
基于翻译API的HSK汉-乌平行词库构建方法研究
2021-07-19 22:31胡创业黄欣欣
电脑知识与技术 2021年14期
胡创业 黄欣欣


摘要:该文介绍了如何利用翻译API技术构建HSK汉语-乌兹别克语平行词库的关键技术和方法,采用基于翻译API技术对HSK汉语词汇完成自动有效的翻译对齐工作,实现HSK汉-乌平行词库的构建目标。并通过两种方法对平行词库完成扩充,最后对未完成对齐的词汇进行人工近义词校对,使HSK平行词库趋于完善。
关键词:翻译API;HSK;平行词库;对齐;扩充
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)14-0201-03
Abstract: This article introduces the key technologies and methods of how to use the translation API technology to build the HSK Chinese-Uzbek parallel thesaurus. The translation API technology is used to complete the automatic and effective translation alignment of HSK Chinese vocabulary to achieve the construction goal of the HSK Chinese-Uzbek parallel thesis. The parallel thesaurus is expanded by two methods. Finally, artificial synonym proofreading is performed on the incompletely aligned words to make the HSK parallel thesaurus perfect.
Key words: translation API; HSK; parallel thesaurus; alignment; expansion
1 背景
平行語料库是同一含义不同语言对齐所组成的语料资源,对机器翻译研究具有重要作用和意义[1-2]。目前在国内研究构建汉语-乌兹别克语对齐语料库的技术外均相对较少,本文将主要介绍汉-乌双语对齐语料库构建技术研究,此研究能为汉-乌机器翻译技术研究者提供语料基础,具有一定的学术价值与应用价值[3]。
通过对相关文献资料调查研究发现,汉语-乌兹别克语对齐语料库的研究仍然处在发展缓慢的初期阶段[4]。国家战略的发展要求我们国家必须加速推进汉-乌对齐语料库的构建和技术研究[5],这项研究技术的成果会对后期的汉-乌机器翻译研究有很大促进作用,并为中乌双方的无障碍交流提供有效的现代信息交流工具,带动两国之间的经济、文化、科技、教育等方面的交流和发展[6-7]。
本文以汉语水平考试(HSK)汉语词汇为基础,引出如何利用翻译API技术自动生成汉语-乌兹别克语双语对齐词库,及其相关技术、问题和实现解决技术方法。汉语水平考试(HSK)中共有1至6级汉语词汇5000个,实验采用翻译API技术能够快速有效生成汉-乌平行语料库,并将库中少量未完成翻译词汇进行人工校对,从而形成不断完善的汉-乌平行语料词库。这对后期的汉-乌机器翻译研究以及乌兹别克语使用者学习汉语都将会有很大的帮助[8-9]。
2 翻译应用程序接口(API)的应用
随着近几年机器翻译技术的兴起[10],研究人员开发了各具不同功能的翻译程序,谷歌翻译、有道翻译、百度翻译是国内应用比较多的三种翻译程序。这三种翻译程序都有可以应用程序接口。有道翻译和百度翻译所包含语种多为国际主流语言,而谷歌翻译除了主流语言以外还包括了许多非主流语言,科研人员可以通过调用翻译应用程序接口来解决各样功能的翻译问题[11-12]。文中研究内容为汉语-乌兹别克语的双语语料库构建,参照下表1分析可知,只有谷歌翻译包含乌兹别克语语种,所以本文采用谷歌翻译应用程序接口。
谷歌翻译和其他大多翻译软件一样都为用户提供API,本文主要使用的是python库中的googletrans包,其核心思想是模拟用户进行访问网页并获取网页内容,通过构造URL发起GET请求,得到一个JSON结果并提取翻译内容。
3 HSK汉-乌平行词库构建
3.1 HSK汉语语料准备与预处理
语料准备。汉语水平考试(HSK)大纲词汇,语料存储格式为EXCEL表格形式,语料里面内容有汉语水平考试(HSK)考试大纲词汇一至六级共5000个。每个词汇后都带有括号并标明等级,这属于噪声部分需要后期处理,并且一至六级词汇都在一个表格,一次翻译内容较多且不易分类,因此需要分为一至六级的六个表格进行分类处理。
语料预处理。去除括号及等级部分,采用表格截取公式为=LEFT(A2,FIND("(",A2)-1),其中A2表示第一列第二行单元格内容,FIND函数表示定位查找目标位置,LEFT表示从左边开始截取,截取完成就会去除语料词后面冗余部分,只保留语料词的有用词汇部分。最后,通过快速复制公式方法快速处理剩余所有词汇。例如:原样的格式“爱(一级)”,改为我们需要的词汇格式“爱”。建立无带其他附加符号的汉语词,总共处理5000个汉语词汇。
3.2 汉-乌对齐语料自动构建
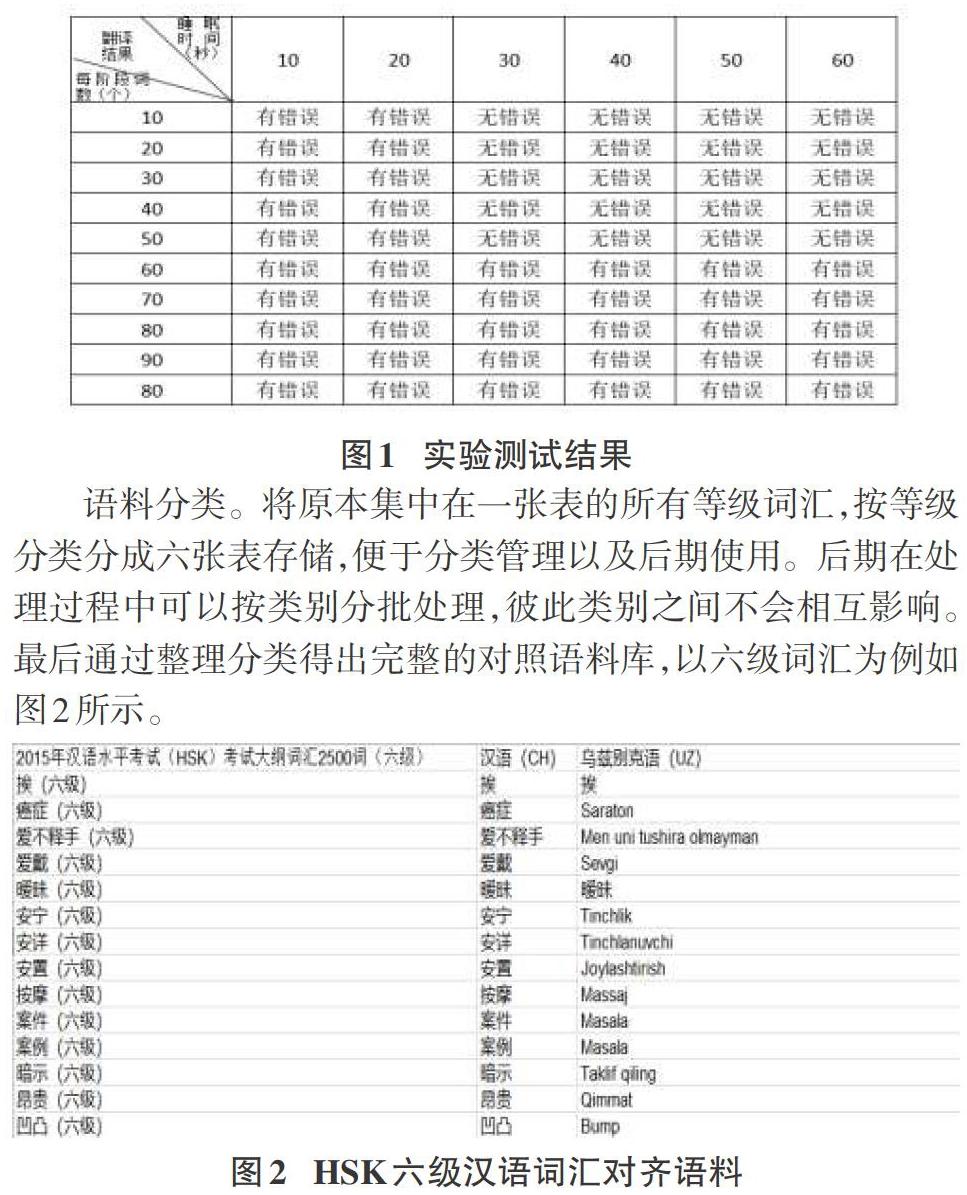
此次实验使用的核心思路如下,通过循环依次读取语料词汇表中已处理的词汇;通过调用谷歌翻译应用程序接口技术,根据不同翻译环境设计翻译模型。而在调用谷歌翻译应用程序接口技术时,由于谷歌翻译服务器有反爬虫机制而不能频繁访问使用,因此需要通过实验测试它的访问最佳参数。通过如图1所示的实验结果分析,当翻译每次翻译频次为50次、休眠时间为30秒时,为访问谷歌翻译服务器的最佳状态。
语料分类。将原本集中在一张表的所有等级词汇,按等级分类分成六张表存储,便于分类管理以及后期使用。后期在处理过程中可以按类别分批处理,彼此类别之间不会相互影响。最后通过整理分类得出完整的对照语料库,以六级词汇为例如图2所示。
从上图我们可以看出大部分HSK汉语词汇均可有效地翻译并写入表中,部分词汇第三方软件无法识别翻译,如上图中的“暧昧”一词,这是中国汉语中比较形象的一个词汇,但国外可能无法理解其含义,因此需要找到它的近义词如“含糊”,进行再次翻译并人工校正。
4 HSK汉-乌平行词库扩充
4.1 基于乌兹别克语语料的HSK词库扩充
1)语料预处理。对于直接从乌兹别克语网站上爬取的乌兹别克语语料,里面带有很多垃圾语料和噪声语料,如网页结构标签、数字、网页链接以及符号等等,整理收集后分类如下表2所示,如果不对其进行预处理除杂,将会对后期实验产生很大影响。
2)分词去重。通過对预处理语料分词后共得到大小共14M的乌语词语料文档,经过分词处理后共计得到1512129条词汇。文档中有大量重复词语,需采用文档去重技术对词语料文档进行去重。使用去重工具,将列表中重复项去掉,最终得到的去重词表通过循环写入表中,共计得到不重复乌兹别克语词条共计11054条,我们这里定义其为新词库。
3)新词库的平行词库构建。
上述所得到的是按顺序排列且不重复的乌兹别克语新词库,这里仍然使用基于翻译API技术的词对齐语料库的构建方法实现新词库的平行词库的构建,具体实现模型如图3所示。
5 结束语
本文首先介绍了翻译API技术的相关应用,并利用此项技术完成对HSK汉-乌平行词库的自动构建。但HSK词库中的词汇是比较常用词汇,并不能完整涵盖所有词汇,因此还有很大的扩展空间。而对于HSK词库的扩充本文采用了两种方法,一种方法是结合所构建的汉-乌平行语料库中的平行词库,以乌兹别克语词汇为基准对照HSK词库进行对照扩充;另一种方法是结合汉语词典对HSK词库进行扩充。这两种HSK词库扩充方法各有优缺点,基于乌兹别克语语料的HSK词库扩充方法所扩充新词都是基于乌兹别克语词汇,基本上都能找到其对应的平行汉语词汇;而基于汉语词典的HSK词库扩充方法的扩充规模较大,但其扩充新词中会存在一定量的词汇无法找到对应的平行乌兹别克语词汇。两种扩充方法的优缺点具有互补的特性,因此将两种方法结合起来对HSK词库进行扩充可以达到很好的效果。
参考文献:
[1] 兰彩玉.中药汉英双语平行语料库的设计及构建[J].亚太传统医药,2014,10(8):1-3.
[2] 房璐.英汉可比较语料库的构建与应用研究[D].苏州:苏州大学,2011.
[3] 阿西穆·托合提.维吾尔语-乌兹别克语机器翻译研究[D].乌鲁木齐:新疆大学,2017.
[4] 徐雄飞.大中华区词对齐自动抽取研究[D].南昌:江西师范大学,2016.
[5] 李哲.俄汉-汉俄平行语料库建设与研制的迫切性及应用价值[J].文学教育(下),2018(1):90-91.
[6] Tao Deng.Correspondence Analysis of English-Chinese Contrast Relationship and Adverbial Module in the Construction of Parallel Translation Corpus[C]//Institute of Management Science and Industrial Engineering.Proceedings of 2018 4th International Conference on Education,Management and Information Technology(ICEMIT 2018).Institute of Management Science and Industrial Engineering:Computer Science and Electronic Technology International Society,2018:4.
[7] 沈韵,张炼.基于平行语料库的计算机辅助翻译软件在翻译教学中的应用——以雪人CAT软件为例[C]//外语教育与翻译发展创新研究(第七卷),2018:254-257.
[8] Lihua Sun.Teaching Design for Translation Based on English-Chinese Parallel Corpus[C]//Singapore Management and Sports Science Institute,Singapore\International Communication Sciences Association, Hong Kong.Proceedings of 2017 2nd EBMEI International Conference on Education,Information and Management (EBMEI-EIM 2017).Singapore Management and Sports Science Institute,Singapore\International Communication Sciences Association,Hong Kong:智能信息技术应用学会,2017:4.
[9] Levshina N.A multivariate study of T/V forms in European languages based on a parallel corpus of film subtitles[J].Research in Language,2017,15(2):153-172.
[10] 刘克强.基于平行语料库的莫言小说英译特征研究[C]//外语教育与翻译发展创新研究(第六卷),2017:236-241.
[11] Afolabi S.Translation and interpretation market needs analysis:towards optimizing professional translator and interpreter training in Nigeria[J].The Interpreter and Translator Trainer,2019,13(1):104-106.
[12] Nú?ez J L,Bola?os-Medina A.Predictors of problem-solving in translation:implications for translator training[J].The Interpreter and Translator Trainer,2018,12(3):282-298.
【通联编辑:谢媛媛】
