
电气火灾大数据监测平台的设计与实现
2021-07-08 08:03:58赵月爱郭兴原吴星辉
太原师范学院学报(自然科学版) 2021年2期
赵月爱,郭兴原,吴星辉
(1.太原师范学院 计算机系,山西 晋中030619;2.太原师范学院 数学系,山西 晋中030619)
随着物联网工程及大数据分析技术的发展和应用,消防工作“预防为主,综合防护”已获得广泛共识,智慧消防系统的研究与开发引起研究者越来越多的关注,相关技术难点也成为当前的研究热点[1].本文设计并实现电气火灾消防预警平台,在楼宇配电箱中部署多传感器实时采集剩余电流、电流、温度及设备经纬度等数据;通过GPRS无线技术直接把监测到的数据发送到云平台;借助阿里云服务器和大数据分析平台实时存储并分析数据,实现精准预测.
1 平台架构设计
图1是该平台的架构图,主要包括数据采集、数据传输和数据分析三大部分.
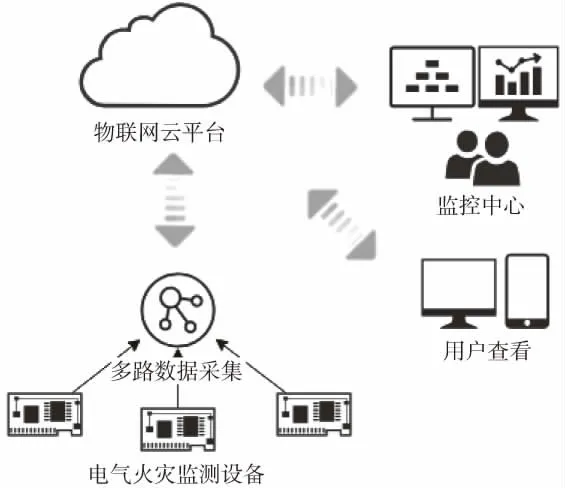
图1 平台架构图
1.1 数据采集
数据采集硬件平台由主控制器、电压传感器、温度传感器、电流传感器、剩余电流互感器、分励脱扣器、蜂鸣器等组成.通过在需要监测区域的配电箱中部署多种传感器对三相电压线缆的各类参数监控,实时采集数据,控制器将数据预处理后发送至云平台.
主控制器采用ARM芯片,控制器主要对上述传感器进行控制,负责数据采集和数据预处理,并通过数据组帧,把数据上传至云服务器.该控制器带有控制按钮、显示面板和指示灯,用户可以根据实际需求对所采集数据进行预警阈值的参数设置,如果数据异常,指示灯将会给与相应提示.
电压传感器用来测量220~380V的交流电压,可在-10℃~70℃的温度中正常工作.本设备对每路电压线缆配一个电压传感器,将采集三相电压传输于控制器中.
温度传感器用来测量线缆温度,本设备将温度传感器直接扎绑于线缆上实时采集3条火线线缆的温度信息,并将温度数据传输于控制器中.
电流传感器工作温度为-25℃~75℃,用于测量3条火线线缆中的电流值,并将电流数据传输于控制器中.
剩余电流互感器可容纳直径30~200mm的电线穿过,工作温度为-12℃~45℃,用于检测电线中剩余电流的大小.根据国家消防部门规定,正常工作的电气设备泄露电流应不大于0.5mA,该设备实时采集剩余电流数据,并将数据传输于控制器中.
分励脱扣器采用MX+OF无源型,工作电压为110~400V,当发生短路,设备故障引起电流过大时,可自动跳闸,从而保护电路设备.
蜂鸣器采用BJ-1高分贝报警器,正常工作电压为220~250V,工作温度为-20℃~70℃,当发生异常情况蜂鸣器将会报警,可以提醒设备管理员及时处理危险.
1.2 数据传输
采用GPRS和Socket技术,对传感器数据进行实时发送和接收.GPRS技术借助运营商网络进行数据联网,可完成数据的发送功能[2].主控制器支持GPRS、RS232和RS485三种接口,本文采用RS485接口用来调试主控制器数据,GPRS模块型号采用SIM800C负责将传感器采集的数据定时发送到云服务器,可由用户设定上传数据频率,默认为60s上传一次[3].图2是GPRS的工作流程图.
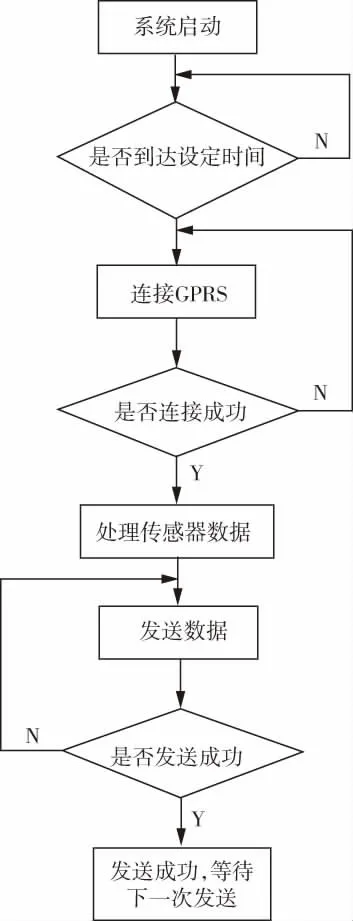
图2 GPRS工作流程图
平台基于TCP网络通信协议,使用Socket套接字完成电气火灾数据的接收并保存至云服务器上的数据库中.同时,为保证客户端和服务器端通信会话的有效性,在正常接收数据的基础之上,结合心跳监测技术使用Socket完成数据的接收及保存.云平台同时接收多个数据采集设备发送的数据,并对不同数据采集设备进行统一管控,保证了电气数据传输的安全性和完整性.
1.3 数据分析
大数据分析平台软件架构基于Hadoop和Spark实现,引入生态圈的多个组件作为此平台的支撑技术.Spark具有强大的处理实时流式数据的能力[4],可对Hadoop上存储的大数据进行计算,满足本平台实时数据分析的需求.
2 数据分析
2.1 数据预处理
平台将三根火线的电流I1、I2、I3,电压U1、U2、U3,温度T1、T2、T3以及剩余电流L分别作为特征值,选取部分数据对电气火灾发生概率p(possiblity)进行预测分析.首先要将信息转换为算法能够处理的形式,将属性中的预警、不预警设为1或0;为方便计算,将电气火灾发生的概率值取对数处理,见式(1)所示:

为查看特征值数据的分布情况,把数据划分训练集和验证集,并统计数据总数count、平均值mean、最小值min、最大值max和分位数等相关信息.表1是数据预处理后的结果.
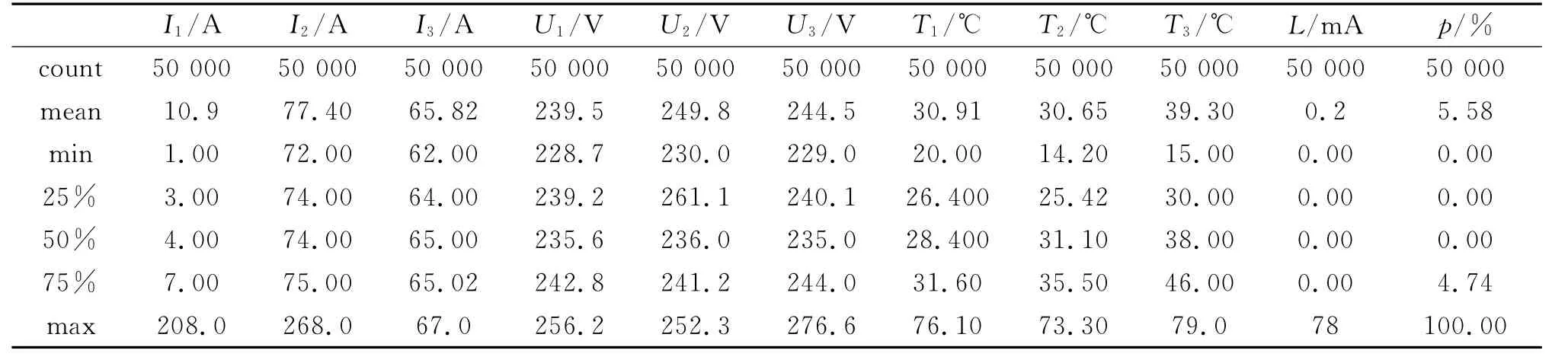
表1 数据预处理表
2.2 标准模型评估
本文采用随机森林、决策树和神经网络三种算法对数据进行了分析,并建立了对应的模型,为对预警模型进行有效的评估,选择以下三个指标进行评价:
2.2.1R2检验
R2检验被称为拟合优度,用于衡量回归方程整体的拟合度,取值范围是0到1之间,值越接近1,说明该模型的结果对于样本的拟合程度越好.R2的计算公式如(2)所示.
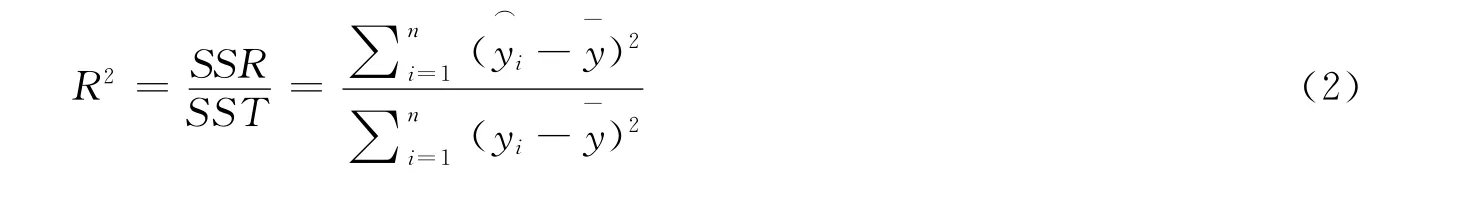
2.2.2 平均绝对误差
平均绝对误差(MAE),该值用来计算预测值同真实值之间绝对误差的平均值,衡量预测值误差的范围.MAE值越小,代表当前算法模型误差越小、性能越好,公式如(3)所示[5].

2.2.3 标准差
标准差是用于衡量一组数据自身的离散程度,该值越小,代表数据集中的数据值与平均值的差异越小,标准差公式如(4)所示.

2.3 随机森林算法预警模型参数优化及结果
在建立基于随机森林算法的电气火灾预警模型时[6],需要对预警模型进行参数优化,以求得最优的实验结果,表2显示的是随机森林算法中常用的每个参数含义及默认值.

表2 随机森林参数介绍表
实验首先按照每个参数的默认值计算,表3是得出的模型评价指标,表中分别列出训练集和验证集的计算数值,从验证集数据可看出使用默认参数的算法模型效果不理想,误差较大.
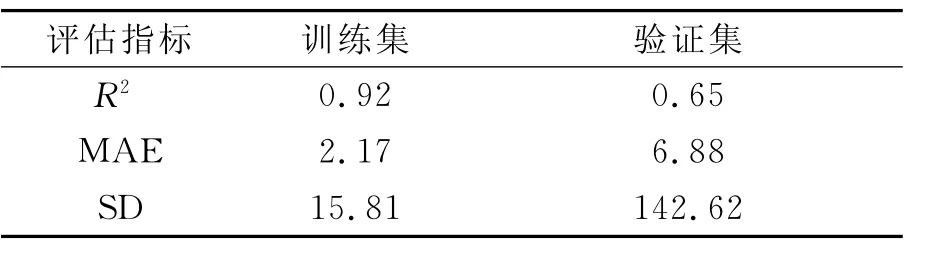
表3 默认参数评价表
接下来对参数进行调整优化,n_estimators范围设置为200至2000,每次增长10;max_depth范围设置为10至100,同样每次增长10;min_samples_split取值设置为2,5,10;min_samples_leaf取值设置为1,2,4.利用RandomizedSearchCV函数进行随机搜索,输出最佳参数值,图3是该函数的搜索过程,当决策树数量大于1800,树最大深度大于70后,拟合优度值与误差值不再发生明显变化.
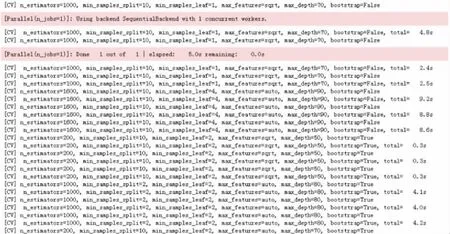
图3 RandomizedSearchCV随机搜索图
最终通过实验表明当随机森林算法预警模型中n_estimators为1800,min_samples_split为2,min_samples_leaf为1,max_depth为70,bootstrap为true时模型效果最好.使用三组不同的数据集在该模型上进行实验,分别得出优化后的预警模型评价指标结果如表4所示,可以看出模型优化后的三组数据拟合优度明显增高,平均绝对误差值减小.
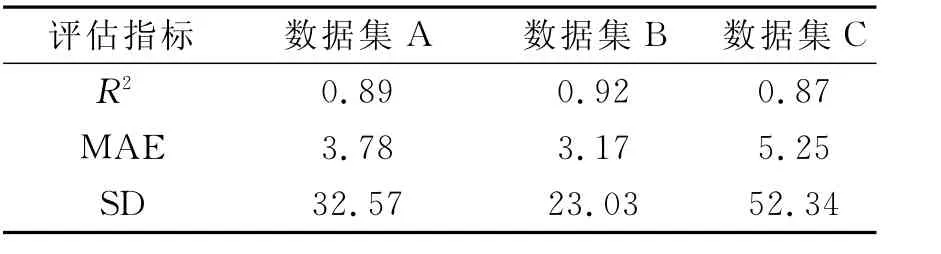
表4 最优参数评价表
图4是通过优化后的预警模型分析得到的,显示了每个特征值所占的比重.从图中可看出电流和温度对于预警结果占较大比重,电压和剩余电流占较小比重,管理员可着重注意电流和温度的变化,当电流值和温度值发生较大的变化趋势,就可能会导致预警事件发生[7].
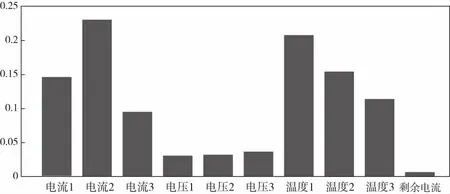
图4 电气火灾特征比重图
2.4 模型性能对比
2.4.1 单机模型性能对比
在单机环境下使用Tensorflow分别得到基于随机森林、决策树和神经网络算法的模型所对应的评价指标,实验分别选取了3组数据进行测试,每组均选择50 000条数据.预警模型性能对比如表5所示.

表5 模型效果评估表

续表5
通过表5数据可以看出,拟合优度值最接近1的是随机森林算法模型,而且该模型的平均绝对误差值与标准差值最小.显然使用随机森林算法模型来预警电气火灾发生的概率效果最好,准确度最高.
2.4.2 Spark集群与单机性能对比
将构建好的随机森林预警模型上传至Spark集群中的Spark Streaming组件中,创建SparkConf对象,设置conf所需要的配置信息,并创建Spark Streaming数据接收器,利用Spark对象读取电气火灾数据并输入到随机森林预警模型中进行计算,得到任务处理结果以及评估结果,采用Spark集群与单机性能对比结果如表6所示[8].
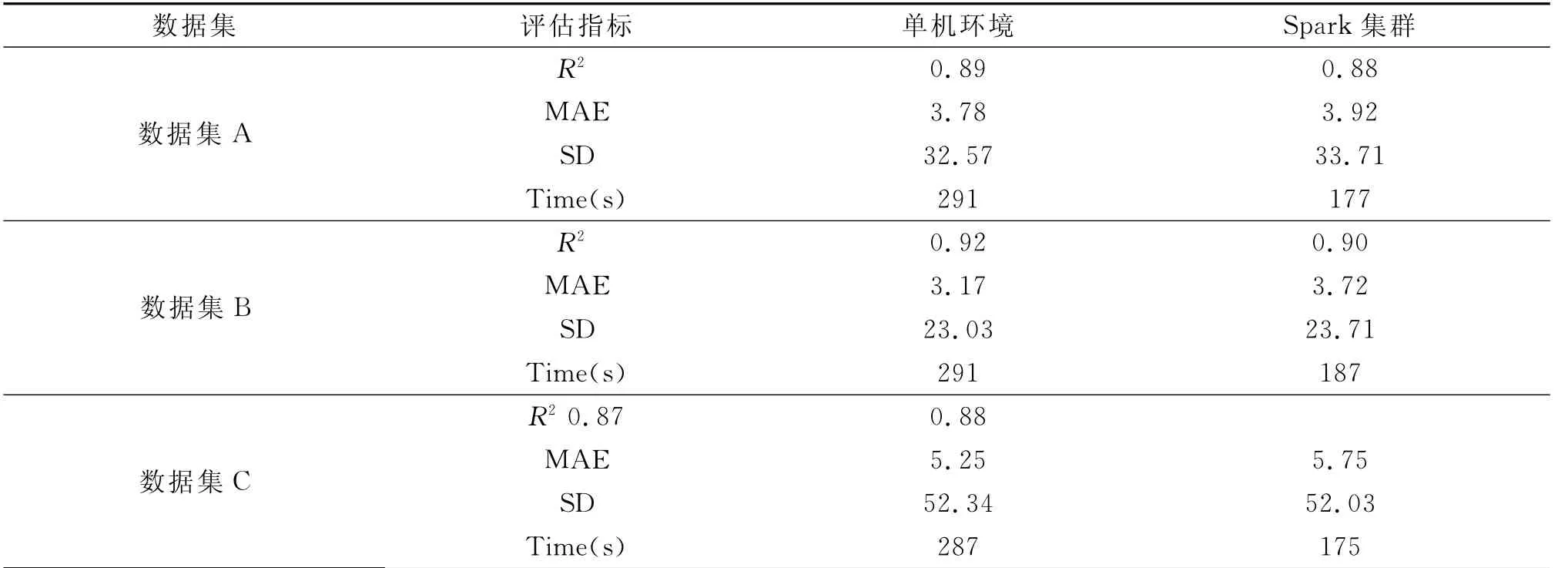
表6 Spark集群与单机性能对比表
通过在Spark集群环境与单机环境中分别运行随机森林预警算法模型,可以从表中数据看出,拟合优度与误差值基本一致,而集群运算速度要快于单机环境,具有较高的稳定性与可靠性.
3 平台实现
电气火灾消防预警平台主要有设备数据管理、大数据分析、监控预警、用户管理四大功能模块.数据管理包括数据采集和数据传输子模块;大数据分析包括数据存储和数据分析子模块;监控预警包括实时监测和异常预警子模块;用户管理包括用户登录和用户权限子模块,各个模块之间功能明确,有效降低了耦合关联程度,有利于程序开发和维护[9].
如图5所示,用户登录平台后,在主界面可看到平台已有的设备数量、设备已采集的数据以及预警数据条数等信息;数据实时监测模块借助百度地图显示各个监测点的情况,分别用蓝、黄、红色表示该监测点数据正常、检测异常、重度异常情况.起火原因统计模块直观显示电气、用火不当、生产作业等起火因素所占比重;平台运行状态模块显示系统工作状态;查看预警数据统计模块显示所有监测点一年中每个月发生预警事件次数.

图5 数据概览图
4 结语
借助窄带物联网、云计算、大数据、移动互联网等新一代信息技术,利用各种智能传感器实时采集各消防信息,并借助大数据平台实时存储和挖掘分析收集到的数据,构建“一张图”的消防预警平台,实现动态感知、智能研判、精准防控.但火灾预警的准确度受到的约束因素较多,比如大气的温度、使用设备的质量及年限等,今后将对相关数据进行融合处理,以便更好地在火灾萌芽阶段及时发现火情[10].
猜你喜欢
经营者(2024年1期)2024-03-30 08:15:09
建材发展导向(2021年12期)2021-07-22 08:06:38
建材发展导向(2021年10期)2021-07-16 07:14:52
今日农业(2019年12期)2019-08-13 00:50:02
现代园艺(2017年22期)2018-01-19 05:07:01
作文评点报·低幼版(2017年8期)2017-03-11 18:34:44
文理导航·趣味课堂(2016年6期)2016-09-09 23:29:34
火控雷达技术(2016年3期)2016-02-06 02:30:27
小说月刊(2014年11期)2014-04-18 14:12:28
河南科技(2014年4期)2014-02-27 14:07:11
