
基于知识图谱的轨迹挖掘研究可视化分析
2021-08-09 03:23冯健文
电子技术与软件工程 2021年11期
冯健文
(韩山师范学院教务处 广东省潮州市 521041)
1 引言
分析人类世界各种移动对象的轨迹以发现隐含的行为模式和社会演进规律,一直是研究者关注的重要问题。尤其在当前物联网应用已广泛应用在社会各领域的背景下,移动对象轨迹通过射频识别技术(RFID)、传感器、日志记录等形式存储,促进了轨迹挖掘技术的高速发展。目前对轨迹挖掘的文献分析较为主观,而采用知识图谱技术可客观梳理文献的研究特征和隐含的共现关系。鉴于此,本文以国内近五年轨迹挖掘研究文献为对象,采用文献识别与科学计量分析的方法,研究两个问题:
(1)轨迹挖掘研究的演进规律;
(2)总结轨迹挖掘研究的特征,指出下一步研究重点方向。
期间,借助SATI 和VOSviewer 知识图谱工具辅助分析,增加文献分析的客观性和减少人工劳动。
2 研究设计
2.1 文献识别和收集
以中国知网(CNKI)作为数据来源和检索工具,采用高级检索方式,按照“主题”为“轨迹挖掘”逻辑检索,时间范围为2016年5月-2021年5月年共五年,检索到中文文献238 篇。剔除与轨迹挖掘研究无关文献后,得到文献232 篇。
2.2 研究方法
根据研究问题,采取文献识别与科学计量的研究方法,分析目标包括:文献特征及研究特征,如表1 所示。文献特征包括出版年份、作者及期刊来源,用于分析文献的基本特征。研究特征包括研究主题,用于分析文献蕴含的研究规律。
根据分析目的和数据类别的不同,采用合适的分析方法。文献特征采用SATI 文献分析工具分析;研究主题采用VOSviewer 知识图谱工具。
2 轨迹挖掘研究的演进规律
2.1 文献特征分析
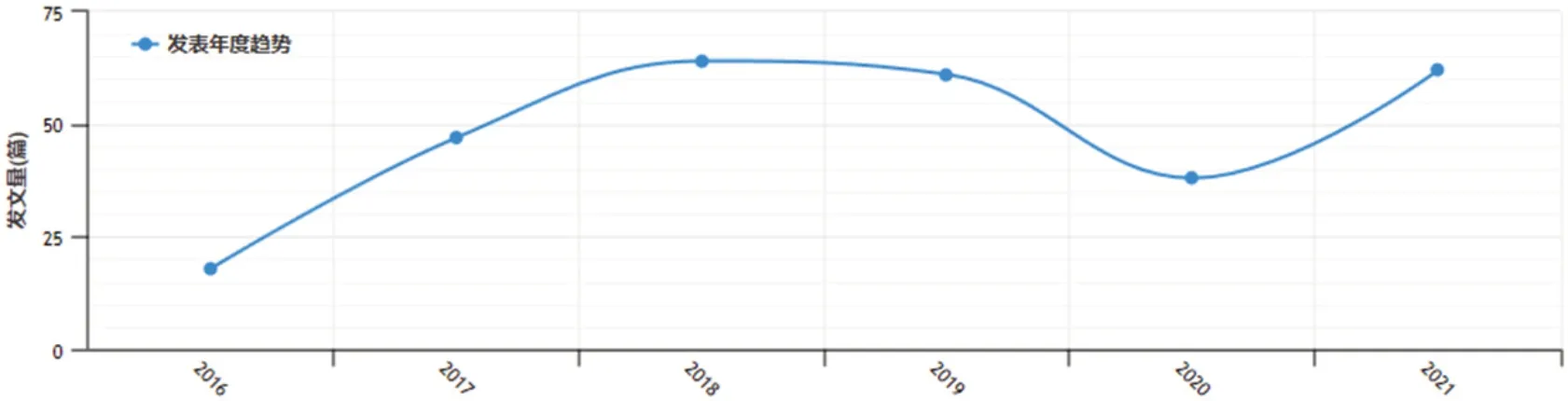
图1:轨迹挖掘年发文量

图2:轨迹挖掘研究关键词词频及共现分析知识图谱

图3:轨迹挖掘研究关键词聚类密度分析知识图谱
2.1.1 年发文量分析
对筛选文献发文时间进行统计,如图1 所示。轨迹挖掘研究发文量从2016年开始逐年增加,尤其是2016-2018年该研究领域文献数量呈现急剧增长趋势,分别是18 篇、45 篇、63 篇,反映我国轨迹挖掘研究热度处于上升趋势。
2.1.2 文献来源分析
对文献的来源期刊及载文量进行分析发现,前五名期刊载文量共17 篇,占文献总数18.46%,如表2 所示。其中《计算机应用》、《计算机应用研究》2 个期刊占文献总数11.95%,表明我国轨迹挖掘研究与社会应用联系紧密。
2.1.3 作者来源分析
对文献的全部作者分析,所在研究单位人数最多前5 名如表3所示。南京师范大学、中国科学院等大学和研究机构是轨迹挖掘研究的主要力量,作者共20 人次,占文献总数12%。另外南京其他高校如南京工业大学、南京理工大学等也在研究单位之列,表明南京高校已形成有规模的轨迹挖掘研究团队。
2.2 研究特征分析
2.2.1 关键词词频及共现分析
为提高规范性和知识图谱可理解度,需建立关键词数据字典对关键词进行归一化处理,方法包括合并名称相近关键词和含义相同关键词,得到702个关键词。图2是采用VOSviewer工具的分析结果,其中前十大高频关键词是:轨迹挖掘、轨迹数据、轨迹聚类、出租车轨迹、轨迹、语义轨迹、可视化、频繁模式、热点区域、GPS 轨迹。值得注意,频次为1 的关键词多达610 个,表明轨迹挖掘应用领域广泛、涉及关键技术多样、研究处于百家争鸣阶段。
2.2.2 关键词聚类密度分析
轨迹挖掘研究关键词聚类密度分析知识图谱如图3 所示。可发现,图谱以轨迹挖掘为热点中心,根据关键词相互的共现关系形成轨迹聚类、轨迹数据、出租车轨迹、语义轨迹等较大聚类区域,还有若干个较小聚类区域。
3 我国轨迹挖掘研究特征
3.1 轨迹聚类
研究者主要根据解决问题需要,对主流的K-means、DBSCAN等聚类算法进行改进,目标是对轨迹分类。朱敬华对传感器网络中多目标不确定轨迹,采用马尔科夫链模型表示,根据轨迹相似性改进K-means 算法进行聚类分组[1]。朱姣改进DBSCAN 算法计算分叉航道内船舶行为模式,为水上监管人员提供水域交通态势[2]。朱家辉改进K-means 算法,采用时间维度和轨迹中的空间差异性语义将交通网络划分为单个密集时间的交通网络区域[3]。赵淼佟以轨迹数据的空间属性和时间属性进行轨迹聚类分析,发现用户的运动规律和行为模式,并为用户提供不同时段的有针对性的推荐服务[4]。赵端从矿井下人员轨迹的关键位置序列数据聚类为关键区域,从而发现人员的日常轨迹,再利用关键区域和轨迹结构相似度筛选出异常轨迹[5]。张翔宇采用聚类算法从用户GPS 轨迹中自动挖掘兴趣地点[6]。
3.2 轨迹数据
相比于轨迹聚类的分类作用,对轨迹数据的预处理是实现轨迹挖掘的质量根本。由于轨迹数据类别繁多,研究者需要根据数据的特点和挖掘应用的需要,研究针对某类轨迹数据的预处理技术。朱家辉利用均值滤波器、快速排序算法修复轨迹漂移点并剔除冗余数据,提出基于双重偏移限制的轨迹分段压缩算法,识别特征点完成分段压缩以实现轨迹质量优化提升[3]。赵雨娟提出面向车间RFID生产数据的清洗模型,解决生产数据质量中数据异常和冗余问题[7]。赵梁滨对琼州海峡水域的船舶AIS 轨迹数据,采用子轨迹长度和量化压缩精度的方法,使用Douglas-Peucker 算法压缩数据量又保留原数据的交通流特性[8]。张沛朋针对巨量轨迹数据,采用时间维度、轨迹点速度和曲率属性,划分子轨迹[9]。在停留点提取的问题上,综合考虑轨迹数据的时间,速度,空间等多维属性,提出停留点预选区,张春风研究非结构化车联网大数据存储与处理技术,改进K-Means 算法对停留点预选区进行聚类提高精度[10]。岳过在室内移动对象的行为模式挖掘预处理过程中,使用Hadoop 平台与Spark计算框架将原始定位信息转换成保留轨迹中关键信息的语义轨迹序列[11]。于文利通过聚类放牧轨迹数据,得到牲畜的不同觅食、进食区域,并计算草场不同区域放牧强度以支持放牧预警机制的研究[12]。

表1:轨迹挖掘研究文献分析框架
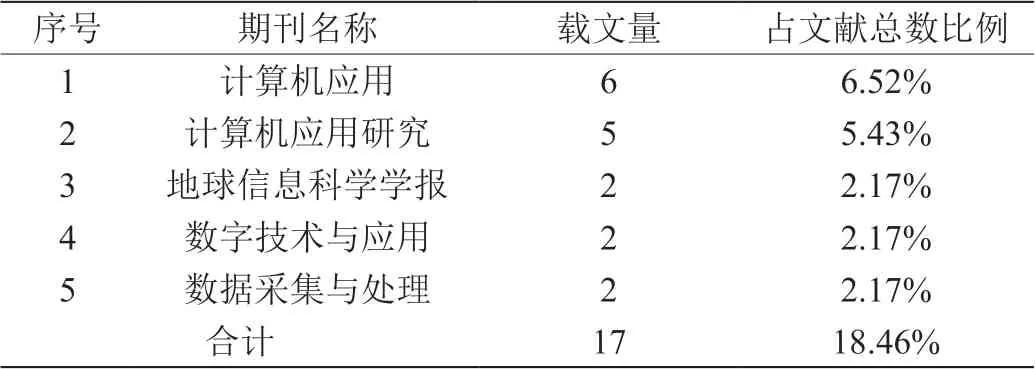
表2:轨迹挖掘研究期刊及其载文情况
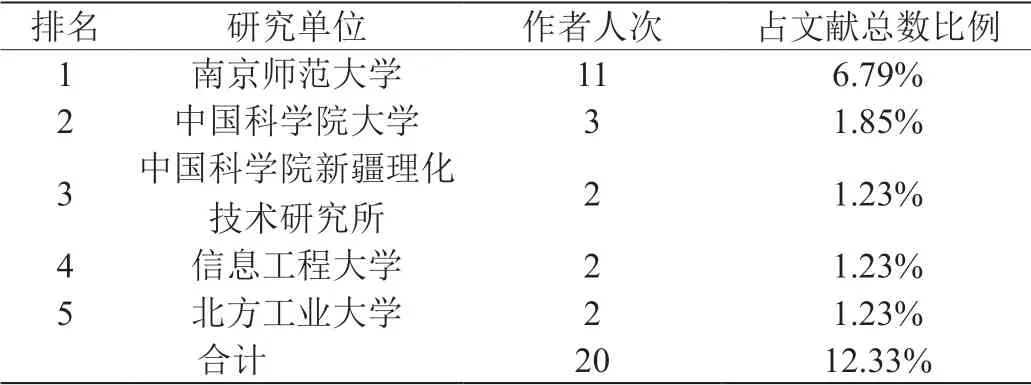
表3:轨迹挖掘研究文献的研究单位作者人次排名情况
3.3 出租车轨迹
出租车都装有GPS,成为轨迹数据挖掘在交通应用领域的研究热点。研究者主要针对司机、乘客、交通管理部门应用需求展开研究。周伦采用聚类算法从出租车轨迹数据中,挖掘城市的载客热点和载客区域,以设计行车信息推荐服务[13]。郑林江对重庆市出租车轨迹划分成网格单元,统计网格内轨迹点密度来定义城市的热点区域,进而分析重庆市居民出行行为[14]。赵玲计算西安市出租汽车载客热点区域,并以总量统计和时间排序进行区域分类,把公共汽车和出租车数据合并分析,支持完善城市综合交通运输体系。杨振娟从兰州市出租车的GPS 轨迹数据提取载客时空轨迹。姚锐基于DBSCAN 聚类统计出租车载客及乘客上车位置和时间段,为司机和乘客推荐最优匹配方案。
3.4 语义轨迹
语义轨迹是在时空轨迹上附加有应用信息,以发现蕴含的有价值行为模式。研究者主要根据应用需求语义指导时空轨迹挖掘的同时,得到更为实用的挖掘结果。赵斌综述语义轨迹研究现状与发展,重点讨论模型定义、语义标注技术、多源数据建模,认为未来应关注语义轨迹数据管理、分类和预测、流式数据挖掘、隐私保护、多粒度挖掘、评价方法等方面。周燕研究语义轨迹频繁模式提取用户停留点。吴瑕研究了近似到达时间约束下的语义轨迹频繁模式AAFP 挖掘方法。刘春采用语义轨迹频繁模式解决拼车需求问题。金莹基于“用脚投票”理论,利用语义轨迹挖掘对用户旅中的兴趣点分类,提高选址准确率、高效性及高适用性。
4 总结与展望
通过对最新的轨迹挖掘文献分析发现:轨迹挖掘研究已成为数据挖掘领域研究热点,不仅形成南京、中科院等核心研究团队,不少研究者也把支持向量机、深度学习、过程发现等方法引入轨迹挖掘研究,应用领域涉及城市交通、旅游、生产、船舶、矿井、牧场等,研究主要集中在挖掘的数据预处理、挖掘算法和结果解释。
时空轨迹是以连续的采样点构成在多个维度上综合形成的曲线,以前研究更多关注轨迹的时空分布,即运动模式,未来的研究应更多集中在语义轨迹研究,因为时空轨迹挖掘的目标是为了发展社会规律进而解决隐含的社会问题。语义轨迹中语义信息融合是研究的难点,尤其是轨迹数据预处理技术,原因是不同的应用会产生异构的轨迹数据和语义维度数据,不仅需要传统的数据抽取、清洗、融合等方法,还需要把聚类、过程挖掘等智能技术从挖掘端前移至挖掘前阶段,以提供高质量和易处理的轨迹数据。在移动对象数量方面分为单体与群体运动模式研究,在挖掘运动模式、规律和异常事件等方面都是持续的研究热点。在数据容量方面,巨量轨迹数据挖掘需要传统轨迹挖掘方法进行创新性改进,包括提高数据预处理效率、采用形式化方法进行模型验证等。同时,面对小规模数据集的边缘计算下的轨迹挖掘未来也应受到更多关注。当前在出租车、船舶、旅游等应用领域已积累较多研究成果,研发领域通用轨迹挖掘分类器系统可进一步扩大轨迹挖掘应用范围,使得研究从理论走向实践,体现轨迹挖掘研究的重要意义。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
开放教育研究(2020年2期)2020-03-31
现代装饰(2018年5期)2018-05-26
电子测试(2017年15期)2017-12-18
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
现代语文(2016年21期)2016-05-25
电子设计工程(2015年6期)2015-02-27
大连民族大学学报(2015年2期)2015-02-27
