
基于FPGA的通用卷积层IP核设计
2021-07-25 03:04安国臣袁宏拓韩秀璐王晓君侯雨佳
河北科技大学学报 2021年3期
关键词:卷积神经网络
安国臣 袁宏拓 韩秀璐 王晓君 侯雨佳
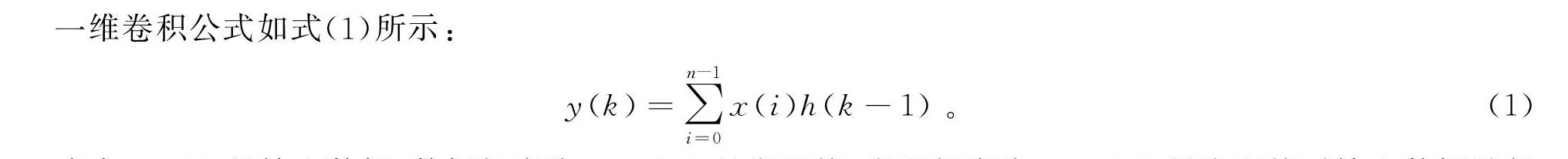
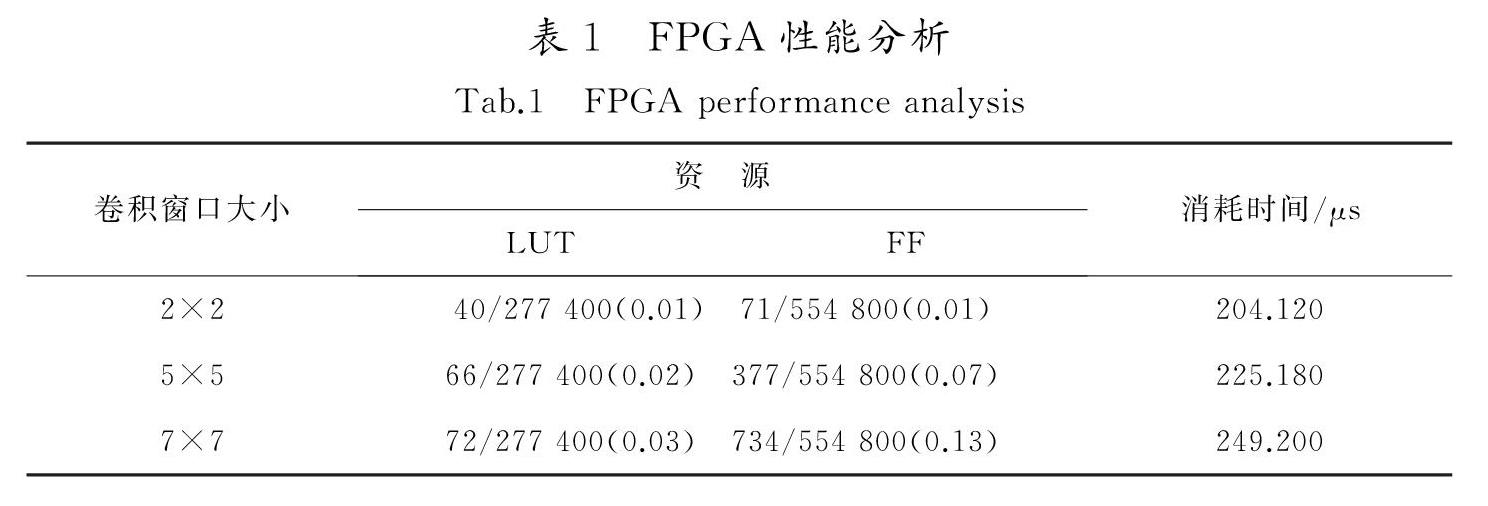
摘 要:针对目前卷积神经网络在小型化、并行化过程中遇到的计算速度不够、可移植性差的问题,根据卷积神经网络和FPGA器件的特点,提出了一种利用VHDL语言参数化高速通用卷积层IP核的设计方法。利用卷积层的计算方式,将卷积核心设计为全并行化、流水线的计算模块,通过在卷积核心的每一行连接FIFO的方式改善数据流入的方式,减少地址跳转的操作,并加入控制核心使其可以随图像和卷积窗口大小调整卷积层参数,生成不同的卷积层,最后將卷积层与AXIS协议结合并封装成IP核。结果表明,在50 MHz的工作频率下,使用2×2大小的卷积核对100×100的图像进行卷积计算,各项资源利用率不超过1%,耗时204 μs,计算速度理论上可以达到最高5 MF/s。因此,设计方案在增加卷积模块可移植性的同时又保证了计算速度,为卷积神经网络在小型化器件上的实现提供了一种可行的方法。
关键词:集成电路技术;卷积神经网络;FPGA;卷积层;设计参数化
中图分类号:TP274;TP391 文献标识码:A
doi:10.7535/hbkd.2021yx03005
Design of universal convolutional layer IP core based on FPGA
AN Guochen1, YUAN Hongtuo1, HAN Xiulu1, WANG Xiaojun1, HOU Yujia2
(1.School of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang,Hebei 050018,China;
2.Shijiazhuang Foreign Education Group,Shijiazhuang,Hebei050022,China)
Abstract:Aiming at the problems of insufficient computing speed and poor portability in the miniaturization and parallelization of convolutional neural network,this paper proposes a design of high-speed universal convolutional layer IP core using VHDL language based on the characteristics of convolutional neural network and FPGA devices.Layer based on convolution calculation,convolution core design is put forward for the parallel calculation and pipeline module,through each line in the convolution of the core connect to FIFO to improve the data flow,reduce the operating address jump,and join the control core to make it can adjust the convolution with images and convolution window size to layer parameters,generate different convolution layer,finally,the convolution layer is combined with the AXIS protocol and encapsulated into IP core.Under the working frequency of 50 MHz,the convolution calculation of 100×100 images with 2×2 convolution check is carried out.The utilization rate of each resource is less than 1%,and the time is 204 μs.The theoretical calculation speed can reach the maximum of 5 MF/s.The IP core structure of the convolutional layer not only increases the portability of the convolutional module,but also ensures the computing speed,which provides a feasible implementation method for the implementation of convolutional neural network on miniaturized devices.
Keywords:
integrated circuit technology;convolutional neural network;FPGA;convolution layer;design parameterization
随着深度学习研究的发展,卷积神经网络在语音识别[1]、图像理解[2]、目标跟踪[3-4]等领域发挥着重要作用。卷积神经网络既需要在原理和结构上继续研究以达到更好的性能指标和迁移能力,也需要更好地把现有神经网络适用到各种实时性、小型化的场合[5]。越来越多的神经网络加速结构被提出,如将卷积层二值化[6]以减少FPGA的运算量、专用的加速SOC[7]使CNN峰值计算性能在100 MHz下达到42.13GFLOPS等。基于此提出了一种参数化设计的通用卷积层IP核加速结构,该结构适用范围更广。
所提出的通用卷积层IP核设计,属于加速器设计通用化,是卷积神经网络加速器设计研究与发展的一个重要方向[8]。该设计通过VHDL语言的参数化设计[9],对一种卷积层加速结构[10-11]进行重构,使其由一种定长卷积加速结构改进为可以生成不同大小卷积窗口的通用卷积核。可移植性方面,通过参数配置IP核,预先配置其窗口大小,被卷积信号或图像大小,即可生成一维、二维不同大小的卷积层,满足不同的卷积计算需要。计算速度方面,优化数据流入方式,避免了地址的跳转,引入并行化和流水线思想,在数据传输不间断的情况下,一个时钟周期即可输出一个有效计算结果。该设计支持AXI4-Stream协议,硬件开发人员可以快速调用该卷积层IP核完成卷积层的开发,不必再把精力浪费到内部卷积结构的设计上。
1 卷积层原理
卷积层有一维卷积层、二维卷积层和多维卷积层,同一种卷积层根据卷积窗口大小的不同也不同,这里主要介绍一维卷积层和二维卷积层。
1.1 一维信号卷积
一维卷积通常被用于时间序列的处理,一维卷积神经网络(1-dimensional convolutional neural network,简称1DCNN)多用于工业故障诊断[12]、医疗诊断[13]等需要对时间序列进行处理的场合。
图1为一维卷积示意图,k个点的时间序列和n个点的卷积核做卷积运算,时间序列从左到右滑动,每次滑动对应数据相乘相加输出一个卷积结果,作为下一层卷积层或者池化层的输入。一维卷积运算又等效于FIR滤波器的直接型结构。
一维卷积公式如式(1)所示:
y(k)=∑n-1i=0x(i)h(k-1)。(1)
式中:x(i)是输入数据,数据长度为k;h(n)是卷积核,卷积长度为n;y(k)是卷积核对输入数据进行卷积后的输出,数据长度为k,在边带不补零的情况下,数据长度为k-n+1。
1.2 二维图像卷积
二维卷积神经网络(2-dimensional convolutional neural network,简称2DCNN)多用于计算机视觉的处理[14-15],通过卷积核模拟人类大脑的神经元对卷积层输入进行局部感知,模拟人脑神经元感知到生物电信号的反应并将感知结果输出。
图2为二维卷积层示意图,一个卷积核模拟的神经元在输入图像上滑动,遍历所有图像数据,每滑动一次,对应的图像数据和卷积核权值相乘求和输出。
二维卷积公式如式(2)所示:
y(p,q)=∑m-1j=0∑n-1i=0x(i,j)h((p-i),(q-j))。(2)
式中:x(i,j)為输入数据,一般为图像数据;图像大小为p×q;h((p-i),(q-j))为卷积核;卷积核的窗口大小为m×n;y(p,q)为输出数据,数据长度为p×q,在边带不补零的情况下,数据长度为(p-m+1)×(q-n+1)。
2 FPGA构架分析
从1988年提出的LeNet-5模型到经典的VGG-16模型,卷积层由最初的2层增加到了13层,甚至在152层的ResNet网络中达到了50层。卷积层数的增加意味着计算量的增加,卷积层的计算量在CNN中占比高达90%[16]。因为神经元和感受野之间的局部连接特点,同一个卷积层下的卷积核是可以并行计算的,同一个卷积核的所有感受区域也是可以并行计算的,所以卷积层可以有很高的并行性。
为了兼顾速度和资源,卷积层一般采用并行加流水线相结合的方式。在某一个感受野内的计算是并行的,即1次计算1个卷积结果。同一个卷积窗口在输入图像上的滑动是流水线式的,即所有数据依次进入卷积窗口进行计算,既增加了并行度、提高了计算速度,又相对节省资源。
对于一个感受野中的单次卷积运算,以5×5大小的卷积窗口为例,对于FPGA并行结构的卷积核,在流水线结构下,1个运算周期可以输出1个卷积结果;对于基于冯诺依曼结构或者哈佛结构的通用中央处理器,1次卷积需要执行25次乘法和24次加法,共计49次计算,加上每次卷积中必须的地址跳转等操作,至少需要50个运算周期才能输出1个卷积结果。通过对比可知,在相同频率下,5×5大小的卷积窗口,基于FPGA的卷积核的计算速度是基于通用中央处理器的50倍以上。
由于传统的FPGA电路定制化的特点,针对固定结构设计的卷积核很难移植到其他算法结构中[17-20],甚至在同一个算法结构中,一个3×3的卷积核也很难扩展成5×5的卷积核。为了解决卷积层加速结构不便移植的缺点,提出了如图3所示的通用卷积层加速结构。由图3可知,该卷积层加速结构的通用性在于仅需在通过生成卷积层时,配置几个简单的参数,即可生成含有指定大小卷积窗口的卷积层。3×3,5×5,7×7甚至是类似于3×5非正方形的卷积窗口和1×N大小的一维卷积窗口,都可以通过简单的配置生成。
该卷积层加速结构支持AXI4-Stream协议,通过AXI4总线获取数据。卷积层结构主要分为3个部分,分别是控制核心区、数据缓存与预处理区和并行计算区。控制核心区负责接收和产生状态信号,通过AXI4总线与外部交互并且通过控制内部FIFO的使能信号控制数据的预处理和计算。数据缓存与预处理区在控制信号的控制下,将输入的数据流分别存入不同的FIFO中,每一行都配有一个FIFO。并行计算区不接受控制核心区的控制,在时钟、使能和复位的控制下独立地进行乘累加操作。
3 通用卷积层IP核设计
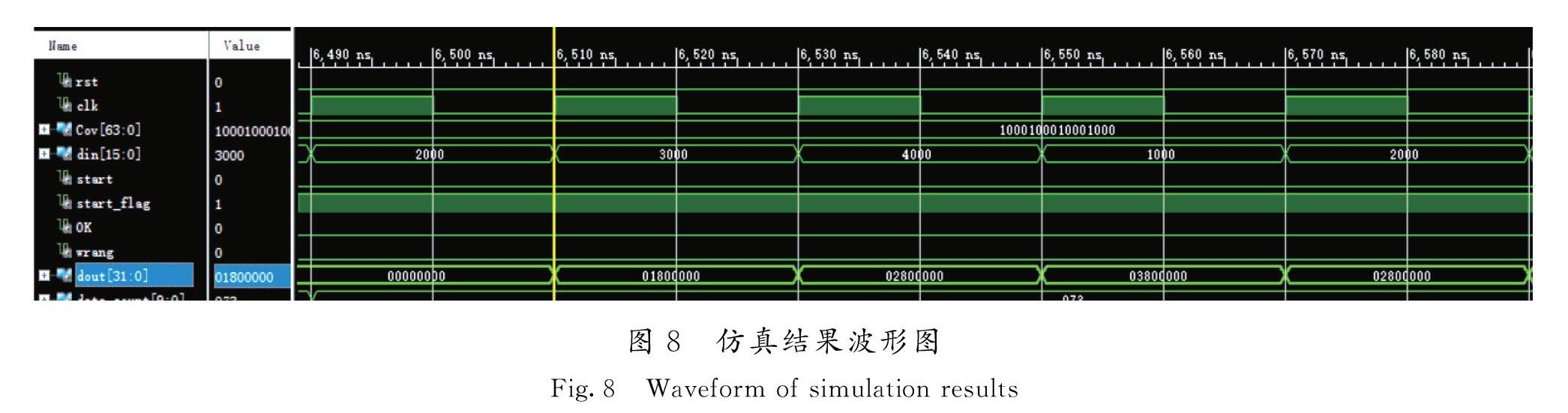
通用卷积层IP核模块运用类属参数语句generic和生成语句generate相结合的方式进行参数化设计。通过在生成IP核时配置参数,将要生成的IP核信息传递进入生成语句,生成特定大小的并行计算电路。计算时,将图像的大小信息输入控制核心模块,由控制核心负责切换卷积核的运行状态。
[4] PEI Xia,LI Dong,WANG Lijun,et al.Deep visual tracking:Review and experimental comparison[J].Pattern Recognition.2018,76:323-338.
[5] 李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].自动化学报,2016,36(9):2508-2515.
LI Yandong,HAO Zongbo,LEI Hang.A review of convolutional neural networks[J].Acta Automatica Sinica,2016,36(9):2508-2515.
[6] 蒋佩卿,吴丽君.基于FPGA的改进二值化卷积层设计[J].电气开关,2019(6):8-13.
JIANG Peiqing,WU Lijun.Design of improved binarization convolutional layer based on FPGA[J].Electric Switchgear,2019(6):8-13.
[7] 赵烁,范军,何虎.基于FPGA的CNN加速SoC系统设计[J].计算机工程与设计,2020,41(4):939-944.
ZHAO Shuo,FAN Jun,HE Hu.Design of CNN acceleration SoC system based on FPGA[J].Computer Engineering and Design,2020,41(4):939-944.
[8] 陈桂林,马胜,郭阳.硬件加速神经网络综述[J].计算机研究与发展,2018,56(2):240-253.
CHEN Guilin,MA Sheng,GUO Yang.A review of hardware-accelerated neural networks[J].Journal of Computer Research and Development,2018,56(2):240-253.
[9] 孙延腾,吴艳霞,顾国昌.基于VHDL语言的参数化设计方法[J].计算机工程与应用,2010,46(31):68-71.
SUN Yanteng,WU Yanxia,GU Guochang.Parametric design method based on VHDL language[J].Computer Engineering and Applications,2010,46(31):68-71.
[10]刘志成,祝永新,汪辉,等.基于FPGA的卷积神经网络并行加速结构设计[J].微电子学与计算机,2018.35(10):80-84.
LIU Zhicheng,ZHU Yongxin,WANG Hui,et al.Design of convolutional neural network parallel acceleration structure based on FPGA[J].Microelectronics & Computer,2018,35(10):80-84.
[11]陈煌,祝永新,田犁,等.基于FPGA的卷积神经网络卷积层并行加速结构设计[J].微电子学与计算机,2018,35(10):85-88.
CHEN Huang,ZHU Yongxin,TIAN Li,et al.Design of convolutional layer parallel acceleration structure of convolutional neural network based on FPGA[J].Microelectronics & Computer,2018.35(10):85-88.
[12]安晶,艾萍,徐森,等.一种基于一维卷积神经网络的旋转机械智能故障诊断方法[J].南京大学学报(自然科学),2019(1):133-142.
AN Jing,AI Ping,XU Sen,et al.An intelligent fault diagnosis method for rotating machinery based on one-dimensional convolutional neural network[J].Journal of Nanjing University(Natural Science),2019(1):133-142.
[13]黃佼,宾光宇,吴水才.基于一维卷积神经网络的患者特异性心拍分类方法研究[J].中国医疗设备,2018(3):11-14.
HUANG Jiao,BIN Guangyu,WU Shuicai.Patient - specific cardiopap classification based on one-dimensional convolutional neural network[J].China Medical Devices,2018(3):11-14.
[14]王礼贺,杨德振,李江勇,等.卷积神经网络在目标检测中的应用及FPGA实现[J].激光与红外,2020,50(2):252-256.
WANG Lihe,YANG Dezhen,LI Jiangyong,et al.Application of convolutional neural network in target detection and FPGA implementation[J].Laser and Infrared,2020,50(2):252-256.
[15]江泽涛,刘小艳,胡硕.基于CNN的红外与可见光融合图像的场景识别[J].计算机工程与设计,2019,40(8):2289-2294.
JIANG Zetao,LIU Xiaoyan,HU Shuo.Scene recognition of infrared and visible fusion images based on CNN[J].Computer Engineering and Design,2019,40(8):2289-2294.
[16]HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).New York:IEEE,2016:770-778.
[17]王婷,陈斌岳,张福海.基于FPGA的卷积神经网络并行加速器设计[J].电子技术应用,2021,47(2):81-84.
WANG Ting,CHEN Binyue,ZHANG Fuhai.Design of convolutional neural network parallel accelerator based on FPGA[J].Application of Electronic Technique,2021,47(2):81-84.
[18]张旭欣,张嘉,李新增,等.二值VGG卷积神经网络加速器优化设计[J].电子技术应用,2021,47(2):20-23.
ZHANG Xuxin,ZHANG Jia,LI Xinzeng,et al.Accelerator optimization design of binary VGG convolutional neural network[J].Application of Electronic Technique,2021,47(2):20-23.
[19]張帆.图像卷积实时计算的FPGA实现[J].电子设计工程,2021,29(1):132-137.
ZHANG Fan.FPGA implementation of image convolution real-time computation[J].International Electronic Elements,2021,29(1):132-137.
[20]范军,巩杰,吴茜凤,等.基于FPGA的RNN加速SoC设计与实现[J].微电子学与计算机,2020,37(11):1-5.
FAN Jun,GONG Jie,WU Xifeng,et al.Design and implementation of RNN accelerated SoC based on FPGA[J].Microelectronics & Computer,2020,37(11):1-5.
猜你喜欢
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
