
基于改进YOLOv3的街道行人检测与跟踪方法
2021-07-19 09:58武明虎黄咏曦
科学技术与工程 2021年17期
武明虎,黄咏曦,王 娟
(1.湖北工业大学湖北省能源互联网工程技术研究中心,武汉 430068;2.湖北工业大学电气与电子工程学院,武汉 430068;3.湖北工业大学太阳能高效利用及储能运行控制湖北省重点实验室,武汉 430068)
室外的行人检测和跟踪在无人驾驶、社会公共安全管理、交通管理等方面应用广泛,而街道的行人检测和跟踪正是其中的基础研究项目[1-2]。传统的街道行人流动调研采用人工的方式进行,需要消耗大量的人工成本和时间成本,极大地影响了公共交通和安全管理的效率。如今,视频监控已经遍布各个街道,且计算机视觉技术迅速发展,目前已实现对视频监控中的行人进行精确的检测,而深度神经网络的发展使得行人的跟踪效果更加完善[3],为街道行人的检测和跟踪奠定了深厚的基础[4-5]。
对于目标检测的方法,从2013年Ross Girshick提出R-CNN[6]开始,人们在短短几年内相继提出Fast R-CNN[7]、Faster R-CNN[8]、Mask R-CNN[9]、SSD[10]、YOLO[11-13]等算法,其中两步检测的目标检测方法(R-CNN系列算法)需要先产生大量候选框之后再用卷积神经网络对候选框进行分类和回归处理;单步检测的方法(SSD、YOLO系列算法)则直接在卷积神经网络中使用回归的方法一步就预测出目标的位置以及目标的类别[14-15]。虽然两步检测的目标检测方法在大多数的场景下精确率更高,但是它需要分两个步骤进行,因此,这种方法将耗费大量的时间成本和昂贵的硬件成本,不适合对视频文件进行实时的检测。而YOLO系列的网络速度更快,可以适应实时视频的检测,泛化能力更强[16-17]。
对于人员跟踪,2016年Alex Bewley提出了简单在线实时跟踪(simple online and real-time tracking,SORT)[18]算法,这种算法把传统的卡尔曼滤波和匈牙利算法结合到一起, 能在视频帧序列中很好地进行跨检测结果的关联, 而且它的速度比传统的算法快20倍左右,可以快速地对目标检测反馈的数据进行处理。
目标检测的准确率和检测框的精度对于后续的目标跟踪十分重要,因此,现提出距离和比例交并比(distance and proportional-IOU,DPIOU)损失替换YOLOv3损失函数中的均方误差(mean square error,MSE)损失,改进YOLOv3中的残差网络,最后结合SORT算法对街道的人员流动进行检测和跟踪,为公共交通和安全管理合理的人员流动数据提供参考,提高管理效率。
1 YOLOv3算法
YOLO系列算法将物体检测作为一个回归问题进行求解,它使用一个end-to-end网络完成从原始图像的输入到物体位置和类别的输出。实现了一步完成目标检测,与Fast R-CNN等分两步的算法相比,有着更快的检测速度。
比起YOLOv2使用的Darknet-19,YOLOv3使用了更加深层的网络Darknet-53,并使用Resnet提出的残差组件,从而使得网络效果更佳。Darknet-53共有53层卷积,首先是1个含有32个过滤器的卷积核,然后是5组重复的残差单元,其详细网络结构如图1所示。
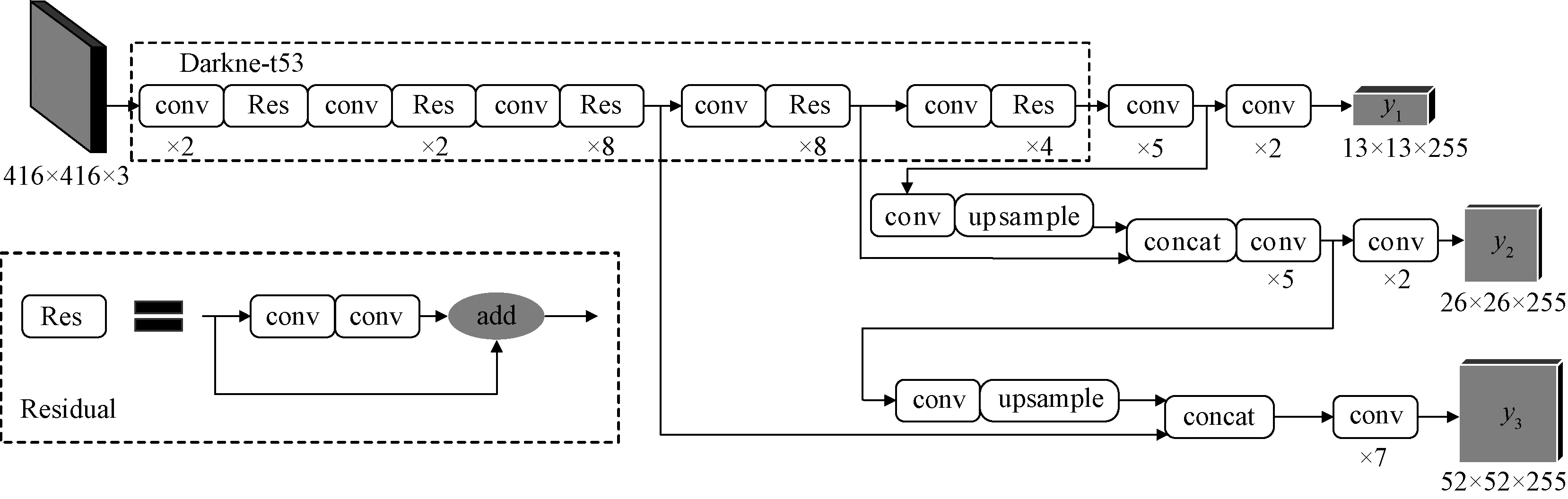
图1 YOLOv3网络结构图
在Darknet-53网络之后则是借用了Faster R-CNN里使用的FPN层,从而实现特征融合,最后生成3个特征图像。这3个特征图像分别包含检测框的位置信息、类别信息和置信度信息。在训练初期的时候,由于网络参数的初始化,位置信息、类别信息和置信度信息与真实的值会有较大的差别,于是YOLOv3根据预测框和真实框的中心点坐标以及宽高信息设定了MSE损失函数[19]。
YOLOv3的损失函数包含3个部分:回归框位置带来的损失lbox、置信度损失lobj和类别损失lcls,其公式为
loss=lbox+lobj+lcls=
(1)
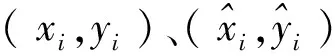
可以看到式(1)中回归框位置带来的损失,也就是lbox部分使用的是MSE损失,它易于求导,对于运算的速度有一定的提升,但它将检测框的中心点坐标和框的宽度、高度等信息作为独立的变量来对待,而事实上框的中心点和框的宽高的确存在着一定的关系,因此,使用这种损失函数会造成较大的误差,这会使检测框和真实框的位置差距较大,导致目标检测部分输出的数据误差偏大,这将会对接下来进行的目标跟踪部分造成不利的影响。因此,将对损失函数的lbox部分和网络结构进行改进和优化。
2 本文算法设计
2.1 算法整体流程
使用卷积神经网络对视频中的行人进行检测和跟踪。视频帧输入之后首先进入YOLOv3目标检测的网络,经过Darknet-53提取特征;其次,进行上采样和特征融合,再进行回归分析;再次,把得出的预测框信息输入SORT算法进行目标特征建模,匹配和跟踪;最后,输出结果。其整体流程如图2所示。
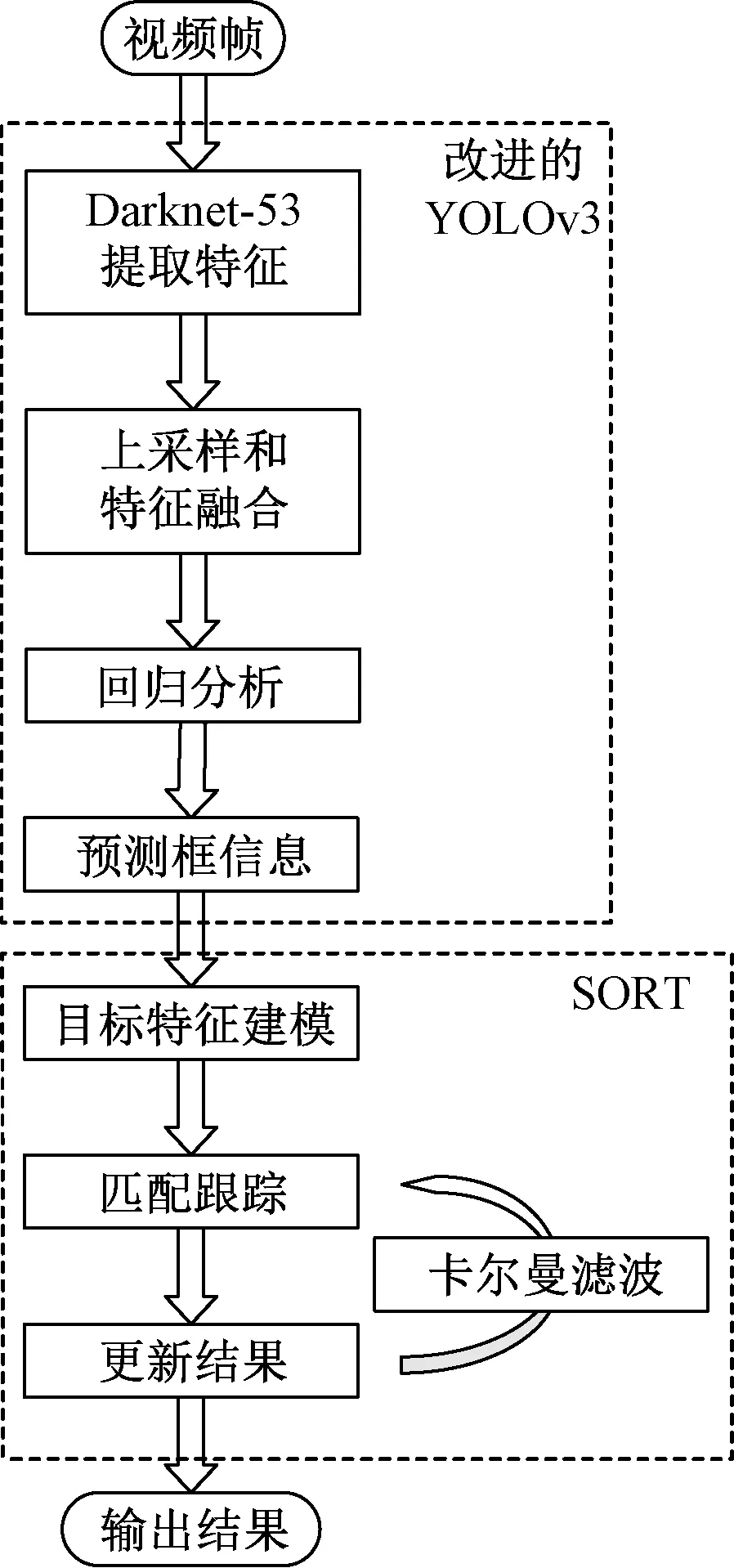
图2 算法整体流程图
2.2 YOLOv3损失函数的改进
由于MSE损失会给异常值赋予更大的权重,模型会全力减小异常值造成的误差,从而使得模型的整体表现下降,并且MSE损失没有考虑到检测框的长宽比例变化是有关联的,从而导致预测框不准确。因此,提出DPIOU损失函数来解决这个问题。
DPIOU损失函数是基于IOU[20]损失函数改进而来。IOU损失函数的定义非常简单,即1与预测框A和真实框B之间交并比的差值,公式为
LIOU=1-IOU(A,B)
(2)
式(2)中:
(3)
IOU损失函数虽然简单易于计算,但是它只在检测边框重叠的时候才管用,在边框没有重叠情况下,它就不会提供滑动梯度,从而导致网络无法迭代下去。因此,需要在IOU损失的基础上加一个惩罚项来解决这个问题,这个惩罚项可以最小化两个检测框中心点的标准化距离,同时,DPIOU考虑到检测框长宽比之间的联系,在以上基础上再加上一个惩罚项,这两个惩罚项可以加速损失的收敛过程。这就是DPIOU损失函数,其具体公式为
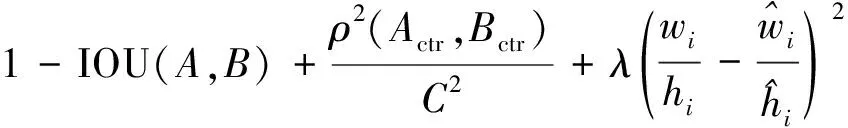
(4)
式(4)中:Actr、Bctr分别为预测框与真实框的中心点坐标;C为预测框A和真实框B的最小包围框的对角线长度;ρ为欧式距离的计算方程。
其示意图如图3所示。
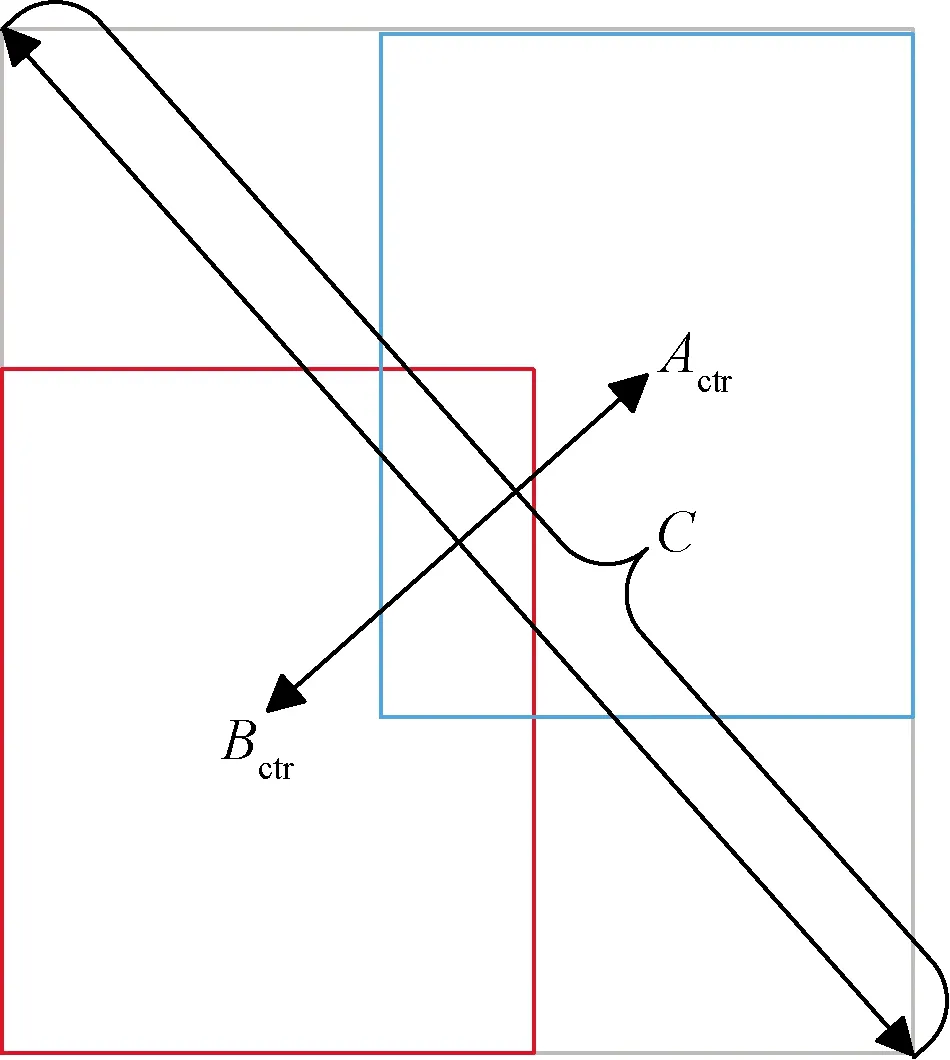
图3 DPIOU损失函数示意图
结合式(4)和图3可知,预测框A与真实框B的距离越远,LDPIOU的值就会越大,反之,LDPIOU的值则将越接近0。增加了两个损失项之后,就可以大大地加快损失收敛的过程,这对于之后的视频文件检测速度有很大的提升。
对于置信度损失项和类别损失项,保留不变。改进后的损失函数最终形式为
loss=LDPIOU+lobj+lcls
(5)
改进之后的损失函数可以反映预测检测框与真实检测框的检测效果,具有良好的尺度不变性。对于包含两个框在水平方向和垂直方向上这种情况,DPIOU损失可以加快回归速度,使得整体损失的收敛速度提升。
2.3 YOLOv3网络结构的改进
如图1所示,YOLOv3网络中的Darknet-53采用了He等[21]于2015年提出的RestNet的结构。RestNet不用学习整个的输出,而是学习上一个网络输出的残差,从而解决了增加网络深度带来的梯度消失和梯度爆炸的问题。RestNet结构如图4所示。
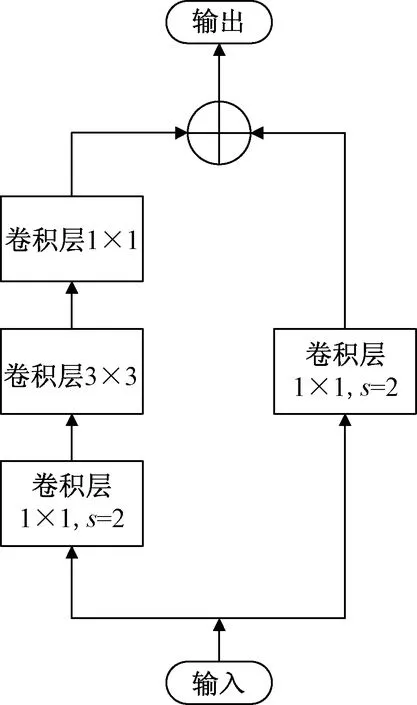
图4 RestNet结构图
ResNet将下采样操作放在步长为2的1×1卷积层,理论上将会造成3/4的特征信息丢失[22],因此,对ResNet的结构进行改进。
首先,将下采样的操作从第一个1×1的卷积层换成第二个3×3的卷积层,因其卷积核尺寸够大,即使将步长设置为2,也不会丢失特征信息。接着,将其右边支路当中步长为2的1×1卷积层换成步长为1的卷积层,并在这层前面添加一个池化层来做下采样,加入池化层进行均值操作之后,会减少重要特征信息的丢失,使其丢失的信息为冗余信息。改进后的网络结构如图5所示。
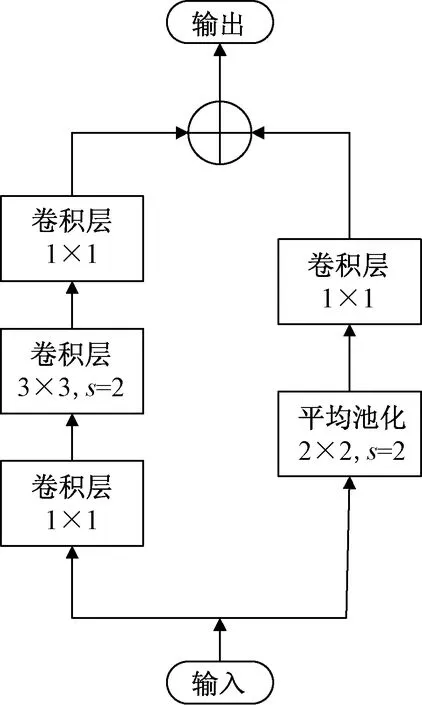
图5 改进RestNet结构图
2.4 SORT算法
在目标跟踪之前,本文已经使用改进的YOLOv3算法完成了目标检测的工作,接着便可以引入SORT算法完成目标跟踪的任务。首先,对目标的特征进行建模,其模型公式为
(6)
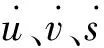
当首帧的特征输入时,以这一帧为目标进行初始化并且创建跟踪器,每个目标标注一个特定的编号,后面帧的数据进来之后,先经过卡尔曼滤波器得到前一帧产生的预测框,求得跟踪器所有的预测框与本帧检测到的预测框的交并比,再使用匈牙利算法得到交并比最大的匹配值,并去掉小于阈值的匹配对,从而实现对目标检测框的跟踪。
3 实验结果分析
3.1 不同网络效果对比实验分析
为了验证改进的YOLOv3网络结合SORT算法在室外街道场景中对行人准确检测和跟踪的可行性,使用它对一处商业街道的行人进行检测跟踪,同时与Faster R-CNN+SORT、SSD+SORT和传统的YOLOv3+SORT做对比,其运行结果图如图6所示。

图6 不同网络模型对行人检测跟踪结果
图6(a)中,Faster R-CNN+SORT存在将橱柜中模特误检的情况;图6(b)中,SSD+SORT的检测框的准确度过差;图6(c)中,YOLOv3+SORT有部分行人的检测框远大于真实框,而图6(d)改进的YOLOv3+SORT可以精确地对街道上的行人进行检测跟踪,足以证实改进网络对街道行人检测追踪的可行性。
3.2 实验结果定量评估
改进的YOLOv3网络理论上会减少重要特征信息的丢失,加快网络收敛速度,减小收敛值,提升网络的整体性能。因此,将对改进前后两种网络的性能做出评估,实验使用谷歌图片库的4 000张图片,使用LabelImag将其按照VOC2007的格式进行标注,其中70%作为训练集,30%作为测试集,总计迭代了4 000次。实验的硬件配置为一块2060的显卡,显存为6 GB,CPU为Intel Core i5-9600KF@3.70 GHz。其loss变化图如图7所示。
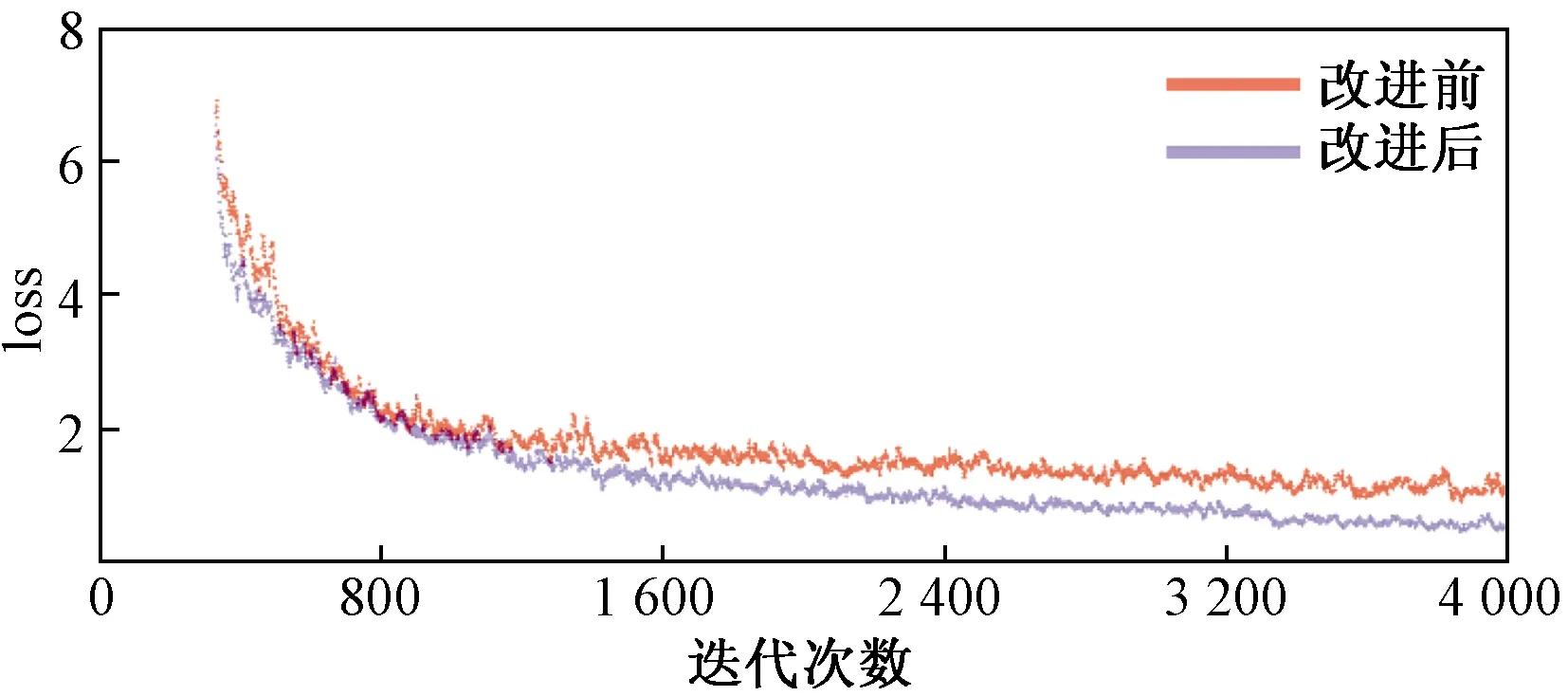
图7 改进前后网络loss曲线
图7中改进后的网络收敛速度更快,网络的整体运行速度变快;最终的收敛值相对较小,目标检测的精确度相对较高。
由于目标是对行人的检测以及跟踪,SORT算法对行人跟踪所需的数据完全由目标检测部分得出,因此,目标检测的准确率尤为重要。平均准确率(average precision,AP)可以反映整个网络的检测性能,因此本文使用AP来衡量检测结果。同时,对比了多种网络在不同损失函数下网络的效果,以检验损失函数的改进对网络检测性能的影响。实验结果如表1所示,其中,AP表示使用不同交并比值作为检测阈值得出的平均准确率的均值,AP75表示使用交并比大于等于75%的值作为检测阈值得出的平均准确率。从表1可以看出,改进的损失函数可以提升网络的性能,改进后网络的平均准确率比原始网络高出4.85%。
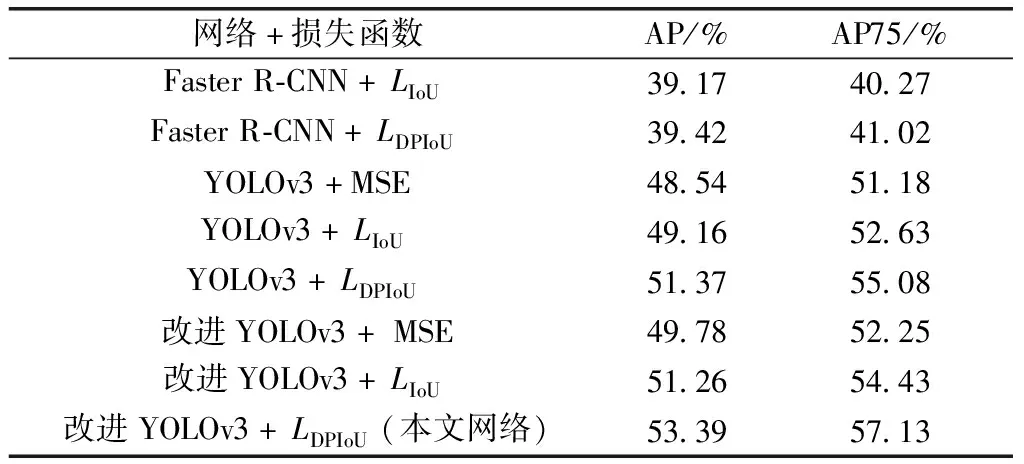
表1 不同损失函数对比实验结果
使用多目标跟踪准确度(multiple object tracking accuracy,MOTA)和多目标跟踪精确度(multiple object tracking precision,MOTP)这两个指标来对改进前后网络的行人跟踪性能进行比较。MOTA考虑到目标个数以及相关目标的属性准确度,用于统计目标跟踪当中的误差累计[23],其公式为
(7)
式(7)中:mt为缺失数,也称为漏检数;fpt为误判数;mmet为误配数;Gt为目标的真实数量。
MOTP是目标位置误差的评估指标,用于量化目标位置确定的精确程度,其公式为
(8)
改进前后的跟踪性能如表2所示,改进后的跟踪准确度相比改进前上升了3.4%,精确度的指标也有提升,同时通过实验得出整体网络的最高速度为14.39 FPS。

表2 改进前后跟踪性能对比实验结果
3.3 实验结果定性比较
使用改进前后的网络对同一个街道场景的行人进行检测和跟踪,从目标检测的准确率,检测框的精确度,行人跟踪的效果等方面来进行比较。由图8的对比实验结果可以看出,改进后的网络检测准确率高,检测框更加贴合目标行人,在行人重叠交错之后,仍然可以准确地标出每个行人的编号,而改进前的网络在跟踪过程中发生了编号互换、转移的现象。

图8 街道行人检测跟踪结果
4 结论
提出改进YOLOv3结合SORT算法在室外街道的场景下对行人进行检测和跟踪,增加了检测跟踪的准确率。首先,引入DPIOU损失函数,提高了检测的精确度。其次,对网络结构中的残差网络部分置换了下采样的位置,增加了池化层,减少了特征信息的丢失。这些改进使本文网络兼顾了准确率和检测速度,极大程度地提升了检测框的精度,便于行人跟踪的实施,最终实现了比较稳定的室外街道行人的实时检测跟踪。本文网络可应用于城市商业街道、人行道、校园道路等场景,使用其得出的人员流动数据,帮助公共交通和安全管理。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
意林(2021年5期)2021-04-18
健康体检与管理(2021年10期)2021-01-03
扬子江(2019年1期)2019-03-08
