
大规模空间轨迹数据管理方法研究
2021-07-05 09:38江翠云
地理空间信息 2021年6期
江翠云,吴 然,方 杰
(1.广东省测绘工程公司,广东 广州 510300;2.广州市城市规划勘测设计研究院,广东 广州 510300;3.国家海洋局南海调查技术中心,广东 广州 510300)
随着5G技术的日益成熟,万物互联的概念逐步深入我国各行各业的改革与发展中,这一点在地理空间信息领域影响尤为显著。传统的空间数据获取方法具有流程复杂、耗时较长、成本较高的弊端,在这一背景下,部署简单、耗时短、成本较低的各类新型空间数据获取方法出现,如常见的用户移动终端、船只车辆上的轨迹跟踪设备等,这使得空间数据体量急速膨胀,呈现出大数据所具备的规模性(volume)、多样性(variety)、高速性(velocity)等特点[1],如何更为高效地分析和利用这么大体量的空间数据,提取当中的价值应用到现实实践指导工作中,是当前地理数据分析领域的重点研究任务[2]。
传统的空间数据库在通常的空间数据存储与分析任务中有着较为良好的表现,如常见的PostGIS、Oracle Spatial等空间数据存储框架提供了多种满足OGC标准的空间数据存储与管理,并提供了大量空间运算和分析功能。但在这类基于行式存储架构的数据库在面对空间大数据的存储与分析任务时容易遇到效率瓶颈,特别是在遇到TB级甚至PB级空间数据时,大量的文件 I/O操作使其难以获得满足业务需求的运行效率。针对这个问题,相关学者基于当前主流的大数据框架进行一系列空间特性的改造尝试,较为典型的有基于Apache Hadoop分布式文件系统的内部数据文件存储逻辑实现对空间数据支持的SpatialHadoop[3]框架,以及针对Apache Spark进行改造的第三方框架GeoSpark[4],其中GeoSpark是当前功能较为完善的具备空间特性的第三方大数据框架,但SpatialHadoop作为分布式文件系统下的空间扩展,其空间特性仍旧较弱,只能支持较为基础的空间操作,而Apache Spark虽然基于RDD结构扩展得到了一定的空间特性支持,但其内部计算所采用的空间分区为简单且尺度固定的格网分区方式,仍旧具有一定的优化空间。
本文选取了当前最新的大数据存储框架ClickHouse作为改造目标,其相较于常见的列式存储框架具备更高的运行性能、更丰富的内置类型和表引擎类型,可以支撑复杂的应用场景,但其原生版本缺乏空间特性的支持,无法直接用于大规模空间数据的处理分析任务。本文将基于其存储与索引特性进行空间特性的改造,通过利用其高效的数据存储和索引方式来满足空间大数据的存储与分析需求。
1 基于ClickHouse 的空间轨迹数据管理
1.1 ClickHouse数据库的特性
ClickHouse[5]是一款面向OLAP(联机分析处理)的列式存储数据管理系统,其数据存储方式有别于传统的关系型数据库,每一列的数据作为单独的数据文件进行管理,这种存储方式使得ClickHouse可以针对单列的数据进行压缩存储和索引优化,并且使得其对于大批量数据的写入和检索能够具备极高的效率,而相比于其他主流的大数据存储分析框架,ClickHouse丰富的表引擎和复杂多样的数据类型使得其可以支持更多样、更复杂的数据存储分析应用场景。
VersionedCollapsingMergeTree是ClickHouse中MergeTree族表引擎的一个子类,其特性可以根据数据记录的状态字段与版本字段来实现数据记录的删除与更新,以此弥补ClickHouse不支持直接的数据删除与更新的缺点,其声明方式需要结合到表创建的相关语法中,如式(1)所示。
除了符合SQL标准的表创建语句外,ENGINE项用于声明所要采用的表引擎,Sign与version分别为状态字段和版本字段,而ORDER BY用于声明表的主键,这会涉及到该表数据的存储顺序与索引细节。如图1所示,Row-1和Row-2被指定为2个主键字段,数据会根据主键的顺序,依次对每个主键的值进行排序,根据排序后值的分界节点,各个主键值可以组合成标记,标记会被ClickHouse内部编码成标记号,标记号即为索引的具体样式。当需要对数据进行检索时,利用生成好的标记号可以快速找到需要的数据段。由于这个特性,使得ClickHouse针对主键字段的范围检索和SQL-IN检索等可以具备极高的检索效率,如需要检索Row-1值为A或B,Row-2值为2的所有数据,则根据标记号会定位到标记号范围在内的数据记录。
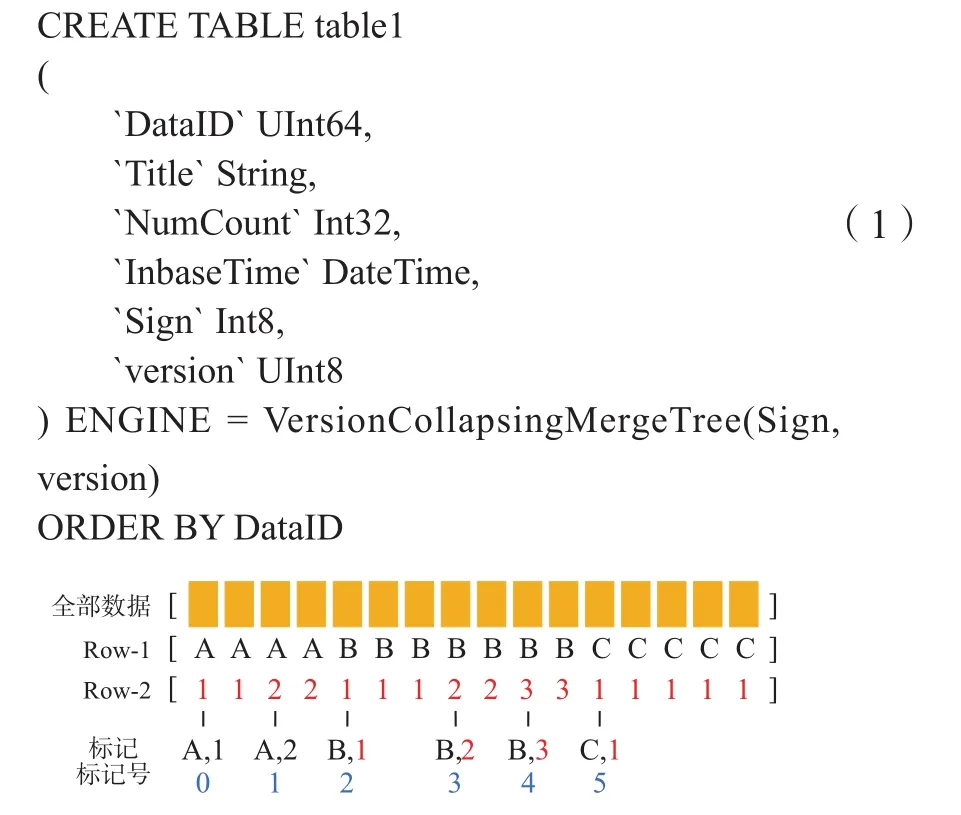
图1 主键排列样式
1.2 基于Geohash编码的空间索引
利用ClickHouse表引擎中主键的特性可以获得较为高效的检索效率,但即使是这样,面对十亿级或百亿级的数据,如果直接进行全量检索或计算,耗时依旧不可观,无法达到快速检索、高效分析的需求。针对这个问题,这里引入了Geohash[6]编码为空间数据构建空间索引信息,该编码是由Gustavo Niemeyer于2008年发明的公共领域地理编码系统,其原理是将二维的地理位置信息编码成为一维的字母和数字,通过引入分层的空间数据结构将空间细分为网络状的桶,通过迭代地对点位所处的经度、纬度进行对半分割,直到约定的最高层级。
Geohash编码对地理空间的区域性描述具有一定的优越性,从其编码方式可以看出,编码的长度越长,其所代表的经纬度范围越小,即表达的位置就越精确,根据这个特点可以限制需要选取的空间数据范围来避过大量与检索或计算无关的数据。除了编码长度正比于表达精度外,Geohash编码在空间中体现为具有一定规律性的分布曲线,这种空间分布曲线被命名为Peano空间填充曲线[7],该曲线具有在任意层级的分割单元内呈现出连续不突变的特点,如图2所示,A区域和B区域分别处于第一层级和第二层级的分割单元内,Peano空间填充曲线在其中呈现连续不突变的特点,而C区域和B区域则存在突变的状况。连续不突变的特点可以利用在空间数据检索中对检索范围进行简化描述的作用。

图2 Peano空间填充区曲线示意图
1.3 轨迹数据存储模型
本文研究的数据源为轨迹类型数据,常见的轨迹数据为车辆的行车记录轨迹数据、船舶的运动轨迹数据及人的运动轨迹记录数据等,这些数据相比于传统的测绘数据没有很高的精度要求,产生速度极快,通常为一系列的点记录和属性记录,且通常不具备固定的格式。如AIS船舶轨迹数据可以以CSV文件的格式进行数据,如表1所示,可见其空间信息为经纬度分离的存储方式。
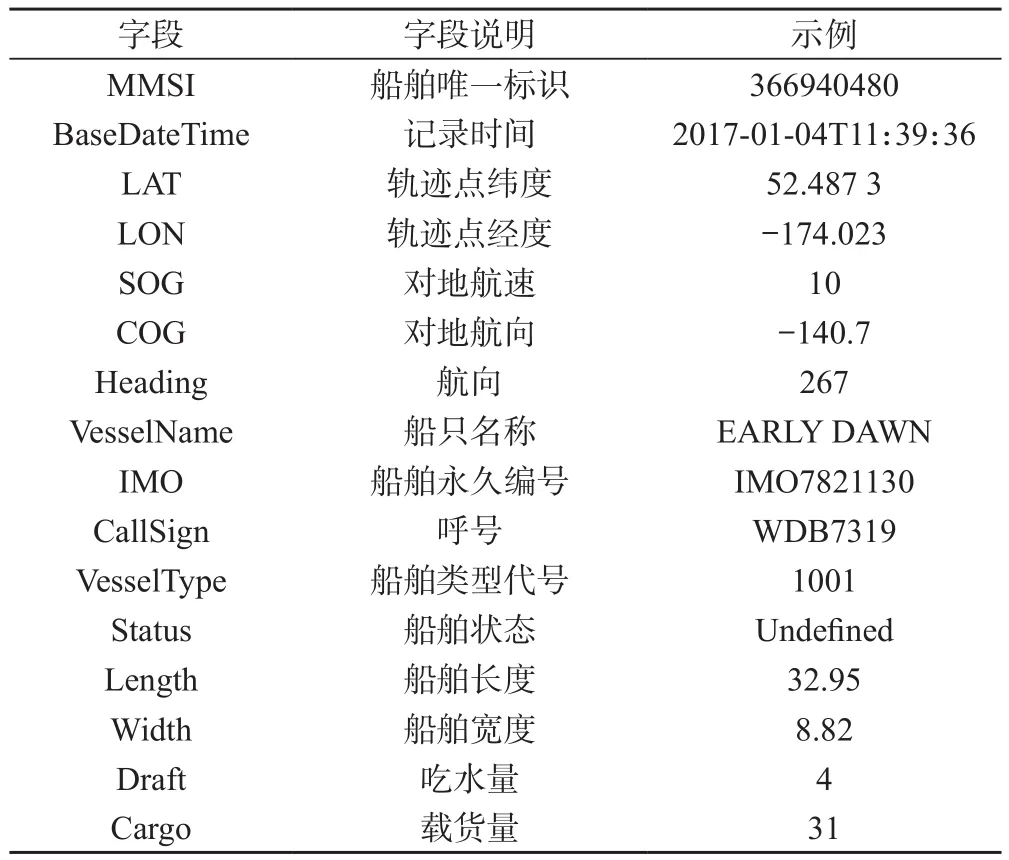
表1 AIS船舶轨迹数据示例
考虑到轨迹类型数据通常的存在方式,本文所采用的轨迹数据存储模型为经纬度分离的存储方式,经度和纬度分别采用一个字段进行存储,而Geohash空间索引信息也单独采用一个字段进行存储,且该字段需要约定设置为表的主键,以在利用空间索引进行检索时能够提升检索效率。在本文存储框架中,Geohash编码采用32位整型数来存储,如图3所示,其中采用前30位存储空间分割信息,也即整体对空间进行15级分割,这样的方式可以避免整型数由于符号位被更改造成正负值的突变。
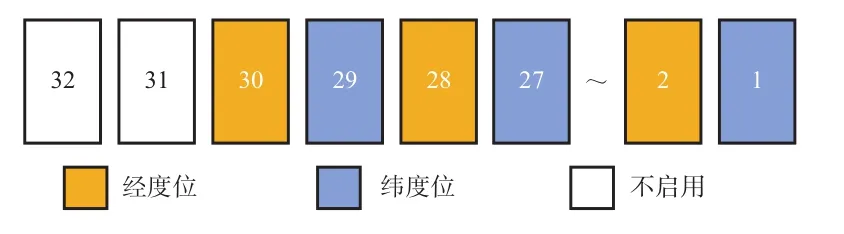
图3 Geohash编码存储规则
1.4 大规模轨迹数据检索
本文采用的轨迹数据检索方式需要借助轨迹数据记录中的Geohash空间索引信息进行,Geohash索引编码值在空间中体现为一个个单独的空间小单元,通过把检索区域转换为这些空间小单元的集合来对轨迹数据进行检索,即可获得满足要求的数据记录集合,且充分利用到了表引擎主键的源生索引来提高检索效率。针对不同的检索范围大小,本文将检索情况分为小范围检索和大范围检索。
1.4.1 小范围空间检索
轨迹点数据小范围检索的实现方式是本文基于Geohash编码索引进行数据检索原理的直接体现,将检索空间范围通过Geohash编码序列表达出来,如图4所示。在SQL语法层面来看,这个Geohash编码序列为整型数组,通过SQL-IN语法,可以对主键字段即Geohash空间编码索引字段进行检索,空间索引值落入编码序列范围中的数据记录会被筛选出来,如式(2)所示,为检索范围所转化得到的Geohash编码索引序列。
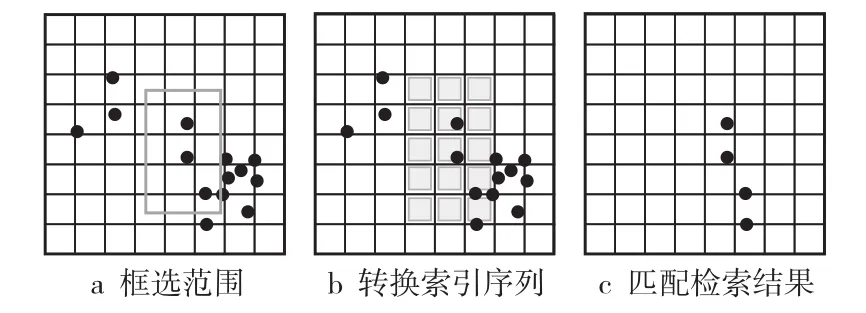
图4 小范围检索示例
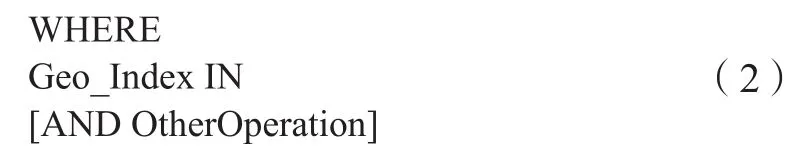
理论上,小范围检索所采用的SQL-IN检索方式可以获得很高的检索效率,通常在10亿级的数据下,表现可以达到几十毫秒,基本可以满足交互式检索的需求。但是这种检索方式在面对大范围检索时,由于范围内Geohash编码单元过多,会使得整体的检索效率严重下降,所以针对大范围检索无法再直接简单地采用SQL-IN语法来支持。
1.4.2 大范围空间检索
轨迹数据的大范围检索需要解决的问题是检索范围内大量的索引单元的表达问题,这个问题可以利用Peano空间填充曲线在任意层级下分割子单元内连续的特点来解决,由于其具备连续的特点,对应的Geohash编码信息的32位整数也是连续的整型序列,可以利用这个序列中的最大值和最小值来表达其中所有索引值的范围,而最大最小值的获取方式如图5所示,将当前层级已标记的位之后的位置为0即可获得最小值,置为1即可获得最大值,分别对应分割单元的左下角和右上角。
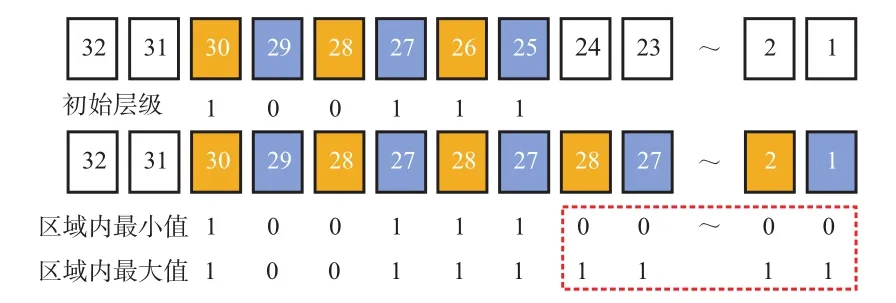
图5 最大最小编码值获取示例
如图6所示,首先基于检索区域确定其所囊括在内的子分割单元,获得分割单元的方法可以利用检索范围长宽平均值与每一个层级下分割单元的大小进行比较,选择略小于长宽平均值的分割单元大小对应的层级为生成子分割单元的层级,这样可以尽可能精确地表达检索范围,避免大量无关的索引单元被用于检索。确定了分割子单元后,分别将子单元用各自的最大最小值表达,把最大最小值转换为针对空间索引字段的范围检索语句(如式(3)所示)来对数据进行检索,即可得到满足检索要求的结果。
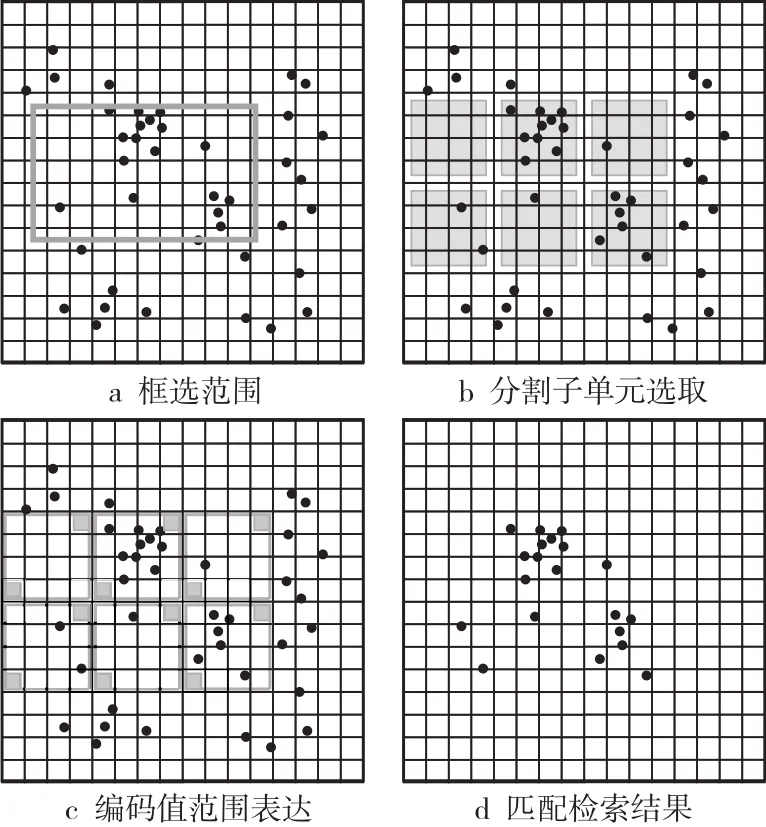
图6 大范围检索示例

2 实验分析
为了验证本文基于ClickHouse的空间轨迹数据管理方案是否相较于传统的空间数据存储框架具有更高的检索与分析效率,选取了典型的AIS船舶轨迹数据作为对照实验的数据集作为效率对比,选取了PostgreSQL+PostGIS空间数据存储框架来进行对比实验,实验主要分为小范围检索与大范围检索,同时检查2种检索场景下的实际效率情况。
2.1 实验环境与数据
为了满足以上实验设计需求,本文准备了如表2所示的实验环境,PostGIS服务器与ClickHouse服务器均采用相同配置的单节点部署方式部署。

表2 实验环境
本文所采用的实验数据为在公开网络获取的AIS船舶轨迹点数据(https://coast.noaa.gov/htdata/CMSP/AISDataHandler/2017/index.html),数据压缩包大小约30GB,解压后为Excel格式的文本类型数据集,入库到数据库中总计约10亿条数据记录,其中包含了较为丰富的字段信息。
2.2 轨迹数据检索效率分析
轨迹数据检索效率分为与传统空间数据库的效率对照实验和不同检索大小范围下的效率对照实验。
与PostGIS的对照实验执行方式分别按照小范围检索(0.001°~0.1°)与大范围检索(大于0.1°)的标准在空间内随机划定检索范围,根据检索耗时计算平均值。如图7所示,无论是小范围检索还是大范围检索下,ClickHouse对大规模轨迹点数据的检索效率都明显优于PostGIS,耗时仅为PostGIS的7%~12%左右。
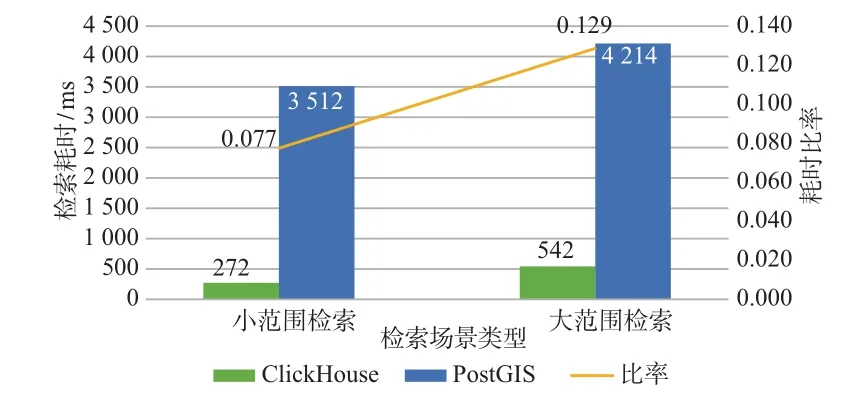
图7 ClickHouse与PostGIS对比实验
对于ClickHouse在不同检索大小范围下的检索效率,采用的实验方式是在空间范围内分别随机按照0.001°、0.01°、0.1°、1°的大小标准划定检索空间范围,并分别计算各种大小标准下的平均耗时情况。如图8所示,检索大小范围在0.001°~0.1°标准内的耗时呈现小幅递增的分布,耗时基本能够维持在毫秒级以内,而当检索大小范围在1°标准或1°以上时,耗时激增至秒级,主要原因是大范围检索中首先需要确定分割子空间单元,而当范围大小标准越大时,分割子空间单元中无关的Geohash编码单元就会越多,这导致后续精检索需要执行的计算就越多,而且精检索过程并没有通过ClickHouse的原生索引进行优化,从而导致整体耗时变长。
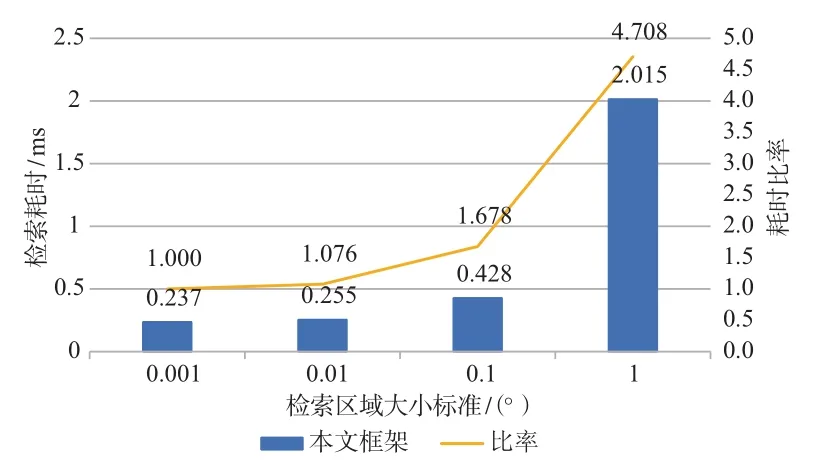
图8 不同检索大小范围的效率实验
3 结 语
本文主要基于当前空间大数据存储与分析遇到的问题,结合最新的大数据存储框架ClickHouse进行空间特性改造,其中融合了Geohash空间索引的构建思想,并将空间轨迹数据的检索分为2种典型场景进行设计。与PostGIS空间数据库的检索效率对比实验中,基于ClickHouse的空间大数据存储框架具备更为优越的检索分析效率,且在不同大小的检索范围下都有较为客观的效率表现。
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
专利代理(2016年1期)2016-05-17
测绘科学与工程(2016年4期)2016-04-17
测绘科学与工程(2014年2期)2014-02-27
测绘科学与工程(2013年1期)2013-03-11
测绘科学与工程(2013年1期)2013-03-11
质量与标准化(2010年5期)2010-05-03
