
基于卷积神经网络的灾难场景图像分类
2021-07-19 09:58王改华周志刚万溪洲
科学技术与工程 2021年17期
王改华,郭 钊,周志刚,万溪洲,郑 旭
(湖北工业大学电气与电子工程学院,武汉 430068)
随着互联网技术的迅速发展,灾难场景图像越来越多出现在人们视野中,为了方便人类查看自己所需的灾难场景图片,因此,图像分类变得愈发重要。随着卷积神经网络取得了一定的突破,图像分类技术的应用越来越广泛,如图像搜索,目标检测[1-3]和目标定位等[4-6]。
充分提取图像特征对提高图像分类精度有巨大的作用。刘琼等[7]提出了一种结合无监督和有监督学习的网络权值预训练算法,融合零成分分析白化与深度信念网络预学习得到的特征,对卷积神经网络权值进行初始化,通过卷积、池化等操作,对训练样本进行特征提取并使用全连接网络对特征进行分类。王改华等[8]提出一种采用无监督学习算法与卷积构造的图像分类模型,从输入无标签图像中随机抽取大小相同的图像块构成数据集,进行预处理,将预处理后的图像块通过两次K-means聚类算法提取字典,并采用离散卷积操作提取最终图像特征,采用Softmax分类器对提取的图像特征进行分类。狄岚等[9]提出一种道路交通标识识别算法,通过色彩增强、图像分割、特征提取、数据增强和归一化等批量预处理操作,形成一个完整的数据集,结合Squeeze-and-Excitation思想和残差网络结构,充分训练出MRESE(my residual-squeeze and excitation)卷积神经网络模型对图像进行分类。史文旭[10]提出了一种基于卷积神经网络(convolutional neural network,CNN)的多尺度方法结合反卷积网络的特征提取算法并对腺癌病理图像进行分类,利用反卷积操作实现不同尺度特征的融合,然后利用Inception结构不同尺度卷积核提取多尺度特征,最后通过Softmax方法对图像进行分类。王雨滢等[11]提出一种深度学习和支持向量机相结合的图像分类模型,提取训练集的图像特征,通过使用训练集图片的深度特征来训练SVM分类器,并且在测试集图片上实现分类测试。
1998年,Lecun等[12]提出用一个可训练的分类器对这些提取到的特征进行分类。标准的全连接多层网络就相当于分类器,并且该方案尽可能多地依赖特征提取器本身的学习。2012年,Krizhevsky等[13]提出使用非饱和神经元和能高效进行卷积运算的图形处理器(graphics processing unit,GPU)实现,加快训练速度。2014年,Simonyan等[14]提出增加网络的深度能够在一定程度上影响网络最终的性能。2014年Szegedy等[15]提出了一种新的结构“inception module”,网络深度(depth)的增加。拥有更深的网络结构和更少的参数和计算量。2015年,He等[16]提出在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。Ma等[17]提出了一种基于主动学习的采样策略。这种采样策略有两个方面的新颖之处:一是采用信息熵来评价分割对象的分类不确定性,将所有分割对象的熵为零或非零,并将后者按熵的递减排列;二是在评价分类不确定性对分类性能影响的基础上,开发了一种主动学习技术。通过随机抽样获取一定比例的零熵对象作为主动学习的种子训练样本,将非零熵对象作为主动学习的候选集,并采用熵查询逐袋算法进行主动学习,以获取最优训练样本。Zhang等[18]提出了一个新的框架,称为SRAD-CNN的SAR图像分类。应用了一个根据斑点减少各向异性扩散滤波器的先验知识构建的滤波层。滤波层不仅可以减少斑点,还可以增强边界。控制滤波程度的主要参数可以通过反向传播算法进行自适应优化。经过滤波层自适应滤波的图像斑点再放入CNN层中分配标签。Lü等[19]提出了一种基于CNN的深度学习方法,结合通过能量驱动采样提取的超级像素进行VHRI分类。该方法主要包括3个步骤:首先,基于地理对象的图像分析的概念,利用基于SEEDS的超级像素分割方法将图像分割成同质的超级像素,从而减少处理单元的数量;其次,从图像中提取训练数据和测试数据,并在超像素级别上对CNN进行各种尺度的协整;最后将训练数据输入到CNN的参数训练中,从VHRI中提取抽象的深度特征。利用这些提取的深度特征,对单尺度和多尺度的两个VHRI数据集进行分类。Zhi等[20]提出了一种密集卷积神经网络(DCNN),通过促进特征重用,加强特征和梯度的流动,提高分类性能。在网络中,特征主要通过设计的密集块进行学习,每层产生的特征图可以通过连通模式直接连接到后续各层。Law等[21]提出一种卷积神经网络街面网(street-frontage-net,SFN),它可以成功地将街面质量评估为活跃的(包含门窗的街面)或空白的(包含墙壁、围墙和车库的街面)。
Attention机制最早是应用于图像领域的。2014年Mnih等[22]提出在循环神经网络(recurrent neural network,RNN)模型上使用了Attention机制来进行图像分类。随后Bahdanau等[23]提出使用类似Attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将Attention机制应用到自然语言处理(natural language processing,NLP)领域中。2017年Vaswani等[24]提出使用自注意力(self-attention)机制来学习文本表示。2018年Chen等[25]提出是用传统的GAN网络做Object Transfiguration 时一般有两个步骤:检测感兴趣的目标;将检测的目标转换到另一个域。其中Attention network 用于提供稀疏的注意力图像(attention maps),物体变换(object transfiguration network)做域转换,之后再将两个网络的输出进行合成得到最终的output。2019年,Nathani等[26]提出了一种用于关系预测的生成式基于注意力的图嵌入方法。对于节点分类,图注意力网络表现出能关注于图中最相关的部分,给定一个知识图谱和关系预测任务,该模型通过将注意力指引到给定节点的多跳邻居的实体和关系特征,生成和扩展注意力机制。2019年,Zhou等[27]提出将语义分割结果作为自我关注线索进行探索,以显著提高行人检测性能。提出的行人自我关注机制可以有效识别行人区域和抑制背景。2019年,Chaudhari等[28]提出注意力模型旨在通过允许解码器访问整个编码的输入序列{h1,h2,…,hT} 来减轻这些挑战。其核心思想是在输入序列上引入注意力权重α,以优先考虑存在相关信息的位置集,以生成下一个输出。2020年,Zhao等[29]提出将传统卷积解耦,并将特征聚集理解成局部区域内的像素特征加权求和。利用注意力机制自动生成这个权值,从而增加所考虑的局部区域大小,又不增加参数目标,同时允许特征聚合适应每个通道。2020年,Qiao等[30]提出了一种端到端的层次注意抠图网络(HAttMatting),实现了这种层次结构的聚合。2020年,Kitaev等[31]提出将传统的多头注意力机制改为基于局部敏感哈希的注意力机制,以及将RevNet的思想加入到Transformer里面来减少参数对内存的占用,另外还有因子分解机支持的神经网络(factorisation-machine supported neural networks,FNN)机制用来减少在全连接层的内存占用量。CNN可对特征数据进行主动学习,具有较好的泛化能力,在图像分类领域得到了广泛的使用。
为了提高灾难场景图片的识别和分类效果,现提出一种基于多分辨率和残差注意力机制的图像分类模型。首先对灾难场景数据集进行划分,随机地将其分为训练集和测试集,利用训练集图像改进卷积神经网络,对其参数进行反复调试,最后通过测试集对其进行分类测试,同时利用其他分类模型对相同的图像数据集进行分类测试,通过分类测试精度对比,说明所提出的方法的可行性和有效性。
1 相关工作
1.1 注意力机制
注意力机制是从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。基于注意力机制的卷积神经网络可以与前馈网络体系结构结合在一个端到端的网络体系中。注意力网络是通过叠加注意力模块来建立的,这些模块产生注意力感知特征,不同模块的注意感知特性是自适应的。注意力机制结构图如图1所示。
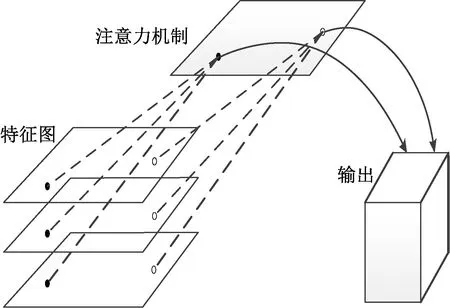
图1 注意力机制结构示意图
1.2 残差注意力机制
残差注意力网络模型如图2所示。结构首先通过一系列卷积和池化,逐渐提取高层特征并增大模型的感受野,高层特征中所激活的像素能够反映注意力所在的区域,再通过相同数量的上采样将特征图的尺寸放大到与原始输入一样大,这样就将注意力机制的区域对应到输入的每一个像素上。
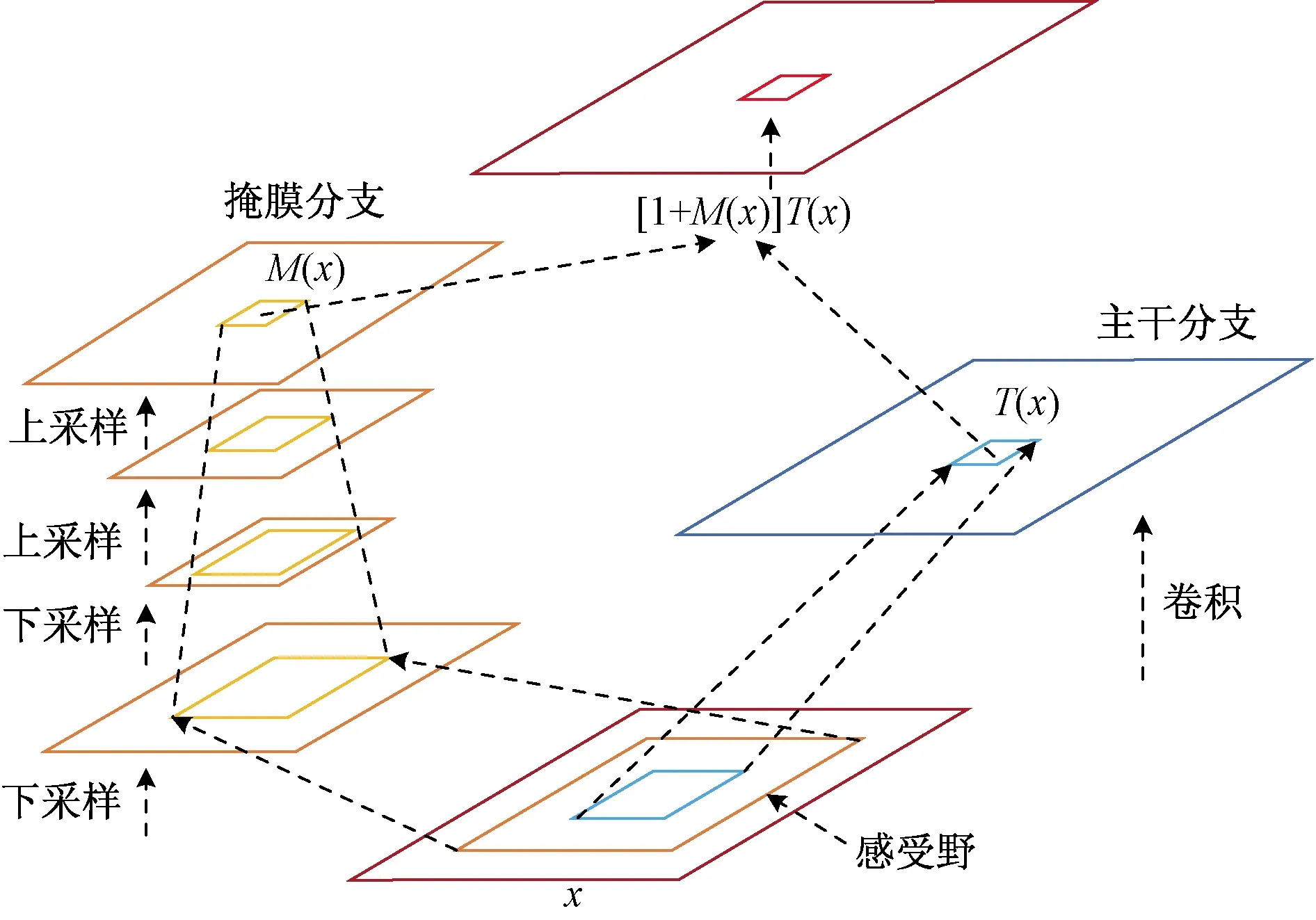
x为输入;M(x)为注意力图;T(x)为输出特征图
在左边的掩膜分支,先下采样,让网络把较为重要的信息提取出来,然后再用上采样把输出和输入大小变为一致,得到注意力图M(x)。而在右边的主干分支,最终输出也是一个特征图T(x)。
掩膜分支输出的注意力图中的每一个像素值相当于原始特征图上每一个像素值的权重,它会增强有意义的特征,抑制无意义的信息。因此,将掩膜分支与主干分支输出的特征图进行点乘,就得到一个注意机制网络模型输出,其表达式为
Hi,c(x)=[1+Mi,c(x)]Ti,c(x)
(1)
式(1)中:Hi,c(x)为注意力机制网络模型的输出;Mi,c(x)为第i个像素点的位置,第c个通道的位置对应掩膜分支特征图的输出;Ti,c(x)为第i个像素点的位置,第c个通道的位置对应主干分支特征图的输出;其中Mi,c(x)的取值范围在0~1,如果Mi,c(x)的值接近于0,那么Hi,c(x)的值会近似等于Ti,c(x),这样从理论上讲,有Attention Module的效果肯定不会差过没有Attention Module的效果。Mi,c(x)是关键,通过添加这个掩膜分支,模型可以自适应地提高重要的特征同时忽视来自主干分支的噪声。
2 基于卷积神经网络的灾难场景图像分类
2.1 基于残差注意力机制DenseNet网络模型
选择DenseNet网络为基础网络,在其基础上提出了一种基于残差注意力机制DenseNet网络模型用于灾难场景图像分类。将残差注意力机制注意力模块(Attention Module)同时加到DenseNet网络模型稠密块1和过渡层1,稠密块2和过渡层2,稠密块3和过渡层3之间。改进的DenseNet网络模型包含了输入层、卷积层、池化层、稠密块、注意力模块、过渡层和分类层。DenseNet-attention网络模型如图3所示。

图3 DenseNet-attention网络模型
输入层将测试图片标准化为3×224×224,即指定图片大小为224×2 243通道。依次经过卷积、池化、稠密块1、注意力模块、过渡层1、稠密块2、注意力模块、过渡层2、稠密块3、注意力模块、过渡层3、稠密块4和softmax输出。经过实验测试,将残差注意力机制注意力模块分别同时加到DenseNet网络模型中稠密块1和过渡层1,稠密块2和过渡层2,稠密块3和过渡层3之间的分类效果最好。
2.2 基于多分辨率DenseNet网络模型
选择DenseNet网络为基础网络,在其基础上提出了一种基于多分辨率DenseNet网络模型用于灾难场景图像分类。在DenseNet网络稠密块中增加多分辨率模块,改变瓶颈层的结构。在瓶颈层中添加多分辨率因子,使瓶颈层的层数不再固定不变,可以通过多分辨因子来控制瓶颈层层数。这里的多分辨率因子设为5,增长率设为24。即稠密块中一共有5个瓶颈层,其中第一个瓶颈层的特征图个数为24,后面的瓶颈层的特征图以24个特征图逐个增加,当到第5个瓶颈层时,自动使特征图个数变为24。由于增长率的存在,每个瓶颈层的输出特征图依次递增。DenseNet-multiresolution网络结构如表1所示。

表1 DenseNet-multiresolution网络结构
2.3 基于残差注意力机制和多分辨率DenseNet网络模型
选择DenseNet网络为基础网络,在其基础上提出了一种基于残差注意力机制和多分辨率DenseNet网络模型用于灾难场景图像分类。将残差注意力机制注意力模块同时加到DenseNet网络模型稠密块1和过渡层1,稠密块2和过渡层2,稠密块3和过渡层3之间。在DenseNet网络稠密块中增加多分辨率模块,改变瓶颈层的结构。多分辨率因子设为5,增长率设为24。即稠密块中一共有5个瓶颈层,其中第一个瓶颈层的特征图个数为24,后面的瓶颈层的特征图以24个特征图逐个增加,当到第5个瓶颈层时,自动使特征图个数变为24。DenseNet-attention-multiresolution网络模型如表2所示。

表2 DenseNet-attention-multiresolution网络结构
3 实验结果与分析
3.1 实验硬软件环境
本文实验是在硬件环境为Windows10、64位操作系统、英特尔Xeon(至强)E5-2683 v3 @ 2.00 GHz处理器、运行内存32 G计算机上进行的,DenseNet网络在Tensorflow框架下完成模型的搭建。为了增加对比实验,加入了Xception和MobileNetV2网络。Xception和MobileNetV2网络在Keras框架下完成模型的搭建。数据集都采用Disaster_Data_Scenes数据集。其中残差注意力机制用于DenseNet、Xception和MobileNetV2网络模型,多分辨率只用于DenseNet网络模型中。
3.2 数据集的介绍
Disaster_Data_Scenes数据集涉及3种不同灾害类型的灾后场景。数据库包含1 763张RGB彩色图像,包括3种不同的灾难类型: 756幅图像是地震图像(0_Ear地震);566图像为海啸图像(1_Tsu海啸),其余441幅图像为龙卷风图像(2_Tor龙卷风)。具体来说,地震数据来自2010年的海地地震和2011年新西兰新克赖斯特彻奇地震;海啸数据来自2004年日本东北海啸和2004年印度尼西亚海啸;龙卷风数据是来自2013年美国俄克拉何马州的摩尔龙卷风。3种不同灾难场景数据集部分图片如图4所示。

图4 灾难场景数据集部分图片
所有数据库中有15%的图片被随机选取作为测试集。因此,在训练阶段随机选取了1 500张图片;其余263张图像作为测试数据。
3.3 实验结果及分析
由于这3类输入图片尺寸大小不一,相差较大。首先对图像数据集进行预处理,在程序中用resize函数把图片大小统一缩小为224×224大小尺寸。把所有的图片分批次投入到模型中进行训练,设定每次输入模型训练图片数量为32。迭代轮数设置800。采用Tensorflow和Keras中的可视化工具Tensorboard,将模型训练和测试保存的数据用Tensorboard可视化工具打开。在Anaconda prompt窗口输入tensorboard--logdir=“网络测试保存的loss路径”,“改进网络测试保存的loss路径”。回车后,可以得到一个网址,然后用Google浏览器打开。DenseNet网络和改进的DenseNet网络,Xception和Xception-attention、MobileNetV2和MobileNetV2-attention网络在灾难场景数据集测试集中accuracy变化曲线图如图5和图6所示。

图5 DenseNet和改进的DenseNet网络模型精度变化曲线图

图6 Xception、改进的Xception、MobileNetV2和改进MobileNetV2网络模型精度变化曲线图
从图5可以看出,迭代次数从0~400轮时,DenseNet和改进的DenseNet测试精度上升较快,迭代次数从400~800轮时,测试精度上升较慢。最终DenseNet网络测试精度为57.41%,DenseNet-attention网络测试精度为66.54%,DenseNet-attention-multiresolution网络测试精度为67.68%,DenseNet-multiresolution网络测试精度为75.29%。DenseNet-attention网络比DenseNet网络测试精度提高了9.13%,DenseNet-attention-multiresolution网络比DenseNet网络测试精度提高了10.27%,DenseNet-multiresolution网络比DenseNet网络测试精度提高了17.88%。改进的DenseNet网络和原网络对比实验说明了残差注意力机制和多分辨率对网络分类效果有一定的提升。从图6可以看出,迭代次数从0~100轮时,Xception和Xception-attention测试精度上升较快,迭代次数从100~800轮时,测试精度上升缓慢。最终,Xception网络测试精度为76.05%,Xception-attention网络测试精度为80.61%。改进的Xception网络测试精度提升了4.56%。迭代次数从0~150轮时,MobileNetV2和MobileNetV2-attention测试精度增长较快,迭代次数从150~800轮时,测试精度变化较慢。最终MobileNetV2网络测试精度为71.86%,MobileNetV2-attention网络测试精度为74.90%。改进的MobileNetV2网络测试精度较原网络精度提高了3.04%。通过改进的Xception和改进的MobileNetV2网络和原网络进行实验对比发现,残差注意力机制对灾难场景图像分类效果有一定的提升。通过上述实验,说明了残差注意力机制和多分辨率对网络模型分类的效果有一定的提升。分类准确率对比如表3所示。

表3 分类准确度对比
4 结论
在理解DenseNet,Xception,MobileNetV2网络结构的基础上,提出了一种改进的DenseNet、Xception和MobileNetV2网络结构。实验结果表明,所提出改进的网络模型比原来网络模型在灾难场景数据集上分类测试精度有一定的提升。改进的Xception和MobileNetV2网络在灾难场景数据库上进行的图像分类实验测试,精度分别提升了4.56%和3.04%。其中DenseNet-attention、DenseNet-multiresolution和DenseNet-attention-multiresolution比DenseNet网络模型精度分别提升9.13%、17.88%和10.27%。通过模型测试比较,说明了所提出的方法的效果较好。应用于灾难场景图像分类有一定前景。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年7期)2016-07-10
华人时刊(2016年16期)2016-04-05
职业·中旬(2009年12期)2009-06-01
