
基于马尔科夫决策过程的WSNs节点检测方法*
2021-07-15 12:08吕孟伟关业欢
传感器与微系统 2021年7期
刘 宏, 吕孟伟, 关业欢
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引 言
随着网络通信技术与传感技术的快速发展,无线传感器网络(wireless sensor networks,WSNs)[1]已广泛应用于制造业、物联网等许多领域。WSNs中的传感器节点大多部署在恶劣或无人值守的环境中,可能遭受到外界攻击或自身引起异常而致使故障,无法做出正确行为,最终导致传感器网络不能正常运行。因此,如何评价且识别网络节点状态的检测技术[2]已成为管理传感器网络的重要内容。
目前已得到国内外研究者的重视。文献[3]提出一种基于非负矩阵分解(NMF)的方法应用于WSNs节点故障检测,通过模拟节点正常行为的特征来决定是否存在偏离正常行为的特征;文献[4]发明一种基于强化学习(reinforcement learning,RL)的入侵检测方法,对检测系统模拟马尔科夫决策过程(Markov decision process,MDP)模型,采用价值迭代算法求解模型的最优检测策略,但方法针对处理网络节点入侵检测这类复杂问题时所获得最优策略的时耗较长;文献[5]提出一种WSNs故障节点检测算法,通过识别节点序列中违反排名的节点从而找到故障节点,算法可较好地应用于WSNs噪声环境和子序列估计问题。
基于此,本文提出了一种基于MDP的WSNs节点检测方法,通过运用Q-Learning优化算法求解经Option方法分层简化后的MDP模型的最优检测策略来确定出网络内各节点的状态情况,从而达到检测节点的目的。
1 基于MDP的节点检测方法
1.1 MDP模型描述
WSNs节点检测可以映射为一个强化学习问题[6],大多建模在MDP上。在此,将强化学习中的环境与智能体(Agent)分别定义为WSNs环境和网络内各节点。
定义一个由n个节点组成的WSNs马尔科夫模型,用五元组表示M={S,A,T,P,Rm},其中,S为网络内n个节点状态的有限集合,状态有正常、异常两种;A是节点可选动作的有限集合,分为分析传感网络日志、分析系统主机信息、分析自节点信息以及分析邻居节点状态;T是决策时间,节点在t时刻下进行状态跳转与动作选择;P是状态转移概率矩阵,表示节点正常、异常状态之间转换的概率;Rm是设置在MDP模型中的立即回报函数,表示节点在t时刻从状s选择动作a转移到下一状态s′后获得的立即回报值rm=Rm(s,a,s′)。具体设置回报值如下:若节点当前是异常状态,经执行动作后,状态跳转到下一状态为正常状态以及节点当前是正常状态,经执行动作后,状态跳转到正常状态,则获得立即回报值1;否则,获得立即回报值为-1。此模型满足马尔科夫性质,即状态转移概率P与立即回报Rm只取决于当前节点状态和选择的动作,与历史无关。其效果在于不需要历史先验信息,只需要记录节点状态情况。
1.2 Option分层简化
由于上述模型较为复杂且当WSNs节点规模较大后求解模型的最优检测策略时存在“维数灾难”问题[6],故采用分层强化学习[7](hierarchical reinforcement learning,HRL)手段,将模型分解为不同层次多个相对简单任务来求解,这样不仅可使MDP模型分层决策,也可有效避免“维数灾难”。
HRL中的Option方法简单实用而备受青睐[8],基本思想是把Option作为一种特殊的动作加入到MDP模型的动作集合中,通过Option把整个节点检测任务分解为若干个并发进行的子任务。这个子任务的含义是:对规模较小的网络节点进行检测。节点检测示意图如图1所示。Option由一个四元组O={Ω,πo,λ,Ro}表示。其中,Ω⊆S为Option的启动状态集合,分为活跃状态和终止状态;πo∈Ω×A→[0,1]为Option中的初始内部策略,节点依据πo选择一个动作或是另一个Option;λ:S→[0,1]为Option的终止条件;Ro是设置在Option中的立即回报函数,节点在t时刻获得Option状态跳转的立即回报值ro=Ro(s,o,s′),具体设置回报值如下:若节点当前是终止状态,经选择动作或是另一个Option后,状态跳转到下一状态为活跃状态以及节点当前是活跃状态,经选择动作或是另一个Option后状态跳转到下一状态为活跃状态,则获得立即回报值1;否则,获得立即回报值为0。
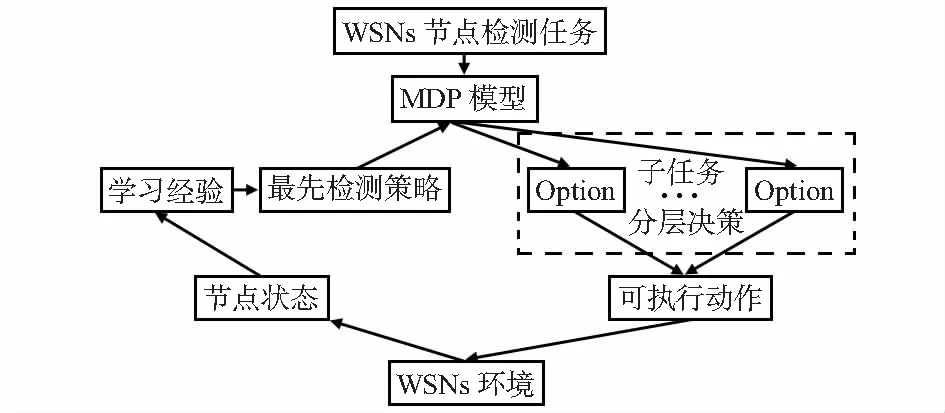
图1 WSNs节点检测示意
1.3 Q-Learning优化算法
Q-Learning[8]是目前最普遍求解MDP模型的最优策略的强化学习算法之一,基本思想是网络内各节点不断地与WSNs环境进行交互,通过贪心策略选择动作并获得立即回报,然后对MDP模型中的评估函数Q值进行迭代直至收敛,最终得到一个最优Q值矩阵表示的最优检测策略,从而获取节点的状态情况。
利用Q-Learning算法迭代状态—动作对(s,a)的Q值,公式如下
Qt+1(s,a)=(1-α)Qt(s,a)+
(1)
式中α∈[0,1]为学习率,γ∈[0,1]为折扣因子,rm为状态—动作对的立即回报值,s′和a′为下一步的状态和动作,Q(s′,a′)为下一步状态—动作对的Q值。
同样地,对Option中的状态—Option对(s,o)的Q值进行迭代,公式如下
Qt+1(s,o)=(1-α)Qt(s,o)+
(2)
式中ro为状态—Option对的立即回报值,o′为在o执行后的下一步Option,Q(s′,o′)为下一步状态—Option对的Q值。
然而,该算法在求解模型的最优检测策略上也存在一些问题:第一,在平衡“探索与利用”问题时,常用贪心策略去解决,即节点以1-ε的概率选择最大Q值的动作,并以概率ε随机选择其他动作。由于探索概率ε为固定值,势必会造成不必要的探索,影响算法运行效率;第二,Q值表示从长远的角度来看哪些动作是好的,可作为MDP模型的一种优化目标函数[6]。在节点选择动作时,通常选择那些能带来最大Q值的动作。对于式(1)中,仅对当前Q值与下一步Q值进行迭代,算法有些"目光短浅",收敛速度较慢。
本文将从这两方面进行改进,使传统Q-Learning算法进一步优化:
1)为了改变贪心策略中的固定值ε,引入模拟退火(simulated annealing,SA)技术[9]进行动态调整,温度衰减公式如下
(3)
式中T0为初始温度且为温度最大值,Tmin为温度最小值,η∈[0,1]为退火因子。
在算法进行每轮迭代中考虑Q值表的变化,将Q值的差值与动态温度值相结合来定义贪心策略的探索概率ε
(4)
式中k为迭代次数。改进后的贪心策略为:节点随机从动作集A中选取动作a′,若Q(s,a′)>Q(s,a),则接收a′为下一步动作,否则以式(4)的概率重新选择下一步动作。从式(4)中可见,通过控制温度值的下降使得探索概率ε随算法深入而逐渐减小,算法避免不必要的探索,提高了算法运行效率。
2)为了避免仅对当前Q值与下一步Q值进行迭代,算法中再增加一层学习过程。对比式(1),改进后的Q值迭代公式如下
Qt+1(s,a)=(1-α)Qt(s,a)+αrm+γmax(αQt(s′,a′)+
(1-α)Qt(s″,a″))
(5)
式中s″和a″为下两步的状态和动作,Q(s″,a″)为下两步状态-动作对的Q值。相较于式(1),尽早更新Q值加快了算法的收敛速度。
同理,在Option方法中对比式(2),迭代Q值的公式为
Qt+1(s,o)=(1-α)Qt(s,o)+αro+γmax(αQt(s′,o′)+
(1-α)Qt(s″,o″))
(6)
式中Q(s″,o″)为下两步状态—Option对的Q值。
1.4 最优检测策略
Q-Learning优化算法求解经Option分层简化后的MDP模型的最优检测策略流程描述如下:
1)初始化各参数。
2)载入状态—Option对及状态—动作对Q值表。
3)由初始πo选择Option。
4)执行Option获得回报值ro并进入Option内部。
a.确定网络节点初始状态s及相应动作a;
b.随机在A中选择动作a′,若Q(s,a′)>Q(s,a),则接收a′为下一步执行动作,否则依据式(4)概率重新选择下一动作,转至步骤(2);
c.执行下一步动作a′,获得回报值rm以及下一步状态s′;
d.依据式(5)迭代Q值,更新状态—动作对Q值表并保存数据;
e.若连续2个探索周期之后不能探索到新状态,转至步骤(5),否则依据式(3)调整温度值并且迭代次数增加一次,转至步骤(2)。
5)依据式(6)迭代Q值,更新状态—Option对Q值表并保存数据。
6)若满足Option终止条件λ(s′)=1,则转至步骤(7),否则转至步骤(2)。
7)若Q值收敛,获得最优检测策略,结束;否则转至步骤(2)。
2 仿真实验与分析
采用仿真软件NS2设置了WSNs场景并模拟攻击节点情景,通过2组实验对Option方法、Q-Learning优化算法以及本文检测方法的有效性进行评估。参数设置如表1所示。
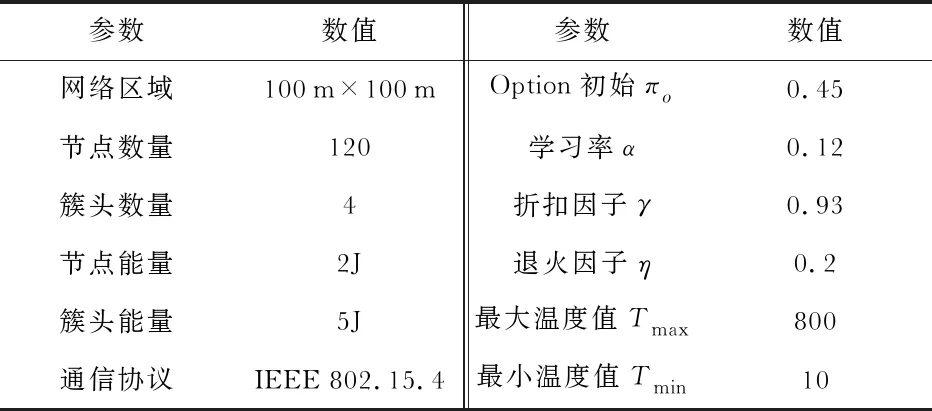
表1 参数设置
实验1为了评价传统Q-Learning算法、文献[9]Q-Learning算法以及本文Q-Learning优化算法的性能,分别考察节点探索动作次数和算法收敛情况。图2(a)为三种算法节点探索动作次数对比,从中来看,随着迭代次数增加,引入SA控制探索概率ε自适应调整后,文献[9]算法与本文算法的节点探索动作次数明显要比传统算法少。图2(b)为三种算法收敛情况对比,从中来看,随着迭代次数增加,三种算法都可收敛,传统算法大致在第58次迭代后开始收敛;文献[9]算法只针对贪心策略进行调整却忽略了Q值的迭代过程将影响算法收敛速度,大致在第49次迭代后开始收敛;本文算法在动态调整贪心策略的基础上,再增加一层对Q值的学习,效果在于当前Q值的更新参考了下两步Q值使算法具有了远视效果,收敛速度加快,大致在第42次迭代后收敛,显示了本文Q-Learning优化算法较其他两种算法使用较少的时间就使得Q值收敛。
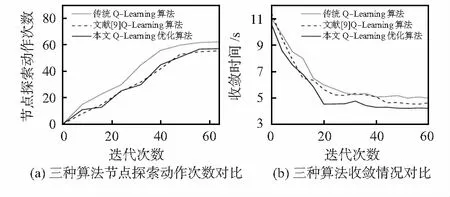
图2 实验结果
实验2设置两种对照方法来验证Option方法和Q-Learning优化算法的有效性,分别是无Option方法和传统Q-Learning方法。前者的MDP模型中不采用Option且运用Q-Learning优化算法求解最优策略;后者的MDP模型中不采用Option且运用传统Q-Learning算法求解最优策略。
为了评价文献[4]方法、本文检测方法以及两种对照方法在不同节点规模下的性能,分别考察获得最优策略的时耗以及ROC曲线。图3(a)为四种方法获得最优策略的时耗对比,可以看出,随着节点规模提升,本文检测方法获得最优策略的时耗均少于其他三种方法,其中采用Option方法简化模型后实现分层决策,提升了节点检测效率;Q-Learning优化算法避免了不必要的探索动作且快速更新Q值,提高了求解最优策略的速度;而文献[4]方法中采用价值迭代算法求解最优检测策略时,迭代过程中过度依赖状态转移概率和回报函数,使迭代值函数次数增多,所获得的最优策略的时耗增多,同时也反映出,在求解MDP模型的最优策略时,Q-Learning算法比价值迭代算法更优。本文引入观测者操作特性曲线(receiver operating characteristic curve,ROC)[3]来评价检测方法性能的优劣,具体描述为检测率与误报率之间的关系。图3(b)为四种方法ROC曲线对比,可以看出,本文检测方法的整体性能要较优于其他三种方法,即检测率较高,误报率较低。
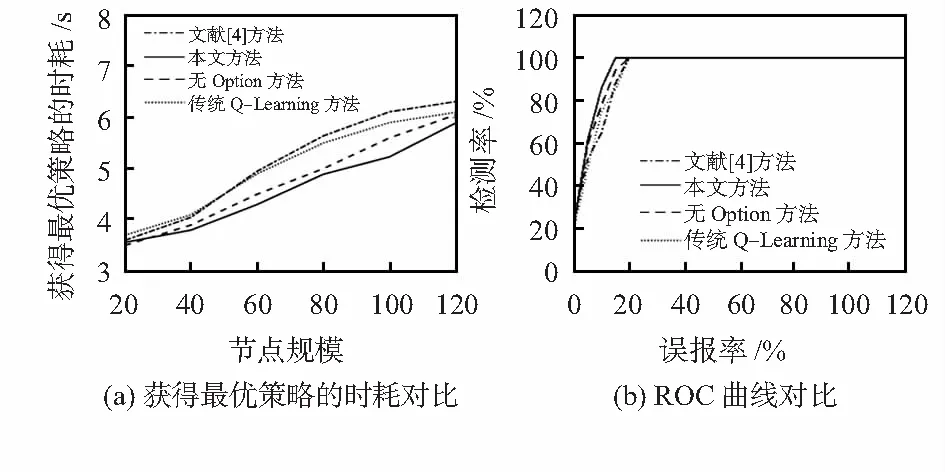
图3 四种检测方法实验结果
3 结束语
本文以WSNs节点作为研究对象,提出了一种检测方法。该方法将强化学习相关理论应用于WSNs节点检测,效果在于不需要历史先验信息,只需要记录节点状态情况且最优检测策略随运行周期更新,提高了检测方法的泛化能力。仿真结果表明,该方法较出色地完成了WSNs节点检测任务。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生作文(低年级适用)(2018年3期)2018-04-17
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
少儿科学周刊·少年版(2015年4期)2015-07-07
