves,and the Nthten-day in a year.The training data was from 1975 to 1991,and the testing data was from 2000 to 2010.In the first stage of the SVM,drought or non-drought was predicted.In the second stage of SVM,the drought category was predicted as Drought or Severe Drought.The LIBSVM tool was used in the implementation,and the results were compared with Artificial Neural Networks (ANN),Maximum Likelihood Classifier (MLC),and Bayes classifier (BC).The SVM model outperformed the other three models in predicting the non-drought category and its ten-day predictions were above 90%. Kisi et al.[102] framed a model to forecast the monthly streamflow in Gerdelli Station on Canakdere River and Isakoy Station on Goksudere River in Turkey’s Eastern Black Sea region.The model was constructed by combining discrete wavelet transform and support vector machine;the past data’s time-series were decomposed into three sub-time series components (D1,D2,and D3)by the Mallat DWT algorithm.D1,D2,and D3 represent the time series mode of 2 months,4-months,and 8-months,respectively.RMSE,MAE,and R were the performance metrics evaluating WSVR with SVR model accuracies.Totally 40 years of observed data for both stations were collected.Out of this,75% was used for training and 25% for testing.The output showed that the WSVR conjunction model increased the prediction correlation coefficient concerning the single SVR model by 19%–30%.There was a reduction in the root mean square errors and mean absolute errors by 11%–46% and 19%–44%. Memarian et al.[135] determined the Co-Active Neuro-Fuzzy Inference System (CANFIS)capability for drought forecasting of Birjand,Iran.The various global climatic signals were explored in addition to the rainfall and precipitation.In total,nine climatic signals were used.NINO 1+2 describes ocean level temperature; NINO 3 and NINO 3.4 describe the Pacific Ocean’s surface temperature.Tropical Southern Atlantic index (TSA)measures the Atlantis surface temperature.SOI was based on water surface pressure.NAO index was calculated using pressure fluctuations in the North Atlantic Ocean.Based on the beach’s average monthly precipitation for Arizona and New Mexico regions,SW Monsoon Region Rainfall (SWMRR)was measured.Multivariate ENSO Index (MEI)was calculated using the parameters such as water surface pressure,temperature,and wind velocity.Thermal fluctuations of the Atlantic Ocean were used in measuring Atlantic Multi-decadal Oscillation (AMO)index.The neural network and fuzzy rules were combined,and the neuro-fuzzy structure was formed.CANFIS performs well in index NINO 1+2 with five months lag. Djerbouai et al.[94] investigated ANN and Wavelet ANN’s prediction accuracy against the stochastic models ARIMA and SARIMA.The difference between ARIMA and SARIMA was that the ARIMA worked well with static data,and SARIMA also functioned with non-stationary data.SARIMA was a non-seasonal model used in modelling seasonal time series with varying mean and other statistics across the years.The experimental results showed that the SPI-12 model provided good forecast than SPI-3 and SPI-6 in one-month lead prediction. Tufaner et al.[136] preferred the regression methods,and the selected input variables had shown promising results.The metrological variables were used as input data.Among the classification techniques ANN,Decision Tree,and SVM,ANN had a correlation coefficient of 0.98. Shirmohammadi et al.[82] developed drought forecasting using wavelet ANN and ANFIS methods with SPI.The metrological drought was tested at different time scales.The study site selected was Tabriz,East Azerbaijan province,Iran; the data period 1952 to 1992 was used to test and then predict the meteorological drought test period extending from 1992 to 2011.Further,to build this hybrid model,the sub-series data played a significant role.In step 1,the original SPI data were decomposed into details using discrete wavelet transform.By applying successive approximation signals,the decomposition process was iterated,and hence the original time series was broken down into lower resolution components of levels 1,2,3,and 4.Seven different kinds of wavelets,namely,db4,bior1.1,bior1.5,rboi1.1,rboi1.5,coif2,and coif4 wavelets,were used.Out of the four models ANN,ANFIS,wavelet ANN,and wavelet ANFIS,wavelet ANFIS produced good prediction accuracy.Woli et al.[80] explored the use of climate indices like ENSO as a predictor.The ARID index was based on ENSO,and its efficiency in drought forecasting was studied.The ARID index with four methods was predicted:ANN,ANFIS,LR,and SARIMA models.The climatic indices,namely JMA,AMO,NAO,Nino-3.4,PDO,and PNA,were deployed.During winter,the ENSO signals were strong,and hence LR and ANFIS prediction were higher.SARIMA model provided the correct prediction in the months where the precipitation was high.However,ANN offered the overall best prediction performance from March to December. Ozger et al.[108] concentrated on finding the PDSI values for drought forecasting.For PDSI calculation,precipitation,temperature,soil moisture,and previous PDSI values were needed.They witnessed that obtaining past year data for precipitation and temperature was easy,but it was challenging for them to get the soil moisture values.The Wavelet Fuzzy Logic (WFL)was used to predict the PDSI.It was found that temperature and precipitation predictors give the best results in predicting PDSI values.Agboola et al.[137] made rainfall prediction in Nigeria using Fuzzy logic.The fuzzy logic model contained two components.The first component was the knowledge base,where the if-then rules with decision making were made.The second component was the decision unit,performing inference operation.The input variables used were temperature,pressure,humidity,dew point,and wind speed.The error rate was very minimal.Hence,it was proved that the Fuzzy logic could be used in the rainfall prediction of Nigeria. Shin et al.[114] designed a model,namely Bayesian Networks based Drought forecasting with Drought Propagation (BNDF_DP),which incorporates dynamic model predictions and a drought propagation relationship.The basic idea used was the drought persistence and transition properties in the drought.The metrological drought occurs initially due to the lack of precipitation followed by a reduction in soil moisture and groundwater depletion.It leads to agricultural drought and hydrological drought.The conversion period from meteorological drought to hydrological drought is called lag time.The hydrological drought forecasting was made using the PHDI and the SPI.The model was constructed with three-parent nodes,namely HDn-current hydrological condition,MHDn+l-predicted hydrological drought using Asia-Pacific Climate Center Multi-Model Ensemble(APCC MME)forecast,SPIn+l-lt; l–lead-time and lt-lag-time)and one child node (HDn+l).ROC Curve analysis proves the proposed model’s superior forecasting skills for long-term drought,with a 2 and 3 month lead time.Sattar et al.[112] attempted to trace the probability of hydrological drought in Korea’s Han River.The Bayesian model finds the probabilistic relationship of weekly lag time between hydrological drought and metrological drought. SPI and SPEI values define the metrological drought,and SRI describes the hydrological drought.Out of 24 sub-basins of the Han River,four sub-basins were chosen for the study.The daily records of precipitation were collected from the Korean Metrological department.From the precipitation data,the evapotranspiration and runoff were calculated using the TANK model.A metric called Response-rate gives the percentage of metrological drought converted to hydrological drought.The joint probability between the lag time and drought Intensity,P(I,LT),was estimated using a Coupla function.Four Coupla functions were examined,namely,Gaussian,T,Gumbel,and Clayton.Further,the Gaussian was chosen as the best choice.Bae et al.[111]devised a Bayesian model-based approach to find the hydrological drought using.The posterior distribution was found out using the Bayesian model using the prior distribution regression result between Historical Runoff (HR)and Ensemble Streamflow Prediction Runoff (ESP_R)as the prior information and a conditional equation derived from the linear regression model as a likelihood function. Mehr et al.[138] developed a novel fuzzy random forest (FRF)model to predict SPEI.The dataset was divided into smaller subsets/branches similar to the divide and conquer algorithm until the branch shows the class directly.An ensemble of FRF overcame the inefficiency of the Fuzzy decision Tree in handling nonlinear data. Aviles et al.[139] pointed out the impacts of the drought condition in the Andean mountains of south Ecuador using the reinforcement learning-based MC model and Bayesian Network (BN)method.Out of the four Coupla functions,two elliptical and two archimedean,the best was estimated using the parametric bootstrap-based goodness-of-fit test.The Ranked Probability Skill Score (RPSS)was used to evaluate the performance of the models.The results showed that the BN-based models were better at predicting severe drought events than the MC-based models.Khadr [121] developed various Hidden Markov Models (HMM)using SPI to predict the drought.The HMM’s speciality is that the output is conditionally independent,which helps us understand the local scale statistics at a larger scale.The HMM performed well with a short lead time,but the forecast accuracy decreased once the lead time increased.HMM performed well for a lead time of 7 months.Shuang et al.[140] devised the hybrid hidden Markov model coupled with multivariate copula for metrological drought forecast with SPI time series.With Bayesian Inference,the model structure and parameters were optimized.The mixture distribution for each prediction was a weighted combination of posterior copula conditional distributions.Further,they also concluded that this method is more accurate than ANN,ARMA,and HMM. Agana et al.[141] created a hybrid predictive model using a denoised empirical mode decomposition (EMD)and a deep belief network (DBN).The StreamFlow Index (SFI)was predicted.The strength of EMD is decomposing any complicated dataset into a finite number of Intrinsic Mode Functions (IMF)of different dominant frequencies and amplitudes.Selecting the IMF is done by Detrended fluctuation analysis.EMD servers were better in input decomposition than wavelet analysis.Chen et al.[142] framed the Deep Belief Network (DBN)based model and compared it with Backpropagation Neural Network; it was observed that DBN was more reliable and efficient for short-term prediction of drought index.SPI12,SPI9,SPI6,and SPI3 predictions were made.The RMSE and MAE values get minimized with the increase in SPI timescale.The RMSE value in the range of 0.4 to 0.5,and the MAE value in the range of 0.2.to 0.3 was achieved in study stations.Poornima et al.[143] utilized a correlation coefficient test to determine the climate indicator along with SPI,SPEI prediction.Long short-term memory was used in a recurrent neural network to predict the drought indices.Zhu et al.[144] worked on the aggregation of LSTM with the Conditional Probability Model (CPM),namely Gaussian Process Regression (GPR).Thess models were accomplished in two various forms by GPR-LSTM-S1 and GP-LSTM-S2.In GP-LSTM-S1,the GPR was used for analyzing the forecasting error series,and in GPR-LSTM-S2,the GPR was embedded in the last hidden layer.GPLSTM-S1 lacks performance stability as compared with GPLSTM-S2.Further,they concluded that the LSTM was good at handling the high-dimensional data. The most important findings observed in the study in this paper are discussed in various sections.In Section 5.1,the results related to multiple ML processes are given.The finding on the hydrological drought prediction is given in 5.2,and 5.3 discusses future work. The critical observation found from the papers taken in this review related to the ML algorithm’s five primary processes,namely Data Collection,Feature Selection,prediction model construction,ensembling,performance evaluation,and parameter tuning,are given below. 5.1.1 Data Collection and Preparation The accuracy of any machine algorithm depends primarily on the quantity and quality of data.In this phase,the necessary data collection was accomplished.From the extensive collection of nearly 75 years of precipitation,rainfall,and temperature data,many drought indices like SPI,SPEI,and PDSI are derived.From the literature reviewed in this paper,we can see that the SPI,SPEI,PDSI,NINO,ELINO data are predominantly used.New Drought indices are used by subjecting the available water-related variables to PCA,calculating the correlation matrices between time series ‘r’and available hydro metrological datasets,yielding the Eigenvalue Eigenvector.Mulualem et al.[131] determined the climatic indicators that calculate the best SPEI.It was found that the best indices for SPEI prediction were rainfall,maximum temperature,and evapotranspiration.Ozger et al.[108] proved that the PDSI prediction with WFL requires temperature and precipitation data predominantly.Borji et al.[93] obtained a virtuous result in SDI prediction with the Gamma test.Marj et al.[77] proved a low correlation between the rainfall recorded and NDVI values predicted.They also forecasted NDVI using two climatic signals NAO and SOI,recorded in the preceding spring.Mehr et al.[109] performed the sensitivity analysis among input variable bands and found the impact of the initial values of PMDI on predicting drought within a 6-month lead-time.NIÑO 3.4 had a high potential to forecast drought for 6-through 12-month lead-time.There was a need for cleaning the data received from weather stations.Most of the data in past years were stored in the format used by FORTRAN.It needs to be transformed into the required format for further processing by the machine learning models. Ali et al.[145,146] decomposed 12 input predictors into nearly 120 sub-components.Simulated Annealing was used to choose the most appropriate IMF’s for the training period.KRR was used to forecast the multiscalar SPI series.The solution was designed to use dynamically driven climatological factors such as atmospheric circulation instead of univariate data.Dikshit et al.[147] SPEI forecasting was good in predicting drought since it considers both the temperature and rainfall.The atmospheric and oceanic phenomena were considered,but it was found that the sea surface temperature does not have much significance.Han et al.[148] suggested using remote sensing data in gauge scarcity areas.Since it was prone to systematic bias,they merged it with the insitu data.Bojang et al.[149] stated that Single Spectrum Analysis (SSA)is an all-time best time series analysis method.It can be customized to any underlying dataset,and it does not need any prior modelling.Hence,they termed it as a model-free method.Decomposition and reconstruction is the two process in SSA.The decomposition is done by performing embedding and singular value decomposition.Han et al.[148] aimed to synthesize the forecasting models used in drought forecasting and tree mortality based on causative mechanisms and global warming implications.For better forecasting,the statistical models with nonlinear and non-stationary behaviour have to be merged with dynamic models to improve their stochastic characteristics.Fig.4 shows the indices and number of papers used in this review paper. Figure 4:Drought indices vs. number of papers 5.1.2 Feature Selection The input for the drought prediction models was given as processed data.The calculated time series data of drought indices get transformed into new time series data.Wavelet analysis helps to de-noise a particular data set; the transformation from the original time series to the new time series was done using wavelet analysis and was used as an input.The appropriate input combination to be fed into the model was pre-processed using the gamma test [93].Many ML studies proved that feature selection improves classification accuracy and reduces processing time.A tree-based iterative input selection (IIS)algorithm was used to test and sort a global predictor matrix.Through a Copula-based approach,the ensembles of drought indices were determined [104].In NDVI values,the selection of the proper cells within the SST and SLP databases was done by linkage data mining models and using the geographical information system (GIS).Probability distribution fits the precipitation data of each station to identify observed precipitation probabilities.The appropriateness of normal and exponential probability distributions was examined by the Kolmogorov-Smirnov (K-S)test.Deng et al.[101] performed data denoising by heursure and rigrsure algorithms,with bior3.3 associated with biorthogonal wavelets with three decomposition levels.Zhang et al.[100] found that more period was needed when many predictors were used.Mehr et al.[109] also proved that using the wavelet algorithm minimizes the noise,and it helped well in PDMI prediction using LGP.Genetic Algorithm is used in optimizing the weights of ANN.Using PCA (Principle Component Analysis)the 9 different drought attributes is reduced to 4,to improve classification and reduce time [150]. Dastorani et al.[76] found a new fact that,when 3-year moving average precipitation was added to the input,the best results were achieved.Farokhnia et al.[151] witnessed that SST and SLP data’s application improved the ANFIS model’s performance.Shirmohammadi et al.[82]determined that the wavelet transforms better handle nonlinear and non-seasonal data. 5.1.3 Building the Drought Prediction Model Many ML models are available for building the drought prediction model.Many successful studies used various ML techniques for drought prediction.The most commonly used ML models are ANN-based,fuzzy,SVM,Bayesian,Random forest,and many more.Generally,the ANFIS offered a better prediction than TLRN [76] with 3-month average precipitation.Fig.5 shows the ML models used in drought predictionvs.the number of papers. Figure 5:Machine Learning (ML)algorithms vs. the number of papers 5.1.4 Ensembling of ML Algorithms Two heads can perform better than one; similarly,when more than one ML model is used in prediction,it will improve the accuracy.The bootstrap technique can be applied by creating bootstrap ANN and SVR ensemble models.Ibrahimi et al.[96] showed good SPI prediction using WANFIS than WASVR and WAANN MLP models.Finally,the results predicted that wavelets boosted ANN and SVR-WBSANN and WBSSVR had better forecasts than other models.Djerbouai et al.[94] clearly explained that the wavelet ANN and wavelet ANFIS wavelet models could cope with the nonlinearity and variations in data due to seasonal changes.Zhang et al.[100]proved that extreme gradients with linear booster performed well.Khan et al.[152] established the metrological drought indices such as the Standardized Precipitation Index (SPI)and the Standard Index of Annual Precipitation (SIAP)values.These values were decomposed into low and highfrequency sub-series by Discrete Wavelet Transform,and then it was passed on to the predictive models of ARIMA and ANN.The wavelet-based ANN had achieved a correlation coefficient value of 0.41 for SPI prediction.The hybrid wavelet-ARIMA-ANN models gave the R2value of 0.872 for SPI.Malik et al.[153] used Effective Drought Index to predict metrological drought using the heuristic techniques,namely,the co-active neuro-fuzzy inference system (CANFIS),multi-layer perceptron neural network (MLPNN),and multiple linear regression (MLR).The monthly time series data lag was determined using the autocorrelation function and the partial autocorrelation function.The hybrid ANFIS algorithm’s performance was better than the classic ANFIS algorithm.Mohamadi et al.[154] captured the relationship between large-scale climate signals and drought indices using a wavelet coherence analysis.Hybrid soft computing models and wavelet coherence seem to be the appropriate tools for predicting hydrological variables. 5.1.5 Evaluating Our Model and Parameter Tuning The performance of the classification algorithm is measured using various evaluation metrics.This feedback on the model is needed to fine-tune the model by varying the algorithm’s parameters.The most commonly used performance measures are RMSE,R2,MAE,NSE,RPSS,and ROC.Mehr et al.[138] evaluated the forecasting model using Boolean statistics,namely total accuracy (TA),Kappa (KA),recall (RE),and classification error (CE). Fig.6 gives the details of the performance evaluation metrics and the number of papers using them. Figure 6:Performance evaluation metrics vs. number of papers The gradient descent and least square methods were used to tune the antecedent and consequent parameters in the ANFIS model.The gradient descent method was used to assign the nonlinear antecedent parameters,and the Least-squares method was employed to identify the linear consequent parameter.The number of iterations taken for the correction of the model parameter was 30 [80].All coefficients of the linear membership function were estimated using the Least Square Technique from the datasets.Using the Bayesian regularization (BR)[74],ANN automatically assigned the optimum values for the objective function’s parameters. Sattar et al.[112] discovered the probabilistic relationships between the meteorological droughts intensity and lag time.There was a higher probability for longer lag time for moderate intensity,whereas there was a lower probability of longer lag time for severe intensity.The Meteorological drought indices,at the same intensity,also impacted the probability of lag time.The probability of lag time occurring was higher in SPI and lowered in the case of SPEI.Using ESP and metrological drought data,the Bayesian model found the hydrological data more accurate than ESP and Dynamic methods.So et al.[155] Modified Surface Water Supply Index(MSWSI)was used as an index in hydrological drought forecasting.The topographical and hydro-meteorological characteristics of South Korea were used.Further,this work depicted the hydrological drought better by using precipitation,river discharge,and dam inflow during 3-month periods.Global Seasonal Forecast System version 5 (GloSea5)and variable infiltration capacity(VIC)model was used in the forecasting framework,and the testing was done for the 2015-16 drought event. A massive amount of historical data is needed to train and develop the ML model.The data unavailability will reduce prediction accuracy.The challenges are the need for high-resolution images without cloud contamination for the models collecting the data from satellite images.Supercomputers are required for the weather forecasting process.The earth is a vast,complex system.Hence it requires a high-resolution monitoring system. Prasad et al.[98] suggested deploying an IIS-W-ANN optimization algorithm for drought forecasting.Further,they suggested that this model’s performance could be improved by finetuning the hidden layer weights and biases.Ozger et al.[108] suggested that future researchers should work on the estimation of soil moisture from PDSI.Mehr et al.[109] devised a model to determine the drought using other climatic indices and analyzed the effect of various wavelet functions in optimizing the model.Kisi et al.[102] also suggested working with other DWT algorithms like the Trous algorithm for enhanced drought forecasting.Borji et al.[93] suggested using a genetic algorithm and multiple regression in pre-processing.Further,it was stated that the detected SST/SLP cells [129] are a future study area to investigate other climate events’impact.Woli et al.[80] established the use of climate indices as a predictor.Ali et al.[146] studied monthly SPI prediction for three agricultural stations of Pakistan using the committee-based extreme learning machine (ELM)and insisted on future researchers working on an adaptable decisions support model. Dikshit et al.[147] had pointed out that a detailed study on the effect of variables on the spatial scale is needed.Khan et al.[152] suggested studying the application of coupled wavelet-ANN-ARIMA models for hydrological drought prediction with different lead times is required. This paper’s extensive literature review found that the drought indices used in prediction and ML algorithms applied are the primal factors in drought prediction.An archetypal portrayal of the ML-based operational model for drought forecasting is shown in Fig.7.Further,this figure demonstrates various constituents that aids in improving the performance of attaining precise drought forecasting outcomes.A single classifier was used in most articles,and the multiple or hybrid classifier usage looks minimum.Also,the usage of multiple drought indices for prediction seems to be a practical solution. Figure 7:An archetypal portrayal of machine learning (ML)-based operational model for drought forecasting Further,the model can be devised appropriately using multiple drought parameters and obtaining the prediction’s efficiency with a hybrid classifier.For instance,four drought predictor values can be calculated.Based on the four parameters’values,rules are created by the rule-based classifier,and drought severity can be predicted.The indices used for finding the drought severity are SPI,Aridity anomaly,PDSI,and NDVI.The record from 1950 can be used in predicting the values of the indices.The indices are considered as features for classification.Based on the output,the rule-based classifier unit sets the rules,and the output gets determined.Instead of using a single classifier,multiple rule-based classifiers can be used in prediction.So each classifier in the multiple classifiers units would give an output prediction.A fusion algorithm might be required to finalize the best from the multiple outputs.The fusion algorithms like the major voting or Dempster Shafer approach can predict the final output.The drought severity output can be measured in three levels Low,Moderate,and severe.Moreover,satellite or in-situ data shall also be incorporated for improving meteorological and hydrological drought forecasting. Drought is a very complex natural hazard for forecasting and handling.It is well understood from the review that many factors influence the drought forecasting process.There are numerous drought indices,including climatic and oceanic factors,the forecast’s leading time,pre-processing climatic data with a wavelet,and other transforms.Also,there are several ML techniques for drought forecasting.When comparing the direct and recursive models,it is seen that the direct models perform well at SPI’s longer time scales and recursive models at shorter time scales.Shirmohammadi et al.[82] proved the exemplary performance of wavelet ANFIS methods with SPI.Prasad et al.[98] achieved the minimum RMSE value of 0.201 using ANN,and HMM [116]had the maximum RMSE of 0.852.Kaur et al.[156] got a maximum prediction accuracy of 95%with ANN-GA.The RMSE value for SPEI prediction done by Park et al.[124] using ANN was 0.338 and by Tian et al.[106] with SVM was 0.429.In Hosseini-Moghari et al.[90],R2values of direct MLP,RBF,and GRNN are 0.627,0.601,and 0.619; for recursive,the R2values are 0.588,0.563,and 0.598 a notable decrease with the recursive method was found.Bayesian model for PHDI got an RPS score of 1.744.The wavelet ANFIS and ensemble-ANFIS [157] are some of the superior models for drought forecasting.Machine learning models with Neural Networks give their best output in forecasting [158,159] and time series analysis [160].The Deep learning methods success in other applications is proved well [161]. Drought is a natural hazard,extremely complex to forecast and handle.The paper critically reviews the drought indices like climatic and oceanic factors,the forecast’s leading time,preprocessing climatic data with a wavelet,and other transforms and ML techniques for drought forecasting.Many factors influence the drought forecasting process.The direct models perform well at SPI’s longer time scales and recursive models at shorter time scales.Many studies successfully used wavelet ANFIS.The paper also explains the fundamental concepts of the drought,its types,and its impact.This review paper can be a brilliant resource for researchers in drought forecasting and mitigation.It elaborates the drought indices,ML algorithms for drought forecasting,and the geographical area of their application in various studies. As future work,a more comprehensive and extensive review of ML techniques for drought forecasting is proposed especially reviewing feature selection,feature extraction,and dimensionality reduction methods.A tool can also be developed for drought forecasting professionals to decide the most suitable approach based on the available data and accuracy.Furthermore,benchmark datasets can be made available as open-source to evaluate the performance of various ML techniques for drought forecasting. Funding Statement:The authors received no specific funding for this study. Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
3.6 Pearson’s Correlation Coefficient

4 Review on Machine Learning(ML)Methods Used in Drought Forecasting
4.1 A Short View of ML Algorithms Used in Drought Forecasting



4.2 Drought Forecasting Using Artificial Neural Networks(ANN)
4.3 Drought Forecasting Using Support Vector Machine
4.4 Drought Forecasting Using Fuzzy Logic
4.5 Drought Forecasting Using Markov Chain(MC)Model
4.6 Drought Forecasting Using Deep Learning
5 Review Findings
5.1 Review Findings Based on ML Model


5.2 Findings on Hydrological Drought Forecasting
5.3 Drawbacks of ML Algorithms
6 Future Research
7 Conclusion
 Computer Modeling In Engineering&Sciences2021年8期
Computer Modeling In Engineering&Sciences2021年8期
- Computer Modeling In Engineering&Sciences的其它文章
- A Knowledge-Enhanced Dialogue Model Based on Multi-Hop Information with Graph Attention
- MRI Brain Tumor Segmentation Using 3D U-Net with Dense Encoder Blocks and Residual Decoder Blocks
- Multi-Disease Prediction Based on Deep Learning:A Survey
- Multi-Material Topology Optimization of Structures Using an Ordered Ersatz Material Model
- Intelligent Segmentation and Measurement Model for Asphalt Road Cracks Based on Modified Mask R-CNN Algorithm
- Stability Reliability of the Lateral Vibration of Footbridges Based on the IEVIE-SA Method