
基于视觉特征的非侵入式用户界面输入项识别
2021-08-20 09:17:08王岩,钱巨
计算机与现代化 2021年8期
王 岩,钱 巨
(南京航空航天大学计算机科学与技术学院, 江苏 南京 211106)
0 引 言
软件测试[1-2]可以发现软件中存在的问题,提高软件产品质量。软件测试中的一个重要任务是测试数据生成[3]。对于图形用户界面(GUI)软件而言,测试数据生成的前提是获取界面中的输入项信息,包括输入项内部提示文字、外部描述标签、内外提示图标等内容。
当前输入项识别主要有2种方法。一种是访问界面结构信息,从软件所在操作系统提供的运行时界面内部数据结构信息出发,获得输入项位置以及其他特征。例如,通过安卓的AccessibilityService服务可以获取界面结构详情,对其解析可以获取输入项信息。Wanwarang等人[4]利用手机界面的结构化信息实现对输入区域的识别定位,使用自然语言对提示文字进行概念提取,并为其构造测试用例。Darab等人[5]首先获取界面结构信息,然后对其解析得到关于输入参数的控件,并提取出搜索关键字标识符,最后利用在线的正则表达式库获取测试用例。上述输入识别方法需要侵入被测软件所在系统,当无法由内部系统访问界面结构信息时,无法应用。例如一些军工软件或者游戏终端机具有较强封装性或较高安全性要求,无法访问软件所在操作系统相关接口,很难得到界面结构详细信息。对这些软件,依赖界面内部结构信息的方法无法使用。另一种是人工给出输入项的位置,提供输入项信息。该方法需要耗费大量的人工成本,无法真正实现测试自动化。近年来,可视化测试技术(例如工具AirTest[6]、Sikuli[7])得到快速发展,它们基于图像和视觉技术来开展测试,为软件测试引入了解决问题的新思路。而界面图像信息比较容易获得,计算机视觉技术近年来也得到了快速发展,使得基于视觉化方法识别输入项具有了新的可能。
本文提出一种基于视觉特征的非侵入式用户界面输入项识别方法,从外部摄像头等非侵入式途径获得的应用界面图片出发,利用直线检测和轮廓检测算法得到候选输入项列表,基于图像直方图等视觉特征,利用支持向量机[8]模型来对输入项进行智能识别,实现非侵入式场景下的输入项识别能力。该方法只需要获取用户界面图片就可以进行输入项的识别,无需访问待测系统内部信息,适用范围更广,例如可用于专用嵌入式设备测试、接口封闭的游戏设备、多媒体设备测试等特色场合。
1 方法总体流程
界面图片中的输入项识别是一个目标检测[9]问题,当前目标检测常用的思路有2种:经典计算机视觉思路和端到端深度学习思路。经典计算机视觉思路是一种先得到待识别区域,然后采集特征,利用机器学习方法判定其类别[10],从而实现目标检测的方法。该方法在模型训练阶段,所需的训练数据相对较少。另一种端到端深度学习思路是像YOLO[11-13](You Only Look Once)这类使用CNN(Convolutional Neural Networks)卷积神经网络[14]直接输出目标的位置和类别。这种方法不需要人工提取特征,由深度神经网络自动学习特征。为了达到较好的识别效果,深度学习[15-16]方法一般需要大量的数据进行学习,才可以使得模型具有较好泛化能力。由于大规模的训练数据集不易获得,所以本文采用经典计算机视觉思路。
本文方法的总体思路是:首先,在界面图像上通过直线检测算法和轮廓检测算法[17]获得潜在输入项的列表;然后,获取候选输入项的关键字匹配特征,输入位置背景颜色特征,输入区域字体颜色特征以及其他关于输入区域图片颜色、位置和大小的特征,并把这些特征转换成特征向量传入到预先训练好的SVM分类器模型中进行判定,并过滤得到真正的输入项列表。具体的方法流程图如图1所示,主要包括获取候选输入项列表、提取候选输入项视觉特征、将特征值转换成特征向量传入到SVM模型中进行判定等步骤。

图1 方法总体流程图
2 获取候选输入项
2.1 图像预处理
当前应用类型繁多,输入项样式多样。有的输入项区域颜色与周边区域颜色色彩差异不明显,使得Canny边缘检测得到的边缘是间断的,造成直线检测或者轮廓检测算法无法完整地得到输入项的边缘信息。针对这类问题,本文使用形态学变换的闭运算使得间断的边缘可以连接起来,方便后续的直线检测和轮廓检测算法寻找目标对象。图2是闭运算效果图,表明闭运算后的二值图可以连接断开的边缘。

(a) 闭运算前二值图

(b) 闭运算后二值图
2.2 利用直线检测获取候选输入项
由于大部分的输入项是以直线方式呈现或者矩形框方式呈现,提示用户在直线上方输入或者在矩形框内部输入,所以采用直线检测得到候选输入项。直线检测方法为,利用累计概率霍夫变换直线检测算法[18]检测图片中的直线,返回的每条直线用(x1,y1,x2,y2)表示,其中(x1,y1)表示线段的起点,(x2,y2)表示线段的终点。基于直线相对宽度,记为relativeWidth=(x2-x1)/W,其中W为图片的宽度,过滤掉长度相对屏幕宽度过短,不符合一般输入项长度特征的直线。对检测到的所有直线分别向上方进行扫描扩展使得得到的区域有机会覆盖对应的提示文字信息,得到每条直线向上方进行扩展所对应的区域图片信息、区域位置信息。其中,直线向上扩展的距离设定δ,使得向上方扩展的距离有机会刚好可以覆盖到提示的文本信息。具体得到的输入项矩形框区域图片信息如式(1)所示,其中Region为区域图片信息,x1,y1-δ分别为裁剪区域左上角的x起点和y起点,x2,y2分别为裁剪区域右下角的x终点和y终点,区域图片信息也就是通过在image上裁剪的感兴趣区域(ROI):
Region=image{x1:x2,y1-δ:y2]
(1)
2.3 利用轮廓检测获取候选输入项
对界面图片中的轮廓进行检测,得到矩形框的候选输入位置。获取矩形框候选输入位置的方法为:
1)提取图像中的轮廓信息,基于轮廓相对面积过滤掉不符合要求的轮廓。对剩余所有轮廓分别获取轮廓的外接矩形,得到每个轮廓对应的区域图片、区域位置信息。图3是符合要求的轮廓的外接矩形。具体而言,设contour为检测到的轮廓,bound()为获取轮廓的外接矩形函数,得到x、y、w、h分别为对应外接矩形的起点x、起点y、宽度w和高度h,轮廓检测算法得到的输入区域图片信息如式(2)和式(3)所示,其中image为读取的图片信息,Region为区域图片信息即对image裁剪得到的感兴趣区域:

图3 轮廓检测外接矩形效果图
(x,y,w,h)=bound(contour)
(2)
Region=image[x:x+w,y:y+h]
(3)
2)合并由直线检测获得的候选输入区域和由轮廓检测获得的候选输入区域,得到潜在输入项列表,潜在输入项列表在经过后续训练好的分类器模型的过滤,即可得到真正的输入项列表。
3 过滤并获取真正的输入项
3.1 特征提取
本文通过人工提取特征作为模型训练的特征向量。提取的特征主要包括图像特征、文字特征。其中图像特征包括:颜色特征和纹理特征等。
1)提示关键字的特征。
提示关键字特征分为2种情况:一种是提示信息有“请输入”这类希望用户输入文字提示的关键词,这类候选输入项大概率是真实的输入项;另一种是有“登录”这种不希望用户输入的关键词,这类候选输入项大概率不是真实的输入项。
获取提示关键字特征值的方法为:
首先对候选输入区域利用光学字符识别(OCR)技术进行文字识别,获取待测区域包含的提示文字信息,判断获取到的文字是否包含指定的输入提示关键字,得到是否包含提示关键字的特征,用fhint表示。fhint=1表示包含输入提示关键字,例如提示信息里包含“搜索” “请输入”等关键词的情况,fhint=0表示无输入提示关键字。
其次,判断获取到的文字是否包含指定的非输入提示关键字,得到是否包含非输入提示关键字的特征,用fforbid表示。fforbid=1表示包含非输入提示关键字,例如提示信息里面包含“登录”“发送”等动作关键词的情况,fforbid=0表示无非输入提示关键字。
2)颜色丰富度特征。
通过输入区域图片计算该区域的颜色丰富度,得到颜色丰富度特征。由于输入项大都是浅色的背景色,所以可以通过对一张图片的色彩丰富度进行量化,用其作为一个判断输入项的特征。对一张RGB(Red, Green, Blue)通道的彩色图片计算色彩丰富度[19]的公式如下所示,其中R是输入区域图片的红色通道矩阵,G是绿色通道矩阵,B是蓝色通道矩阵,rg为红色通道与绿色通道的差值,yb为红色通道矩阵加上绿色通道矩阵的一半减去蓝色通道矩阵的值,∂rg、∂yb分别表示rg矩阵和yb矩阵的标准差,μrg、μyb分别表示rg矩阵和yb矩阵的平均值。计算得到色彩丰富度,该特征用fm表示:
rg=R-G
(4)
(5)
(6)
(7)
fm= ∂rgyb+0.3×μrgyb
(8)
3)纹理特征。
纹理是图像的重要特征之一,常用于图像的分类任务中。纹理特征[20]刻画像素的邻域灰度空间分布规律,而输入区域从纹理特征的角度看也呈现一定的规律性,例如输入区域的背景纹理通常比较简洁。并且灰度共生矩阵是一种常用的通过灰度的空间相关特性来描述纹理的方法,可以用灰度共生矩阵上的熵表达图片的纹理复杂程度,所以把图片的熵作为一个输入项特征。计算熵特征fent的公式如式(9)所示,其中G为生成的灰度共生矩阵,k为灰度共生矩阵的行数和列数值,且行数和列数值相等,G(i,j)表示灰度共生矩阵中根据下标对应位置元素的值,fent表示求得的熵。
(9)
除了熵之外,灰度共生矩阵还有其他的统计量用来表示纹理特征。所以本文研究方法还选择对比度、能量、逆方差等统计量来表示纹理相关特征。计算方法如式(10)~式(12)所示,其中G(i,j)表示灰度共生矩阵中根据下标对应位置元素的值。
对比度(contrast)反映了某个像素值及其领域像素值的亮度的对比情况,计算公式为:
(10)
能量(angular second moment)反映了图像灰度分布均匀程度和纹理粗细度,计算公式为:
(11)
逆差矩(inverse different moment)反映图像纹理的同质性,计算公式为:
(12)
4)提示字体的颜色和大小特征。
由于大多数的输入提示信息文字颜色都具有一定的规律,例如浅色的提示文字,所以可以把字体的颜色作为一个特征。计算提示文字的颜色方法为,对输入区域图片进行轮廓检测,检测到输入区域图片中所有的字体,然后计算字体轮廓内部的RGB平均值,得到输入提示字体颜色的特征,该特征用ffontR、ffontG、ffontB表示。同时,基于文字块的轮廓信息计算输入提示信息字体的大小特征,该特征用ffontSize表示。因为输入提示信息的字体一般大小适中,太大或者太小的文字不符合常规输入提示文字表征,所以使用提示信息字体大小作为其中一个特征。
5)输入区域其他特征。
通过候选区域的外接矩形得到候选区域的宽度特征,该特征用fw表示。基于外接矩形坐标得到输入区域是否关于用户界面图片纵向中心线对称特征,该特征用fsym表示,计算方式为比较输入区域中心点的横坐标与图像中心点的横坐标,两者之间相差距离小于给定阈值则认为是对称,否则认为不对称。
统计输入区域不同颜色区间像素值的个数,获得输入区域的图片颜色直方图,将其转换为一维的向量,构成子特征集,与其他特征共同组合,形成关于输入项的特征向量。颜色直方图反映了图像的色彩分布,例如偏白还是偏黑,直方图特征用Fhist表示。
同时,基于HSV(Hue, Saturation, Value)颜色空间计算输入区域的色调、饱和度和亮度特征,3个特征值分别用fh、fs、fv表示。另外,由于大部分输入区域的背景色以浅色为主,所以取输入区域图片RGB这3个通道平均值作为背景颜色特征,3个特征值分别用fr、fg、fb表示。总的关于输入项的特征描述如表1所示。结合所有特征组成关于候选输入区域的特征向量,使用F表示,fi为特征向量的第i个特征值。

表1 输入项特征
F=(f1,f2,…,fn)
(13)
3.2 模型训练
针对所选定的特征,在已有的界面图像数据集上采集输入区域的特征数据和非输入区域的特征数据,打上各自对应的标签,以此为训练数据,训练出用于判别输入项的SVM模型。训练数据集从多张图片中生成,并且每张图片中有输入项和非输入项2种类别的候选输入区域,总的训练数据记为{s1,s2,…,sm},每个候选输入项对应的特征向量记为F(s),特征向量对应的标签记为γ,且γ∈{0,1},得到的T为训练输入项判断模型的训练数据,fij为第i条训练数据的第j个特征值,γi为第i条训练数据的标签值。
(14)
3.3 模型预测
对获取到的界面图片中潜在的输入项列表,依次利用训练好的SVM模型对候选输入区域进行判断,过滤并得到真正的输入项列表。单个候选输入项判断方法为:计算该候选输入项图片区域的各项特征值并转换为特征向量,把得到的特征向量传入到预先按照同样特征在给定的训练案例集上学习好的SVM分类器模型,利用模型判断该输入项是否是真实的输入项。设训练好的模型为R,候选输入项对应的特征向量为(f1,f2,…,fn),则判断输入项类别的过程通过式(15)表示,其中fi为第i个特征值,若Y=true表示是输入项,Y=false则表示不是输入项:
Y=R(f1,f2,…,fn)
(15)
由于同一个真正的输入项可能被直线检测或轮廓检测同时检测到多次,所以需要根据2个输入区域的交叉重叠比例过滤冗余的输入项,最终得到真正的输入项列表。
4 实验及结果分析
实验从Google Play应用商店选取了包括SpeechTrans、PizzaHut等106个应用,应用的类别涵盖了教育、生活等20种类别。从这些应用中选择200张包含输入项的界面图片作为实验数据集。这些界面图片数据集不仅包含输入项,而且每张界面图片具有对应的界面结构信息,利用界面结构信息不仅可以得到训练模型的训练数据集,而且可以作为模型判断输入项识别效果的依据,自动地进行输入项识别效果的统计计算。
本文使用SVM作为智能预测的模型,SVM是一种监督学习的二分类模型,它的基本模型是定义在特征空间上间隔最大的线性分类器。在样本空间中,划分超平面可通过如式(16)的线性方程来描述,其中w为法向量,决定了超平面的方向,b为位移项,决定了超平面与原点之间的距离:
wTx+b=0
(16)
如果可以利用间隔最大化寻找到最优超平面(w,b)能将训练样本正确分类,则说明样本是线性可分的,否则是线性不可分的。对于线性不可分问题,将样本从原始空间映射到一个更高维的特征空间,使得样本在高维特征空间线性可分,并引入核函数来代替高维甚至是无穷维特征空间中内积的计算。由于特征空间维数很高,甚至可能是无穷维,因此直接计算内积比较困难。有了核函数就不必直接去计算高维空间中的内积,而用核函数代替内积的计算。
实验主要使用OpenCV[21]开源工具进行图像处理,使用Sklearn[22]机器学习库进行模型的训练以及预测过程,具体使用SVM的分类器模型,经过网格搜索方法确定模型的训练超参数,实验最终使用的核函数为径向基函数(RBF),并设置惩罚系数C为20,gamma参数为0.009进行模型训练。训练数据集获取方法为:
首先,利用直线检测算法和轮廓检测算法对训练集中的界面图片进行检测,可以得到候选输入项列表。然后,根据界面图片对应的界面结构信息获取界面图片中真正的输入项列表。根据真正的输入项列表信息,可以对候选输入项列表中的每个候选输入项打上对应的标签,并计算候选输入项的视觉特征,组合所有的特征值和标签值即可得到训练数据集。模型训练完毕之后即可对测试图片进行测试,计算识别到的输入项区域与实际真正的输入项区域的交并比(IOU),超过指定阈值则认为输入项识别成功,本实验IOU阈值设置为0.5。另外,实验采用五折交叉验证的方式评价本文的方法,把实验数据集分成5份,每次选择其中的4份作为训练数据集,剩余的1份作为测试数据集,取5组实验的平均值作为本文方法的评价数据。
界面图片中的输入项识别可以理解为二分类问题。二分类问题常用的评价指标有精确率、召回率、F1分数。计算方法为,通常以关注的类为正类,这里是以输入项的类为正类,其他类为负类。分类器的分类情况可能有4种情况:TP——将正类预测为正类数;FN——将正类预测为负类数;FP——将负类预测为正类数;TN——将负类预测为负类数。
其中,精确率定义为:
(17)
召回率定义为:
(18)
另外,精确率和召回率通常是一对矛盾的度量[23]。一般来说,精确率高的时候,召回率往往偏低;而召回率高时,精确率往往偏低。通常只有在一些简单任务中,才可能使精确率和召回率都很高。由于本文对精确率和召回率的重视程度一致,所以选用F1作为精确率和召回率的调和均值,它同时兼顾了精确率和召回率,可以更好地评价二分类模型,公式定义为:
(19)
本文方法的输入项识别效果如图4所示,界面图片中存在的输入项可以被较好地识别出来,识别的输入项区域包括输入项内部提示文字、提示图标等区域,为测试用例的生成提供了条件。

图4 输入项识别结果
本文方法的识别精度如表2所示,其中共有6组实验数据,分别是五折交叉验证过程中的每一组试验数据和5组试验数据的平均值。其中直线和轮廓识别这组数据是使用直线检测和轮廓检测算法进行实验获取,可以发现获取的候选输入项位置列表得到的召回率较好(平均值为0.94),目的是为了后面用SVM机器学习方法判定的时候可以有机会识别出更多的真正输入项。经过SVM模型判定之后,除了召回率有所下降,精确率有比较大的提高,表明该模型对界面图片中的候选输入项可以很好地识别,具有一定的可行性。
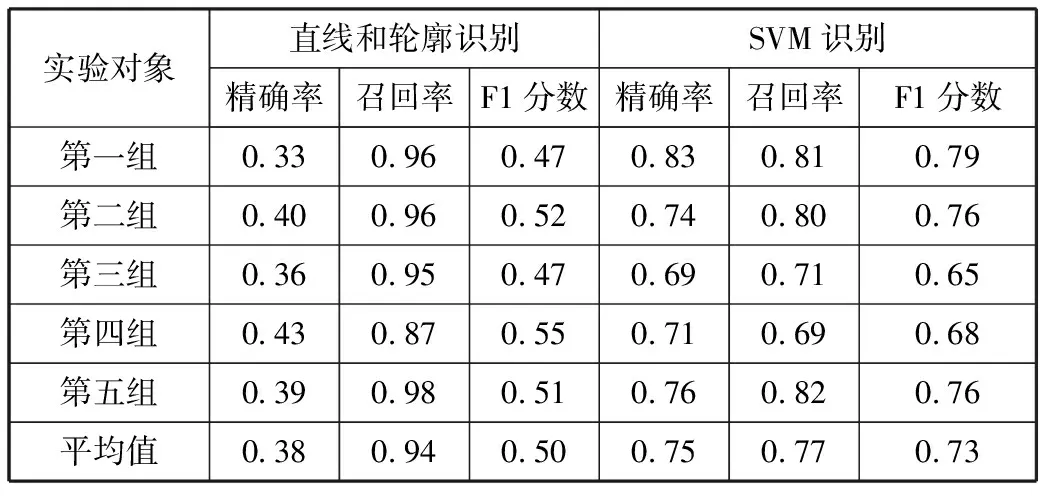
表2 输入项识别精度
5 结束语
本文提出了一种基于视觉特征的非侵入式用户界面输入项识别方法,该方法在无法获得应用内部结构信息的非侵入式测试场景下可以进行输入项识别。实验结果表明,本文方法可以有效地进行界面图片中输入项的识别,可以用于专用嵌入式设备测试、接口封闭的游戏设备等特色场合,克服了现有技术在上述场合无法应用的局限。
猜你喜欢
装备制造技术(2020年1期)2020-12-25 05:19:06
当代陕西(2020年13期)2020-08-24 08:22:02
制造技术与机床(2019年11期)2019-12-04 05:50:54
小学生导刊(2018年13期)2018-11-30 15:19:29
制造技术与机床(2017年5期)2018-01-19 02:49:17
数学小灵通·3-4年级(2017年10期)2017-11-08 08:43:10
小学生导刊(低年级)(2017年2期)2017-06-10 02:37:43
潍坊学院学报(2016年2期)2016-12-01 13:00:11
新闻传播(2015年11期)2015-07-18 11:15:04
计算机工程(2015年4期)2015-07-05 08:27:39
