
基于深度学习的语义通信系统*
2021-08-03 08:33:32涂勇峰陈文
移动通信 2021年4期
涂勇峰,陈文
(上海交通大学电子信息与电气工程学院,上海 200240)
0 引言
近年来,通信技术发展迅猛,但面临着巨大挑战。从1G发展到5G,移动通信技术几乎每十年更新一代,通信速率越来越快,已在智慧城市、高清视频、自动驾驶、远程医疗等领域发挥着重要的作用。然而,全球数据流量始终在无休止增长。国际电信联盟(ITU)预测,按照目前的趋势来看,直到2030年,全球移动数据流量每年增长速率将会达到55%,全球移动数据流量将会提升100倍之多,远超5G的体量。另外,以更高的容量、可靠性与更低的时延为目标的技术进步会带来频谱资源的巨大耗费以及通信能耗的急剧增长。为了满足日益增长的通信需求,6G技术需要做出一些改变。
语义通信是一种智能通信方式,契合6G时代的智能体交互需求。6G通信技术在智能化背景下诞生,在将来,多种多样的智能体充斥于生活中,智能体之间的通信不可忽视[1]。智能体之间的通信是面向目的的通信,关键是使接收方正确理解发送方的信息内容,从而降低接收方对信息的不确定性。当前通信技术大多以香农的信息论为基础,即保证每个传输比特的正确接收,而并不关注信息中承载的含义,这种方式会产生大量数据的冗余,造成不必要的通信资源的耗费[2]。语义通信引入语义层次的信息,关注信息内容而非编码符号,迎合了智能体通信的特性需求,符合6G的发展需要。
人工智能算法的不断发展推动着语义通信的发展。新兴的人工智能算法和计算使语义表示成为可能,而这也是语义通信的基础。特别是NLP(Natural Language Processing,自然语言处理)所探讨的用计算机代替人工来处理大规模的自然语言信息,通过人类所定义的算法进行加工、计算等系列操作模拟人类对自然语言的理解,其根本就是提取与利用语义信息的问题,与语义通信的需求吻合。LSTM(Long Short-Term Memory,长短期记忆网络)[3]模型能够捕捉序列中的广范围的依赖关系,Transformer[4]模型关注输入的特定部分,通过并行运算实现序列到序列的映射。人工智能算法是解决语义通信中一些关键问题的有效方法。
本文探究一种基于深度学习的语义通信系统,以文本为传输内容,通过NLP中的Transformer模型进行语义编解码,从而仿真语义通信系统的基本架构。对于文本,传统的编解码方式简单直接地将其转化为无意义的通信符号序列进行传输,而忽略了其中蕴含着丰富的语义信息。本文将语义通信系统构建成一个深度神经网络,以Transformer模型为基础,利用文本中词与词之间的巨大关联进行语义挖掘与特征提取,并加入信道编解码层、信道层与量化层,联合组成一个语义通信系统网络。
1 语义通信理论与模型
1.1 语义通信理论
Shannon与Weaver[5]将通信的问题分为三个层面:
(1)技术层面:通讯符号如何准确地加以传输?
(2)语义层面:传输的符号如何精确地传达含义?
(3)效用层面:收到的含义如何以期望的方式有效地影响行为?
考虑技术层面的问题,Shannon建立了通信的数学理论基础,将通信定义为发送端的信息在接收端的精确复现。在此基础上,通信技术的发展不断追求更精确的数据传输,同时以更高的容量、可靠性以及更低的时延为目标。显而易见,随着数据量的爆炸式增长,带宽需求的急剧增加,将会有越来越多的频谱资源被占用,这对未来通信的发展带来了巨大挑战。
当前通信技术的发展以准确传输数据为目标,却忽视了数据中承载的信息含义,而这正是语义层面的问题。通信网络的发展趋向智能化,追求有效性和可持续性,此时将语义视为不相关不再合理。关注传输内容中承载的含义,即语义信息,利用语义信息进行编码,去除冗余数据,减少传输数据量,这种通信方式即为语义通信。
Carnap等人[6]基于内容的逻辑概率,首次引入语义信息论(SIT)的概念。J. Bao等[7]将SIT进行了扩展,提出了语义通信的一般模型(GMSC),定义了语义噪声和语义信道的概念。文献[8]基于GMSC提出了一种无损语义数据压缩理论,验证了从语义层面上进行数据压缩,从而显著减少传输数据的可能。这些工作为语义通信的发展提供了一些方向和意见,但仍有许多问题有待探讨。
1.2 语义通信模型
语义通信模型的一般框架如图1所示,与传统通信系统相同,语义通信系统包含发送端、信道与接收端三个部分,主要区别在于语义通信系统所采用的编解码方式。语义通信系统的发送端包含语义编码与信道编码部分,接收端包含信道解码与语义解码部分。

图1 语义通信模型的一般框架
在传统通信系统中,编码以数据压缩形式进行,编码结果只记录符号的标识,并没有记录符号的含义信息。而语义编码是针对信源中的语义内容,对有含义的信息进行编码表达,其过程实际就是对信源中的语义概念的高度抽象与压缩。语义解码是编码逆过程,通过解码过程还原的语义信息要与发送端相同。整体而言,语义编码在知识库的指导下,对语义源中蕴含的语义信息本身进行编码获得语义码,之后再通过信道编码方式发送。接收端对接收到的信息先进行信道解码获得语义码,再经由语义解码获得恢复后的信息。
在已有的工作中,文献[9]将深度学习与联合信源信道编码结合,通过语义信息的传递在接收端恢复文本信息。文献[10]将联合信源信道编码用于图像的传输中,并取得了较好的效果。文献[11]提出了内容为语音的语义通信方式,验证了语义通信对语音的有效性。
2 基于深度学习的语义通信系统架构
本文提出一个基于深度学习的语义通信系统模型,将文本作为传输内容,实现从发送端到接收端的传输。采用Transformer模型作为语义编解码的核心部分,用于语义信息的提取与理解。
如图2所示,网络的整体结构包含编码器、信道、解码器三部分。将待传输的句子记为s= [w1,w2, … ,wn],其中wi表示句子中的第i个单词。编码器的作用表示为函数α,输入s经编码器编码后得到比特序列B=α(s)。比特序列B通过信道传输,在接收端得到R,解码器的作用表示为函数β,经解码器解码恢复的句子记为s' =β(R)。下面分别对每部分进行详细介绍。

图2 基于深度学习的语义通信系统架构
2.1 编码器
编码器先在输入句子s后添加句尾标识符,再将其中的每个单词映射为D维的表示向量,转化后的E=[e1,e2, …,en,e]包含输入句子中的n+1个表示向量。表示向量由向量嵌入与位置嵌入两部分组成。向量嵌入将单词映射到高维度以表示特征,位置嵌入与单词在句子中的位置相关,可以给模型提供位置上的信息。
编码分为语义编码与信道编码两步,先进行语义编码再进行信道编码。本模型将两个Transformer编码块连接实现语义编码,将E通过编码映射为Es,Es表示提取语义信息后的抽象语义,蕴含了整句话的语义信息。Transformer编码块由多个注意力层叠加,注意力公式表示为:
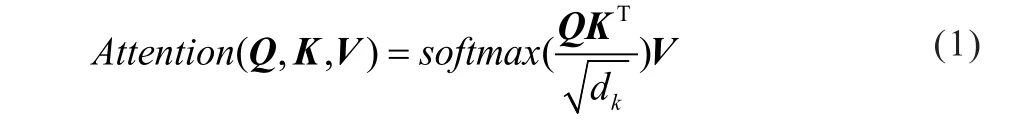
Q、K、V均由输入进行线性变换得到,dk为调节因子。其本质是去计算句子中的每个词与句中所有词的关联性以及重要度,再利用这些相互关系调整权重以获得每个词新的表达。将多个不同的注意力层进行拼接,使模型可以专注于不同语义特征的提取。最后的输出Es蕴含了该词本身以及与其他词的关系,是一个针对整句话的全局表达,蕴含了整句话的语义信息。
信道编码由两个隐藏单元数不同的全连接层组成,隐藏单元数逐层递减以进行数据压缩。第一层的激活函数采用Relu函数,第二层的激活函数采用tanh函数,编码后的输出记为Ec,可表示为:

W1,W2为全连接层的权重矩阵,b1,b2为全连接层的偏置。
2.2 信道
为实现编码器与解码器的联合训练,将信道作为网络模型中的一层。本模型选择AWGN信道作为信道层,对输入信号B加入高斯白噪声,输出记为R。噪声的加入可表示为:

其中N代表噪声,服从均值为0,方差为σ2的高斯分布。
2.3 解码器
经由噪声干扰后的信号R进入解码器后,先进行信道解码。信道解码层为两个隐藏单元数逐渐增大的全连接层,最后一层的隐藏单元数设为D以确保维度一致,信道解码的输出记为Rc,可表示为:
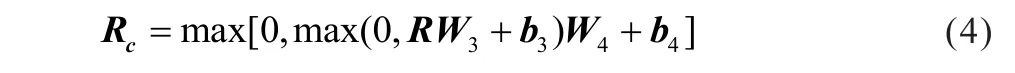
W3,W4为全连接层的权重矩阵,b3,b4为全连接层的偏置。
语义解码层的由两个Transformer解码块连接组成。Transformer解码块包含两级不同的注意力层。第一级注意力层的Q、K、V均由前一层解码块的输出得到,第二级注意力层的Q来自于前一级注意力层的输出,而K、V通过编码块的输出得到。
语义解码层的输入分为两部分,一部分是信道解码的输出Rc,一部分是已知的解码结果,通过两部分的输入共同推测下一个解码结果。如图2所示,语义解码层首先把句首标识符作为输入,与Rc结合推测出第一个输出w1',之后将与w1'合并作为第二次输入,再结合Rc推测出第二个输出w2',以此循环,直到接收到句尾标识符,获得完整的输出s'。在训练时,将待解码的结果直接设置为语义解码层的输入,从而加快训练速度,在测试时,采用上述的解码方式逐词预测得到输出s'。
2.4 损失函数与衡量标准
将输入句子s与输出句子s'的交叉熵作为网络训练的损失函数,可表示为:

其中,q(wi)表示输入句子s中第i个词为wi的真实概率,p(wi)表示输出句子s'中第i个词为wi的预测概率。
采用词准确率作为评估模型表现的标准,可表示为:

Equal函数判断s中第i个词wi与s'中第i个词wi'是否相等,相等返回1,不等返回0。n为s中包含的单词总数。
3 仿真结果与分析
为了验证算法的有效性,将本文提出基于深度学习的模型与传统的信源信道编解码模型在AWGN信道下的表现进行了对比,比较了在传输比特数有限的情况下不同模型的效果。
3.1 仿真参数
采用欧洲议会语料库[12]作为文本数据集,其中包含220万个句子以及5 300万个单词。对数据集进行预处理,选择长度为4~30个单词的句子并分为训练集与测试集。处理后的训练集包含116万个句子,测试集包含1.2万个句子。
网络参数的设置如表1所示,模型维度D设置为512,编码器包含两个8头的transformer编码块以及两个全连接层,解码器包含两个全连接层以及两个8头的transformer解码块。
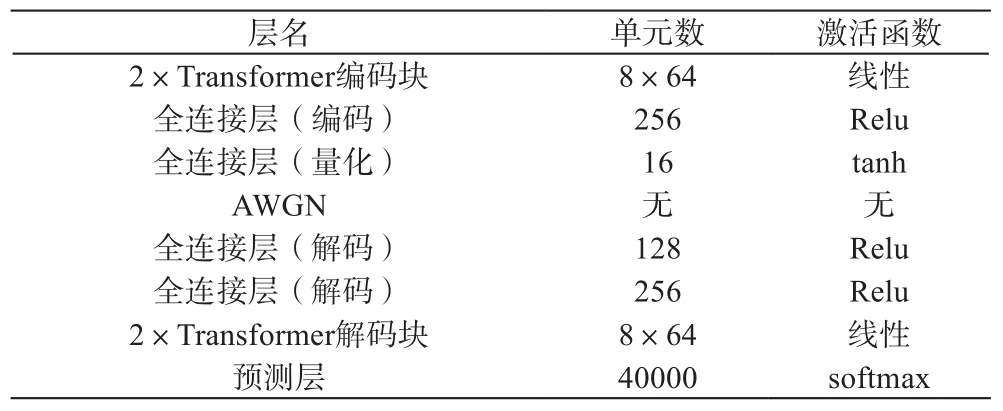
表1 网络参数值
用于对比的传统模型采用哈夫曼编码与5 bit定长编码作为信源编码方式,信道编码统一采用RS(7, 5)编码,调制解调方式为2PSK。在传输比特数有限时,优先保证已编码部分的准确率直至达到比特数限制。
3.2 结果分析
图3比较了在平均每单词比特数一定时,本文提出的基于深度神经网络的语义通信模型与两种传统通信模型在不同信噪比下的词准确率。可以看出,在平均每单词比特数为16 bits/词时,5 bit定长编码的效果最差,哈夫曼编码略优于5 bit定长编码,本文所提模型在全部信噪比环境下均优于两种传统模型。在较高信噪比时,本文所提模型的效果更好。两种传统模型在信噪比较高时的词准确率均无法随信噪比增大而提升,其原因是平均每单词比特数有限且无法满足该方式下的编码需求,有部分句子中的单词无法被编码。
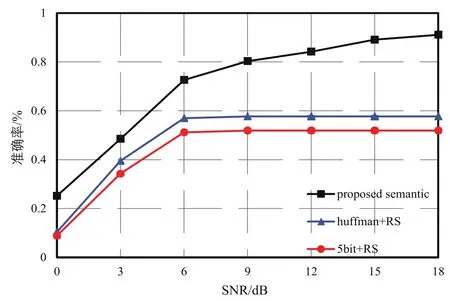
图3 平均每单词比特数为16 bits/词,语义通信模型和其他模型在不同信噪比下的准确率
图4比较了在信噪比为9 dB时,本文提出的模型与两种传统通信模型在平均每单词比特数不同时的词准确率。当给定平均每单词比特数较高时,所有模型均可达到很高的准确率。当给定的单词比特数很少,如8 bits/词时,三种模型的准确率均较低,语义通信模型的准确率更低一些,其原因是在仿真时,语义通信模型对所有单词分配相同的编码比特数,而传统模型利用有限的比特数优先保证已编码部分内容的准确传输。当平均每单词比特数适中,在12~24 bits/词时,哈夫曼编码的效果略优于5 bit定长编码,本文所提模型明显优于两种传统模型。总体而言,本文所提模型能够利用有限的平均每单词比特数进行编码,并取得比传统通信模型更高的准确率。
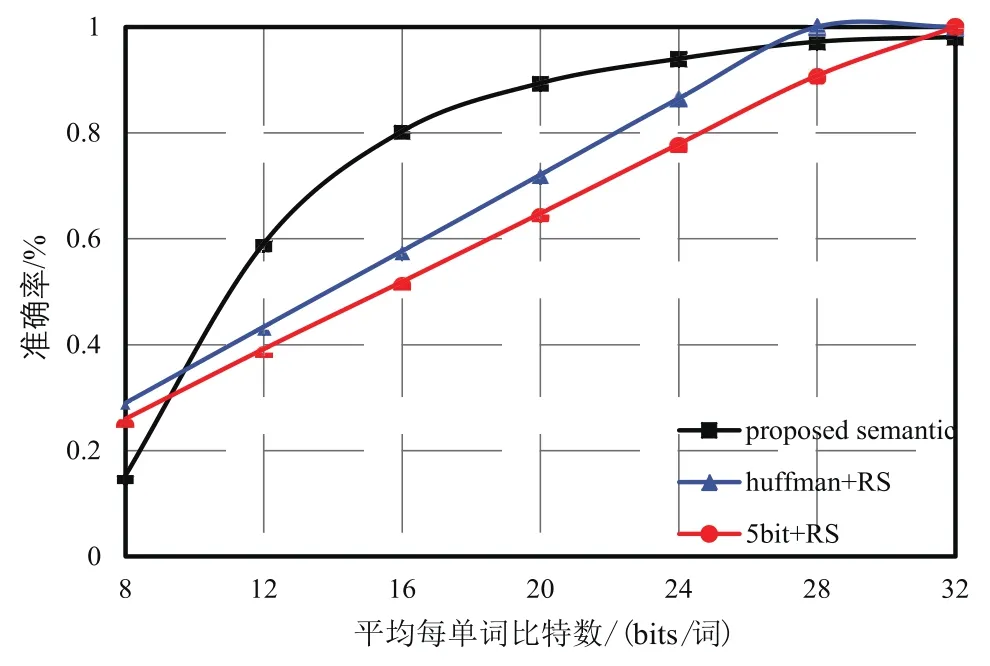
图4 信噪比为9 dB时,语义通信模型和其他模型在不同平均每单词比特数下的准确率
4 结束语
本文提出一种以文本为传输内容的语义通信系统,利用内容的语义信息进行编码传输。仿真验证表明,在AWGN信道下,相较于传统通信方式,本文所提模型的传输数据更少,准确率更高。结果验证了语义通信的方式能够有效减少传输数据,降低通信耗费,符合6G时代的智能通信需求,是未来通信技术的发展方向。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
海峡姐妹(2017年10期)2017-12-19 12:26:20
三联生活周刊(2017年33期)2017-08-11 04:35:44
银行家(2017年1期)2017-02-15 20:27:20
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:42
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:44
电子设计工程(2015年8期)2015-02-27 12:05:33
