
防范虚假申报引发项目管理风险的研究
——申报资料校验系统设计及应用为例
2021-07-11 08:26王鸿飞
科技管理研究 2021年11期
王鸿飞,何 悦
(广东省科学技术情报研究所,广东广州 510033)
1 研究背景
2020 年7 月29 日,广东省审计厅发布《广东省人民政府关于2019 年度省级预算执行和其他财政收支的审计工作报告》,工作报告指出科技孵化育成体系建设绩效存在的问题,对广东省2015 至2018年度科技企业孵化育成体系建设政策落实和相关资金管理使用绩效进行了审计调查,抽查相关孵化载体,发现6 家孵化器存在虚假申报,骗取相关资质认定和财政补助;通过数据筛查发现7 391 家在孵企业、毕业企业不符合孵化器入驻条件[1]。科技项目申报资料真实性存疑的问题一直存在,虚假申报在传统形式审查过程中难以识别,未能发现并有效制止较普遍存在的财政资金被骗取和公共资源损失浪费问题。孵化载体资质认定中的虚假申报行为,主要表现为参与孵化载体资质认定的申报单位在不符合认定条件的情况下,伪造在孵企业的工商信息及知识产权信息,希望通过填报虚假信息达到符合认定条件资格。从广东省审计厅在工作报告中提出的问题分析,可判断审计部门对科技项目监督管理运用了新的技术手段,在数据挖掘及逻辑关联方面已优于科技管理部门事前形式审查的技术手段,无形中对科技管理部门在科技项目管理工作上也提出新的挑战。科技事业的发展事关科技进步和国家未来发展的竞争力,其中项目的申报和遴选是科技事业发展的一个重要入口,过往项目事前形式审查的方式已不适应现监督管理的要求,虚假申报导致的项目管理问题较为突出,随之引发的项目管理风险已逐步呈现。
在此背景下,本研究聚焦于项目申报资料中的工商信息及知识产权信息校验研究,结合孵化载体资质认定管理工作的风险特征,对化解项目管理风险提出新的技术手段,对在孵化企业的工商信息及知识产权信息进行真实性校验,通过实践引证了防范项目管理风险的有效措施。
2 文献综述及现状分析
2.1 文献综述
2.1.1 理论实践方面
邱莹等[2]对2018 年广东省自然科学基金项目形式审查情况进行总结和分析,形式审查的内容仅对申报要求进行审查,并无对申报资料进行真实性校验。姚宁广[3]在安徽省科学技术奖励管理工作中,对形式审查提出新的要求,除了过往常见的限项申报审查外,对是否使用上一年度落选项目、获奖材料是否重复使用等均有进行校验,但该校验是通过人工完成。翁振群等[4]通过对2012 年至2016 年度自然科学基金不予受理的常见原因进行分析,形式审查的手段较为简单,无法校验真实性。刘培云等[5]以科研项目管理实践为例,从健全完善信息化项目管理系统、建设推进科研信用体系、管控研究人员风险、监控项目经费风险、研判项目失败风险、监测技术与实验平台风险等方面,讨论提出了若干可选择的项目风险应对策略。刘春林[6]基于信息不对称理论,对常见的编辑可以介入的学术不端行为提出应对措施和建议。顾卓[7]认为科研项目信息存在不对称的现象,提出加强科技项目的过程管理,建立健全科技项目管理问责制等管理风险控制的建议。姚佳良[8]提出新型学术不端判定模式,增加了“专业人员复检”步骤,形成“计算机审查系统初检-专业人员复检-专家判定”模式,可有效减少对复制比高的学术论文的误判,增加判定的专业性。钱乾等[9]认为科技项目管理中存在风险,需对风险进行准确识别、判断,并制定针对性的管理策略,应运用信息化手段全面降低科技项目管理风险。
2.1.2 技术设想方面
马瑾男[10]在基于数据池的项目形式审查智能评判系统在解释数据池内涵的基础上,从审查主体与评判规则入手,详细介绍了基于数据池的项目形式审查智能评判系统的功能,通过智能评判系统,可实现数据的积累、汇聚,减少人力操作,但仅限于科研诚信和财务审查,数据来源于自有数据的校验,无法多维度对申报资料的真实性进行校验。张重毅等[11]对科技论文隐性学术不端行为判别特征分析。针对论文中的公式或图表抄袭、跨语种抄袭,提出了相关的算法模型。上官学奎等[12]对科技项目申报限项核查构建研究,在项目的限项申报提出了校验规则与反馈流程。柳亭等[13]在奖励申报系统中增加历史数据查询功能,对涉及重复报奖的专利、论文、专著、标准等获奖情况进行查重,实现知识产权状态检索、知识产权重复使用校验,避免重复报奖。潘昕昕[14]提出建立统一的监督评估信息系统,建立相关数据库,通过提交结构化的报告和数据,实现对项目实施全过程的痕迹管理,汇集项目管理和监督信息,对项目实施动态监控和风险预警,在项目信息分析的基础上选取项目进行重点监督。简国明等[15]构建了大学生创新创业训练计划项目结项材料查重系统,通过结项材料的文本比对、相似判别、数据甄别和线上运行,得出结项材料查重报告。陶秀杰等[16]对企业科研项目管理流程进行深入的设计与研究,设计并实现基于情报和知识管理的科研项目管理系统,有效地提高科研项目的管理效率。王欣宇[17]设计相似度分析模型,利用大数据分析技术对科技项目申报材料进行相似度计算,计算出申报材料的相似度比率,并详细列出相似的具体内容,可辅助项目管理决策。朱昆等[18]以项目、信息、报表为核心,设计了科研项目管理系统,实现科研单位的高效率、精细化、全方位、决策型管理。杨朝红等[19]提出了一种交换数据格式标准、数据库标准和文档开发标准的行业信息化标准的自动化校验方法,能够替代部分人工验证工作。王晨辉等[20]在项目评审中利用神经网络自动拟合能力,对知识产权关联度进行分析,代替人工进行辅助评审,为人工评审提供参考。
2.2 现状分析
在孵化载体资质认定中,在孵企业的数量及真实性直接影响申报单位是否符合认定条件。在孵化企业的工商信息包括统一社会信用代码、成立时间、注册地址、注册资本、企业类型、登记机关,伪造工商信息是为了伪证在孵企业主要研发、办公场所是否在所属孵化器场地内,孵化时限是否超过时限。知识产权信息包括专利、商标、软件著作权、作品著作权,伪造知识产权信息是为了伪证在孵企业知识产权的所有权归属、专利在途状态。伪造手段一般通过利用修图软件编造虚假材料及对照申报条件利用反向工程的原理,伪造在孵企业的工商信息或知识产权信息。导致作造假例频现,原因在于过往没有手段或方法对申报资料进行多维度真实性校验。虽然科技管理部门已加大力度实施现场检查,打破了之前只重“书面审核”,不看“企业实际”的惯例。但这种检查单纯依靠检查人员的经验判断,仍然缺乏有效的工具或手段,无法有效甄别各样佐证材料的真实性。同时“上有政策,下有对策”,众多网络自媒体对如何规避科技部门的检查都有科学合理的套路教学,使实际的检查效果大打折扣。针对虚假申报的问题,2020 年广东科技管理部门在阳光政务平台及时补增了知识产权校验功能,但只针对高企校验,其他专题项目暂时无法校验。
2.3 存在问题
综上,理论实践的文献均聚焦于申报资料合规性的问题上,形式审查多数通过人工鉴别,对申报资料的真实性无法进行校验。技术设想的文献止步于具体功能的构思或架构设计,实践以查重或限项为主,并无对申报资料进行真实性校验的实践。针对文献及现状,仍存在以下问题,一是无法校验项目申报资料真实性,缺乏有效工具;二是形式审查单凭个人经验判断,人工审核工作量大;三是虚假申报引发的项目管理风险依然隐性存在,亟需采取有效手段防范风险。
3 申报资料校验系统设计
本系统设计思路是结合孵化载体资质认定项目管理工作过程中存在的风险特征,围绕填报的工商信息及知识产权信息与第三方数据库提供的接口进行校验匹配,达到判断在孵企业真实性的效果。
3.1 系统整体设计
系统设计在标准方面,依托国家电子政务建设的各种信息技术标准(环境、技术、信息、安全、信息交换标准等),针对不同层面的使用者的应用水平,充分考虑系统的易用性。在可扩展方面,兼顾二次开发的需要及支持未来可能出现扩展的需要,系统采用开放的可扩充模块结构,保证以后可以方便地升级和不断增加新功能、增加容量、以及在同一平台上扩充其他业务应用功能。在安全方面,采用安全保密技术进行用户身份认证,应用系统的登录、流转等功能模块中,操作方式应简单快捷。应具备完善的日志管理等功能,能够追踪记录每次操作情况,并对非法操作进行告警。
3.1.1 架构设计
申报资料校验系统架构分为5 层,包括应用层、业务层、管理层、执行模型、资源层(见图1)。可以直接在平台上使用,无需下载软件或者小程序,可内嵌到各种系统中,使用方便灵活,大大提高形式审查的准确率及审查效率,对形式审查及项目评审起到重要的辅助作用。
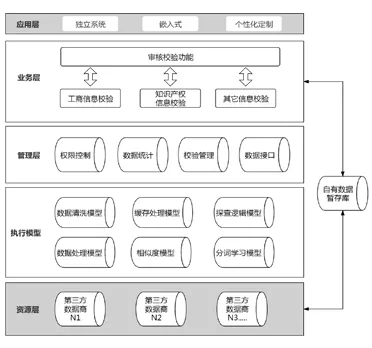
图1 申报资料校验系统架构
3.1.2 流程设计
工商信息及知识产权信息导入后,先从暂存库数据校验信息,若暂存库无对应的数据可校验,则通过第三方接口进行校验,通过校验后显示出对应的校验结果(见图2)。
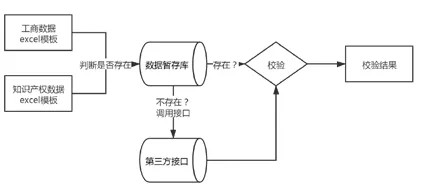
图2 校验流程
3.1.3 校验内容
申报资料校验系统根据不同项目/需求方的要求可设计不同字段的校验,本次校验字段如下.
(1)工商信息可校验的字段包括:企业名称、统一社会信用代码、成立时间、注册地址、注册资本、所属行业、企业类型、登记机关。
(2)知识产权信息可校验的字段,具体如表1所示。

表1 知识产权信息校验字段
3.1.4 校验模型设计
申报资料校验系统包括6 大模型,在数据标准化方面,涉及到大量的数据录入和采集工作,需对数据进行清洗及标准化,设计了数据清洗模型。在应对网络延时、接口数量过多及校验数据量较大方面,设计了缓存处理模型、接口聚合与探查逻辑模型、防过载或高并发模型。在校验实施逻辑方面,设计了中文分词计算关键相似度模型及分词学习模型,提高模糊判断的准确率。
(1)数据清洗模型。通过删除、更正数据中错误、不完整、格式有误或多余的数据,使数据具备逻辑上的准确性,保障来自各个数据源的数据的一致性。在异常值以及噪声的处理方面,主要是创建清洗应用库和清洗规则,主要对录入的数据源创建清洗规则、清洗运行时间以及创建和修改清洗后数据结构(见图3)。如工商信息的成立时间采用自动化标准格式,会对2020.10.21、2020 年10 月21 日和2020/10/21 等类型进行转化为2020-10-21 格式。知识产权编号采用多条件综合判断,在匹配前先过滤填写与接口数据中的空格、所有字母和小数点及后面数字/字母、特殊符号,包含“ ()();;,,.&-《》{}”。
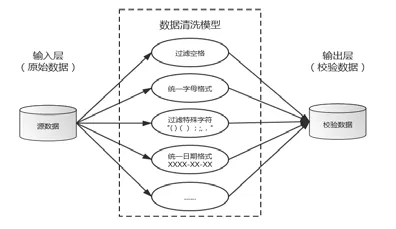
图3 数据清洗模型
(2)缓存处理模型。由于系统需调用第三方接口,而第三方接口存在网络延时、服务不用等不可控因素,系统采用较主流的Redis+数据库结合的缓存技术(见图4)。
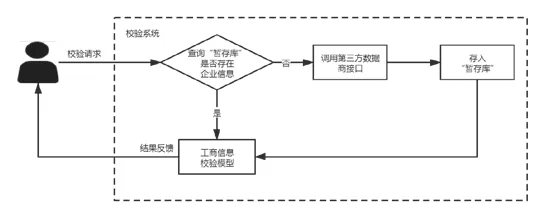
图4 工商信息缓存处理模型
(3)接口聚合与探查逻辑模型。知识产权校验的类型主要分为商标、发明专利、实用新型、商标、软著等类型,需校验的字段较多,各类型的接口分散在不同的第三方数据商,实施校验的逻辑也较为复杂。为确保准确性,需要聚合不同的第三方接口,再进行分类、整理、梳理逻辑,并进行二次开发满足校验需求。此外,还需实现企业知识产权内容探查逻辑。因单次调用第三方数据商接口进行校验时,部分第三方数据商提供的数据有条数限制,每次调用均只返回指定条数的数据(如10 条)。如某个企业的知识产权数据有50 条,需调用约5 次第三方接口才能完成校验,为提升用户使用体验和降低成本系统运营成本,结合缓存技术,设计了知识产权探查逻辑进行处理,即合理的使用缓存和主动调用接口策略(见图5)。
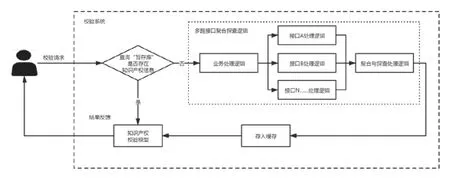
图5 知识产权信息校验模型
(4)防过载或高并发模型。由于每条校验数据都要访问一次接口,这存在数据请求和处理的过程,若导入校验数据太多(大于200 条),会造成数据延迟、浏览器报错或服务器卡机的情况,为了解决实际用户操作和大批量数据校验卡机的问题,优化了相关执行判断。具体如下:第一步,数据导入后,先判断前序任务是否有正在匹配中的数据,无前序任务则直接进入下一步,若显示“待匹配”需等待前序任务匹配完后再进入下一步;第二步,判断导入模板的校验数量是否大于50 条数据,若导入模板数据少于或等于50 条,则导入后显示校验结果页,若导入模板数据大于50 条,则导入后跳转到校验记录页,显示数据“匹配中”,再进入下一步;第三步,数据校验采用定时器+异步处理方式,每分钟向第三方接口发送50 条数据请求并校验,直到数据校验完毕,校验记录才显示“已匹配”,并可查看匹配结果。
若同时上传多个大于50 条的模板,系统有队列校验过程状态,未开始校验的模板显示“待匹配”,未处理完模板显示“匹配中”,匹配完毕模板显示“已匹配”;工商信息校验和知识产权校验并行校验,可以同时校验,不相互影响(见图6)。
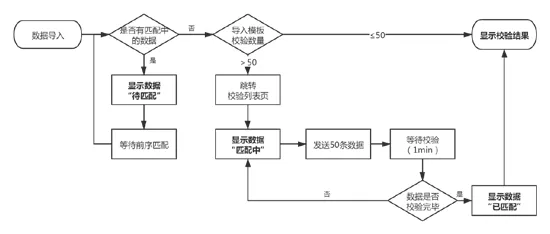
图6 知识产权信息校验模型
(5)基于中文分词计算关键相似度模型。以工商信息的企业注册地址文本内容为例,用户实际填报的内容、格式无法有效统一,本系统使用了分词技术并结合计算关键词相似度来有效提升校验的准确性。如系统期望填报的企业注册地址内容标准格式为“*省*市*区*路*号”,实际填报基本为“*市*路*园区*号”,与期望存在较大出入,为保障快速、精确校验企业注册地址,采用中文分词技术后再进行相似度算法进行校验比对。对填报的企业注册地址和通过第三方数据接口获取的企业地址分别进行中文分词。Ca 为用户填报内容,Cb 为第三方接口数据。根据用户填报的企业注册地址文本内容Ca 与通过第三方接口获得的企业注册地址文本内容Cb,分别使用JieBa 分词组件工具对文本内容采取前向查找模式进行切分,得到词串集合Sa、Sb。
用户填报内容:
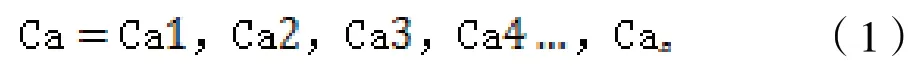
用户填报内容切词分组:
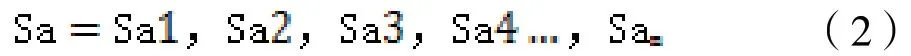
第三方接口内容:
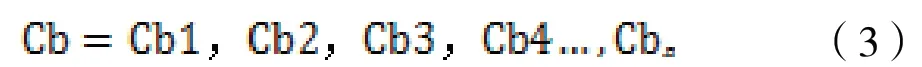
第三方接口内容切词分组:
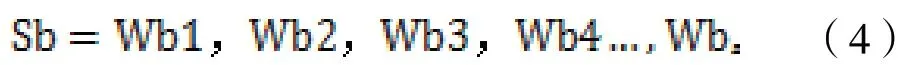
通过计算方法,计算出用户填报内容切词分组后与第三方接口内容切词分组后的相似度模型,为切词分组后的Sa 词串,为切词分组后的Sb 词串,计算相似度差值越小,内容越接近,可判断为相似度越高,计算方法为:
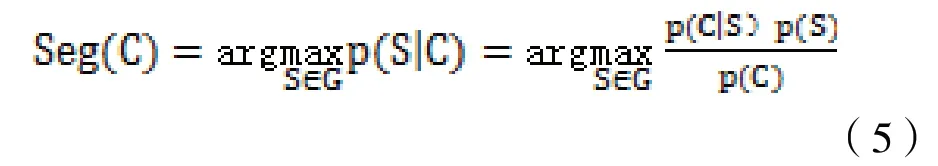
(6)分词学习模型。在校验系统中实现词库智能学习,将申报资料中的语句转化成语料库中的词,当有新文本信息导入时,针对文本中出现的新词进行智能学习,同时将新词通过字符串分词算法抽取出来,添加至暂存库词典中。该算法能够经过语料训练从而分出“新词”,即过往数据中没有收录到的词。只要它的出现次数超过一定的阈值,就能被识别,以便之后在分词过程中能抽取出来,实时更新语料库,完成智能学习功能。分词学习模型改进了传统字符串分词中的词典结构,提高了分词过程中的匹配速度,提高了分词效率,为校验提供了快速、准确的查询对比方法。分词学习模型主要采用正向和逆向匹配算法。
正向匹配分词算法处理流程步骤如下:
1)数据清洗标点符号预处理,并把每段文字提取出单独存放,预处理完的结果存为单个分词输入文件。
2)按顺序读出分词输入文件中的一段文字,记一段文字为Sn,分词结果为Kn(n=1,2…),全部读取完毕时,算法结束。
3)待切分的中文字串为Sn=C0C1C2…Cn,当前正在匹配字为Ci(0<=i<=n,i初始为O),j=i。首先根据Ci 为开头的词条树,然后沿着树结点逐层匹配,直到出现以下3 种情况之一:找不到匹配节点、找到可以成词的节点、i 等于n。
4)此时,Ci 最小匹配,切分出的结果为Ki=CjC1C2…Ci。若i等于n,此段文字分词结束,转步骤2)。若i小于n,i=i+l,转步骤3)。
逆向匹配算法处理流程步骤如下:
当进行逆向逐字匹配时,只要使用上文所述倒转词典中的词条,对算法稍作改动即可。由后向前对文本进行匹配。
1)与正向算法一致。
2)与正向算法一致。
3)待切分的中文字串为Sn=C0C1C2…Cn,当前正在匹配字为Ci(0<=i<=n,i初始为n),j=i。首先根据Ci 为开头的词条树,然后沿着树节点逐层匹配,直到出现以下3 种情况之一:找不到匹配节点、到达树的叶子节点、i等于0。
4)此时,C0 为最大匹配,切分出的结果为Ki=CjC1C2…Ci。若i等于0,此段文字分词结束,转步骤2)。若i大于0,i=i-1,转步骤3)。
当工商信息及知识产权信息导入校验系统后,经过内部的分词算法,对导入的信息进行分词处理,通过对文本中的已录词和未学习词进行识别,完成分词了解,最终根据校验系统要求将语句相同率和相同语句标示,输出对比结果。
3.1.5 校验逻辑
(1)工商信息。以企业的名称作为主键,第一步先通过“企业名称”进行校验,如校验无误,进入第二步;如校验有误,无法调出接口信息,显示“企业名称有误”。第二步同时对统一社会信用代码、成立时间、注册地址、注册资本、企业类型、登记机关的信息进行校验。如发生错误则提示错误的类型,并提示出录入与第三方数据比对校验的详细内容,方便用户快速定位找出问题并解决(见图7)。
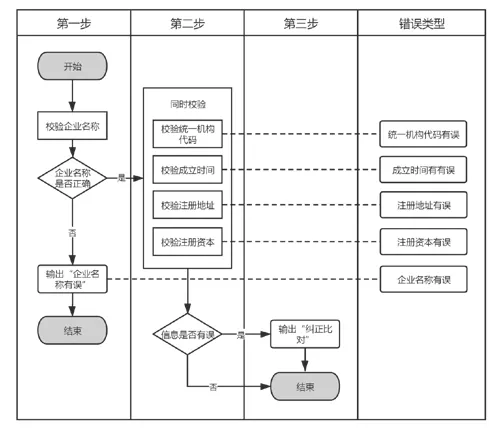
图7 工商信息校验逻辑
(2)知识产权信息。知识产权信息校验按照以下校验顺序进行校验:企业名称->知识产权类型->知识产权编号->知识产权名称->知识产权状态。以企业的名称作为主键,第一步对企业名称进行校验,如校验无误,进入第二步;如校验有误,无法调出接口信息,显示“无知识产权数据”。第二步校验知识产权类型,如校验无误,进入第三步;如果校验有误,无法调出接口信息,同样显示“无知识产权数据”;第三步依次对知识产权编号、知识产权名称、知识产权状态进行校验。如发生错误则提示错误的类型,系统提示出错类型和录入与比对校验的详细内容,方便用户快速定位找出问题并解决(见图8)。其中,知识产权状态在纠错对比栏目中显示正确的状态与具体法律状态描述。
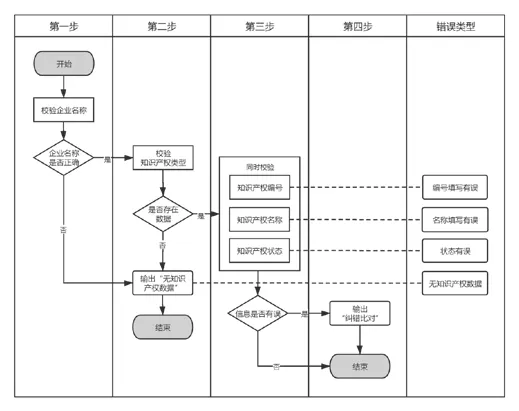
图8 知识产权信息校验逻辑
因知识产权存在多种状态,会存在信息不对称的问题,难以判断真实性。特别是已申请未授权或已授权未拿到证书的仍属于在途状态,故知识产权状态采用法律状态进行判断,具体以第三方数据方反馈的参数状态为依据。通过梳理分析,理清了公告号与申请号的逻辑关系,能准确判断知识产权是否处于有效状态。
最终梳理为三种状态,已拥有、已申请属于有效状态,已失效属于无效状态,如表2 所示。
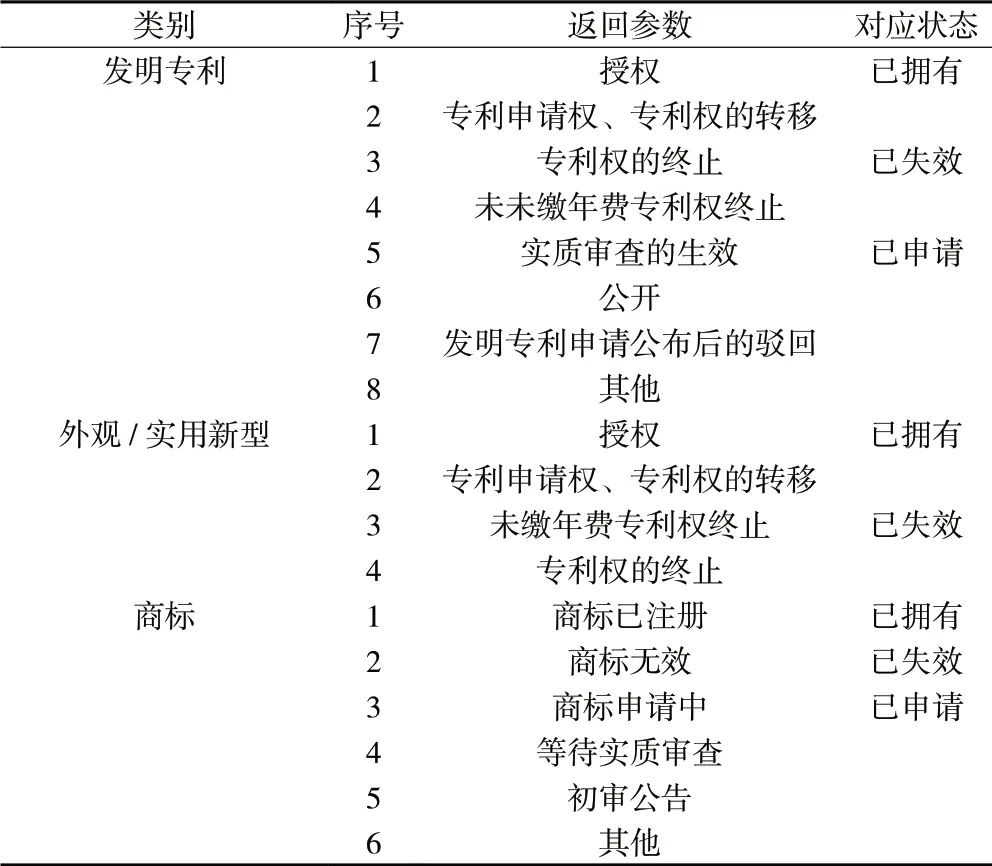
表2 知识产权状态判断表

表2(续)
3.2 创新点
(1)暂存库模块。该功能主要是避免短时间内反复查询或测试,造成数据数据冗余及影响统计分析的效果。在校验数据过程中,先从暂存库数据校验信息,若暂存库无对应的数据可校验,则通过第三方接口进行校验。调用第三方接口后,新数据会自动更新到暂存库,供下次查询使用;暂存库数据设置为7 天的保留期限,7 天后数据将会自动删除,保证数据实时性。
(2)相似度的容错设置。实际填报信息与真实信息存在差异,可能是填错或填漏一两个字符,但并非虚假信息;为避免误判填错或填漏的信息,通过概率模型提升模糊判断的准确率,形成容错机制,容错率可自行调节,最低限度可设置为70%,即填报内容与第三方数据匹配达到70%以上相同,视为真实信息;最高可调节为100%,即填报内容需与第三方数据匹配,需绝对相同毫无偏差,才能视为真实。
3.3 实用性
(1)数据实时性高。通过与官方数据对比,实际与市场监督管理部门及知识产权管理管理部门的数据延迟时间在10 天内。
(2)可视化统计分析。通过对数据归集和梳理,可形成工商信息及知识产权信息的数据简报,可生成数据可视化界面如折线图、柱形图、饼形图等,作为辅助评审决策的依据。
4 实践研究
广东省科学技术情报研究所创业孵化中心作为孵化载体认定项目管理的专业机构,研发及运用了申报资料校验系统,对2020 年度孵化载体资质认定项目的申报资料采用了真实性校验,主要是校验申报填报在孵企业的工商信息和知识产权信息的真实性。校验结果如下,对在孵企业工商信息进行真实校验6 398 项,主要校验在孵企业工商信息的真实性,正确率为85%;知识产权校验总数13 624 项,主要是校验知识产权(专利、商标、版权)的真实性,校验正确率为82%。具体内容详见表3。对系统校验的结果进行20%以上的人工抽查,与官方网站数据对比工商信息及知识产权信息,判断准确率达100%。

表3 工商信息及知识产权信息校验结果统计 单位:项
通过加强事前对孵化载体申报资料的真实性校验,提高了形式审查的准确率及审查效率,对判断申报资料的真实性起到关键作用,隔绝了虚假的申报资料,有效地控制虚假申报进入评审环节,使风险管理能力明显改善,项目质量明显提高,运用新的技术手段化解审计风险,及时解决了审计部门对2019 年科技孵化育成体系专项资金提出的问题,避免管理风险循环发生,孵化载体资质认定项目管理工作的经验值得借鉴及推广示范。
5 本文局限
本文基于孵化载体资质认定管理工作的需求,只针对工商信息及知识产权信息的校验方法及实践进行研究,可校验的维度仍然受限,后续将加快完善可校验的类别,增加社保人数、上市企业、融资历程、投资机构、行政处罚、税收违法、严重违法、论文、税收情况、欧美日国际专利、ISO、奖励、CMMI、植物新品种、国家级农作物品种、国家一级中药保护品种、国家新药、集成电路布图设计等企业常用资质。例如社保人数的数据,可向人社部门或数字广东申请调用接口;论文可以从知网、万方、维普等机构获取对应的数据接口,接入系统进行校验。同时,还需保障第三方校验数据源头的充足性,以多方数据源作为校验逻辑的依据,避免发生误判。
6 相关建议
(1)引导专业机构做好项目管理“守门人”。加强科技项目申报资料的事前审查,把好第一道关。借鉴本文研究内容基础上,要进一步加强专业机构以风险防范为基础的管理意识,以事加强前形式审查为重点,以有效的手段或工具为支撑,以校验结果为保障,通过加强形式审查,防范审计风险。建议加强省新型研发机构、省工程中心、重点实验室、重点研发计划等计划项目的事前审查,对申报的佐证材料进行“应验尽验”,排除后顾之忧。
(2)加强项目风险预判及管理。应对项目风险需加强挖掘项目管理潜在的风险和引起这些风险的内外部因素、项目风险的征兆与表现等,准确地分析和处理在科技项目中可能出现的风险,对项目风险应对措施计划进行不断更新与完善。当前和今后一个时期,要把防范审计风险作为一项紧迫的任务,切实抓好风险防范。建立一套符合科技项目管理自身情况的风险管理框架,最大限度地减少风险的发生概率和可能造成的不良影响,从而保证科技项目的顺利实施。
(3)落实科学技术活动违规行为处理措施。为规范科学技术活动违规行为处理,营造风清气正的良好科研氛围,按照科学技术部令第19 号《科学技术活动违规行为处理暂行规定》,发现在科学技术活动的申报、评审、实施、验收、监督检查和评估评价等活动中提供虚假材料,应对申报单位或相关责任人采取严格处罚措施。根据负面影响或财政资金损失的严重程度,禁止申报单位或相关责任人在一定期限内承担或参与财政性资金支持的科学技术活动;记入科研诚信严重失信行为数据库。造成特别严重负面影响或财政资金损失,应采用顶格处罚,对违规单位和个人取消5年以上直至永久相关资格。
猜你喜欢
少先队活动(2022年9期)2022-11-23
中学生学习报(2022年15期)2022-04-17
校园英语·月末(2021年13期)2021-03-15
中国外汇(2019年13期)2019-10-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2017年13期)2017-12-15
电子制作(2017年1期)2017-05-17
创新科技(2014年14期)2014-07-27
中学生英语·外语教学与研究(2008年4期)2008-03-18
