
基于XLNet的情感分析模型
2021-07-19 09:58梁淑蓉谢晓兰陈基漓
科学技术与工程 2021年17期
梁淑蓉,谢晓兰,2*,陈基漓,2,许 可
(1.桂林理工大学信息科学与工程学院, 桂林 514004;2.广西嵌入式技术与智能系统重点实验室, 桂林 514004)
随着互联网时代发展起来的各种消费、娱乐和工作平台,不仅给人们带来便利生活,也给意见反馈和信息交流提供媒介,人们更愿意通过网络平台反馈自己对事物的喜好程度。情感分析是对主观文本的情感倾向性分析,可获取人们对事物的情感倾向,也给决策者规划提供参考。
情感分析的发展主要经过3个阶段:基于情感词典方法阶段、基于机器学习方法阶段和基于深度学习方法阶段[1]。情感词典是最早用于情感分析的手段,但人工构建的情感词典存在情感词不完整、在不同的语境情况下无法识别情感倾向以及不能及时收录新词等问题。第二阶段在机器学习的基础上,根据文本特征的提取进行情感分类,相较于情感词典的方法能减少人工标注的劳动力,但分类器的优劣取决于特征提取的效果,导致其泛化程度不高。而深度学习的方法通过对人的神经系统的模拟来构建网络模型,比上述两者都更具优势。近年来,随着计算机生产力的提高,云计算技术、大数据等技术以及先进技术的不断发展,使得深度学习方法被广泛应用于自然语言处理(natural language processing,NLP)领域,主要体现在三种主流预训练模型手段:
第一种是神经网络语言模型Word Embedding(词嵌入),先通过无监督学习语料得到的词向量,再应用于下游任务,Word2Vec模型和GloVe模型都是Word Embedding的代表,但该方法未考虑上下文语义。对此,文献[2]在Word2Vec基础上引入BILSTM以及文献[3]在GloVe基础上引入LSTM,用来获取文本的上下文信息,将提取到的词向量输入分类器进行情感分析,但分类器效果会依赖于特征提取能力的优劣,泛化能力不高。
第二种手段是采用RNN及其扩展方法,例如LSTM、GRU和Seq2Seq等,由于考虑了上下文语义,能很好地应对NLP中机器翻译[4]、阅读理解[5]和情感分析[6]等相关问题,但缺点是需要大量标注数据和监督学习。文献[7]提出一种GRU和胶囊特征融合的情感分析模型,相对基于CNN方法的模型,准确率得到了提高。文献[8]将BILSTM和CNN相结合,该解决方案使用迁移学习为情感分类的特定任务嵌入微调语言模型,从而能够捕获上下文语义。文献[9]基于CNN和Bi-GRU网络模型,引入情感积分来更好提取影响句子情感极性的特征,再加入注意力层使得模型相对比其他相关模型获得更高的准确率。上述改进方式都是希望引入新机制的优势优化模型性能,但未从本质上解决模型缺陷。
第三种手段基于无监督学习,并充分考虑上下文语义,是目前公认最有效的模型训练手段。以此衍生的模型有ELMo[10]、OpenAI GPT[11]、Bert[12]和XLNet[13]。ELMo的本质是多层双向的LSTM,但ELMo通过无监督学习语料得到上下文相关的特征不能适应特定任务。OpenAI GPT则是对ELMo的改进,采用Transformer替代ELMo的LSTM部分,同时针对不同任务进行Fine-Tuning,但在编码时不能看到后文的语义。2018年Google提出的Bert模型基于Encoder-Decoder架构和双向Transformer编码,同时采用masked语言模型和上下文语句预测机制,BERT的出现开启了NLP新时代,在情感分析领域也取得不错成果,但也仍存在一定的缺陷,如模型上下游任务不一致而导致泛化能力低,每个预测词之间相互独立,以及生成任务能力不高。次年,谷歌大脑提出了XLNet模型,采用自回归语言模型,引入置换语言模型解决AR模型不能双向建模的缺陷,也增加了factorization order和Two-stream attention机制,一定程度上解决了BERT的缺陷,在许多公认的数据集任务中表现也十分优异。
当前,基于BERT和XLNet两种模型的优化方法在情感分析上的应用成为研究人员关注的焦点,针对BERT的改进,文献[14]基于BERT模型结合BILSTM分析微博评论的情感倾向,提出的方法F1值有较高结果,但由于BERT参数过大,训练难度大的问题,使用的是发布训练好的模型。针对以往模型不能解决长文本存在的冗余和噪声的问题,文献[15]在文本筛选网络中采用LSTM和注意力机制相结合方式,来筛选粗粒度相关内容。再与细粒度内容组合并输入BERT模型中,该方法一定程度提升了方面级情感分析任务性能。文献[16]基于BERT模型,引入BILSTM层和CRF层来扩展原模型,可以根据上下文来判断那些情感倾向不明显文本的情感倾向。文献[17]针对BERT模型不能提供上下文信息的问题,结合GBCN方法构建新模型,采用GBCN门控制机制,根据上下文感知嵌入的方法,优化BERT提取出的词向量特征。文献[18]在BERT的基础上增加BILSTM和注意力机制构成的情感分析模型,相比以往模型,准确率和召回率都得到较好的结果。可以观察到,大多数情况对BERT的改进是在模型的基础上,增加一些神经网络处理层,最后再进行微调的过程。目前针对XLNet的优化研究处于初步探索阶段,但从文献[19]可发现,基于Transformer-XL结构的XLNet模型应用于情感分析领域,其效果优于以往技术,并且训练模型所需数据减少了120倍。文献[20]提出一种基于XLNet和胶囊网络的模型,该方法通过提取文本序列的局部和空间层次关系,产生的局部特征表示经过softmax再进入下游任务,其性能优于BERT模型。文献[21]基于XLNet提出了一种CAW-XLnet-BiGRU-CRF网络框架,该框架引入XLNet模型来挖掘句子内部隐藏的信息,相比其他中文命名实体识别框架获得了较好的F1值。文献[22]针对抽取式数据集(如QuAD)类型的机器阅读理解任务,采用XLNet语言模型代替传统Glo Ve来生成词向量,实验表明在基于XLNet模型训练的词向量的基础上建立网层来进行SQuAD任务,比以往大多数模型取得更好的F1值。文献[23]针对股票评论提出了基于混合神经网络股票情感分析模型,利用XLNet语言模型做多义词表示工作,提出的模型能兼备短文本语义和语序信息提取、捕获双向语义特征以及关键特征加权的能力。可以观察出,采用XLNet预训练模型学习到的词向量比以往模型获得更多的上下文语义信息,将XLNet预训练模型的潜力充分挖掘成为研究人员目前的新工作。
因此,基于前人研究成果及优化策略,现提出XLNet-LSTM-Att情感分析优化模型,该模型通过XLNet预训练模型获取包含上下文语义信息的特征向量,利用LSTM进一步提取上下文相关特征,引入注意力机制分配权重突出特征的重要程度,再判别情感倾向性。本文模型通过在XLNet的基础上,添加新的网络层来获取更为丰富的语义信息,进而提高情感分析模型预测的准确性,优化模型性能。
1 XLNet-LSTM-Att模型
目前的自然语言处理领域大多遵循两阶段模型规则,第一阶段是上游任务预训练语言模型阶段,第二阶段是下游任务的调优阶段。XLNet-LSTM-Att模型预训练属于上游任务,该模型由3层结构组成,分别为XLNet层、LSTM层和Attention层,如图1所示。

图1 XLNet-LSTM-Att模型架构图
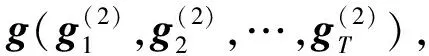

Attention层:Attention层是为了给特征向量赋予不同权值。对于从LSTM层进一步筛选出来的特征向量h(h1,h2,…,hT),通过Attention机制对保留的特征根据不同的影响程度a(at,1,at,2,…,at,T)而赋予不同权重,提高模型对重要特征的注意力。最后通过softmax激活函计算文本对应类别的向量表示,最终将向量表示执行下游情感分析任务。
1.1 XLNet层
XLNet是谷歌大脑提出的一种新的NLP预训练模型,该模型在20个任务上超越了BERT的性能,并且在18个任务上取得了最佳效果[12]。可以预估XLNet模型未来在NLP领域的发展将会有更好的表现。
1.1.1 自回归语言模型
XLNet基于对下游任务更友好的自回归语言模型。自回归语言模型具有计算高效性、建模的概率密度明确的优点。假设给长度为T的文本定序列x(x1,x2,…,xT),自回归语言模型的目标函数由式(1)来表示。
(1)
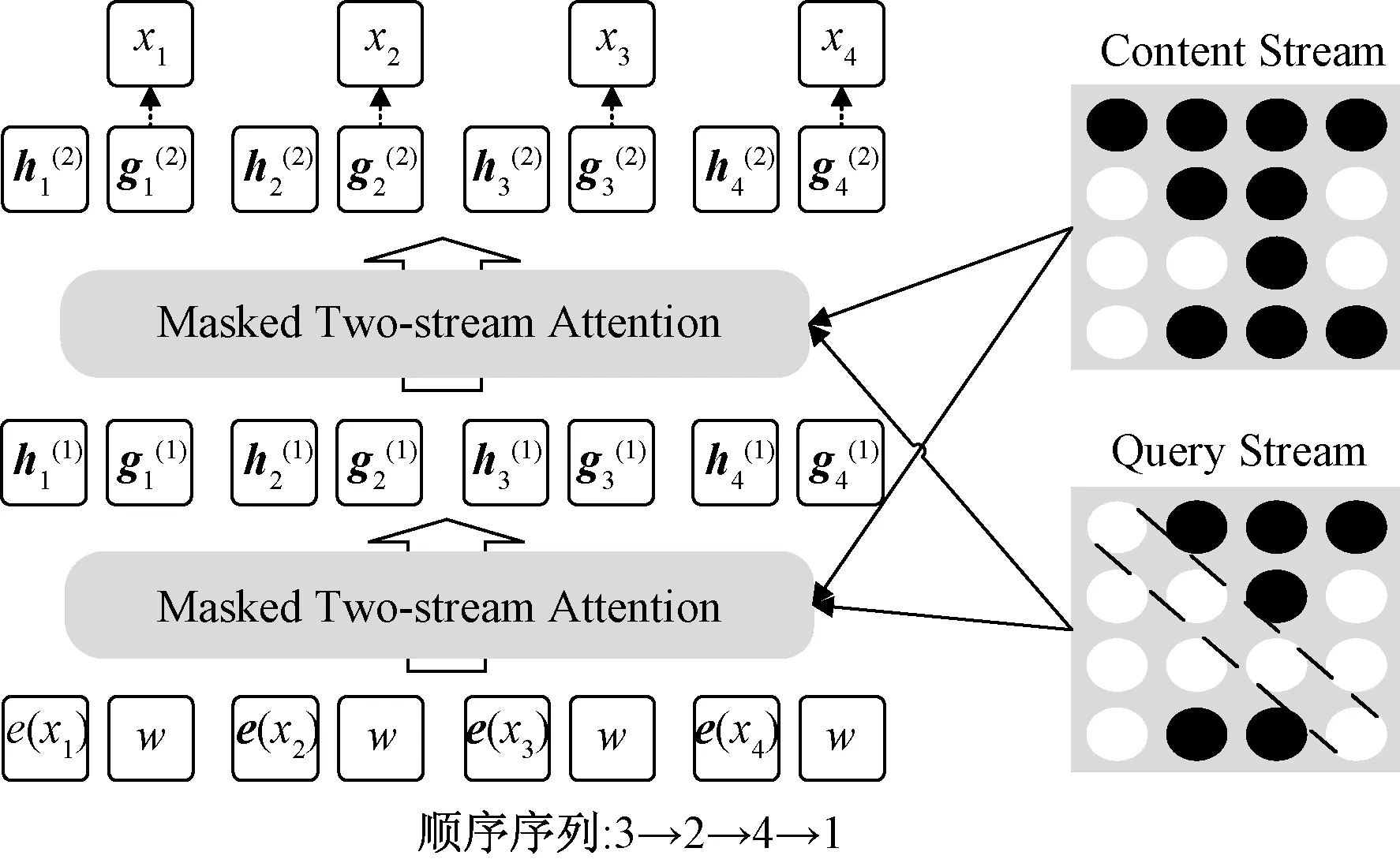
通过式(1)可知,自回归语言模型根据上文内容来预测下一个词,模型不能看到下文信息。假设需预测词为xt,x 1.1.2 Permutation Language Modeling XLNet采用了一种新型的语言建模任务PLM,通过随机排列语序来预测某个位置可能出现的词。PLM需要两个步骤来实现。 第一步:对全排列采样。首先,PLM模型需对序列顺序进行factorization order(全排列),以获得不同的语序结构,假设给定序列x(x1,x2,…,xT),其语序的排列方式为1→2→3→4,对序列顺序全排列得到3→2→4→1、2→4→3→1、1→4→2→3等顺序。根据序列因式分解产生的不同顺序来预测x3的举例如图2所示。 图2 根据序列因式分解产生的不同顺序预测x3 对于顺序3→2→4→1的情况,因x3排在首位,则只能利用其隐藏状态men进行预测;对于顺序2→4→3→1的情况,可根据x2和x4的信息来预测x3的内容,也就达到了预测过程中获取上下文信息的目的。 对于上述全排序的方法,对给定长度T的序列x,有T!种排序结果,当序列长度过大时会导致算法的复杂度过高,并且也会出现预测词位于首位的情况,显然对模型的训练无益。因此,XLNet通过式(2)对序列全排序进行采样优化,去除不合适的序列。 (2) 式(2)中:ZT为长度为T的序列全排列的集合;z为从ZT里采样的序列;zt为序列z中t位置上的值;Εz~ZT为对采样结果求期望来减小其复杂度。 第二步:Attention掩码机制。Attention掩码机制的原理是在Transformer的内部,把不需要的部分mask,不让其在预测过程中发挥作用,但从模型外部来看,序列顺序与输入时保持一致。 顺序序列3→2→4→1的掩码矩阵由图3所示,序列真实顺序没有改变,通过mask的操作达到类似随机排序的效果。在掩码矩阵中,其阴影部分为预测时能参考的信息,当预测x3时,由于其在首位无参考信息,因此掩码矩阵第三行无阴影;当预测x2时,可根据x3内容预测,因此掩码矩阵第二行的位置3有阴影,以此类推。 图3 顺序3→2→4→1掩码矩阵 PLM既解决了AR语言模型不能获取上下文语义的问题,又解决了BERT模型中mask之间相互独立的问题。 1.1.3 双流自注意机制 双流自注意(two-stream self attention)机制可解决PLM模型中,全排序序列语序随机打乱使得模型退化为词袋模型的问题。双流(two-stream)分为Content Stream和Query Stream。传统的AR语言模型对于长度为T的序列x目标函数为 (3) 式(3)中:z为从长度为T的序列x全排列随机采样序列;zt为采样序列t位置上的序号;x为预测词;e(x)为x的embedding;内容隐状态hθ(xz 由于PLM会将序列顺序打乱,需要“显式”的加入预测词在原序列中的位置信息zt,式(3)更新为 (4) 式(4)中:g(xz (5) 式(5)中:m为网络层的层数,通常在第0层将查询隐状态g(0)初始化为一个变量w,内容隐状态h(0)初始化为词的embedding,即e(x),根据上一层计算下一层数据,Q、K和V分别为query、key和value,是通过对输入数据不同权值线性变换所得矩阵。 双流自注意机制希望在预测xt时,只获取xt的位置信息,对于其他词,既要提供位置信息,又要提供内容信息。图4是顺序序列3→2→4→1预测x1时在Content Stream流和Query stream流的工作原理。 图4 双流模型 当预测x1时,模型能获得x2、x3和x4的信息,其中,在图4(a)所示的Content Stream流中,预测x1既编码了上下文的信息(位置信息和内容信息),还编码了预测词本身信息;在图4(b)的Query stream流中,预测x1编码了其上下文信息,且只编码了预测词本身的位置信息。 图5 双流自注意机制实现原理图 XLNet预训练模型更够充分学习到上下文语义信息,XLNet-LSTM-Att模型在该层将输入文本序列转化为可被机器识别的词向量表达。 LSTM是一种特殊的循环神经网络模型,该网络模型以RNN为基础,加入了遗忘单元和记忆单元来解决梯度消失和梯度爆炸的问题。LSTM由遗忘门、输入门和输出门3个门结构构成。LSTM架构如图6所示。 ht-1为上一个单元输出;ht为当前单元输出;xt为当前输入;σ为sigmod激活函数;ft为遗忘门输出;it与的乘积为输入门输出;ot为输出门输出 各个门控单元计算公式如下。 (1)遗忘门决定上一时刻单元状态中保留什么信息到当前时刻Ct。 ft=σ(Wf[ht-1,xt]+bf) (6) (2)输入门决定当前时刻网络的输入xt有多少信息输入到单元状态Ct。 it=σ(Wi[ht-1,xt]+bi) (7) (8) (9) (3)输出门控制单元状态Ct输出多少信息ht。 ot=σ(Wo[ht-1,xt]+bo) (10) ht=ottanh(Ct) (11) LSTM的实现首先经过遗忘门,确定模型丢弃上一个单元状态中的某些信息,根据ht-1和xt输出一个0~1之间的数值,决定是否舍弃该信息。然后通过输入门来确定有多少信息被添加到单元状态,其中sigmoid层决定信息更新,tanh层创建一个备选的更新信息,从而更新单元状态。最后输出门确定单元状态的输出信息,sigmoid层决定输出部分,再经tanh处理得到值与sigmoid门的输出相乘,得到最终输出内容。 LSTM通过特殊的门结构可以解决学习能力丧失的问题,避免了当预测信息与相关信息距离较大导致的信息丢失。XLNet-LSTM-Att模型在该层对XLNet层输出的序列进行深度学习,从而对特征向量做进一步特征提取。 Attention机制通过对输入序列x中每个词的重要程度赋予不同权重,使得模型能够获得更好的语义信息,提升模型效率。采用的注意力机原理实现公式为 eij=a(si-1,hj) (12) (13) (14) 式中:i为时刻;j为序列中的第j个元素;si为i时刻的隐状态;eij为一个对齐模型,用来计算i时刻受第j个元素的影响程度;hj为第j个元素的隐向量;αij为i时刻受第j个元素受关注的程度;Tx为序列的长度;ci为经权重化后输出的向量。Attention机制架构如图7所示。 图7 Attention机制架构 对情感分析来说,句子中的每个词对于其情感倾向的影响是不同的,为了扩大关键部分的影响力,需要找到并突出其关键部分,因此在LSTM层上引入Attention机制来提取文本中对于情感倾向重要的部分,采用传统的Attention机制Soft Attention来接收LSTM层的输出作为输入,根据不同特征向量的重要程度不同,对其赋予权重,最后经过softmax归一化处理得到加权的向量表示,至此上游任务完成。 XLNet-LSTM-Att模型以keras架构实现,通过Anaconda平台采用Python语言进行仿真验证。采用谭松波采集的酒店评论语料ChnSentiCorp-6000进行仿真实验,该语料是一个正负类各3 000篇的平衡语料,实验将数据集划分训练集和测试集规模如表1所示,取数据集前5 000条数据作为训练集,其余为测试集。语料示例如表2所示,其中标签0为负面评价,标签1为正面评价。 表1 数据集基本信息 表2 语料示例 仿真实验将XLNet+LSTM+ATT模型与TextCnn、LSTM、BiLSTM、BERT、XLNet 5种常见的情感分析模型作对比试验,其中各模型参数设置如表3所示。 表3 模型参数设置情况 仿真实验效果由精准率P、召回率R、F1值和AUC 4个评价指标来评判,AUC即接受者操作特性曲线(receiver operating characteristic curve, ROC)下对应的面积,通过预测概率计算,AUC值越大则分类器效果越好。精准率、召回率、F1值计算公式为 (15) (16) (17) 式中:TP为把正类评价判断为正类评价的数量;FP为把负类评价错判为正类评价的数量;FN为把正类评价错判为负类评价的数量。 图8为XLNet-LSTM-Att模型与5种其他模型进行比较的结果,分别从精准率P、召回率R和F1值评价模型优劣。 图8 6种模型测试结果 在对比实验中,提出的XLNet-LSTM-Att优化模型其精准率、召回率、F1值均优于其他模型,其中,模型与BERT模型比较,精准率提高0.48%,与XLNet模型比较,精准率提高1.34%。 表4给出的是不同预训练模型的AUC值,目前常应用于情感分析的模型在AUC值上均取得不错水平,且由于BERT和XLNet能真正识别上下文语义,其AUC值比以往模型更高,其中,提出的XLNet-LSTM-Att模型AUC值略微提高,也表明了所提出模型具有良好的性能和泛化能力。 表4 6种模型AUC值 情感分析愈来愈成为政府和企业舆论把控的手段,通过对现有的预训练手段进行分析,基于XLNet预训练模型能提取上下文语义优势,提出在该模型上增加LSTM层和Attention机制的优化模型XLNet-LSTM-Att,该模型首先利用XLNet获取包含上下文语义的特征向量,再利用LSTM网络层进一步提取上下文相关特征,最后引入Attention机制对提取出的特征分配权重,对文本进行情感倾向性分析,经过对比实验仿真,提出的模型在精确率等评价指标均有一定程度的提升。下一步工作中,对情感细粒度划分是今后的研究重点。


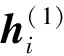
1.2 LSTM层


1.3 Attention层

2 仿真实验分析
2.1 数据集信息


2.2 相关参数设置

2.3 评价指标
2.4 结果分析


3 结论
猜你喜欢
黄河之声(2022年10期)2022-09-27北京航空航天大学学报(2022年8期)2022-08-31中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化(高中版.高二数学)(2022年4期)2022-05-25中学生数理化·高二版(2022年4期)2022-05-09当代陕西(2019年9期)2019-05-20文苑(2018年21期)2018-11-09当代贵州(2018年21期)2018-08-29长江学术(2016年4期)2016-03-11Coco薇(2015年12期)2015-12-10
