
基于知识图谱的在线课程资源个性化推荐模型研究
2021-08-09 03:23杨夏
电子技术与软件工程 2021年11期
杨夏
(湖南科技职业学院 湖南省长沙市 410004)
与传统的面对面学习方式相比,网络学习是提供终身教育的革命性方式。然而,不同的学习者有不同的学习风格、学习目标、学习经历和其他偏好,传统的“一刀切”的学习方法已经不能满足学习者的需要。目前,越来越多的个性化系统被开发出来,试图解决影响学习结果的个性化学习过程。
Google 于2012年5月推出了“知识图谱”(Knowledge Graph, KG)技术,它创新了表示、管理和组织知识的方式,赋予了传统互联网技术新的能力。以直观的、结构化的呈现形式提供知识服务,将传统的课程篇章学习(网页互联)转换为对知识点及其相互之间关系(知识互联)的学习,可以极大地提升学习效率与学习体验。本文将知识图谱应用于个性化学习,开发一种基于知识图谱的适用于个性化学习的推荐系统,根据学习者概况、学习对象和学习历史等推荐学习资源和学习路径。
1 基于知识图谱的个性化学习系统
1.1 系统架构
系统由三个主要部分组成,分别是:学习者建模组件(对学习者资料建模);课程资源管理组件(主要包括课程本体建模和学习对象本体建模);个性化推荐组件(支持个性化学习资源推荐和个性化学习路径推荐)。
系统设计了四个数据库,分别是学习者概况数据库、学习历史数据库、课程本体数据库和学习对象数据库。学习者概况数据库包含学习者的个人信息、学习偏好和当前学习状态。对于学习历史数据库,其内容来源于以下几个方面:在学习过程中,系统记录了每个学习者的在线行为及其相关实体,包括知识点ID、学习目标、学习时间、学习对象ID、学习水平和学习者正在进行的活动。课程本体数据库中存储课程知识的组织和内部关系的明确定义。学习对象数据库中存储学习资源的内容和一些形式化的语义描述。
1.2 系统组件
1.2.1 学习者建模组件
学习者建模组件收集学习者个人信息,在学习过程中对其进行建模和更新。事实上,学习者概况代表了学习者的兴趣、偏好、背景、需求和知识。为了描述个人信息和学习偏好,可以在FSLSM 的基础上构建了leaner 本体。该模型有四个维度来区分学习者的风格,即感知、输入、处理和理解。
当学习者首次注册该系统时,系统用学习风格指数(ILSs)来测试他的学习风格。另外,系统还可以通过观察学习者在学习过程中的行为和分析学习者的日志文件来调整学习者学习风格的记录条目。
学习者建模组件通过收集学习者个人信息为最终集成的概要文件建模。主要考虑了以下个性化参数:学习风格、教学信息、先决条件、目标、计划、活动、媒体偏好、学习水平、界面偏好等。为了得到一个适用的知识图谱理解,系统在个性化参数的基础上形成了学习者知识图谱。同时系统为学习者档案设计了四个重要的个性化参数,分别是:学习级别(低,中和高);精通级别(知识,理解和应用);学习方式(知觉,输入,理解和处理);当前学习知识点ID。
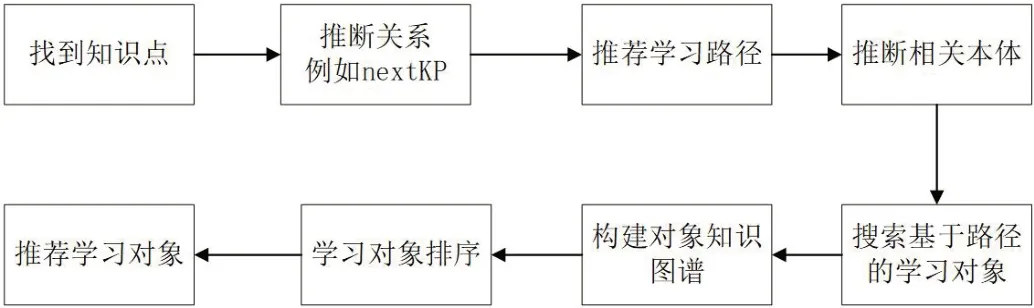
图1:推荐流程
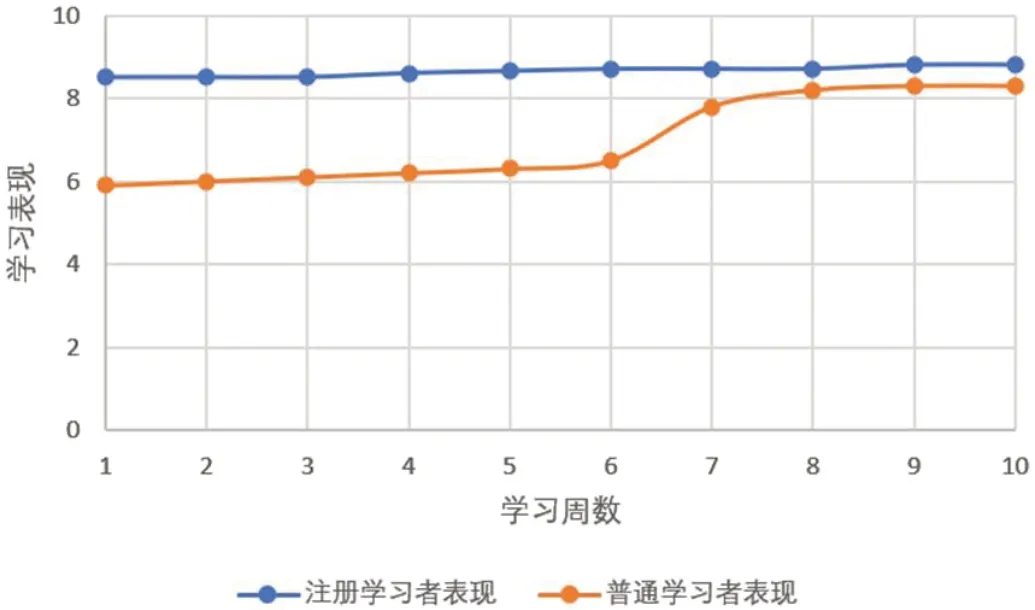
图2:注册学习者和普通学习者的表现
在建模过程中,将显式方法和隐式方法相结合。显示方法采用问卷调查的方式,建议用户在首次注册时提供个人学习信息。然而,学习者可能不能准确地表达自己的兴趣,而且学习者的兴趣可能会随着时间的推移而改变。因此,内隐方法是通过观察学习者在学习过程中的行为来实现的。学习者建模组件监控和记录学习者的学习活动和学习进展,从而可以同步更新学习者概况。
1.2.2 课程资源管理组件
课程知识图谱描述与课程相关的学习资源,实现课程资源的共享。课程本体的构建是基于教学方法、学习者概况和学习者的特殊需求。课程资源管理组件对课程本体和学习对象本体进行建模。课程一般由章节组成,每个章节有一个或多个知识点。一个知识点包括一组学习对象。
(1)需要在系统中创建的课程。课程包含课程名、课程ID、课程描述以及课程所包含的章节。
(2)创建章,包括章节名称、章节ID、章节描述,隶属于哪门课程,难度等级以及包含的知识点,同时还需要建立不同章节之间的关系,例如前一章、后一章的关系、完成学习需要遵循的前导章节、后续章节的关系等
(3)创建知识点(PK),包括知识点名称、知识点ID,同时将知识点和学习对象集合成一个知识点,与其他属性一起,建立不同领域知识点之间的关系:从一个知识点可以链接到前一个知识点和下一个知识点的关系;以及完成学习需要遵循的前导知识点、后续知识点的关系等。
为了更好地理解课程资源的知识图谱,针对个性化学习平台提供的资源建立了学习对象知识图谱,将课程对象划分为6 个子本体,分别是应用学习风格、难度级别、访问率、文件大小、应用知识点和媒体类型。课程资源管理组件使用基于课程本体的标注工具对学习资源进行标注,被标注的实体作为学习对象本体的实例;这些与资源对象相关的信息都存储在学习对象库中,因此可以在学习过程中自动丰富学习对象库。
1.2.3 个性化推荐组件
注册时,学习者将收到学习风格索引(ILSs)和个人信息表,以确定其学习风格和个人信息。当学习者学习到一个新的知识点时,系统会找到他以前学习过的与当前知识点相关的前导知识点的学习信息,并对其进行预测试,以估计出适合他的学习资源和学习路径。
事实上,推理、比较和推荐三个功能可以被整合在个性化推荐组件中。当然,推荐机制是基于课程本体和学习对象本体的。当学习者完成对某个知识点的学习并开始学习下一知识点时,个性化学习系统将首先从学习者资料数据库中搜索当前知识点,然后推理引擎将在此基础上结合课程本体数据库中的语义关系推断其相关知识点和合适的路径;在接下来的过程中,系统的搜索引擎还可以从学习对象数据库中搜索相应的学习对象,并基于学习本体对每个学习对象的语义相似度进行评估,最后系统将学习对象进行排序,对学习对象进行整理,推荐三个结果给学习者。
定义1:level(学习者的学习水平):假设level = {L1, L2, L3}是一组学习水平,包括低、中、高三个学习水平。例如,L1 表示低,量化为-1。
定义2:Lmastery(学习者掌握的程度)。假设LMastery = {M1, M2, M3}是一组学习者精通程度的集合,其中包括前面提到的知识、理解、应用三个级别。例如,M1 表示知识,量化为-1。
结合学习者简介中的两个个性化参数,根据学习者的学习水平和掌握水平计算所需学习对象的适当难度水平得分。公式描述如下:

LD 表示为学习对象做适当推荐的难度水平。
定义3。Dlevel(学习对象的难度)。假设DLevel = {D1, D2, D3}是一组课程材料难度等级,包括三个不同的难度等级。D1 表示容易,量化为-1;D2 表示中间,量化为0;D3 表示hard,量化为1。
结合学习对象的LD 和难度等级,计算出DiあcultySim 的语义匹配值(diきcult Similarity value)。公式描述如下:
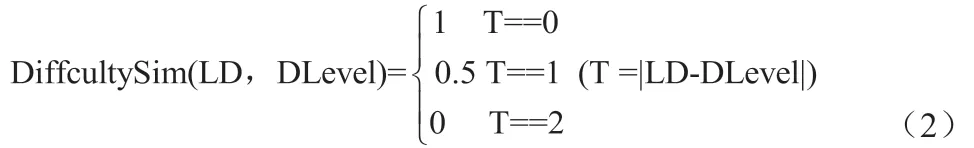
DiあcultySim(LD, Dlevel)表示学习对象的推荐难度语义值。公式(2)计算输入的语义匹配值和感知的语义匹配值。它们分别基于公式(3)和公式(4)。
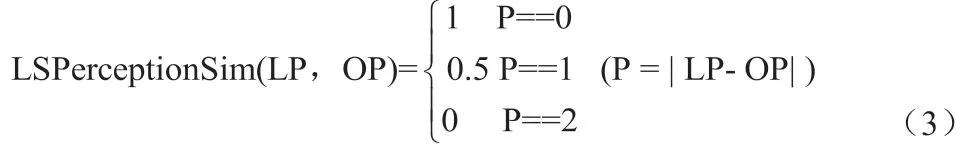
LP 是一组感知(敏感-直觉)学习风格维度的价值,OP 是学习对象的感知维度的价值的集合。
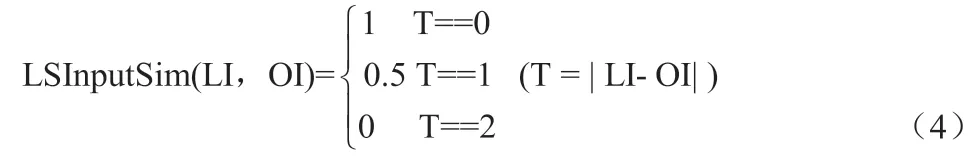
LI 是学习者学习风格的输入(视觉-言语)维度价值的集合,OI 是学习对象的输入维度价值的集合。
系统还考虑了教学方法、知识点结构和学习对象特征来推荐学习对象或学习路径,推荐算法的主体由四部分组成:
(1)相关知识推理。该部分将基于课程本体库,按照本体的左、右、上、子层次,以及nextKP 关系推断本体项,左右层次还可能包括具有nextKP 关系或previousKP 关系的本体;
(2)学习路径构建。根据nextKP 关系或左/右兄弟级的推断结果计算学习KP 路径,然后根据学习历史库对其进行调整,形成KPs 序列;
(3)语义相似值评价。对学习者轮廓参数与学习对象的语义匹配值进行评价;
(4)学习对象排序。将学习对象按照语义相似度值进行排序,并向学习者推荐学习对象。推荐过程如图1 所示。
通过匹配学习者的学习者轮廓参数和学习对象,基于提出的推荐算法推荐个性化的学习路径和学习对象。当学习者进行一个学习过程时,系统会通过观察学习者在学习过程中的行为来更新其学习轮廓的参数,再根据新的学习轮廓对学习对象进行推荐。
2 推荐模型的验证
为了验证个性化推荐系统是否有助于学习过程,设计并实施了一系列的实验。在超星学习平台的《Java 程序设计》课程的学习过程中,选取了60 名参与“数据类型”和“运算符与表达式”一章学习的学生进行调查。目的是分析因变量即学习者的表现对学习效率的影响。作为课程的要求,学生必须参加课后测试,以测试成绩作为衡量学习者学习效能的指标。与没有向系统提供个人学习信息的普通学习者相比,注册学习者的整体表现良好。图2 显示了比较结果。
图中x 轴是10 周学习者的平均表现。上面的线表示注册学习者的平均表现。下面的线表示普通学习者的平均表现。分析表明,学习者学习成绩的提高与其学习时间有关。学习成绩是系统质量的一个指标。
3 结论
研究提出一种基于知识图谱的个性化学习服务,以促进学习者的学习绩效和学习成就。系统用感知、输入、处理和理解四个重要特征描述学习者的概况和学习对象;用知识图谱支持语义推理和匹配机制;推荐算法的设计是通过比较学习对象的特点和学习者的个性化参数,从而将个性化内容推荐给学习者;根据知识结构向学习者提供学习对象和学习路径的动态建议。另外系统还可以更新学习者的学习概况参数,分析学习者在学习过程中的行为。实验结果表明,基于知识图谱的个性化推荐能够提高学习者的学习效率。
基于学习者知识图谱的自动学习是个性化学习系统的一个挑战,这样的系统可以更有效地预测学习者的学习兴趣和需要。未来,可以继续优化学习者档案数据库、课程本体学习数据库和历史数据库,生成,多模知识图谱,为每个学习者提供个性化学习内容,提高他们的满意度。同时个性化学习系统的隐私问题应引起重视。
猜你喜欢
哲学分析(2023年4期)2023-12-21
睿士(2023年2期)2023-03-02
少先队活动(2020年12期)2021-01-14
中国音乐学(2020年4期)2020-12-25
中成药(2017年3期)2017-05-17
厦门理工学院学报(2016年1期)2016-12-01
文学教育(2016年27期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
杂草学报(2012年1期)2012-11-06
