
甘肃榆中县常见草本植物检索系统的设计与实现
2021-07-28 07:19修炀景侯蒙京谢玉鸿冯琦胜梁天刚
草业科学 2021年6期
修炀景,侯蒙京,谢玉鸿,冯琦胜,梁天刚
(兰州大学草地农业生态系统国家重点实验室 / 兰州大学农业农村部草牧业创新重点实验室 /兰州大学草地农业教育部工程研究中心 / 兰州大学草地农业科技学院, 甘肃 兰州 730020)
植物分类是研究不同类群植物起源进化、发展规律和物种亲缘关系的学科,其方法是将不同类群的植物按照形态和生理特征,由主到次的异同进行分类直到种并最终按照系统的规则排列,以便于人类认识和利用植物[1]。植物检索是依照植物分类的规律和方法,通过深入了解某植物的特征后,在众多的植物中找到目标植物的过程[2]。植物分类与检索是植物学的重点和基础,也是众多生物学科发展的前提,这对植物资源的调查、物种多样性的认识与保护以及种群起源及进化的研究有着极其重要的作用[3]。
传统的植物分类研究主要依据生殖器官特征和营养体特征,采用平行式或定距式检索表进行检索和鉴定植物[2]。随着计算机的发展和普及,图像分类与识别技术有了新的手段和方法[4]。早在1996 年,英国国家植被分类系统(National Vegetation Classification)就基于法国的FLORA-SYS 开发而成,全面系统地总结了全英国的植被类型信息[5]。近年来,因多媒体数据库技术可以把图像和文字有机地结合起来,进而图像数据库构建、分类和检索工作在计算机应用领域被进一步拓宽[6]。其中,Access 技术因具有占据空间小、操作简便等优点,被成功地应用于植物分类检索中[7]。
徐世伟等[8]使用Delphi 编程工具和Access 数据库技术,实现了常见军事救生植物的查询与识别;胡杨[9]依据虚拟设计的使用环境不同,使用Access、SQL 以及VBA (Visual Basic for Applications)技术,完成了内蒙古地区唇形科植物数字化检索系统;袁小凤等[10]对三峡库区珍贵濒危植物数据进行调查,建立了基于Access 的植物地理分布信息查询数据库。尽管现存的植物数据库检索系统较多,主要是对某一范围内各种植物资源的整合,而针对单独某种特定类型植物的数据库较为少见。此外,现有的植物数据库中对植物形态特征多以文字或平面示意图的形式表达,缺乏相应草本植物的数字图像信息[6],致使现存的众多数据库检索系统中涵盖的草本植物信息数据不精不全,且检索查询的范围较大,操作极为不便,难以满足特定情况下的使用需求。
基于以上内容,本研究以甘肃省榆中县为研究区,使用摄影测量的方式采集草本植物资源信息,构建了包括植物名称、地理分布、形态特征、生态特征和3D 立体图像等信息的数字图像数据库,利用Access数据库和VBA 语言设计开发出了常见草本植物的检索系统,针对特定的草本植物类群进行相关数据的收集、归纳和整合,旨在为草地资源调查、草类植物鉴别分类以及科研教学工作提供数据与技术支持。
1 材料与方法
1.1 研究区概况
研究区位于甘肃省榆中县,地处103°49′15″ –104°34′40″ E,35°34′20″ – 36°26′30″ N,总面积3 259.77 km2,海拔1 430~3 670 m,年均降水量300~400 mm,年均气温6.6 ℃,属于温带半干旱气候。榆中县北部地形主要为低山丘陵,中部主要为黄土丘陵,植被类型主要以草原植被和荒漠植被为主;南部大部分位于兴隆山自然保护区境内,植被类型多样,植被覆盖度良好,植被类型主要以寒温性针叶林、落叶阔叶灌丛为主。榆中县整体位于甘肃省中部,地处森林植被向荒漠草原植被的典型过渡带,草本植物类型多样,数量较多,因此易于开展草本植物的数据收集工作[11](图1)。

图1 研究区采样点空间分布图Figure 1 Spatial distribution map of sampling points in the study area
1.2 数据收集与3D 建模
研究区内草本植物种类繁多,且许多草本植物的形态结构都较为类似,通过实地调查对植物进行分类识别。植物信息采集的主要步骤包括:1)位置确定:以GPS 数据为主,参考榆中县植物分布图[12],确定植物生长的位置;2)植物识别标注:对所有种类的植物进行人工标注,确定植物名称并记录,对于一些不能确定的物种,参照《中国植物志》或咨询草本植物识别经验丰富的专家,对这些植物进行反复验证,确保识别精确;3)植物图像数据采集:通过摄影测量方法,以适当的距离从植物各部分(花、叶、茎和果实等)进行多角度拍照;遇到植株较小或根系较浅的草本植物,还需挖取其地下部分拍摄,从而获得全方位、完整的植物数字图像信息。采集的植物图像数据要求主体突出,背景简单,细节清晰。通过中国植物图像库网站(http://ppbc.iplant.cn/)下载图像对植物图像数据做进一步补充说明[13]。
植物信息预处理:以人工筛查的方式对实地拍摄图像进行清选,从中筛除模糊、高反光和背景杂乱等未达到拍摄要求的图像数据。由于清选后部分物种的图像数量较少,因此选择水平镜像翻转,顺、逆时针90°翻转,裁剪等方式进行数据扩增并进一步归纳整理[14]。最后以《中国植物志》为标准,对各种植物数据进行标准化处理,建立草本植物图像数据集。将搜集到的植物信息归纳整理且把每个物种作为一个单独的子数据集;Access 数据库中每个数据集为单个文件,最大理论容量2 G;当数据储量过大时,可使用Access 的数据项目直接联系到SQL(Structured Query Language),通过新建一个数据库项目将其导入即可实现。
利用Agisoft Photoscan 软件实现植物3D 模型的建立。Agisoft Photoscan 是一款根据数码相片将2D图片数据转化为3D 模型数据的三维重组软件,该软件的三维重组技术的最大特点和优势是无需设置初始值,软件即可自主识别所添加图片数据的重叠部分,从而完成建模任务(http://www.agisoft.cn/)。通过添加模块、添加照片、对齐照片、成对预选、建立密集点云、设置工作区、生成网络、生成纹理等一系列方法构建植物三维模型(图2、图3)。
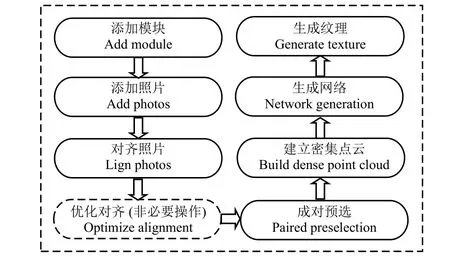
图2 Agisoft Photoscan 3D 建模流程图Figure 2 Flow diagram of Agisoft Photoscan 3D modeling

图3 植物三维模型图(示例)Figure 3 Plant 3D model diagram (sample)
草本植物数字图像数据收集时间为2019 年4 月至9 月,共获得9 372 张照片。其中,数码相机实地摄影测量采集到256 种草本植物的图像数据,涉及禾本科、豆科、十字花科等13 个科,共5 664张;通过中国图像数据库下载到的图像数据共3 708张。由于在植物图像数据实地采集过程中不可避免存在未达到建模标准的图像数据,会造成建模成功率降低,因此最终共建立植物3D 模型211 种(表1)。

表1 进行3D 建模的植物物种清单Table 1 List of plant species for 3D modelling
1.3 关键技术介绍
该软件系统开发基于Delphi 编程工具和Office中的Access 来设计实现。其中前端的操作功能利用Delphi 编写VBA 语言完成,后台数据库采用Access管理工具。Delphi 是一种基于窗口、面向对象和可高速编译的可视化编程工具。Delphi 能完成从底层、网络到平台开发等一系列工作,运用范围广,尤其是在数据库开发方面更具优势[15]。VBA 是新一代标准宏语言,该语言简单且功能强大。它由微软公司开发,在其桌面应用程序中执行通用的自动化任务的编程语言,是可视化、解释性以及面向对象的BASIC 语言。Access 是一种数据库管理系统,它所占据的空间较小,系统逻辑清晰且操作简便,一直以来都被广泛作为中小型数据库后台存储的理想介质。它具有和Office 软件功能相似的数据库,允许使用子数据表,允许从Excel 或向Excel 导入数据,能对数据的相关数据自动更正,能通过设置条件来控制结果输出,并在关闭时对文件自动进行压缩调整[16]。
1.4 草本植物检索功能精度评价
为了保证检索系统的可靠性,分别用正向检索途径和反向检索途径两种检索方式进行精度评价。正向检索的精度评价是从数据库中所涵盖的所有物种中,通过随机选择的方式挑选出10 种草本植物,查询字段选择为名称并在查询内容中输入中文名称(或拉丁名),逐一判断输出结果是否与目标植物一致。其精度评价公式如下:

式中:P为识别准确率;x为检索结果正确的物种数,y为正向检索的物种总数。
在反向检索途径中,根据限定信息的数目,对不同科属物种的识别精度进行分类评价。从各类不同科属植物中随机选择5 种(车前科除外),随机选择每个植物较为明显或较易观察的形态特征(如叶形、叶序、花色、花序、萼片数和种子类型等特征)进行查询,得到目标物种数并计算其平均数,进而计算出该科属植物识别准确率。其精度评价公式如下:

式中:P为识别准确率;n为随机选择的物种个数(n= 5);x为各物种经查询得到的目标物种数;y为数据库中的总物种数(y= 256)。

续表1Table 1 (Continued)
2 系统设计
2.1 系统构架设计
该系统遵循 MVC 的分层设计思想,将系统整体上分为数据层、应用逻辑服务层以及表现层[17](图4)。数据层由植物素材知识库和植被信息知识库组成,通过植物编号字段进行一对一主键关联。这样设计便于清晰明了地表示实物显示中的关系,方便数据管理以及功能扩展。表现层由登录界面和系统前台界面组成,其中登录界面包含用户名、密码、登录按钮和退出按钮,这样设计的优点在于操作简洁,便于对用户标识鉴别和后台登录信息的审核管理。系统前台界面包含查询字段、查询内容、查询按钮、重置按钮以及植物的各类相关信息,此设计方便查询操作,且能清楚地显示植物信息。逻辑服务层可以实现数据的“查改增删”,利于对存取控制和视图机制的安全管理。通过ID 唯一身份标识码检索,逻辑层面的检索成功率可达100%,能准确地查询到目标对象;通过植物各字段信息关键词检索,逻辑层面的检索成功率较高,且随着关键词数目的增加而提升。
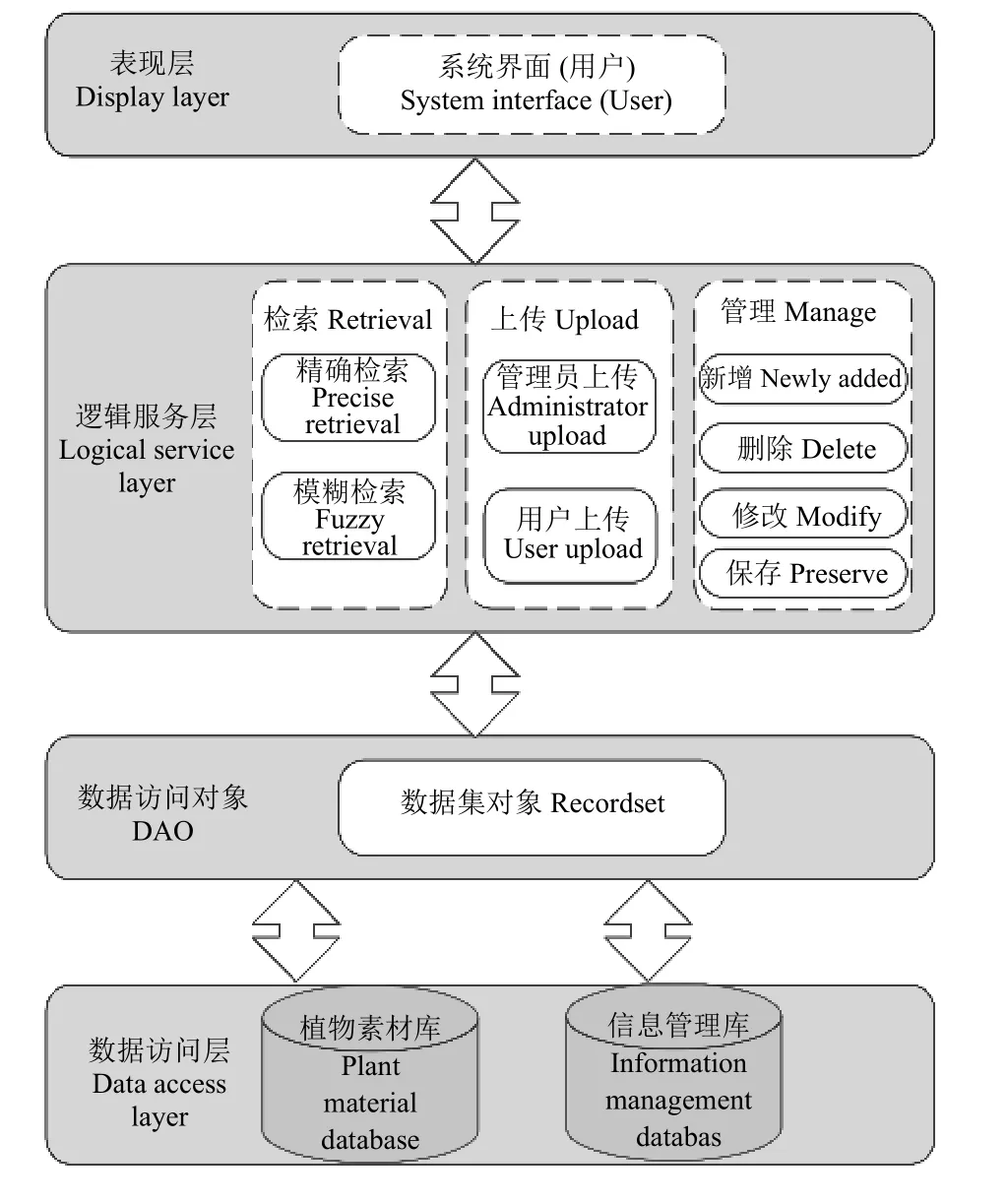
图4 检索系统结构层次图Figure 4 Hierarchy of retrieval system structure
2.1.1 数据层(Model)设计
新建类模块并命名为Model,为tblData 中各字段定义私有变量,使用DAO 中的Recordset 对象作为中介。上述代码对Recordset 对象变量mrst 的定义完成后,在类的实例化事件中为mrst 创建基于表tblData 的数据集,其中tblData 位于本地,若转移tblData 只需修改此处的代码即可。此外为Model 类模块设计外部接口,在考虑外部接口对私有变量读取的基础上设计“查改增删”接口。
1)查询接口:查询接口通过函数设计实现。该函数由植物名称,叶形、叶序、花色、种子类型,耐寒性,水分要求和地理位置等字符串构成,这些字符串将形成一个唯一标识的ID,通过form 表单传递的方法进行传参。需注意的是一个函数只能返回某单一值,而此处需返回的值包括多个字段,因此将返回值保存在类的私有变量中。此处使用到Recordset的Seek 方法[18],该方法需为其提供索引值,具有较快的查询效率。
2)修改接口:由逻辑分析可知,对于tblData 某条数据的修改,需找到目标数据所在字段,如植物编号、植物名称、生长环境、地理分布范围和形态特征等,再将修改值返回到函数数据中。此处通过向接口函数传递Model 类型的参数实现,即向Model类中的函数Update 传递Model 类参数,再将Model类对象作为Update 参数,即使用新的植物信息数据覆盖原有的数据。这两类参数均为动态参数,参数文件内容包含植物的文字信息数据或图象信息数据。此方法的优点是既能传递所需修改的目标信息,又可以传递修改后的目标值。
3)新增接口:向tblData 添加一条记录,需要提供新记录所有字段的值。综上,此处仍为接口函数传递Model 类型的参数,即代码首先根据提供的参数查看是否能在已有数据中查询到目标(此处提供的参数以植物编号和植物名称为主)。若不能查询到目标则允许将记录添加到tblData 中。
4)删除接口:该接口提供数据的某一字段信息(此处字段以植物编号和植物名称为主),找到后将其删除即可。
2.1.2 逻辑服务层(Controller)设计
再次创建类模块,命名为Controller。定义两个对象变量,分别为数据层和视图层中的植物信息参数并点击系统前台界面中的重置按钮将其初始化。由于View 初始化时,需要向其指定一个具体窗体,即需将该窗体作为系统的前台界面。因此为Controller设计一个Init 接口,该接口可链接到目标窗口从而将植物的信息数据传入具体的窗体对象。使用控制器层(Controller)实现“查改增删”接口。重新实现“查改增删”无需重写数据层代码,而是将以上操作代理给模型层(Model)对象变量mobjModel。
2.1.3 视图层(View)设计
设计一个将数据显示到窗体界面的接口,并用窗体(Form)作为用户界面。此处不直接在窗体代码模块中处理数据的显示问题,而是额外用一个类模块View。声明一个Access 窗体变量,将数据显示到窗体上。虽然已有mfrm 窗体对象变量,但在代码运行时并不确定该对象变量将会指向的具体窗体,因此在View 对象在初始化后为mfrm 指定一个具体窗体用以完整的显示各类型植物信息。同时,在View 类对象销毁时释放掉mfrm 的指针,实现接口函数Display 用以将植物的各字段信息显示到mfrm窗体上,该接口函数Display 使用超链接的方法传递参数:当点击检索系统前台的查询按钮后跳转到类模块View 的初始化对象,进而传递植物编号(ID)和植物名称(Name)参数。设计一个反向接口GetDisplayedData 用以获取mfrm 窗体上所显示的数据。最后添加帮助函数,该函数同样通过超链接的方法传参,方法是点击系统前台界面中的重置按钮,用以清空mfrm 窗体上数据的显示。
2.2 数据库逻辑设计
数据库逻辑设计是将系统接收到的用户需求通过信息的提取进而转化为概念模型信息的过程,该设计得以实现的理论依据是各个数据信息内部存在的语义关联性,通过信息内部的关联得到抽象模型。本系统用到的模型为E-R 模型[19],该模型是对于现实的抽象表现,其基本语义包括实体(科属种)、实体属性(科属种拉丁名和中文名、地理分布、形态特征以及生长环境)与集合之间存在的联系(属从属于科、种从属于属)。本系统的逻辑设计原则是将E-R 图,即实体与实体、实体与属性之间的关联性按照一定的原则转化为关系模型,并确定模型的属性和码[19]。转化原则如表2 所列。

表2 系统逻辑算法流程Table 2 System logic algorithm flow
2.3 系统模块(功能)设计
系统的设计模块(图5)显示,用户对该检索系统使用过程中,可在主页面下通过不同的检索字段来选择其中某一种方法,根据所掌握的数据信息选择合适的查询字段,例如植物中文名称、拉丁名、形态特征、地理分布和生长环境等进行检索操作,系统经过逻辑运算后,在页面的下方给出所有符合限定条件的检索结果。除此之外,用户可通过输入户名和密码进入管理界面,执行植物信息的增加删除管理功能[20]。
在后台管理模块中,用户可通过输入用户名和密码进入系统的管理界面,在此可完成数据的修改,添加和删除,包括植物名称、形态特征、地理分布和生长环境等文本信息和图像数据。在植物检索模块中,用户可通过名称、形态特征、生长环境、地理分布4 个方面的信息检索植物(表3)。通过正向检索途径查询某植物中文名或拉丁名,当系统在数据库中检索到目标植物后,会将结果输出给用户;用户也可通过反向检索途径查询某植物除名称外其余不同字段的关键词,即给出某种植物的形态特征等信息来确定植物名称。每个部分都支持关键词检索,这提高了模糊查询的成功率[21]。

表3 植物信息统计表Table 3 Statistical table of plant-related information
3 系统的实现
3.1 系统基础功能实现
在系统登陆界面(图6)输入特定的户名及密码即可进入后台管理界面,该界面与检索系统界面相同,但区别在于当处于管理界面下,各文本信息模块均可实现增删和修改,且图片信息模块下方的添加/修改、保存并新增和删除图片按钮可执行操作;而当处于访客登陆状态,即处于检索界面时,以上操作均不可被执行和实现,但用户可通过管理员获得管理许可进行信息编辑。
图6 系统登陆界面Figure 6 System login interface
在该系统中,可根据不同字段进行多条件联合查询(图7)。系统主界面主要可分为检索模块、文字信息模块(包括植物编号、名称、生长情况、地理分布、形态特征等基本信息)和图片信息模块。使用者可通过检索模块正向检索,将查询字段选为名称,在查询内容中输入物种名称,点击查询即可显示对应的植物信息,选择重置即可重新检索。使用者也可通过检索模块反向检索,如:将查询字段选为生长环境,输入该植物的地理分布范围,点击查询;继续将查询字段选为形态特征,输入该植物的外部形态,点击查询;这样通过逐级检索的方式即可查询到目标植物的名称,最后选择重置即可重新检索。在反向检索时,当输入某植物的部分信息进行检索并选择查询后,会展示当前限定条件下所有符合的植物类型。所以若想准确地确定目标植物名称,须尽可能多的确定该植物的特征信息,从而缩小目标范围,并对照各植物的特征信息、图像数据以及3D模型,最终确定目标植物。

图7 系统检索界面Figure 7 Search system interface
3.2 系统稳定性评价
本系统使用的工作站处理器为AMD Ryzen R5-4600H,主频为3.00 GHz,动态加速频率4.00 GHz,16 G 内存,显卡GTX 1650Ti,运行系统为Windows 10。启动该检索系统时CPU 占用率约保持在20%,但随着使用时间延长,CPU 占用率会随之增长,在35%左右逐渐趋于平稳;内存使用率随系统运行时间的延长变化不大,基本维持在17%左右(图8)。在整个使用过程中系统响应时间较快,未出现明显迟滞。Access 最大支持数据可达2 G,数据库最多可支持约255 个并发访问。除了在CPU 满负载运行时,其余大部分情况下的使用一般不会感觉到明显迟滞现象。说明系统运行较为稳定,可满足绝大部分使用需求。

图8 CPU 占用率以及内存使用率变化图Figure 8 CPU utilization change chart
3.3 系统检索功能精度评价
为了保证检索系统的可靠性,分别对正向检索途径和反向检索途径两种检索方式进行精度评价(表4)。经判定,正向检索途径识别准确度接近100%,说明精确查询准确性良好。在反向检索途径中,当输入的形态特征信息数为3 条时,识别准确率最高的是车前科,达到100%,其次是莎草科和藜科,两者分别达到77.7%和76.5%,准确率最低的是禾本科,为56.9%。当输入的形态特征信息数为6 条时,识别准确率最高的是车前科、旋花科、莎草科和蒺藜科,均达到100%,其次是蔷薇科和豆科,分别为90.0%和89.7%,准确率最低的仍是禾本科,为82.4%。随着限定信息条数的增加,各科植物物种的识别精度都得到了提高,尤其是旋花科、禾本科等识别精度提升明显,分别上升了28.6%和25.5%。该系统对各科物种识别准确率的高低存在差异的主要原因是由于各科不同种的植物形态特征的相似程度不同以及各科植物在数据库中的总容量不同。但可以肯定的是,限定的信息数目越多,对植物的形态特征描述越准确,得到的目标范围越小,也就越容易确定目标植物。
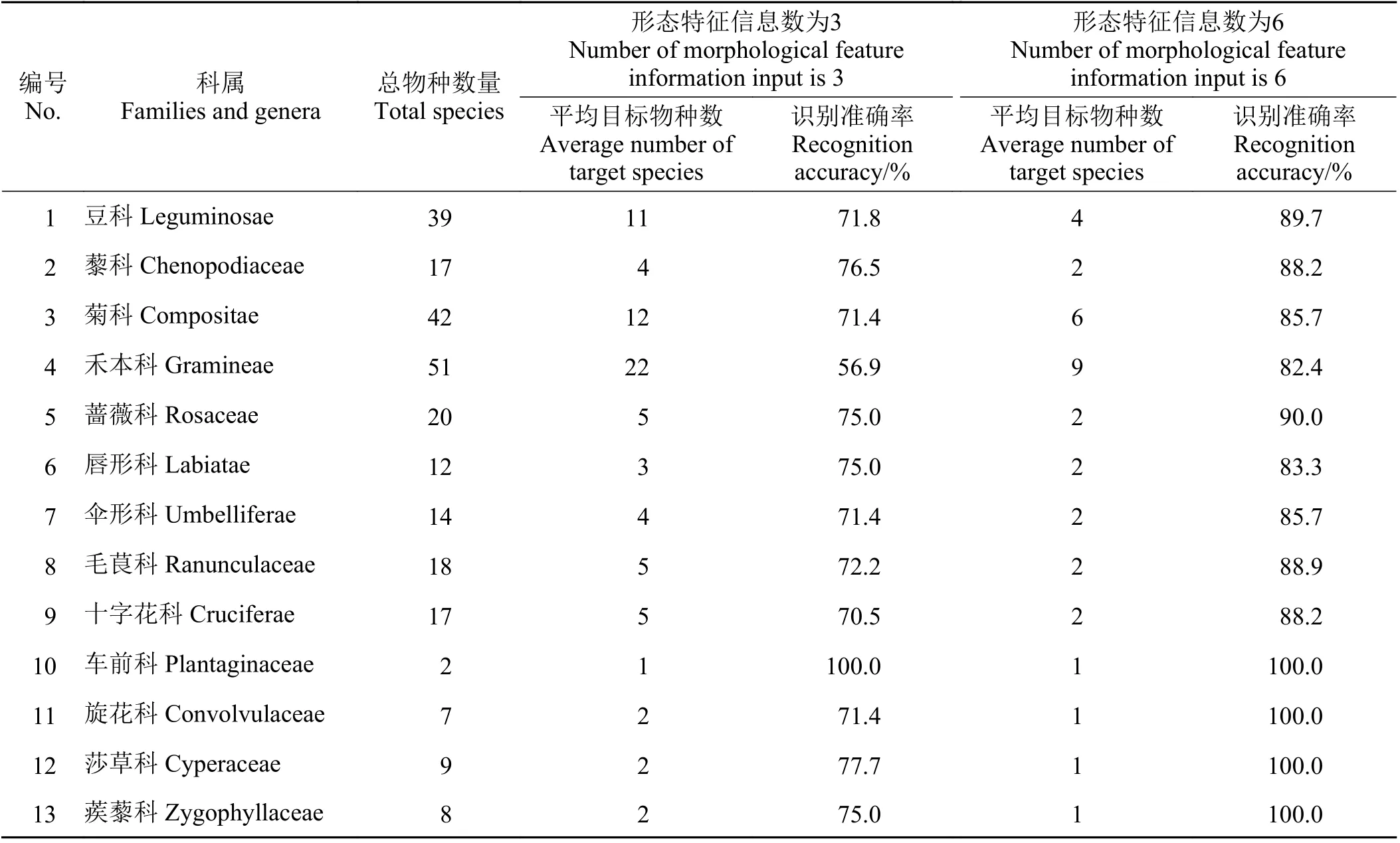
表4 不同科植物物种模糊查询准确率Table 4 Accuracy of plant species identification in different families
4 讨论与结论
本系统基于Access 数据库,利用VBA 语言编写完成,通过多种方式对256 种草本植物的数据进行收集、整理和分类,构建出草本植物检索系统。经验证,当输入形态特征信息数为3 条时,除了禾本科以外,植物识别率均在70%以上;输入形态特征信息数为6 条时,植物识别率均在80%以上,其中车前科、旋花科、莎草科和蒺藜科识别率可达到100%。该系统检索准确度较好,能够胜任日常使用需求。其中,禾本科识别精度较低,原因主要是禾本科各物种之间形态特征相似度较高,识别难度较大。
与传统方法相比,本系统不必逐条判断植物形态特征,检索效率得到极大提高。为了体现与传统检索方法相比之下的高效性,分别测试了在正向检索和反向检索情况下两种检索方法的效率差异(表5)。在相同时间内对选取同一批植物依次进行检索,并保证检索结果正确无误。经判定,5 min 内使用该检索系统的正向检索数目为66 个,反向检索数目为19 个;5 min 内使用中国植物志的正向检索数目为9 个,反向检索的数目为4 个。

表5 5 min 内检索正确的物种数量Table 5 Retrieval of the correct number of species in five minutes
本系统也仍有一些待改进之处,如利用实地拍摄和网络数据补充两种方式完成了对草本植物图像数据的收集,并对部分物种数据进行了扩增,但仍存在部分植物图像数据少的问题,进而影响3D建模的结果;本系统目前尚不支持网页端和移动端的使用,使用中存在一定的局限性。这些都是在后期需要注意完善和改进优化的方面。今后进一步研究考虑扩大研究区域,收集更多草本植物图像数据,优化数据库结构,对常见的植物形态结构做出图文示意,扩大系统适用群体。此外,将数据库部署发布至网页端和移动端,实现更加便利的草本植物信息检索,以期为开展草地资源调查监测、科研教学等方面提供技术支持。
此外,该系统便携性更好,更利于在户外环境中的使用;其他同类检索系统,如孙学刚等[22]完成的甘肃省稀有濒危植物数据库和田兴军等[5]完成的江苏植物资源信息系统,其系统内的植物信息虽覆盖面广,但数据体量大,针对于草本植物的检索效率低,且录入的信息不够精细,致使模糊查询效果不理想。本数据库所包含的数据仅限于草本植物,数据信息与之相比更加精细完整,模糊查询准确度更高;数据体量较小,系统反应速度快,使用体验良好。此外,本系统还为每种植物构建了3D 模型,使用户对植物形态特征有更直观的感受,同时也可依据其提高模糊查询准确性。Access 在数据量过大或访问人数较多时IIS(Internet Identity System)可能会出现假死现象。管理者可通过定期编辑数据、压缩数据库、限制注册与登陆人数等措施来保证其良好的使用性。若系统使用的需求量较多或数据量很庞大时,可以考虑将Access 数据库转化为SQL 数据库。
猜你喜欢
档案天地(2019年5期)2019-06-12
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
专利代理(2016年1期)2016-05-17
计算机与网络(2013年6期)2013-10-16
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
智能计算机与应用(2007年4期)2007-08-25
