
基于Bi-LSTM和支持向量机的风机叶片短期覆冰状态预测模型
2021-07-21 14:07:04熊昌全何泽其张宇宁
四川电力技术 2021年3期
熊昌全,何泽其,张宇宁,黄 胜
(1.国家电投集团四川电力有限公司,四川 成都 610065;2.国家电投集团四川电力有限公司凉山分公司,四川 西昌 615000)
0 引 言
随着化石能源短缺以及环境污染等问题的出现,风力资源作为绿色可再生能源受到科学与工业界的高度重视[1]。为充分有效地利用风力资源,风电场一般建于高海拔山区或沿海区域,这些地区往往具有昼夜温差大、湿度大、风力强等特点。在低温季节,长期处于潮湿寒冷环境下的风电场面临严重的风机叶片覆冰问题。风机叶片覆冰将加剧叶片的疲劳载荷以及影响风机产能,严重时会导致设备故障和风机寿命缩短。极端情况下,过度积冰甚至可能发生风机塔筒坍塌[2-3],严重影响风电场安全经济运行。因此亟需开展对风机叶片覆冰状态预测研究,提前采取防范措施以预防可能发生的覆冰危害,确保风电场安全高效运行。
针对风机叶片覆冰状况研究,文献[4]利用天气数据进行预测研究,将预测结果输入基于物理机理的iceBlade模型中,实现对风机叶片的覆冰监测。文献[5]基于压电陶瓷应力波测量,提出了风机叶片覆冰主动监测方法,结果表明,压电陶瓷电压测量信号与覆冰厚度存在显著的相关性,方法偏向实验分析。以上覆冰检测研究以覆冰产生机理和过程数值作为重点研究对象,缺少对风机自身运行数据的考量。文献[6]基于数据分析的风机状态监测方法,提出一种基于数据采集与监控系统(supervisory control and data acquisition, SCADA)数据变量相关性的监测方法,实现在不同工况下对风机健康状况的定量评估。文献[7]基于SCADA数据,提出了一种主动诊断式的覆冰监测方法,分别从机组整体性能、叶桨吸能效率、机组塔架振动对风机覆冰开展精细化研究,并进行了相互验证,但忽略了指标整体关联性。文献[8]通过SCADA系统收集的基础数据作为模型输入,提出了一种基于长短期记忆网络的叶片覆冰故障检测模型,但LSTM模型存在精确性不足等问题。文献[9]提出了一种基于BP神经网络的风机叶片故障预测方法,先根据行业经验,从SCADA监测数据集选出与风力发电机叶片结冰关联度高的数据,通过多源融合的方法利用BP神经网络自聚类算法进行叶片结冰故障预测,但对数据选择和处理较为粗糙,导致预测精度欠缺,且BP自聚类算法存在分类数据需求大的问题。支持向量机(support vector machine,SVM)在学习样本数较少的情况下比人工智能方法有更强的适应性、更好的分类能力[10]。
综上所述,传统的覆冰状态监测方法不能精确判断风机叶片覆冰状态,且风机覆冰状态监测数据冗余,处理较为困难。针对这个问题,提出一种基于双向传播长短期记忆网络(bidirectional long short-term memory, Bi-LSTM)和SVM的风机叶片覆冰状态预测模型。首先,基于主成分分析法对SCADA数据进行降维处理,得到与风力发电机叶片覆冰关联度较高的数据特征;其次,对筛选的数据特征历史数据进行数据分析与预处理,并作为训练集输入Bi-LSTM神经网络进行训练,Bi-LSTM可以有效解决传统LSTM网络对长关联数据点信息识别能力较差的问题,经过测试表明预测模型精确度良好;最后,基于大量历史数据集训练好的SVM模型,对Bi-LSTM数据特征输出的预测数据进行覆冰状态判别,最终确定风机叶片是否会出现覆冰故障。
1 SCADA数据特征处理
1.1 主成分分析法
基于SCADA监测系统得到的数据指标集维数较多,在此情况下,往往会使得计算量增大引发维数灾难,因此需要对数据指标集进行降维。主成分分析法[11](principal component analysis,PCA)是一种广泛使用的数据指标降维方法,其目的是对能反映风机叶片覆冰状态特性的数据特征进行降维,同时对具有较高的原始变量信息量的数据特征进行排序,因此可利用该方法筛选影响风机叶片覆冰的关键指标。其步骤如下:
1)对数据进行标准化处理
2)计算标准化矩阵的相关系数矩阵
R=(Sij)p×p,i,j=1,2,…p
(1)
式中:R为协方差矩阵;Sij为协方差矩阵中第i行和第j列所对应的数。
3)计算相关系数矩阵的特征值和相应的特征向量
4)选择主成分
每个特征根对应的特征向量为a1,a2…,ap,通过特征向量将标准化的数据指标转化为主成分
yi=a′iβ
(2)
式中:yi为主成分;β为预处理后的原变量值。
主成分的信息量大小由方差贡献率决定,其表达式为
(3)
式中:αi为方差贡献率;λi为特征值;m为选取协方差矩阵特征值的个数。
累积方差贡献率表达式为
(4)
式中:G(m)为累积方差贡献率;λk为第k个主成分的特征值。
5)计算主成分载荷
主成分载荷的表达式为
(5)
式中:lij为主成分载荷;aij为各变量间的相关系数矩阵。
6)主成分得分表达式
Gi=α1y1+α2y2+…+αpyp
(6)
式中,Gi为最终所提取的主成分得分。
最后,将原始数据集带入主成分表达式中即可计算出主成分得分,通过筛选主成分得分高的构成新的数据特征集,通常当累计方差贡献率大于85%时,所确定的主成分可以反映相关变量特性。
1.2 数据预处理
为使数据特征形式符合Bi-LSTM风机叶片覆冰预测模型的输入规范,采用归一化和标准化对数据进行预处理[12]。针对范围有限的数据特征,采用归一化统一不同数据特征的取值范围,即将数据特征的上限设为1,下限设为0,其表达式为
(7)
式中:X′为预处理后的数据特征;X为原始数据;Xmax、Xmin分别为数据特征中的最大值和最小值。
对于范围不确定的数据,采用标准化降低异常数据带来的影响,即将数据特征的均值转化为0,方差转化为1,其表达式为
(8)
式中,δ、ζ分别为数据特征的均值和标准差。
2 Bi-LSTM神经网络
为解决一般的循环神经网络(recurrent neural network, RNN)存在的无法记忆长时间段信息和对内存与计算时间要求高的局限性,LSTM作为一种时间循环神经网络被设计提出[13-14]。且双向机制可以提供给输出层输入序列中每一个点完整的过去和未来的上下文信息,进一步提高网络对长关联信息的识别能力[15]。
LSTM单元包含3个门控:输入门、遗忘门和输出门。此外,每个序列索引位置t有向前传播的隐藏状态h(t),同时还有一个用于描述前后时间耦合的细胞状态,记为C(t)。具体模型结构如图1所示。
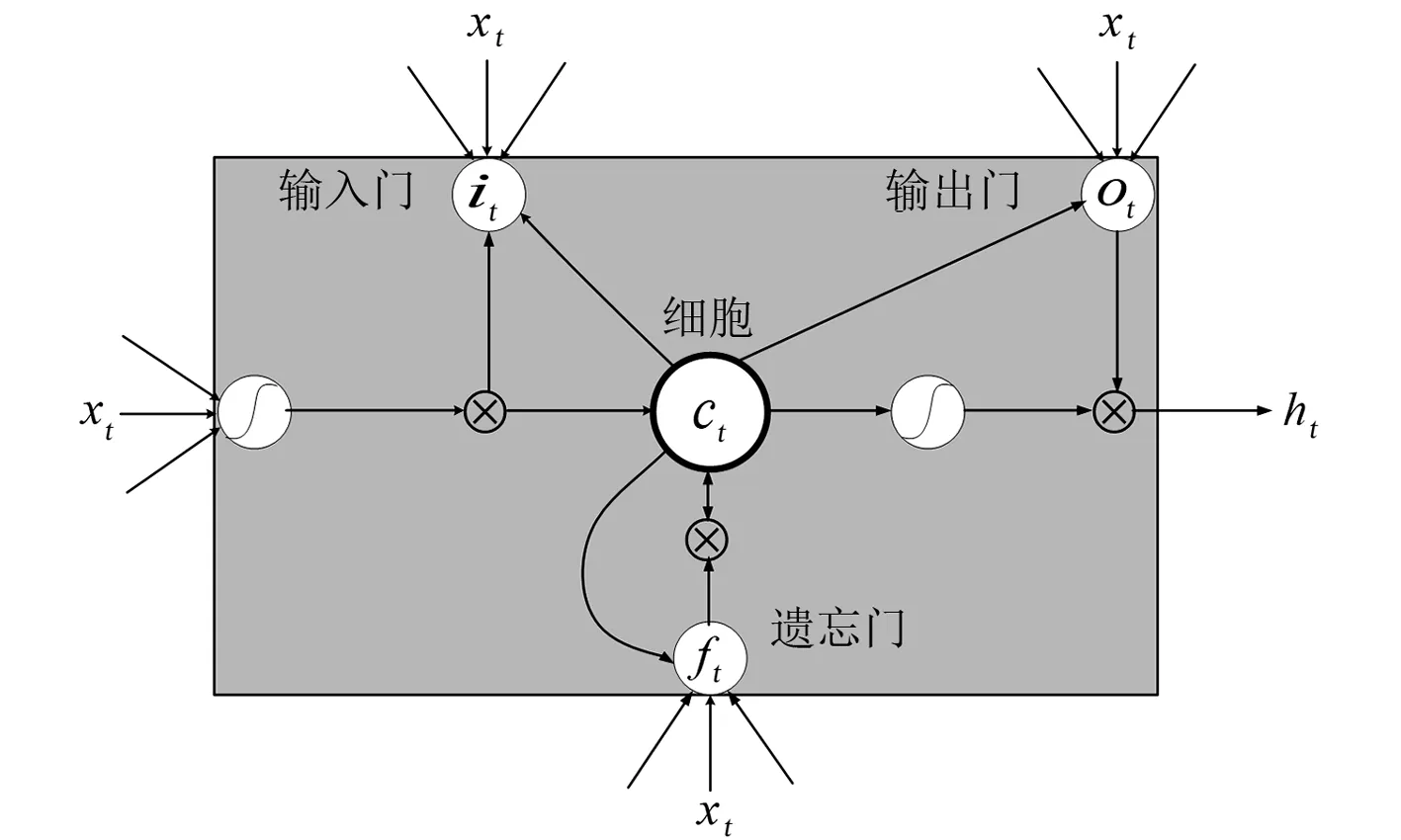
图1 LSTM内部结构
LSTM的3个门控具体运作流程如下所述:
1)遗忘门
遗忘门决定前一个时间步内部状态对当前时间步内部状态的更新。首先,在遗忘门输入端输入上一序列的隐藏状态ht-1和本序列数据Xt;其次,通过激活函数σ,得到遗忘门的输出pt;最后,输出值pt赋值给对应细胞状态变量Ct-1,表达式为
pt=σ(Wpht-1+UpXt+bp)
(9)
式中:Wp、Up为线性关系的系数;bp为t-1时刻到达t时刻的神经元所对应输入门的偏置;σ、pt分别为sigmoid的激活函数和输出结果,其中pt∈(0,1)。
2)输入门
输入门决定当前时间步的输入和前一个时间步的系统状态对内部状态的更新。具体为将过去的记忆与现在的记忆合并:首先,由sigmoid激活函数得到it;其次,由tanh激活函数得到at;然后,将it与at进行相乘;最后,用所乘结果对细胞状态进行更新,其表达式为
(10)
式中,Wi、bi分别为t-1时刻到达t时刻的神经元所对应的输入门的权重函数和偏置;Wa、ba分别为t-1时刻到达t时刻的神经元所对应的输入数据的权重函数和偏置;Ui、Ua为输入门线性关系的系数。
细胞状态更新过程由Ct-1与遗忘门输出pt的乘积和输入门it与at的乘积构成。此过程表达式为
Ct=Ct-1⊙pt+it⊙at
(11)
式中:Ct为新细胞状态;⊙为哈达玛积。
3)输出门
输出门决定内部状态对系统状态的更新。输出基于细胞状态,但最终输出结果会被过滤。首先,运行一个sigmoid层来确定细胞状态的输出部分;其次,把细胞状态通过tanh进行处理(得到一个在-1~1之间的值)并将它和sigmoid门的输出相乘,最终输出结果。
ot=σ[Wo(ht-1,xt)+bo]
(12)
ht=ottanh(Ct)
(13)
式中:ot为输出门系数;Wo和bo分别为t-1时刻到达t时刻的神经元所对应的输出门的权重函数和偏置。
Bi-LSTM网络的基本思想是对于一个训练序列进行向前和向后两次LSTM训练,并连接着同一个输出层,从而提供给输出层输入序列中每一个点完整的过去和未来的上下文信息,如图2所示。其公式为:
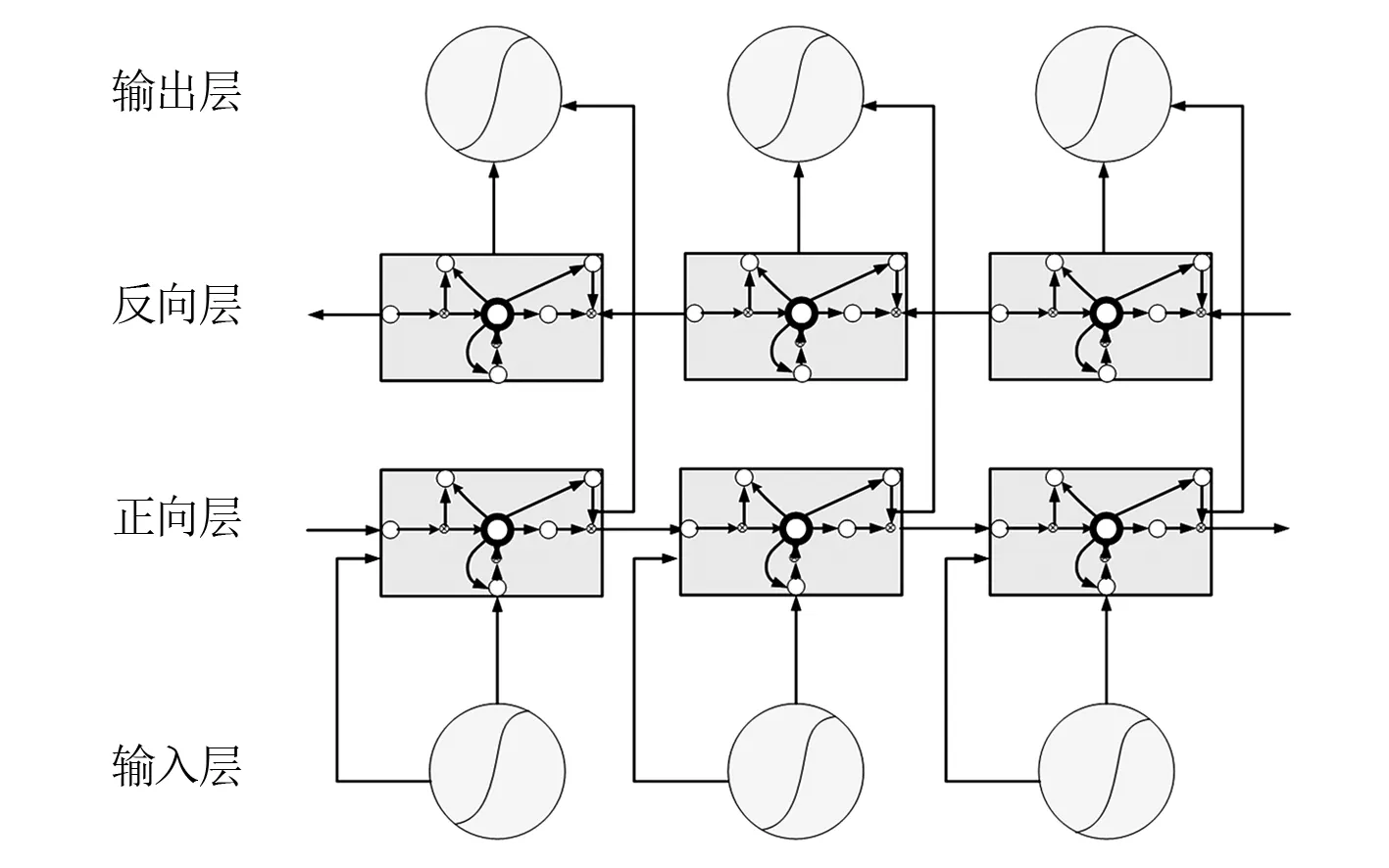
图2 Bi-LSTM
1)正向计算LSTM隐藏层状态
st=f(U·xt+W·st-1)
(14)
2)反向计算LSTM隐藏层状态
(15)
3)最终输出取决于s和s′
(16)
式中:U、V、W为各个权重矩阵;f、g为LSTM激活函数。
Bi-LSTM网络拥有的特殊门结构和记忆功能,具有良好的时序数据处理能力。风机覆冰预测所需基础数据冗杂且都与时间序有关,所以Bi-LSTM网络适用于所提的风机叶片覆冰状态预测。
3 SVM模型
支持向量机是由Vapnik等人提出[10]。SVM可用于高维模式的识别,即分类问题研究。其基本思想是,基于在数据集里找到支持向量,在特征空间上找到最佳分离超平面使得训练集上的不同样本间隔最大。
腕表搭载的机心Movement RR-01在时间指示上仅为简单的小三针,但是十分有心地加入了停秒机制和秒针归零机制,方便腕表精准调校(大部分的腕表在调整时间时秒针会继续走)。这款机心还仿制了旧式怀表的上链机制,令表主在上发条时能够听到非常复古的机械声。这些细节处的用心,大概就是这匹黑马得以登顶的原因。机心提供100小时动力储存,时分秒显示。
对于二分类问题,最优分类超平面的表达式可设为
wφ(x)+b=0
(17)
式中,w、b分别为权重和阈值偏差。
进一步地,原样本空间的二分类问题可表示为
yi(wφ(x)+b)≥1
(18)
式中,yi∈[-1,1],为输出状态类别。
同时引入松弛变量εi、惩罚因子C以及Lagrange乘子αi应对可能产生的样本分错问题,将原问题转换为对偶问题,即
(19)
根据Kuhn-Tucker条件,αi须满足
(20)
求解上述问题,可得到最优分类函数
(21)
式中:sgn(u)为符号函数,若u>0,则sgn(u)=1,u<0,则sgn(u)=-1;xi为是样本变量数据;yi为样本类标;x为待分类样本;m为支持向量个数;K(x,xi)为核函数。
根据专家的先验知识预先选用核函数为
K(x,xi)=exp(-γ|u-v|2)
(22)
式中,u、v为数据集的样本。
4 模型求解
采用MATLAB软件平台,对所建立的基于Bi-LSTM和SVM的风机叶片覆冰状态预测模型进行求解。系统硬件环境为Intel Core I5 CPU,3.30 GHz,8 GB内存,操作系统为Win10 64 bit。求解流程如图3所示,具体步骤如下:

图3 模型求解流程
1)采用PCA对原始指标数据集进行降维处理,降维得到与覆冰关联度贡献最大的特征指标。
2)基于降维得到的特征指标选择所对应的历史数据,进行数据标准化预处理,用于Bi-LSTM预测模型的训练及测试评估。
3)选择降维得到特征指标对应的覆冰及未覆冰状态的历史数据,对SVM分类进行训练。
4)将实际数据输入Bi-LSTM预测模型,输出得到特征指标预测数据,再输入SVM分类模型对风机叶片覆冰状态进行判断。
5 算例分析
5.1 PCA特征指标降维
基于PCA对SCADA特征指标集降维得到13个特征指标。根据主成分得分对叶片覆冰影响的重要程度由大到小的排序如表1所示。由于主成分舱内温度、环境温度及偏航位置的累积方差贡献率达到了85%以上,具有较高的原始变量信息量,可以反映叶片覆冰状态之间的相关性,因此选择上述3个特征指标作为所提模型的输入量。

表1 13个数据特征排序
5.2 Bi-LSTM预测模型分析
对覆冰和正常状态的数据集添加标记以区分,总共采集2000组数据,其中后400组数据为覆冰状态数据。根据模型经验[16],并对比在不同训练样本和测试样本下的预测精度,如图4所示,可知训练数据和测试数据的数量之比为1600∶400时能收获较好的预测精度,且再增加训练样本时,模型的预测精度基本保持不变。因此选用1600组数据用于模型训练,400组数据用于模型测试。通过多次试验,Bi-LSTM预测模型的参数为:2层隐藏层,每层神经元数依次为64、128个;训练1000轮;激活函数为adma;批大小为32。
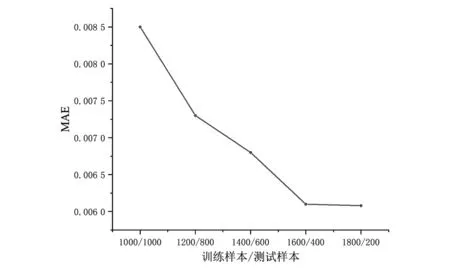
图4 不同训练样本/测试样本比例下模型预测效果对比
选取主成分得分前三的数据特征的舱内温度、环境温度及偏航位置3组指标,通过可视化视图显示Bi-LSTM训练集数据的预测结果。图5、图6和图7分别展示了预处理后的机舱温度、环境温度及偏航位置预测值和实际值走势。从图中可看出,预测值和实际值具有较高的重合度,说明所提方法Bi-LSTM预测模型有效性。

图5 舱内温度真实值与预测值对比
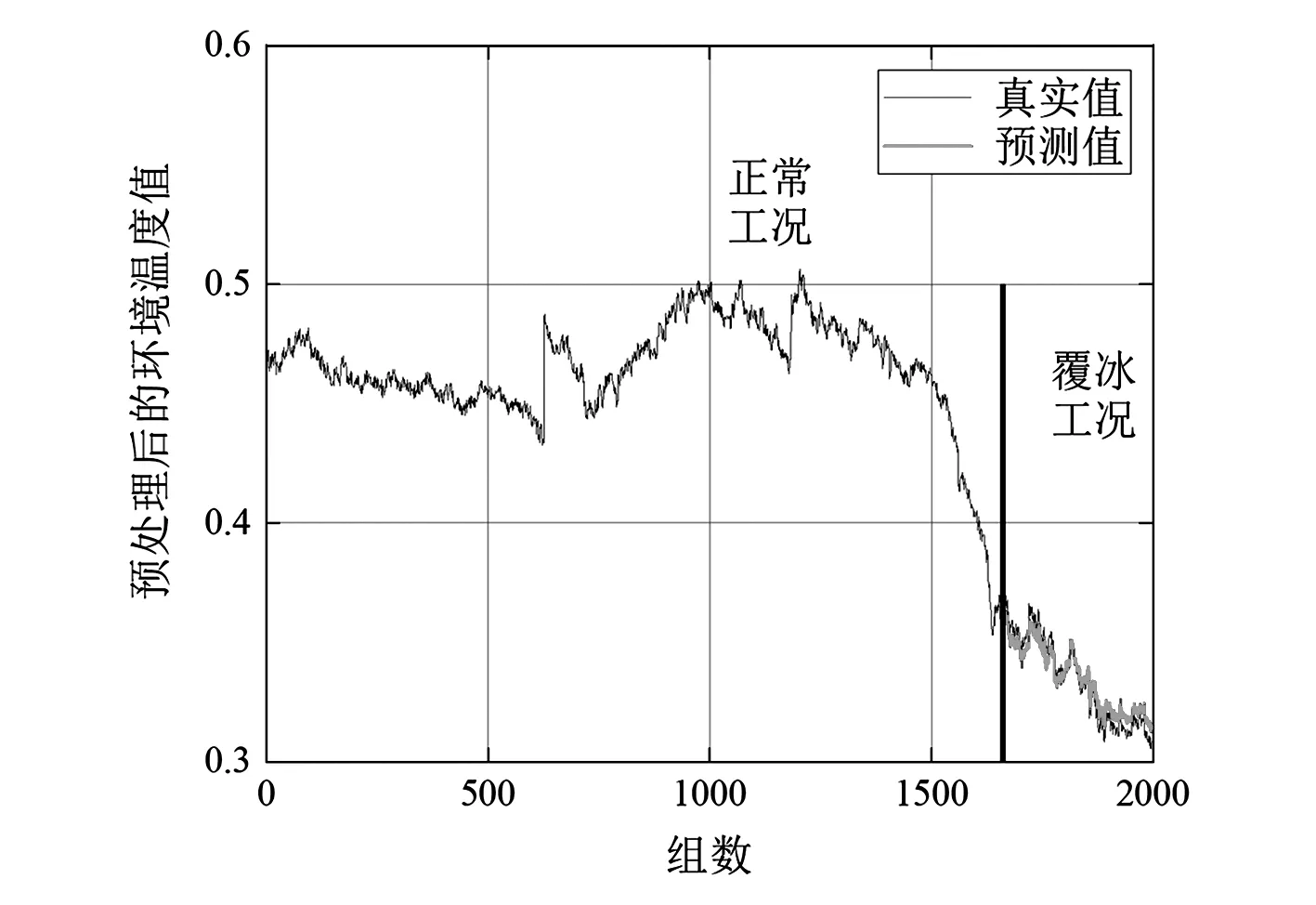
图6 环境温度真实值与预测值对比
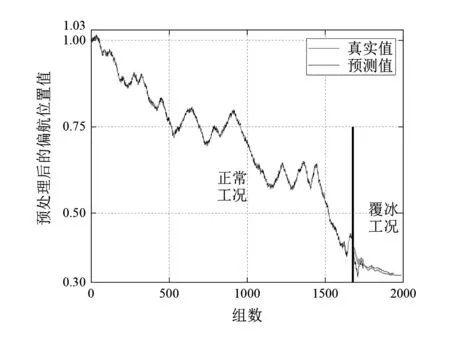
图7 偏航位置真实值与预测值对比
为进一步说明采用Bi-LSTM预测模型的准确性,采用表2中的3种误差函数作为模型评价指标[17]。

表2 误差函数
误差函数的公式如下:
1)平均绝对误差(mean absolute error, MAE)
(23)
2)平均绝对百分比误差(mean absolute percentage error,MAPE)
(24)
3)均方根误差(root mean square error,RMSE)
(25)

通过测试集数据预测结果,选取舱内温度为例,对比Bi-LSTM与其他3种预测模型的MAE、MAPE和RMSE评价指标,如表3所示。所采用的Bi-LSTM模型评价指标均优于其他两种模型,由此可见Bi-LSTM预测准确性更好。
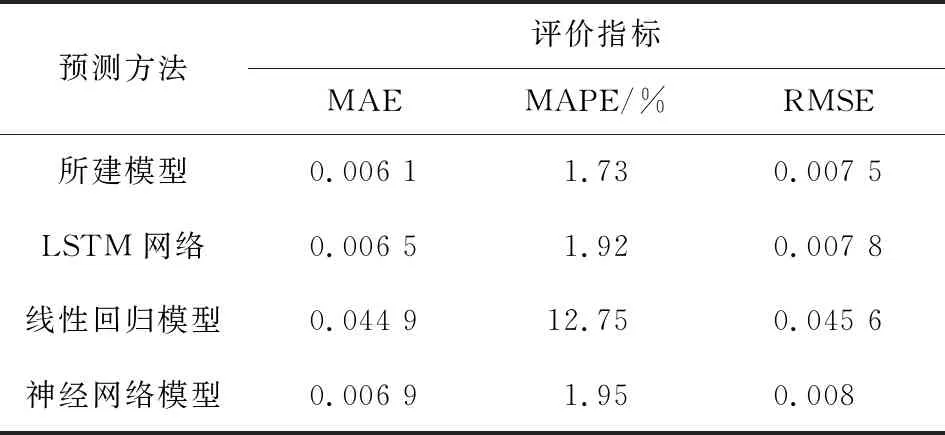
表3 4种预测模型的性能指标结果
5.3 风机覆冰状态预测分析
基于Bi-LSTM和SVM的风机叶片短期覆冰状态预测模型,自动判断未来一段时间内是否会出现风机叶片覆冰故障。首先,分别从2000组正常工况和覆冰工况预测数据集中各挑选300组标签数据,将标签数据输入SVM模型进行深度训练,将覆冰工况下每组数据的训练值标记为1,正常工况下每组数据的训练值标记为0。当SVM模型训练完成后,通过将真实数据输入Bi-LSTM预测模型,再将预测输出值输入SVM模型,对应可得到一个在0.5左右的聚类输出值,若输出值大于0.5,则判断1,状态为覆冰;若输出值小于0.5,则判断为0,状态为正常。
从实际数据集中各挑选40组正常和覆冰工况下的数据输入Bi-LSTM状态预测模型,得到舱内温度、环境温度及偏航位置的预测值,将其输入SVM分类模型,最后根据预测输出值判断风机叶片覆冰状态,基于Bi-LSTM和SVM状态预测模型输出结果最终只有4组数据发生误判,76组预测输出为正确。通过此实验可以得出,所提的预测方法准确率为95.0%。
6 结 语
以某风电场风电机组SCADA数据为基础,提出了一种基于Bi-LSTM和SVM的风机叶片覆冰状态预测模型,通过大量历史数据对Bi-LSTM预测模型及SVM模型进行训练,Bi-LSTM预测可以得到更好的预测效果。此外,结合实际数据,对风机叶片未来一段时间是否会出现覆冰故障进行预测,预测结果表明所提的方法正确率可以达到95.0%,在准确性和时效性上要强于其他传统方法。进一步地,当获得新的实际数据后,预测模型可以继续对训练集进行扩展,进而提高预测准确率。同时可以为风机叶片覆冰状态预测提供可靠的决策依据,确保风电场在严寒季节能安全经济运行。
猜你喜欢
天天爱科学(2022年12期)2022-11-10 08:33:28
装备制造技术(2020年1期)2020-12-25 05:19:10
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
能源(2018年5期)2018-06-15 08:56:02
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
能源(2017年9期)2017-10-18 00:48:27
现代工业经济和信息化(2016年12期)2016-05-17 05:37:47
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
安徽冶金科技职业学院学报(2015年3期)2015-12-02 03:46:38
