
Research on Variable Selection of Protein in Soy Lysine Spectroscopy Based on Latent Projective Graph
2021-07-08 09:58ChangzhengDUJuechenLONGJijunZHANG
农业生物技术(英文版) 2021年1期
Changzheng DU Juechen LONG Jijun ZHANG

Abstract [Objectives]This study was conducted to solve the problems of complex near-infrared spectrum information of soybean lysine, serious collinearity and insufficient predictive ability of full-spectrum modeling. [Methods]A new variable selection method, i.e., variable combination model population analysis method, was used to select characteristic wavelengths of soybean lysine near infrared spectra. The binary matrix sampling strategy and exponential decay function were used at first to delete the variables providing no information and select the near-infrared characteristic wavelengths of soybean lysine, which were then combined the partial least square method to establish a prediction model. Compared with other variable selection methods, the Monte Carlo variable combination model population analysis method selected the least wavelength points and the model had the strongest predictive ability. The variable combination model population analysis method adopting the binary matrix sampling strategy made up for the shortcomings of the single Monte Carlo sampling method. [Results]The experimental results showed that the Monte Carlo variable combination model population analysis algorithm could better select the characteristic wavelengths of soybean lysine NIR spectra and improve the reliability of the prediction model. However, in general, the accuracy of the lysine prediction model is not satisfactory, and it needs to be further reconstructed and optimized in future research work. The reason might be that the determination accuracy of the chemical value of lysine content was insufficient, or it might be caused by the poor absorption of the hydrogen-containing group of lysine in the near-infrared spectrum region and the poor correlation with proteins. [Conclusions]This study provides a reference for soybean high-lysine breeding.
Key words Soybean; Lysine; Near infrared spectrum; Population analysis
With the development of modern chemical analysis instruments, the application of near-infrared spectroscopy to analyze high-dimensional chemical and biological data generated from complex analysis systems is an important step. The goal and significance of variable selection are summarized in three levels: the first is to improve the prediction accuracy of the model; the second is to perform model calculations faster by reducing the dimensions; and the third is to provide a more easily understandable process of generating latent variable data. However, when faced with a situation with a large number of variables and a small sample, it is difficult to find a set of optimal variable combinations that satisfy the above three aspects among the many variables. With the development of chemometrics, a large number of variable selection methods have been proposed at home and abroad, and the above three problems have been dealt with in different ways, such as random frog algorithm[1](RF), particle swarm optimization[2](PSO), uninformed variable elimination method (UVE), Monte Carlo uninformed variable elimination method[3](MC-UVE), and genetic algorithm[4-6](GA). Although a large number of variable selection methods have been proposed at home and abroad, few algorithms consider the influence of variable combination factors. In this study, the Monte Carlo variable combination model population analysis[7-9](MC-VCPA) was applied for the first time to select characteristic variables of soybean lysine near infrared spectra, hoping to provide a reference for soybean high lysine breeding.
Materials and Methods
Sample collection and preparation
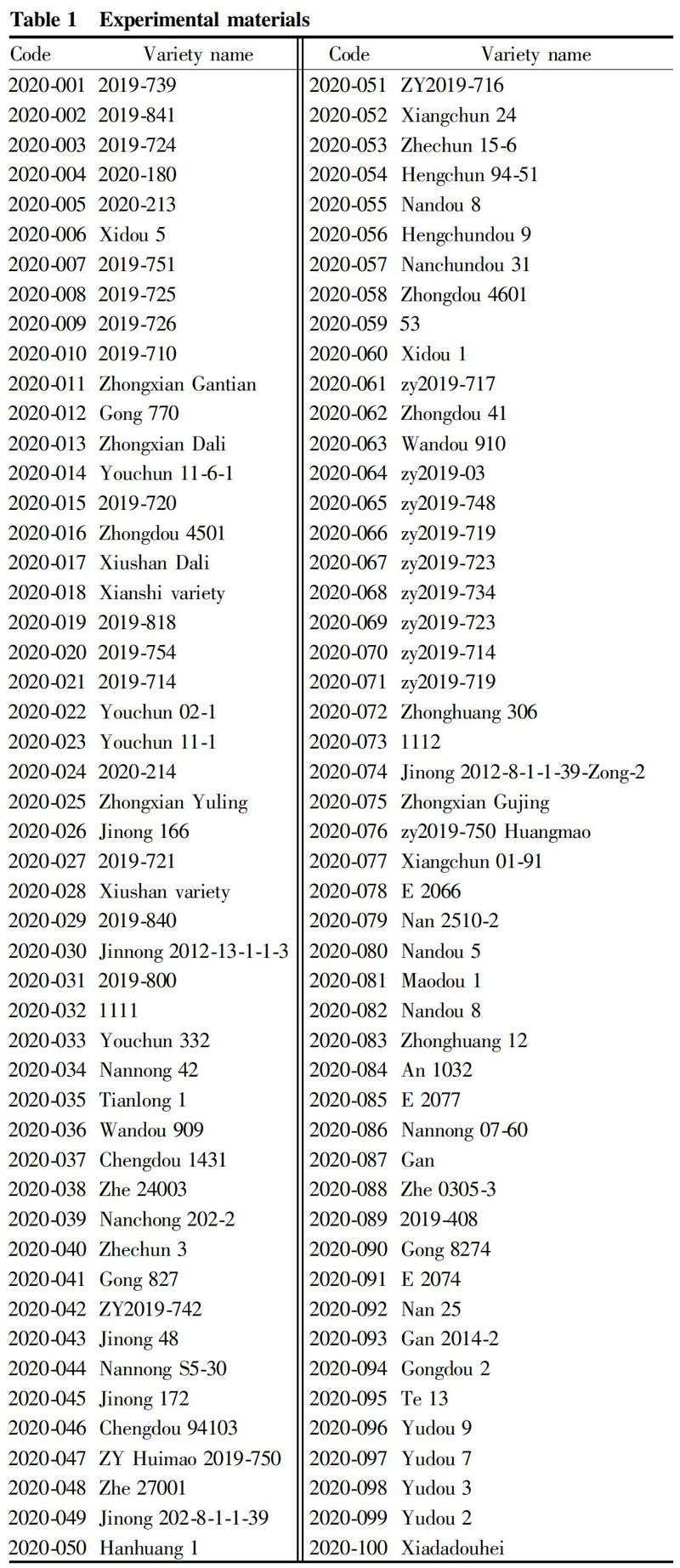
The experimental material soybean was provided by the soybean research laboratory of Chongqing Academy of Agricultural Sciences. The names of 100 soybean germplasms are shown in Table 1. In the first stage, 63 samples from different sources were collected and used as a calibration set; and in the second stage, 37 samples from different sources were collected and used as a prediction set. Each sample was divided into 2 parts equally, of which one part was pulverized with a cyclone mill and sieved with a 0.5 mm standard sieve until the sample particle size was below 0.28 mm (60 mesh) to prepare a crushed sample, and the other one was reserved as the original sample. After the samples were sealed and packaged, they were stored in a 4 ℃ freezer.
Experimental methods
Determination of lysine chemical value
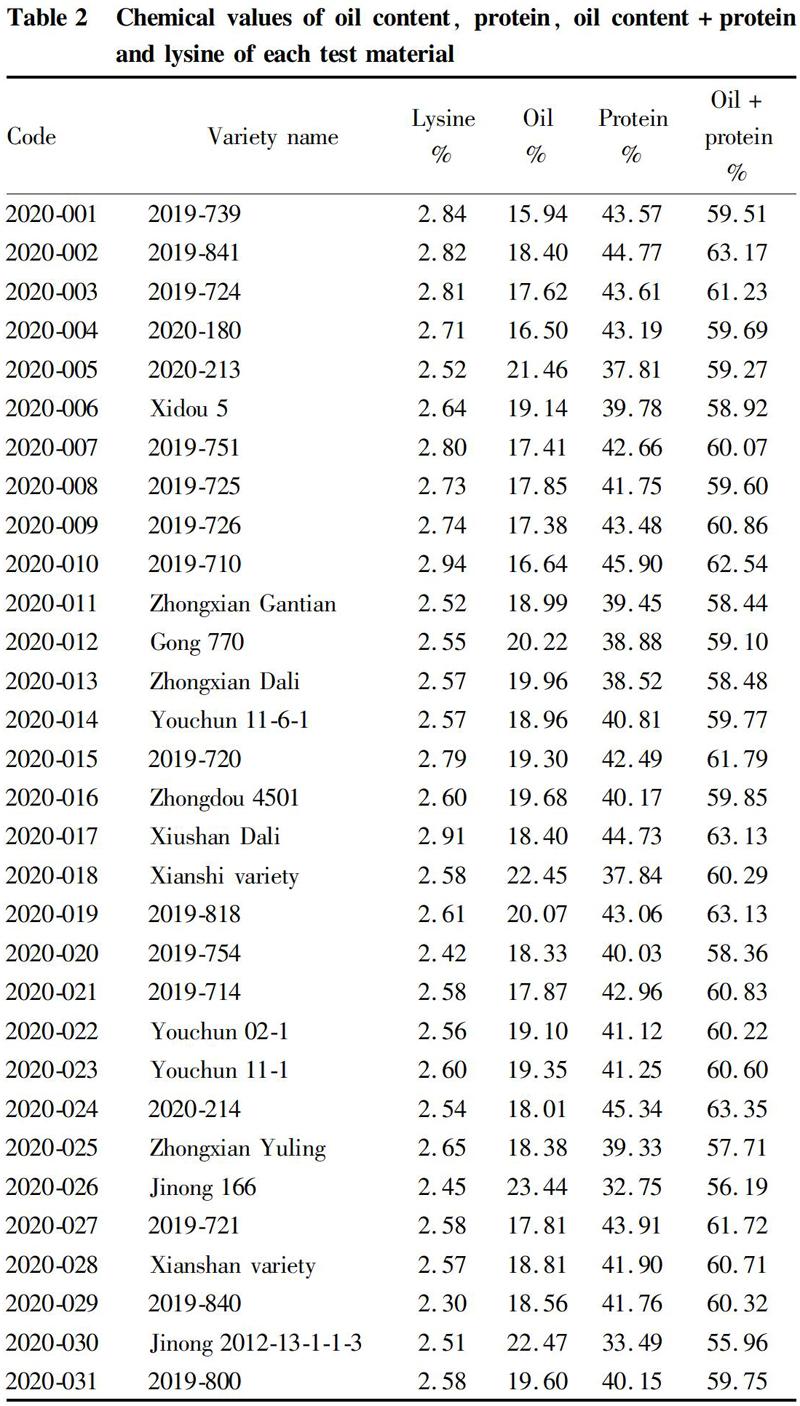
A certain amount of soybean powder (0.2 g) was added into a hydrolysis tube, and added with 10 ml of 6 mol/L hydrochloric acid. After degassing with a BILON-650CT multi-purpose constant temperature ultrasonic extractor for 10 min, nitrogen was then blown in. The extraction system was sealed and placed in an oven at 111 ℃ to hydrolyze for 23 h, followed by taking out and cooling to room temperature. The sample solution was diluted with deionized water to 100 ml, shaken well, and filtered into a test tube with a 0.45 μm filter membrane. Then, 1 ml of the filtrate was pipetted to a 10 ml volumetric flask and diluted to constant volume. The dilution was filtered with a 0.45 μm filter membrane into a sample bottle, and determined with an L-8900 automatic amino acid analyzer for the content of each amino acid (Table 2).
Determination of protein chemical value
Each of the soybean samples was taken, crushed and sieved through a 60-mesh sieve. The samples were sealed for later use. Then, 0.5 g of each soybean meal was added into a digestion tube, and added with 0.717 9 g of CuSO4·5H2O, 6.282 1 g of K2SO4 and then 10 ml of concentrated sulfuric acid to digest at 420 ℃ for 1 h. After cooling to room temperature, the protein content was determined with a Kjeltec 2300 automatic Kjeldahl nitrogen analyzer (Table 2).
Determination of oil chemical value content
A GZX-9146MEB fat analyzer was used for the detection. First, 2.0 g of each soybean meal was put into a filter paper tube, which was then plugged lightly with absorbent cotton. Into each extraction cup, 27 ml of petroleum ether was added. Each filter paper tube was added into an extractor, and extracted for 1 h. The extraction cups were taken out and dried at a constant temperature of 105 ℃ to a constant weight, and the total fat content was calculated (Table 2).
Collection of samples' near infrared spectra
In this study, a FOSS-W-700 near-infrared grain quality analyzer was used for spectrum collection. The collection was performed under the instrument wavelength of 1 000-2 500 nm, the data sampling interval of 1 nm and the spectral resolution of 10 nm. Temperature will affect the absorbance and wavelength shift of samples, and thus the spectral quality of samples[10]. The samples to be scanned should be taken out of the freezer and placed in the laboratory environment for more than 48 h before the spectrum was collected, such that the spectral scanning was performed after the sample temperature returned room temperature. Each sample was loaded three times, and the average spectrum was taken after scanning, which was the base sample spectrum (Fig.1-Fig. 4, for details, see Appendix 1∶100 Soybean Material Spectra).
Correlation analysis of soybean lysine content
All chemical value data processing and analysis were carried out in DPS 9.5 software.
The average contents and variation ranges of lysine, oil, protein, oil+protein of 100 soybean samples are listed in Table 2. The average lysine content of the selected materials was 2.55%, and the variation range and variation coefficient were 0.95% and 6%, respectively. The average oil content was 19.44%, and the variation range and variation coefficient were 8.9% and 9.6%, respectively. The average protein content was 39.96%, and the variation range and variation coefficient were 15.39% and 8.4%, respectively. The average protein+oil content was 95.40%, and the variation range and variation coefficient were 10.5% and 3.3%, respectively.
From the data on the variation ranges of soybean oil content and average protein content, the selected soybean samples had a large nutrient content and a good representativeness. Meanwhile, the variation coefficients of lysine, oil content and protein content were all below 10%, indicating that the stability of lysine, oil and protein was better. However, in these samples, the average content of lysine was less than 3%, and the variation range was less than 1%. It showed that the content of lysine in soybeans was low and the variation range between varieties was small, which is not good for soybean breeding to improve soybean lysine.
Model Evaluation and Spectral Preprocessing
All spectral data processing and modeling were performed in Mat lab2013b, PLS-Toolbox 8.0 and OPUS 8.5 software.
The role of model evaluation parameters is to test the reliability of the prediction model established by the calibration set samples. In the process of multivariate calibration modeling of near infrared spectroscopy, the frequently used model evaluation parameters are prediction residual sum of squares (PRESS), root mean square error of cross validation (RMSECV), and correlation coefficient (R) between predicted and true values, etc. The model evaluation parameters used in this study were modeling root mean square error of calibration (RMSEC), determination coefficient of calibration set (Rc2), and root mean square error of prediction (RMSEP). The high-frequency noise and low-frequency noise generated during spectral data collection will affect the correlation between the near-infrared spectrum and the soybean lysine content, thereby affecting the reliability of the prediction model. In order to avoid the impact of these high-frequency noise and low-frequency noise, the spectral processing system of the FOSS-W-700 near-infrared grain quality analyzer was used to denoise the spectral signal to obtain more accurate near-infrared spectral data of soybean lysine, as shown in Fig. 1.
Research on the Selection Method of Characteristic Variables in Variable Combination Population Analysis
Principle of the variable combination population analysis algorithm
VCPA is a new variable selection algorithm. The algorithm first uses Binary Matrix Sampling (BMS) to sample k sets of variable subsets from the variable space, and then uses Partial Least Squares (PLS) to calculate the root mean square error of cross validation (RMSECV) of these k sets of variable subsets, and σ×k sets of variable subsets with the smallest RMSECV are retained. The frequency of each variable in the σ×k sets of variable subsets is calculated, and the exponential decay function (EDF) is used to remove the wavelength points with a smaller frequency, and the remaining variables are repeatedly subjected to BMS sampling and EDF elimination. This process is repeated N times, leaving L spectral variables. Finally, the RMSECV of all variable combinations of these L variables are calculated, and the variable combination with the smallest RMSECV value is the final selected characteristic variable combination.
Characteristic variable selection based on VCPA
The VCPA algorithm is a new algorithm that takes into account the combined effects of all variables. First, the principal component analysis (PCA) was used to obtain the maximum number of principal components of the calibration set modeling data as 13. Then, through a large number of experimental tests on other control parameters, with following settings: sampling times k=1 000, iteration times N=50, the ratio of excellent subsets among k variable subsets σ=10%, the percentage of the number of times each variable in the binary sampling matrix M is sampled to the total number of samples α=0.5, the number of remaining variables L=14 was obtained.
The calibration set variables were sampled 1 000 times by BMS. This process could not only obtain 1 000 different variable combinations, but also ensured that each variable had the same sampling probability. The RMSECV of these 1 000 sets of variable combinations were calculated separately through PLS, obtaining 1 000 different RMSECV, and finally the 100 variable combinations with the smallest RMSECV value were selected. The RMSECV of the selected 100 variable combinations.
The frequency of occurrence of each variable in the 100 sets of variable combinations was calculated, and the less frequent variables in the 100 sets of variable combinations were deleted through EDF to obtain new calibration set data. Then, the new calibration set data was subjected to 1 000 times of BMS sampling to select 100 variable combinations with the smallest RM-SECV, and the occurrence frequency of each variable was calculated, followed by EDF variable deletion. After 50 cycles of this process, only 14 spectral variables were left. Finally, the RMSECV of all variable combinations of these 14 spectral variables were calculated by PLS. The variable combinations with the smallest RMSECV value were the characteristic variable combinations selected by VCPA. The characteristic spectral wavelengths retained were 1 196.532, 1 307.216, 1 436.789, 1 656.243, 1 728.236, 1 737.467, 1 862.914, 1 974.425, 2 229.173, and 2 359.275 nm, as shown in Fig. 2.
PLS modeling was performed with the characteristic variable combinations selected through MC-VCPA, obtaining a model with RMSEC 0.437 2, the coefficient of determination (R2C) 0.782 40, RMSEP 0.453 3, and the coefficient of determination of the prediction set (R2P) 0.691 4. The obtained scatter plot between the true values and the predicted values of the model correction set and the scatter plot between the true values and the predicted values of the prediction set are shown in Fig. 3 and Fig. 4, respectively.
Results and Analysis
The soybean lysine content prediction model established by VCPA combined with PLS was compared with other modeling methods GA-PLS, RF-PLS, full-spectrum modeling and MC-UVE-PLS. The results are shown in Table 4. In order to avoid the influence of randomness of each modeling method on the variable selection results during the operation process, each variable selection method was run 50 times, and the variable combination with the smallest RMSEP was taken as the final running result of each variable selection method.
Comparing the prediction results of soybean lysine content obtained by using different modeling methods, it can be seen from Table 4 that the prediction accuracy of PLS based on each variable selection method was stronger than that of PLS modeling based on full spectrum, indicating that it is useful to perform variable selection before establishing a soybean lysine content prediction model. In contrast, the soybean lysine content prediction model established by WTP-MC-VCPA-PLS had the best accuracy. Compared with the prediction results of WTP-PLS, its RMSEP dropped from 0.505 2 to 0.453 3, and the prediction accuracy increased by 10.3%. In addition, WTP-MC-VCPA-PLS, WTP-GA-PLS, WTP-RF-PLS and WTP-MC-UVE-PLS all used fewer variables for modeling. This phenomenon proves that using fewer variables to establish a soybean lysine content prediction model can achieve better prediction capabilities. Comparing WTP-MC-VCPA-PLS with WTP-GA-PLS, it can be seen that its RMSEP dropped from 0.493 5 to 0.453 3, which was because every time the EDF variable deletion strategy adopted by MC-VCPA is executed, some variables with small contributions will be deleted. With the implementation of EDF, the variable space will become smaller and smaller, and then the best variable combination will be established in a smaller variable space, which improves the combination probability of useful variables and avoids uninformed variables and the influences of interference variables. Comparing WTP-MC-VCPA-PLS with WTP-RF-PLS and WTP-MC-UVE-PLS, it can be seen that its RMSEP dropped from 0.485 4 and 0.473 8 to 0.453 3, respectively, which was because the Monte Carlo sampling strategy adopted by WTP-RF-PLS and WTP-MC-UVE-PLS cannot guarantee that each variable has the same sampling probability, while the BMS sampling strategy adopted by MC-VCPA makes up for the shortcomings of the single Monte Carlo sampling strategy.
Discussion
According to the above analysis, the WTP-MC-VCPA-PLS model could be used to predict the content of lysine. The determination coefficient of the calibration set was 0.782 40 and the determination coefficient of the prediction set was 0.691 4. Although the results of the prediction model were not ideal, the prediction model can be used as a rapid screening method in the selection of soybean high-lysine breeding materials. In addition, in the research results of this study, the coefficients of determination of the calibration set and the prediction set were far lower than those reported by Wang et al.[11]. This result might be due to the following reasons:
The accuracy and precision of chemical determination results were insufficient
The lysine contents of soybean powder samples mainly depend on the protein amino acid in the peptide bond state. The protein chains need to be broken and hydrolyzed into single amino acids before the determination, and then the total content of protein and free amino acids is determined. At present, no hydrolyzing agent and method that can hydrolyze all lysine without damage and keep it stable has not yet been discovered, which leads to the inaccuracy and insufficient precision of the determination of lysine content.
Lysine had poor absorption in the near infrared region
The double-frequency and combined vibration frequency of the hydrogen-containing group of lysine are too low and unstable, which makes the absorption in the near-infrared spectrum region poor. In addition, the low degree of correlation between lysine and protein may also be one of the reasons for the poor absorption in the infrared spectrum.
Conclusions
We used the MC-VCPA algorithm to select the near-infrared characteristic wavelengths of soybean lysine quality, and established a PLS prediction model. Compared with the soybean lysine content prediction model established by the full-spectrum PLS, the PLS prediction model showed RMSEP reduced from 0.505 2 to 0.453 3 and prediction accuracy improved by 10.3%, and reduced the spectral variables from 256 in the full spectrum to 14, which meant that the number of variables was greatly reduced and the model was simplified, indicating that the MC-VCPA algorithm can relatively better select the characteristic wavelengths of soybean lysine NIR spectra, simplify the model, and improve the calculation efficiency and reliability of the model. However, in general, the accuracy of the lysine prediction model is not satisfactory, and it needs to be further reconstructed and optimized in future research work. The reason might be that the determination accuracy of the chemical value of lysine content was insufficient, or it might be caused by the poor absorption of the hydrogen-containing group of lysine in the near-infrared spectrum region and the poor correlation with proteins.
References
[1]ZHU PL, HE Y, SHAO YN. Application of near-infrared hyperspectral imaging to predicting water content in salmon flesh[J]. Spectroscopy and Spectral Analysis, 2015(1):113-117. (in Chinese)
[2]LIANG YZ, XU QS. Instrumental analysis of complex systems: white, gray, and black analysis systems and their multivariate analysis methods[M]. Beijing: Chemical Industry Press, 2012: 242-247. (in Chinese)
[3]YUN YH, WANG WT, TAN ML, et al. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration[J]. Anal. Chim. Acta, 2014(807): 36-43.
[4]LEARDI R. Application of genetic algorithm: PLS forfeature selection in spectral data sets[J]. Chemometr, 2008, 14(5-6): 643.
[5]LEARDI R. Genetic algorithms in chemometrics and chemistry a review[J].Chemometr, 2001, 15(7): 559-569.
[6]YUN YH, CAO DS, TAN ML, et al. A simpleidea on applying large regression coefficient to improve the genetic algorithm–PLS for variable selection in multivariate calibration[J]. Chemometr. Intell. Lab. Syst, 2014(130): 76-83.
[7]YUN YH, WANG WT, DENG BC, et al. Using variable combination population analysis for variable selection in multivariable calibration[J]. Anal. Chim.Acta, 2015(862):14-23
[8]ZHANG HL, DI X, SHI XG, et al. The method study of wavelet threshold de-noising based on wheat NIR diffuse reflectance spectroscopy[J]. Journal of Changchun University of Science and Technology, 2010, 33(4): 46-49. (in Chinese)
[9]SONG YC, HUAN KW, HAN XY, et al. Variable selection of wheat protein near infrared spectra based on Monte Carlo variable cluster analysis[J]. Journal of Changchun University of Science and Technology, 2017, 40(5): 29-35. (in Chinese)
[10]ZHAO H, HUAN KW, ZHENG F, et al. Research on variable selection of protein in wheat near infrared spectroscopy based on latent projective graph[J]. Journal of Changchun University of Science and Technology, 2016, 39(5): 51-54. (in Chinese)
[11]LI Y, WEI YM, WANG F. Affecting factors on the accuracy of near-infrared spectroscopy analysis[J]. Journal of Nuclear Agricultural Sciences, 2005, 19(3): 236-240. (in Chinese)
[12]WANG WZ, FU CZ. Application of near infrared reflectance spectroscopy to quickly determine the contents of protein, fat and part of amino acids in soybean[J]. Zuowupinzhong Ziyuan, 1994(1): 31-32. (in Chinese)

- 农业生物技术(英文版)的其它文章
- Review on Effects of Sunlight on the Internal Quality of Peach Fruit
- Research Progress on Genetic Breeding of Sweet Sorghum Related to Sugar Traits
- Screening of Red-flesh Small Watermelon Varieties for Substrate Cultivation in Spring Greenhouses
- Planting Techniques of Pennisetum giganteum in Huanghuai Area
- Bibliometric Analysis of Status Quo and Trend of the Research on Duck Based on the Web of Science Database
- Preparation and Insecticidal Activity of Sea Anemone Peptide AP-GI from Aiptasia pallida