
基于BERT-BiLSTM的网民情绪识别
2021-08-18 21:53潘梅
电脑知识与技术 2021年18期
关键词:网民
潘梅
摘要:为帮助政府等相关部门及时掌握大众对特定公共事件的主要情感倾向,针对基于词向量的深度学习方法实现网民情绪识别,存在高度依赖分词准确性、一词多义等问题,提出基于BERT-BiLSTM的网民情绪识别方法。首先,基于BERT预训练模型获取预处理后的待识别文本词向量;然后,利用BiLSTM提取上下文相关特征进行学习;最后,通过分类器获得文本的情感极性,包括积极和消极两类。通过对疫情期间网民情绪识别数据集实验表明,基于BERT-BiLSTM的网民情绪识别模型P值为88.98%,R值为92.72%,F1值为90.81%,相比于LSTM和BiLSTM模型性能更优。本识别方法可为网民情绪识别研究提供借鉴,识别结果可为政府决策分析和舆情引导提供参考。
关键词:网民;情绪识别;BERT;BiLSTM
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)18-0074-03
开放科学(资源服务)标识码(OSID):
Emotion Recognition of Internet Users based on BERT-BiLSTM
PAN Mei
(Chengdu Normal University, Chengdu 611130, China)
Abstract: In order to help the government and other relevant departments grasp the main emotional tendencies of the public on specific public events in time, aiming at the problems of high dependence on word segmentation accuracy and polysemy in deep learning method based on word vector to realize internet users emotion recognition, this paper proposes ainternet users emotion recognition method based on BERT-BiLSTM. Firstly, the text word vector with preprocessed and to be recognized is obtained based on the BERT; secondly, the context sensitive features are extracted by the BiLSTM for learning; finally, the emotional polarity of the text, including positive and negative, is obtained through the classifier. The experiments of internet users emotion recognition data set during the epidemic period shows that the Precision is 88.98%, Recall is 92.72%, and F1 is 90.81%based on BERT-BiLSTM, which is better than LSTM and BiLSTM. The recognition method can provide reference for the research of internet users emotion recognition, and the recognition results can provide reference for government decision-making analysis and public opinion guidance.
Key words: internet users; emotion recognition; BERT; BiLSTM
1 引言
随着互联网技术和移动通信技术的高速发展,普通大众均可便捷地在网络上对公共事件发表评论和分享观点,通过网络表达对各种社会事件的情感态度。该方式可以迅速传播和延伸至网络各区域,引发公众关注和热议,形成网络社会舆论,网络舆论通常会产生巨大的舆论动向和影响。公共事件爆发后,政府须尽快掌握人们对该话题的关心程度和发展趋势,有效提高其公信力和应急管理能力。如新型冠状病毒(COVID-19)感染的肺炎疫情,迅速引发国内和国际舆论的持续关注,众多网民参与疫情相关话题讨论。政府部门需要掌握公众在该事件传播过程中的情感状况和社会舆论情况,科学高效地做好防控宣传和舆情引导工作。因此,对网民发表的评论进行情绪识别分析,把握大众对特定事件的主要情感倾向,是辅助政府进行決策分析和舆论引导的重要手段。本文通过对特定公共事件传播期间网民情绪识别方法进行研究,为及时准确掌握网络大众情感提供参考。
网民情绪识别的核心是对网民评论的短文本进行情感分析,其主要分为基于情感词典的方法[1]、基于传统机器学习的方法[2]和基于深度学习的方法[3]。基于深度学习的方法在建模、解释、学习和表达等方面较优,但主流的深度学习分析方法大多都是基于词向量的分类,该类模型存在高度依赖分词准确性、一词多义等问题。因此,本文提出基于字向量的BERT-BiLSTM深度学习模型进行网民情绪识别方法研究和实验。
2 BERT-BiLSTM情绪识别模型
2.1整体设计
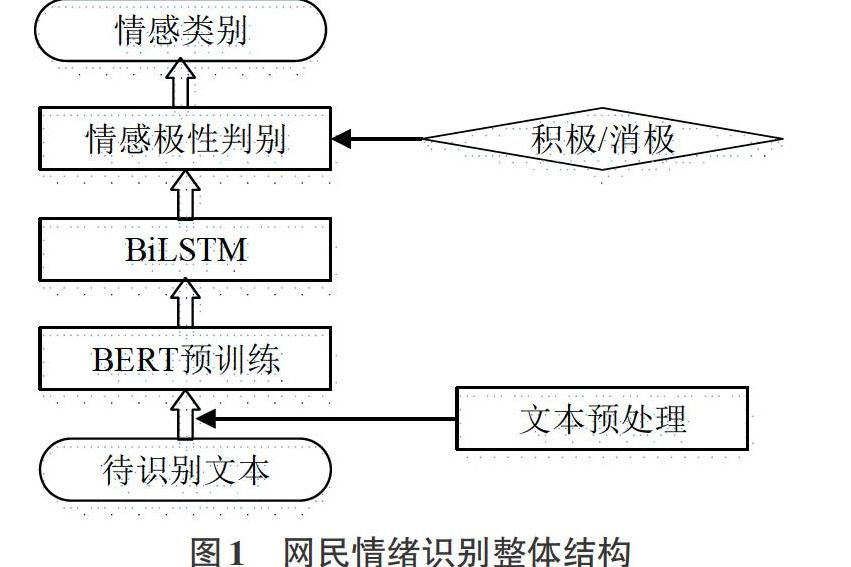
本文提出的基于BERT-BiLSTM的网民情绪识别方法主要由3部分组成:BERT预训练、BiLSTM和情感极性判别,具体如图1所示。
首先,将待识别分析的文本进行去停用词、去乱码等文本预处理;然后,基于BERT预训练模型获取包含上下文语义信息的文本词向量;接着,利用BiLSTM提取上下文相关特征进行学习;最后,通过分类器进行情感极性判别获得文本情感类别,包括积极和消极2类。该识别方法的关键为BERT预训练和BiLSTM循环神经网络。
2.2 BERT预训练
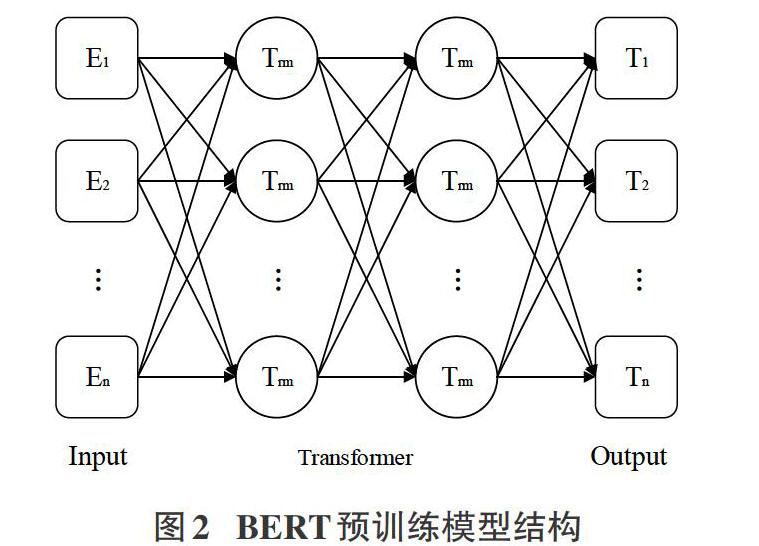
BERT(Bidirectional Encoder Representations from Transformers)是Devlin J[4]等提出的一种采用多层双向Transformer 的自然语言处理(NLP)预训练模型。该模型主要由输入层、编码层和输出层3部分构成,如图2所示。其中, [E1,E2,…En]为模型的输入;[Trm]为自注意力(Self-attention)机制编码转换器;[T1,T2,…Tn]为模型的输出[4]。
BERT模型采用多层双向Transformer和Self-attention机制,其具有双向功能;该模型联合了两种语义表征方法:一是掩码语言模型(Masked LM),二是下句预测(Next Sentence Prediction)方法,通过联合训练实现了双向LM模型预训练。BERT预训练模型是基于字符实现文本向量化,能充分利用上下文特征,不依赖分词准确性,可有效解决一词多义等问题。
本文经过BRET向量化后的网民评论文本[X]如式(1)所示:
[X∈{x1,x2,…xn}] (1)
式中,[n]为文本[X]的长度。
2.3 BiLSTM循环神经网络
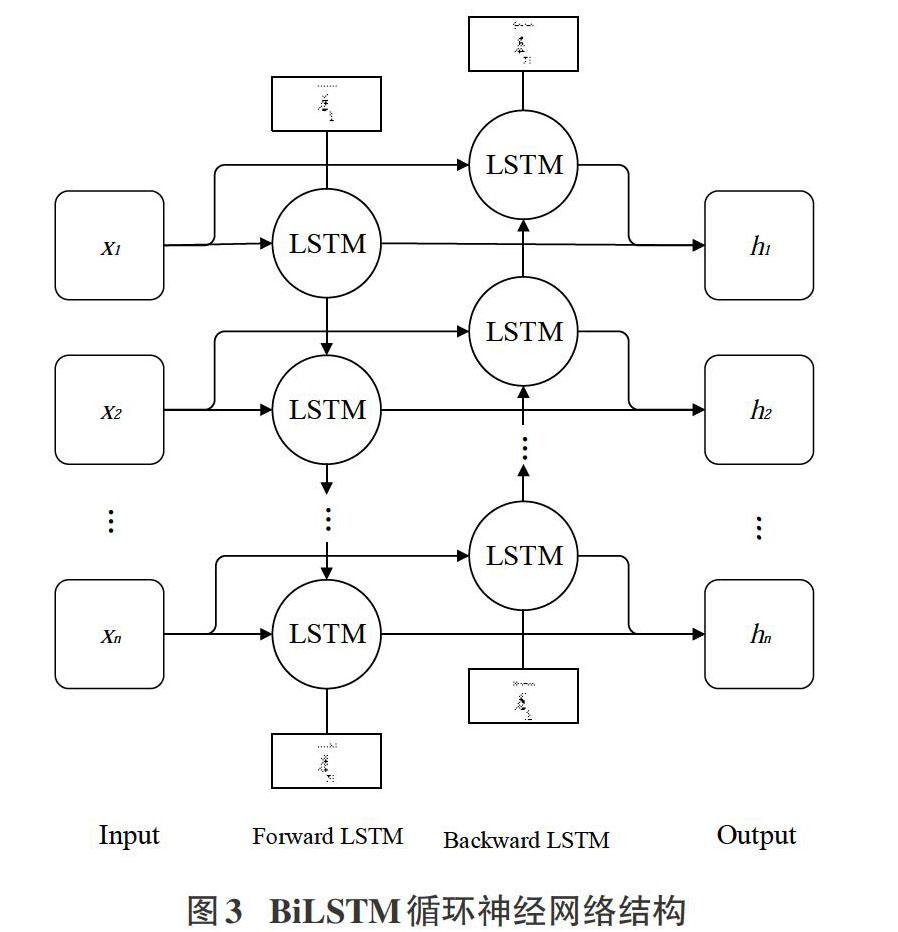
双向长短时记忆(Bi-directional Long Short-Term Memory, BiLSTM)网络是Graves A[5]等提出的一种由前向LSTM(Long Short-Term Memory)和后向LSTM两个方向叠加而成的循环神经网络(Recurrent Neural Network, RNN),该网络可以分析到文本的上文和下文信息,有效解决LSTM仅能分析文本上文信息的单向性问题。BiLSTM网络结构如图3所示。
BiLSTM的输入为BERT模型的词向量[X∈{x1,x2,…xn}],Forward LSTM按[x1,x2,…xn]顺序读取,输出向量集合[h1,h2,h3,…hn];Backward LSTM按[xn,…x2,x1]顺序读取,输出向量集合[{h1,h2,h3,…hn}];其中,[hn]和[hn]分别为最后时刻前向隐层和后向隐层的特征向量。拼接[hn]和[hn]获取文本最终的特征向量[hn],即BiLSTM输出如式(2)所示:
[hi={hi,hi}] (2)
式中,[i]为文本[X]的第[i]([i≤n])个词。
3 网民情绪识别实验
3.1 实验平台
本网民情绪识别方法研究所需实验平台为:计算机、Windows 10操作系统和Pycharm 2019软件,利用Python编程语言实现,具体参数如表1所示:
3.2 实验数据
本网民情绪识别实验数据为疫情期间网民情绪识别数据集[6],约100000条,分为积极、中性和消极3类。其中,积极评论(标记为1)25392条,消极评论(标记为-1)16902条。实验首先对数据进行去无关符号等预处理操作,再将数据集按7:3的比例分成训练集和测试集。
3.3 实验结果与分析
为验证本文设计的网民情绪识别模型的有效性,实验选取了LSTM和BiLSTM两种方法与BERT-BiLSTM进行对比,采用精确率P(Precision)、召回率R(Recall)和F1值三个指标来评估模型的性能。实验结果如表2所示:
对比3种方法的实验结果可知,相比于LSTM和BiLSTM模型,BERT-BiLSTM模型的P值、R值和F1值均有较大幅度提升:P值分别提升2.8%和2.57%,R值分别提升6.35%和6.45%,F1值分别提升4.54%和4.47%。由BiLSTM模型值高于LSTM模型值可知,BiLSTM模型在获取文本上下文特征上的性能更优,能提取到更多上下文信息;由BERT-BiLSTM模型值高于BiLSTM模型值可知,BERT模型的字符向量比词向量在获取文本特征上的性能更优,能提取到更多文本信息。总之,本文提出的结合BERT模型和BiLSTM模型的网民情绪识别方法对疫情期间网民情绪识别数据集有更优的性能。
4 结束语
本文提出的BERT-BiLSTM算法模型,可以有效实现网民情绪识别。在特定公共事件传播过程中,政府可以采用该方法及时掌握大众的主要情感倾向,为其决策分析和舆情引导提供参考,辅助其实现科学化高效率办公。同时,该情绪识别方法也可以为网民情绪识别分析研究提供参考。
参考文献:
[1] 冯超,梁循,李亚平,等.基于词向量的跨领域中文情感词典构建方法[J].数据采集与处理,2017,32(3):579-587.
[2] 洪巍,李敏.文本情感分析方法研究综述[J].计算机工程与科学,2019,41(4):750-757.
[3] 金志刚,胡博宏,张瑞.融合情感特征的深度学习微博情感分析[J].南开大学学报(自然科学版),2020,53(5):77-81,86.
[4] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv: 1810.04805, 2019.
[5] Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Network, 2005, 18(5): 602–610.
[6] 北京市政務数据资源网. data.beijing.gov.cn
【通联编辑:王力】
猜你喜欢
在线学习(2021年3期)2021-09-10
环球时报(2019-10-14)2019-10-14
遵义(2018年20期)2018-10-19
中国公路(2017年9期)2017-07-25
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
湖北社会科学(2015年9期)2015-12-28
新闻与传播研究(辑刊)(2015年0期)2015-01-22
