
中国管理科学领域热点主题识别与趋势预测
2021-08-21 10:57梁镇涛张羽帆武汉大学信息资源研究中心湖北武汉430072
中国科技论坛 2021年8期
余 辉,梁镇涛,张羽帆 (武汉大学信息资源研究中心,湖北 武汉 430072)
0 引言
随着国内外对科学知识的重视以及网络设施的进一步发展,科学文献总量愈发庞大并以指数级的速度增长,各领域的研究热点和前沿也随时代更迭发生变化。因此,从大量非结构化的学术文本中识别和预测学科研究热点的生命周期,特别是热点主题的浮现点,有助于学者把握当前领域研究方向、规划未来职业生涯,同时也有利于科研管理机构更精准、更合理地进行科研资金分配,从而更有效地提高国家的软实力。学科研究热点的走势和演化,是一个对研究主题生命周期中热度进行测度并量化的研究,直接对主题进行研究热点统计分析,忽略了研究热点本身的动态发展过程。而研究热点的生命周期曲线,有助于找到研究热点的浮现点、最高点和衰落点等重要转折点。学术论文是重要的正式学术研究成果展现形式,对学术论文研究方向的把握是呈现研究热点和分析研究趋势的重要方法。对文献或研究主题进行分类也有助于科学文献的检索,并且能更好地呈现学科和研究主题的走势及演化[1]。
目前学科热点识别有基于全文文本、主题、引文和关键词等粒度的方法,考虑到文献往往包含多个主题,采用更细粒度的分析方法能够更好地表达文献中主题的语义关系。其中,关键词是文献核心内容的高度凝练,能直观反映文献主题内容,目前已被广泛应用于学术文本的主题发现研究中[2]。为了识别国内管理科学领域中的热点主题并预测其发展趋势,本研究以国内管理科学重要学术期刊为数据来源,对作者关键词聚类形成研究主题,并根据聚类形成主题的热度,分别计算并比较以热度排序、达到一半频次年份以及达到主题浮现点年份3种排序下的主题研究热度增长判断,验证一半频次和睡美人主题浮现点 (d值)在研究趋势预测上的合理性,结合睡美人特征 (一半频次)和主题热度对主题进行分类,最后通过热点浮现点的识别,找出当前学科研究热点,以及热点发展趋势分析。
1 相关研究及理论
1.1 学科研究热点发现方法
早期研究通过分析单篇文献本身的影响力大小来对学科热点进行识别,如苏新宁基于CSSCI文献数据,通过文献的参考文献数量和被引频次等传统引文指标,对研究领域的影响力进行讨论[3]。此外,引用分析还包括共引分析 (同时被其他文献引用)[4]、耦合分析 (共同引用一篇或多篇相同文献)[5]和直接引用分析[6]等,通过多元统计分析方法把文献或期刊、作者、机构等研究对象的引用关系网处理后用便于分析的方式进行呈现[7],这是辅助科学发展过程和构建知识图谱的重要方法[8]。这3种方法都通过引用关系来对文献进行聚类,并以聚类中最关键的文献主题来确定这一类的研究主题[9]。黄文彬等借鉴传统引文分析方法,把关键词作为对象进行共引分析,并用网络分析和多维尺度分析方法进行检验,结果表明关键词共引分析聚类效果较好[10]。
共词分析是较为经典的内容分析方法之一,根据不同关键词同时出现在一篇文章中的情况建立其联系,目前被广泛用于领域主题之间以及主题内的研究发展与演化分析中[11]。唐果媛等在研究国内外共词分析时指出,在共词分析中关键词是主要的研究对象[11]。李海林等通过把共词矩阵转换为相似矩阵,结合时间序列分析方法对主题发现和演化规律进行探究[12]。高继平等人用词共现方法实现关键词的抽取并发掘热点主题[13]。吴健等参考Donohue[14]和孙清兰[15]对高低频关键词临界值的计算,对高频关键词进行共现聚类分析,得出深阅读领域的研究热点[16]。随着自然语言处理相关技术的发展,共词分析在社交网络和商业上也得到较为广泛的研究与应用[17]。
以引文为基础研究科学文献之间的关系网络、进展和演变可以有一个较好的时序继承依据,而在热点主题的发现上,用共现或引用的方法聚类时,没有考虑语义信息,在总结一类研究热点时,并不能很好地代表一类主题特征[18]。庄建昌等基于语义聚类方法,运用词向量构建出领域热点关键词模型[18]。张长宏等结合内容分析方法和引用分析方法,形成一个新的语义空间,得到了更准确的关键词聚类主题[9]。章成志等用TF-IDF算法进行主题词提取并用K-Means聚类对学科热点和趋势进行研究,减少了监测成本并提高了监测的时效性[19]。基于语义的聚类根据语义相似度来控制类别大小及主题相关性,提高了聚类结果的可解释性。
1.2 学科热点主题分类
早期研究热点主题方法大多都存在时滞问题,并且无法预测研究趋势。针对这一问题,学者尝试使用多种方法和判别指标对研究文献或研究主题进行分类,以预见可能出现的新兴热点主题。杜建等在研究睡美人和王子文献时基于被引速率把文献分为3类,即快速突破型、延迟承认型和被引速率低且总次数也低的文献[20];张靖雯等在此基础上以被引速率 (CS)为单指标,从小到大把文献分为延迟承认型、厚积薄发型、领先优势型和昙花一现型[21],如图1所示。

图1 单指标文献类型划分
根据 “鬼域”在主题发展研究中的应用[22],HU等依据近年来关键词出现频次和总出现频次双指标组合将热点划分为4类,即新热点、持续热点、非热点和鬼域[23],如图2所示。
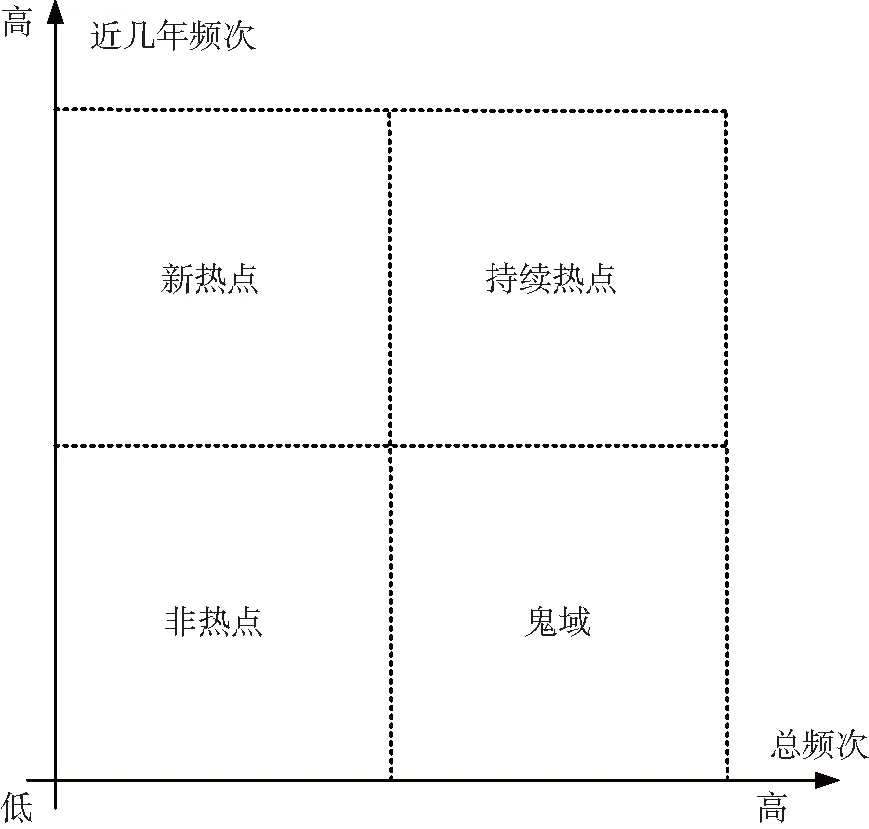
图2 双指标关键词热度划分
1.3 睡美人现象
引文分析是论文质量和学术影响力评估的一个重要方法[24],但学者在研究中发现被引数量和论文的质量、影响力并不是简单的正相关关系,高被引并非是论文高质量的保证,反之亦然[25]。这一问题与论文被引的动态过程相关,而被引的频次动态可以映射出文献在一系列引文中所对应的角色。
睡美人指的是科学中那些开始被忽视后来被大量引用的文献,Raan给出了最早的主观定义,即年均引用量小于等于2的时间大于5年,在被大量引用后,4年累计被引用超过20次[26]。该方法随后被学界广泛使用并加以改进,如Ke等基于被引时间和次数提出的客观指标方法,该方法不需要设置时间和引用次数等主观阈值[27]。此外,有学者提出曲线拟合法,基于年度引文次数构造时间序列数据,识别文献的引用轨迹[28]。上述研究的核心思路是识别早期被引次数较少、但在某个时间节点后突然大量增加的文献。这类文献的价值在早期没有得到重视,但往往在一段时间后被发现具有重要科学意义[29]。
在睡美人文献的被引变化过程中最重要的是被引量激增的时间点,即被引次数突变点。在该时间节点之后,文献的价值和热度开始快速增加,并很快成为高引论文。本研究借鉴睡美人文献及其被引次数突变点的识别方法,尝试识别研究主题成为研究热点的浮现点,即表明研究热点会有一个增长的趋势。睡美人现象中,强调了两个特征:①对 “沉睡”时间长度的要求,文献需要保持较长时间的低关注度状态;②对 “苏醒”的要求,需要有较大的苏醒强度,即在短时间内热度呈现陡峭上升趋势。在满足以上要求后,即认为该文献属于睡美人文献,且在将来会有一个热度增长。从睡美人引言曲线可知,满足睡美人特征的文献在苏醒点后的一段时间内会有一个热度快速上升的过程。本文认为,当主题满足睡美人的特征时,也会呈现这样一种热度上升的趋势。
三指标识别法分别从沉睡时长、沉睡次数和苏醒强度3个方面对睡美人特征做出要求[26],这在学界得到广泛认可。其中,主题热度在过去几年可能有过上升和下降,称为全要素睡美人[30],这一点不影响本文的主题识别研究,即重点从沉睡时长和苏醒强度来对具有睡美人特征的主题进行识别和预测。
本研究中,总关键词频次可以作为苏醒强度指标,达到总频次一半所需的时长可以作沉睡时长指标,结合这二者对聚类主题进行划分,识别主题热度较大并且达到总频次一半耗时较长的主题为具有睡美人特征的主题,并认为此类主题未来有一个上升趋势。从这一思路出发,本研究首先对收集的文献进行聚类以表示研究主题,在验证达到一半总频次时间在趋势预测中的作用后,通过对这些主题聚类的睡美人特征的强度计算划分主题为4个类别,再对4个主题类别的发展趋势进行分析,找出未来热度会上升的主题类。
2 研究方法
2.1 研究思路
本文研究思路可以分为数据准备、研究过程和研究结果3个部分。在数据准备部分,主要介绍文献数据的来源以及关键词的选取方法和理由,并对关键词进行聚类,聚类结果是本文研究的热点对象;在研究过程部分,首先分析聚类识别热点主题与关键词分析主题两种方法的特点,并说明本文选取聚类方法的原因;然后对数据集进行拆分,判断主题类别是否增长,根据热点热度、一半频次年份以及最大d值年份降序排序画出累计增长数折线图进行对比分析,验证一半频次年份和最大d值在主题增长趋势预测上的准确性;在研究结果部分,结合睡美人指数对统计信息进行分析,找到聚类热点主题整体特征、热度以及睡美人特征强度 (即一半频次年份)等,并通过热点主题的总频次和睡美人沉睡时长来进行热点主题的分类。热点发现研究流程如图3所示。
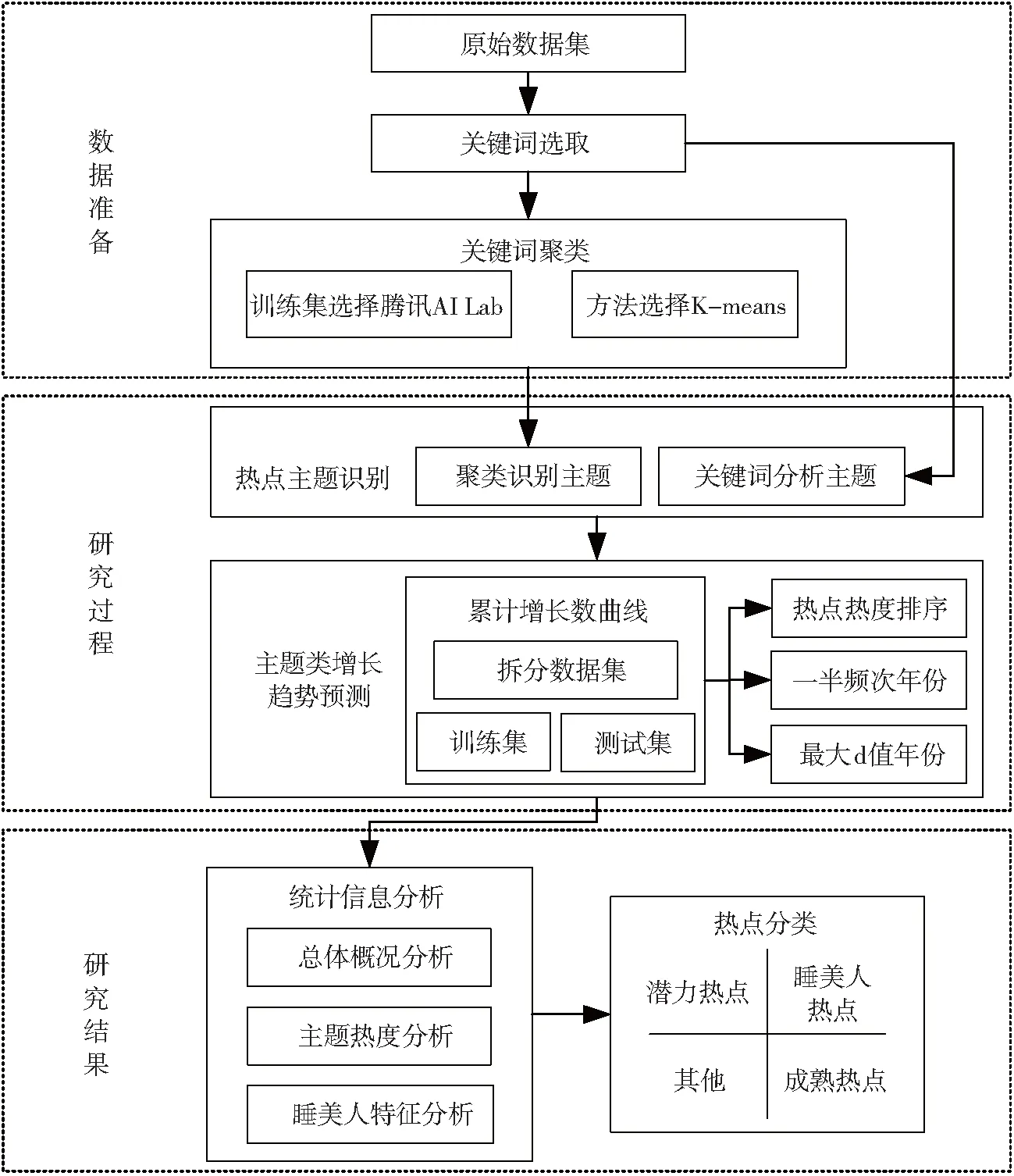
图3 热点发现研究流程
2.2 数据准备
本研究对国家自然基金委指定的30个管理科学重要学术期刊做热点发现分析,对以下30个期刊进行检索,以期刊近20年收录的文献为研究原始数据来源,检索时间为2019年7月15日,具体期刊列表及类别见表1。
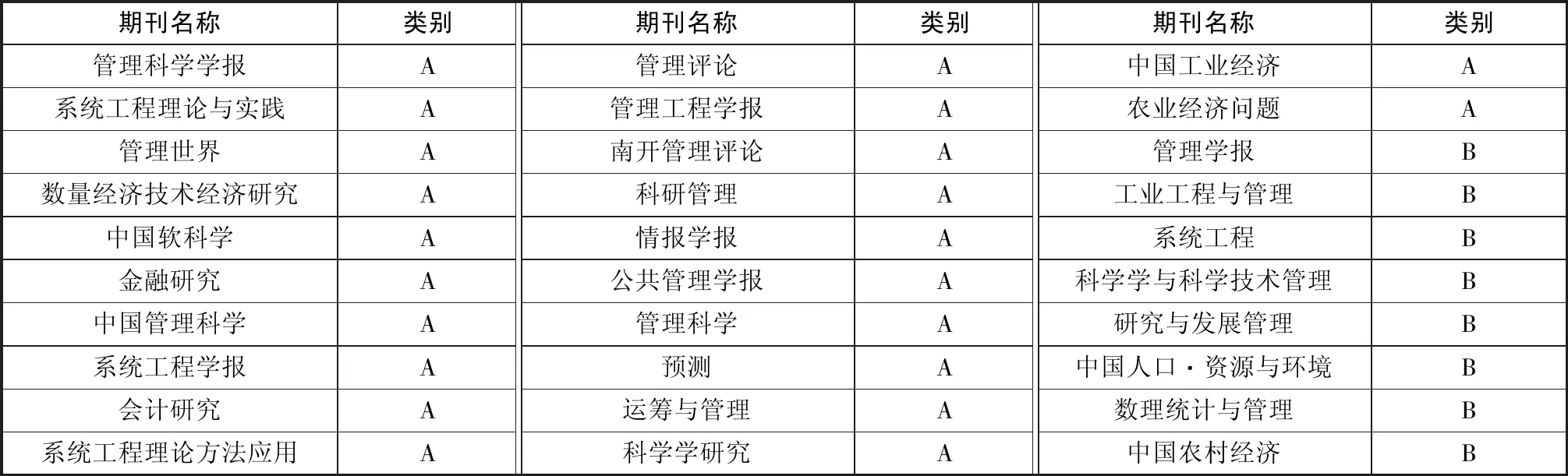
表1 NSFC管理科学重要学术期刊表
为了使研究更具现实意义,核心期刊应该是文献的主要对象,而中国知网的核心期刊收录率为99%[31],并且在刘振华的实证研究中,数字资源使用排名第1位的也是中国知网[32]。据此对所选文献进行筛选,去掉少量英文文献及一些不适合处理的文献,最终选取文献61509篇。相较于从篇名和摘要中抽取的关键词,作者关键词能够反映研究者对文章研究主题的归纳,在表达核心主题上的效果更好。因此,本研究选取作者关键词为研究对象,处理后以95165个不同的关键词为聚类分析的初始数据。
2.3 关键词聚类
本文通过对关键词进行语义聚类来提取研究主题,即把所有关键词聚类并提取主题关键词或主题词,认为这一类关键词所涉及的研究属于同一个主题,同时聚类形成的主题用于下文对比直接用关键词进行热点分析。基于语义特征的聚类体现了主题中的语义信息,其结果具有更好的可读性,有利于对研究方向的理解。聚类训练集选取腾讯AI Lab公开数据集,具有权威性,应用词向量方法进行词相似度计算,避免文献之间的共引或共现等方法无法对聚类结果进行解释以及热点主题提取[33]。对关键词聚类的效果会直接影响热点发现方法的适用性,在聚类方法中DBScan不需要指定类别数,从而类别数与类成员都具有一定的随机性;AP计算耗时长,有其他参数要调整,不适合扩展到其他领域或更大数据量的运算中。所以聚类选择K-means方法,结合改进的手肘法,并进行多次聚类对比来选取恰当的聚类数k,以便睡美人指数能应用于聚类后的结果进行热点浮现点的识别,如图4所示。
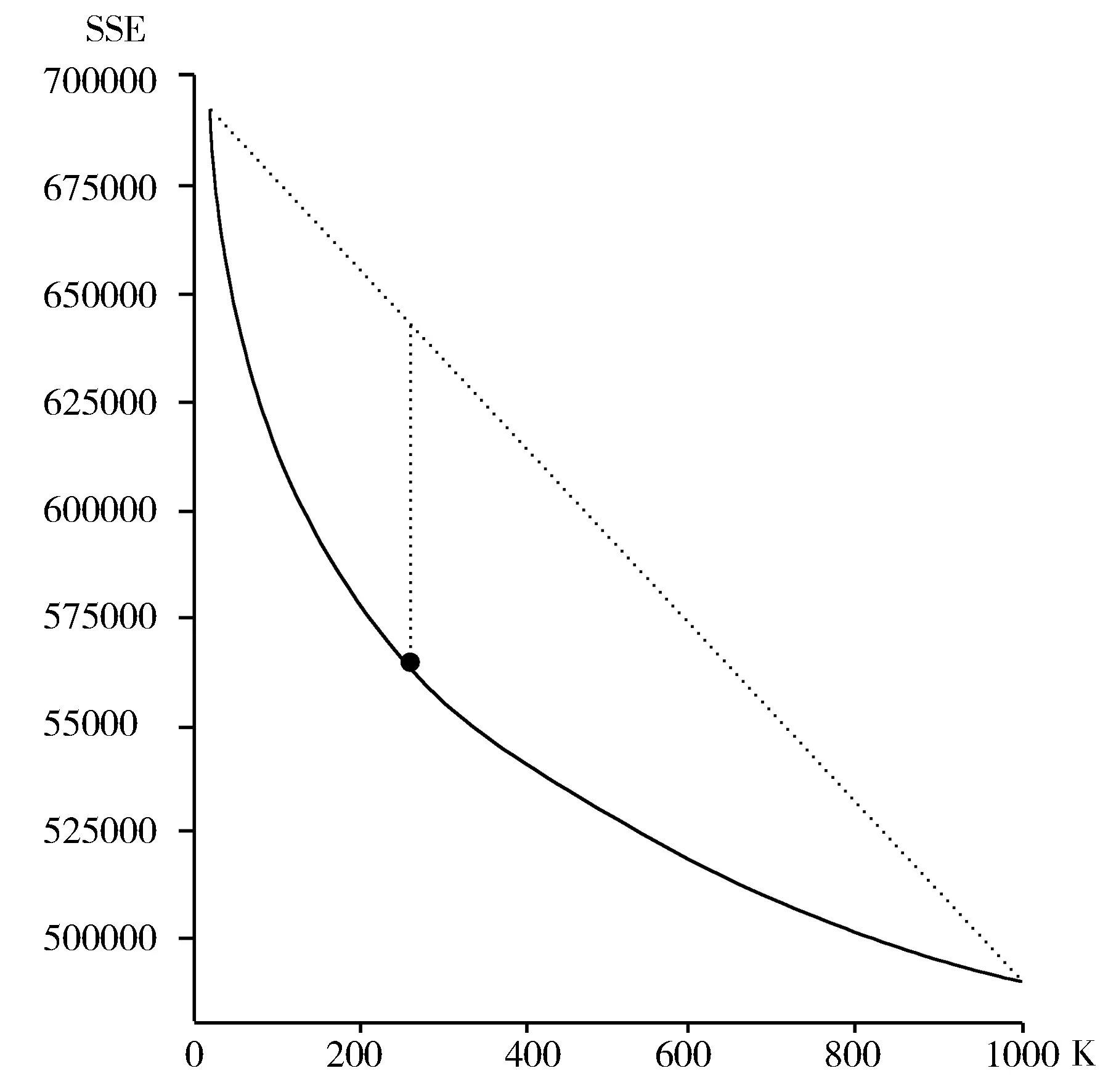
图4 改进手肘法求k值
由图4可见,由于k值较大,曲线整体上比较平滑,手肘法并不能直接得出一个合适的k值。吴广建等在研究K-means自动获取k值方法中把手肘图的起点和终点相连,计算这条线到SSE曲线的的纵向距离,并以距离最大点的横坐标为k的最终取值,提高了k值的选取效率[34]。
3 研究过程
3.1 关键词分析热点主题
为了更直观地观察对比20年间的热点主题强度,本文绘制关键词的词频云图,词的字体大小即词频高低,筛选出词频最高的100个词后,生成的词频云如图5所示。

图5 Top100关键词云图
由图5可见,影响因素、创新、经济增长等相关领域在20年间热度较高,这些与聚类主题热度排名基本吻合,因素分析 (影响因素)和创新能力 (创新)在主题热度上分别排在第5位和第6位。供应链在图5中是热度最高的,但从对主题的热度排序来看供应链排在第16位,即直接用关键词进行热度分析的结果与聚类后主题进行热点分析有一定差别。直接用关键词作为主题,会使主题数量过多且冗余,多个意义相近的关键词作为独立的主题存在,并且个别关键词的使用频率远超其他词,也使进一步分析更加困难。在当前研究中关键词词频超过700的仅3个,超过100的仅161个,不到总关键词95165的千分之二,这些关键词并不足以代表整体研究方向。
主题聚类中可能存在长尾效应,即那些与主题相关的单个关键词词频较低,但是数量极大,这影响了直接用关键词进行热点分析的结果准确性,如主题类 “人才企业”,关键词进前40的仅有2个,超过100词频的关键词仅有6个,但有463个关键词属于这一类别,主题类别热度排第1位;关键词 “供应链” (单个关键词词频为792个),代表的主题类包含385个关键词,热度排名16; “经济增长”关键词词频排名第6 (单词频506),但在主题聚类中,包含94个关键词,总词频排名为121,在260个聚类结果中处于中间位置。
综上,直接用关键词作为研究热点的分析可找出热点关键词,在较为成熟和规范的研究主题上有一定效果,但无法完全代表热点主题方向。此外,当新热点主题并没有形成较为统一的用语时,该方法容易忽略掉这一类研究主题方向。
3.2 聚类识别热点主题
用聚类结果进行热点主题识别就是把主题聚类按热度降序排序,可以说明当前时间这类主题是研究的热点,而随文献量增长使期刊文献的迟滞性现象更加普遍,此方法得出的热点主题只能代表当前时间点的前一段时间,无法预测未来研究热度的趋势。人才企业、因素分析和创新能力3个主题热度排名靠前的主题类随时间的频次变化,如图6所示。
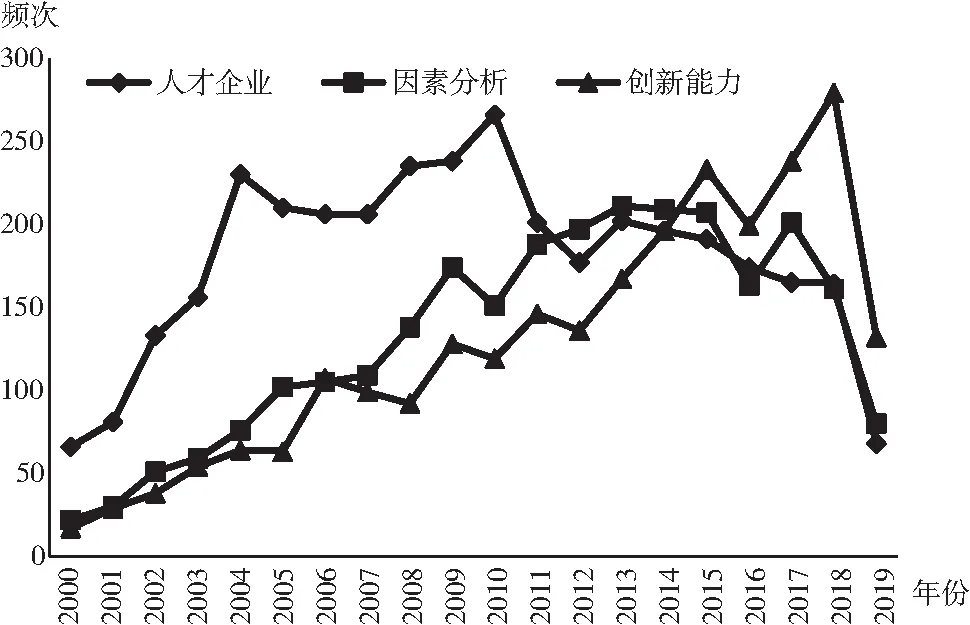
图6 热点主题频次变化
由图6可见,在聚类后主题中排名第1位的主题类 “人才企业”,在2010年达到最大热度后,在整体论文基数不断增长的环境中,研究热度一直在下降;主题类 “因素分析”和 “创新能力”总热度相近,但 “创新能力”呈现出不断增长的趋势,而 “因素分析”处于平稳期。总频次较高的主题可能是较早的研究热点,随着研究的成熟或是技术的更迭,此主题类已经不再是研究的热点;总频次较低的研究点可能是刚浮现的研究点,正处于快速上升时期,未来可能成为研究热点,所以不考虑时间因素的聚类总频次代表的热度也并不能很好的说明热点主题的现状或者是将来的发展趋势。通过以上分析,本文考虑了单个关键词作为研究对象的不足,在主题划分中加入时间因素,能较好地对主题发展趋势进行识别和预测。
3.3 睡美人特征主题浮现点计算
主题浮现点的计算有利于对研究热度增长趋势的分析,根据睡美人指数的意义,引文苏醒后,会有一个强势上升期,即本文得到热点苏醒后认为本主题会有一个上升期,但目前处于自身生命周期的哪个阶段需要进一步判断。在对睡美人特征主题进行识别后,可以精准地用睡美人指数处理方法寻找热点的浮现点,即睡美人的苏醒点,有助于更精准地分析和预测睡美人特征主题的发展趋势。目前公认最科学的方法是美丽系数识别法[35],它不依赖于主观判断,只和实验时间点有关,即最大值是否因时间发生变化,如果当前时间点为最大值则可能该主题热度仍在持续增长,如果热度基值较大,则可以直接判断该主题为未来有一个热度持续期。如果当前时间不是最大值,则需要进行下一步计算热点浮现点。先把识别出来的睡美人特征主题按年份变化列出频次变化表,以时间为横坐标,频次为纵坐标把该主题的散点图,连成折线图,如图7所示。找出最大值即图的顶点和起点的坐标,并将这两个点用线段连接起来,并计算出各点到此线段的距离,找出最大距离d值,此点即为要寻找的主题浮现点。设当年主题词定位点坐标为P (x0,y0),起点和顶点的连线L如公式 (1),P到L的距离如公式 (2)所示:
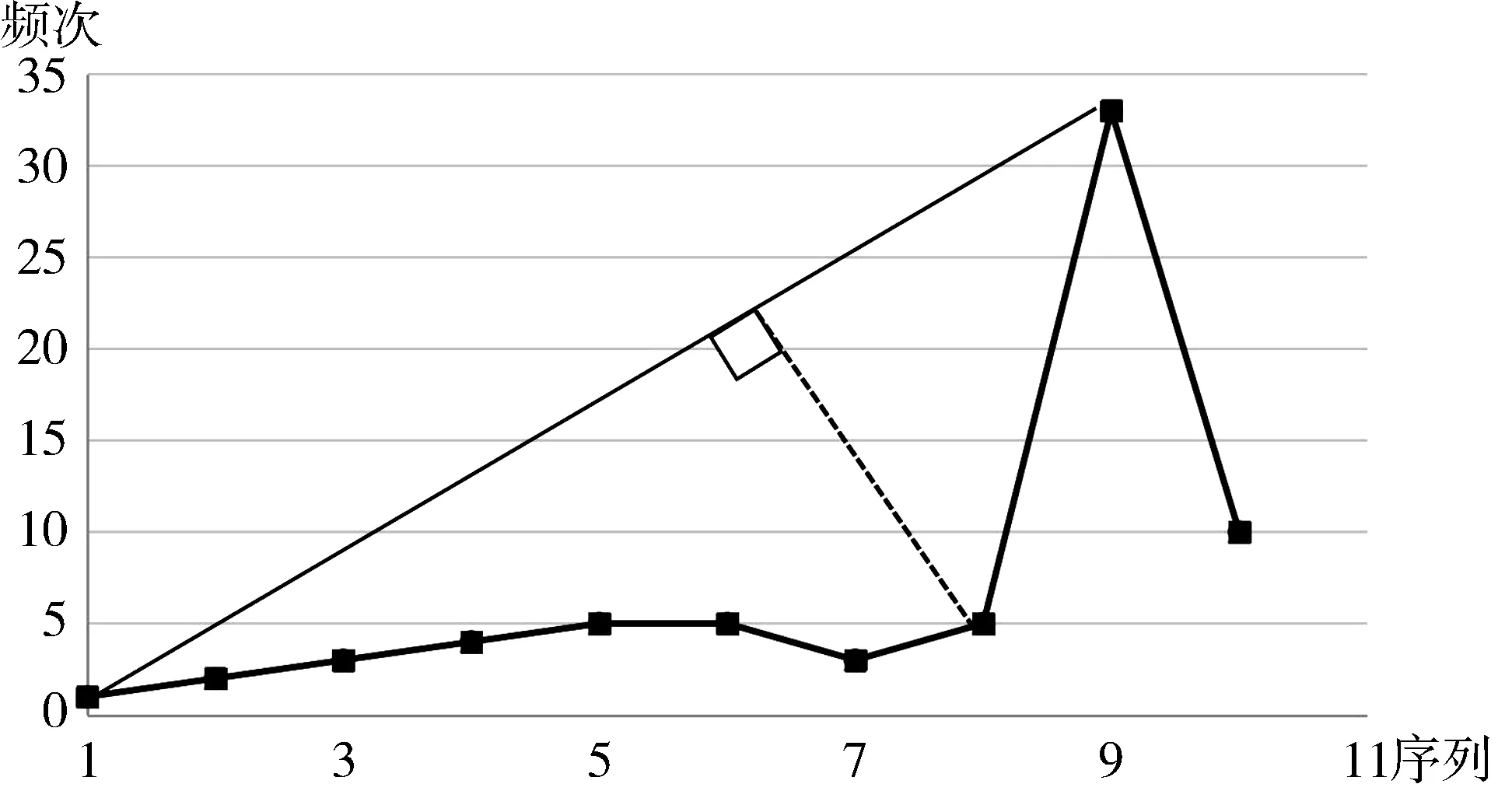
图7 美丽系数求浮现点示意
L:Ax+By+C=0
(1)
(2)
从数学特性可知,当横坐标以连续年份 (2010、2011、2012)为数轴标签时,d值结果与横坐标为连续自然数 (0、1、2)没有区别,即可看作是图形在横坐标方向进行的整体平移,如图8所示。以一年或者两年,或者是每个月为横坐标间距,会使得横坐标等比变化,d值大小会发生变化,但相对大小不会改变,即横坐标的起始值大小以及间距大小不会影响d值的相对大小。这使得该方法在计算距离寻找热点主题浮现点时不受主观时间划分参数的影响,提高了方法的准确性。
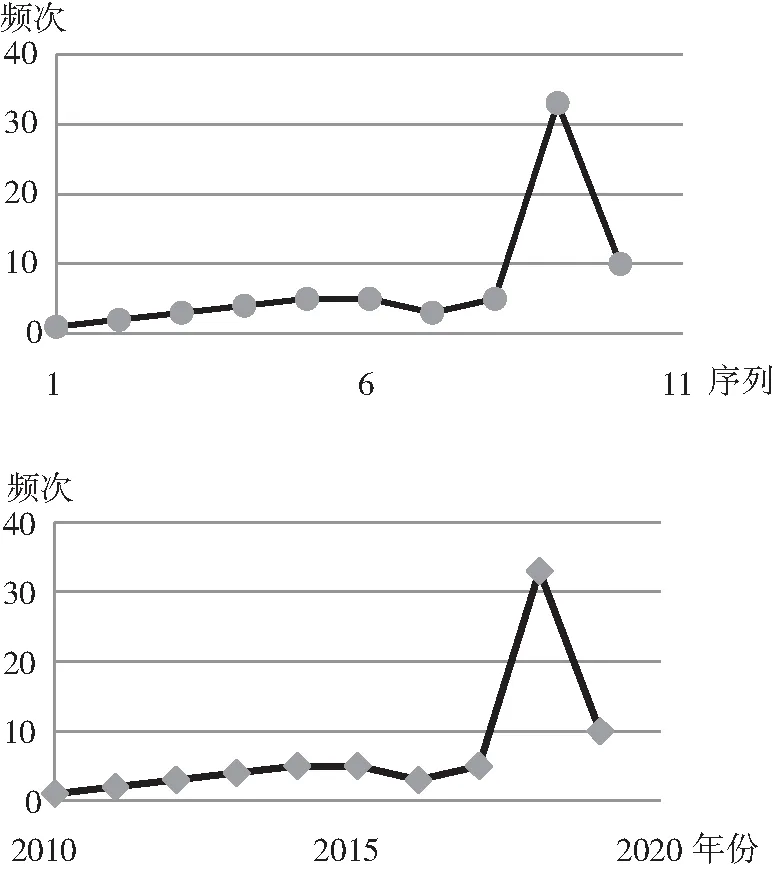
图8 横坐标不同大小及间隔比较
3.4 主题类增长趋势预测
由于词频形成的热度缺少时间因素,无法对趋势进行预测,本文借鉴睡美人理论思想,分别用各主题类达到总词频一半词频的年份以及睡美人中美丽系数产生的距离d值来预测主题类研究热度是否会在未来增长。本研究把数据集分为前15年和后5年,用前15年的数据进行分析预测,并取每个类别对应的后5年的热度均值作为是否增长的比较标准,由于文献数据整体数量变化,所以最终实际比较的是单个类别占总体类别的比例大小变化。用前15年的数据的热度、一半频次年份、最大d值年份3种方式的倒序排序,3种排序下增长的主题类别累计计数如图9所示。其中,横轴为主题类数,纵轴为累计增加主题类数,本数据中总增长主题类数为117类。
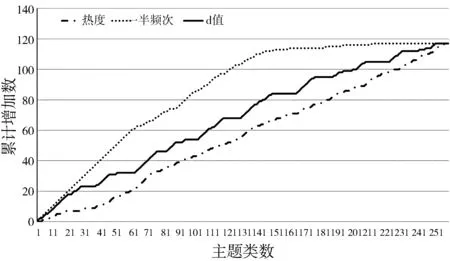
图9 累计增长类别数变化
由图9可见,在以热度降序排序中,累计增长总体分布较为均匀,所形成的累计曲线近似直线,即表明之前的累计热度无法对热度增长趋势进行预测,研究热度增长与之前研究总热度无明显相关性。一半频次曲线和d值曲线在前20个类别中,基本是全部增长,预测较为准确;在0到60类别之间,以一半频次为降序排序的预测准确,并且在112个类时达到80% (93个主题类)的增长类别覆盖。从3条曲线对比可知,在预测主题热度是否增长上,以一半频次降序排序效果明显优于直接用热度和d值。而从原理上分析也不难得出一半频次是中时间是主要的依据,而d值综合考虑的时间和增长幅度,在前几名中预测效果较好,后期可以用来对增长程度进行比较分析,也验证了本文以达到一半频次时间排序划分主题类的正确性,并计算靠前类别的d值来分析增长程度的研究思路的可行性。
4 研究结果
实验过程的可行性得到验证后,本文对采集的20年所有数据进行研究热点主题分析,以及一半频次和d值计算,找出国内管理科学领域研究热点并对发展趋势进行预测。
4.1 主题识别结果
对聚类结果进行基本信息分析包括对结果进行主题热度变化图的绘制分析来帮助呈现文献主题的总体发展趋势以及一般生命周期变化;并把结果以表格形式展示出来,方便查看聚类结果的好坏;把聚类结果以云图形式呈现出来,能更直观地呈现热点主题。本研究聚类先取k值为260,聚类结果260个类,由人工检验聚类效果,并选取类名或者以单个或多个词作为类名,部分主题以及关键词输出结果见表2。

表2 部分主题及关键词频次结果
由表2可见,各类都有一个较集中的主题,聚类效果较好。各主题类可以根据总词频来判断本类主题在研究中的热度,前20主题按热度 (总频次)排序结果见表3。
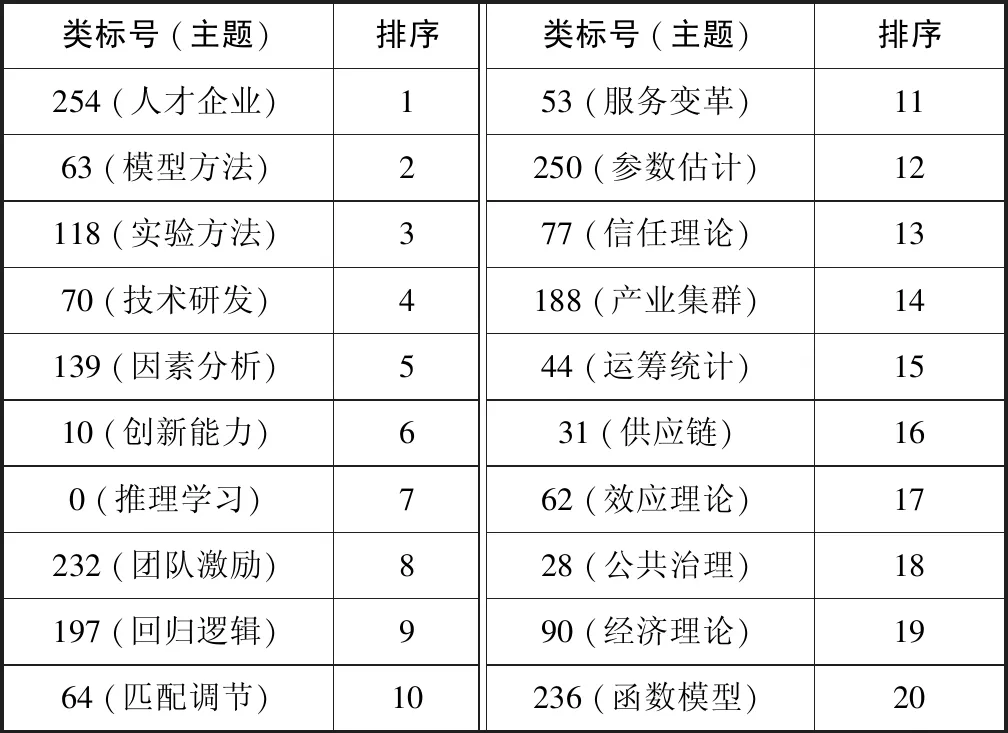
表3 Top20聚类主题热度排序
4.2 热点主题趋势分类预测
(1)主题整体研究热度变化。所有聚类结果的总频次年份变化和以当年总主题频次标准化后的年份变化如图10所示。由图10可见,研究整体趋势是不断增长的,与标准化的图进行对比可知,这与文献数量有直接关系,即每年基础文献量的增长并不能说明所有主题的热度都在增加。从标准化后变化可以看到各种特征的折线都是存在的,大多数主题在20年间都处于低热度分区,少量主题出现大起大落,个别主题热度呈不断增长趋势,对各个不同主题进行分析和归类可以识别出热点主题和睡美人特征主题。
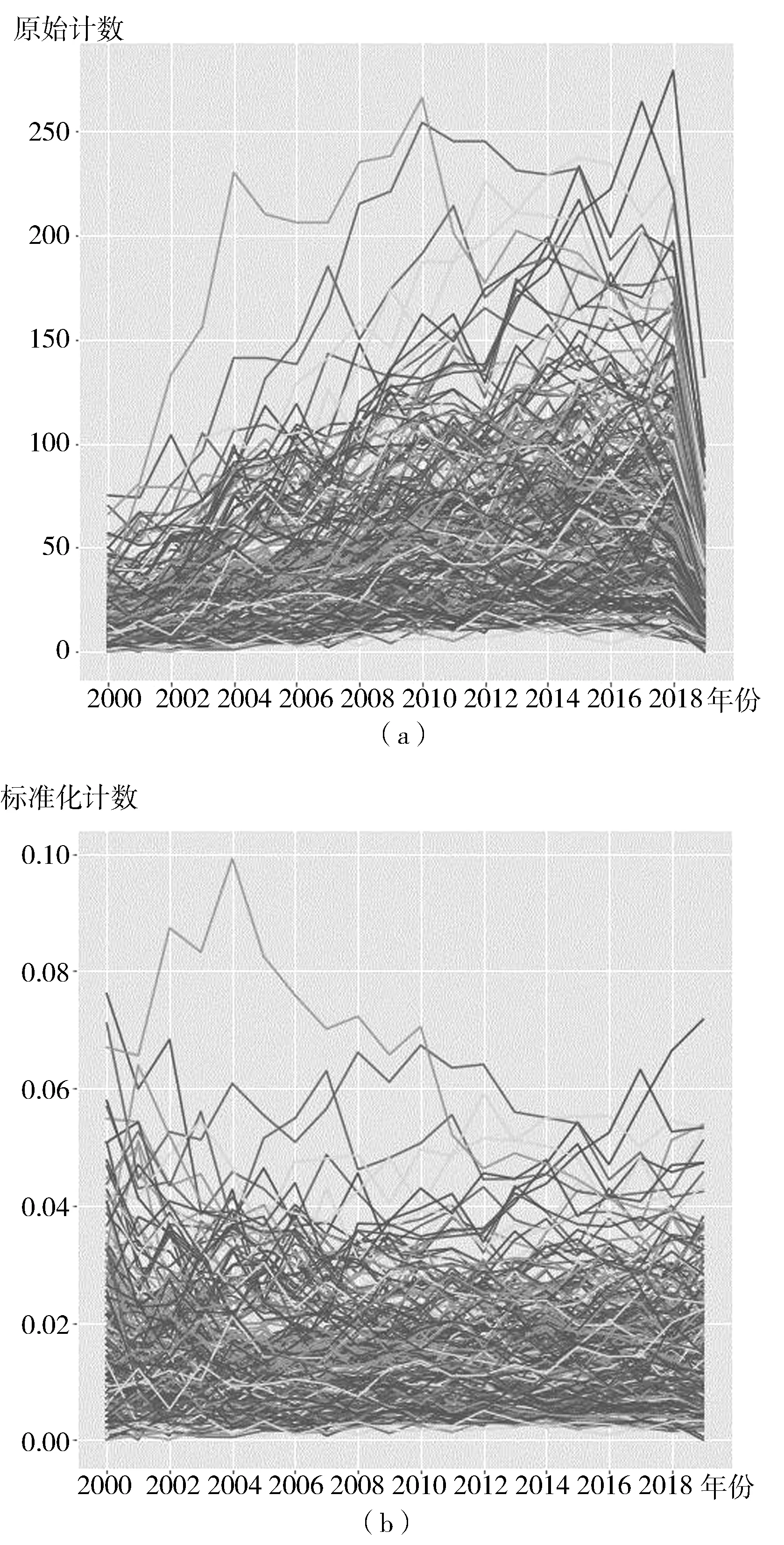
图10 聚类主题热度年份变化
(2)四分位数法划分主题。四分位数分布划分法在2010年被用于睡美人文献的识别,通过分析文献达到一半自身总被引次数的时长来找出那些 “沉睡”时间较长的文献[36]。本文借鉴此思想,在已经验证一半频次在趋势预测有效的基础上,先计算出各聚类主题累积频次达到总频次的一半时的年份,并以年份从小到大排序,即所需时长从小到大排序,并以后四分之一的时间点为标准进行比较。晚于这个时间节点的主题获得自身一半的频次的时间晚于领域内75%的主题,自身为睡美人特征主题的可能性较高。四分位数法得出文献主题可能较多,但可以锁定睡美人特征主题的范围[37],并且可以认为主题到达一半频次所需要时长越长,则睡美人沉睡特征越强。
在关键词分析中进行筛选高频词时,往往通过研究者经验直接进行选择,这样能很好地区分那些超高热度的关键词与热点,但是那些热点也可能是目前学界都已经公认了的,对未来研究的指导意义有限。Vaughan根据同频词理论的假设,提出了高低频词之间的拐点可以当作这个分界点[38],即研究可以用这个拐点来进行热点的筛选,但由于本文聚类结果较多,拐点并不明显,所以本研究热点热度的划分也采用四分位数法,把各聚类结果的总频次作为主题的总热度,并用这个热度进行从大到小的排序,选取前四分之一的主题为热点主题。
研究产生聚类主题260个,四分位数在65位上。根据计算到达主题一半频次的时间排序后,四分位点上的时间为2013年,取比2013年更长的时间,即超过13年的才达到一半频次的主题,一共有20条,并认为这20个主题都有足够长的沉睡时间特征。主题总热度频次按从大到小的排序后,第65个主题总频次为1272,即认为超过1272次的主题类别划分为热度较高的主题类。以热点热度 (总频次)为横坐标,沉睡时长 (苏醒时间)为纵坐标,两个四分位数的交点为原点 (1272,2013),以此建立坐标轴,将各个主题类划分在坐标轴的4个象限内,如图11所示。
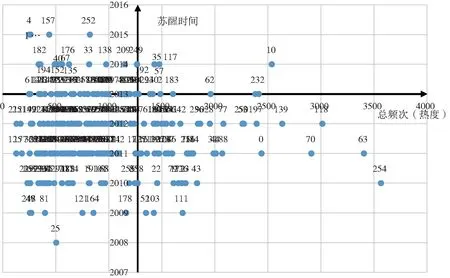
注:数据标签为聚类时自动生成类标号。图11 研究热点主题分布
由图11可见,右上分区为睡美人特征区,即热度较高和苏醒时间较长的主题分区,这个分区的主题特点是同时具备睡美人潜力和较高的累积热度,属于高热度的研究主题,且关注度可能会持续增长。右下方为成熟的研究热点区,区域内的主题具有较高热度,但其积累时间较早,在今后可能出现下降的趋势。但考虑到该类主题热度基数较大,并不会迅速失去研究关注度。左上方为潜在热点区,处于该区域的主题热度目前在领域内不高,但在近年来多处于热度快速上升期,在未来可能成为高热度的研究主题。左下方则是不存在睡美人特征且热度较低的研究主题,属于少数学者关注的研究范围。
4.3 睡美人特征主题分析
借助热点主题浮现点可以更准确地分析当前主题处于睡美人生命周期的具体阶段,以预测主题未来热度走势。本文对睡美人特征较强20个主题类 (睡美人热点和潜力热点两个分区内的主题类)进行浮现点的计算,结果见表4。
由表4可见,顺序为四分位数法中达到一半总频次所需时长降序排列,而这一结果与美丽系数法结果即表4中得出的年份并不吻合,可见进一步对睡美人特征主题进行苏醒点的识别的必要性。其中起始年份为2000年或2001年,即为数据收集的前两年,但由于数据量极小,在研究时间范围之前的起点数量更小,对结果的影响较小。
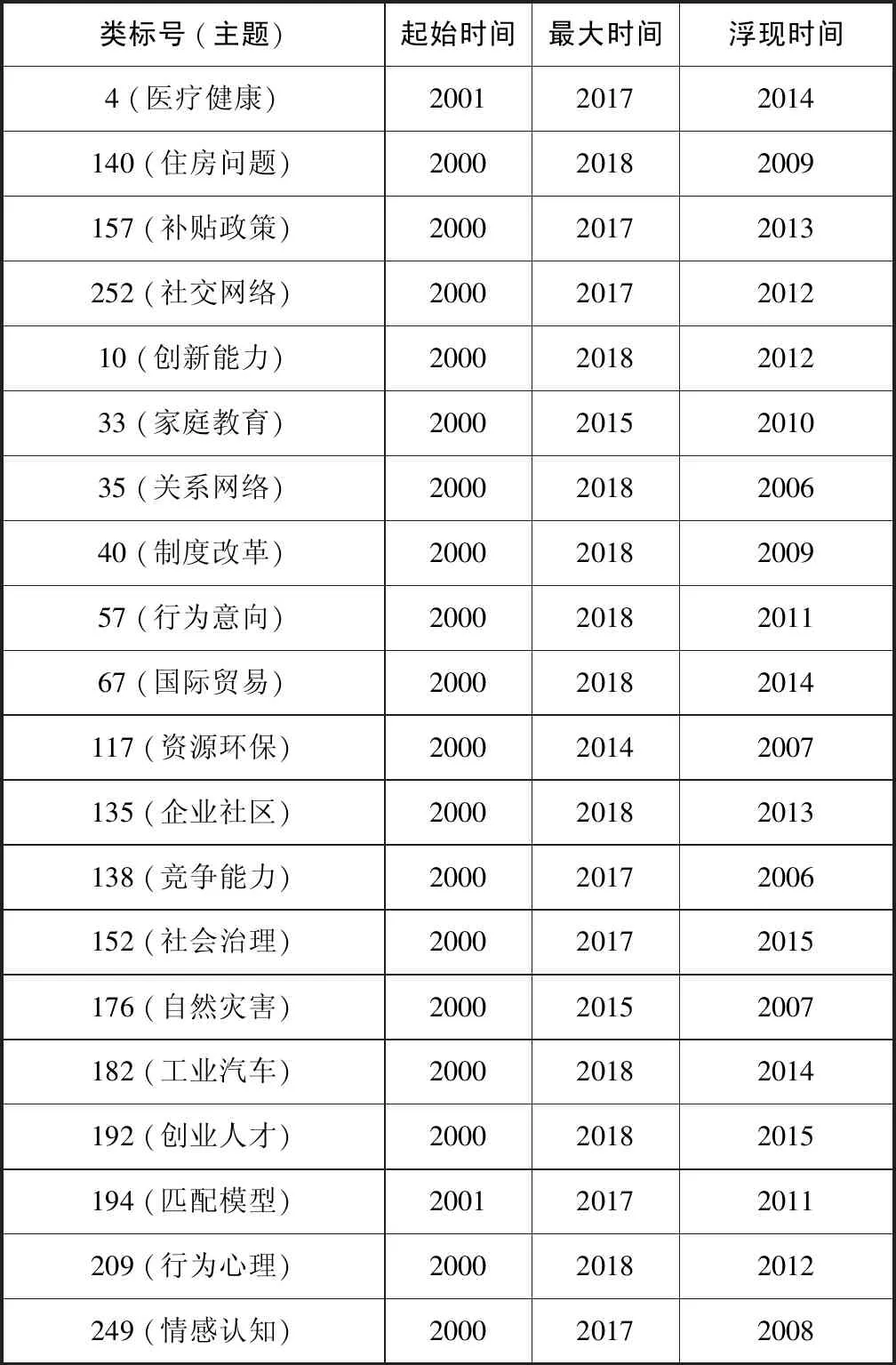
表4 20个睡美人特征主题浮现点年份
在这20个聚类主题中,住房问题、创新能力、关系网络、制度改革、行为意向、国际贸易、企业社区、工业汽车、创业人才和行为心理这10个主题在2018年达到最大值,即当前处于或未达到最大值点 (2019年数据未收录完整),其中创业人才、国际贸易、工业汽车、创新能力和行为心理5个主题类浮现点较晚 (2012年后),并且还未到达顶点,属于正在快速发展的研究主题,预测未来会有一个热度增长的过程。竞争能力、自然灾害、资源环保、情感认知、家庭教育和匹配模型6个主题类,主题浮点较早 (2011年前),并且也在2018年前达到自身热度的最大值,根据睡美人曲线接下来会有一个热度下降的趋势。
4.4 结论
在了解聚类基本信息后,结合主题区域分类结果和热点主题浮现点分析,对热点主题类进行研究热度发展趋势分析和预测,研究结论如下。
(1)创新能力、关系网络、行为意向和资源环保4个主题类属于睡美人特征热点主题,其中创新能力类主题类浮现点较晚,近年来增长速度较快,未来极有可能成为超高热度的研究主题。
(2)医疗健康、住房问题、补贴政策、社交网络、家庭教育、制度改革、国际贸易、企业社区、竞争能力、社会治理、自然灾害、工业汽车、创业人才、匹配模型、行为心理和情感认知这16个主题属于潜力热点主题,其中创业人才、国际贸易、工业汽车和行为心理4个主题类浮现点较晚,近年来增长速度较快,研究人员可以对这些主题方向进行研究,未来可能会有一个热度持续上升的过程,并很可能成为新兴热点。
(3)人才企业、模型方法、实验方法、技术研发、因素分析、推理学习、团队激励、回归逻辑、匹配调节、服务变革、参数估计、信任理论、产业集群、运筹统计、供应链、效应理论、公共治理、经济理论和函数模型等61个主题属于成熟热点主题,拥有领域类超过四分之三主题的热度。因此,要选定这些主题为研究方向的学者需要考虑到研究已经成熟或处于热度衰退期,是否还有研究的意义;正在从事此研究的学者要考虑研究方向是否需要转型。
5 结束语
热点主题的识别与趋势预测可以为相关研究者和机构提供研究方向的参考,本文将睡美人特征引入主题识别中,以关键词聚类为主题的构建基础,对国内管理科学重要期刊上的主题进行划分,识别出睡美人特征热点主题。对比关键词分析和主题聚类的研究热点识别结果,验证了睡美人特征 (一半频次以及d值浮现点)在预测研究增长趋势上的有效性,以及在预测主题未来发展趋势上的优势。
本研究也存在一定局限性。首先,本文未考虑多个关键词是否出自同一篇文献的情况,这可能导致直接统计频次时权重不均衡;其次,聚类认为一个研究主题包含多个关键词,但并未考虑同一关键词属于多个研究主题的情况。后续研究可对同主题下关键词是否来自同一篇文献进行判断并进行权重赋值,并考虑关键词同时属于不同研究主题的情况,综合分析主题的研究热度趋势。
猜你喜欢
工会博览(2023年3期)2023-04-06
儿童时代·快乐苗苗(2022年8期)2022-10-18
加油站服务指南(2022年6期)2022-07-28
车迷(2019年10期)2019-06-24
发明与创新(2019年43期)2019-03-25
快乐语文(2018年7期)2018-05-25
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
中国记者(2014年6期)2014-03-01
