
基于增益统计的XGBoost提升方法研究
2021-08-09 03:23龚奎孙宇
电子技术与软件工程 2021年11期
龚奎 孙宇
(广西大学计算机与电子信息学院 广西壮族自治区南宁市 530004)
XGBoost[1]是2016年陈天奇发布的基于分类与回归树的提升树系统,在很多针对结构化数据的机器学习任务中,它达到了前沿水平。XGBoost 对于特征相互独立的数据集具有极好的效果,得到了广泛使用。XGBoost 发布后,不少学者也在探索对XGBoost 进行改进,Chen 等采用将LSTM 与XGBoost 预测结果联合预测的方法,提出LSTM-XGBoost 模型[2],并证明该方法优于单一组合模型。岳鹏等提出使用Stacking 方法集成XGBoost,CatBoost,LightGBM等的XLC-Stacking 方法[3],提高了模型的最终预测精度。
目前改进XGBoost 的方法大多采用集成其他算法的方案,对于XGBoost 和数据本身的探索尚不充分。对于数据集本身存在的在特征之间互相干涉的情况下,基于树的模型有可能过学习训练数据,容易在树中出现过拟合的噪音结构。在2018年,XGBoost 增加了特征交互约束参数[4](Feature Interaction Constraints)以抑制这一问题,该参数可以将预先知道的具有交互作用的特征集作为参数传递给模型。
但XGBoost 并没有提供获取特征交互约束参数的方法,需要对于领域本身已经有足够的了解,或者需要针对性对于数据进行预先分析处理,这些问题限制了该参数的普遍使用。本文通过对XGBoost 模型信息的分析挖掘,直接从模型中提取潜在的交互特征并应用于下一轮训练,实验表明,提取的信息有助于预测效果提升。
1 相关概念
XGBoost 的训练方式是一颗回归树训练结束后,下一颗树以上一颗树的预测值与实际值之间的残差作为输入进行训练,通过迭代提升训练,减少最终回归偏差。模型可表示为:

1.1 目标函数
对于每一颗树,训练中需要评估残差,得到残差最小的树。评估残差的目标函数由损失函数和正则化项组成。XGBoost 允许自定义损失函数,损失函数须可以二阶导。评估树的残差的目标函数为:

其中Obj(t)是第t 颗树的目标函数,是用于衡量yi和差异的损失函数,Ω(ft)是正则化项,n 是样本数量。

其中,ft (Xi)是正在训练的第t 颗树的预测结果,y(t-1)表示前面t - 1 轮的预测结果,在当前树生成过程中是常量。
将目标函数进行泰勒二阶展开,可以得到公式:

当训练第t 颗树时,y(t-1)已经确定,属于常量。移除常量,可得简化后的目标函数:
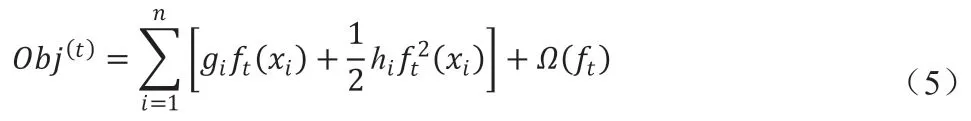
1.2 叶节点权重
函数ft(x)是每颗树计算预测值的函数,可以重新定义为:

其中,ω 是叶节点的权重,q(x)是把样本x 映射到对应叶节点的函数。
在XGBoost 中,正则项可以定义为:

其中,T 是叶节点数量,γ 和λ 是对应项的权重,作为参数传递给模型。
为了度量一颗树的好坏,代入以上公式到目标函数转换得到:其中,Ij是分配到第j 个叶节点的样本集合。

再定义Gj=∑i∈Ijgi,Hj=∑i∈Ijhi以上公式可简化为:

设第j 个叶节点最优叶节点权重为ωj*,由上式可得最优叶节点权重计算公式:

1.3 增益
在能评估一棵树的好坏之后,就可以确定树的节点如何分裂。XGBoost 采用贪心策略[5],每次选取所有特征,用于分裂当前同一深度节点。度量分裂时分别计算左子树和右子树的G 和H,则增益定义为:

仅在增益大于0 时才发生分裂,也即分裂收益大于γ 时进行分裂。
1.4 模型信息结构
在训练后的模型中,包含每棵回归树的每个节点的下列信息:
(1)分裂特征与分裂条件:分裂条件为真走yes 方向,分裂条件为假走no 方向,特征值缺失走missing 方向;
(2)节点增益gain;
(3)分类到叶节点上的训练数据的二阶梯度之和cover。
也可以看到看到每个叶节点的以下信息:
(1)叶节点权重值leaf;
(2)分类到叶节点上的训练数据的二阶梯度之和cover。
1.5 特征交互
对于函数Y=f(X1,X2),假如Y 随X1变化受X2值的影响,则说X1和X2是交互特征[6],也即存在特征交互[7]。具有特征交互的特征之间可能是任意的函数关系。特征交互典型的例子是异或[8]。

表1:异或问题
从表1 中可以看到,X1和X2分别对于Y 线性无关,无法单独根据X1或X2获取有助于判断Y 值的信息。但是在X1和X2联合的情况下,可以对Y 值给出有效判断。
1.6 特征交互约束参数
在最小化目标函数的时候,对于具有特征交互作用的数据集,训练回归树会得到不反应真实规律的结构关系。2018年,XGBoost项目贡献者讨论并实现了特征交互约束参数,发布在0.81 版的XGBoost 中。特征交互参数允许用户根据预先得知的交互特征,带入模型训练。
将真实存在的特征约束关系作为特征交互约束参数传入训练有助于得到更加稳定和准确的结果。对模型的具体约束是指,如果约束列表中的参数作为特征用于分裂回归树,则其子树的节点只能从此列表中取得。特征约束的原理是,如果多个特征联合进行预测具有更好的效果,那么就应该在构建树的过程中,将交互特征作为直接上下级联合一起对样本进行预测,从而避免因特征交互产生的噪音节点得到更好的结果。
2 改进原理与计算过程
XGBoost 的模型包含所有节点的增益,因此可以统计出各节点特征的增益之和,和所有处于同一分支并且相连的节点组合的增益之和。节点的增益之和除以节点出现次数,可以得到单个节点的平均增益;节点组合的增益之和除以同一组合的出现次数,可以得到组合的平均增益。如果发现某特征组合的平均增益,大于对应特征单独计算的增益平均值之和,则可以认为模型中,特征组合情况下的获得的增益高于非组合情况下的增益,可以将其带入特征交互参数重新训练,从而检验是否能提高模型性能。考虑到会有平均增益大于单个增益和的特征组合数量较大的情况,为了控制时间复杂度,这里将平均增益除以单个增益和,逆序排序,取前N 项。
计算过程可以分成3 部分,以下列为算法1,算法2,算法3,位于前面的算法是后面算法的基础。算法1,用于统计所有从根节点到叶节点的路径和路径的所有连通子集,算法2,用于获取平均增益比率最高的前N 个特征集合,算法3,带入特征集合到模型重新训练,取得效果最好的模型。
2.1 算法1
步骤1:定义路径列表P,P 为节点对象的集合,节点对象包含增益与编号信息;
步骤2:定义递归方法F,参数为根节点R 和节点列表L,L初始值为空;
步骤3:如果根节点R 是空,返回;
步骤4:节点列表L 添加根节点R 的增益与编号,L 为当前已遍历路径节点;
步骤5:如果根节点左子树和右子树均为空,则遍历此时的节点列表L,取得路径L 的所有连通子集,将编号与增益之和添加到路径列表P 中;
步骤5.1:以方法F 遍历根节点R 的左子树,以R 的左子树为根节点参数,L 为节点列表参数;
步骤5.2:以方法F 遍历根节点R 的右子树,以R 的右子树为根节点参数,L 为节点列表参数。
2.2 算法2
步骤1:输入模型树的集合和特征集合数量N;
步骤2:循环取每一颗树,带入算法1,取得所有路径;
步骤3:对以上过程获得的路径列表,统计相同路径出现次数,对于节点完全相同的路径,累加增益;
步骤4:对各路径用增益除以出现次数,得到平均增益;
步骤5:对平均增益从大到小排序,输出前N 个路径的列表。
2.3 算法3
步骤1:初次训练;
步骤2:训练得到的模型M1 带入算法2,得到路径列表;
步骤3:分别将路径列表转为特征交互约束参数,分别加入参数中训练得到多个模型,取效果最好的模型MB;
步骤4:将M1 与MB 比较,取效果较好的模型作为最终输出。
3 实验结果与分析
3.1 数据集
实验数据集来自UCI 数据集[9]、OpenML 数据集和Kaggle 数据集,表2 描述了实验所用数据集。数据集按训练集和测试集各50%,以类别等比例随机划分。
3.2 评价指标
对于二分类任务的评估标准设为AUC(Area Under roc Curve),对于多分类的评估标准设为Kappa 系数。

表2:数据集信息
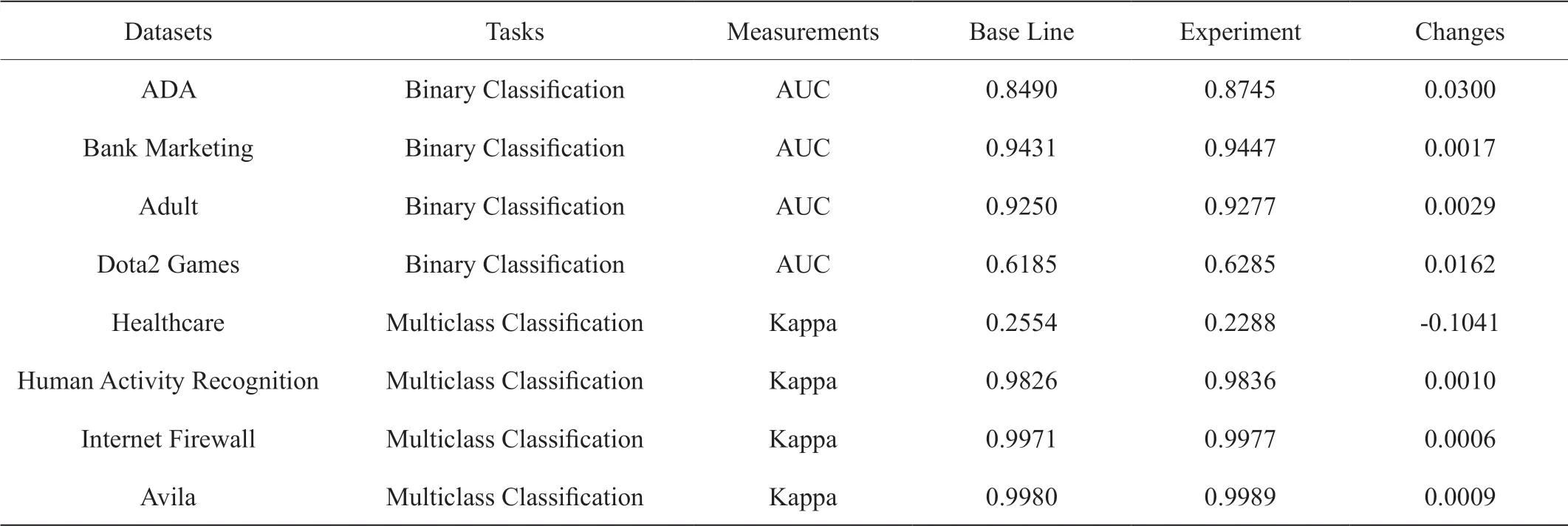
表3:实验结果对照表
3.2.1 AUC
在输出为类别概率的二分类问题中,设TP(True Positive)表示将正类预测为正类的样本数量,TN(False Negative)表示将负类预测为负类的样本数量,FP(False Negative)表示将负类预测为正类的样本数量,FN(False Negative)表示将正类预测为负类的样本数量,定义真阳率TPR(True Positive Rate):

假阳率FPR(False Positive Rate):

使用FPR 作为横坐标,TPR 作为纵坐标得到ROC 曲线(receiver operating characteristic curve)。AUC 即ROC 曲线下的面积。AUC范围是[0,1],越大预测结果越好。对于随机的预测结果,值期望接近0.5,对于高度准确的结果,值接近1。
3.2.2 Kappa 系数
对多分类问题,得出预测结果和真实结果的混淆矩阵[11],即可计算Kappa 系数。计算公式为:

其中,p0是每一类正确分类的样本数量之和除以总样本数,pe是所有类别分别对应的“实际与预测数量的乘积”。Kappa 系数范围是 [-1,1],越大预测越准确。对于随机的预测结果,值期望接近0,对于高度准确的结果,值接近1。
3.3 实验环境与参数
实验硬件电脑CPU 配置为Intel 酷睿i7 处理器,16G 内存。软件采用Anaconda 构建虚拟Python 环境,conda 版本4.5.11,Python版本3.7.9,XGBoost 版本0.81。
实验对照组采用默认参数,其特征交互参数默认为空。对比实验采用统计得到的特征交互列表作为特征交互参数,其他参数与对照组一样,实验组取具有最佳效果的特征交互的模型预测结果。
为显示效果改变程度,实验仅对寻找具有最优预测结果的特征交互过程进行测试,所有结果取4 位小数。
3.4 实验结果
实验结果如表3 所示,对于4 个二分类问题,AUC 均得到提升,对于4 个多分类问题,Kappa 系数有3 个得到了提升,1 个下降。
4 总结
实验表明,采用算法在多个数据集上有效取得精度提升。但是对于部分问题,找到的特征交互信息在对照组导致精度下降。事实上,并不是所有数据集的特征之间都具有特征交互关系,特征交互约束仅当客观存在才能提高精度,如果特征之间相互独立,那么预测效果无法得到通过寻找特征交互得到有效改善。
因此,为了确保模型精度不下降,应该将所有训练后模型结果在同一评价指标下进行对比,仅在取得提升时采用特征交互约束,最终选择精度最高的模型作为输出模型。
该方法的优势在于不影响原有训练过程,在训练时间允许的情况下,可以有效探索对模型精度的进一步提高和数据内在关系的发现,更加充分利用了XGBoost 模型本身提供的信息。
还需要进一步探索的是,特征交互约束允许以多个集合的方式传入模型,本文为了降低复杂度,仅对单一特征集合传入实验。如果采用多个集合同时传入,效果有进一步提升的空间。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
北京航空航天大学学报(2021年6期)2021-07-20
小学生学习指导(中年级)(2021年4期)2021-04-27
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
电子设计工程(2014年18期)2014-02-27
