
基于结构MRI和机器学习的阿尔茨海默病病程分类研究
2021-08-04 08:09姚丽丽范炤
磁共振成像 2021年6期
姚丽丽,范炤
阿尔茨海默病(Al zheimer's disease,AD)是一种具有记忆障碍和认知衰退特征的神经退行性疾病[1]。现有的治疗只能暂时帮助缓解记忆和认知问题,不能根治。为了获得疾病的控制治疗,迫切需要对AD病程进行分类,以便早期准确诊断,及时治疗。国内外大量研究人员通过研究AD患者脑神经影像学结构和功能的变化[2],试图寻找能够有助于AD临床诊断的生物标志物,为早期诊断提供价值。结构磁共振成像(structural magnetic resonance imaging,sMRI)由于其无创性和高普及性的优点,广泛应用于AD早期诊断。近年来,随着科学技术的发展,大量结合机器学习的医学图像数据被用于AD的分类预测[3],如何选择特征选择算法对疾病预测至关重要。目前,在影像学的AD研究中常采用主成分分析法、偏最小二乘法等进行降维[4],使用支持向量机(suppor t vect or machine,SVM)、逻辑回归(l ogistic regression,LR)、随机森林(random f orest,RF)等各种分类模型[5-7]来验证和评估提取的特征是否具有良好的分类性能。这些研究证实,基于图像结构信息的疾病分类技术对临床诊断更有帮助。然而,MRI原始图像维数高,早期AD结构变化不明显以及研究样本总数的限制使得AD早期评估和诊断的发展受到限制,并且由于不同的实验条件导致研究结果的不同,至今很难有高效准确的算法能够应用于临床。因此,本研究基于sMRI数据和患者临床信息特征[年龄、性别、教育水平、简易智力状态检查(Mini-Mental State Examination,MMSE)评分]提出一种L1-SVM特征选择法,通过与SVM、RF、LR、误差逆传播(back pr opagat ion,BP)神经网络这4种分类算法结合建立并选出最合适的预测模型,并创造性地针对每一阶段病程转化给出具体的生物标志物。
1 材料与方法
1.1 研究数据来源
本研究数据来自AD神经成像倡议(Al zheimer's Disease Neuroimaging Initiative,ADNI)数 据 库(http://adni.l oni.usc.edu/),回顾性分析编号为4018~5210的符合标准的受试对象543例。根据ADNI标准,接受教育(或参加工作)不得少于6年的60~90岁老年人,经伦理委员会批准,所有对象均签署知情同意书。共分为4组:139名正常认知者(normal control s,NC)、220例早期轻度认知障碍患者(earl y mil d cognitive impairment,EMCI)、108例晚期轻度认知障碍患者(l ate mil d cognitive impairment,LMCI)和76例AD患者。各组纳入标准如下:(1)NC组:年龄、性别及教育水平均匹配;无记忆力下降;MMSE评分为24~30分;临床痴呆评定量表(cl inical dementia rat ing,CDR)0分;认知功能正常,基本日常活动没有障碍。(2)EMCI组:教育水平达到初中毕业水平及以上;MMSE评分为24~30分;逻辑记忆量表进行测试:教育水平为16年以上得分9~11分,8~15年得分5~9分,7年以下得分3~6分;CDR为0.5 且没有其他认知障碍;基本日常活动无障碍。(3)LMCI组:同EMCI,区别是教育水平16年以上为≤8分,8~15年得分≤4分,0~7年得分≤2分。(4)AD组:MMSE评分为20~26分;CDR为0.5 或1.0 ;根据NINCDS/ADRDA新标准诊断为AD。
1.2 数据预处理
收集这些研究对象的sMRI图像数据,数据集由Phil ips 3.0 T磁共振扫描设备采集,采集参数为:射频TR为6.8 ms,TE为3.1 ms,翻转角为9°,视野大小 为:RL=204 mm/AP=240 mm/FH=256 mm,层 厚 为1.2 mm,层 数 为170,体 素 为1.0 mm×1.0 mm×1.2 mm。利用Free sur f er 3.4 .0 软件将sMRI三维图像经过空间标准化、图像平滑、图像分割等一系列预处理后得到272项结构形态学指标包括70项皮层表面积(sur f ace ar ea,SA)、68项皮层厚度(cor t i cal t hi cknesses,TA)、16项海马亚区体积(hippocampal subf iel d,HS)、49项 皮 层 下 体 积(subcortical vol ume,SV)和69项皮层体积(cor t ical vol ume,CV)。除此之外还获得了对应4项临床统计数据,包括性别、年龄、教育水平和MMSE评分(见表1)。
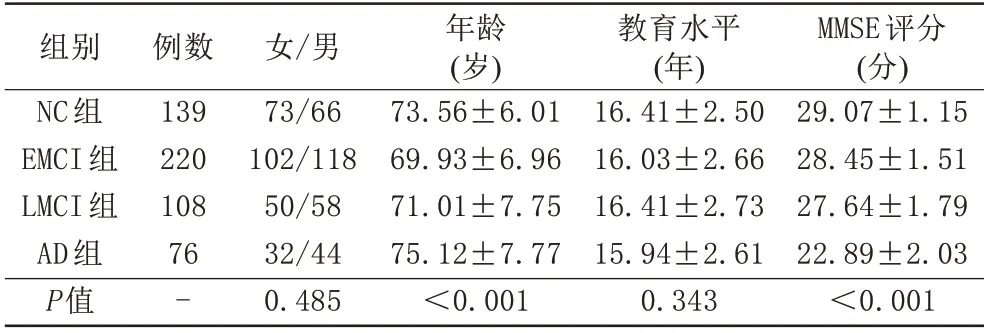
表1 研究对象人口统计临床信息Tab.1 Demographic and clinical information of study subjects
1.3 特征选择算法
本研究首先通过特征选择获得与分类相关的重要特征来增强学习算法的泛化能力,但是不再沿用传统统计学方法来进行,而是希望与分类模型一样,也通过机器学习算法能够智能化选择最优特征。SVM在分类领域里得到了广泛的研究和应用且适合本研究数据的分类问题,而其本身不具备特征选择能力,因此在SVM模型中引入正则化惩罚项来使特征个数最小化并且解决过拟合问题[8]。L1和L2正则化都可以达到这种目的,但L1比L2更容易获得稀疏解[9]。L1正则化是损失函数的惩罚项,可以对某些参数作一定的限制。因此得到损失函数:

针对272项数据集和加入4项临床信息后的276项数据集这两种进行特征选择。根据特征选择后排名顺序决定预测相关度大小,各组得到的特征中排名越靠前说明对该阶段病程的影响越大。本研究数据由Pyt hon 3.7 实现,包括分类模型算法的运行。
1.4 机器学习分类模型
1.4.1 SVM模型
SVM可以利用结构风险最小化的原理将输入样本映射到高位特征空间,在此空间上构造最优分类超平面,使分类问题获得良好的泛化能力[5]。给定训练样本(xi,yi),每一个样本点xi对应一个类别标签y i,yi∈{-1,1}。SVM的最优分类函数为:
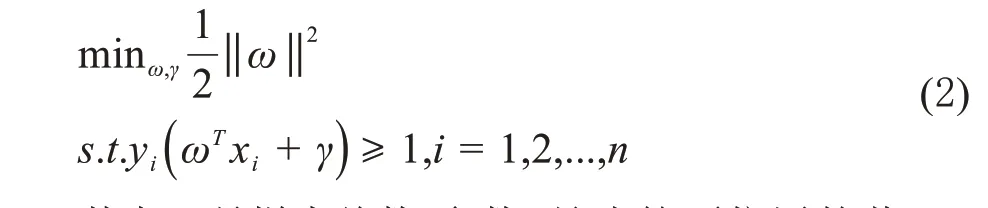
其中,n是样本总数,参数γ是决策面位置的截距,ω为控制方向的行向量,当xi为决策面ωTx+γ=0所对应的支持向量样本点时,ωTxi+γ为-1或1。
1.4.2 BP神经网络模型

1.4.3 LR模型

1.4 .4 RF模型
RF属于集成学习的一种,由许多决策树组成。通过构建并结合多个学习器来完成学习任务。算法的本质是通过集合树型分类器,构造不同的训练集来增加分类模型间的差异并通过投票进行分类和预测[7]。RF的决策函数为:
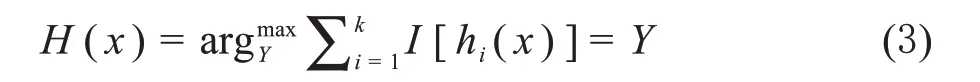
其中,H(x)为组合模型函数,hi(x)表示单个决策树,Y表示目标变量,经过k轮训练得出最多决策树支持的一类。
1.5 模型性能评估
本研究采用最小偏差和方差的十折交叉验证方法对各个分类模型进行评估。将数据集分成10份,随机抽取9份作为训练样本构建分类模型,另一份作为测试集对模型性能进行检验,获得分类结果,重复10次训练和测试后得到的10个测试结果均值即为该模型算法的准确率,针对本研究数据类别分布的不平衡,除了准确率这项评价指标外,还考虑了敏感度和特异度。此外,AUC也用作评估分类器性能的指标。
2 结果
2.1 特征选择结果与分类
2.1 .1 272项特征选择结果
通过L1-SVM特征选择模型提取后,在识别NC与EMCI组时,有133项特征被提取并进入分类模型。其他NC-LMCI、NC-AD、EMCI-LMCI、EMCI-AD和LMCI-AD组中,分别有86、58、112、78和78项被提取。特征选择的结果根据它们对该分类组的重要程度来排列,本研究只显示各组前10项(见表2)。从整体来看,最主要的10项特征分别为TA-左颞横回、SA-左颞下回、SV-右杏仁核、CV-右额眶回内侧、TA-左颞中回、HS-右海马前下托、SA-左颞极、CV-右额上回、CV-左扣带回后部、SA-左额眶回内侧。

表2 272项特征中贡献最大的前10项特征Tab.2 Top 10 important features of 272 features
2.1 .2 276项特征选择结果
将4项临床人口学指标加入到272个形态学指标后,各指标在区分每一组时的重要程度发生改变。在区分NC和EMCI组时,从276项特征中提取到的最优特征子集有121项。同样,对于NC-LMCI、NC-AD、EMCI-LMCI、EMCI-AD以及LMCI-AD这些组,分别有82、22、113、39和53项特征被提取到BP神经网络及其他模型。同样只显示贡献最大的前10项。从整体来看,最主要的10项特征分别为TA-左颞横回、MMSE评分、SA-左额眶回内侧、CV-右额眶回内侧、SA-左颞下回、SV-左腹侧间脑、TA-左颞中回、年龄、TA-右眶回、HS-右海马前下托。
从表3可看出,MMSE评分在AD病程的各个阶段表现出非常明显的变化。在识别NC-LMCI、EMCI-AD、LMCI-AD这3组分类时,年龄有很大影响。性别的重要性微乎其微。值得一提的是,在本研究中,针对疾病病程的各个阶段特征的重要程度都展示出来。其中,在区分NC-EMCI组时,年龄排名第14位,性别排名第31位,文化程度排名第70位。对于NC-AD组,教育水平表现出显著差异,年龄和性别没有出现在最优特征的子集中;对于EMCI和LMCI组,年龄排在第11位,性别排在第28位,教育水平排在第63位;对于EMCI和AD组,教育水平排在第23位,对于LMCI和AD组,性别排在第14位。

表3 276项特征中贡献最大的前10项特征Tab.3 Top 10 important features of 276 features
2.2 不同分类模型预测结果
本研究基于两种数据集提取特征后进入BP神经网络模型进行分类,并与RF、SVM、LR 3种常用预测模型进行对比。结果发现BP神经网络模型预测效果高于其他3种模型(见图1、2),而且从整体来看,在276项数据集下分类预测结果更高,尤其识别NC-AD组时准确率最高,为98.9 0%,而LR、SVM、RF 3种模型在识别该组时准确率分别为90.6 6%、92.0 2%、96.7 7%。在272项数据集下BP神经网络、LR、SVM、RF模型在识别NC-AD组时准确率分别为95.3 9%、89.4 2%、91.6 3%、92.1 8%。除此之外,BP神经网络分类模型基于276项数据集在NC-EMCI、NC-LMCI、EMCI-LMCI、EMCI-AD、LMCI-AD组的准确率分别为83.5 3%、95.0 4%、93.0 1%、96.9 3%、92.4 1%。除了准确率,各组在两种数据集下的特异度、敏感度也比较高,AUC值更是高达1.0 0(见表4),且增加人口统计学指标前后模型的泛化能力有所提高。
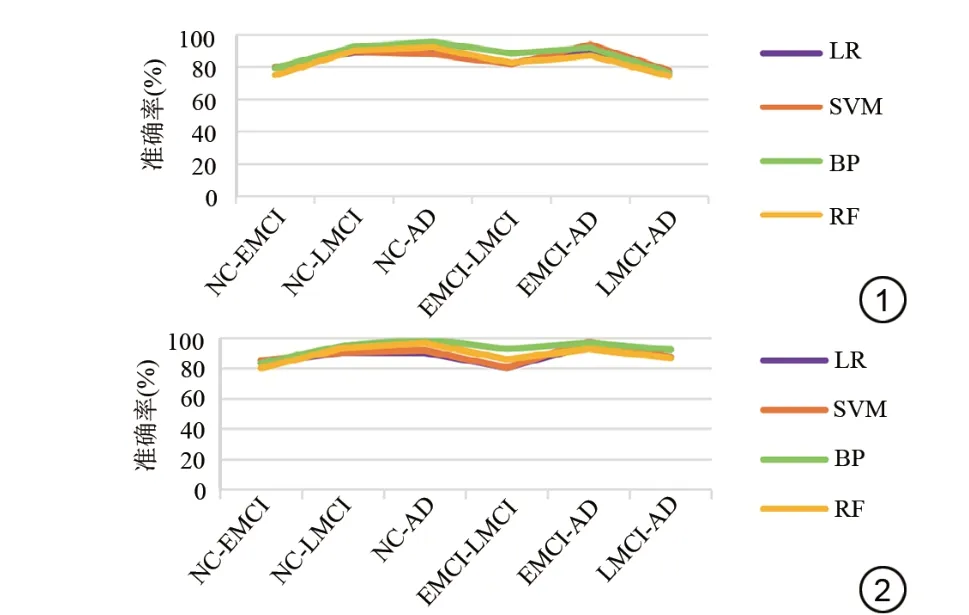
图1 272项特征选择下4种分类模型结果 图2 276项特征选择下4种分类模型结果Fig.1 The results of four classification models were selected for 272 features.Fig.2 The resultsof four classification modelswere selected for 276 features.

表4 BP神经网络在两种特征数据集下的分类结果Tab.4 Classification results of BPneural network under two characteristic data sets
3 讨论
本研究发现了区分各分组时的关键病变部位,并按重要程度排名,更有助于预测病程进展。从272项sMRI形态学指标特征选择结果来看,最优特征子集集中分布在边缘系统和颞叶,海马、海马亚区、以及杏仁核隶属于边缘系统的组成结构[12]。这些结构都可以单独被作为研究AD病程发展的指标。
除了与已有研究一致的脑部形态学变化之外,本研究还发现仅在某个分组中的特征变化有助于预测病程判断。TA-左颞横回在识别NC-EMCI、NC-LMCI、EMCI-AD、LMCI-AD分组的各个病程中都尤为重要,颞横回为听觉皮质区,可见在AD疾病进程中听觉的不断弱化是判断病程的重要依据,与已有研究[13]一致。而在NC-AD组中SV-左海马贡献最大,说明海马在正常人和AD患者之间的差异非常明显,海马主要负责学习和记忆,其萎缩情况反映AD病情的严重程度[14]。并且左侧大脑比右侧大脑严重,这与之前报道[13]一致。而HS-右海马前下托在识别NC-LMCI组、NC-AD组以及LMCI-AD组时排名在最优特征的前十,表明海马亚区也可被用来反映或预测疾病病程的发展,甚至有研究表明海马亚区可能更适合预测AD[15]。在区分NC-EMCI、NC-LMCI和EMCI-LMCI这3组时,SA-左颞下回对分类决策起重要作用,颞下回负责学习和记忆,在进展为LMCI的时候,患者的学习记忆表现出更多差异;由此可见,颞叶萎缩可以用来预测AD疾病的进展情况。
本研究将MCI分成EMCI和LMCI两个阶段,对NC、EMCI、LMCI、AD 4组进行两两分类,通过具体化分类更早识别MCI阶段进而能够对AD进行早期诊断,而以往的研究[16]只对NC、MCI、AD 3组进行两两分类,也涉及BP神经网络以及其他模型,然而在NC-AD组的分类准确率一般在80%~95%。
在sMRI基础上增加年龄、性别、教育水平3项人口统计学指标和MMSE评分后在疾病病程各阶段的准确率均高于只有272项sMRI指标的准确率,可以实现最优分类精度。无论是272项特征还是276项特征,BP神经网络分类器的整体预测效果都优于其他3种分类器。尤其在NC转化为AD的过程中,BP神经网络的准确率高达98.9 0%,而已有研究在引入性别、年龄后对NC-AD组的预测准确率达91.0 7%[17]。
本文方法对病程分类的准确率由高到低依次为NC-AD、EMCI-AD、NC-LMCI、EMCI-LMCI、LMCI-AD、NC-EMCI组。当同样的数据集采用传统统计学方法进行特征选择后用SVM分类研究[18]时准确率达90.9 0%,而本研究L1-SVM特征选择下该模型准确率为91.6 3%。传统统计学方法识别NC-AD组时准确率最高为96.4 5%,而本研究为98.9 0%,总体预测效果高于传统统计法,不同组别中结果略有差异。
本研究顺应当下人工智能时代,提出的BP神经网络模型在L1-SVM特征选择下对NC-EMCI-LMCI-AD两两分类的预测效果较好,这种联合算法可以作为临床辅助诊断AD的有效工具。综合考虑影像数据与临床特征信息有利于精准预测AD病程,希望能够为后续的研究提供参考。同时,本研究存在局限性,后续也会增加样本量,尝试用其他影像数据,比如DTI、PET、f MRI或其他生物标志物,进一步提高比较难区分的病程分类组识别率,从而及时进行干预,阻碍病程进展,为国家和社会减轻负担。
作者利益冲突声明:全体作者均声明无利益冲突。
猜你喜欢
现代临床医学(2022年4期)2022-09-29
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
中国实用医药(2016年31期)2017-05-27
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
