
一种面向句子的汉英口语翻译自动评分方法
2021-08-13 07:43李心广陈帅龙晓岚
中文信息学报 2021年7期
李心广,陈帅,龙晓岚
(1.广东外语外贸大学语言工程与计算(广东省)重点实验室,广东广州510006;2.广东外语外贸大学信息科学与技术学院,广东广州510006)
0 引言
汉英口语翻译质量测评是近年来汉英翻译质量自动测评领域热点之一[1-2]。在口语自动评分中,已有的研究大多是针对发音质量层面的口语测评[3-5],如朗读题和跟读题等。朱洪涛等人[3]通过最大似然线性回归和最大后验概率算法对英语朗读题进行评分,并取得了一定的效果。但与文本内容(关键词,句子大意等)相关的题型的研究,如口译题和复述题等,仍缺乏有效的评测策略。虽然部分学者已开展了相应的研究,但真正应用到大规模口语考试评分中的成果是十分有限的。如严可等人[2]采用语速、文本覆盖率和关键词覆盖率等指标对口语复述题进行评分,然而该方法缺少对句子大意的整体分析。Suyoun Yoon等人[6]采用Siamese卷积神经网络提取考生口语句子中的关键信息特征进行评分,但同样对句子级的大意没有做进一步研究。因此,要建立起一种有效的汉英口语翻译题自动评分模型仍存在诸多挑战。
本文介绍一种汉英口语翻译质量自动评分方法。我们选取语义关键词、句子语义相似度及口语流利度三个主要参量,作为评价指标来评价翻译质量。在句子级汉译英中,关键词的翻译一定要达意,汉英句子的大致含义也应准确。作为口语翻译,流利度参量也很重要,流利度也反映了译者口语整体水平[6]。在面向句子的汉英口语翻译题的评分研究方面,研究者一般会关注汉英口语翻译准确度的评测,以及答题者对整个句子的大意理解。这也是我们选择以上三个评价参量的主要原因。在中国的很多英语口语水平考试中,汉英口语翻译题是主要题型,因此汉英口语翻译题的自动评分具有实际应用意义。本文研究所涉及的数据来自广东省高等教育自学考试英语专业的口译课程考试。
在上述考试中,句子级汉英口语翻译题人工改卷的参考答案标准明确指出:关键信息的译出应占60%,句子总体理解与表达占40%。因此在构建自动评分模型时也应考虑这种评分标准。
在关键词评分方面,评分模型不仅应考虑答案给出的关键词的评分,还应考虑与关键词相关的同义词的评分[7]。因此我们应建立与答案关键词相关的同义词库,然后通过同义词与关键词相关的程度来给出关键词的得分。
在句子大意理解方面的评分,学者一般通过计算标准答卷与答案的相似度进行评分。随着深度学习技术的发展[8-9],基于深度学习的某些特定的神经网络模型能挖掘句子中更深层次的语义信息[10]。由于这一发现,一些研究者将神经网络模型运用在口语自动评分任务上,如Qian Yao等人[11]搭建的自适应深度学习口语评分系统;Chen Lei等人[12]采用长短时记忆神经网络进行口语发音评价。本文尝试将深度学习用于汉英口语翻译自动评分中的句子大意评分。
具体评分系统构架如图1所示。
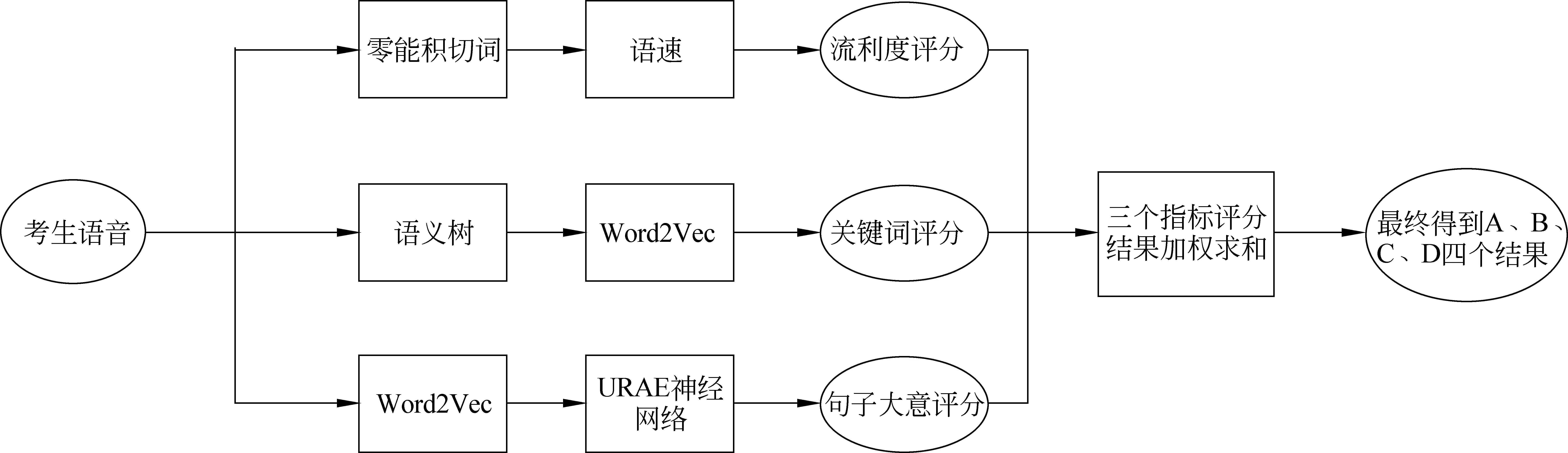
图1 汉英口语翻译自动评分系统的构架
从图1可知,在关键词汇层面评分上,采用基于同义词辨析的关键信息语义相似度评分方法;在句子大意评分上,采用可伸展递归自编码模型[8](URAE)句子语义相似度评分方法;在发音质量评分上,采用基于语速和语音分布情况的流利度评分方法。最后得分为三种评分指标的加权总和。
1 汉英口语翻译质量评分模型
1.1 基于同义词辨析的关键词翻译计算方法
从汉译英口语翻译评分标准(表2)可知,关键词的译出评分非常重要。为了准确评价答卷中的关键词译出信息情况,我们需要考虑以下两种情况:其一,参考答案中关键词的个数;其二,参考答案中关键词的同义词使用情况。因此需要判断考生的答案中是否包含题目所要求的关键信息,即考察考生对关键词及其同义词的掌握程度。为了能够判断出考生对关键词及其同义词的掌握程度,本文采用了结合Word2Vec和语义树[13]的同义词辨析方法,在词汇层面上对考生口语的关键词信息进行语义分析和评分。
从语义层面看,句子通常由“关键词”和“一般词”组成,“关键词”是指能影响句子意思的词汇,也就是口语答题要求的关键信息;而“一般词”对理解整体句子的意思不会产生决定性影响[14]。因此,根据人工评分要求,本文主要对句子中的关键词进行评分,“一般词”对句子的影响在句子大意评分时一并考虑。由于Word2Vec能够挖掘关键词及其同义词的语义,并以向量的形式表现出来,所以可以用来计算语义相似度。为了对答题关键信息评分,我们需要建立针对答题关键信息的语料库,这个语料库应包含关键信息词汇及使用频度高的同义词。为了避免同义词过多,选择同义词时应考虑考生的知识掌握范围。实验前,我们对所有关键词及使用率高的同义词进行录音,构建语音库。同时进行人工标注,构成文本语料库,供两种实验方案使用。
下面是一道汉英口语翻译题及标准答案,题目为“经济决定金融,金融又促进经济发展。”标准答案为“Economy sets the tune,whereas financial developments interact with economy.”。其中,“Economy”“financial”“developments”“interact”是标准答案的关键词。关键词及同义词结构如图2所示。

图2 语义树
在图2中,每棵右单支树中的节点单词互为同义词,相似度向右逐步降低。
本文在词汇层面上,使用同义词辨析的方法对关键信息进行评分,具体的步骤如图3所示。首先,识别出考生答题的关键词在语义树中的位置,若未能在语义树中发现考生答题的关键词,则代表标准答案的同义词库中不包含该词,该关键信息点失分;若存在语义树的节点中,就将考生答题的关键词通过先前训练好的Word2Vec模型转换为语义特征向量,然后利用余弦相似度计算出两个单词之间的语义相似度,图3中的“⊕”代表做余弦相似度的计算。最后的关键信息得分,即为该词所对应语义相似度的映射得分。

图3 词汇语义相似度计算流程图
1.2 基于URAE神经网络的句子语义相似度计算方法
1.2.1 URAE神经网络介绍
可伸展递归自编码(URAE)神经网络是由Socher Richard[8]等人在递归神经网络(图4)的基础上,结合自编码器(图5)改善而来,基于其可以提取到句子大意的有效特征,一开始主要用作语义检测(paraphrase detection,PD)。本文在句子层面,使用URAE神经网络模型进行句子语义的分析。
如图4所示,递归神经网络[15]通过树形结构来处理句子序列信息。其基本过程为:对输入的句子(X1~X5代表句子中的字或词语的语义特征)按照其网络节点的顺序两两结合产生父节点。然后继续把新生成的父节点和其他子节点再次作为输入进行处理。由底向上依次递归,直到所有的子节点都被整合,得到最后根节点的特征,而该特征可以被认为是对所有输入节点的特征提取表示。

图4 递归神经网络模型图
如图5所示,自编码器[16]被分为两层结构:编码层与解码层。其基本思路为:前者通过编码压缩输入数据的特征,得到输入数据的另外一种表示方式;后者通过解码还原出原来的输入。倘若还原的结果和输入十分接近,就认为经过编码后的特征可以代表输入的近似表示。因此,自编码器的意义是对隐层神经元的限制,而不仅仅是还原输入的数据。本文通过编码后的隐层神经元来挖掘到句子的语义特征。

图5 自编码器模型图
URAE神经网络在递归神经网络的基础上,结合自编码器,将压缩到父节点中的特征又重构出来形成子节点,并以测量原子节点和重构子节点之间的误差来评判特征提取是否有效。倘若误差过大,说明该相邻的节点合并效果不好,需要不断地遍历优化将重构误差最小的两个相邻节点相结合。可伸展递归自编码模型如图6所示。
在图6中,P代表父节点,“/”代表自编码器重构出来的子节点。在汉英口语翻译自动评分中,叶子节点(如X1,X2等)代表句子的字或词语语义特征,非叶子节点(如P1,P4等)代表组合短语或者句子的语义特征,训练模型的目标就是计算出该语义树的最优重构误差,获取到顶点(如P4)的整体句子语义特征。重构误差的计算步骤如式(1)~式(3)所示。
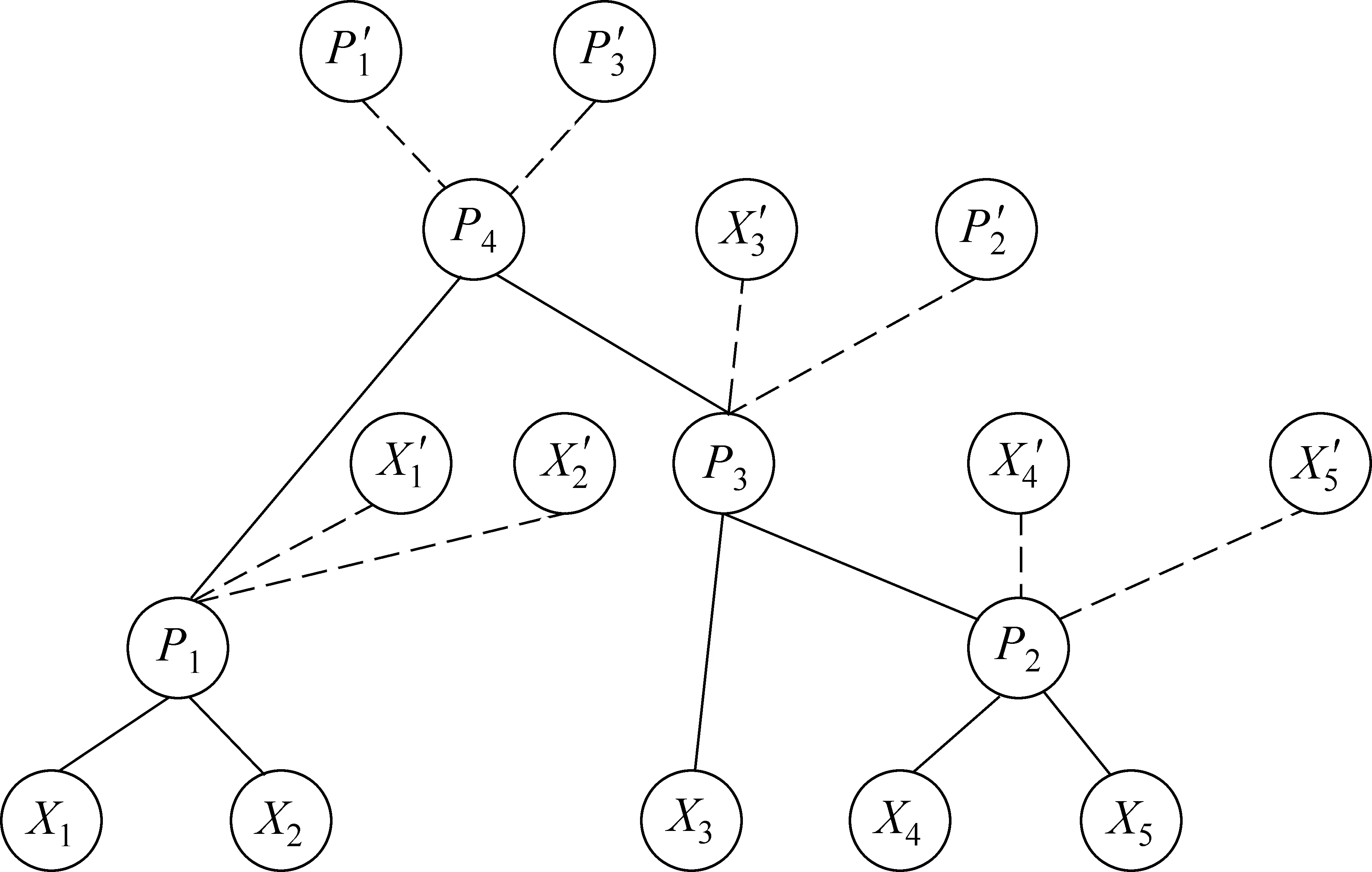
图6 可伸展递归自编码模型图
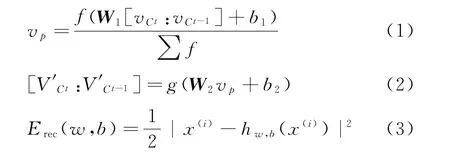
其中,每一层由子节点对生成的父节点,进行标准化处理的计算为式(1),式(2)代表重构函数,式(3)为重构误差函数。vp代表k维的父节点的向量;代表相邻的子向量的联接,并且与都为k维向量;W1和W2为参数矩阵,其维度为k*2k;b1和b2是k维的偏置项;f和g为激活函数;Erec为重构误差函数。
1.2.2 URAE神经网络的应用
本文通过URAE 神经网络模型计算句子语义相似度,从而对考生汉英口语翻译出的句子大意进行评分。具体流程如图7所示。该模型主要由三部分组成:Embedding层,URAE层和Cosine层。
(1)Embedding层
该层的作用是初始化输入的句子数据(如S1,S2)。本文使用Word2Vec[17]将句子中的词语转换为词向量(word embedding),得到每个词语的低维稠密向量(如X1,X2,Y1,Y2等),帮助解决向量稀疏的问题。Word2Vec又可以分为CBOW 模型和Skip-gram 模型[18]。一般来说,CBOW 模型训练词向量效率更高,Skip-gram 模型训练词向量准确度更高。本文采用Skip-gram 模型为神经网络训练提供更充分的语义信息。其中,Xi,Yi∈Rk表示S1,S2中词语的维数为k维。本文训练时分别采用{50,100,150}维对比。
(2)URAE层
本层将训练好的词语向量(如X1,X2,Y1,Y2等)通过URAE神经网络提取语义特征后,获得句子向量(如P1和P2)。在模型训练时,损失函数基于欧式距离和式(3)做进一步的改进,对全局所有节点的重构误差进行训练,具体如式(4)所示。

其中,在式(3)的基础上,引进m代表总共的节点个数。
(3)Cosine层
在得到汉英口语翻译中考生答案和标准答案的句子语义向量后,采用余弦相似度的方法,对两个句子向量进行匹配计算,得到句子语义相似度。图7中的“⊕”代表级余弦相似度的计算。最后句子大意的评分,即为句子语义相似度进行映射后的得分。

图7 句子语义相似度计算流程图
1.3 口语流利度评分方法
在发音层面,本文主要对考生的口语流利度进行分析。口语流利度是评阅老师能够直接评判考生口语发音能力的一个重要指标。而口语流利度主要体现为说话人的语速快慢[19],所以本文基于语速(tempo/rate)和语音分布情况进行评测,进而做出对口语流利度的评分。其中,语速特征表现为每个单词的平均发音时长。具体的评分步骤如图8所示。

图8 口语流利度评分流程图
首先,要将考生语音通过基于短时能量和过零率的双门限切词法[20](简称零能积切词),获得口语语音中的单词个数n及第i单词的时长pronounce_Timei。接着使用式(5)计算出语速特征。若该考生语速特征大于所设定的阈值,则判断为流利,进而通过分数映射函数给出流利度评分;若考生语速特征小于所设定的阈值,则判定该考生语音分布不均匀,不符合口语答题的发音要求。
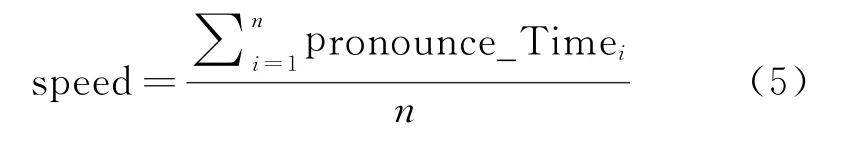
1.4 分数融合模型
汉英口语翻译自动评分模型的评测总分通过以下步骤得出:
(1)导入考生口语答题语音,通过基于零能积切词法模型计算,得到语音段的平均时长和平均停顿时长,并计算出考生的说话语速,进而计算出流利度得分。
(2)利用训练好的关键词Word2Vec向量,确定考生答题音频中的关键词与模型库中关键词的拟合度。匹配出该关键词在语义树中的位置,计算出该关键词的得分。
(3)采用Word2Vec的方法,使用URAE 神经网络模型,将语料库中所有句子的语义特征转换为向量。匹配出考生语音和标准答案的句子大意的相似度,给出该句子大意的评分。
(4)最后的评测总分即为三个评分指标的加权结果,如式(6)所示。

其中,α1,α2,α3分别为关键词得分、句子大意得分及流利度得分的权重。经线性回归预测法分析[21],权重值依次设置为0.6、0.3、0.1。最后将总分映射到A、B、C和D 等级区间中。
2 实验结果分析
2.1 实验数据
为了验证本文方法的有效性,我们进行了相关实验。考题选自2015年6月广东外语外贸大学公开学院口译与听力考试中,第一部分为汉英口语翻译题。该部分共含有5道小题(表1),每道题目总分为2分。我们收集到3 100份有精确人工评分标注的真实语音数据,每道小题共有620份语音数据,时长都在20 s以内,由620名学生在6个不同考场录制而来。为了减少评分老师主观性对评分结果带来的影响,每份语音答卷都由两位评分老师独立评分,取两位老师评分的平均分作为人工评分。

表1 翻译题目及参考答案(注:粗体字部分为关键词)
在进行关键词评分和句子大意评分前,需要将3 100条语音答卷样本人工转译成文本。同时,为了提取考生的有效语义特征,将“the”“a”“to”“this”“can”等停用词全部除去。
在实验过程中,本文将分别对5道题目进行建模与实验。最后总体评分模型的实验结果取5次实验的平均值。对于每道题目数据集的划分,采用“训练:测试=7:3”的比例进行实验。
2.2 评分细则
本文建立了由关键词、句子大意和口语流利度三项评分指标所构建的评分模型。选取三项指标的权重分别设置为:0.6、0.3、0.1。
参考一线评分老师的建议,本文结合“信、达、雅”翻译原则,以及翻译题的教师评分标准,对总分为2分的单个翻译题,设置了4个评分等级A、B、C、D。其中,评分标准和各个等级所对应的分数区间如表2所示。
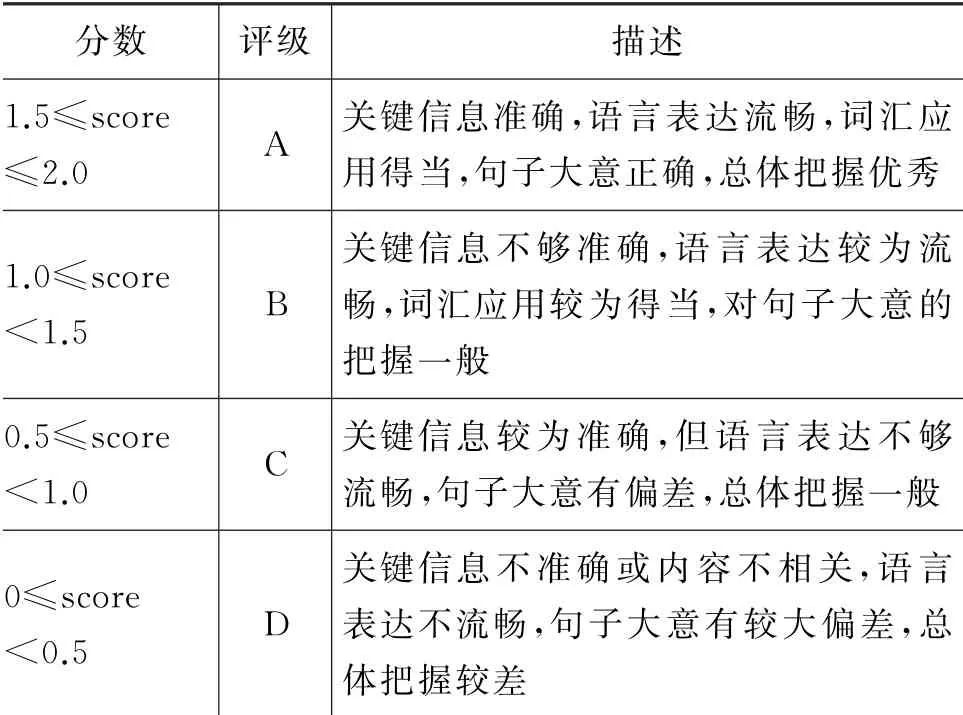
表2 评分标准及评级
2.3 实验细节
语音数据的录制参数为:单声道、22 050 Hz的采样率、16位编码。利用Word2Vec将关键词转换为词向量,词向量维度采用100 维。学习率选用0.001。URAE层的神经元个数设置为100,激活函数采用tanh函数,使用Adam 作为优化的方法,每次训练的数据量(batch)为3,损失函数如式(4)所示。
2.4 实验结果及分析
结合Chen Miao等人[22]使用的实验评价指标,本文利用一致率(准确度)和皮尔逊相关系数,来评判本文所搭建汉英口语翻译自动评分模型的评分能力。一致率和皮尔逊相关系数(r值)如式(7)、式(8)所示。

其中,xi代表模型的评分,为模型评分的均值;yi代表老师的评分,为老师评分的均值。并且,0<r<0.2表示极弱相关,0.2 <r<0.4表示弱相关,0.4 <r<0.6表示中等相关,0.6<r<0.8表示强相关,0.8<r<1表示极强相关。
为了验证本文方法的有效性,我们采用以下的对比实验方案:①口语流利度评分方法和关键词评分方法不变,在句子大意评分中不使用URAE 模型,直接将Word2Vec生成的词向量均值化获得句子语义表示并评分。②在实验方案①的基础上,将关键词评分及句子大意评分中的Word2Vec替换为另一种目前预训练效果较好的Bert模型[23]③在实验方案②的基础上,对句子大意评分时采用Bert和URAE模型进行实验。本次的实验结果如表3~表7 所示。

表3 本文模型评分与老师评分对照表(部分)

表7 本文模型评分与老师评分相关度
(1)表3为部分实验结果对照表,从中可以看出,本文模型评分的结果与老师评分的结果存在较好的相似性。表4表明,本文搭建的汉英口语翻译自动评分模型在5个题目上的平均一致率为0.855 8。其中,最高值可达到0.884 2,说明模型评分的准确度接近老师的真实评分,具有较好的有效性。由于在实际判分时老师会酌情评分,而模型评分是根据制定好的各个评价指标进行评分。因此,采用统一评分规则的模型评分具有更高的客观性与真实性,同时可以解释本文模型评分与老师评分存在着一定的差异性。
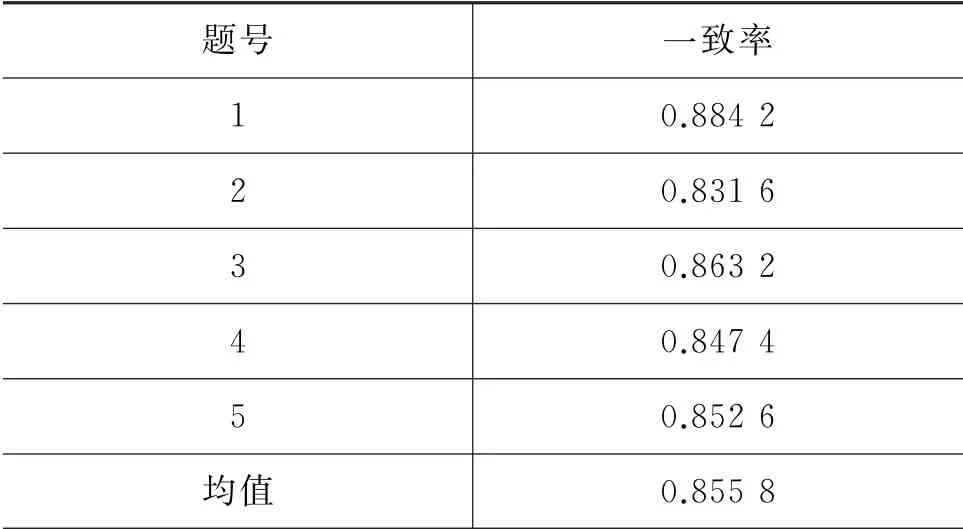
表4 本文模型评分与老师评分一致率
(2)结合表4、表5和表6来看,单纯使用Bert模型比单纯使用Word2Vec模型的实验效果提升了0.022,说明Bert确实通过多层双向解码过程在一定程度上提升了有效信息的获取。而使用Word2Vec+URAE虽然在题2和题4 上的一致率低于Bert+URAE,但在5道题目上的平均一致率取得了最好的结果。这说明,本文提出的Word2Vec与URAE模型结合效果更好,在一定程度上提升了关键词语义和句子语义的表示能力,从而提升了口语自动评分的准确性。
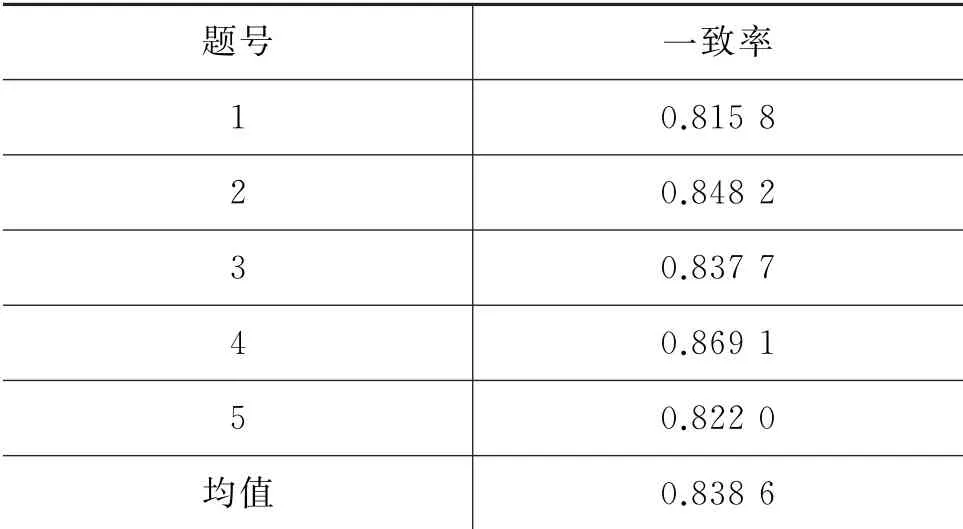
表5 基于Bert+URAE的模型评分与老师评分一致率
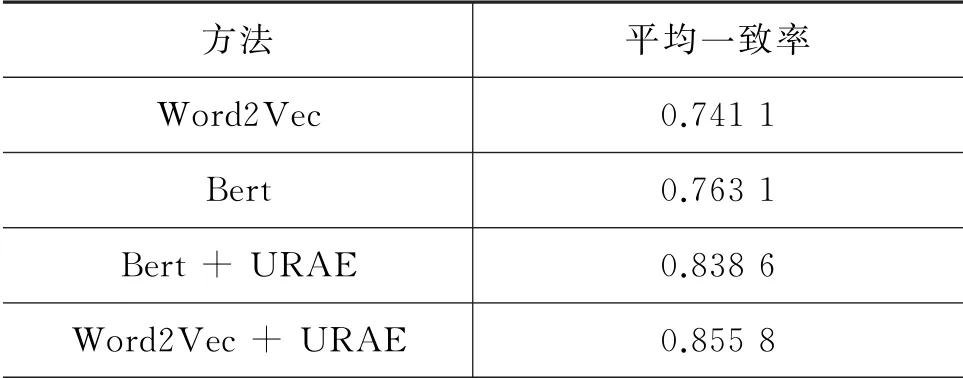
表6 不同实验方法的平均一致率对照表
(3)表7表明,本文评分模型与老师的平均评分相关性达到了0.847 9,说明模型的预测评分与老师的真实评分之间具有较强的相关性。其中,最高值可达到0.908 4,说明题5的模型评分与老师评分具有非常高的相关度。由此证明,引入了同义词辨析,URAE 神经网络模型和语速特征的评测方法,能够增强汉英口语翻译自动评分模型的评分能力。
3 结论
本文以广东省高等教育考试的汉英口语句子翻译题为研究对象,旨在分析汉英口语翻译题的评分机理,从而建立起客观有效的汉英口语翻译自动评分模型。本文研究表明,采用对答卷关键词的同义词辨析法、URAE神经网络模型对句子翻译大意的分析和基于语速及语音分布情况流利度的评分方法有较好的结果。
进一步工作的方向为:(1)语料的数量需要增大。由于目前口语翻译题难于找到公测数据,研究工作主要针对具体考试建立相关评分标准与测试数据库,从而导致数据库规模不大,这会影响神经网络模型对语义特征的提取与训练,进而影响有关语义的评分准确性。(2)语音识别模块的加入。本文在实验过程中采用人工转译的形式代替语音识别。而只有语音识别与自动评分相结合,才能够建立起完整的口语测评系统。(3)增多评价指标。本文目前没有涉及语法层面和语调层面的研究。建全评分模型的评价指标,将会使得评分机制更加全面,评分结果更加客观。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
文苑(2018年22期)2018-11-19
学生天地(2017年10期)2017-05-17
华北电力大学学报(社会科学版)(2016年4期)2016-12-01
外语教学理论与实践(2016年1期)2016-06-11
现代语文(2016年21期)2016-05-25
小天使·三年级语数英综合(2016年6期)2016-05-14
大连民族大学学报(2015年2期)2015-02-27
语言与翻译(2014年1期)2014-07-10
外语学刊(2011年4期)2011-01-22
