
多项式函数拟合实现汉语声调的语音合成
2021-08-06 02:32李建文王咿卜
西安科技大学学报(社会科学版) 2021年3期
李建文 王咿卜
摘 要:汉语语音的声调是个人语气与情感状态最直接的表达,是体现汉语语言状态最重要的特征之一。为了使得语音合成的逼真度得到有效的提高,讲话者的话语更加具有区分度,通过加入声调参数特征实现语音语调变换,以期成为情感识别和语音识别的准确度最有力的助推剂,弥补语音合成结果在情感特征以及语音演唱方面的不足。分别对汉语阴平、阳平、上声、去声采用基频提取的方式进行声调的分析、研究,将得到的基频曲线采用多项式函数拟合的方法对汉语4种声调进行重新构建,从数学角度对汉语声调进行分析、重构,采用三角函数曲线模拟随时间变化的语音基频曲线,根据共振峰频率将曲线进行叠加,达到了95.91%的满意的识别结果。结果表明:采用多项式函数拟合方法实现汉语4种声调的语音合成,更好地还原了语音的数学本质,使得抽象化的语音表现得更直观可控。
关键词:语音合成;函数拟合;基频提取;汉语;声调;情感
中图分类号:TN 912.33
文獻标志码:A
文章编号:1672-9315(2021)03-0506-10
DOI:10.13800/j.cnki.xakjdxxb.2021.0316
Abstract:The tone of Chinese speech is the most direct expression of personal mood and emotional state,and it is one of the most important characteristics of the state of Chinese language.In order to effectively improve the fidelity of speech synthesis and make the speakers speech more distinguishable,the tone transformation is realized by adding tone parameter features,so as to become the most powerful booster for the accuracy of emotion recognition and speech recognition,and to make up for the shortcomings of speech synthesis results in emotion features and voice singing.The high and level tone,rising tone,falling-rising tone and falling tone of Standard Chinese are analyzed and examined by the way of fundamental frequency extraction.Finally,the method of polynomial function fitting is used to reconstruct the four tones of Chinese.The four tones are analyzed and reconstructed mathematically.Trigonometric function curve is used to simulate the fundamental frequency curves of Chinese tones with time.According to the formant frequency,the curves are superposed with the recognition result 95.91%.The synthesis results show that:the polynomial function fitting method may be used to realize speech synthesis of four tones in Chinese,which can better restore the mathematical nature of the voice and make the abstract speech more intuitive and controllable.Key words:speech synthesis;function fitting;fundamental frequency extraction;Chinese;tone;emotion
0 引 言
语音是人与人传递信息和表达情感最有效的方式之一。中国汉字大约有十万个,是一种独特的声调表意语言[1-2]。在计算机对字符进行编码过程中,汉字在众多语言中所占存储空间最大,导致编码过程中极为不便,但若从拼音角度出发,按不同声调对汉字进行归类,却可以把汉字数目缩减到约原始容量的1/4,极大的缩减了工作量且保证了语音的逼真度。在如今人工智能高速发展的时代,语音识别及语音合成要做的不仅是算法准确度的提高,更应该注重其智能化和逼真度[3-4]。语音识别与合成的结果固然重要,但忽略了不同情景下语音相关合适声调的选择,就难以真正实现智能化。个性化的语音合成,需要把话语中声调所表达的情感状态作为考察的特征之一[5-8]。同样的语言,不同环境、情绪,会使语音发出者使用不同声调。在医学中,针对听力障碍者推出的人工耳蜗产品也并未考虑声调、语调等特征的感知[1-2]。因此,从数学角度出发,考虑汉语4种声调的特征参数以及之间参数的变换很有必要。
刘梦媛设计了基于HMM的语音合成系统,选取缅甸语事物声母及带声调事物韵母作为合成基元,解决了变音和变调问题[9];王国梁设计了端到端的语音合成系统Tacotron 2,在语料不足的情况下使用预训练解码器,并通过多层感知机代替变线性变化对停止符进行预测[10];宋刚基于Target模型进行语调分析,总结了4种声调的基频曲线变化规律,采用分段拟合方法,将各个声调分为两段来研究,拟合过程中所需特征参数有各段音调的斜率、音高变化的调域及所占时间[11];薛健采用线性多项式进行声调模型的构建,主要从归一化的规范模型出发,建模的参数需要从原始语音得到中值频率、不同音调基频变化的调域、同一音调但调型不同的变化调域[12]。上述研究中,前两者基于深度学习进行语音合成,但深度学习需要极大容量语料包,过程繁琐,且失去了对语音音调的数理本质的探究,而基于Tacotron的方法现在更适合对英语的处理,目前对汉语等多文字的语言应用尚不成熟。后2篇论文从基频轨迹出发,讨论了基频曲线与汉语4种音调的关系,并未涉及到基频轨迹拟合4种声调在语音合成方面的实际应用。文中研究旨在从汉语4种声调的角度出发,基于归一化模型的思想,研究并提取汉语4种声调基频轨迹之间的共性,采用高次多项式对其进行拟合,最终以函数形式实现一种音高和音长变化可控、所需参数少且适应于各种发音的声调变换模型,以期在语音合成、情感分析领域对语音逼真度和情感度的提高方面提供参考,以及在医学领域对人工耳蜗的构造和声调康复训练方面提供参考[1]。
1 汉语声调规范
1.1 发音原理
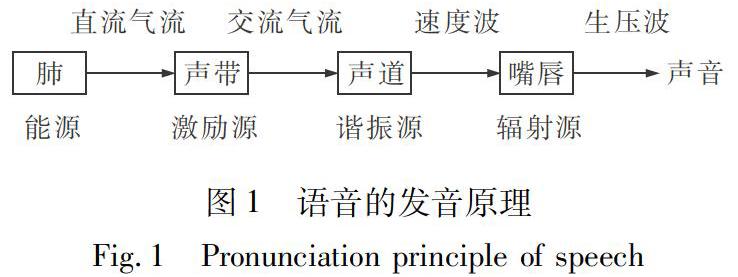
声音的形成,主要由肺、气管、喉和声道等器官参与,语音发音原理如图1所示。空气通过肺器官输出直流气流,产生发音的动力,进入喉,喉部位的声带作为声源,产生振动,输出交流气流,再通过声道对交流气流产生谐振,对声音进行调整,从声道输出的速度波最终经过口唇辐射输出声压波,产生了人耳中听到的声音[8]。
从图1可得,声音的发出主要是由声带周期性的振动产生。无论是汉语还是其他语言,语音都可按照声带的参与分为浊音和清音。浊音的发出伴随着声带的振动,清音是气流与空气摩擦产生,没有声带振动的参与,因此,从浊音角度出发进行语音声调研究。
1.2 五度制音高标记
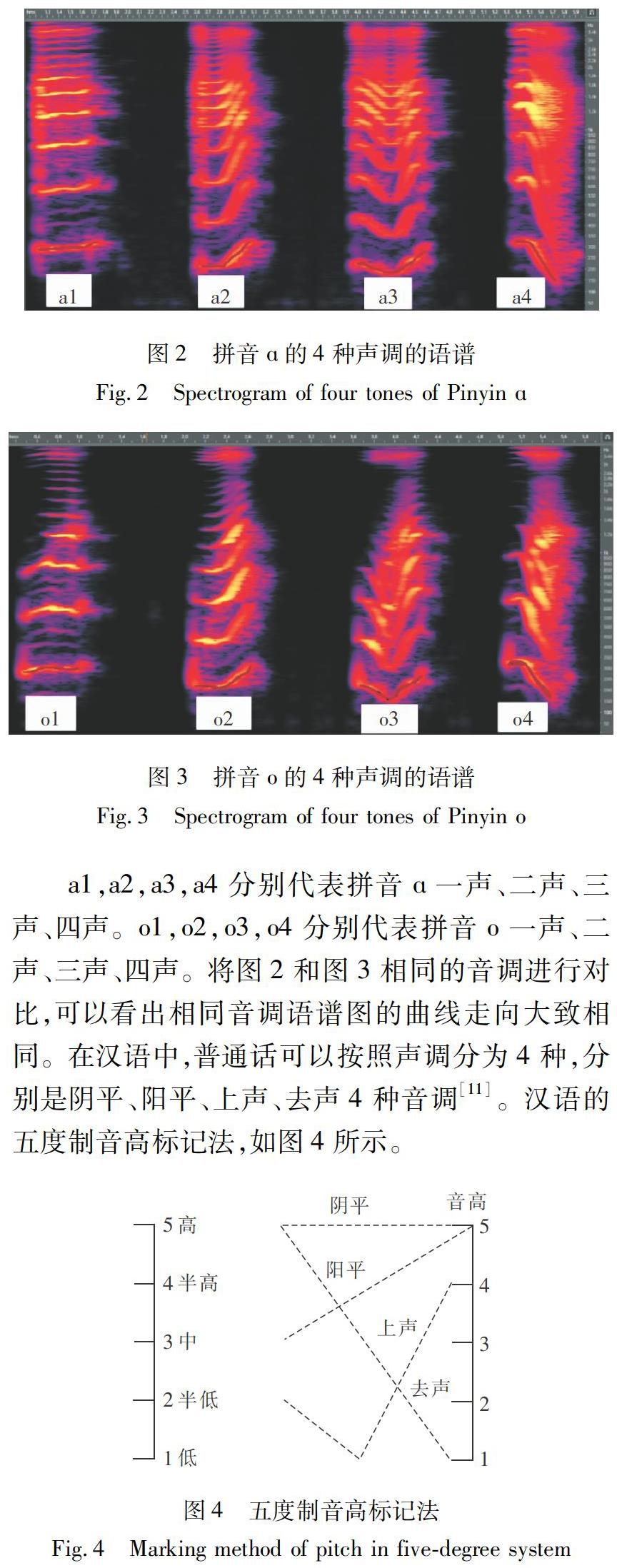
语言之所以能够体现人类的情感,最主要的特征就在于说话人对于声音声调的选择。相同的话语,不同的抑扬顿挫也会使得情感的偏重点有所差别。虽然每个人说话的腔调与讲话节奏都不同,但相同声调在走向上都是大体一致的,拼音ɑ和拼音o的4种声调的语音频谱图(称语谱图),如图2、图3所示。
a1,a2,a3,a4分别代表拼音ɑ一声、二声、三声、四声。
o1,o2,o3,o4分别代表拼音o一声、二声、三声、四声。
将图2和图3相同的音调进行对比,可以看出相同音调语谱图的曲线走向大致相同。在汉语中,普通话可以按照声调分为4种,分别是阴平、阳平、上声、去声4种音调[11]。汉语的五度制音高标记法,如图4所示。
从图4可以看出,五度最高,一度最低,根据声调的不同,选择的音高也不同,每个汉语都有其对应的音调,即相应的音高走向,但相同音调曲线走向具有同样的共性。
1.3 基頻
在分析语音信号时,主要考察2个重要的参数,其中之一为基频。已知声音的发声源是由声带的周期性振动产生,声带一次的开启与闭合称为一个周期,这种周期的倒数称为基音频率(简称基频)[8,13-14],人们所说的声调指的是基频关于时间的曲线。在语谱图上,横坐标为时间,纵坐标为频率,基频指的是位置最低的一条横线对应的纵坐标的值,该值称为基音频率[15-17]。
提取基频,首先对语音信号进行加窗与分帧的处理,连续信号被分为时域离散信号,m为起始时间量,得到第i帧的语音信号为xi(m),长度为M,对第i帧的语音信号xi(m)进行自相关运算[17-18],得到Ri(k),见式(1)。
式中 k为时间的延迟量;N为语音信号经过分帧处理后每一帧的长度;xi(m+k)为移位k步的语音信号。
已知周期性函数进行自相关计算后,得到的函数同样具有周期性,一个周期内自相关函数图像为递增函数,在周期的整倍数位置处获得最大值[18-20]。由于语音信号的基频具有周期性,周期值为P,因此采用自相关计算得到的函数也具有周期性,周期仍为P,且在P的整倍数位置处自相关函数会达到最大值max(Ri(k)),见式(2)、式(3)。
从式(3)知,当k=0时,R(P)为最大值[18]。根据这一原理,采用式(1)进行对语音信号进行自相关函数运算,在R(k)中通过寻找最大值的周期性来确定每一帧语音信号的周期值P[15]。
1.4 共振峰
语音信号另一个重要的参数为共振峰。在发音过程中,基频由声带振动产生,由于传输到声道发生谐振会产生各次谐波,这些谐波同一时刻所对应的频率值为相应基频的整倍数[8]。在语谱图上,各次谐波有亮有暗,亮区域的波对应的频率值便是共振峰的频率值[16]。从图1可知,当不考虑口唇辐射作用时,语音信号是由n时刻的声门脉冲激励u(n)(即基频的周期信号)经声道响应v(n)滤波得到,即
由式(5)可得,在倒谱域中,声门脉冲激励与声道响应两者相分离[21-22]。为了提取共振峰,采用倒谱法来获取共振峰的频率值,具体操作如下。
x(n)是一个长度为M的语音信号,将第i帧的语音信号xi(n)进行N点傅里叶变换得式(6)
将式(8)中的窗函数与倒谱序列(n) 相乘得到hi(n),见式(9),再进行FFT变换得到Hi(k)包络线,见式(10),N为傅里叶变化的区间长度 N≥M,在包络线上取最大值,即得共振峰频率值[22-24]。
某一帧信号进行共振峰提取步骤,如图5所示。最终获得的一声拼音ɑ语音包络线,如图6所示,虚线对应的横坐标的值为共振峰频率。
2 四声声调分析
2.1 声调提取
从图2、图3可以看出,语音的声调由基频曲线的频率走向决定,因此采用基频提取的方式对声调进行分析。实际情况下提取出来拼音ɑ的4种声调基频散点图,如图7所示。
从图4与图7对比可得,实际情况下提取出来的四声调散点图与理论上的音高走向差异很大。主要区别有以下几点:
1)阴平声调的基频走向并不是简单的直线,在开始与结束位置存在小幅度的起伏变换。
2)实际情况下,阳平声调的基频变化值由起初F0·45到最终F0,与理论上F0·35到F0不同。曲线趋势分为上升段与下降段,拐点更接近前端[11]。
3)实际情况下,上声声调的基频变化值由起初F0·35到F0·15再到最终F0,与理论上F0到F0·15不同。曲线趋势分为上升段和下降段,拐点位置居中,其幅度变化比阳平变化幅度大[11]。
4)实际情况下,去声声调的基频变化值由起初F0·65到最终F0·35,与理论上F0·25到 F0·15再到F0·35不同。曲线趋势变化快,时间短。
为了使得2.2节的语音合成更具有逼真性,根据理论与实际相结合的方式进行语音声调的函数拟合。
2.2 声调拟合
2.2.1 函数最高次数选择
为了使得拟合曲线更接近实际情况下的声调,采用n次多项式对实际情况下提取出来的各个音调基频进行拟合。
式中 yl为第l音调的拟合结果(l=1为阴平,l=2为阳平,l=3为上声,l=4为去声);i为次数;ai为次数为i次的系数;x为时间序列;ai为x的系数。
对于次数n,由多项式性质可得,当n选择越高,函数拟合效果越好,误差越小,但过高会导致过拟合越来越严重。为了防止过拟合且保证有较小的误差,统一采用相同的有限次数对4种声调进行拟合。在4种声调中,由于上声声调的基频曲线变化最复杂,因此选择上声调为例进行不同次数拟合,表1为多项式不同次数拟合结果。
综合分析各种次数的拟合结果,确定了当次数n大于等于4时拟合效果较好,由于当n大于4时,各项次数的系数值过于大,基本在e+04以上,且拟合效果的提高程度很小。因此,在拟合函数时,选择n=4来进行函数拟合,不仅可以有效的保证了声调的匹配程度,而且简化了参数,减小了运算量。不同拼音的四声调走向有其共性,选择n=4来进行拟合,也可以更好的使拟合函数适应不同的语音,避免过拟合。
2.2.2 函数系数
由于采用多项式函数进行曲线拟合,因此在拟合过程中,采用最小二乘法进行n次拟合。
2.2.3 拟合步骤
由于语音波形可以分解为多个三角函数,同样,也可以经过三角函数的叠加构成语音波形。三角函数的频率为基频,其各次谐波为基频的整倍数级,三角函数的幅值为基频及各次谐波的强度,由此,进行曲线拟合,如图8所示。
根据图8流程,可将声调合成分为以下几步:
1)将获取的基频连续曲线y(t)进行预处理,首先对声调经过分帧处理,得到离散点,初始横轴位置为n0,声调频率最高位置为y0,将曲线移至横轴初始位置y(n-n0),为使得拟合函数统一并且方便处理,将曲线纵轴初始位置设置为0,即y(n-n0)-y0,得y0(n)。
2)为了使拟合函数能够根据实际情况进行音高控制,将得到的n时刻的y0(n)进行归一化,让曲线的频率最高值为1,最低点为0。根据式(15)得y1(n)。
3)对y1(n)采用二项式定理确定多项式的系数,得到拟合函数。
4)由于音调的频率变化差值较大,因此需要对拟合函数进行纵轴的扩频以实现真实的幅度变化,通过获取原始语音的音高差
max(y(n))-min(y(n))来对拟合函数进行扩频,以实现正确的音高变化,见式(16)得到y3(n)。
5)扩频之后的拟合函数y3(n)与实际曲线y(n)的音高仍存在差异,因此要通过移位使得拟合函数的初始频率达到原始音频的初始频率,由拟合函数y3(n)的中值频率y3c与实际曲线y(n)的频率中值yc的差值决定移位量,更好的保证了合成的基频曲线不受原始语音基频两端不稳定点的影响。最终由式(17)得到拟合结果y41。
将拟合结果进行语音参数读取,得到声调变化的时域信息(初始位置为t0,结束位置为t1),采用矩形窗进行时域截取,见式(18)。为了使得声调变化时长可控,设最终发音时长为t2,fs为采样率,N为语音信号分帧后的长度,进行扩展最终得到y4(n),见式(19)。
2.2.4 Pitch模型
通过上述步骤依次可得4种声调的拟合函数模型的参数分布及拟合结果,见表2。
从表2可得,阴平的基频曲线变化幅度较小,阳平次之,上声和去声的基频曲线变化幅度较大。根据最终得到确定系数与极限值1相比可得,4次所多项式进行语音基频拟合方法可行。
3 实验及结果
根据表2中4种声调的拟合函数参数,令发音时长为1,基频的频率最大值为300 Hz,最终得到4种声调基频发音曲线,如图9所示。
从图9(a)可得,阴平的曲线在实际情况下并不是单一的直线,在最高频率300 Hz时,有较小幅度的波动。图9(b)中阳平的基频曲线有拐点,拐点之前为斜率递增,拐点之后斜率递减。图9(c)中上声的基频曲线有拐点,拐点之前为斜率递减,拐点之后斜率递增。图9(d)中去声基频曲线在发音中间阶段先有小幅度的频率波动。
由文中2.2.2知,语音可以经过多个三角函数叠加构成,见式(20)。
式中 Amp(Amplitude)为幅度,控制声音的响度,w为声带振动频率,t为时间,φ控制声音发音时间的移位。由于w=2·π·f,f为基频周期。则式(21)变化为如下函数。
在语音合成过程中,要实现声调控制,需要将固定的声带振动频率即式(20)中的定值w变为随着时间有相应声调起伏变化的函数,即y1(n),实验合成语音选取的采样频率为8 kHz,因此在合成过程中,时间的间隔n值非常小,即离散的采样取值可以等效为连续时间变化
式中 yl(t),l=1,2,3,4为式(12)中4种声调拟合函数;k为基频的整倍数级;2·π·k·yl(t)为共振峰频率。
根据上式(22)最终从数学原理角度出发实现了带有音调控制的语音合成。经过Adobe Audition的分析,原声和合成的拼音ɑ的4种音调的语谱对比,如图10,11,12,13所示。(左侧为原声语谱图,右侧为合成语音语谱图)。
从处理结果看,由于现实情况下,人受身体状态与发音器官构造的差异,使得语音的发出在语谱图上会呈现一些有干扰的阴影,影响发音效果[3]。对于越标准的发音,基频与共振峰曲线越清晰,存在的阴影越少。为合成清晰度高、干扰小的语音,采用函数拟合方法可以很好的去除外界对发音的影響,使得发音结果更标准。图10,11,12,13对应的一声、二声、三声声调都能够得到很好的拟合结果,而四声调存在偏差是因为在实际情况下,基频的变化不是从刚开始就下降,一般先保持一段水平进而开始走低,由于这段水平发音时间很短且保持一声,因此在进行函数拟合时,可以利用平缓的下降来进行拟合,得到拟合结果。
现在大部分考虑声调的语音合成系统,主要采用Target模型及二次曲线拟合方法。在该模型中,4种声调被简单地划分为斜率为零、上声、下降不同且变化趋势单一的直线,结合二次曲线计算基频曲线拐点位置进行拟合[11]。由于三声调曲线变化最复杂,因此以三声调为例进行实验对比,拼音ɑ上声的原声和以Target模型为基础的语音合成结果,如图14所示。对于拼音ɑ上声采用高次多项式和以Target模型为基础的语音合成结果,如图15所示。
从图14,图15可以看出,由于语调曲线变化不是单一的,而是变化复杂且拐点较多,因此采用高次多项式,较以Target模型为基础进行带语调的语音合成结果得到的拟合效果更好。
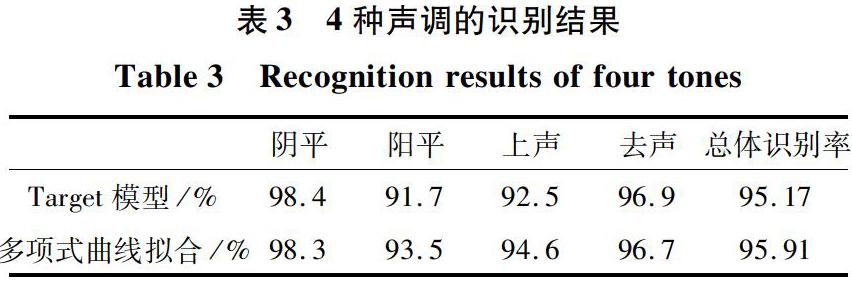
利用支持向量机的方法对声调拟合参数进行训练、分类,最终得到2种方法关于4种声调的识别结果,见表3。
从表3可知,对于阴平和去声来说,由于2种声调的基频变化曲线都是单一的,因此2种方法的识别率几乎没有差别,而对于阳平与上声音调来说,采用多项式进行基频曲线拟合效果更好,总体识别率也更高。虽然采用多项式曲线拟合方法进行转换之后,阳平和上声较阴平和去声识别结果的正确率较低。但总体上看,此曲线拟合技术已经可以达到使用的效果。
4 结 论
1)语音发音2个重要的参数:基频和共振峰。对语音的某一帧频率值进行自相关运算,在周期P处存在极大值。基频值采用自相关运算求极大值方法求得。共振峰的频率值可根据倒谱法求得。
2)4种语调的基频曲线在实际情况下,一声语调存在波形变化,二声与三声语调基频与五度制音高标记法描述的音高走向不同,拐点更接近前端,四声语调基频下降趋势更快,时间更短。
3)采用多项式进行基频曲线拟合,选择四阶多项式拟合与原始曲线相似度可达到97.98%,同时避免了曲线过拟合。
4)对发音的数学原理进行分析,提取了语音的基频以及共振峰2个重要参数,最终通过三角函数的叠加以及4种音调的控制实现了声调可控的语音合成。相比传统的基频提取,文中能够通过函数拟合来灵活调整语调,相比机器学习,文中方法对语料包的要求更低。经过验证,达到了95.91%的识别率。对于今后语音合成、情感分析、语音识别的智能化、准确度有很好的参考价值,对探究发音的数学原理有参考意义。
参考文献(References):
[1] 亓贝尔,古鑫,刘子夜,等.汉语普通话人工耳蜗使用者对声调识别的分析研究[J].中国耳鼻咽喉头颈外科,2017,24(4):175-179.
QI Beier,GU Xin,LIU Ziye,et al.Lexical tone perception in native-mandarin cochlear implant users[J].Chinese Archives of Otolaryngology-Head and Neck Surgery,2017,24(4):175-179.[2]杨丽萍,卢岭,刘莉,等.人工耳蜗使用者汉语声调感知与音乐感知相关性研究[J].中华耳科学杂志,2019,17(6):905-909.YANG Liping,LU Ling,LIU Li,et al.Lexical tone perception and melodic pitch perception in mandarin-speaking cochlear implant users[J].Chinese Journal of Otology,2019,17(6):905-909.[3]张丹烽,李冠宇,赵英娣.语音合成技术发展综述与研究现状[J].科技风,2017,328(22):78
-79.ZHANG Danfeng,LI Guanyu,ZHAO Yingdi.The development and research status of speech synthesis technology[J].Technology Wind,2017,328(22):78-79.[4]王剑辉,姜龙滨,穆宝良.关于MEDLINE-Abstracts文献的语法规则的构建与实现[J].西安科技大学学报,2007,27(1):111-114.WANG Jianhui,JIANG Longbin,MU Baoliang.Construction and implementation of grammatical rules for processing of the English sublanguage of MEDLINE-Abstracts[J].Journal of Xian University of Science and Technology,2007,27(1):111-114.[5] LUO X,LAUREN H.Vibrotactile stimulation based on the fundamental frequency can improve melodic contour identification of normal-hearing listeners with a 4-Channel cochlear implant simulation.[J].Frontiers in neuroscience,2019,13(10):1145-1158.[6]YU Keke,LI Li,CHEN Yuan,et al.Effects of native language experience on Mandarin lexical tone processing in proficient second language learners.[J].Psychophysiology,2019,56(11):13448-13462.[7]HAN Y Q,MARTIJN G,MARIA M,et al.Relative contribution of auditory and visual information to mandarin Chinese tone identification by native and tone-nave listeners[J].Language and Speech,2019,63(4):856-876.[8]宋知用.MATLAB在語音信号分析与合成中的应用[M].北京:北京航空航天大学出版社,2013.[9]刘梦媛,杨鉴.基于HMM的缅甸语语音合成系统设计与实现[J].云南大学学报(自然科学版),2020,42(1):19-27.LIU Mengyuan,YANG Jian.Design and implementation of Burmese speech synthesis system based on HMM[J].Journal of Yunnan University:Natural Sciences Edition,2020,42(1):19-27.[10]王国梁,陈梦楠,陈蕾.一种基于Tacotron 2的端到端中文语音合成方案[J].华东师范大学学报(自然科学版),2019(4):111-119.WANG Guoliang,CHEN Mengnan,CHEN Lei.An end-to-end Chinese speech synthesis scheme based on Tacotron 2[J].Journal of East China Normal University:Natural Science,2019(4):111-119.[11]宋刚,姚艳红.用于汉语单音节声调识别的基频轨迹拟合方法[J].计算机工程与应用,2008(29):239-240,244.SONG Gang,YAO Yanhong.Curve fitting of pitch contour used for tone recognition of isolated mandarin syllables[J].Computer Engineering and Applications,2008(29):239-240,244.[12]薛健,蔡莲红.一种基于声调规范模型的声调变换方法[J].计算机工程与应用,2005(10):40-43,85.XUE Jian,CAI Lianhong.A tone transformation method based on standard tone model[J].Computer Engineering and Applications,2005(10):40-43,85.
[13]THALES A D L,MRJORY D C A.A survey on automatic speech recognition systems for Portuguese language and its variations[J].Computer Speech & Language,2020,62(7):101055-101071.[14]张涛,马宏伟,郭长立,等.传输矩阵法研究薄膜体声波谐振器[J].西安科技大学学报,2010,30(2):251-254.ZHANG Tao,MA Hongwei,GUO Changli,et al.Research of thin film bulk acoustic resonators(FBAR)using transmission matrix method[J].Journal of Xian University of Science and Technology,2010,30(2):251-254.[15]WU H,DONG X X,WANG Q M.New principle of busbar protection based on a fundamental frequency polarity comparison.[J].PloS one,2019,14(3):1-25.[16]李永,范雪,杨鸿波.声谱图在汉语普通话声调识别中的应用[J].信息通信,2017(7):89-92.LI Yong,FAN Xue,YANG Hongbo.Application of spectrogram in tone recognition of Mandarin[J].Information and Communications,2017(7):89-92.[17]SAMPAIO M C,BOHLENDERJ E,BROCKMANNB-AUSERM.Fundamental frequency and intensity effects on cepstral measures in vowels from connected speech of speakers with voice disorders[J].Journal of Voice,2019,11(19):30347-30349.[18]马效敏,郑文思,陈琪.自相关基频提取算法的MATLAB实现[J].西北民族大学学报(自然科学版),2010,31(4):54-58,63.MA Xiaomin,ZHANG Wensi,CHEN Qi.Implementation of pitch detection based on ACF by Matlab[J].Journal of Northwest University for Nationalities(Natural Science),2010,31(4):54-58,63.[19]曹梦霞,郑永果,郑尚新.基于归一化自相关的语音基频特征提取[J].信息技术与信息化,2014(2):49-51.CAO Mengxia,ZHENG Yongguo,ZHENG Shangxin.Fundamental frequency feature extraction of speech based on the normalized cross correlation function[J].Information Technology and Informatization,2014(2):49-51.[20]吴树兴.一种语音信号基音周期时域估计算法[J].电脑知识与技术,2019,15(22):214-216.WU Shuxing.A time domain estimation algorithm for speech signal pitch period[J].Computer Knowledge and Technology,2019,15(22):214-216.[21]DE CARVALHO CLSTENES C,DA SILVA DANIELLE MELO,DE CARVALHO ANTONIO D,et al.Evaluation of the association between voice formants and difficult facemask ventilation[J].European Journal of Anaesthesiology,2019,36(12):972-973.
[22]白燕燕,胡晓霞.基于基音周期和共振峰频率检测的倒谱特征研究[J].电子测试,2019(17):48-49.BAI Yanyan,HU Xiaoxia.Study on cepstrum characteristics based on pitch period and formant frequency detection[J].Electronic Test,2019(17):48-49.[23]王硕,MANNELLR,NEWALL P,等.共振峰信息在汉语声调感知中的作用[J].中国耳鼻咽喉头颈外科,2012,19(1):14-17.WANG Shuo,MANNELLR,NEWALL P,et al.Role of formants in Mandarin lexical tone perception[J].Chinese Archives of Otolaryngology-Head and Neck Surgery,2012,19(1):14-17.[24]HU G X,DETERMAN S C,DONG Y,et al.Spectral and temporal envelope cues for human and automatic speech recognition in noise[J].Journal of the Association for Research in Otolaryngology:JARO,2019,21(1):73-87.[25]張勤.最小二乘估计在曲线拟合中应用的研究[J].成功(教育),2011(18):302-303.ZHANG Qin.Study on the application of least square estimation in curve fitting[J].Success(Education),2011(18):302-303.[26]魏引尚,郑活勃,王宁.采空区自燃“三带”特征的最小二乘法分析[J].西安科技大学学报,2015,35(2):159-164.WEI Yinshang,ZHENG Huobo,WANG Ning.Characteristic analysis of spontaneous combustion“three-zone”in goaf by least square method[J].Journal of Xian University of Science and Technology,2015,35(2):159-164.[27]刘霞,王运锋.基于最小二乘法的自动分段多项式曲线拟合方法研究[J].科学技术与工程,2014,14(3):55-58.LIU Xia,WANG Yunfeng.Research of automatically piecewise polynomial curve-fitting method based on the least-square principle[J].Science Technology and Engineering,2014,14(3):55-58.
猜你喜欢
小天使·一年级语数英综合(2020年9期)2020-12-16
小天使·一年级语数英综合(2020年9期)2020-12-16
金桥(2020年5期)2020-09-10
小天使·一年级语数英综合(2019年9期)2019-11-10
小太阳画报(2019年10期)2019-11-04
作文周刊·小学一年级版(2019年28期)2019-09-07
小资CHIC!ELEGANCE(2018年20期)2018-07-06
课堂内外(高中版)(2017年9期)2018-02-24
小雪花·成长指南(2016年8期)2016-09-21
作文评点报·初中版(2014年2期)2014-03-11
