
基于融合句法特征的翻译方法研究
2021-08-20 10:28刘晶
电子设计工程 2021年16期
刘晶
(陕西铁路工程职业技术学院,陕西渭南 714000)
机器翻译以高性能的计算机作为运算核心来实现不同自然语言之间的转换,在人工智能与机器学习领域中占据了较大的比重[1]。目前较为常见的机器翻译应用场景为一些互联网公司(百度、谷歌、有道等)提供的在线翻译服务,这些服务均可实现多种语言间的相互粗糙翻译。虽然这些翻译结果与翻译从业人员的翻译结果相比仍有差距,但在翻译质量要求较低的场景下,仍有较为广泛的使用价值。
到目前为止,机器翻译技术已经发展了几十年。虽然不断推出了各种算法模型,但机器翻译准确程度仍较低,无法替代专业译员。其中,最突出的问题为单词较多、句型结构复杂的长句、从句翻译效果较差[2]。在英语中,长句的结构成分较为复杂,除了主要的句子结构外还有各种修饰词、连接词等。此外,长句还可能会包含有一个以上的从句。从句之间的关系也有嵌套、并列及平行等组成方式,所以句法分析是长句翻译的必要前提[3]。因此,对长句和难句进行句法分析预处理是提高长句翻译质量的有效解决方式之一。
文中针对英汉机器翻译的长句翻译质量较差的问题,对长句进行算法训练与处理,将其分离成易翻译的短句进行组合翻译,进而提高机器翻译的质量。
1 英汉句法翻译方法
基于句法分析的机器翻译方法在机器语言翻译领域占据着重要地位,句法分析主要是对整个句子序列的成分结构进行分析。而机器会与句法库中的句式结构进行比较,进而对长句的句法进行判断后再进行翻译。机器翻译的最终目标是将源语言翻译成为高质量的译文,虽然对句子进行句法分析不是机器翻译的最终目的,但是句法分析却影响着机器翻译的质量。因此,句法特征分析也是诸多专家与学者极为关注的一项技术,近几年提出了众多关于句法分析的理论方法[4-6]。
目前,句法分析翻译方法大体可以分为两类:基于语言模板的翻译方法与基于统计学的翻译方法。
基于语言模板的翻译方法是最早关于语法翻译的技术方法,语言模板是指句子的表面特征,比如:根据句子的单词数量、句子标点的位置、句子所拥有的特征词汇等进行模板匹配,并在语料库中进行准确度匹配进而实现句子的翻译。基于语言模板翻译方法的优点是在句子模板特征较强时翻译最为准确,其不足之处是句子模板特征较弱时翻译不准确甚至无法进行翻译。
为了对基于语言模板的翻译方法进行改进,各地学者均进行了深入的研究[7-11],逐渐演变成为基于统计学的翻译方法。该方法可以使用机器学习的方法,对句子的弱特征进行大量的数据挖掘与特征学习,例如对长句的连词特征、句式特征及标点使用特征进行学习,这可以弥补模板匹配翻译方法中对句子特征匹配不全的缺陷。但基于统计学的方法也有自身的局限性,例如虽然在长句中可以通过挖掘句中逗号、连词、特殊句式之间的联系等处理方法解决基于规则方法的语言现象覆盖度不足的问题。但若句子本身标点符号或连接词数量较少,则基于统计学翻译方法的准确率也会下降。
因此,文中结合基于语言模板的翻译方法与基于统计学的翻译方法,提出了融合句法特征的机器翻译方法。
2 基于融合句法特征的翻译方法
2.1 句法特征模型建立
句法特征方法也称为依存句法分析或从属关系文法,其关注的对象是长句中各个单词之间的联系。在英文语法中,句子成分关系常见的有主谓关系、动宾关系、并列关系等。而在一个句子中,动词一般被看作是句子中的核心词,该句中的其他词与核心词均有直接或间接的关系[12]。
而对一个句子进行句法特征分析,分析过程通常使用一个有向图进行表示,如图1 所示。句子中的单词为一个个单独的节点,核心词与依存词的句法关系使用有向的箭头进行标示,在箭头的上方对其关系进行说明。
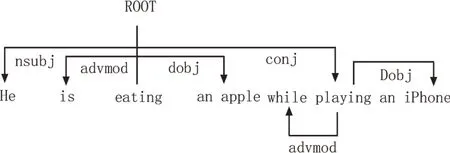
图1 句法特征有向图模型
而在文中所提出的句法特征模型中,其是按照单元进行存储,下面将建立句法特征单元模型。该模型直接将单词之间的句法关系存储到相应的句法单元中,单元构建规则如下:

式(1)中,Mi表示句子中第i个单词的存储句法单元,MPxi、MCxi、MBxi表示句子中第i个父节点单词、子节点单词及相邻节点单词的位置。
虽然句法特征模型可以对句子成分进行判断,构建的翻译模型也可达到较优的正确率。但由于模型本身的局限性,该模型不能够较优地学习句子的弱特征。因此仍需要在句法特征的基础上加入统计学的模型,以强化长句中各个单词的词义联系,从而进一步生成正确的结果。
2.2 基于条件随机场的统计学模型
在对长句进行切割的过程中,并不是任意长句均可被切分成为适当的短句。只有当切分出来的句子拥有独立的句法特征结构,才会认为对长句的切分是有意义的。因此,文中引入了条件随机场模型对长句中的词汇与逗号进行有意义的切分。在条件随机场的模型中,所有语料应适当的被其训练,进而判断语料集中的句子分割是否具有合理性。
条件随机场的从属分类为无向图模型,该模型具有最大熵与隐性马尔科夫链的特征,该统计学模型在自然语言处理领域中的应用较为广泛。其可将条件随机场定义为一个条件概率事件,用X代表观测序列集条件,用Y代表标记序列集条件,则条件随机场模型可以用条件概率P(Y|X)表示。下面根据统计数学模型对条件随机场进行定义[13-14]。
条件随机场的数学定义为:假设某无向图为T(V,E),其中V为各项顶点的集合,E为各边的集合。假设Y={Yv|v∈V},即顶点集合中的每一项单独元素均会有一变量Yv。设X为可满足Yv的条件,则变量Yv可以满足下式:
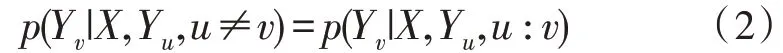
其中,u、v表示包含在图T中的两个顶点,则(X,Y)为一个条件随机场。该随机场的示意图如图2所示。
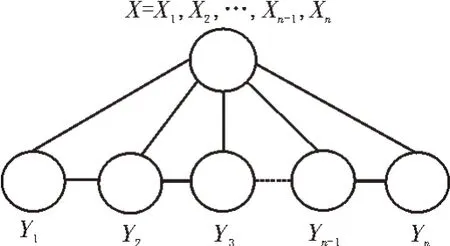
图2 随机场的示意图
而目前条件随机场模型的实现工具有多种,文中使用CRF 工具实现句子的标注及切分。
2.3 融合模型建立
由上文可知,基于句法特征的模型无法对句子的弱特征进行学习。因此,文中结合基于语言模板的翻译方法与基于统计学的翻译方法,建立基于融合句法特征的翻译模型。该模型可强化长句中各个单词的词义联系,进一步提升长句切割后的翻译质量。两种简单模型的结合方式使用并列执行的方式,即基于句法特征对句子进行分析;基于条件随机场对句子进行分析,进而得到两种长句切分方式。然后对这两种方式进行融合,融合方法包括合并、去重等。最终,在翻译引擎中进行翻译。模型的处理流程图如图3 所示。

图3 融合模型执行过程
图3 中,在使用融合句法特征模型进行句子切分前,首先要对条件随机场模型进行训练。模型训练过程如下:
1)选取语料集合并进行预处理,对语料中的句子进行前处理,包括重复句子的去除、句子特殊符号的去除等;
2)对语料集合中的句子进行特征提取,此时使用句法特征滤波器对句子进行成分分析与依存有向图的建立,随即完成对句子特征进行提取;
3)将句子特征输入至条件随机场模型中进行训练即可。
在模型训练完毕后,预处理模块中条件随机场的训练结果,会输入至分割过程中的条件随机场解码器中进行解码。同时与使用句法特征处理的句子进行比较处理,完成合并、去重等操作,最终将处理好的句子送入翻译模型进行翻译。
2.4 模型训练过程
文中模型训练脚本语言使用Python 编写,作为一种面向对象的编程语言,Python 以其简单、高效的特点被广泛应用于机器翻译与脚本语言中。相对于Java 或C++等语言而言,Python 效率更高,可以与其他语言编写的模块相结合。同时拥有丰富的第三方功能库,能够适应于多种编程需求。训练脚本的代码执行过程,如图4 所示。

图4 代码执行过程
图4中,第一行命令为依赖项的安装,包括Python版本的设置、模型的路径设置及训练模型的版本设置等。第二行命令为执行Fenge.py 脚本,该脚本的输入为语料集合,输出为长句切割后的准确率与召回率,同时将切割完毕的句子输出到下一条命令中。第3 条命令为执行Test.py 脚本,该脚本执行翻译引擎,对句子进行翻译,同时使用典型的翻译评价标准(BLEU 与NIST 分数)对句子的翻译质量进行评估。
文中训练脚本使用到的硬件设备列表,如表1所示。

表1 模型训练环境
3 实验仿真与结果分析
3.1 模型预训练
由上文可知,在检验模型翻译质量前,首先要对条件随机场模型进行训练。在自然语言处理领域,国际计算语言学协会年会(ACL)是该领域的国际顶级会议,而每年ACL 会议在官方网站会发布用于机器翻译的训练集。文中选择ACL2019 发布的新闻类型长句“News Crawl:articles from 2017”英语训练集作为训练语料集。为了更优地训练条件随机场模型,在语料集中仍要继续进行抽取。使用文中模型的目的是提高长句翻译质量,因此语句抽取规则为单词数量大于或等于15,每句逗号数量大于或等于1。则文中训练语料集,如表2 所示。
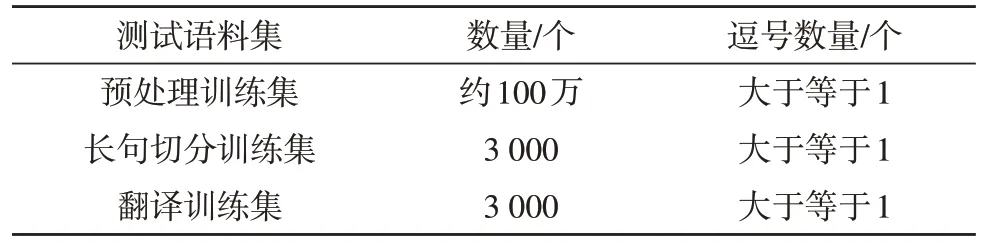
表2 训练集信息
3.2 模型训练结果
文中实验需要解决如下两个问题:
1)对长句进行切分处理后,使用模型还原切分前的长句,以验证模型切分的准确性;
2)对长句处理完成后,使用文中建立的模型训练,然后再对句子进行翻译,观察长句翻译质量是否有提高。
因此,文中首先验证长句,再进行合理切分,最终从上文提及的语料集中抽取了3 000 个长句进行训练。实验步骤如下:
1)使用句法分析工具对语料集中的长句进行句子特征提取;
2)删除长句中的逗号后,使用文中模型对句子、逗号进行重新添加,进而对比插入位置的准确率。表3 为切分合理性实验结果。

表3 句子切分实验结果
由表3 实验结果可以看出,使用条件随机场方法与使用融合句法方法对句子进行切分的准确率是大致相同的。但融合句法特征方法的召回率更高,这充分证明了融合句法特征方法对句子切分的合理性。
下面进行翻译准确度实验,对长句处理后,使用文中建立的模型训练,再对句子进行翻译,观察长句翻译质量是否有提高。实验使用Moses 作为翻译引擎[15],Moses 翻译引擎在使用前基于100 万个英语平行语料进行训练。翻译质量使用BLEU 与NIST[16]译文评价指标进行打分。BLEU 标准是用来评价机器翻译结果与人工翻译结果的相近程度,该标准使用便捷,比较接近人类的评分;NIST 标准是美国国标局建立的机器翻译自动评价体系。BLEU 与NIST 译文评价标准现已成为国际通用译文评价系统,因此文中使用BLEU 与NIST 对模型翻译质量进行评估。实验测试结果如表4 所示。

表4 翻译准确度试验结果
实验结果表明,文中提出的融合句法特征的翻译方法对翻译质量有大幅度的提升,BLEU 分数较单一地使用基于句法特征的模型与基于条件随机场模型更高,同时NIST 分数也有所提高。因此,文中提出基于融合句法特征的翻译方法对长句翻译质量有一定程度的提升。
4 结束语
文中针对英汉机器翻译的长句翻译质量较差的问题,提出了融合句法特征的机器翻译方法。对长句进行算法训练与处理,将其分离为易翻译的短句进行组合翻译。在实验测试中,对经过模型训练的句子进行翻译。实验结果表明,句子的BLEU 与NIST 值均有不同程度的提高,因此文中提出的模型对机器翻译的翻译质量有一定程度的提升。
猜你喜欢
中华诗词(2021年3期)2021-12-31
大连民族大学学报(2021年2期)2021-07-16
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
海外华文教育(2016年1期)2017-01-20
现代语文(2016年21期)2016-05-25
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
——意群—动态对等法
长春大学学报(2012年9期)2012-09-19
