
基于神经网络模型的空气质量预测研究
2021-07-07 03:57金仁浩曾国静
黑龙江科学 2021年12期
金仁浩,曾国静,王 莎
(北京物资学院 信息学院,北京 101149)
0 引言
国内空气质量问题一直受到各界的高度关注,尤其是北方冬季较容易出现的雾霾天气,不仅会导致大气能见度下降,还会增加呼吸道系统疾病的发病率和死亡率[1]。近年来,经过政府的积极治理,华北地区的空气质量得到了显著提升,但大气污染防治工作仍然是一个长期艰巨的过程。当前,各地的环境监测机构和气象部门实时公布当地的空气质量数据和气候条件,对这些数据进行建模分析及预报调控是当下亟待解决的科学问题。
国家环保部从2012年开始采用空气质量指数(AQI),定量描述空气质量状况。AQI是根据SO2、NO2、PM 10、PM 2.5、O3、CO这6项污染物浓度指标计算出来的一个综合指标[2],各地环保部门一般同时会监测和公布这7项指标。目前,对污染物浓度预测的技术主要分为数值模式方法和统计预测两大类。数值模式方法是基于大气物理学、大气动力学和大气化学理论,以污染物移动的动力学模型、污染源详细信息及化学反应模型为基础,可以准确地预测任何指定的、任意地点和任意时间段上的污染物浓度。由于这种方法需要多方面大量的数据来确定复杂方程中的参数,涉及到巨大的计算量,限制了这种方法的广泛应用[3]。然而,统计预测方法不依赖于大气变化机制,仅基于污染物和气象历史数据通过建立统计模型、机器学习或深度学习模型实现对污染物浓度的预测。目前,大型气象研究机构主要采用数值模式方法,而普通研究者往往采用统计预测方法。
国内基于统计预测方法的空气质量预测研究已经相当丰富。譬如:刘慧君利用逐步回归方法对武汉市的PM 2.5指标进行了预测[3]。田静毅等使用BP神经网络模型对秦皇岛市空气质量进行预测分析,预测结果较为准确地拟合了往期的空气质量数据[4]。戴李杰等以上海浦东区的PM 2.5指标为目标变量,以该地区PM 2.5模式预报值和5个气象因子作为输入变量构建支持向量机模型[5]。崔相辉等(2017)以京津冀地区为例,选择气象参数建立基于深度置信网络的PM 2.5预测模型[6]。侯俊雄等利用随机森林算法以PM 2.5模式预报值和气象因子对北京单个监测点的PM 2.5值进行预测[7]。郑洋洋等建立基于深度长短期记忆循环神经网络(LSTM)模型对太原市空气质量指数(AQI)进行仿真预测[8]。上述这些基于统计预测方法的研究往往都得到较高的预测精度,但在模型设置时普遍存在不合理现象。这些研究都以包含当日气象条件或当日其他污染物浓度值的数据为基础来预测当日的 AQI 或 PM 2.5 浓度值。同日的6项污染物浓度指标之间往往存在较高的相关性,且这种预测设置意义较小,因为空气监测站点会同时监测常见的所有污染物浓度,无需再对空气质量进行预测。但仅以往日的污染物或气象数据对下一日空气污染物浓度预测的研究较少尚未检索到,因此本研究尝试填补这一空缺,并分析和比较这种数据设置的模型预测效果。
目前统计预测方法中,神经网络类模型被广泛应用,主要包括有:多层前馈神经网络( BP神经网络)、卷积神经网络、循环神经网络、深度置信网络和模糊神经网络等。其中,BP神经网络是成熟的最常用的神经网络模型,被各种数据分析软件支持,该模型还适合进行短相关的非线性时间序列预测[9]。相较于其他神经网络模型,BP模型对数据量要求不高,适合本研究的数据要求,因此选用BP神经网络对本研究的数据设置效果进行预测效果分析。另外,本研究还选用更受关注的北京空气质量数据作为研究的数据基础。
1 数据和方法
1.1 数据
选用2016年1月1日至2018年12月31日的北京市空气质量数据建立BP神经网络预测模型,空气质量数据来自“中国空气质量在线监测分析平台”(www.aqistudy.cn)。空气质量数据包括北京市 AQI 指数、PM 2.5、PM 10、 SO2、NO2、CO 和 O3的每日均值,本研究选取 AQI 作为目标变量。由于城市的空气质量数据往往与天气状况存在着一定的相关性[7],基于天气数据的可获得性,本研究选取了4种北京天气数据:日最高温(HT)、日最低温(LT)、风速(WNDP)、天气(WEAT)。天气数据来自于“天气后报网”(www.tianqihoubao.com)。
1.2 BP神经网络模型
如图1,BP 神经网络包含一个输入层、一个或多个隐含层和一个输出层,每层包含若干个节点,各层节点通过加权路径与相邻层节点链接。当预测目标变量为分类变量时,输出层包含多个输出结点;但当目标变量为区间型变量时,仅包含一个输出节点。 BP 神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小,是应用最广泛的神经网络,其突出优点就是具有很强的非线性映射能力和柔性的网络结构[9]。
BP神经网络的工作方法主要分为两个过程。第一个过程是信号的前向传播,信号从输入层输入,经过隐含层的计算输出新的权重,最后到达输出层;第二个过程是误差的反向传播,获得的权重从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。简而言之,BP神经网络的核心就是根据得到的结果计算误差,通过反馈误差,不断修改权重和阈值,从而得到误差最小的输出结果[10]。
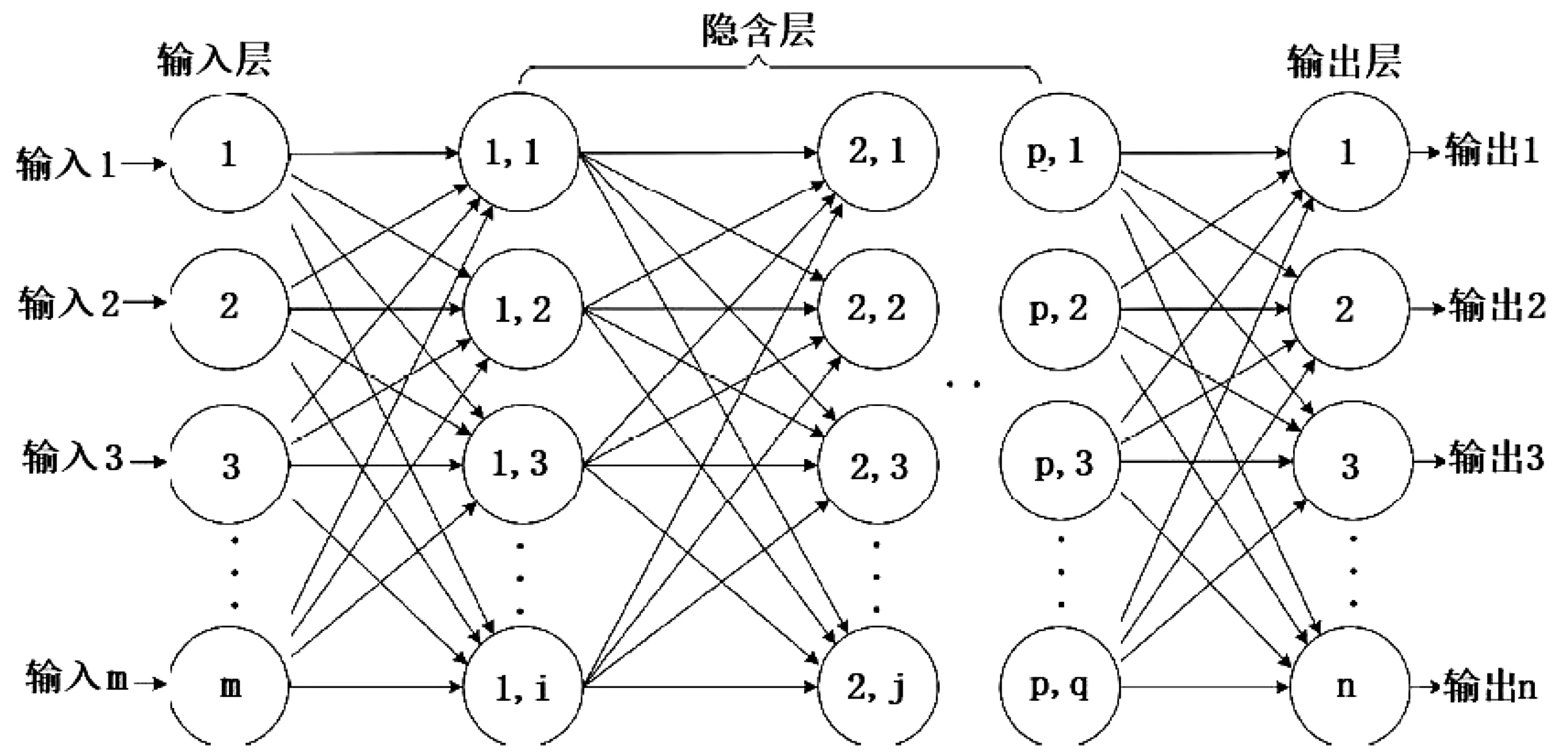
图1 BP神经网络模型Fig.1 BP neural network model
1.3 模型设置
以当日污染物浓度或气象数据对当日 AQI 或 PM 2.5 的预测研究已经比较充分,众多文献显示,多种统计预测方法都能取得较高的预测精度。本研究选取当日 AQI 浓度值作为目标变量,主要研究仅以往日污染物或气象数据实现对当日空气污染物浓度预测的可行性,因此本研究根据模型输入变量的不同设置了3种预测模型,模型变量设置如表1所示。全模型的输入变量包括:当日其他污染物浓度值、当日天气变量、滞后一天 AQI 及其他污染物浓度值、滞后一天天气变量。滞后全模型的输入变量包括:滞后一天 AQI 及其他污染物浓度值、滞后一天天气变量。滞后污染模型的输入变量包括:滞后一天 AQI 及其他污染物浓度值。
本研究构建包含输入层、输出层和两层隐含层的四层BP神经网络模型,输出层的节点仅包含一个神经元,即当日 AQI 值。为了比较不同输入变量对预测效果的影响,本研究对隐含层进行统一设置,两层隐含层都包含8个神经元结点。选用平均绝对误差和平均绝对误差率这两个统计量来衡量模型的预测效果,并将数据集按 7:3 的比例分为训练集和测试集,以模型在测试集上的预测效果来评价模型的优劣。

表1 3种预测模型输入变量设置Tab.1 Input variable setting of 3 kinds of prediction models
2 实证分析
2.1 数据相关性分析
各种污染物的日均变化图与月均变化图所反映的趋势基本一致,但由于日均变化图较为密集,展示效果差,因此本研究仅仅展示月均变化图。各污染物2016—2018年月均浓度变化如图2所示。由于CO和SO2的浓度值尺度与其他污染物相比明显偏小,故与AQI的相关性以散点图形式分别展示,如图3所示。由图2可知,AQI月均指标值与PM 10、PM 2.5、NO2浓度值的变化趋势大体相同,与O3的变化趋势存在一定的滞后性。由图3散点图可得,AQI月均指标值与SO2的相关性较高,相关系数达到0.73;与CO的相关性一般,相关系数达到0.53。

图2 北京市2016—2018年污染物浓度月均变化图Fig.2 Monthly variation diagram of the pollutant concentration from 2016 to 2018 in Beijing City

图3 北京市2016—2018年污染物浓度月均值散点图Fig.3 Scatter diagram of monthly mean value of pollutant concentration from 2016 to 2018 in Beijing City
由表2可知,除臭氧指标外,AQI日均值与当日其他污染物浓度日均值相关系数普遍较高,其中与PM 2.5相关性达到0.97,与PM 10相关性达到0.86,与当日天气指标值的相关性明显偏低,其中与风速指标值的相关性最强,系数绝对值仅仅为0.07。AQI日均值与滞后一日指标值的相关性强度比当日值有一定程度的下降,除臭氧指标外,与污染物滞后值相关性强度一般,与NO2相关性最高达到0.6,与AQI滞后值的相关系数为0.58,与滞后一日天气指标值的相关性有所上升,但依旧不强,其中与风速指标值的相关性最强,系数绝对值仅为0.15。
综合图3和表2信息可知,当日AQI日均值与其他各指标之间均存在一定的相关性,将这些指标作为BP神经网络模型的输入变量存在一定的合理性。

表2 日均AQI值与其他指标当日或滞后1日值的相关系数Tab.2 Correlation coefficient of average daily AQI value and other indexes on the day and one day lag behind
2.2 模型预测分析
根据模型设置进行建模分析,将建模所得预测值与真实值进行比较,可得到对不同模型设置的预测效果进行评估。选用平均绝对误差和平均绝对误差率作为模型预测效果的评价准则,模型计算是通过 SAS EM 软件实现。根据输入变量不同而形成的3种模型预测效果,如表3所示。

表3 北京AQI指数模型预测误差分析表Tab.3 Analytical statement of the model prediction of AQI index in Beijing
由表3可知,基于“全模型”的BP神经网络在训练集和测试集上的预测效果都达到最优,预测效果明显高于“滞后全模型”和“滞后污染模型”。在测试集上,“全模型”的平均误差率仅为5.99%,而平均绝对误差仅为5.23,预测精度较高,说明“全模型”对当日空气质量的预测能力较高。此结果与表2中展示出来的当日AQI日均值与当日其他污染物浓度高度相关的结果一致。然而,“滞后全模型”和“滞后污染模型”的预测效果较差,在测试集上的平均绝对误差率达到45.70%和45.85%,说明仅仅依靠滞后一日的污染物数据或天气数据不能实现对当日AQI指数的准确预测。此结果也符合表2中展示出来的结果,即当日AQI日均值与滞后一日其他变量信息相关性普遍不高。虽然“滞后全模型”比“滞后污染模型”多包含4个滞后天气变量,但在测试集上预测的绝对误差率仅降低0.15%,这主要是因为滞后天气变量与目标变量的相关性都比较低,说明天气变量提供的信息量较少。另外,表3所展示出来的预测效果在一定程度上也符合民众对北京空气质量的真实感官,尤其在秋冬季,比较容易会出现前后两日空气质量等级差异明显的现象。
3 结论与建议
3.1 结论分析
数值模式方法虽然可以精确地实现对空气质量的预测,但该方法对大气变化理论、数据和计算量都有较高的要求,仅适用于大型研究机构,而统计预测模型要求简单,被广泛应用。在统计模型预测研究中,主要以当日气象条件或当日其他污染物浓度值的数据为基础来预测当日的空气质量,虽然能取得较高的精度,但这种预测模型设置实际应用意义较小。尝试仅以往日的污染物或天气数据实现对下一日空气质量预测的统计建模,并分析这种数据设置的预测效果,相关研究结果可总结如下:
(1)AQI 日均值与当日其他污染物浓度日均值的相关系数普遍较高,与滞后一日污染物浓度的相关性强度一般,但与当日或滞后一日天气指标值的相关性普遍较低。
(2)基于“全模型”的BP神经网络对当日空气质量有着较高的预测能力,预测精度较高;“滞后全模型”和“滞后污染模型”的预测效果较差,仅仅依靠滞后一日的污染物数据和天气数据不能实现对当日AQI指数的准确预测。
(3)模型预测结果和相关性分析的结论一致,当日 AQI 的神经网络预测主要依靠当日其他污染物浓度指标,而对滞后一日相关污染物和天气指标的依赖较少。
3.2 研究展望
根据研究内容总结,本研究对空气质量的统计模型预测提出如下建议:
(1)虽然当日其他污染物浓度指标对提高当日空气质量的预测有着较大的帮助,但实际意义较小。建立空气质量统计预测模型,应仅基于历史数据。
(2)历史天气与当日空气质量有着密切的联系,但如何提取出有效的历史天气信息变量用于下一日空气质量的预测仍需进一步的研究。
猜你喜欢
今日农业(2021年11期)2021-11-27
中老年保健(2021年11期)2021-08-22
环境科学研究(2021年6期)2021-06-23
环境科学研究(2021年4期)2021-04-25
少儿科学周刊·儿童版(2021年23期)2021-03-24
小哥白尼·趣味科学画报(2020年4期)2020-10-20
文苑(2020年7期)2020-08-12
动漫星空(兴趣英语)(2018年9期)2018-10-30
汽车与安全(2016年5期)2016-12-01
汽车与安全(2016年5期)2016-12-01
