
基于CiteSpace的国内语料库翻译学研究的可视化分析(1996—2020)*
2021-07-02 00:50王明树
成都大学学报(社会科学版) 2021年3期
郑 茜 王 钤 王明树
(四川外国语大学,重庆 400031)
描写性翻译研究摆脱了传统译学研究的规约性本质,主张翻译研究的实证性特点,通过对翻译现象进行描写,总结出普遍性的规则,进而对翻译现象进行解释。语料库语言学是“以语料库为基础的语言研究方法”[1],旨在“揭示隐含的普遍规律”[2]。随着语料库语言学进入翻译研究,“数据驱动的定量分析方法”[3]与描写性翻译研究不谋而合,逐渐形成了新兴的“语料库翻译学”。
语料库翻译学以语言学理论和翻译理论为指导,借助概率和统计手段,围绕双语真实语料进行历时或共时的翻译研究。[4]Mona Baker教授在1993年发表的文章CorpuslinguisticsandTranslationStudies:ImplicationsandApplications,标志着语料库研究范式正式进入译学研究。[5]111随后众多国内外学者开始围绕这一话题进行探讨,引起了一波热潮。本文借助文献计量工具CiteSpace(引文空间)对1996—2020年发表在国内核心期刊上的文献进行科学图谱的可视化分析,以发现国内语料库翻译学研究在核心研究圈的研究现状、热点话题、关注重点和存在的问题等,进而提出相关建议。
一、研究工具和数据来源
本文的研究工具为美国德雷塞尔大学知识可视化与科学发现联合研究所的陈超美博士开发的CiteSpace软件。“CiteSpace是应用Java语言开发的一款信息可视化软件,它主要基于共引分析理论(co-citation)和寻径网络算法(pathFinder)等,对特定领域文献(集合)进行计量,以探寻出学科领域演化的关键路径及其知识拐点,并通过一系列可视化图谱的绘制来形成对学科演化潜在动力机制的分析和学科发展前沿的探测。”[6]244
本文所用数据为发表在国内核心期刊上与语料库翻译有关的论文。借助中国知网的高级检索功能,输入关键词“语料库”,并含“翻译”,选择期刊来源为SCI、核心期刊、CSSCI,检索获得1215条结果。因其中包含众多不符合条件的文献,将其手动剔除,获得659条有效文献。检索结果中第一篇与语料库翻译相关的文献起始时间为1996年,因而将本文研究的时间跨度限定为1996—2020年。
二、数据分析
首先将从中国知网下载的659条数据进行年发文量的大致分析以观察国内语料库研究的走势。然后将数据导入CiteSpace转换为符合该软件的处理格式后,新建项目进行可视化,选择时间期限为1996—2020年,时间切片为1年,阀值选定为50,依次对作者、机构、关键词进行可视化图谱共现,以发现国内语料库研究的领头作者、机构、研究领域和相关热点等。
(一)发文量
将659条数据导入Excel表格可以快速定位每年的发文量,依据年发文量绘制曲线图可以推导出1996到2020年间国内语料库翻译研究在核心研究圈的走势(如图1)。图1所显示的年发文量呈波动增长,依据曲线图走势,可将核心研究圈的国内语料库翻译研究分为三个阶段:起步阶段(1996—2001)、低缓阶段(2002—2008)、发展阶段(2009—2020)。
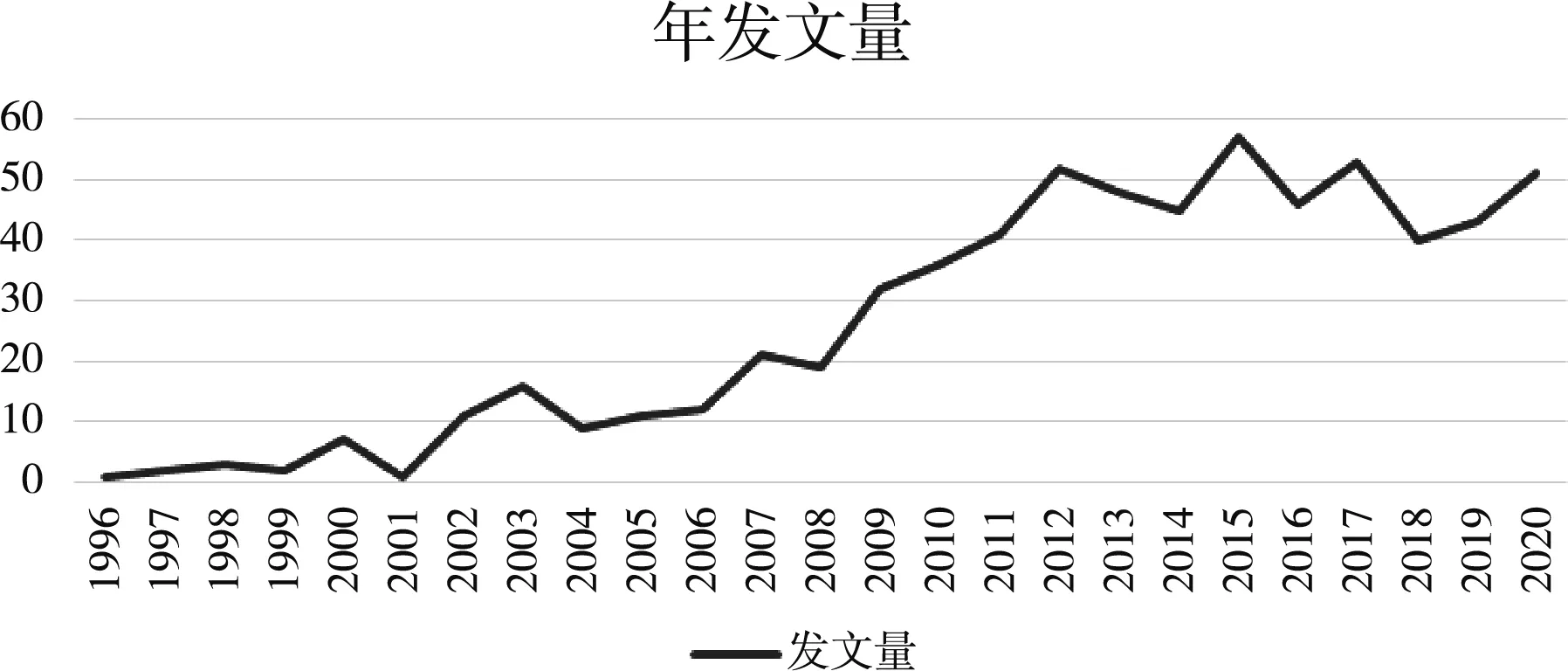
图1 年发文量曲线图
起步阶段的6年间核心期刊每年发表的论文数量为1-7篇,总数为16篇,年均发文量为2.7篇,发文量的基数较小,语料库翻译学受核心研究圈的关注度还不够。低缓阶段的7年间核心期刊每年发表的论文数量为9-19篇,总数为99篇,年均发文量为14.1篇,较起步阶段取得了一定进展,但是发展缓慢。发展阶段的12年间核心期刊每年发表的论文数量为32-57篇,总数为544篇,年均发文量为45.3篇,发文基数较低缓阶段取得了较大增长,说明语料库翻译学开始受到较多核心圈学者的关注,并呈现起伏发展的态势。
(二)研究者
借助CiteSpace软件对659条数据选择节点类型(Node Types)为作者(Author)的可视化图谱分析,得到图2。图2左上角的黑体字显示了相关数据,重点关注其中的“N=590,E=445”这两项数据。其中的“N”代表节点(即图中的圆圈),圆圈和字号的越大,作者在659条数据中出现的频次越高,“E”代表连线;节点之间的连线代表作者之间的联系,连线越粗,说明他们在同一篇文献中共现的频次越高[7],由此可以看出作者之间的合作关系。作者合作图谱中出现了590个节点,连线仅为445条,从图中也可以直观地看出各作者之间连线较少,几个突出的作者(如王克非、胡开宝、秦洪武、黄立波等)间的连线也较少,说明研究者之间缺乏合作。
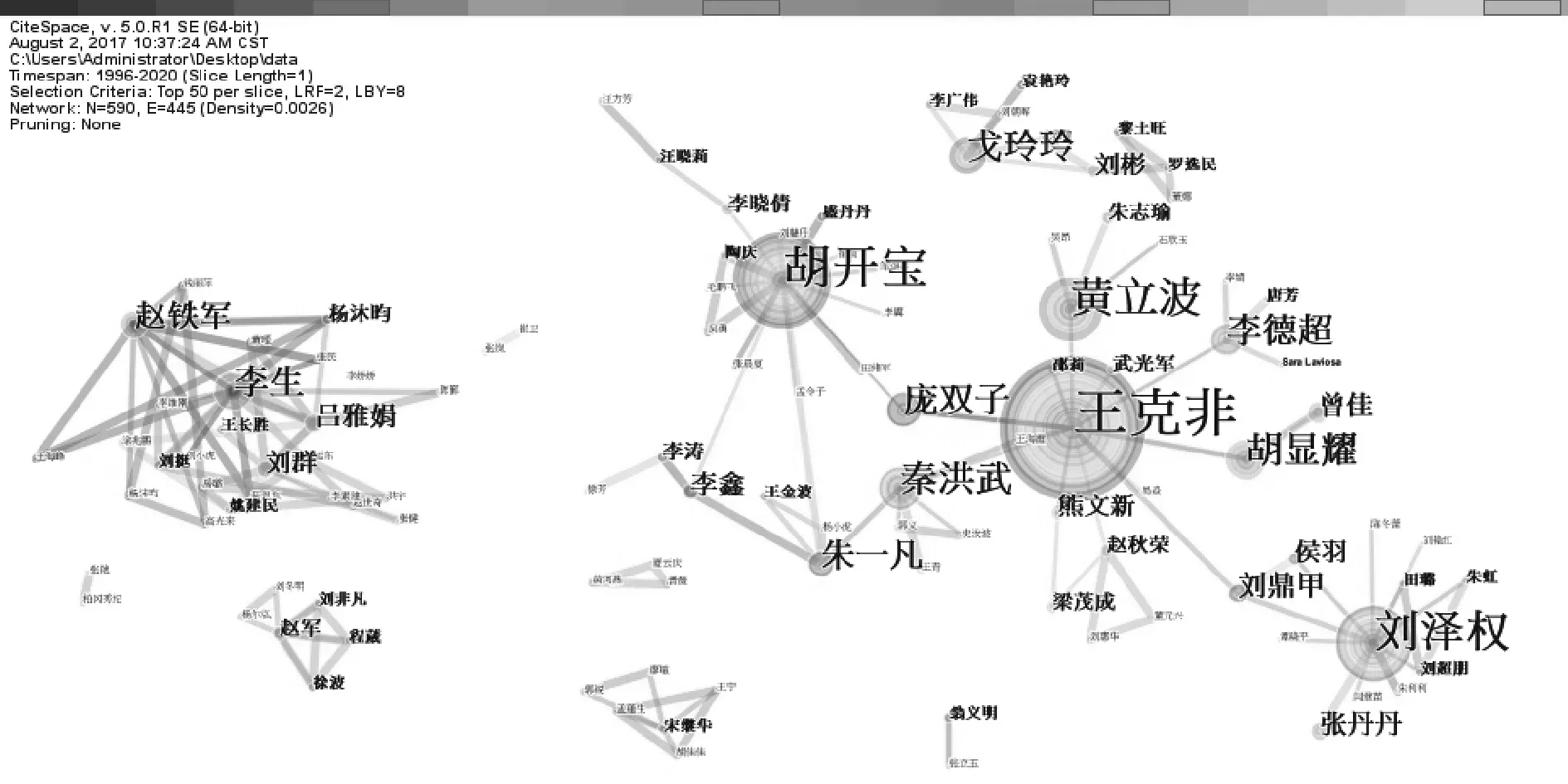
图2 作者合作图谱
借助CiteSpace中显示的有关作者的分析数据,截取前10位高产作者的数据并制成表格,可得到如表1所示的结果。其中王克非、胡开宝、刘泽权、黄立波、秦洪武在核心期刊发表的文献较多,最后3位作者发表的文献数量皆为9篇。这10位作者之外的作者发表的文献数量绝大多数在1-5篇。结合图2可看出国内语料库翻译研究呈现出单核心的发展模式[5]115,少数核心成员占据重要地位,发挥着举足轻重的作用。
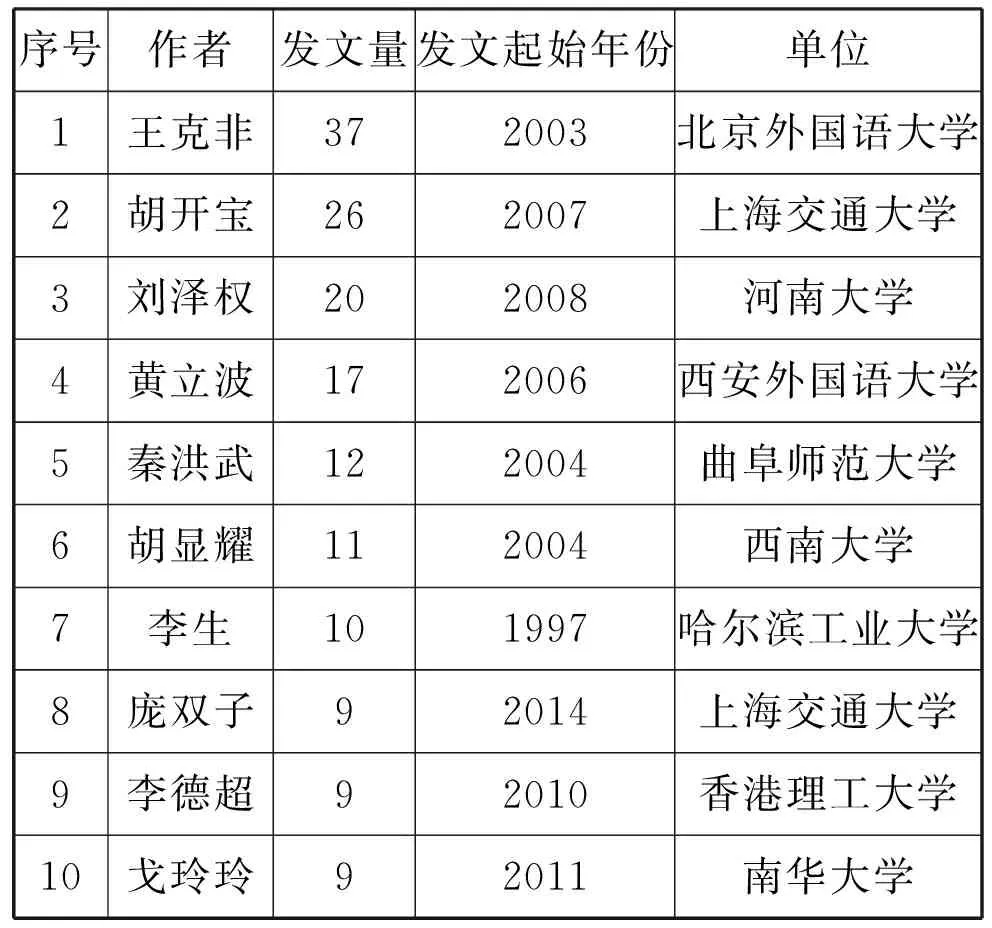
表1 10位高产作者信息
(三)研究机构
在CiteSpace操作界面,选择节点类型为机构(Institution)进行可视化分析,得到如图3的可视化图谱。根据左上角数据中“N=461,E=224”可以看出各机构间的合作也不够紧密,仍需加强合作,以碰撞出新的火花。从图中节点圆圈和字体的大小可以看出国内语料库翻译学最主要的研究机构为北京外国语大学中国外语教育研究中心和上海交通大学外国语学院。

图3 机构图谱
为了更加清楚地展现重要的国内相关研究机构,笔者借助CiteSpace中的相关数据绘制了表2,列出了前10所在核心期刊发表文献较多的机构。表中的机构多为专业外语类院校或综合类院校的外国语学院。其中外语类院校表现最为突出,前10名院校中有5个名额被外语类院校占据(有重复);在发文时间上,北京外国语大学在核心期刊上的发文时间最早,引领了后来的相关研究。
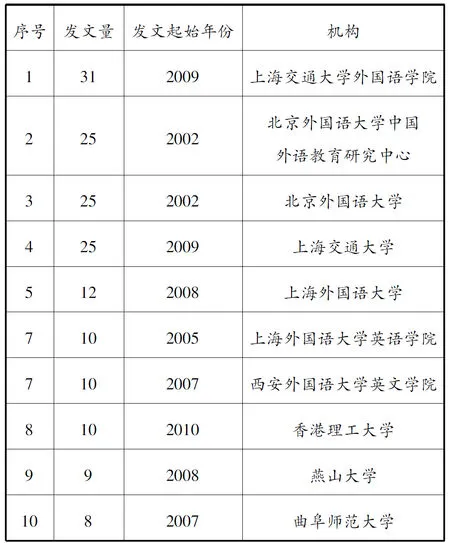
表2 重要机构研究信息
(四)研究领域
将CiteSpace操作界面的节点类型选择为关键词(Keyword)进行科学图谱的可视化分析,可得到如图4的关键词共现图谱。将图谱中的关键词按照相关算法进行聚类总结,可得到如图5的关键词聚类图谱。聚类视图“侧重于体现聚类间的结构特征,突出关键节点及重要连接”[6]248,将两张图中的相关关键词数据结合起来分析能够得出核心研究圈有关国内语料库翻译学的主要研究领域。
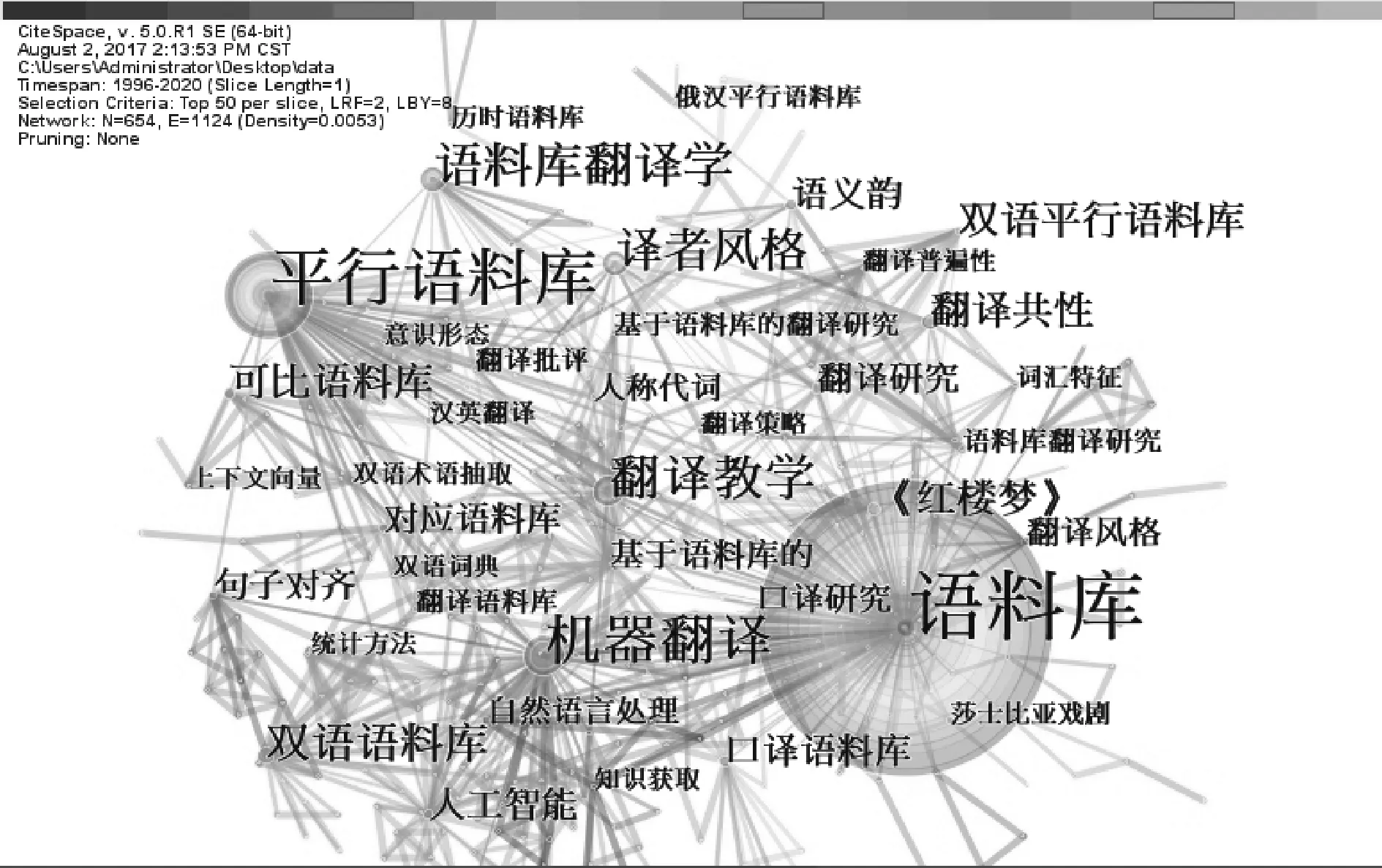
图4 关键词共现图谱
图4中出现了语料库、平行语料库、机器翻译、译者风格、语料库翻译学、翻译教学、双语语料库等字号较大的关键词,说明这些关键词在659条文献中出现的频率高,所受到的关注度较高。但是图4中还有其他字号相对较小的关键词,如口译研究、语义韵、《红楼梦》等,说明学者对其他的话题仍然有关注。图4中的关键词较多,总结起来很难做到十分精确。因此,为了提高总结研究领域的精确度,笔者借助CiteSpace软件的关键词聚类这一功能,将图4中联系较为紧密的关键词进行汇总形成聚类,得到如图5的关键词聚类图谱。
CiteSpace依据网络结构和聚类的清晰度,提供了模块值(Q值,即Modularity Q)和平均轮廓值(S值,即Mean Silhouette)两个指标,当Q值>0.3时,聚类结构就是显著的;当S值达到0.7就可认为聚类是令人信服的。[6]249图5左上角的数据显示Q值=0.7366,S值=0.5528,因此该聚类图谱的聚类结构十分显著,且结果令人信服。
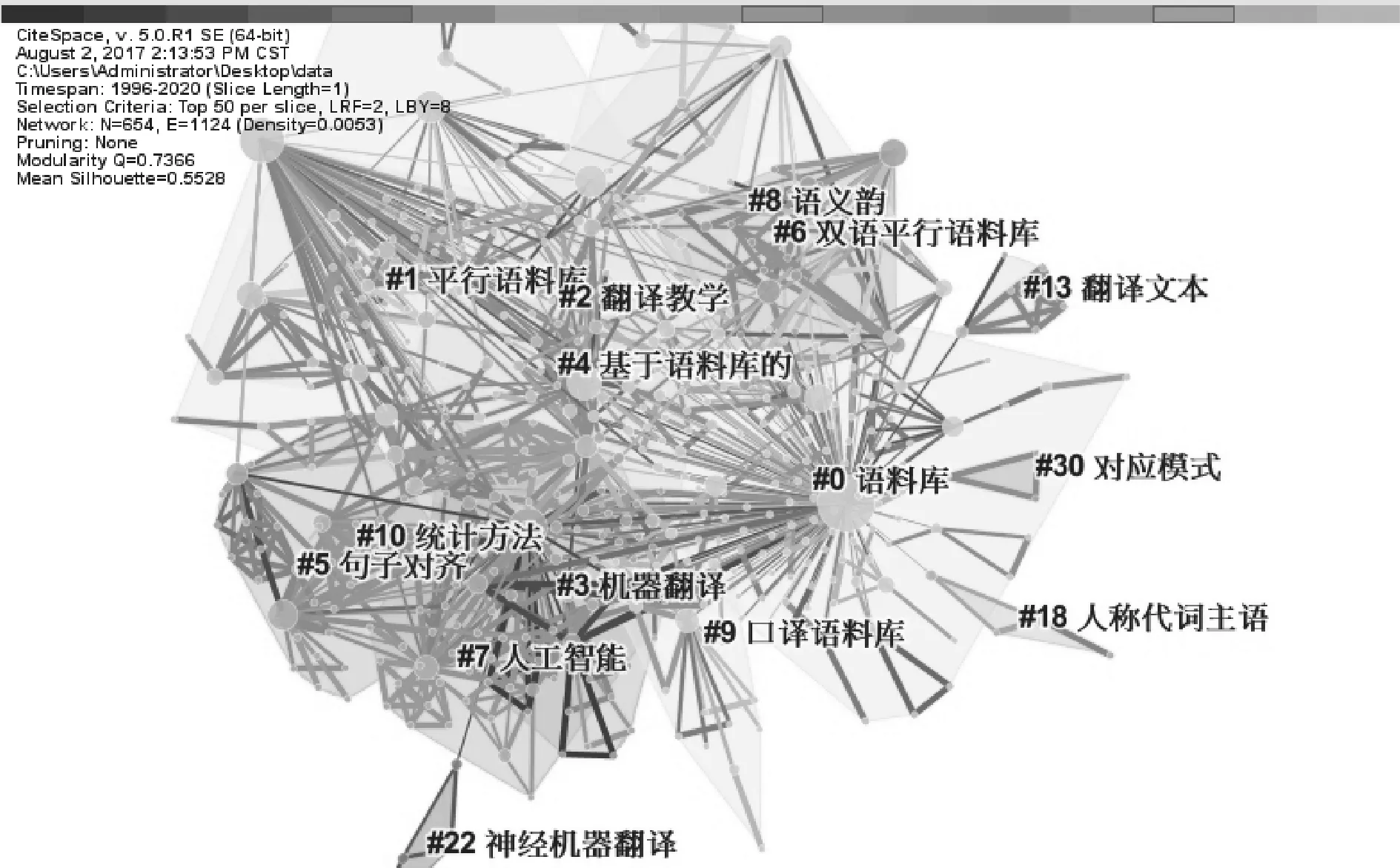
图5 关键词聚类图谱(LLR算法)
图5中各聚类按数值从小到大所包含的文献量依次递减,笔者截取了CiteSpace中前9个聚类的相关数据汇入表3。表3中“聚类内代表性关键词”一栏中的第一个关键词为该聚类名称,因为其代表性最强。笔者截取了每一聚类的前三个代表性最强的关键词,借助这些关键词有助于定位核心研究圈对于国内语料库翻译学的研究领域。
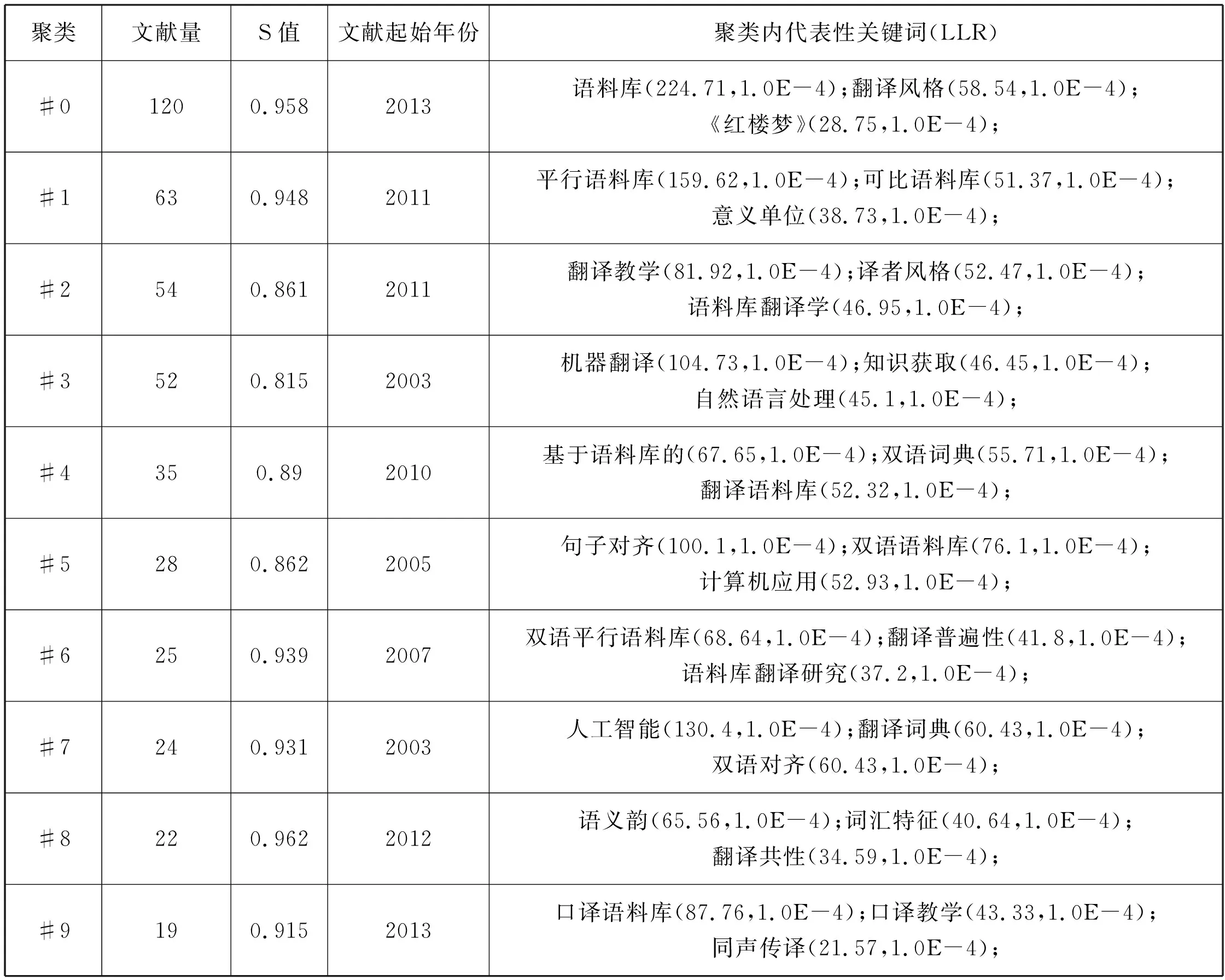
表3 聚类汇总
通过对表3中的关键词进行整合分析,结合图4中的关键词信息,可将核心研究圈对国内语料库翻译的研究划分为以下四个领域:
a.机器翻译(人工智能、自然语言处理、双语对齐等);
b.语料库建设(双语语料库、平行语料库、《红楼梦》、莎士比亚戏剧、可比语料库、口译语料库等);
c.翻译教学(翻译教学、口译教学等);
d.翻译研究(翻译风格、翻译共性、翻译普遍性、译者风格、语料库翻译学、语料库翻译研究、翻译策略、翻译批评等);
翻译研究可细分为语言特征研究(语义韵、意义单位、词汇特征)、译者风格研究(译者风格、翻译文体)和翻译共性研究(显化、翻译共性)和翻译语言研究(翻译风格)四个板块。
(五)研究热点
将图4的关键词共现视图改为关键词时区视图进行呈现,结合CiteSpace软件总结的1996到2020年出现的研究爆发点,有助于发现不同阶段的研究热点。
图6的关键词时区视图显示研究初期的话题集中在机器翻译上;1997年开始核心研究圈一直都在关注语料库的建设,从最初的双语语料库发展到对创建口译语料库和自建语料库的研究;2004年开始利用语料库进行翻译教学的探索;2008年开始将注意力放到翻译研究上,对翻译共性、译者风格等进行研究,到现如今,基于语料库的翻译研究仍是核心研究圈的重点关注话题。
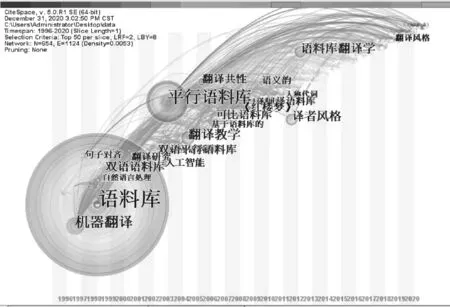
图6 关键词时区图
基于对不同阶段的主要研究话题有所了解,借助CiteSpace的爆发点总结功能,能够准确发现不同阶段的研究热点,如图7所示。总体来看,前半阶段的研究重点关注机器翻译相关的研究话题,后半阶段研究重心转向语料库建设和语料库翻译学方面的研究。仔细分析图7发现,1997—2005年机器翻译都是研究的热点话题,其间双语语料库的研究几乎同步进行;1998—2008年重点研究由自然语言处理发展到人工智能,为语料库建设和应用于翻译研究打下基础;2011—2015年开始运用语料库技术来研究译者的翻译风格,并且兴起了自建《红楼梦》语料库来研究译者的翻译风格和文体的热潮;2012年,王克非将Baker命名的“基于语料库的翻译研究”和Tymoczko命名的“语料库翻译研究”正式采用“语料库翻译学”这一术语进行概括[8],于是从2012年至今,语料库翻译学相关的研究都是核心研究圈关注的热点话题;2016—2017年核心研究圈开启了对可比语料库的研究,并形成一定热潮,如王克非和秦洪武借助历时复合语料库来研究翻译语言对汉语的影响[9];2018年开始,有关翻译风格的研究兴起。鉴于可比语料库、历时语料库建设所取得的进展,2018年开始一直持续到2020年的翻译风格研究较以往的译者风格研究有了质的飞跃,不再单纯分析译者的翻译偏好和策略等传统话题,而是从翻译语言的角度进行展开,如朱一凡和秦洪武借助英汉翻译历时语料库考察了“individualism”一词的汉语意义在中国经历的历时变化[10];秦洪武和孔蕾借助历时类比语料库将汉语原创语料和汉语翻译语料进行对比,发现汉语语言确实受到了翻译语言的影响,较多使用修饰语,因而结构容量有所拓展、复杂性增加,但是内部构成并没有发生变化[11]。借助于语料库建设取得的新成就,有关翻译语言的研究逐渐引领语料库翻译研究的新潮流。

图7 关键词爆发点图
三、国内语料库翻译研究存在的问题及建议
国内语料库翻译研究经过了二十余年的发展,取得了相当大的进步,但是仍然存在一些问题亟待解决。笔者拟列出研究过程中发现的问题,并给出相关建议。
首先,国内语料库翻译研究存在重微观轻宏观的现象。语料库翻译学集合了描写性翻译研究和语料库语言学重描写和重实证的特点,但是在一定程度上过于重视对例子的描写,而忽略了解释这一维度,未能将微观层面的语言现象上升为宏观的文化层面,缺少对语言背后的意识形态和翻译伦理等的探讨。较多学者都是借助语料库技术来探讨译者的翻译风格和文体,没有对译者的翻译动机和限制因素进行深入的分析,只停留在语言层面,忽视了社会和文化因素。针对这一问题,核心研究圈的学者们应该秉持探究的意识,脱离微观语言层面的分析,可尝试拓展语料库批评译学这一研究思路。胡开宝教授于2015年提出了“语料库批评译学”这一概念,并对其属性、研究内容和意义等做了详细解释,明确指出“语料库批评译学”是采用语料库方法,在观察、分析和统计数据的基础上,对文本特征和其背后的意识形态因素进行分析的研究[12];并且于2020年与盛丹丹一起进一步叙述了基于语料库的文学翻译批评研究的内涵、意义及发展方向[13]。胡开宝的这一思路值得核心研究圈的学者们深入探索并从中得到启示。
其次,国内语料库翻译研究存在研究不均衡的现象。根据以上的数据分析可知,核心研究圈对于国内语料库翻译研究多集中在书面材料语料库的建设上,对于口译语料库的研究相对薄弱;Baker和Laviosa等提出了第一代翻译共性假设,包括显化、简化和传统化(或规范化)等[14]。但是核心研究圈学者对于翻译共性的探讨集中在显化这一因素上,缺少对其他几个方面因素的探讨;对于语料库翻译教学的探讨相较于其他话题也较少。语料库技术用于翻译教学能够改进教材编写方式、改革教学方式和工具,核心研究圈的学者多为高校教师,若能对其深入研究,开发出更多选择,那么国内MTI的翻译学硕士的教学成效将大大提高。学者们还应该加强口译语料库的建设,推动国内语料库翻译研究均衡发展。
再次,国内语料库建设在语种、技术、规模、规范性等方面仍存在一些不足。国内的语料库多为英汉语,其他语种的语料库较少,品类较为单一,且多为书面语料库;我国平行语料库在字句对齐技术和检索工具方面仍需提升[15];我国虽有较大规模的语料库,但是较国外的语料库规模相比仍然还有提升的空间,且大型语料库数量较少,其中的语料内容不够完善,多是研究者自建的小型语料库,因此在共享方面仍然存在问题,不利于研究者之间的合作与深入交流。在语料库的规范性方面,各个小型语料库的建设标准不一,给信息的共享和流通造成了阻碍。因此,核心研究圈的学者们应致力于语料库的建设与提升,加强合作,共同建设囊括众多语料的大型语料库,在交流中制定出合理统一的建设标准,推动各大小语料库的共享与信息流动,并且将完善的口译语料库的建设提上日程。在语料库的建设方面,团队合作是重中之重。从上文机构和作者的分析结果中发现核心研究圈国内语料库翻译学研究的研究者和研究机构之间缺乏合作,单核心的发展模式不利于语料库的建设与共享。只有形成团队,加强沟通交流,才能产出好的语料库产品和研究成果。[16]
最后,国内语料库翻译研究在跨学科和理论发展方面仍有不足。我国的语料库翻译研究虽是语料库语言学和描写性译学的结合,但是主要集中在这两个领域,缺乏认知、社会学、心理学等学科知识的汇入,跨学科支撑不足。此外,国内语料库翻译研究多借鉴国外理论,缺乏本土理论的挖掘。国内学者应该在利用国外理论分析翻译现象的同时,注意结合汉语的特色,从中发掘符合汉语的本土理论,并利用该理论对翻译现象进行解释,从而验证理论的正确性和有效性。
四、结语
在进行研究的过程中,有效利用研究工具能够为研究者提供便利,甚至带来新的发现。CiteSpace这一可视化软件为研究国内语料库翻译学的发展概况提供了有力抓手。借助这一分析工具,笔者总结了国内语料库翻译研究的高产作者、领先研究机构、研究领域和热点等重要信息。同时发现,在研究者方面,国内语料库翻译学研究存在单核心发展模式,对核心人物的依赖性过高;研究者和研究机构间缺乏团队合作。在对研究领域和热点的分析中,发现国内语料库翻译学研究存在重视微观层面译者风格和翻译共性的探讨,忽视从宏观层面进行文化分析的现象,且存在研究领域不均衡、跨学科支撑不足等问题。此外,对于语料库的建设仍存在不足、本土理论发展的能力较为薄弱。因此,核心研究圈的学者和机构之间应该加强合作,提升翻译语料库的建设水平,并与其他学科的专业学者加强沟通,推动语料库翻译研究的跨学科建设。此外,寻找新的研究点、加强对薄弱环节的研究,并且在研究中发掘本土理论也是研究者们面临的重要课题。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
外语学刊(2021年1期)2021-11-04
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
新城乡(2018年6期)2018-07-09
师道·教研(2017年11期)2017-12-10
领导科学论坛(2016年9期)2016-06-05
互联网天地(2016年1期)2016-05-04
中国报道(2009年12期)2009-01-15
