
适用于便携式设备的深度神经网络眼动跟踪
2021-08-20 09:17:10王建华冉煜琨
计算机与现代化 2021年8期
王建华,冉煜琨
(成都理工大学工程技术学院,四川 乐山 614000)
0 引 言
从人机交互[1]到医学诊断,从心理研究到计算机视图,眼动跟踪[2]已经应用到众多领域,也有一些成功的商业产品,如美国Neuro 4D眼动仪、瑞典的Tobii X2-60眼动仪等。对于眼动跟踪,大多需要在合理摄像头的情况下才能表现良好的性能,然而,在现实环境中不够鲁棒,这些因素阻碍了眼动跟踪技术的普及和应用。
目前,已经有了一些眼动跟踪(或称为视线跟踪)的方法,一般可以分为基于模型的估计法和基于外观的估计法[3-4]。
基于模型的方法使用眼睛的几何模型。该类方法又可以细分为基于角膜反射的方法和基于形状的方法。基于角膜反射的方法[5-6]依赖于外在光源来检测眼睛特征;基于形状的方法[7-8]从所观察到的眼睛形状中推断凝视方向,如瞳孔中心和虹膜边缘。这些方法趋向于处理相片质量较差和灯光条件多变的情形,主要缺陷是成本高,硬件需定制,在不可控环境下不够精确。
基于外观的方法[9]直接将眼睛作为输入,也可以用于分辨率较低的图像中。相关研究表明[10],与基于模型的方法相比,基于外观的方法所需用户训练数据量更大。
另外,也有一些相关反馈[11]的方法,如文献[12]提出了一种基于眼动跟踪的图像检索重排序方法。该方法使用桌面式眼动仪获取用户观察结果图像的注视点数据,实时地分析这些注视点,找出用户感兴趣的信息,再将这些信息重组成一个新的查询。这个查询更能表达用户的查询意图,返回更多用户查询意图的相关图像。
众包法[13]很大程度上使用了人本计算,注重自由发挥和创意,具有一定的随机性和可扩展性。相关研究也表明[13],众包法能够以较好的可扩展性标注大型数据集。因此,本文通过众包法构建大规模数据集:基于移动的眼动跟踪数据集,包含了不同背景下的约1500个目标,记录了在不同光照条件和无约束头部移动的数据。使用该数据集训练一个深度神经网络,用于端对端的凝视预测。本文方法的最大优势是不依赖于头部位姿预测,只训练眼睛和脸,也不依赖于显著图。虽然本文深度神经网络的精度较好,但输入参数的大小和数量使得它仍难在移动设备中实时使用。为此,本文对其进行优化,训练了一个更小更快的网络,使之具有一定的实时性能。
1 本文方法
1.1 大规模数据集的构建过程
1.1.1 眼动跟踪数据的收集
本文的目标是研发一种收集移动设备中眼动跟踪数据的方法,该方法具有可扩展、可靠和变化性大的特点。
1)可扩展性。众包法的概念是协调和指导一个群体(例如互联网的一大群人)来做“微工作”以解决软件或者个人难以解决的问题。这里的“微工作”通常指一系列机制和方法。众包法在极大程度上使用了人本计算,是解决可扩展性的常用方法之一,很容易应用到大型数据集和具有复杂结构的社区网络中。对于眼动跟踪数据集,其缺点在于很多众包法平台是专门为了台式电脑或笔记本电脑设计的,难以将其应用到所需要的用户体验中。因此,本文使用一种混合方法,将众包法与客户所需的移动应用设计结合起来,构建一个IOS应用,即:GazeCapture[14],记录并上传凝视跟踪数据。
2)可靠性。本文设计出一种全自动的方法,保证参与者都注意且直接显现在屏幕中。①为避免分散注意力,需要保证所有参与者的设备都是飞行模式,且在整个任务过程中没有任何网络连接,直到完成该任务并准备上传。②在点周围显示出闪烁的黑色圆圈,如图1所示,会使眼睛的注意力集中在圆圈中心,其中灰色虚线表示为了保持参与者的注意力。这种闪烁的点会持续大约2 s,且从0.5 s起开始记录。在点移动到新位置时,允许参与者有足够的时间来注视点的位置。③在2 s即将结束时,窗口会出现一个小字母(L或R),持续时间为0.05 s。基于该字母,参与者需要在屏幕的左边(L)或右边(R)进行标记。这可以用于监控参与者的注意力,保证他们参与到该应用中。如果参与者标注错误,将会受到警示。④使用植入IOS的实时人脸检测器,保证参与者的脸在大多视频帧中可见。

图1 单个点演绎的时间轴
3)多样性。为学习鲁棒的眼动跟踪模型,数据的多样性非常重要,因为多样性在完成高精度的免校正的眼动跟踪时至关重要,所以本文设定不同背景以达到多样性。首先,使用众包法在位姿、外观和照明等方面达到多样性。其次,通过展示一段指示性视频,不断改变手机与参与者之间的距离。最后,让参与者在每60个点后改变其移动设备的方向。这样,摄像头和屏幕的相对位置就会发生变化,从而提升了多样性。
1.1.2 数据集特征
本文从1020个参与者中收集数据,相应的凝视位置就有245,500帧。部分帧如图2所示,其中810个参与者使用智能手机,210个参与者使用平板电脑,从这些移动设备中分别提取了约210,000帧和35,500帧。

图2 本文数据集的部分帧样本
为了说明本文数据的多样性,本文使用文献[15]中的方法来估计这些帧中的头部位姿h和凝视方向g。与其他数据集相比,本文数据捕捉法可以捕捉到相机与用户之间的相对位置的变化,且这些变化较大。这些较大的变化将有助于训练和评估眼动跟踪。
1.2 深度神经网络的学习过程
1.2.1 学习端到端模型
本文目标是使用深度卷积神经网络[16](CNN),设计出能够利用单一相片的信息进行鲁棒的凝视预测模型,最大限度地利用大规模数据集。模型的输入数据为:人脸的照片以及在照片中的位置,以及眼睛的图像。通过该模型,可以推断出与摄像头相对的头部位姿以及与头部相对的眼睛位姿,进而推断出凝视的位置。基于这些信息,本文设计的网络整体架构如图3所示,其中,输入值包括从原始帧(大小为224×224)中检测的左眼、右眼以及人脸图像。人脸网格是一个二值掩码,用于表示帧内头部的位置和大小(帧的大小为25×25)。图3中的卷积层Conv-E1和Conv-F1的核大小为11×11,数量为96个;Conv-E2和Conv-F2的核大小为5×5,数量为256个。Conv-E3和Conv-F3的核大小为3×3,数量为384个。Conv-E4和Conv-F4的核大小为1×1,数量为64个。步长stride一般选1或2。全连接层中,FC-E1、FC-F1、FC1和FC-FG2的维度均为128;FC-F2的维度为64;FC-FG1维度为256;FC2维度为2。网络输出为视线的预测位置。
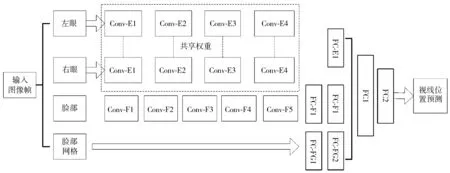
图3 本文眼动跟踪CNN的模型结构
为了最大限度地使用所提大规模数据集,设计了联合预测空间,使用所有数据训练单一模型。直接预测单一方向的设备屏幕坐标是没有意义的,因为输入值变化较大。因此,本文利用了前置摄像头通常与屏幕在同一个表面上,且垂直于屏幕这一原理,预测了与摄像头相对的点位置(在x轴和y轴上),预测空间如图4所示,其中,点表示本文数据集的所有点投影到预测空间的结果。轴表示与摄像头的距离(单位为cm);当摄像头处于(0,0)时,屏幕中的所有点都会投影到这个空间中。最后,使用欧氏距离损失函数训练了x轴和y轴的凝视位置模型。该预测对每个设备和方向调整都有帮助,尤其是在智能手机和平板电脑中的数据分布不平衡情况下。
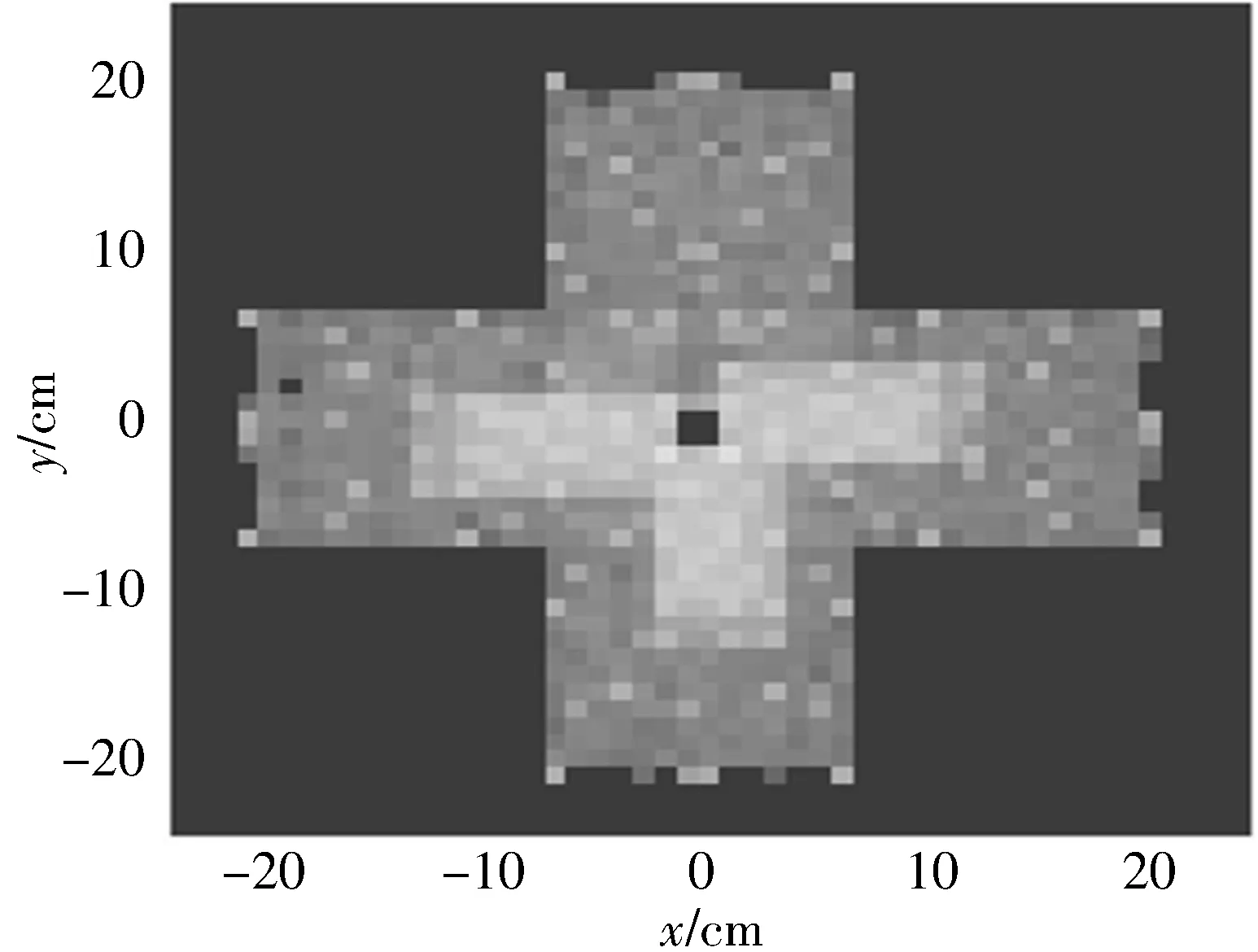
图4 本文的统一预测空间
1.2.2 优化
为了设计较为实用的眼动跟踪器,本文尝试降低模型的复杂度、计算时间以及内存占用量。首先,设计具有鲁棒性的深度神经网络来进行质量较低的眼部检测。然后,利用人脸特征点面部检测生成的紧凑结果[17]来生成更小的网络。文献[17]提出了约束局部神经场(Constrained Local Neural Field, CLNF)方法检测脸部标志区域。这些标志性区域是更加有辨识力的区域,对眼动跟踪具有重要意义,且图像尺寸明显变小(大小为80×80),因此运行速度更快[18]。优化后的网络结构如图5所示。总体参数选择不变,参考图3中的参数介绍。
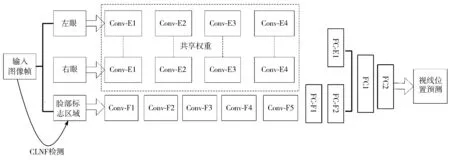
图5 优化后的网络
为了使得网络生成的质量较高,本文综合了真实值、完整模型的预测以及底层特征,使用JETPAC Deep Belief SDK将该模型应用到iPhone6S中,发现优化后的模型运行时间为0.2 s。将该模型与Apple的人脸检测基线相结合,可达到10~15帧/s的检测速度。
2 实验结果与分析
2.1 实验设置
本文实验从GazeCapture的视频帧中选取了1,149,000个包含眼睛检测的帧,一共选出了1,020个参与者,且每个人至少有一个帧包含有效检测。另外,将该数据集分成了训练集、验证集和测试集,分别包含740、80和200个参与者。在验证集和测试集中,只选择看到全部点集的参与者,这样可以保证数据集和测试集中数据分布的一致性,每个参与者选取60帧~200帧。此外,通过转换眼睛、人脸和改变人脸网格,将训练集和测试集增强多倍,以评估本文方法的性能,数据增强后,每个参与者的数据量估计有300帧~1000帧。在训练中,独立处理每一个增强得到的样本,而在测试中,取增强所得样本的平均预测值,以获取原始测试样本的预测值。GazeCapture数据集经过150,000次迭代生成的初始学习率为0.002,经过75,000次迭代后,将学习率降为0.001。在整个训练过程中,冲量单元为0.9,权值衰减为0.0005。
由于移动设备的屏幕尺寸不同,因此移动手机和平板电脑使用的距离不同,本文提供了这2种设备的性能评估。为了模拟真实使用情况,即每个给定凝视包含一系列帧,可以包含点误差。在这种情况下,分类器的输出就是与某一位置凝视点相对应的视频帧预测的平均值。
本文的硬件平台是Intel酷睿i5-4200U CPU@ 2.60 GHz,内存大小为16.0 GB,GPU为Geforce GTX 1080ti。开发环境为Win7操作系统下,Python 3.5语言的PyCharm集成开发工具,使用Keras框架提供的深度卷积神经网络模型。
2.2 不受约束的眼动跟踪
本文中,不受约束(未校正)指的是摄像头位置不固定,受约束(校正)指的是摄像头位置相对固定。通常情况下,受约束时的预测误差更小,但不受约束情况下的评估更有现实意义。因此,本节分析所提方法应用到不受约束的眼动跟踪中,以评估对于新面孔的泛化能力。
实验将数据分为训练数据和测试数据。为了阐明训练和测试中数据的增强作用,性能评估包含了有训练测试增强和没有增强这2种结果。作为基线,本文将TabletGaze中的执行方法(预训练的ImageNet模型)应用到GazeCapture中。不受约束的眼动跟踪结果和消融研究结果如表1所示,其中,误差和点误差的值都是以cm为单位,值越低越好,Aug表示数据集增强,tr和te分别表示训练和测试。基线指的是将支持向量回归[19](SVR)应用到预先训练的ImageNet[20-21]的网络特征中。具体来说,ImageNet作为图像网络项目,包含了多种网络架构,本文选择AlexNet[23]网络。使用预训练的AlexNet网络提取特征,在FC1层中提取特征后,使用SVR训练模型,以预测每个参与者的凝视位置。该方法组合(AlexNet+SVR)作为一个基线方法。图6给出了误差分布情况,其中,左右两边子图中的黑白同心圆圈均表示摄像头的位置。表1和图6的结果表明:本文模型明显优于基线方法SVR,在移动手机和平板电脑中的误差率分别为1.53 cm和2.38 cm。点误差低于误差,这表明,训练增强和测试增强都有助于降低预测误差。虽然测试增强可能不具有实时性能,但训练增强可以用于学习更鲁棒的模型。另外,针对每个设备和方向调整,本文模型有助于进一步降低误差,尤其是对平板电脑,这是因为在GazeCapture中移动手机的样本比例(85%)大于平板电脑的样本比例(15%)。
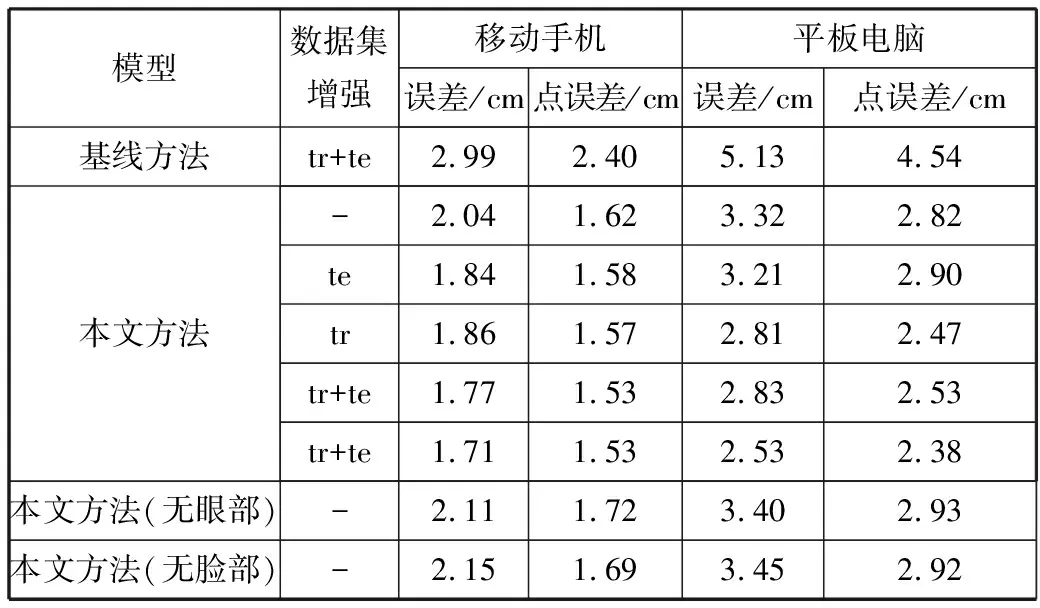
表1 不受约束的眼动跟踪结果和消融研究结果
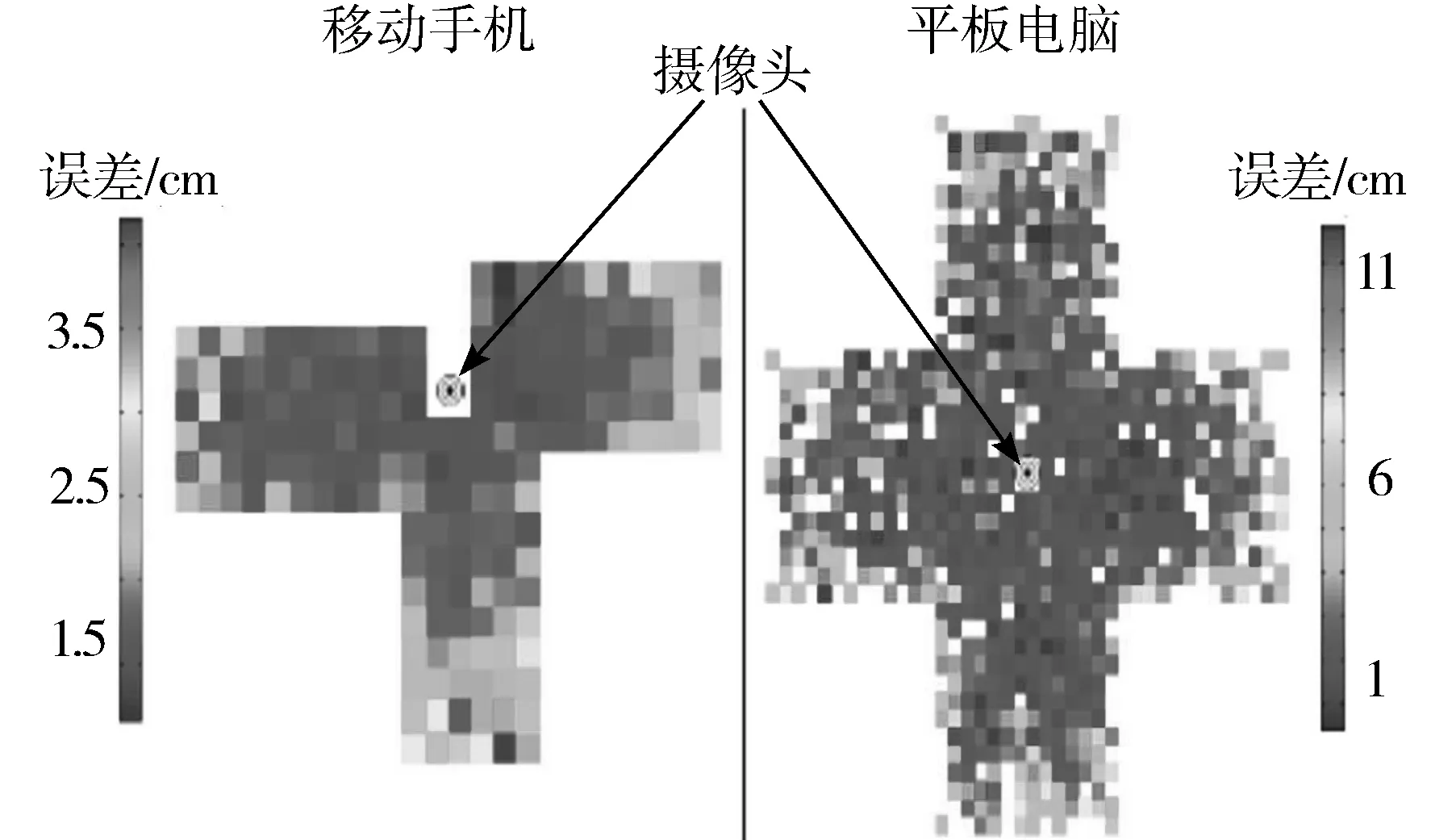
图6 预测空间中的误差分布
2.3 含有校正的眼动跟踪
本文利用每个参与者设定的13个固定点位置来模拟校正过程。对于测试集中的每个参与者,使用这13个固定位置的视频帧进行训练,并在剩下的位置中进行评估。不同校正点数量的实验结果如表2所示。可以看到,当不校正点时,结果会略微下降,在训练SVR时,由于过拟合,会发生这种情况。然而,当使用13个点(最多)进行校正时,性能会得到较大提升,在移动手机和平板电脑上的误差分别变成1.34 cm和2.12 cm。

表2 校正点数量不同时的性能
2.4 跨数据集的泛化分析
为了评估跨数据集的泛化性能,将本文特征学习应用到TabletGaze[22]中。TabletGaze包含共51个参与者,以及有40个可用参与者的子数据集。本文将这40个参与者分为2个部分,32个用于训练,8个用于测试。将SVR用于本文方法的特征提取,并将已训练好的分类器应用到测试集中。比较的方法有TabletGaze[22]、MPIIGaze[17]和2个基线方法。其中,中心预测是指忽视数据,预测屏幕的中心位置,另一个方法是将SVR应用ImageNet预训练的AlexNet[23]网络以进行特征提取。实验结果如表3所示,可以看出,本文方法提取的特征明显优于其他方法,其误差为2.58 cm,这表明了该方法的特征泛化能力较好。

表3 将不同最新方法应用到TabletGaze数据集时的结果
2.5 多样化分析
为了更好地理解不同部分的重要性,表1的后半部分给出了依次移除本文模型的不同组成部分后所得的结果,总体来说,这3个输入值都提升了方法的性能。有人脸没有眼睛时所得的结果与本文方法所得的结果类似,这说明本文所提方法可以设计出只需要人脸和人脸网格作为输入值的有效方法。因为大规模数据集使得CNN可以有效地识别出不同人脸(眼睛)的差别,然后作出精确的预测。
数据集大小对降低误差至关重要,其影响结果如图7所示。其中,图7(a)给出了在不断增加训练参与者总数时,本文方法的性能变化。从图中可看出,当参与者数量增加时,误差明显降低,这表明收集大规模数据集的重要性。为了表明多样化数据的重要性,分析了如下2种情况:1)参与者数量增加,每个参与者样本数量保持不变;2)增加每个参与者的样本数量,保持参与者数量不变。这2种情况下,样本的数量均保持不变。由图7(b)可知,当参与者数量增加时,误差降低的速度更快,这间接表明了多样化数据的重要性。
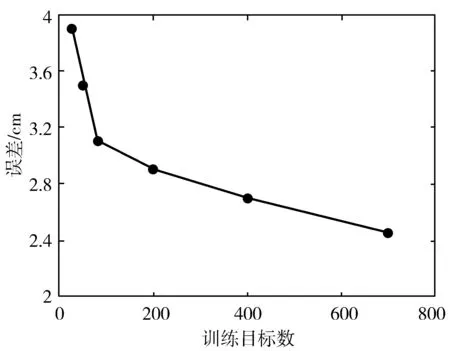
(a) 目标数与误差
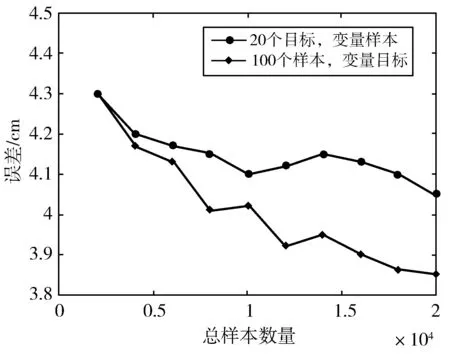
(b) 目标与样本
3 结束语
本文针对移动设备的眼动跟踪,在大规模数据集的构建过程,利用已有技术,构建了一个IOS应用:GazeCapture,记录和上传凝视跟踪数据。同时,验证了众包法在智能手机凝视数据方面的重要性,阐明了大规模数据集以及多样化数据对于训练眼动跟踪的鲁棒性。利用大规模数据集训练本文所提方法。经过实验评估,本文方法能够鲁棒地预测眼动跟踪。此外,应用本文模型学习的特征也可以很好地应用到其他数据集中,具有较好的可扩展性和多样性。
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23 13:46:18
汽车实用技术(2022年7期)2022-04-20 11:44:42
载人航天(2021年5期)2021-11-20 06:04:32
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
动漫星空(2018年9期)2018-10-26 01:17:14
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:28
华人时刊(2016年13期)2016-04-05 05:50:03
外语学刊(2016年4期)2016-01-23 02:34:15
发明与创新(2015年33期)2015-02-27 10:40:09
出版与印刷(2014年4期)2014-12-19 13:10:39
