
用于场景识别的多尺度注意力网络*
2021-07-15 12:08彭玉青刘宪姿袁宏涛武仪美
传感器与微系统 2021年7期
彭玉青, 刘宪姿, 袁宏涛, 武仪美
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 引 言
场景识别技术的目的是使计算机能够通过一系列的判别算法,自动判断图像的类别,为场景图像分配语义[1]。随着场景图像类别的丰富和图片数量的增多,场景图像的类内差异性和类间相似性对场景识别精确性的影响越来越明显,使得场景识别更具有挑战性。 早期的场景识别方法主要使用底层特征描述子表示场景图片,如GIST,SIFT,HOG[2,3]等,它们是描述图像颜色、形状、纹理等基本特性的基础特征。这种特征形式简单、容易获取和计算,但得到的图像全局表示具有一定局限性。随着深度神经网络和大量数据集的出现,越来越多的研究人员开始尝试使用深度学习方法。
目前将卷积神经网络(convolutional neural network,CNN)应用于场景识别领域的研究已有很多。研究人员通过融合不同类型的特征增强特征判别性。Wang L等人[4]通过两个不同深度的网络结构分别提取图像的局部特征和全局特征,融合两个网络结构的输出作为识别结果。Wang Z等人[5]采用以Inception-v2为基础的多组合网络架构,其中的一个网络结构用于获取对象类信息,另一个用于获取场景类信息,融合两个模型的特征后进行分类。这类方法需要多个网络模型,导致训练网络模型的难度加大,且计算过于复杂,时间开销大,算法实用性不强。
另有部分研究学者通过对图像区域的筛选得到更具有判别性的特征。李彦冬等人[6]通过似物性检测获得图像中的显著性区域,利用神经网络提取特征进行分类。余良琨等人[7]通过选择性搜索得到潜在物体框,提取深度特征后进行分类。Bai S等人[8]利用滑动窗口获得候选目标区域,经过CNN和长短期记忆(long short term memory,LSTM)的处理进行分类。这类方法通过传统算法生成一系列候选区域,但场景图像较为复杂时难以得到准确的显著性区域,算法性能严重下降。
以上基于CNN的场景识别方法都是通过对所有特征的分析处理得到最后的分类结果,而场景图像中并不是所有特征都属于有效信息,对分类结果起作用。人类识别场景时会选择性关注一部分信息,忽略其他可见的信息,注意力机制就是模仿人类这种感知方式的一种方法,而且注意力机制已经在图像分类、目标检测等领域取得显著成果。SENet[9]利用特征的通道间关系产生通道注意力图谱,计算量小且能附加到任意模型。CBAM[10]建模通道与空间注意力,并且具有轻量级的优点。残差注意力模块[11]通过堆叠注意力模块并进行注意力残差学习使模型深度增加。在以上几种注意力模型中,兼顾通道与空间的注意力模型具有更好的性能,但是计算空间注意力时会因下采样操作丢失部分信息,导致得到的注意力特征具有一定的局限性。
本文将提出一种用于场景识别的多尺度注意力网络(multi-scale attention network,MANet),增强图像特征表现力,关注重要特征,抑制不必要特征。
1 基于VGG16的多尺度注意力网络
1.1 整体结构
本文以VGG16作为主干网络,将构建的多尺度注意力模块MANet附加到VGG16的最后一个卷积层(Conv5_3),为输入特征的通道和特征图各部分分配权重,增强预测时的多尺度判别性特征。模块输出的聚合特征输入到池化层和全连接层;在全连接层引入中心损失函数与SoftMax损失函数联合监督,拉进同一类别特征间距离。最后,由SoftMax层输出预测场景类别,其整体结构如图1所示。
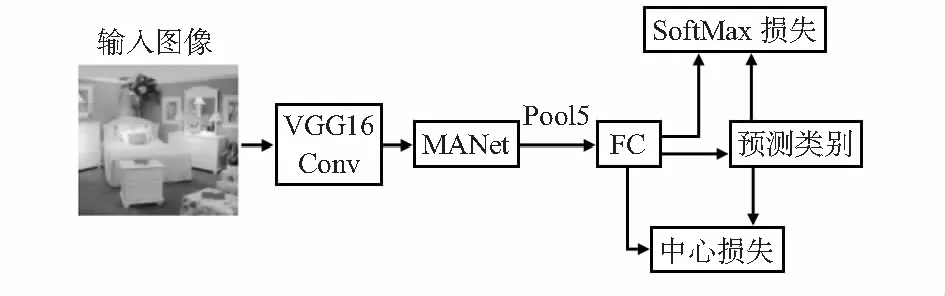
图1 加入MANet的VGG16模型结构
1.2 多尺度注意力模块MANet
MANet将主干网络最后一层卷积输出的特征作为输入,通过不同感受野的平均池化层得到不同尺度的特征图,使池化后的特征图大小分别为1×1和输入特征图的1/2,1/4。尺度1分支生成通道注意力特征,对特征通道进行重标定;尺度2和尺度3分支,基于不同尺度的特征图分别生成空间注意力特征。最后,串联各个尺度的特征,降维至初始特征大小,输入到池化层和全连接层进行计算,如图2所示。给定最后一个卷积层输出的特征F∈C×H×W,整体计算过程可概括为
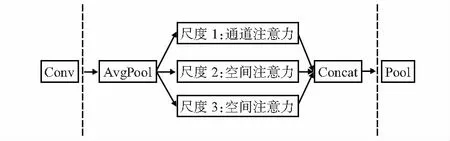
图2 多尺度注意力网络结构
F′=dr(Fc+Fs1+Fs2)
(1)
式中Fc,Fs1,Fs2∈C×H×W为经过多尺度注意力模块的各个分支标定的注意力特征, dr为1×1卷积降维操作,最后输出聚合后的特征F′∈C×H×W。
1.3 通道注意力
图2中的尺度1通道注意力用来构建通道间的关系,为通道分配权重,突出更值得关注的对象。本文的通道注意力结构是基于SENet的改进,其结构如图3(a)。SENet通过全局平均池化操作将特征沿空间维度压缩成一个通道描述符,表征在特征通道上响应的全局分布;通过非线性学习建模通道间的依赖性,然后在通道维度上对原始特征进行重标定。但是经过标定的特征图输出响应较原来会变弱,所以本文加入注意力残差学习,使显著的特征更加显著,而且聚合注意力特征与原始全局特征,既保证了特征信息的全面性,又防止网络层数加深可能产生的梯度消失现象,其整体计算过程如下
Fc=Mc(F)=(Ac(F)+1)*F
(2)
Ac(F)=σ(g(W,F))=σ(W(Avg0(F)))
(3)
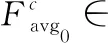
1.4 空间注意力
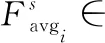
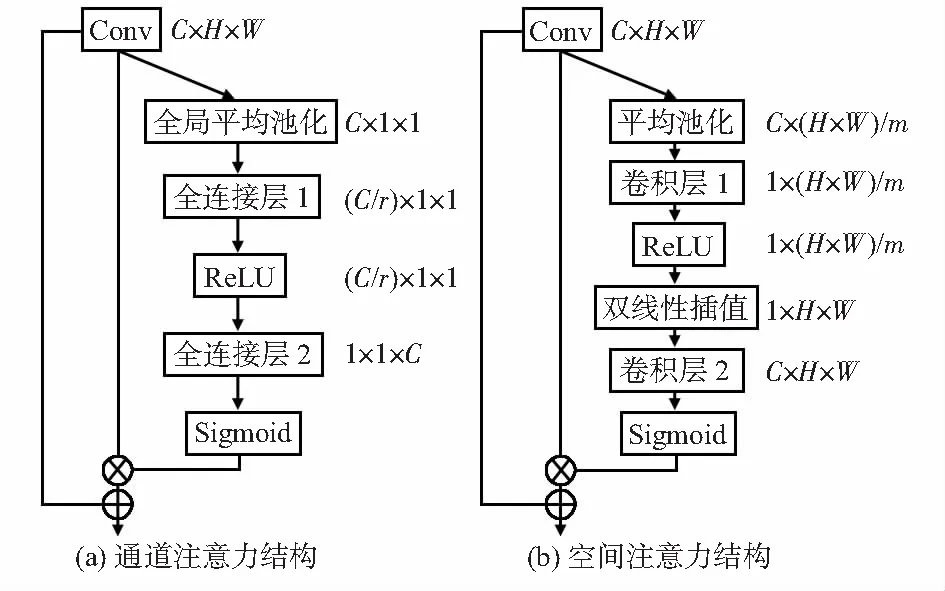
图3 注意力分支结构
Fsi=Msi(F)=(Asi(F)+1)*F
(4)
Asi(F)=σ(h(f,F))=σ(f(Avgi(F)))
(5)
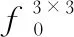
1.5 损失函数联合监督
SoftMax损失使不同类别特征保持分离,其描述如下
(6)
式中xi∈d为yi类的第i个特征,Wj∈d为全连接层参数矩阵的第j列,b为偏置项。m为每批次的图片数量,n为类别总数。
SoftMax损失仅作用于不同类别间的特征,对于类内特征差异性大的情况难以发挥很好的效果。而场景图像的类内差异性明显,所以对于场景识别任务,深度学习特征不仅需要可分离还需要可判别。因此,本文引入中心损失和SoftMax损失联合监督训练[12],如图1所示。中心损失的定义如式(7)所示,其中,cyi为第yi个类别的特征中心
(7)
在每次迭代中,通过平均相对应类别的特征去计算中心,拉近同一类别特征间的距离。Lc的梯度和cyi的更新公式如下
∂Lc/∂xi=xi-cyi
(8)
(9)
式中φ为一个判断函数,yi=j时值为1,否则为0。SoftMax损失与中心损失的联合监督可以表示为
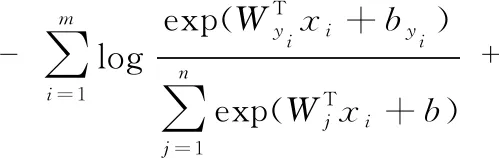
(10)
式中 参数λ用于平衡两个损失函数的比重。λ=0时可视为只使用SoftMax损失监督训练。
2 实验与结果分析
2.1 实验设置与数据集
本文所有实验都在同一实验环境下完成,使用CPU为Xeon W—2123;GPU为GeForce GTX 1080Ti,24 G;在Ubuntu 16.04操作系统上使用开源深度学习框架Caffe完成网络的微调训练。以Places205预训练的VGG16模型为基准,基础学习率为0.001,动量设定为0.9,共训练100 epoches,每3 000次迭代学习率变为原来的1/10。由于GPU的物理内存有限,训练期间采用小批次32的训练方式。
本文选择两个标准场景识别数据集进行实验,即MIT Indoor67和SUN397。MIT Indoor67数据集共包含67类室内场景,共计15 620张室内场景图像,每类至少有100张图像,每类选择80张作为训练集,20张作为验证集。SUN397数据集共包含397类,每个类别至少有100张图像,共计108 754张图像,每类选取50张为训练集,50张为验证集。
2.2 多尺度注意力模块实验分析
本文在MIT Indoor 67数据集上进行了通道注意力,空间注意力,以及多尺度注意力并行的实验对比。并分析了注意力残差学习对通道和空间注意力的影响;卷积核大小对空间注意力的影响,实验结果如表1所示,其中“VGG16”为基准模型。
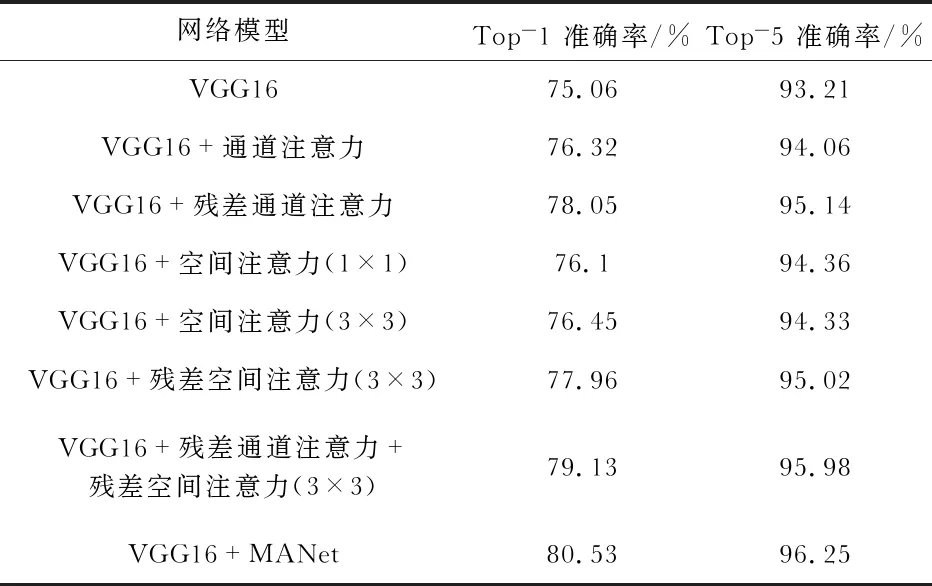
表1 多尺度注意力模块实验分析结果
实验结果表明,相较于原始模型,加入通道注意力结构能够有效的提高识别的准确率,而改进后的残差通道注意力模型“VGG16+残差通道注意力”有更好的表现,说明本文改进的通道注意力模块有更好的提取特征的能力,实现了更好的注意力计算。带有残差学习的空间注意力模块也产生了更好的准确性,并且在不同卷积核大小的比较中,采用较大卷积核的模型“VGG16+残差空间注意力(3×3)”有更好的表现,这表示需要大的感受野来决定空间上重要的区域。因此本文设计的空间注意力结构将卷积核大小设为3×3,并使用注意力残差学习。最后,多尺度注意力结构并行计算能得到更精细的注意力图,优于仅使用通道注意力或空间注意力,表明结合两种注意力是至关重要的,而且使用多尺度注意力模块的“VGG16+MANet”具有更高的精度,说明多个尺度的空间注意力特征互补,多尺度结合能够弥补信息缺失。
2.3 联合监督实验分析
2.3.1 损失函数联合监督效果验证
本实验在MIT indoor 67数据集上进行了损失函数联合监督的效果验证。对比了中心损失分别加入到fc6和fc7层不同位置的情况,实验结果如表2。实验结果表明联合监督优于单个损失函数监督,且中心损失作用在fc7时使模型达到了最好的识别性能。
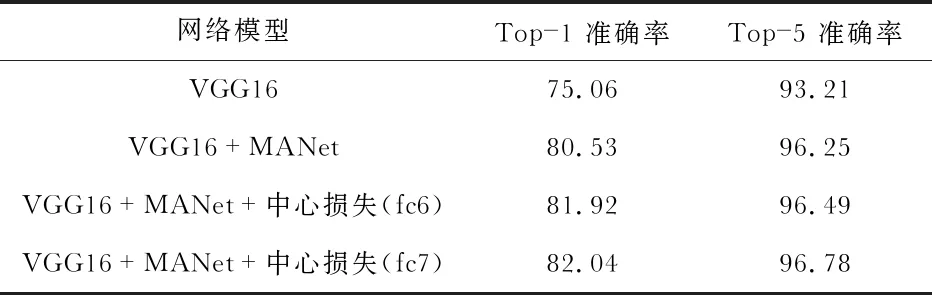
表2 损失函数联合监督的对比 %
2.3.2 对类内差异性和类间相似性的影响效果验证
在MIT indoor 67中选取了多个类别进行测试。表3为本文模型与基准模型在“书店”和“图书馆”两个典型易混淆场景的对比,“误判率”表示误判为相似类别的概率,即将“书店”识别为“图书馆”,将“图书馆”判断成“书店”的概率。
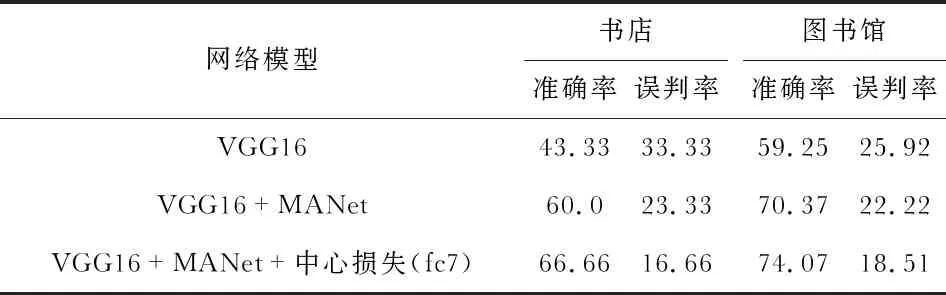
表3 相似类别实验结果对比 %
图4为不同场景下的对比,准确率都有较大提升。从结果中可以看出,原始网络模型对易混淆类别的识别是极其困难的,本文模型能够更准确识别出相似类别,说明通过多尺度模块聚合的特征具有判别性;联合监督的优化方法能够更加有效削弱类内差异性和类间相似性对识别任务的影响。
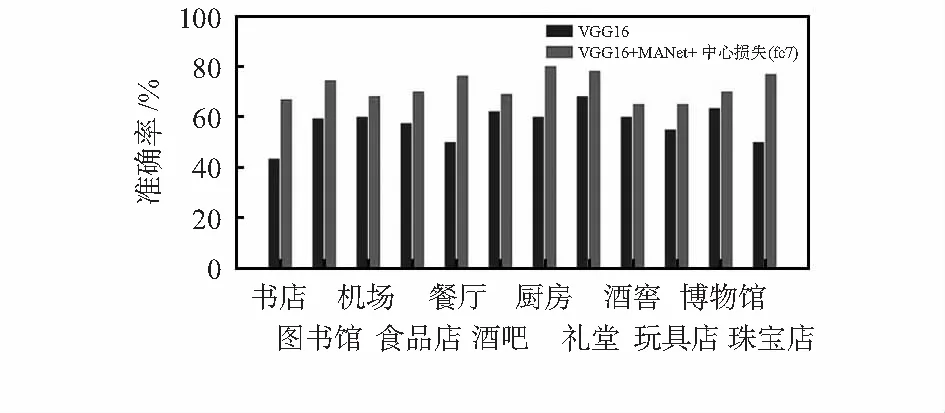
图4 本文模型与基准模型在多个类别的准确率对比
2.4 与其他算法对比分析
在MIT Indoor 67数据集和SUN397数据集均进行了与其他场景识别算法的对比实验,如表4所示。实验结果表明,本文模型在两个数据集上都达到了最好的识别效果。SUN397数据集因包含的场景类别复杂,图像数量较大,其识别准确率普遍较低,但本文模型具有较高准确率。由此可以看出本文模型有更好的场景识别性能,具有更强的鲁棒性。
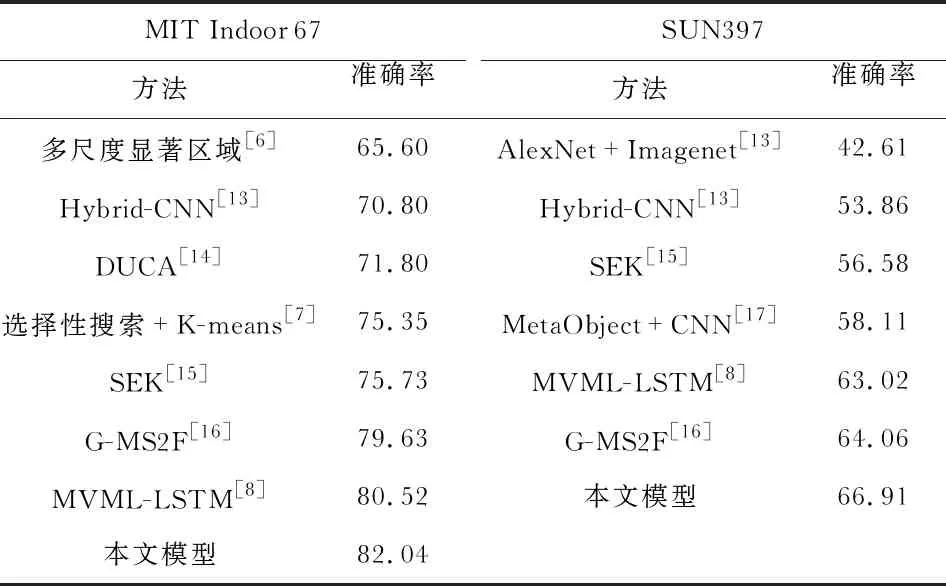
表4 MIT Indoor 67和SUN397数据集上不同算法准确率对比 %
3 结束语
通过对特征的通道和空间两个方面的重标定,关注判别性更高的部分。实验结果证明,改进后的通道注意力结构产生了更精细的注意力计算,更加突出值得关注的对象信息;设计的空间注意力结构能够有效关注显著性区域;最后融合多尺度特征使其更具有判别性且弥补了特征丢失,削弱了类间相似性。此外,本文还引入了中心损失联合监督的优化策略,有效减少了类内差异性的影响,进一步提升了分类准确率。最后,分别在MIT Indoor 67和SUN397数据集上验证本文模型,识别效果均优于其它算法,充分证明本文算法具有更优的识别性能和更强的鲁棒性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
民族古籍研究(2018年1期)2018-05-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
时代英语·高三(2014年5期)2014-08-26
中国中医药现代远程教育(2014年16期)2014-03-01
