
智能视域下非物质文化遗产视频资源的传播策略
2021-07-22 02:10:44庄文杰童名文
华中师范大学学报(人文社会科学版) 2021年4期
庄文杰 童名文
(华中师范大学 人工智能教育学部, 湖北 武汉 430079)
引言
非物质文化遗产(以下简称“非遗”)是人民群众在劳动中形成的集体智慧结晶,彰显着鲜明的民族特色和历史记忆,是珍贵和不可再生的精神文化宝藏。党和国家非常注重对传统文化的保护、传承与可持续发展,多次提出“文化是一个国家、一个民族的灵魂”①,“实施中华优秀传统文化传承发展工程,是建设社会主义文化强国的重大战略任务”②等重要论断。因此,发挥信息技术优势、提升文化与科技深度融合能力,符合我国文化大繁荣和提升文化软实力的主旋律,是对文化振兴与文化强国号召的响应,更是文化、科技工作者的历史责任与时代使命。
视频作为一种优秀的媒介载体,可利用其特有的视听叙事和艺术渲染手段,来系统、直观、多元地呈现文化元素和表达文化内涵,是非遗数字资源的重要组成部分。历经长期积淀和努力探索,对非遗视频的管理与利用已上升到新的高度,涌现出了大批脍炙人口、制作精良的新作品,凝结了较多资源组织、传播推广的新模式,并呈现出一派百家争鸣、百花齐放的新态势。但是,相较智能时代的要求,目前非遗视频资源的传播进程仍处于粗放、单向、静态的传统范式中,还不足以在反映视频规律的前提下智能匹配受众个性需求,也不能根据受众认知变化实时地做出策略调整。为解决上述问题,需要以创新的视野重新审视非遗视频资源的传播要素,理清其内部的作用机制,并展开应对策略的研究与实践。因此,本文聚焦非遗视频资源,通过资源、受众、策略三方关系的逻辑梳理来创设智能传播情境,同时结合对非遗视频结构化组织、目标受众个性特征解析、智能传播引擎实施路径的深入探讨,分别去解决内容智能生成、过程智能诊断、策略智能修正的问题,以期能为非遗视频智能传播的实现提供有价值的参考思路。
一、相关研究
智能视域下,非遗视频资源的传播是一项复杂的系统工程,现以传播中关键环节为线索,分别从资源组织、受众画像、智能策略这三个方面来展开相关研究的述评。
(一)资源组织
结构良好的组织状态有利于资源的存储、管理和调取,是智能传播的前提。较多研究者针对不同领域,从标准规范、方法过程、应用实践等层面做了大量的理论探讨和经验总结。B.Murtha从元数据架构出发,利用受控词表和分类体系,丰富了艺术与建筑领域的描述模式③。Noriko Kando等通过对文化遗产中异构资源的多维元数据整合,实现了资源的无缝检索与融合④。印度学者Hiranmay Ghosh等利用MOWL本体语言,构建出多媒体资源与领域概念间的感知模型,从而实现了古典舞蹈知识与视频之间的关联⑤。翟珊珊以“楚剧”为例,在资源本体基础上,利用元数据关联和语义化标注的方法,实现了楚剧多媒体资源的有效聚合⑥。董坤等根据非遗知识属性提出7元组的本体结构模型,并基于D2RQ平台,完成了RDF格式转化与关联数据发布⑦。在实践中,更多的研究者立足于特定项目,通过综合方法的选用来揭示多维度、多层级的资源本质。徐雷等对敦煌壁画中静态图像元素采用复合语义标注,从叙事维度出发完成了基于情节、实体和活动信息的组织与表达⑧。侯西龙等使用SURF算法和窗口阀值的镜头分割法,将“七夕节”视频分割成不同颗粒度的逻辑单元,并通过单元的语义标注实现了概念与视频间的语义关联⑨。
非遗视频,不仅在格式、形态、内容、对象、时空上具有多维的描述角度,还拥有文化空间、人物关系、影音叙事、艺术手法等独特的语境关系。现有研究虽可提供一定的方法指导,但还不能全面匹配非遗视频的逻辑结构并揭示内在关系。所以,有必要深入思考非遗视频的媒介属性和知识表征过程,进一步理顺其知识空间和本体架构思路。
(二)受众画像
受众是传播的主体,对其准确的解读决定了交互走向和体感效果,是智能传播实现的必要条件。不少研究表明,捕捉受众需求、描述个性特征可实现资源与对象的精确匹配,提升服务的智慧化水平。陈丹等通过读者的个性特征定位,为数字馆藏资源的智慧服务提供了思路⑩。Rossi等通过分析登机用户的个性轨迹,实现了智能化的资讯服务和机场管理。受众行为是内在属性的外在显化,Chikhaoui利用概率后缀树和标准化互信息的综合方法来抽取受众特征行为,并通过因果推理完成活动的预测。徐海玲等通过概念格方法,对读者群体的特征行为进行关联数据挖掘,以此来预测潜在阅读兴趣。在受众画像中,也有不少研究专注于社会属性和个性属性的细致阐述,比如,邱云飞等从自然属性、需求偏好和特征行为几方面来构建社交媒体的用户标签;肖君等从基本特征、学习行为、学习路径等方面来进行在线学习者画像分析;自适应学习平台Knewton,从用户偏好、认知风格、知识结构和能力水平等角度来动态评估学习者智能的在线学习过程。
对非遗视频受众而言,因项目在内容上的复杂性,其在年龄分布、兴趣爱好、目标需求、认知基础上存在较大差异。现有研究在解决群体认知差异大、范围跨度广的问题的深度略显不足,还需在此基础上进一步凝练受众共性和增强包络性,并通过受众行为的定量分析与深度挖掘以构建动态修正的合理机制。
(三)智能策略
随着时代进步与技术提升,现代传播更为注重先进理念的引领和科技元素的融入。在文化传播领域,代表性的观点有:智能媒体可以崭新的形态实现非遗内容的裂变式传播;依托5G和多种数字技术,可加快非遗知识转型并提供智能、即时的内容与产品;VR和AI技术,可帮助构建文化体感情境,加深文化认知和促进文化服务;短视频,可在“互联网+”时代实现非遗文化的大众普及并产生传播的集聚效应。在知识传播领域,美国的ISIS-TUTOR、Adaptive VIBE、Knewton,可实现特定领域知识内容的智能推送;荷兰爱因霍芬科技大学的AHA可实现学科内容的智适应呈现与导航;雅典大学的INSPIRE可实现个性化学习内容的智能生成。在智能算法优化领域,徐天伟等从基于项目、用户和属性值矩阵的协同过滤,盈艳等从预测填充矩阵的聚类算法,马相春从知识路径和资源推送的智适应系统架构等角度都给出了一定的解决方案。
智能传播是未来的发展趋势和前沿阵地,有必要从智能化视野上对非遗视频的传播模式和方法展开探讨:通过对资源智能布局、受众智能分析的深入剖析,实现领域视频资源的精准投放;通过对智能诊断与智能决策原理的系统研究,创设丰富的智能交互情境。只有解放思想,吸收、借鉴和融合相关领域中的新理念、新方法、新技术,并将理论与实践相结合,才能创新文化传播业态,顺应时代发展的需要。
二、非遗视频资源智能传播模型
为达到对非遗视频资源的智能传播目标,在系统架构中不仅需要思考如何突出特定文化空间内所蕴含的丰富语境关系,并按照特征内容做好对视频信息载量、数据标识、关联方式、链接强度的规划,而且需要考虑如何提炼传播对象的共性,采用动态视角定量分析受众个性特征,更为关键的是如何体现智能性,即通过创设智能传播情境去挖掘受众交互行为的数据、去接受众个性需求定向匹配视频资源并实时做出策略上的智能调整。基于以上观点,本文从“非遗视频资源组织”“受众个性特征解析”“智能传播处理引擎”这三个方面设计了非遗视频资源的智能传播模型,具体框架如图1所示。

图1 非遗视频资源智能传播模型示意图
非遗视频,是采用动态影音去直观呈现文化内容、表达文化知识、反映文化情境的专属数字资源。在实际的管理与利用中,常因制作标准不同,其在格式规范、清晰程度、光影质感、语音规范、画面节奏上会有较大差异;因叙事维度不同,在知识阐述、学术深度、艺术表现上亦表现出不同的可利用价值。所以,为深度刻画非遗文化内涵,克服碎片化、无序化的组织障碍,从而实现立体、全面、系统的组织过程,在资源选取中,可遵循“保障非遗知识叙事完整、优先选择历史稀缺资源、注重质量与风格的协调统一”,即“取其意、用其珍、统于形”的原则,来对视频资源进行筛选与过滤。在粒度标定中,应以表述内容的知识点为界限,通过剪辑、加工与重塑的处理,采用非遗视频元(最小视频单位)的形式来输出可播放的单个视频实体。在语境表达中,应在文化学者的指导下,通过多维的数据属性描述、语义关系标注、难度系数标记等途径来实现资源的链接与聚合,进而构建出高效、智能的结构化非遗视频资源网络。另外,为监测受众认知和掌握情况,并为智能决策提供依据,每个非遗知识单元都将设置一组认知测试题,该集合也对应存储于资源库中。
受众是智能传播的中介与桥梁,决定了资源调取和策略实施的具体走向。考虑到系统冷启动问题,将采用“老受众”与“新受众”两种方式:“老受众”通过登录,可直接载入特征数据;“新受众”将通过基本信息注册、特征初始化后在特征库中存入其个性数据。基本信息,将分别从姓名、性别、年龄、身份、职业、兴趣、爱好等维度收集信息,用于群体分类和相似度比较;特征初始化,将利用国际通用的成熟量表和认知测试题,分别从目标需求、访问风格和认知状态上量化受众的个性数据。同时,在资源交互过程中,将采集受众的特征行为和项目评价数据,并通过特定算法去智能、动态地修正与更新初始的特征数据。
处理引擎是智能传播的核心驱动模块,担负着资源提取、智能布局、情境交互、认知评测、智能决策、信息反馈等诸多功能。智能传播引擎的运转流程可解读为以下几个环节:第一,读取受众个性特征数据,根据受众的目标与需求,调用资源库中对应的非遗视频单元,并按照受众的访问风格属性定位进行合理的、匹配的资源布局;第二,创设丰富的受众与资源交互情境,呈现访问视频的先后序列、已通过和未通过的知识点表单,设置符合受众习惯的项目评价按钮,提供多元化的导航方式(比如:知识点图谱、项目地域分布图)以供顺序式或跨越式点播;第三,待当前非遗内容单元访问结束后,调用对应的认知测试题对受众的掌握状态进行智能评估与决策;第四,将决策信息反馈给资源智能布局模块,对于通过的受众可直接进入下一认知单元,对于不通过的受众则需要进行认知内容的补充或难度系数的调整。
以上模型架构,为智能传播的实现提供了一定的理论指导和方法思路,下面将对其中的具体细节、实施路径、技术路线进一步展开策略的详细探讨与研究。
三、非遗视频组织策略
面对项目众多、内容复杂且形式多样、表现灵活的非遗视频资源,若要实现对其有效组织并能可视化地反映出内部的组织结构,还需理清非遗视频在知识承载、叙事方式、内容阐述、媒体制作等方面的内在规律,并在此基础上建构出合理解决组织基因提炼、逻辑层次表述、关联关系表达的系统方案。
(一)非遗视频元提取
非遗视频是非遗知识的载体。按“世界经济合作与发展组织”(OECD)对知识体系的划分,非遗知识可对应地分解为事实型知识(know-what)、原理型知识(know-why)、技能型知识(know-how)和人员型知识(know-who)。非遗的事实型知识主要包括基本信息和历史资讯,即项目概述、传承现状、演变历程、历史故事、存世资料等;原理型知识大多为反映文化空间的事件知识与时空知识,即事件顺序、仪式流程、服装道具、时空节点等;技能型知识主要是“做”与“唱”中步骤流程与器物使用的程序型知识,即工艺流程、唱法腔段、制作技能、演述技巧等;人员型知识是对代表人物和典型人物的了解,即各级代表性传承人、领域专家、重点承继人和参与人等信息。理解非遗的知识类别,做好知识跨度范围的界定,将有助于非遗视频最小内容表征单位的提炼与析出。
视频作为视听融合的大众媒介,因现场影像与声音的写实束缚,在创作中只能采用有限的手法来进行素材采集和内容表征。但是,通过后期的艺术加工和综合的叙事组合,也可完成无限的表意功能。经过对制作过程的系统分析,可将非遗视频归纳出“事件纪实”“人物访谈”“情境再现”“画外解说”“细节展演”这五种视听形态。事件纪实,是以主观或客观视角,在现场通过摄像机去记录和还原事件发生过程和发展全貌;人物访谈,是通过话题引导和自由讲述,呈现个人对历史、过程、事件及物品的见解与观念;情境再现,是通过场景复原和真人演绎,重现虚幻人物和历史故事;画外解说,是以语言为线索,通过对应的视觉画面来进行原理阐述和观点表达;细节展演,利用特写镜头和“点”的刻画,去展现和演示技术与技巧的细微内容。不同形态的视频,具备各自的信息表达优势,通过复合与叠加即可全方位、多角度、立体化地系统表征非遗知识内容。具体映射关系可参见图2所示。
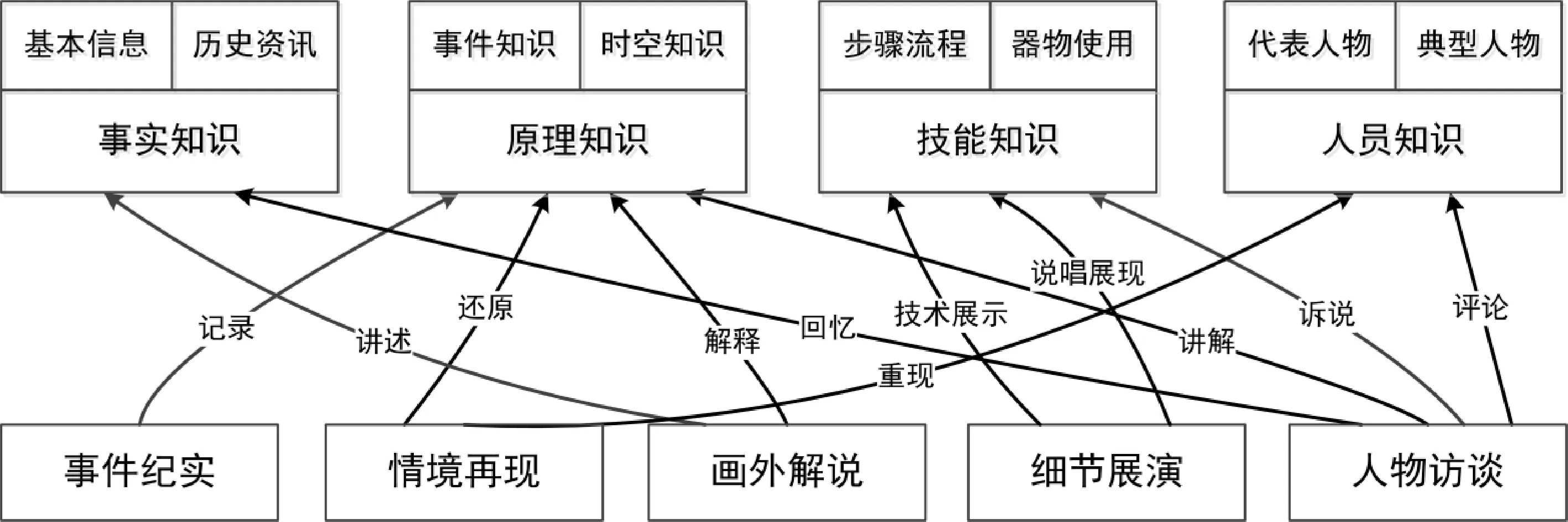
图2 不同视频形态与非遗知识表征的关系映射示意图
在非遗视频元的提取中,需要非遗领域和视频技术人员的通力配合与相互协作,采用层层递进、逐步细化的方法与原则。素材的筛选,应按照视频形态完成以项目为单位的视频归类与集中,并在资源储备较为充足的前提下优先选用质量较高的影音数据。在知识覆盖范围的界定中,应以领域专家为主导,通过非遗知识最小表征单位的理解,实施对视频中长镜头的切分和单个镜头的重组。在画面与声音的优化组合中,应做到以内容叙事为导向,通过角度与景别的切换,来丰富画面节奏和提升视觉张力,同时,应尽量保留现场同期声,并添加恰当的音响效果以烘托整体氛围。
(二)视频资源本体模型
非遗视频经过视频元提取,可得到诸多完整的视频实体。为进一步清晰表达视频间的逻辑结构和相互关系,还需要搭建合理的资源本体。
本体模型,一般采用最核心、最简洁以及包络性最强的术语或关键词来描述对象的结构层次,是对事物逻辑和组织关系的顶层设计,有助于知识的抽象归纳和具象联结。目前,国内绝大多数非遗资源本体模型,均借鉴了文化类资源概念参考模型(CIDOC CRM)的核心思想,采用以内容叙事为线索、以点串面的构建思路。该思路主要针对非遗泛在资源,虽可一定程度解决内容共联、项目共通等问题,但还无法刻画视频的内在规律及突出其在媒介表达、叙事组织、艺术创作中的本质特征。所以,在非遗视频的本体模型构建中,一定要遵循视频的创作思维,在符合视频内容语境的基础上,进一步突出概念之间的逻辑层次。为了快速识别与定位视频实体,本文以知识表征中视频形态为切入点,从“事件纪实”“细节展演”“画外解说”“情境再现”“人物评述”这五个方面来构建非遗视频资源本体中的一级层次。以视频的信息表述形态来完成本体中基本概念层次搭建,一方面无须对表达内容进行完整解读,即可快速识别与定位非遗视频元属类,这有利于提升视频实体的组织效率;另一方面,以形态来进行非遗视频建构,能更贴近受众的访问习惯和风格判断,将有利于后期智能传播过程的实践。
非遗具有众多的门类,比如民俗、舞蹈、美术、音乐、文学等,同类别下不同项目亦表现出不同的专属特征。结合对非遗视频阐述内容的共性提炼,本体中的二级概念层次可做如下标定:事件纪实,按照事件类别细分出竞技事件、仪式事件、内容事件与活动事件;细节展演,根据展示对象的不同,细分出步骤演示和说唱演述;画外解说,依据概况角度和解说对象的不同,细分出基本信息、时空特性、资料与物品、发展脉络;情境再现,从再现对象和虚构情境的角度,可细分出历史故事、历史人物、环境与物品;人物评述,可根据访谈对象的差异,拓展为代表性传承人、典型人物、专家与学者、参与人。具体本体模型框架可参见图3所示。

图3 非遗视频资源本体模型构建示意图
上述的两级概念层次体现了非遗项目的共通性,能较为全面地满足不同项目的本体架构。但在三级及以下概念层级的拓展中,还需紧密结合具体非遗项目中多元的文化内容、多样的文化语境以及复杂的人员关系等,做到具体情境具体分析。
(三)资源关联与可视化
为构建有序、聚合、结构与可视化的非遗视频资源网络,对单个非遗视频元实体,可通过属性描述建立外部的逻辑关联,通过视频间丰富的语境联系建立内部的语义关联。
元数据,作为一种对实体属性描述的标签数据,可为资源的识别、管理、组织及追踪提供导向。为详细说明非遗视频元在基本信息、非遗属性、视频属性、关联属性这四个维度的特征,本文在参考国际通用的DC、CDWA、VRC等元数据标准的基础上,经过重点筛选与利弊权衡,确立17个核心元素来完成非遗视频元实体的元数据描述。其中,选取{名称、标识符}来标注基本信息,以实现检索、查询和调用的功能;选取{民族、项目类型、内容概述、传承人、领域专家、参与人}来说明视频实体在项目性质、内容以及人员方面的信息;选取{发布机构、制作人、拍摄时间、拍摄地点、视频形态}来突出视频在出品、制作及类别中的特征;选取{关键词、属类资源、层级资源、平行资源}来建构视频间相互关联的渠道。在元数据著录后,经过RDF语言的关系标注,并结合相似特征属性的数据比较,即可实现相同维度的非遗视频元集聚。
在本体结构框架的指引下,因叙事视角的复杂性、呈现形态的多变性、艺术表现的多样性,非遗视频元各实例间会具有丰富的语义关系。通过对视频间概念与概念、概念与实例、实例与实例间潜存关系的共性提炼,可以发现:在视频创作中,围绕同一个主题,不同形态视频可采用不同艺术加工角度来表达平行的内容;在内容叙事中,可通过不同视角来展现事物的整体与局部,比如事件纪实强调事件发展过程的面,细节展演注重具体环节中的点;在表意功能中,视频还具备解释、说明、重现等作用,比如解说类视频可用语言来诠释事件发生的历史背景,情境再现可重现历史人物与故事;在人物行为中,可通过人员主持、参与等主动行为以及对客体的述说、回忆、评论等言语行为产生较为复杂的关系。因此,可将非遗视频元间的语义关系总结为同一关系、点面关系、释义关系和行为关系这四大类别,详细说明参见表1。

表1 非遗视频元间语义类别及关系说明(部分)
在明确了元数据和语义关系的基础上,本文使用LodLive工具来生成非遗视频的可视化关联图谱。在图谱中,每个节点均代表着单个视频实例,链接箭头则描述了两者间的关系,以任意节点为起点,都可搜寻到与之相关的视频实体,并以递进的方式说明两者之间的关联属性。图4展示出了“黑暗传”视频间部分的关联图谱,其左侧是以元数据为导向的外部关联数据集,可从不同的相似程度上建立自建数据集与众多开源数据集之间的联接;右侧为领域内部非遗视频元的关联数据集,表示出了概念逻辑和丰富的语义关系。非遗视频的可视化关联图谱,能帮助发现更多有价值的隐含信息,也更有利于实现对非遗视频元实体的查找、调取和管理。

图4 民间文学“黑暗传”的视频关联图谱
四、受众特征解析策略
受众是连接视频资源和传播引擎的纽带与桥梁,对其个性化特征的准确解读,将影响和决定内容投放及策略实施。面对纷繁各异的目标对象,在个性特征刻画中,不仅要明确与分析出可描述的共性维度,搭建全面与系统的特征解析模式,还需确立根据受众状态进行定量分析与动态描述的方案。
(一)目标受众分析
开展非遗视频资源的智能传播研究,主要是为了让更多的人了解、传承和弘扬我国优秀的传统文化,通过系统的文化探索、文化认知、文化实践,树立起文化认同与文化归属的正确价值观。随着非遗文化的日益普及,更多的人渴望通过视频来提升自身的文化素养。根据预期目标不同,非遗视频的传播与推广对象可大致包含非遗项目承继人、“非遗进校园”所覆盖的中小学生、相关文化专业的在校大学生、文化专题研究人员以及对某类项目具有浓厚兴趣的普通民众这五类群体。上述目标群体,在年龄分布、知识基础、工作性质上均有不同,在预期目标、文化需求、认知习惯等层面也表现出较大差异。但是,经过对传播中受众外显共性的分析,可以归纳出:在起始阶段,多数受众会利用知识地图和搜索引擎来定位资源和表达需求,会设定目标,并通过对资源价值和自身绩效的判断来评价传播效果;在过程阶段,会具备稳定的视频类型访问偏好,并按照一定顺序来接受和处理信息,会通过同化与顺应方式来完成新旧知识融合和自身知识体系改造等。因此,本文将从需求与目标、访问风格、认知状态这三个维度来完成目标受众的共性分析。
受众需求,可通过内容检索与热区点击来明确;受众目标,在参考布鲁姆在认知目标领域分类标准的基础上,依据注册角色的不同,划分出“知道与领会”“应用”“分析”“综合”“评价”这5个等级。当然,受众也可根据对内容了解和认知情况的变化,自主选择或改变相应的目标层级。访问风格是对受众喜好方式的理性判断,是资源智能布局的重要参数。为了便于定量计算,借鉴相关研究成果,可分别从信息加工、信息感知、信息输入和内容理解这四个角度来剖析。通过对“学”与“做”先后顺序的解读,来定位活跃型或沉思型;通过对“具体”与“抽象”知识特征的加工分析,来定位感觉型或直觉型;通过对“视觉”或“听觉”信息偏爱程度的测量,来定位画面型或言语型;通过对导航路径和习惯的记录,来定位序列型与综合型。在认知状态的分析中,应该立足于单个知识点,通过知识标号、抽象系数、难度等级的导入来标注内容细节,通过浏览记录与测试结果来备案访问过程,通过对知识掌握程度和能力水平的变化来呈现认知结果。
综合上述分析,图5给出了详细的受众特征解析模式。在该模式中,除了明确需求与目标、访问风格、认知状态这三个特征维度,并根据内在结构对其核心要素进行拓展以外,还从数据传输的角度给出了合理架构,也就是:利用基本信息数据库存储需求与目标数据,构建个性风格数据库存储确定的访问风格属性,同时根据受众交互行为,采用算法来修正其中的访问风格数据;调用资源单元信息数据完成知识点信息的标注,同时构建认知状态数据库完成对访问历史和认知结果的信息储存,以供智能传播引擎进行数据分析。

图5 目标受众解析模式的架构示意图
(二)访问风格判断策略
访问风格是对受众信息处理偏好方式的定性分析,为快速、精确地定位出风格维度属性,同时兼顾新、老受众的不同处理方式,可采用初始描述与动态修正相结合的递进过程。
1.初始化描述
为解决新受众在初次进入智能传播系统时所遇到的冷启动问题,本文选用在国际上通用且内容全面、问题精炼、耗时较短的Felder-Silverman量表来完成初始访问风格维度定位。
Felder-Silverman量表,共有44道客观选择题,分别从信息加工、信息感知、信息输入、内容理解这4个方向来探知受众的访问风格特征。根据受众的问卷作答情况,量表将结果属于单个维度左侧的标记为a,右侧的标记为b,通过数值累加和“(较大数-较小数)+较大数字母”的规则来推断访问风格属性;同时,为处理因过于接近而判断模糊的问题,将处于{3a、2a、a、b、2b、3b}区间的标记为“平衡型”。因此,通过一系列的作答数据统计,可描绘出该受众初始的访问风格属性值,比如:某受众,其信息加工为3b、信息感知为5a、信息输入为7a、内容理解为5b,初始化结果即为{平衡型、感悟型、画面型、综合型}。
2.动态修正过程
由于Felder-Silverman风格量表在评测中维度过于宏观,其精度会存在一定缺陷,并且在问卷答题过程中受众会表现出一定程度的主观随意性,所以上述初始化结果并不能准确反映受众真实的访问风格属性。行为是受众偏好方式的外在显化,分析、提炼、积累、挖掘受众与资源交互中的有效特征行为,将有利于推断出真实的受众访问风格参量,从而完成动态的修正过程。
受众在对非遗视频的选择过程中,经常会依据自身偏好做出视频类型的优先序列组合,即表明非遗视频形态与访问风格维度之间存在一定的前因后果规律。为了清晰地呈现该因果概率的关系,本文采用贝叶斯网络来实施以上不确定性事件的推理过程。依据访问风格维度的划分,同时结合非遗视频在表述形态、内容组织以及信息导向中的贡献大小,可确立如图6所示的访问风格贝叶斯网络有向无环图。
受众行为具有多维性,在遵循“重点突出、力求简洁”的原则下,经过比较与权衡可选取“点击次数”和“访问时长”作为其核心基元。点击次数,凸显了受众兴趣的外在表现,包含对视频、导航、按钮、热区的操作计数;访问时长,强调了兴趣的持续跨度,包含对特定视频浏览、论坛阅读和导航停留的时间长度。为简化贝叶斯网络的推理过程及呈现逻辑细节,本文以信息输入维度为例,分别从“纪实”与“访谈”视频出发,同时结合受众特征行为,可得到如图7所示反映信息输入维度中各种概率关系的贝叶斯有向无环图。
概率关系是下级指标对上级维度的影响权重,经过相关文献的梳理与归纳,可分别标注出如表2、表3、表4中所示的诸条件概率参考值。

表3 “访谈”类视频条件概率表

表4 信息输入条件概率表
上述各表中条件概率参数的取值,表示了在某状态的前提下,另一相关事件发生的可能性。比如:表2中,P2=1和P1=1,表示“纪实”类视频访问的时间长且频率高,意味着该受众偏爱“纪实”类资源,所以P5=1的赋值较高;P2=1和P1=0,表示该类视频访问时间长,但点击次数少,可能是专注于某一个视频,或者处于暂停状态,所以P5取中间值。同理,可依次得到其他情境中的条件概率参考值。
为完成动态的定量推理过程,还需将受众特征行为数据转化成与之相匹配的先验概率值。比如,初始化为“平衡型”的某受众,经过一段时间,其对纪实类视频共浏览6次、访谈类为1次、纪实类时长为5小时、访谈类为0.2小时。利用加权平均计算,可确定该受众的先验概率取值,分别为:P(P1=1)=0.86、P(P2=1)=0.96、P(P3=1)=0.14、P(P4=1)=0.04;P(P1=0)=0.14、P(P2=0)=0.04、P(P3=0)=0.86、P(P4=0)=0.96。
将以上数据分别代入贝叶斯全概率公式,即:
可得:P(P7=0)=0.904;P(P7=1)=0.096。
在终端的维度偏向判定中,可设置合理的比例来比较两参数之间的差距。对于以上结果,因P(P7=0)> [P(P7=1)*1.5],可推断出该受众的信息输入维度偏向左侧,即属于“画面型”。同理,亦可修正其他维度中访问风格的初始化参数。
(三)认知状态解析策略
受众对非遗内容的认知过程以单个知识点为线索,通过“点”的突破以达到“面”的积累。为此,在知识点认知状态的刻画中,应将重点放在内容、目标和掌握情况这三个方面。其中内容阐述通过知识点本身和相互关联属性来说明,认知目标通过认知等级和难度层次来为智能判断提供依据,掌握情况更多反映出浏览过程、测试状态、掌握程度和能力水平的变化。另外,为方便计算机建模和信息处理,还应当明确各参数的字母标识、数据类型、值域范围和初始赋值,具体如表5所示。

表5 以知识点为单位的认知状态初始化参数说明表
随着对内容的深入了解,受众认知状态会发生变化,特别体现在能力水平上。为及时监测和评估受众在该方面的变化,一般采用知识点后测的方式,并通过“累计积分”的方法来分析数据。后测试题项,由领域专家根据项目反应模型并结合具体内容来给出,以3-5项为宜,并采用难度平均分配的标准。表6列举出了认知目标为“分析”的某大学生在单个知识后测中的得分和实际累计积分情况。

表6 某受众的测试状态和实际累计积分统计表
为准确衡量该受众在能力水平上是否达到对应的认知等级,可比较“实际累计积分值/积分参考值”与“平均难度系数/难度阈值跨度”的数值比例大小。比如表7中,“分析”维度的积分比值为0.667,平均难度系数与阈值最大值的比值为0.889,因0.667>0.889*2/3,所以该受众达到“分析”的能力要求;而“综合”维度积分比值为0.333,平均难度系数与阈值最大值的比值为0.896,因0.333<0.896*2/3,所以该受众没有达到“综合”的能力要求。
所以,通过以上数据计量的方法,可以准确地评估受众在认知状态中的动态变化,并为智能诊断和策略调整提供数理支撑。
五、智能传播引擎实施策略
经过资源结构化组织与受众个性特征解析过程后,智能传播的实现打下了夯实的基础,下一步将要重点研究智能引擎模型设计、内容智能生成以及资源智能调整等问题的解决思路。
(一)智能传播引擎模型设计
智能传播引擎,是实现对非遗视频资源智能传播功能的关键驱动模块。在整体模型框架设计中,应当以内容需求和目标定位为前提,在充分理解核心数据采集与挖掘、资源有效调用与布局、策略智能应用与调整等原理的基础上,通过对受资交互、认知诊断、信息反馈、资源修正等过程与细节的探讨,来揭示智能传播的内在规律。因此,本文结合对传播中诸要素及其相互作用机理的综合分析,设计了非遗视频资源智能传播引擎的整体模型,具体架构如图8所示。

图8 智能传播引擎的模型架构示意图
以上模型,分别从数据挖掘、数据处理、数据反馈这三个角度,详细说明了智能传播中关于需求定位与内容生成、资源匹配与受众交互、认知诊断与资源调整的整个过程。
首先,受众利用知识图谱中热区的点击或搜索单元中关键词的输入来进行需求表达,引擎将根据非遗视频领域本体的资源数据,完成相关单元的检索与调用。在内容生成中,为突出受众间兴趣的相似性和内容间知识的关联性,引擎将结合受众对视频元的评分数据以及相关的元数据和语义关联数据,采用“基于受众”和“基于内容”的混合式协同过滤算法,分别从受众相似性和内容关联性两方面生成候选视频单元集合,并通过预测评分计算产生最接近的TOP-N资源推荐列表。
其次,混合式协同过滤算法生成的资源表单与受众个性并不完全匹配,还需结合访问风格维度,对推荐表单进行重组与排列。同时,为提升资源生成精度,在受众与资源的交互情境中,可创设“点赞”、“分享朋友圈”、“转发微信”、“发表评论”环节以捕获显式评分数据,通过对浏览次数、访问时长等特征行为的挖掘以生成隐式评分数据。
再次,在一个单元访问结束后,引擎将调用相应的后测试题集对受众认知情况进行评测,其结果将反馈并记录于认知掌握状态数据库中。经过与预设目标的比对,通过的受众可直接进入下一非遗视频单元;不通过的受众,则需进行一定的认知补偿,即使用“难度过滤”以降低相同内容的难度系数,直至通过评测为止。
智能传播引擎是一个有机的整体,为保障其高效运转,重点在于如何提升推荐算法精度以达到内容智能生成效果,难点在于如何适应受众特性以达到资源智能调整目标。
(二)内容智能生成策略
在相关联的内容提取中,仅依靠受众对资源的喜好评价会导致数据稀疏性问题,仅根据有效行为的数据挖掘也不足以描绘出受众兴趣以及各视频间的逻辑关系。所以,为进一步提高内容生成的精度,除利用好显式、隐式评分数据外,还应当多元化地审视受众对内容的兴趣表达,并采用交叉、复合的方法做好特征数据的量化与混合。经过综合比较,本文选用对视频元评分、浏览次数、访问时间、受众兴趣与知识特征相似性这四个特征维度,并通过数据矩阵的制定来完成混合式推荐算法的数据输入,具体过程如下:
1.“受众—视频元”评分矩阵
受众对视频元的评分行为反映了其对视频内容的喜好程度,可通过统计交互过程中点击“点赞”、“转发”、“分享”等按钮的次数来得到。假设受众集合为U={u1,u2,u3,…,um},视频元集合为I={i1,i2,i3,…,in},以受众集合为纵轴、视频元集合为横轴,具有点击行为标注为1,不具行为标注为0,这样可得到一个m*n的二维矩阵,记为Rm×n。
2.“受众—视频类别”浏览次数比例矩阵
浏览次数,是通过单类视频的访问频率来反映受众兴趣。对于纪实、情境、访谈、解说、细节这5种非遗视频,假设a为其中一类,用Iua表示单个受众对a类视频的浏览次数,用Iu表示该受众对所有视频的浏览次数。为表示某类视频的浏览次数比例,采取Iua除以Iu的规则,即可得到横坐标为受众、纵坐标为视频类别的i*5矩阵,记为Pua。
3.“受众—视频类别”访问时间比例矩阵
浏览次数比例矩阵仅表达了历史中的受众访问兴趣状态,但引入访问时间参数,可更真实地动态反映受众当前的兴趣点。在矩阵生成中,采用起始访问时间与当前时间的差值来表示访问时间跨度,对a类视频,用Tua表示某受众访问该类视频的时间跨度总和,用Tu表示该受众所有视频类别的时间跨度。为呈现某类视频的访问时间比例,将Tua除以Tu,即可得到一个j*5的j名受众在不同类型视频的访问时间比例矩阵,记为Sua。
4.知识特征与受众兴趣相似度矩阵
知识特征可说明视频元在非遗内容中的属性,受众兴趣可通过评分比重来反映对某内容视频的偏好程度,将两者进行相似程度比较,可以更好地从内容关联角度提炼受众期望的视频元序列。
对知识特征的描述可按照逐级细化方式,分别从非遗属类、项目名称、视频形态、内容层次来展开,即包括{[民俗、民间文学、传统音乐、传统舞蹈、传统戏剧、曲艺、杂技与竞技、传统美术、传统技艺、传统医药]、[项目名称]、[事件纪实、细节展演、画外解说、情境再现、人物评述]、[内容事件、活动事件、步骤演示、典型人物……]}这33个关键点。通过空间向量表示的方法,可采用分段函数来标记知识特征中的各维度权重,如果具备该属性就在对应位置标注“1”,不具备就标注为“0”。这样,可得到一个j*33的知识特征二维矩阵,记为Vj={(t1,wj1),(t2,wj2),(t3,wj3),…,(tn,wjn)}。同样的道理,运用受众对知识特征单项的评分之和除以全部项目评分总和的方法,可得一个i*33的受众兴趣二维矩阵,记为Ui={(t1,wi1),(t2,wi2),(t3,wi3),…,(tm,wim)}。因向量Ui与Vj具有相同维数,利用余弦相似度计算,就可得到一个表达知识特征受众兴趣的相似度矩阵,记为Bm×n。
以上述构建的四个矩阵为基础,就可进行相关数据的交叉与混合。在“基于受众”的列表生成中,为解决浏览次数比例和访问时间比例矩阵不同维的问题,可引入兴趣函数intr(u,a),通过设置比例权重系数θ(为平衡起见,一般取值为0.5),来实现次数和时间这两个矩阵的线性相加;可引入兴趣相似性函数intr_cmp(u,v),来完成受众对单个视频元兴趣的相似度比较,并得到与评分矩阵同维的m*n矩阵;使用Pearson相似度系数,通过同维的兴趣相似性函数与“受众-视频元”评分矩阵相乘,并复用“基于受众”的协同过滤算法,即可得到受众可能喜欢的视频元表单。在“基于内容”的列表生成中,采用分段函数将数据稀疏的评分矩阵与“受众兴趣-知识特征”相似度矩阵进行叠加,可得到新的“受众—视频元”评分矩阵Cm×n,然后进行内容关联的视频元间相似度比较,并复用“基于内容”的协同过滤算法,即可得到内容关联的视频元表单。以上两条路径的数据混合与计算过程可参见图9所示。

图9 内容智能生成的数据混合与计算过程
(三)资源智能调整策略
为了更好地使受众获得丰富的智能交互体验,还需对生成的资源进行一系列整合,主要是调整视频元的呈现顺序以符合当前受众的访问习惯、调整知识的难度系数以匹配当前受众的认知状态。
混合式协同过滤在视频资源的生成中存在一定的局限,其最小推荐单位只能聚焦到单个非遗知识点上。但对于单个知识点来说,其下还可按叙事角度的变化细分出多个不同表述形态的非遗视频元。比如:民间文学项目《黑暗传》中的“盘古开天”知识点,下面就包含了“丧事现场纪实”、“完整唱腔演述”、“故事真人情境演绎”、“唱本传承历史解说”、“代表性传承人访谈”、“领域专家点评”等非遗视频元。这就需要采用恰当策略,来实施对诸多非遗视频元呈现顺序的调整。在前文受众个性的访问风格定位基础上,为便于计算机对标签数据的载入、分析与处理,可将风格维度左侧的属性标记为“0”、右侧标记为“1”,即用不同的二进制编码代表不同的受众访问风格。例如,访问风格为{活跃型、直觉型、画面型}的受众,可简化为{010}。按访问风格的定义,每种风格属性都对应着不同的视频偏好,将固定的视频形态进行编码,即可产生与受众相匹配的视频呈现序列,具体操作可参见表7。因此,访问风格为{010}的受众,其视频偏好顺序为{451},在“盘古开天”单元呈现中可采用{唱腔演述、传承人访谈、专家点评、丧事现场、真人演绎、历史解说}的视频序列。

表7 访问风格维度与视频偏好关系映射表
另外,资源的调整还应体现在知识难度的智能上下浮动上。为了更符合受众直观感受,提升难度系数的智适应调整能力,可利用基于深度学习的循环神经网络。在资源的组织中,每一个非遗视频元都标注有对应的难度系数,多个富有难度梯度的知识点共同组成了一个非遗知识单元。为培育循环神经网络的难度系数智能调整能力,在训练样本的初始采集中,可由领域专家全程参与并指导,采用随机抽取的方式完成资源的初始布局。然后,根据受众的访问内容和认知状态,人工调整并指定与之相匹配的具有不同难度层次的非遗视频元,对已通过的知识点,下一单元可适当地提高平均难度,对未通过的知识点,则调用低于平均难度等级的视频资源。经过一定量的积累,即可得到较为全面的难度系数调整训练集。最后,导入训练集样本数据,通过设定神经网络的层数和形态,完成网络训练以达一定的智能调整精度。
对于学习后的循环神经网络,即可用于对样本集外的受众进行难度等级的智能匹配。当然,该受众的难度调整反馈数据,也可添加入先前的训练样本数据集中,继而不断地优化神经网络的难度调整精度。
结语
以智能化视野开展对非遗视频资源的传播研究,是一项较为前沿的课题。本文在系统梳理相关研究经验和成果的基础上,通过对传播核心要素中内部作用机制和外部影响原理的系统分析,分别从非遗视频资源组织、受众个性特征解析、智能传播处理引擎这三个方面构建出了非遗视频资源智能传播的整体模式。为了更为深入、有效、准确、智能地实施整个传播过程,在内容上以最小粒度的非遗视频元为组织单位,通过对非遗视频叙事逻辑和形态本质的剖析,从概念层次、元数据描述、语义标注层面探索了数据关联与可视表达的方法;在对象上明确目标主体类别,通过提炼共性特征维度并采用行为挖掘和定量分析的策略,形成了基于访问风格和认知状态初始设置与动态修正的具体思路;在引擎驱动上,结合数据的交换与反馈过程,分别从内容智能生成与资源智能调整两方面给出了具体的方案细则。
以上诸多工作,为非遗视频资源智能传播的实现提供了一定参考思路和借鉴经验,但在平台的开发、应用以及针对具体非遗案例所开展的智能传播效果评测上还略显不足。所以,下一步的研究重心将集中于非遗具体案例的应用实践,同时深入拓展对受众情境体验的量化评估。
注释
①习近平:《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》,北京:人民出版社,2017年,第51-52页。
②《中共中央办公厅 国务院办公厅印发〈关于实施中华优秀传统文化传承发展工程的意见〉》,2017年1月25日,http://www.xinhuanet.com/politics/2017-01/25/c_1120383155.htm,2020年11月18日。
③B. Murtha, “Practical Issues in Applying Metadata Schemas and Controlled Vocabularies to Cultural Heritage Information,”Cataloging&ClassificationQuarterly, vol.36, no.3-4, 2018,pp.47-55.
④Noriko Kando and Jun Adachi, “Cultural Heritage Online:Information Access across Heterogeneous Cultural Heritage in Japan,” http://www.kc.tsukuba.ac jpdlkc e-proceedings/papers/d1kc04pp 136.
⑤A. Mallik, S. Chaudhury and H. Ghosh, “Nrityakosha:Preserving the Intangible Heritage of Indian Classical Dance,”JournalonComputing&CulturalHeritage, vol.4, no.3, 2017, pp.1-25.
⑥参见翟姗姗:《基于关联数据的非物质文化遗产资源聚合研究》,北京:科学出版社,2015年。
⑦董坤、谢守美:《基于关联数据的MOOC资源语义化组织与聚合研究》,《情报杂志》2016年第6期。
⑧徐雷、王晓光:《叙事型图像语义标注模型研究》,《中国图书馆学报》2017年第5期。
⑨侯西龙、谈国新等:《非物质文化遗产视频语义标注方法研究》,《情报科学》2018年第11期。
⑩陈丹、柳益君、罗烨、钱秀芳、吴智勤:《基于用户画像的图书馆个性化智慧服务模型框架构建》,《图书馆工作与研究》2019年第6期。
猜你喜欢
吉林广播电视大学学报(2021年4期)2022-01-14 02:35:48
作文成功之路·小学版(2020年5期)2020-06-11 12:48:26
文苑(2018年23期)2018-12-14 01:06:06
小天使·一年级语数英综合(2018年11期)2018-11-23 09:47:26
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
传媒评论(2018年6期)2018-08-29 01:14:40
资源再生(2017年3期)2017-06-01 12:20:59
新闻传播(2016年11期)2016-07-10 12:04:01
