
声光警报器音频自动检测系统研究与设计
2021-07-19 22:11张红英
电脑知识与技术 2021年13期
张红英


摘要:为解决以往警报器质检依赖人工听音的问题,研究了音频自动检测方法。通过对比分析正常警报器音频和异常警报器音频的声谱图,分别总结出4类音频异常的频谱特点,提出了以幅频特性曲线峰值点的频率和幅度为主要元素的音频特征向量设计方法。为解决异常音频样本数量较少的问题,提出了三种音频处理方法。基于BP神经网络原理设计并训练了警报器音频识别模型,准确率达99.8%,异常音频召回率达100%。基于Windows系统开发了声光警报器音频自动检测系统,实际使用效果良好。
关键词:声谱图;机器听觉;异音检测;神经网络;特征提取
中图分类号:TP23 文献标识码:A
文章编号:1009-3044(2021)13-0024-04
Abstract: In order to solve the problem that the previous alarm quality inspection relies on manual listening, an automatic audio detection method is studied. By comparing and analyzing the sound spectrums of normal alarm audio and abnormal alarm audio, the spectrum characteristics of four types of abnormal alarm audio are summarized, and the design method of audio feature vector is proposed, which takes the frequency and amplitude of peak points of amplitude-frequency characteristic curve as the main elements. In order to solve the problem of small number of abnormal audio samples, three audio processing methods are proposed. Based on the principle of BP neural network, an alarm audio recognition model is designed and trained, with an accuracy of 99.8% and an abnormal audio recall rate of 100%. Based on Windows system, an automatic audio detection system for acousto-optic alarm is developed, which has a good practical effect.
Key words: sound spectrums; machine hearing; heterophony detection; neural network; feature extraction
1 背景
聲光警报器是一种通过声音和光来向人们发出示警信号的装置,广泛应用在各类场所,是保证生产和人身安全的重要设备。在警报器的制造过程中,需要检查警报声音是否异常,以往主要采取人工听音的方式来进行。由于警报声音的声压级很高,1米内可达到100dBA以上,长期之下会对检验人员的健康造成不利影响,且人工主观判断也存在一定的随意性。因此,研发声光警报器异音检测系统具有现实意义。
受限于应用范围,关于声光警报器音频自动检测技术的研究较少。文献[1-2]中研制了自动测试发声元件蜂鸣器的频率的装置,基本原理是:首先对蜂鸣器音频进行快速傅里叶变换,得到幅频特性曲线,然后提取幅频特性曲线中峰值点对应的频率,最后判断峰值频率是否在正常的频率范围内。由于分析方法较为简单,上述装置无法识别蜂鸣器声音过小、声音嘶哑、声音断续等问题。
本文在对警报器音频进行频谱分析的基础上,提出了音频特征向量的提取方案,构建了基于BP神经网络的音频检测模型,最终开发出用于检测声光警报器音频的自动化系统,并投入生产使用。
2 音频样本采集
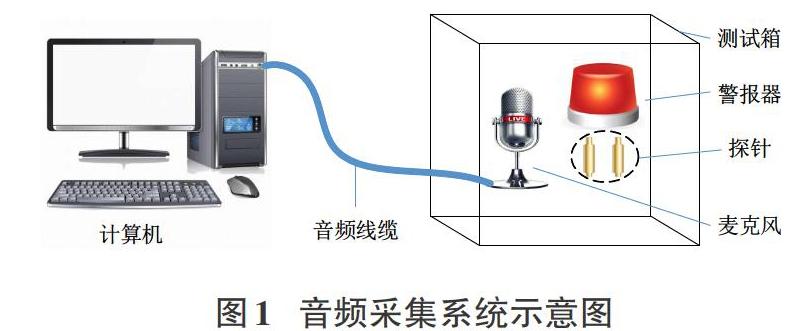
声光警报器音频采集系统如图1所示,麦克风、警报器均放置在具有隔音效果的测试箱内,麦克风通过音频线缆连接到计算机上,探针通过导线连接到测试针床(图中未展示),当探针接触到警报器底部的簧片时,警报器将发出变调周期约为3s的警报声音。
采用C#语言开发音频采集工具,通过端点检测实现仅在警报声音响起时保存录音。通常情况下警报器声音响度远高于环境噪音,采用短时平均能量阈值法作为端点检测算法。另外,音频采样频率设定为48KHz,采样精度设为16位。
3 音频特征提取
3.1 声谱图构建
声谱图是通过对音频信号进行加窗分帧及离散傅里叶变换而来。本文选择海明窗作为窗函数,设定帧长与离散傅里叶变换点数相等,帧移为帧长的[12]。帧长过短时,离散傅里叶变换的总点数较少,将导致频率分辨率不够(如图 2(a)所示,图像对比度低,图形边缘模糊);帧长过长时,分帧后的音频信号非平稳性增加,也将导致频率分辨率降低(如图 2(b)所示,图形边缘模糊)。
经过测试,当帧长设定为4096点时,频率分辨率较好,此时警报器音频的声谱图如图 3所示,其中横坐标为报警时间,纵坐标为声音频率,像素灰度越深表示相应时刻、相应频率的声音分量越大。另外,可以看出警报器音频包含基音和泛音,在一个变调周期内基音频率先是逐渐升高至最高点,再逐渐降低。
3.2 异常音频分析
统计发现警报器音频异常可归纳为声音过小、声音断续、夹杂异音、音调抖动、音调增高等五种情况。其中,声音过小可通过计算警报器音频的声压级检测出来,不再赘述。
1)声音断续
是指一个变调周期内的某个或某些时刻警报器无声音,图 4(a)标记框内的频率曲线断开处即对应警报器无声音时刻。
2)夹杂异音
是指一个变调周期内的某个或某些时刻警报器音频中带有杂音。如图 4(b)标记框所示声音分量既不在基音频率曲线上,也不在泛音频率曲线上,即为异音。
3)音调抖动
与夹杂异音的表现类似,但出现音调抖动的时刻,正常的基音或泛音分量消失,如图 4(c)标记框所示音频分量。
4)音调增高
是指报警器音频的基音和泛音频率明显超出正常范围,对比图 4(c)图和 4(d)可以发现,后者基音的频率明显高于前者。
另外,图4所示异常音频样本是在较为安静的环境下录制的,车间现场检测警报器时,现场的气动装置等产生的动作噪音会叠加到警报器音频中。如图 5所示,标记框内带有噪音分量。可以看出,噪音的频率分布相对均匀。
3.3 特征选择及归一化
提取音频特征参数的方法有很多,如基于小波包分解提取子频带能量谱参数[3],基于2D-Gabor 滤波器对提取声纹特征[4],基于PCA降维方法提取差异性频段特征[5]等,这些方法所提取出的参数主要反映了音频的整体特性。从图4可以看出,本文所研究的警报器音频异常状态大多持续时间较短,异常时长占整个变调周期的比例约为百分之五,需要有针对性地选择音频特征参数。
以图5所示声谱图为例,将其任意一帧幅频信息单独绘制,即可得到相应的幅频特性曲线。图6为叠加有噪音的音帧对应的幅频特性曲线,图7为相邻音帧的幅频特性曲线,对比可以发现,有噪音干扰时(1KHz,7KHz)区间内频率分量的平均幅值和最小幅值有所增加。另外,幅频特性曲线峰值点的频率及幅值信息体现了警报器音频的主要特征。当音频异常时,相应峰值点的频率及幅值将受到影响。
4 训练样本集构建
4.1 异常样本扩充
警报器制造过程中,音频异常的样本数量较少,这就导致收集的正常样本数量远多于异常样本。受异常音频特征的启发,采用“清零”“互换”“偏移”三种方式处理异常音频样本,以生成新的异常样本,具体说明如下:
1)清零
模拟声音断续的特征,随机选择特征向量[t]中两个相邻特征单元[si]和[si+1],将此两个特征单元的元素值置零。
2)互换
模拟音调抖动的特征,随机选择特征向量[t]中两个不相邻特征单元[si]和[sj],将此两个特征单元的元素值互换。
3)偏移
模拟音调增高的特征,将特征向量[t]中每个非零峰值点的频率[fj]同时增加一个随机偏移量[Δf]。
4.2 输出编码
本文所研究的异常音频识别属于二分类问题,对识别结果采用一位二进制进行编码即可,编码规则为:将正常声音用“0”表示,异常声音用“1”表示。
5 检测模型构建
5.1 模型设计
BP神经网络被广泛应用于解决分类建模问题,通过前期的网络学习可使得后期预测结果与期望结果充分接近。在结构上BP神经网络由输入层、若干隐含层、输出层构成,每一层网络又由若干神经元组成[6]。式(3)即为神经元的表达式,其中[f(?)]为激活函数,[xi]为输入参数,[wi]为权值,[θ]为阈值。
BP神经网络模型设计主要是确定网络层数、神经元个数、激活函数等。输入层节点的个数与特征向量的长度相等;输出层神经元的个数与输出编码的位数相等;隐含层层数及神经元数量则结合经验法则及试探法来确定,本文最终设计为由6个节点构成的1个隐含层。隐含层激活函数设定为leaky_relu(),输出层激活函数设定为sigmoid()。
5.2 模型训练及验证
收集正常警报器声音样本9000个,异常警报器声音样本200个,对每个异常样本分别进行三种样本扩充操作5次,最终得到异常样本3200个。从上述样本中,随机抽选10%的正常样本和异常声音样本用作测试集[T],其余样本用于训练模型。训练设置如下:优化算法设置为RMSProp;损失函数设置为binary_cross_entropy;初始学习速率设置为0.01,训练过程中逐渐减小学习速率;验证集比例设置为0.2;批大小设置为100。训练过程中识别准确率变化趋势如图8所示。可以看出从第35轮训练开始,准确率提升速度已十分缓慢,此后验证集上的准确率甚至有所下降,这说明模型过拟合现象加重,故选择第35轮时的模型参数构建识别模型。
利用得到的模型处理测试集[T],结果如表 1所示。计算可知,模型的准确率为99.8%,对异常音频的召回率为100%,虚警率为0.2%。需要说明的是,由于测试集样本数量仍偏少,模型的真实指标与上述数值之间存在一定差異。
6 系统集成开发
以C#为编程语言,基于WinForm框架开发警报器声音检测系统。系统主要包括声音采集和音频识别两部分功能,工作流程如图 9所示。系统能够实时监听环境声音,当检测到警报器音频后,自动生成相应的音频特征向量,并使用识别模型进行检测,识别结果经计算机串口输出。
7 结束语
本文所研制的声光警报器异音检测系统已经用于实际工程,使用效果良好。总结研究,可以得出以下结论:
1)多数类型的警报器音频异常的持续时间较短,异常时长占整个变调周期的百分之五左右,需要提取每一帧音频的信息,才能准确识别出异常;
2)根据每一帧音频的幅频特性曲线峰值点信息、特定频率区间的频率分量幅值信息等构建特征向量,可以用来检测警报器音频是否异常;
3)使用BP神经网络构建警报器音频检测模型,具有较好的识别准确率。
另外,使用过程中发现,当增加新的声光警报器型号时,需要重新收集音频样本,难以快速训练出高准确率的识别模型,后续还需要围绕改进建模方法继续研究。
参考文献:
[1] 杨明,林先锋,钟伟强,等.音频分析在蜂鸣器测试中的实践[J].电子质量,2018(10):78-81.
[2] 朱健民.基于ARM Cortex-M4和快速傅里叶变换的蜂鸣器自动测试方案[J].机电信息,2019(15):24-25,27.
[3] 江毓,郑燕萍,张新,等.基于改进BP神经网络的电机异音诊断[J].重庆理工大学学报(自然科学),2020,34(1):242-246,262.
[4] 杜晓冬,滕光辉,Tomas Norton,等.基于声谱图纹理特征的蛋鸡发声分类识别[J].农业机械学报,2019,50(9):215-220.
[5] 程华利,樊可清.异音检测的机器学习方法及其在电机质检中的应用[J].测控技术,2015,34(4):55-58,62.
[6] 刘方斌,曲均浩,张志慧.基于BP神经网络的天然与非天然地震识别[J].计算机应用与软件,2020,37(1):106-109,185.
【通联编辑:谢媛媛】
猜你喜欢
电子制作(2019年19期)2019-11-23
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
电测与仪表(2014年20期)2014-04-04
