
基于卷积神经网络的生活垃圾图像分类模型设计
2021-07-03 10:50:04王晓峰黄飞龙文冠鑫苏盈盈
重庆科技学院学报(自然科学版) 2021年3期
秦 浩 王晓峰 喻 骏 黄飞龙 文冠鑫 苏盈盈
(1. 重庆科技学院 电气工程学院, 重庆 401331; 2. 重庆科技学院 数理与大数据学院, 重庆 401331)
对生活垃圾进行分类收集和处理,有利于保护环境、节约资源。利用图像识别分类技术对生活垃圾进行分类,目的是实现对生活垃圾类别的高效、快速、精准识别。目前,在这方面的研究已取得了一些成果。吴健等人设计了基于计算机视觉的实验室垃圾分析与识别方案[1];吴碧程等人提出了基于卷积神经网络的智能垃圾分类系统[2];汪洋等人提出的基于卷积神经网络的垃圾分类系统,对7种生活垃圾进行分类,准确率可达91.71%[3]。本次研究,我们针对图像出现阴影遮挡、暗光、模糊等复杂情况,引入Retinex算法[4],并通过改进VGG-16[5]卷积神经网络模型,构建了一种可适应多种类生活垃圾的智能分类模型。
1 垃圾图像分类方法设计
1.1 数据集的获取
据《生活垃圾分类标志》(GB/T 19095 — 2019),生活垃圾分为4个大类:可回收物、有害垃圾、厨余垃圾(湿垃圾)和其他垃圾(干垃圾)。目前,还没有公开的垃圾分类识别实验数据集。我们研究使用的生活垃圾图像数据,主要通过网络爬取和摄像机拍摄2个途径获得。数据集中共有77 656张图片,其中将有害垃圾分为12个小类,可回收垃圾分为136个小类,厨余垃圾分为48个小类,其他垃圾分为47个小类,共计243种生活垃圾类别。每张图片的格式全部处理为JPEG格式。同时,对获得的数据进行标记、整理,制作成一个多种类的生活垃圾图像数据集(见图1)。

图1 生活垃圾图像样本
1.2 数据集的划分
在训练集的处理上,采用十折交叉验证(10-fold cross-validation),测试改进模型的准确性。将77 656张生活垃圾图片分成均等的10份,对其编号;轮流将其中的9份作为训练集,1份作为测试集。每进行一轮实验都会得到相应的正确率,将10次实验测得的正确率平均值作为分类模型的精准度评价指标。
在验证集的处理上也实行交叉验证,从10份数据集中轮流抽出1份作为验证集,其他9份作为训练集。循环验证,直到每份都被作为验证集使用过。对每次训练结果的精度做精准记录,通过计算精准度平均值,保留精准度最高的模型,并将该模型的权重、超参数作为最终模型的权重和超参数。十折交叉验证过程如图2所示。
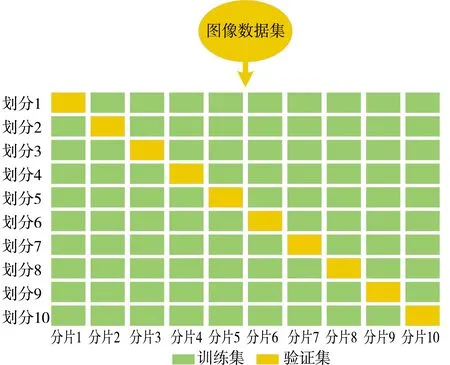
图2 十折交叉验证划分
在测试集的处理上,用了7 059张图片对改进的VGG-16卷积神经网络模型分类精准度进行检测,进一步验证模型的准确率和泛化能力。
1.3 图像数据的处理
为了保证模型检测结果的稳定性和准确性,针对拍摄采集图像过程中由于光线、视角等因素导致的阴影遮挡、暗光、模糊等复杂情况,引入Retinex算法,在图像动态范围压缩、边缘增强和颜色恒定3个方面进行处理,增强图像自适应性。将照射图像估计为空间平滑图像,以(x,y)为像素点坐标,原始图像为S(x,y),输出图像为R(x,y),亮度图像为L(x,y)。以exp表示指数函数。将对数域r(x,y)图像输出转化为实数域R(x,y)图像输出。Retinex算法流程如图3所示。

图3 Retinex算法流程
由图3可知,原始图像、反射图像、亮度图像满足式(1)。
S(x,y)=R(x,y)*L(x,y)
(1)
对式(1)进行两边同时取对数变换,得初始图像对数域输出表达形式:
(2)
为了对原始图像进行增强处理,引入中心环绕函数F(x,y)即高斯核函数,如式(3)。
(3)
式中:λ为归一化常数;c是高斯环绕尺度因子。由于高斯核函数的二重积分为1,λ满足式(4)即可。
∬F(x,y)dxdy=1
(4)
通过式(3)的高斯核函数和式(2)中的初始图像,可得改进后的图像对数域和实数域输出形式:

(5)
(6)
式中:R(x,y)为输出图像实数域形式;K指中心环绕函数的个数,取值为3,意将原始图像从小、中、大3个尺度分别对图像边缘细节、色彩范围、平衡色彩进行处理;⊕指卷积操作;wk为中心环绕函数的权重系数。
实验结果表明,当中心环绕函数的权重系数w=0.11,高斯环绕尺度因子c=15时,对处理图像暗光环境有较好的效果;当w=0.06,c=80时,对处理模糊图像的效果较为明显;当w=0.05,c=120时,对处理阴影遮挡图像的效果较好。通过Retinex算法处理阴影遮挡、模糊、暗光图像的效果如图4所示。

图4 以Retinex算法对图像的处理效果
1.4 垃圾图像分类识别过程
在训练过程,利用改进后的VGG-16卷积神经网络对输入的生活垃圾图像特征进行提取。通过迁移学习,利用ImageNet上预训练的VGG-16模型前4个卷积块的权重参数,初始化本次研究模型的前4个卷积块的卷积核大小、卷积核数量、神经元、权重参数,同时使用大量生活垃圾图像数据对模型进行训练,更新权重参数,得到针对生活垃圾智能分类的最优权重参数。模型训练过程如图5所示。
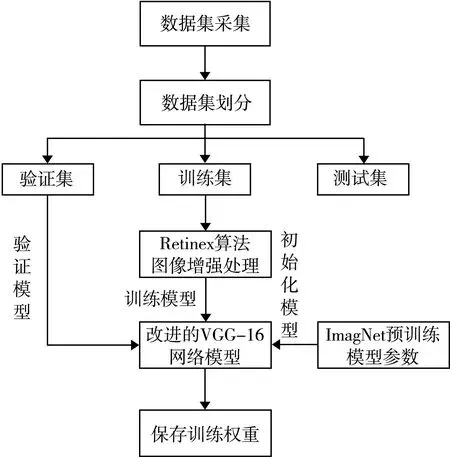
图5 模型训练过程
在测试过程中,首先加载训练的最优权重参数,然后将测试集作为模型输入,预测得到与有害垃圾、厨余垃圾、其他垃圾、可回收垃圾对应的分类结果。模型测试过程如图6所示。

图6 模型测试过程
2 网络模型设计
VGG-16卷积神经网络包含13个卷积层、5个卷积块、1个池化层、1个全连接层,通过相互交叉堆叠的方式连接在一起(见图7)。这样的方式,既使得网络参数在一定的可控范围之类,又使得网络达到了一个较为深层次的深度,提升了网络模型针对图像分类的准确度。

图7 VGG-16卷积神经网络结构
现以一张224×224像素的可回收垃圾图像为例,说明其在VGG-16模型中的处理流程。首先,图像依次经过VGG-16模型的5个卷积块,在每个卷积块中通过5×5和3×3的卷积核以及2×2池化核进行卷积、池化操作,对其特征进行提取。此时,图像的像素由224×224缩小为7×7。然后,经过全连接层将提取到的所有特征图融合,同时将第5个卷积块池化后的图像数据压平为一维向量,计算出分类的评估值。最后,通过Softmax分类器将全连接层的图像数据进行映射,得出图像类别的概率得分,从而实现对图像的识别分类。
对于有4个大类243个小类的多种类生活垃圾图像,为了防止分类模型出现过拟合情况,导致分类准确率下降,我们对VGG-16卷积神经网络的分类交叉熵损失函数进行了改进。原来的损失函数定义形式如式(7)。
(7)
式中:Lorg表示分类交叉熵损失函数;N代表样本总数;αnm为标注真实值的第n个样本的第m个属性的值,采用one-hot编码;ynm是网络预测值第n个样本的第m个属性值;i表示样本上限值;j表示样本属性上限值。
为了增强模型泛化性能,防止模型出现过拟合的情况,引入L1正则化和L2正则化,构建针对生活垃圾分类的新损失函数。
仅使用L1正则化构造损失函数,即是在原损失函数后面加上一个L1正则化项,如式(8)。仅使用L2正则化构造损失函数,即是在后面加上一个L2正则化项,如式(9)。
(8)
(9)
式中:β是损失函数和正则项之间的调节系数;n为模型训练集的样本数量;δ为模型的所有权重参数。
从公式上看,仅使用L1正则化构建的损失函数,为了保证损失函数快速收敛,是对所有的权重参数给予相同的惩罚力度,将导致趋于0的权重参数在被惩罚时变成0;仅使用L2正则化构建的损失函数,是对权重参数较大的给予了很大的惩罚力度,而对权重参数较小的给予很小的惩罚力度,将导致趋于0的权重参数不被惩罚。为提高模型分类精准率,防止模型过拟合,对式(7)的损失函数Lorg进行改进,提出新的分类交叉熵损失函数Lnew。
(10)
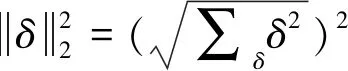
(11)
(12)
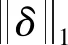
在改进后的损失函数中,如果p=0,则退化为L2正则化;如果p=1,则退化为L1正则化。测试表明,当t=0.76,p=0.54时,能够同时兼顾L1和L2正则化,降低模型的过拟合,提高分类精准率。
在模型训练过程中,有很多训练的图像数据特征具有共线性,它们对于分类来说都非常重要。而L1正则化随机提取其中一个特征,丢弃其他特征;L2正则化只是在图像特征呈现高斯分布时进行均值选择。因此,通过实验对比,我们在原始损失函数Lorg上,先引入L1正则化进行特征选择,再引入L2正则化处理共线性的图像特征。通过这种级联的方式,将其权值平分给各种图像特征,保留有用的图像特征,从而防止模型出现过拟合情况,提升模型准确率和泛化性能。
3 实验及结果分析
为避免实验环境因素造成分类模型效果的差异,所有对比实验均在相同的软硬件配置条件下进行:采用Windows10系统,显卡为GeForce GTX 1650 with Max-Q,开发环境为Pycharm2020、Python3.7,深度学习框架为Tensorflow2.0,图像加速器为CUDA10.0/CUDNN7.6.5。
为了验证设计的垃圾图像分类方法的分类效果,将数据增强前后、损失函数修改前后与原VGG-16模型的准确率和损失值进行对比。分类模型评估结果如表1所示。
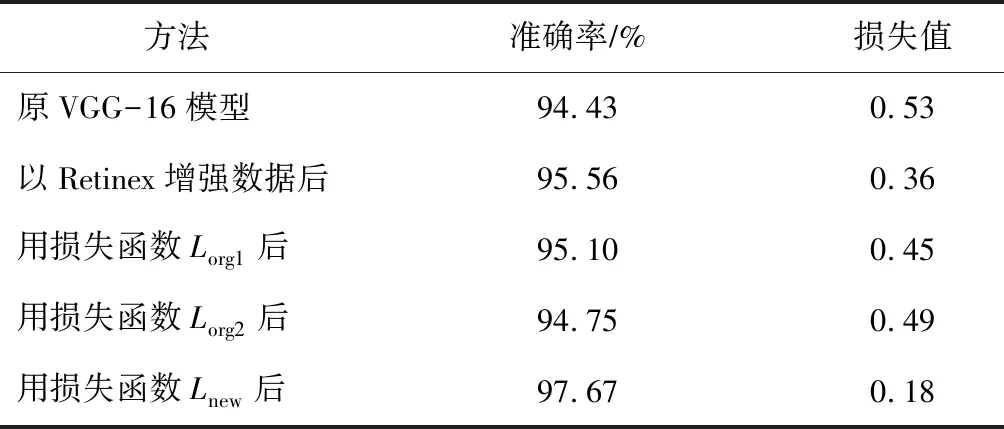
表1 分类模型评估结果
使用原VGG-16网络模型对垃圾图像进行分类,准确率为94.43%,损失值为0.53;引入Retinex算法,对图像进行增强处理后,准确率为95.56%,提升了1.13个百分点。在损失函数中加入L1或者L2正则化后,分类准确率较原网络模型有较小幅度的提升。采用改进后的交叉熵损失函数之后,分类准确率达97.67%,较原网络模型在图像数据增强后的准确率又提升了2.11个百分点;损失值为0.18,也下降了一半。通过引入数据增强算法和改进损失函数,模型防止了过拟合情况,提升了泛化性能和分类准确率。
4 结 语
在生活垃圾分类中,采集的垃圾图像难免存在模糊不清、暗光荫蔽、阴影遮挡等情况。采用基于深度学习的VGG-16卷积神经网络模型对垃圾图像进行识别分类,可以取得较高的准确率,但该模型原用的交叉熵损失函数会导致模型过拟合,降低了模型性能。针对垃圾图像数据的多样性,引入Retinex算法,对存在遮挡、暗光、模糊问题的图像进行增强处理;同时改进损失函数,加入正则化项,提升了模型在垃圾图像检测分类上的准确率和泛化性能。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
今日农业(2019年15期)2019-01-03 12:11:33
数学杂志(2018年5期)2018-09-19 08:13:48
中国交通信息化(2018年5期)2018-08-21 03:37:40
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
