
基于命名实体识别任务反馈增强的中文突发事件抽取方法
2021-07-30 10:33武国亮徐继宁
计算机应用 2021年7期
武国亮,徐继宁
(北方工业大学电气与控制工程学院,北京 100144)
0 引言
近年来,公共安全突发事件频发。网络的普及使得公共事件相关的有价值的信息散布在各类网络文本中,事件抽取(Event Extraction,EE)在这类信息的挖掘和提取方面有着极其重要的作用。事件发生时,对社交网络上的相关事件描述文本进行事件抽取,能够及时地了解事态信息,使应急部门快速做出反应。在事件发生后,通过事件抽取对报道中事件信息的结构化提取,建立相应的案例库,从而为下一步的事件分析和制定防范预案做有力的支撑。
事件抽取主要分为模式匹配方法[1-4]和机器学习方法[5-8]。在基于机器学习的事件抽取方法中,数据和特征决定模型学习的上限,因此提高数据质量和优化特征选择显得尤为重要。前者属于数据采集和数据预处理范畴,难以通过对模型的改进来提高,但后者可以通过语义特征挖掘来实现。命名实体识别(Named Entity Recognition,NER)和事件抽取是信息抽取的两个子任务,实体是事件抽取内容的组成部分,基于此学者们通过命名实体识别进行实体语义信息的挖掘,进而提高事件抽取任务的学习效果。Li等[5]提出了一个结构化预测模型,能同时实现实体、关系和事件三个信息抽取任务。Yang等[6]提出了篇章内的事件和实体联合抽取模型,通过采用联合因子图模型来联合学习每个事件内部的结构化信息、篇章内不同事件间的关系和实体信息。吴文涛等[7]提出了一种混合神经网络模型HNN-EE(Hybrid Neural Network for Entity and Event Extraction),能同时对实体和事件进行抽取,深度挖掘了两者之间的依赖关系。仲伟峰等[8]利用基于注意力机制的序列标注模型联合抽取句子级事件的触发词和实体,通过多层感知机判断实体在事件中扮演的角色。上述文献都证实了实体识别能够明显提高事件抽取效果。
与英文事件抽取不同的是,中文语料中表达语义的基本单位为词语,但词语间没有显示间隔,且中文语料中存在着大量的多义歧义词,如果分词错误则会使模型对句子语义理解造成明显的误差,从而对事件抽取结果带来负面影响。因此直接对中文语料进行分词预处理的效果大幅度依赖分词工具的准确性,适用性较弱。针对该问题,Zhang 等[9]基于长短期记忆(Long Short-Term Memory,LSTM)网络提出一种用于命名实体识别任务的Lattice(点阵)机制,通过该机制有效地利用丰富的词语边界信息,将词典融合到字符级的中文语料中使其附加词语语义信息。Liu 等[10]对前者的工作进行了优化和拓展,直接在字向量中融入词语向量,并采用4 种不同的方法对多词同首和多词同尾的特殊情况进行处理。Xue 等[11]将自注意力机制与Lattice机制进行融合形成新型点阵变换编码器,能够以批处理模型捕获字符与匹配的词语之间的依存关系,使模型处理速度得到明显的提高。针对上述研究现状,本文以开放领域的中文突发事件数据作为研究对象,对仅能获取字粒度语义信息的双向长短期记忆网络-条件随机场(Bidirectional Long Short-Term Memory network-Conditional Random Field,BiLSTM-CRF)事件抽取模型进行词语维度和实体维度的语义特征增强,提出一种基于命名实体识别任务反馈增强的事件抽取改进模型FB-Latiice-BiLSTM-CRF(FeedBack-Lattice-BiLSTM-CRF)。该模型增加了命名实体识别辅助任务并将其输出反馈至输入端,反馈信息与输入融合得到动态实体分词结果;将Lattice 机制与双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络进行结合,使反馈得到的动态实体分词信息通过该机制输入到模型后增强输入的实体语义特征,句子其他部分通过自组词查询得到相关词语结果;最后通过最大化同方差不确定性的最大高斯似然估计方法对各任务损失进行了平衡处理。实验结果表明,本文提出的改进模型相较于基准模型在事件抽取各项评价指标和模型训练收敛速度上都有明显的提升。
1 数据准备
1.1 数据来源及数据集划分
本文使用的实验数据来源之一是中文突发事件语料库(Chinese Emergencies Corpus,CEC)[12],该语料库是由上海大学语义智能实验室所构建。根据国务院颁布的《国家突发公共事件总体应急预案》的分类体系,从互联网上收集了合计332篇地震、火灾、交通事故、恐怖袭击和食物中毒共5类突发事件新闻报道作为生语料,然后再对生语料进行文本预处理、文本分析以及一致性检查等处理,最后将结果保存到语料库中。与ACE2005(Automatic Content Extraction 2005)中文语料库和TimeBank 语料库相比,CEC 语料库对事件和事件要素的标注更为全面。
由于训练本文提出的神经网络模型需要一定数量的数据,因此需要对原语料库进行扩充。以CEC 语料库的数据为参考,本文爬取了国家突发事件预警信息发布网“近期突发事件”和微博平台“中国新闻网”发布的公共突发事件报道,通过数据筛选和数据清洗后,与CEC语料库合并最终得到1 847篇实验语料,共计206 383字符。
经过打乱数据排列顺序获得特征分布近似均匀的数据后,本文按照8∶1∶1 的比例将数据划分为训练集、验证集和测试集。训练集用于训练模型参数;验证集用于每隔一定的迭代之后测试模型的效果,从而及时保存训练过程中达到更好效果的模型参数;测试集用于评估训练完成的模型效果。
1.2 标签定义
根据数据特征种类及稀疏程度,同时参考CEC 语料库的数据标签及标注内容,本文将事件抽取标签重新定义并分为七类:事件触发词(Event Trigger Word)、事件类型(Event Type)、事发时间(Happened Time)、事发地点(Location)、事件参与者(Event Participant)、受影响对象(Affect Object)和受影响对象状态变化(Affect State)。其中,受影响对象状态变化是指该对象自身状态因受到事件发生的影响而产生的改变,如房屋“被摧毁”,车辆“被损坏”,人员“被困”“受伤”“死亡”等。
本文设计的算法中使用命名实体识别作为辅助学习任务,因此需要定义命名实体识别的标签信息。根据数据的特征定义了五类标签,分别是:时间(Time)、地点(Location)、组织(Orgnization)、人(Person)和设备(Equipment)。
1.3 数据标注
在本文实验中,事件抽取任务和命名实体识别任务全部转化为序列标注问题,并选择BIO 标注法对数据进行标注。尾字母B 表示标签对应的第一个字,I表示标签对应的中间或最后一个字,O 表示无关字符。对训练集进行事件抽取和命名实体识别联合标注,对验证集和测试集仅依据事件抽取标签进行了标注。
虽然事件抽取和命名实体识别的标签定义中有重合部分,但在标注方法上存在以下不同:
1)EE标注仅针对描述事件的信息,NER 标注针对所有符合实体标签的信息。以时间信息标注为例:“中新网4月12日电据巩义市政府新闻办公室官方微博消息,4 月10 日22 时左右,巩义市发生一起自备火车冲出避难线倾覆事故。”EE 标注只关注后半句中的事发时间“4月10日22时左右”,而NER 标注将句中的两个时间实体信息全部进行标注。
2)EE标注以事件要素整体为单位,NER 标注以实体为单位。以地点信息标注为例,EE 标注和NER 标注对比如表1所示。

表1 在地点信息上标注事件抽取和命名实体识别Tab.1 Labeling event extraction and named entity identification on location information
2 模型算法
2.1 BiLSTM-CRF
BiLSTM-CRF 网络结构如图1 所示:首先将输入文本通过Embedding 层进行字符编码后输入到BiLSTM 网络中,再通过正反向传播计算使得各字符融合相应的上下文语义信息;线性层对BiLSTM 层的输出进行特征提取并将其维度调整到符合条件随机场(Conditional Random Field,CRF)层的输入维度要求;最后通过CRF 层学习标签序列的潜在规则信息并计算出最优的预测序列进行输出。
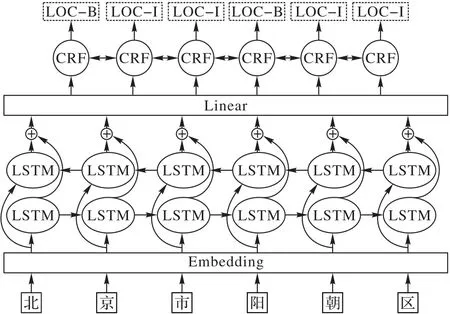
图1 BiLSTM-CRF网络结构Fig.1 BiLSTM-CRF network structure
BiLSTM-CRF 综合了BiLSTM 对上下文的语义获取能力和CRF 对序列预测结果的优化能力,使得其在处理事件抽取、命名实体识别等序列标注任务上展现出较好的效果。
2.1.1 LSTM
BiLSTM-CRF 的BiLSTM 网络层主要由LSTM[13]神经元构成。LSTM是一种特殊的循环神经网络,其单元内部结构如图2所示。

图2 LSTM单元内部结构Fig.2 Internal structure of LSTM unit
LSTM单元的内部结构为其增加了信息存储和更新机制,而这些机制通过一系列门结构来实现,其中遗忘门ft选择性丢弃一些传递信息,输入门it整合该时刻的输入信息,输出门ot为输出提供输入分量信息,从而解决了循环神经网络(Recurrent Neural Network,RNN)的长远依赖问题。LSTM 单元内部信息计算公式如下:
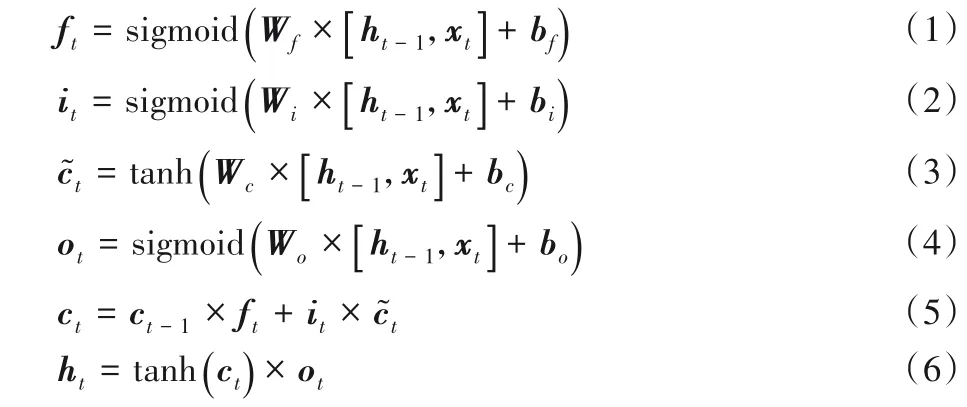
其中:[a,b]表示向量a与向量b进行拼接操作;ht-1和ht分别表示神经元上一时刻和该时刻状态的输出信息;ct-1和ct分别表示神经元上一时刻和该时刻状态的细胞状态信息;表示候选细胞状态,Wf、Wi、Wc和Wo表示权重,对应的偏置项为bf、bi、bc和bo。
2.1.2 CRF
CRF 是一种特殊的隐马尔可夫模型。在序列标注任务中,模型虽然能够直接预测输出,但每个输出的标签前后之间没有关联性,难以符合标签序列中隐含的规则。CRF 能够学习标签序列中的规则信息,例如输出序列不能以LOC-I开头、LOC-I 不能接在TM-B 后面等,从而大幅度提升了序列标注任务的准确率。
若CRF 层的给定序列为x=,标签序列为,其最大条件似然估计公式如下:

其中:P表示原序列到预测序列对应的概率。定义s(x,y)为输入序列到标签序列的评分函数,则概率P计算公式如下:

2.2 FB-Lattice-BiLSTM-CRF
基于单任务事件抽取基准模型BiLSTM-CRF 的缺陷,本文提出了一种基于命名实体识别任务反馈增强的事件抽取改进模型FB-Latiice-BiLSTM-CRF,主要结构如图3 所示。针对基准模型仅能学习到字粒度语义特征的问题,本文将Lattice机制融入BiLSTM网络,借用词向量对输入语料的语义增强效果提高了模型对数据特征的学习能力;此外通过增加命名实体识别任务预测输出反馈机制,使模型获得动态实体信息,为Lattice-LSTM机制提供了定向的实体分词结果,减少实体部分自组词数量大带来的运算负荷;针对多任务损失不平衡问题,本文使用最大高斯似然估计的方法,使各任务的损失同方差不确定性最大化,从而实现各任务损失达到平衡,同时增加主辅任务控制系数引导命名实体识别任务辅助事件抽取任务的学习。

图3 FB-Lattice-BiLSTM-CRF结构Fig.3 FB-Lattice-BiLSTM-CRF structure
2.2.1 Lattice-LSTM机制
中文语料的事件抽取和命名实体识别关注的目标一般是词语或是词语构成的短语,所以与分词具有很强的关联性,He 等[14]通过研究证实了将分词结果的词语信息作为输入能够增加语义特征从而有效的提升模型的性能。在序列标注任务中,将分词结果融入输入序列通常有两类方法:一类是使用第三方工具直接对输入语料进行分词预处理,然后通过Embedding 层进行词粒度嵌入,但这种方法的效果很大程度上取决于分词结果的准确性。例如“南京市长江大桥”应分词为“南京市,长江大桥”,也可能被分词为“南京,市长,江大桥”,后者出现了歧义词,将会对模型训练产生负面影响。另一类是将遍历的词信息融入字粒度的输入中,代表方法是Zhang 等[9]基于LSTM 网络提出的点阵长短期记忆网络(Lattice-Long Short-Term Memory network,Latiice-LSTM)机制,其主要结构如图4所示。

图4 Lattice-LSTM结构Fig.4 Lattice-LSTM structure
Lattice-LSTM 机制定义了一个新神经单元,如图4 中阴影单元所示,其内部结构与LSTM 单元相似,唯一不同的是该单元没有输出门,即传递信息中只有细胞状态c而没有直接输出信息h。此外,字嵌入和词嵌入过程分别使用不同的Embedding网络Ec和Ew进行。
若词的长度为n,词首字对应时刻的LSTM 细胞状态信息为c1,则新单元将c1作为输入,计算得到新单元输出的细胞状态cw;Lattice-LSTM机制会把词信息融入词尾字作为输入对应时刻LSTM 网络的输入细胞状态cn-1中,即新单元输出的细胞状态cw和cn-1进行拼接形成新的细胞状态[cw,cn-1],由于新的细胞状态维度与原维度不同,因此需要定义一个新的门来进行转换,公式如下:

如果多个自组词的词尾指向相同位置字符,则进行归一化处理后求和得到融合后的细胞状态如下:
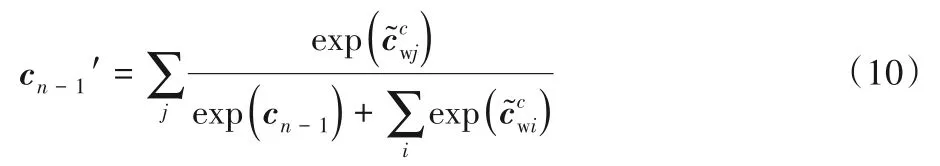
针对Lattice-LSTM 自组词的词量多,语义泛化增强可能引起特征过度增加的问题,本文将通常作为辅助任务的命名实体识别结果反馈到输入端,和原始语料数据进行融合,从而形成实体分词信息;再将分词信息输入到Lattice-LSTM 机制中进行定向词信息融入。一方面,分词信息的加入对事件抽取任务具有增强效果;另一方面,定向的实体分词使得命名实体识别任务形成正反馈,能够有效加速模型的收敛过程。与对训练数据进行分词预处理效果不同的是,该模型融合反馈信息的分词结果是动态的,会随着命名实体识别任务效果的提高而不断优化,避免了因分词错误而产生歧义的问题。
对于除实体以外包含动词、介词等的剩余句子部分,进行逐个字符遍历,同时分别查询从当前字符起的前2、3、4 个连续字符组合是否存在于中文词典中,如果存在则返回自组词结果。由于歧义性大且自组词数量较多的实体部分已经得到确定结果,句子整体的自组词数量会明显减少,从而使Lattice-LSTM部分的运算量得到有效的优化。
2.2.2 多任务损失平衡
为了解决多任务损失失衡问题,Cipolla 等[15]提出一种通过最大化同方差不确定性的最大高斯似然估计的方法。该方法以回归任务和分类任务为例进行了任务分析、方法定义和相应的公式推导。参考该方法解决多任务损失平衡问题的思路,本文对CRF 层输出的序列标注任务定义了如下概率分布函数:


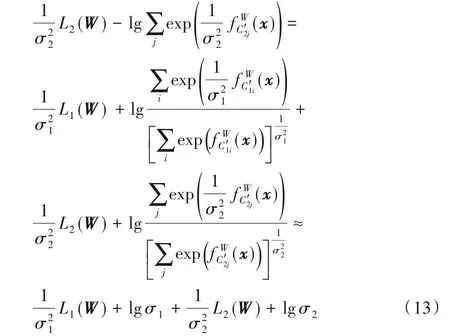
其中:L1(W)、L2(W)分别为事件抽取任务和命名实体识别任务的交叉熵损失;σ1和σ2是可学习参数,通过网络训练进行更新。随着σ1和σ2的优化,各任务的损失将逐渐趋于平衡。
在FB-Lattice-BiLSTM-CRF 模型中,命名实体识别只是事件抽取的辅助任务,为避免两任务在模型训练后期出现过度对抗竞争的问题,增加超参数主辅任务控制系数K作为事件抽取任务关联项的系数,总损失如下:
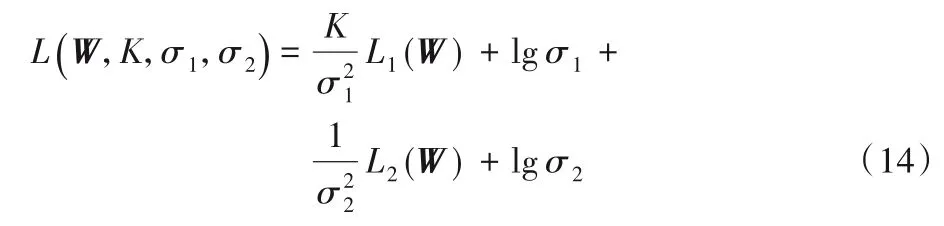
在模型训练过程中,σ1和σ2的更新受到学习率的限制,使得两任务的损失不会迅速达到平衡,因而即使超参数K取相同的值仍可以在模型的迭代过程中持续影响σ1和σ2的更新。若希望K能够全程调节主辅任务在网络中的作用,则要求K为一个变量。
3 实验结果与分析
3.1 实验环境与参数设置
本文的实验环境为:操作系统Ubuntu 18.04,CUDA 10.01;GPU 1080ti,显存11 GB;编程语言Python 3.7,机器学习框架Pytorch 1.6;编译器Pycharm Profession
实验参数如表2所示。

表2 实验参数设置Tab.2 Experimental parameter setting
可学习参数σ1和σ2初始值为0.1。此外,经实验测定K满足{K|K2=d+4,K>0}时,模型有较好效果,其中d为迭代次数。
3.2 评价指标
本文实验中使用序列标注任务常用的准确率P(Precision)、召回率R(Recall)和F1(F1 值)作为模型性能的评价指标,计算公式如下:

其中:TP(True Positive)表示测试集中被正确识别的标签数量,FP(False Positive)表示被错误识别的标签数量,FN(False Negative)表示测试集中没有被识别的标签数量。
3.3 结果分析
为了验证模型的有效性,本文设置了三组对比实验,各对比实验模型分别是:
1)BiLSTM-CRF(单任务):基于BiLSTM-CRF 的单任务事件抽取模型,在本实验中该模型为基准模型;
2)BiLSTM-CRF(多任务):基于BiLSTM-CRF 的事件抽取和命名实体识别多任务联合学习模型,较基准模型增加了对实体语义特征的提取;
3)BiLSTM-CRF(多任务+Lattice 机制):基于Lattice-BiLSTM-CRF 的事件抽取和命名实体识别多任务联合学习模型,该模型中的Lattice机制全部使用自组词查询结果,较基准模型增加对实体语义特征提取的同时,将词语语义信息融入相应的字向量中。
此外,由于FB-Latiice-BiLSTM-CRF 模型存在输出反馈机制,在训练方式上与对比实验模型不同。该模型单次迭代的训练过程如图5所示。
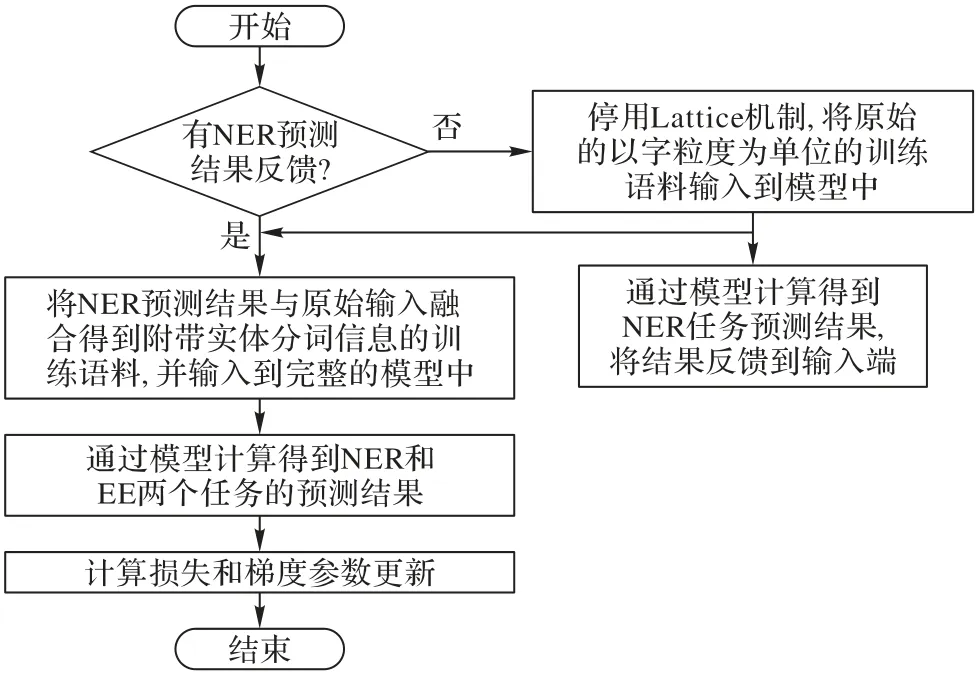
图5 FB-Latiice-BiLSTM-CRF单次迭代训练过程Fig.5 Single iteration training process of FB-Latiice-BiLSTM-CRF
四种模型在相同的超参数设置下进行训练,训练过程中分别取验证集上有最好结果的模型进行保存,最后在测试集上进行事件抽取的预测结果如表3 所示。可以看出,实体维度和词语维度的语义增强都对基准模型有明显提升;同时,本文提出的FB-Latiice-BiLSTM-CRF 相较于基准模型,在准确率、召回率和F1 值分别提升了7.63、4.41 和5.95 个百分点,验证了针对基准模型缺陷进行的模型结构改进和损失平衡优化是有效的。

表3 四种事件抽取模型在测试集的结果评价 单位:%Tab.3 Result evaluation of four event extraction models on test set unit:%
FB-Latiice-BiLSTM-CRF 模型由于将输出结果反馈到输入,实体分词位置信息与结果预测的实体位置信息相同,在命名实体识别任务上相当于正反馈作用,这会加速该任务的训练过程,进而提高整个模型训练的收敛速度。本模型和基准模型在验证集上F1值评价变化如图6所示。

图6 模型训练过程中在验证集上的F1值曲线Fig.6 F1 value during model training on verification set
4 结语
针对BiLSTM-CRF 模型在中文突发事件抽取任务上可学习语义特征维度较低的问题,本文提出了端到端的改进模型FB-Latiice-BiLSTM-CRF。该模型通过增加命名实体识别任务输出反馈机制和Lattice 机制,使用最大化同方差不确定性的最大高斯似然估计方法平衡各任务损失,提高了模型对词语和实体语义特征的学习能力。对比实验表明,改进后的模型在准确率、召回率和F1 值上均有明显提升,同时提高了模型训练中的收敛速度。该改进方法未对模型中间层进行限制,因此也可应用于其他使用LSTM 或门控循环单元(Gate Recurrent Unit,GRU)网络为底层网络的语言模型中,例如增加注意力机制的BiLSTM-Att-CRF(Bidirectional Long Short-Term Memory network-Attention-Conditional Random Field)模型,以BiLSTM 作为Encoder 的Seq2Seq 模型,预训练语言模型ELMo(Embeddings from Language Models)等。
本文提出的模型由于存在输出反馈机制,使用通用方法进行模型训练时,复杂度有所提高;此外,模型中主辅任务控制系数K的测定还缺少针对性的研究,目前只是在小范围值域内进行了局部优化。今后将针对这两个方向做进一步研究探索。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
