
基于膨胀卷积和门控循环单元组合的入侵检测模型
2021-07-02 00:35张全龙王怀彬
计算机应用 2021年5期
张全龙,王怀彬
(天津理工大学计算机科学与工程学院,天津 300384)
(*通信作者hbwang@tjut.edu.cn)
0 引言
计算机技术飞速发展,它已经渗透到人们的工作和日常生活中,给人们带来了极大的便利;但同时网络攻击变得越来越频繁,网络安全已成为人们必须面对的挑战[1-3]。入侵检测技术是网络安全的重要组成部分,而入侵检测技术是分类问题,需要做的事情是建立入侵检测模型,使其能够有效地对各种网络攻击进行分类识别,以便及时采取安全防范措施。
当前,广为人知的入侵检测方法之一是使用不同的机器学习技术来降低错误率,例如K 最近邻(K-Nearest Neighbor,KNN)[4]、神经网络(NeuralNetwork,NN)[5]和支持向量机(Support Vector Machine,SVM)[6-8]已广泛用于入侵检测。文献[9]中提出了一种基于KNN 回归的动态多间隔预测模型;文献[10]中提出了一种混合的机器学习技术,结合了K-means 和SVM 来检测攻击。集成分类器(例如Adaptive Boosting[11]、随机森林(Random Forest,RF)[12-13])通常由多个弱分类器构成,避免在训练过程中过拟合,可以实现更强大的分类功能。Al-Yaseen 等[14]使用SVM 和改进的K-means 算法来构建多层混合入侵检测模型;但是,对于KDD CUP99 数据集中U2R(User to Root)和R2L(Remote to Local)的低频攻击样本,此模型的检测率非常低,远低于其他高频样本的检测率。尽管基于机器学习的网络入侵检测模型具有强大的检测能力和适应网络环境变化的自适应能力,但是它们仍然受到不平衡数据的影响。卷积神经网络(Convolutional Neural Network,CNN)[15]是深度学习研究的重点,在计算机视觉、语音识别和自然语言处理方面取得了出色的研究成果。与传统的特征选择算法相比,它可以自动学习更好的特征。文献[16]中首先使用不同的降维方法去除了多余的特征,然后将降维数据呈现给CNN。尽管获得了很好的准确性,但它掩盖了CNN 的优势——自动提取特征。门控循环单元(Gated Recurrent Unit,GRU)是递归模型,已用于如自然语言处理和情感分析等序列学习。文献[17]中实现了网络入侵检测模型的GRU、MLP(Multi-Layer Perceptron)和Softmax 模块,并在KDD CUP99和NSL-KDD训练数据集上进行了实验;文献[18]中进一步提出通过一维卷积来统一和共享多传感器权重的问题;文献[19]中设计结合了CNN 和长期短期记忆(Long Short Term Memory,LSTM)网络的模型;文献[20]中构建了一个新的深层神经网络(Deep Neural Network,DNN)模型,该模型使用GRU 和MLP 提取数据信息,仿真结果表明,GRU 单元在入侵检测方面比LSTM单元更有效。
为了提高检测的分类准确度,本文模型通过膨胀卷积来增强感受野的同时提取增强的特征,并且使用GRU 模型来挖掘数据样本之间的时间序列信息。本文模型最大优点是可以准确提取数据的特征,并且检测到以前从未见过的攻击。
本文模型主要贡献如下:
1)使用膨胀卷积来增大感受野,以此来提高模型对特征获取的准确度,对数据样本进行充分的学习。
2)使用GRU 神经网络来获取数据之间的时间关系特征,以此来检测未知的攻击。
3)使用随机梯度下降(Stochastic Gradient Descent,SGD)优化算法用于协助训练模型,并且使用动量法来增加SGD 更新的稳定性。
1 膨胀卷积
在传统的卷积神经网络中,会使用池化层来保持特征不变性并避免过度拟合,但是会大大降低空间分辨率,丢失特征图的空间信息。当加深卷积神经网络的层时,网络需要更多的参数,并导致更多的计算资源消耗。Yu等[21]提出的膨胀卷积很好地解决了这一问题。膨胀卷积是一种卷积算子,它使用不同的膨胀因子在不同范围使用相同的滤波器,膨胀卷积能够更有效地扩展感受野。与传统卷积相反,膨胀卷积的内核中存在孔,孔的大小为膨胀率。一维卷积的公式如下:
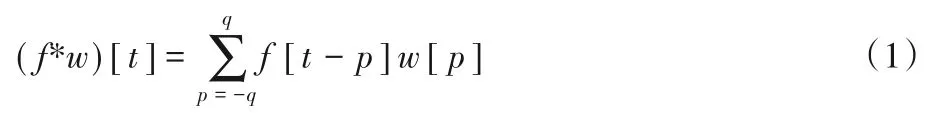
其中:f为输入,w为卷积核,t为卷积核的大小,p为卷积的下限值,q为卷积的上限值。如果是膨胀卷积,则一维膨胀卷积的公式如下:
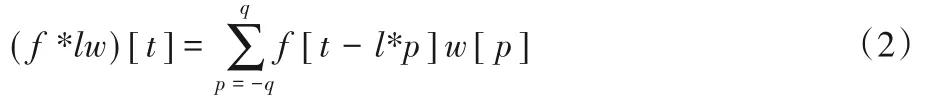
其中l是膨胀率。本文对输入数据应用膨胀卷积时,与传统卷积相比,感受野将得到扩展,而不会降低分辨率,能够在不增加参数数量或计算量的情况下增大感受野,换句话说,本文使用相同层数可以实现更大的感受野,而无需引入比普通卷积更多的操作。膨胀卷积是一个将步幅进行卷积而元素分开的卷积过程,与传统的卷积相比,膨胀卷积是到较宽区域的稀疏连接。本文堆叠3 个具有不同步幅的膨胀卷积层,尽管膨胀卷积具有与常规卷积相同的过滤器大小,但是通过堆叠它们,可以感知更大的范围。
本文设计的膨胀卷积模型如图1 所示。该模型具有3 个膨胀卷积层,每个卷积层的膨胀率分别为2、4、8:当膨胀率为2 时,膨胀卷积过后特征集中神经元数量为32;当膨胀率为4时,膨胀卷积过后特征集中神经元数量为64;当膨胀率为8时,膨胀卷积过后特征集中神经元数量为128。这样本文模型可以从原始数据中提取尽可能多的特征,并且可以得到神经元数量分别为32、64、128 的特征集。经过3 个膨胀卷积层后,特征集可以获取原始数据包含的所有信息。在每个卷积层之后,都有一个ReLU(Rectified Linear Unit)激活层,用于为模型添加非线性特征。本文不在每个卷积层之后都使用maxpooling 层,而是在3 个膨胀卷积层之后加入max-pooling 层来防止过拟合。
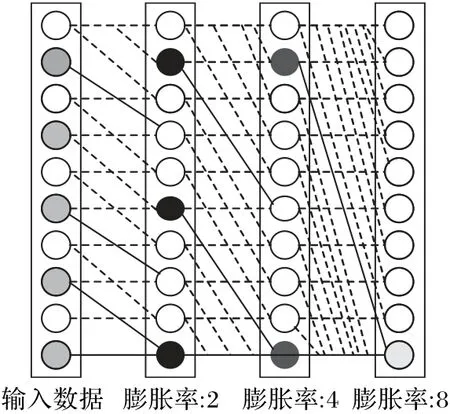
图1 膨胀卷积模型Fig.1 Dilated convolution model
本文使用多级膨胀卷积神经网络捕获数据之间的局部相关性和长期依赖性。具体来说,本文的卷积神经网络是三级膨胀卷积神经网络,它能够以指数形式扩展接受域级别而不增加参数数量,因此,膨胀卷积捕获长期依赖性成为可能。本文使用具有不同膨胀率的多级膨胀卷积,这样做避免了由膨胀导致的重要局部相关性缺失,也能使输入的所有数据都能够参与计算。
2 门控循环单元
传统的深层神经网络(DNN)在样本分类和特征提取方面突破了浅层网络的局限性,具有强大的非线性拟合能力。然而,DNN 没有考虑分类样本之间的时间关系,导致分类过程中一些信息的丢失。循环神经网络(Recurrent Neural Network,RNN)[22]有效地解决了时序依赖性问题。RNN 引入了隐藏层单元之间的反馈连接,以便网络可以将学习到的信息保留到当前时刻,并确定网络的最终输出结果以及当前时刻的输入;但是,RNN 无法学习导致梯度消失的长期依赖关系[23]。LSTM 是许多用于改善RNN 的网络结构中最广泛使用和有效的结构之一,但是LSTM 中有很多参数,并且需要花费更多的时间来将模型参数调整为最佳状态。与LSTM 相比,GRU 的门更少,可以节省更多的训练时间和计算资源。图2显示了GRU的典型架构。
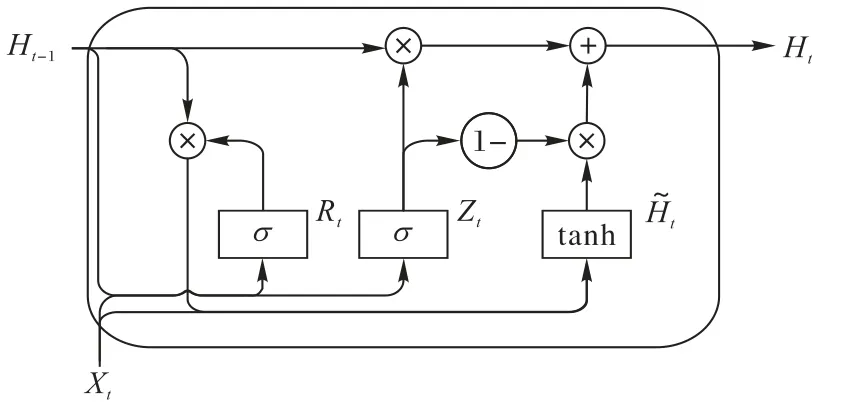
图2 GRU模型Fig.2 GRU model
GRU 中有两个主门,即更新门和重置门。更新门用于控制将多少先前状态信息带入当前状态;重置门用于控制GRU忽略前一时刻的状态信息的程度。所有的关系定义如下:
1)重置门:
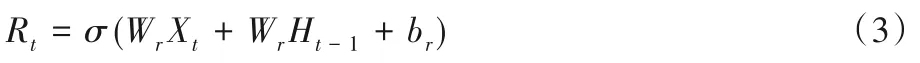
2)更新门:
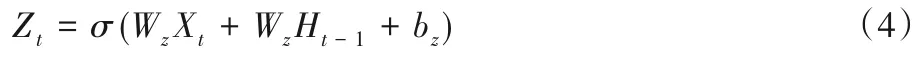
门控循环单元中的重置门和更新门的输入均为当前时间步输入Xt与上一时间步隐藏状态Ht-1,输出由激活函数为sigmoid 函数的全连接层计算得到。其中Wr、Wz是权重参数,br、bz是偏差参数。
3)候选状态:
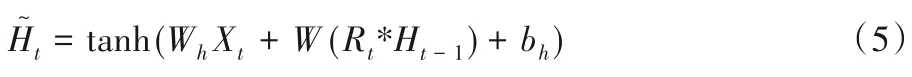
4)隐藏状态:
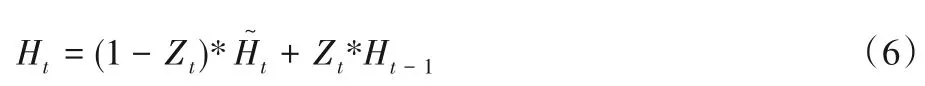
其中:Wh、W是权重参数;bh是偏差参数。门控循环单元将计算候选状态来辅助稍后的隐藏状态的计算,将当前时间步重置门的输出与上一时间步隐藏状态做按元素乘法。如果重置门中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上一时间步的隐藏状态;如果元素值接近1,那么表示保留上一时间步的隐藏状态。这个设计可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
3 基于膨胀卷积和门控循环单元组合模型
本文通过将膨胀卷积与GRU 模型结合在一起形成新模型来提取数据的特征,两者的结合构成了一个深层网络,可以实现更优化的结果。其结构如图3所示。

图3 基于膨胀卷积和GRU的组合模型Fig.3 Combined model based on dilated convolution and GRU
该模型由膨胀卷积部分、GRU 部分、全连接层部分和输出部分组成。由于膨胀卷积和GRU 网络结构的输入形式不同,因此提取的空间特征会在膨胀卷积部分的输出处进行调整,保证GRU 部分输入的大小与膨胀卷积的输出大小一致,以满足GRU 模型的输入格式。在GRU 模型的输出层之后连接一个全连接层,对先前提取的特征进行集成,最后一个全连接的层的输出值传递给Softmax 进行分类。模型各层参数如表1所示。
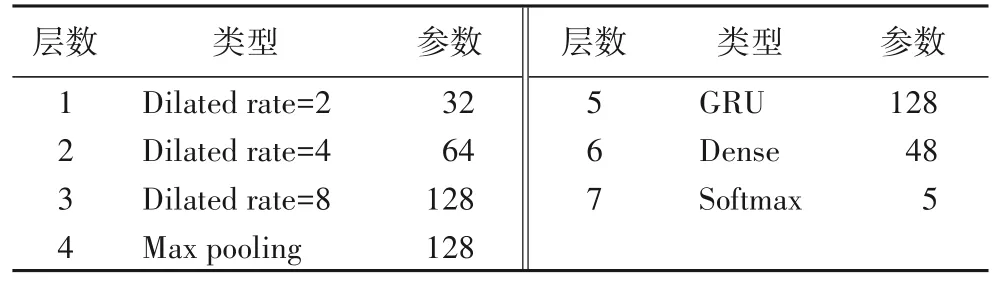
表1 模型中各层结构参数Tab.1 Parameters of different layers of model
膨胀卷积部分提取的特征用于训练分类模型,考虑到特征在不同位置具有局部性,因此在三层膨胀卷积之后使用池化层,在一定程度上汇总不同位置的统计信息,将小邻域中的特征点集成以获得新特征,以减少数据量并避免过拟合。经过膨胀卷积和合并后,使用reshape 函数重新整形为向量;然后,通过全连接层获得输出,这样就可以得到膨胀卷积提取的空间特征。膨胀卷积可以准确提取空间特征,但在学习序列相关信息时效果不佳,因此,为提高仅使用膨胀卷积的网络入侵检测的准确性,本文加入了GRU模型。膨胀卷积和GRU模型都代表了深度学习算法,膨胀卷积可以提取空间维度中的数据特征,并且增大感受野,GRU 具有可以长时间保存上下文历史信息的特性,并且可以在时间级别上实现数据特征的提取。
4 实验结果和分析
本文实验的总体步骤如图4 所示。首先使用所提出的模型提取数据的特征,以提高分类的准确性;训练后,获得了具有良好分类性能的模型,并使用该模型对测试集进行分类,以获得优异的分类结果。本文实验使用的CPU 为Intel Core i7-7700、GPU 为GeForce GT 730、操作系统为Windows 10,内存为16 GB。
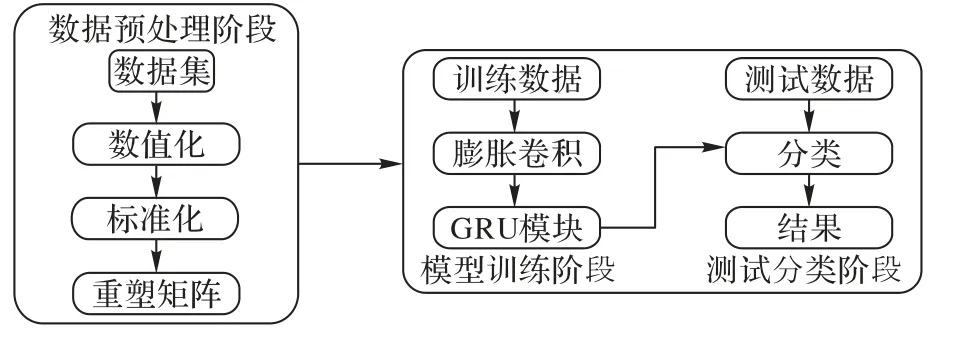
图4 实验总体步骤Fig.4 General steps of experiment
本文使用SGD 优化算法,经过多次和小范围实验训练,实验参数设置如下:学习率设置为0.01,此时模型的学习状态最佳;权值衰减系数为0.000 001,此时模型的复杂度对损失函数影响最小;动量(momentum)设置为0.9,此时SGD的稳定性最好;正则化方法Dropout失活率设置为0.2。
4.1 数据描述
本文使用3 个公开可用的入侵检测数据集KDD CUP99、NSL-KDD 和UNSW-NB15 数据集。在入侵检测领域,KDD CUP99 和NSL-KDD 是著名的数据集[24],两个数据集中每个入侵记录都具有42 维特征,标签主要包含普通数据和4 种攻击数据:DoS(Denial of Service)、Probe、U2R、R2L。UNSW-NB15数据集包含许多现代网络的新攻击,可以将其分为1 个正常类和9 个攻击类。在本文的实验中,KDD CUP99、NSL-KDD、UNSW-NB15数据集中样本类别分布如表2所示。
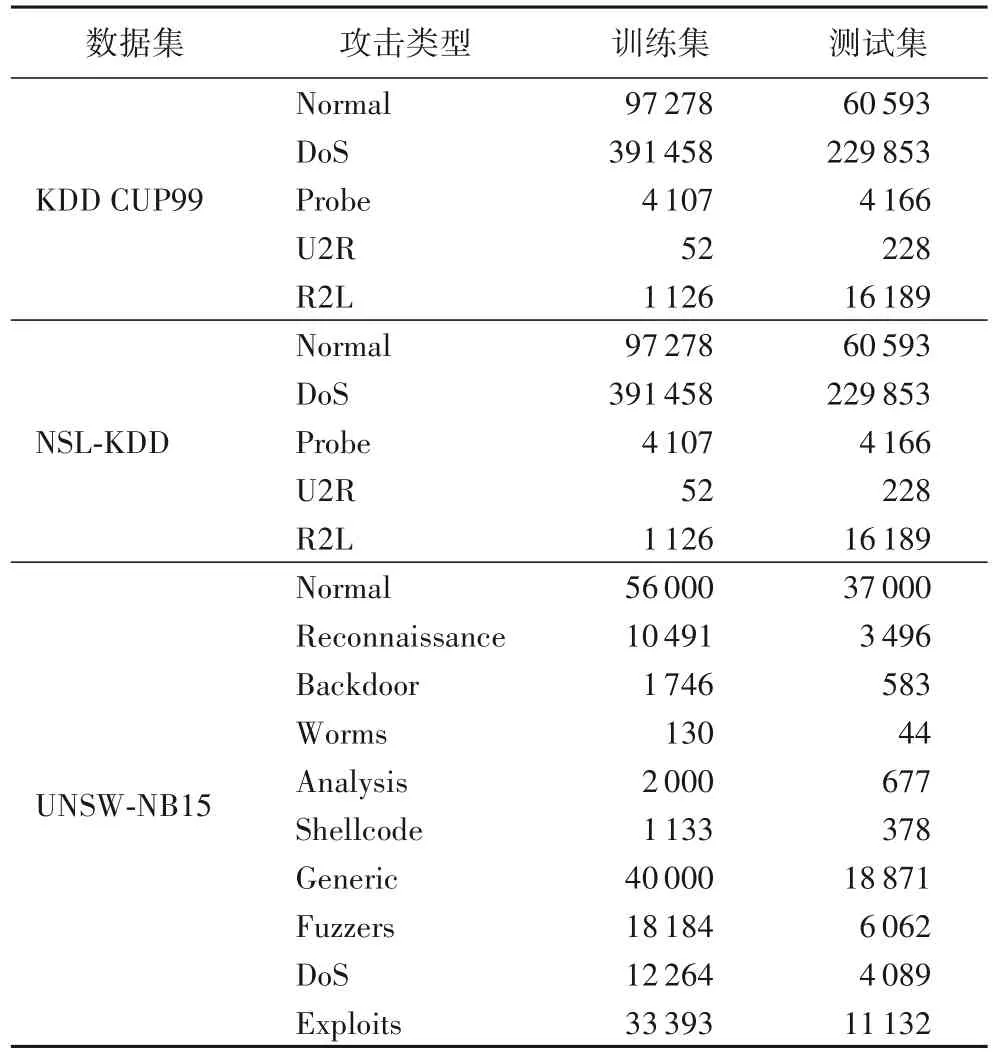
表2 数据集样本分布Tab.2 Dateset sample distribution
4.2 数据预处理
本文对数据集中的字符型特征属性进行数字化和标准化,得到一个标准化的数据集,然后将每个数据转换为二维矩阵,使其符合膨胀卷积模型的输入格式。处理后的数据集有训练数据集和测试数据集,训练数据集用来训练网络模型,测试数据集用来验证模型的有效性。由于数据特征的复杂性,数据预处理包括以下3步:
1)数值化处理。
由于模型的输入是数字矩阵,因此使用one-hot 编码方法将数据集中具有符号特征的数据映射到数字特征向量。将KDD CUP99 和NSL-KDD 数据集中正常数据(Normal)和4 种攻击类型(DoS、Probe、U2R、R2L)这5 种类标签进行数值化处理,也对UNSW-NB15 数据集中正常数据(Normal)和9种攻击类型(Reconnaissance、Backdoor、Worms、Analysis、Shellcode、Generic、Fuzzers、DoS、Exploits)这10 种类标签进行数值化处理。
2)标准化处理。
在数据集中,不同类别的数据值大小明显不同,最大值的范围变化很大。为了便于算术处理和消除尺寸,采用归一化处理方法,在[0,1]区间内均匀且线性地映射每个特征的值范围。用以下方程将数值数据归一化为[0,1]:

其中:max为样本数据的最大值,min为样本数据的最小值,x为标准化后的数据。
3)将标准化数据转换为矩阵。
读取数据的每个网络记录都将进行尺寸转换以符合网络模型的格式。为了输入到膨胀卷积神经网络中,使用reshape转换函数将网络数据重塑为矩阵。
4.3 评估指标
在本文中,准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-measure 被用作评估模型性能的关键指标。这些指标是从混淆矩阵的4 个基本属性中得出的,如表3 所示,其中TP(True Positive)表示攻击数据被正确地分类为攻击,FP(False Positive)表示正常数据被错误地分类为攻击,TN(True Negative)表示正常数据被正确地分类为正常,FN(False Negative)表示攻击数据被错误地分类为正常。
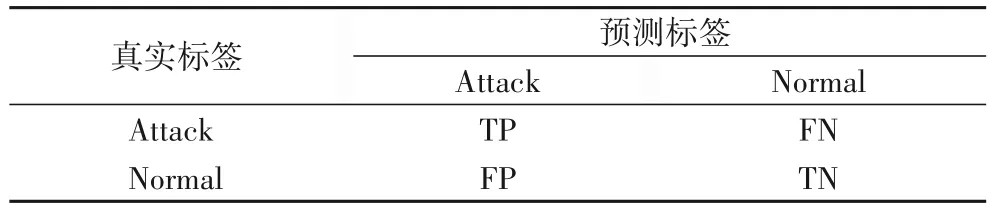
表3 混淆矩阵Tab.3 Confusion matrix
本文将使用以下评估指标来评估本文所提出模型的性能。

4.4 KDD CUP99数据集的实验结果
实验包括训练和测试两个过程,使用KDD CUP99 数据集的训练集和测试集来进行实验。本文模型使用训练集对模型进行训练,最后使用测试集对模型进行测试。
五个标签类的评估指标值通过图5 可以被更清楚地观察到,低频样本U2R、R2L类在本文模型下,Precision、Recall、F1-measure三个评估指标依然拥有较高的值。
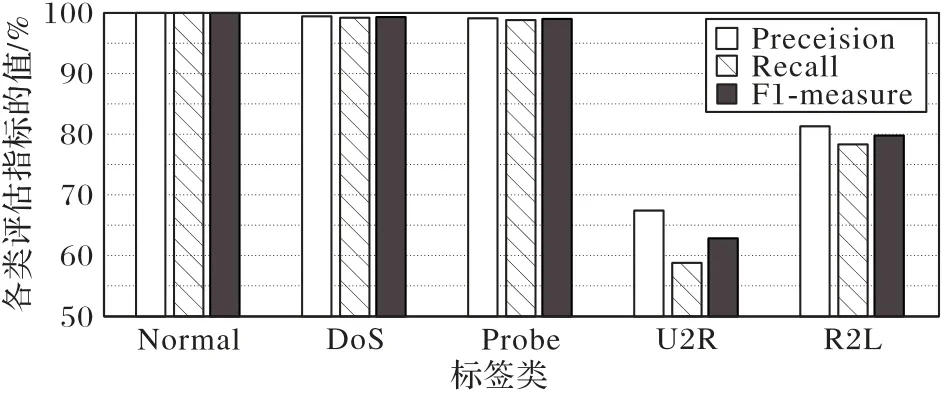
图5 KDD CUP99数据集的五个标签类的评估指标值Fig.5 Evaluation index values of five label classes of KDD CUP99 dataset
为了评估所提模型对未知攻击的检测效果,使用了KDD CUP99数据集中17种未知攻击类型,这17种未知攻击类型存在于测试集中,而在训练集中不存在。这17 种未知攻击的召回率如表4 所示。从检测结果上可以看出,本文模型可以对未知攻击进行检测。
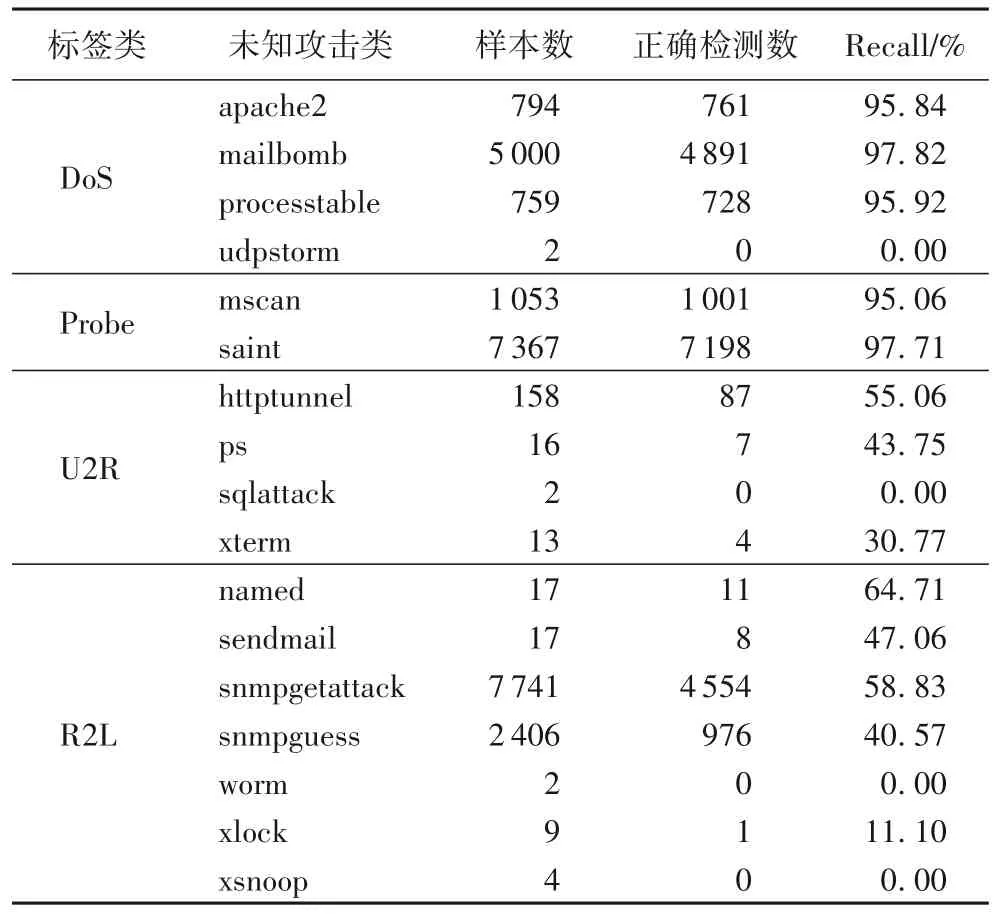
表4 KDD CUP99数据集上未知攻击类型的检测结果Tab.4 Unknown attack type detection results on KDD CUP99 dataset
目前,许多机器学习和深度学习算法已应用于网络入侵检测。支持向量机和经典卷积神经网络广泛用于网络入侵检测,因此,将入侵检测中常用的经典分类模型与本文中的模型进行了比较。本文使用SVM[7]、S-NDAE(Stacked Nonsymmetric Deep AutoEncoder)[25]、MHCVF(Multilevel Hybrid Classfier with Variant Feature sets)[26]模型和本文模型在KDD CUP99 数据集上对分类性能进行了比较,如表5所示。
从表5 可以看出,与传统的SVM、S-NDAE、MNCVF 模型相比,本文模型测试结果最好,准确率达到99.78%,召回率达到99.33%。当面对复杂数据时,从分类结果可以看出,本文模型仍然比其他模型获得更高的准确率。

表5 KDD CUP99数据集的上各模型实验结果对比 单位:%Tab.5 Comparison of experimental results of different models on KDD CUP99 dataset unit:%
4.5 NSL-KDD数据集的实验结果
为了进一步验证本文模型,还对NSL-KDD 数据集进行了实验。各指标的分布通过图6 可以被更清楚地看到,选取入侵检测中常用的经典分类模型与本文模型进行了比较。本文使 用SCDNN(Spectral Clustering Deep Neural Network)[27]、DNN[28]、SMOTE+CANN(Synthetic Minority Oversampling Technique and Cluster center And Nearest Neighbor)模型[29]和本文模型在NSL-KDD 数据集上对分类性能进行了比较,比较结果如表6所示。
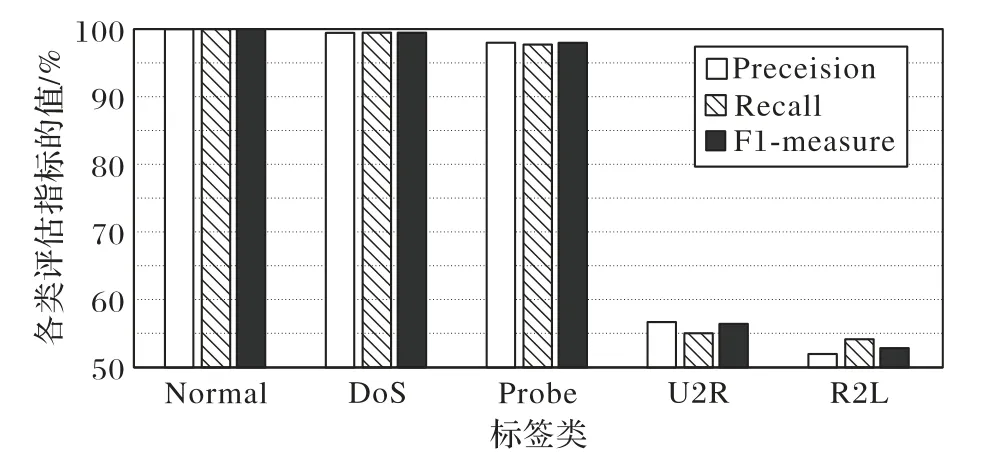
图6 NSL-KDD数据集的五个标签类的评估指标值Fig.6 Evaluation index values of five label classes of NSL-KDD dataset

表6 NSL-KDD数据集上的各模型实验结果对比 单位:%Tab.6 Comparison of experimental results of different models on NSL-KDD dataset unit:%
从表6 可以看出,与SCDNN、SMOTE+CANN 和DNN 三种分类器相比,本文模型准确率可以达到99.53%,召回率达到99.25%。从图6 可以看出,本文模型在Precision、Recall 和F1-measure 几个评价标准上得到的结果都很高。从分类结果可以看出,所提模型是有效的,当面对复杂数据时,本文模型仍然比其他模型获得更好的结果。
4.6 UNSW-NB15数据集的实验结果
UNSW-NB15 数据集中包含许多现代网络的新攻击,使用本文提出的模型用训练集数据进行训练,最后使用测试集对模型进行测试。各指标的分布通过图7可以被更清楚地看到。本文同样选取入侵检测中常用的经典分类模型与本文模型进行了比较。使用RF[13]、SVM[8]和MSCNN(MultiScale Convolutional Neural Network)模型[30]与本文模型在UNSW-NB15数据集上对分类性能进行了比较,比较结果如表7所示。

表7 UNSW-NB15数据集上的各模型准确率对比Tab.7 Accuracy comparison of different models on UNSW-NB15 dataset
从表7 可以看出,与RF、SVM、MSCNN 三个模型相比,本文模型有最高的准确率,可以达到93.12%。与传统的模型相比,在新型数据集UNSW-NB15 上进行实验时,从分类结果可以看出,本文模型仍然比其他模型获得更高的准确率。
5 结语
本文提出了一种基于膨胀卷积和门控循环单元(GRU)相结合的入侵检测新模型。首先,对数据集进行数值化和标准化处理,这样可以减少模型的训练时间;然后,通过膨胀卷积和GRU 构建的网络模型对输入数据进行分类。该模型利用深度学习的出色性能,通过重复的多级学习自动提取特征。本文使用KDD CUP99、NSL-KDD 和UNSW-NB15 三个入侵数据集来进行实验。根据统计显著性检验可以得出结论,该模型优于其他分类器。本文提出的模型在准确率和召回率方面取得了优异的结果,尤其是在多特征数据集中,发现训练数据规模越大,检测性能越好。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
软件(2017年6期)2017-09-23
少儿科学周刊·儿童版(2017年3期)2017-06-29
