
基于深度学习的轻量级道路图像语义分割算法
2021-07-02 00:35冯子亮
计算机应用 2021年5期
胡 嵽,冯子亮
(四川大学计算机学院,成都 610065)
(*通信作者电子邮箱1626429788@qq.com)
0 引言
图像语义分割[1-3]是计算机视觉中的基础性技术之一,主要针对图像中的每个像素点的语义信息来进行分类分割,在自动驾驶、机器人视觉以及智能场景理解领域具有非常重要的应用价值。道路图像语义分割作为自动驾驶领域不可或缺的重要一环,协助车道线检测以及行人检测与识别等任务[2]。现存的图像语义分割网络模型存在模型参数量巨大、计算复杂等缺点,未能达到移动端进行快速实时语义分割的要求。因此,本文使用深度可分离卷积设计出了一种轻量级对称式U 型编码器-解码器结构的网络模型MUNet,融合不同层级特征来填充丢失细节。在下采样中丢失的空间信息其实不能简单地通过融合就能被完整恢复,所以本文在MUNet 中加入稀疏短连接,加强相邻网络层间的信息互通,捕捉边缘上下文信息并进行特征复用。由于现阶段的分割网络较难分割较小目标,比如道路场景下的电线杆,以及具有相似外观的不同目标或者是具有不同外观的同一目标[3]。为了解决这些问题,本文在网络中融合了注意力机制,更好地捕捉全局上下文信息,减少类间粘连以及类内分隔的发生,在极大地减少参数量降低计算复杂度的同时得到更精细的分割结果。在实际训练中由于语义分割这类像素级密集预测任务的特殊性以及硬件限制,通常会设置很小的batch size,在这样的情况下使用批归一化(Batch Normalization,BN)[4]并不能得到很好的结果,因此本文选择使用组归一化(Group Normalization,GN)[5]来替代BN进行更有效的归一化。
本文的主要工作如下:
1)使用深度可分离卷积设计出一种轻量级对称式U 型编码-解码结构网络模型,联合不同层级特征,在极大地减小参数量以及计算量的同时也保证了网络分割精度;
2)在编码端以及解码端不同网络层次之间加入稀疏短连接,进一步补充下采样过程中丢失的空间细节;
3)在网络中融入注意力机制,这样的注意力机制融合了长距离依赖以及通道注意力依赖,能更好地利用全局上下文信息;
4)使用GN 来替代BN,在batch size 很小的情况,也能得到很好的分割结果。
1 相关工作
1.1 图像语义分割
在图像语义分割任务中,为了获得更丰富的特征图,网络通常会融合多尺度信息、直接增大感受野或者使用注意力机制等方法。其中融合多尺度信息的方法可分为编码器-解码器结构以及金字塔结构等。使用类似编码器-解码器结构的图像语义分割网络有全卷积神经网络(Fully Concolutional neural Network,FCN)[6]、U-Net[7]、SegNet[8]、深层特征聚合网络(Deep Feature Aggregation Network,DFANet)[9]等,将编码端获取到的信息映射到解码端,便于解码端很好地恢复分割目标细节信息。而金字塔场景分析网络(Pyramid Scene Parsing Network,PSPNet)[10]等网络则通过金字塔结构融合多尺度信息,聚合不同区域的同类目标上下文信息。DeepLabv3+[11]将编码器-解码器结构和金字塔结构相结合,联合两种结构的优势,提高模型分割效率。
为了获得大感受野从而促使网络分割性能得到提升,语义分割网络选择大卷积核或者空洞卷积。通过使用大卷积核来获得足够大的感受野的操作往往会耗费大量的计算资源,因此一些网络,比如全局卷积网络(Global Convolutional Network,GCN)[12]通过堆叠小卷积来替代大卷积核,在降低参数量和计算量的同时获得和大卷积核类似的感受野。空洞卷积在语义分割中是一个强有力的工具来有效地调整卷积感受野[13],DeepLabv3+中也使用了空洞卷积,组成了空间金字塔结构融合多尺度语义信息,但使用空洞卷积会大量消耗内存。
注意力机制作为图像语义分割网络中获取全局上下文信息有力的工具之一,在近年来的分割网络中被广泛使用,比如判别特征网络(Discriminative Feature Network,DFNet)[14]利用卷积块注意力模块(Convolutional Block Attention Module,CBAM)[15]选择更具判别力的特征,解决分割目标类内不一致问题。
1.2 注意力机制
计算机视觉中的注意力机制主要通过一层新的权重将图片中关键的特征标识出来,让深度神经网络学习到每一张图片中需要关注的区域,加强卷积空间特征表达,得到更多的全局上下文信息。目前在图像语义分割中使用的注意力机制主要是软注意力机制,包含空间注意力以及通道注意力机制,单独加入通道注意力或者将空间注意力以及通道注意力进行融合[15-21]。软注意力机制中还有自注意力机制,这是软注意力机制的另一种特殊形式,主要代表是非局部注意力网络(Non-Local neural Network,NLNet)[22],提出了一种Non-local操作获取图像中位置长距离依赖。为了更好地获得更多的全局上下文信息,全局上下文网络(Global Context Network,GCNet)[23]还将NLNet中的Non-local操作以及文献[21]中的通道注意力机制相结合,得到结合两者优点的注意力机制,简单有效地对全局上下文进行建模,更好地补充网络中的语义信息,增加提取特征的多样性。
1.3 轻量级神经网络
为了降低常规卷积带来爆炸式增长的计算量,很多方法选择构建参数量以及计算量较少但有效的神经网络。构建这样简单有效的神经网络的方式主要有两种:一种是选择使用深度可分离卷积或者组卷积组成轻量级神经网络[24-31];另一种就是进行模型裁剪[32-34]。由于模型裁剪可能会带来不可恢复的细节丢失,同时如何进行相对有效的裁剪工作仍需进一步的理论支撑,现阶段主要是选择前一种方式来获得轻量级神经网络快速有效地分割目标。
2 模型设计
2.1 网络架构
本文主要使用文献[24]提出的深度可分离卷积设计出一种轻量级对称式U型编码器-解码器结构网络模型MUNet,极大地减小参数量以及计算量。文献[24]中的深度可分离卷积由一系列的深度卷积(depthwise convolution)以及1×1 点卷积(pointwise convolution)组成,其与标准卷积的对比如图1 所示,图1中Dk表示卷积核的尺寸,M表示输入通道的大小,而N表示输出通道的大小。
MUNet 基础卷积块借鉴文献[30]提出的MobileNetv2 网络中的倒置残差卷积块结构,具体结构如图2所示。
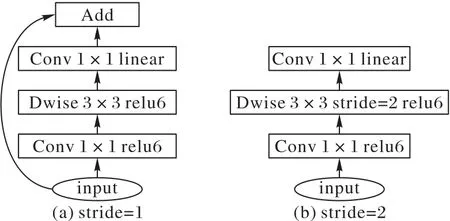
图2 倒置残差卷积块Fig.2 Inverted residual convolutional block
在MUNet 中也引入了在文献[30]以及[31]中出现的relu6 以及h-swish 激活函数。relu6 函数主要是为了避免低精度浮点数无法精确描述数值而带来的精度损失,可表示为:

h-swish 函数计算成本低,因此在本文中MUNet 的设计也采用了这样的激活函数尽可能地减少计算量,可表示为:
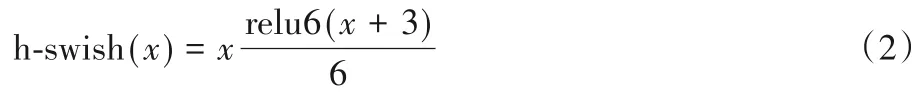
最终设计得到的轻量级对称式U 型编码器-解码器架构的网络模型MUNet的具体结构如图3所示。图中虚线框内表示MUNet 的基础卷积块,网络的左端作为编码端使用步长为2 的深度可分离卷积进行下采样,网络的右端作为解码端使用双线性插值进行上采样还原下采样过程缩减的图像尺寸,以获得更高分辨率的分割特征图。编码端和解码端对应大小的特征进行通道级别的特征融合,通过融合不同层级特征来弥补图像经过下采样操作丢失的细节。网络中的稀疏短距离连接主要为相隔一层的两个卷积块之间进行通道级融合,在基础卷积块中加入注意力机制,目的是来提取更充沛的全局上下文信息。
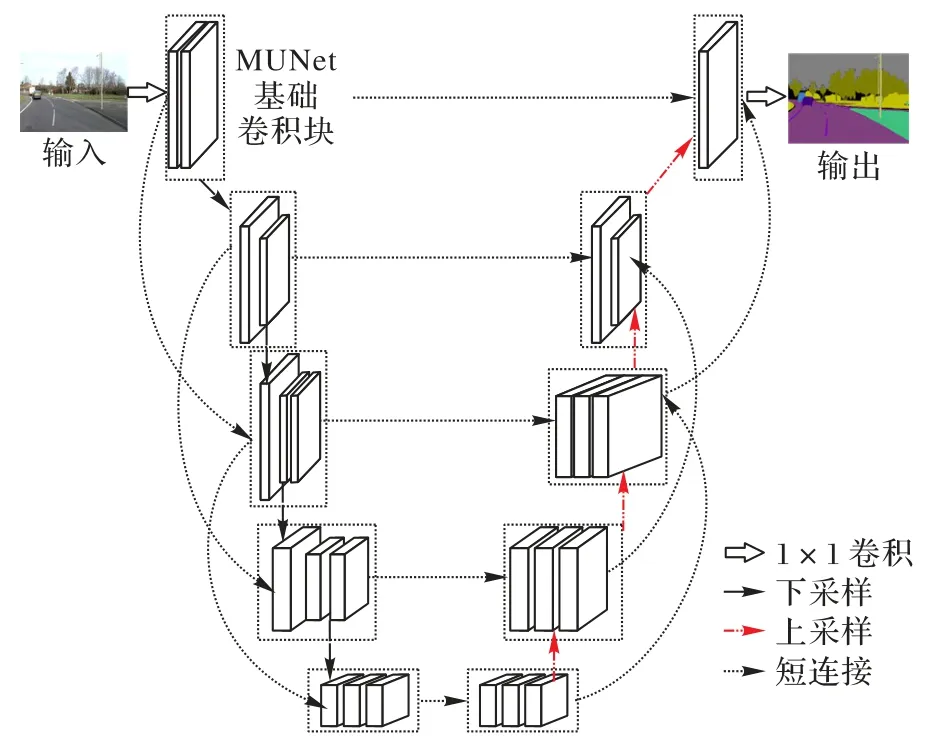
图3 MUNet网络结构Fig.3 Network structure of MUNet
2.2 稀疏短距离连接
MUNet在网络编码端以及解码端中设计了前面层和后面层的稀疏短距离连接,将相邻网络层卷积得到的高层语义特征以及底层细节特征进行通道级别的融合,实现特征复用从而得到更好的分割结果。与文献[35]和文献[36]中的前后层密集连接不同,为了实现模型参数量和性能表现之间更好的折中,本文实现的是稀疏短距离连接,即每层网络并不作为相邻层的直接输入,而是作为相邻层的下一层的额外输入。
使用公式表示网络在第i层的输出为:

Fi(·)为非线性转化函数,由一系列深度可分离卷积等操作组成,这里的第i层在本文中实际上表示由多个卷积层组成的第i个卷积块层。编码端以及解码端的稀疏短连接结构类似,在编码端的稀疏短连接具体结构如图4所示。
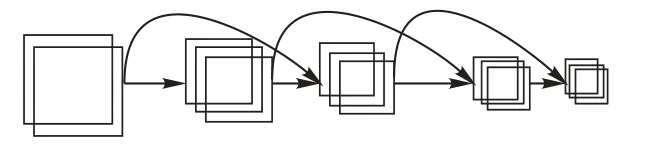
图4 MUNet稀疏短连接结构Fig.4 MUNet sparse short connection structure
2.3 注意力机制
MUNet使用编码器-解码器结构来融合多尺度信息,但是这类方法捕获的是同类上下文,而忽略了不同类别的上下文关系。为了能有效聚合不同类别上下文信息,在物体边缘处获得更精确的预测,本文在MUNet 中融入了类似文献[23]中的混合注意力机制GC 模块,该注意力机制将Non-local 模块以及Squeeze-and-Excitate(SE)[21]模块进行有效融合,进一步提升网络分割性能。
SE 模块对不同通道进行权值重标定,由于其主要捕捉通道依赖,缺乏对空间信息的全局上下文建模。而Non-local 模块主要捕捉长距离依赖,旨在从其他位置聚集信息来增强当前位置的特征,这样的操作计算量巨大。因此,SE 模块和Non-local 模块的融合能够达到取长补短的效果,对整个特征进行全局上下文建模,增加特征提取的多样性。
在本文中使用的GC模块用公式可表示为:

在式(4)中将输入的特征图定义为x=,z为模块的输出,Np表示特征图的位置数量,Wk、Wv1以及Wv2为线性转换矩阵,表示1×1卷积。
具体模块细节如图5所示。
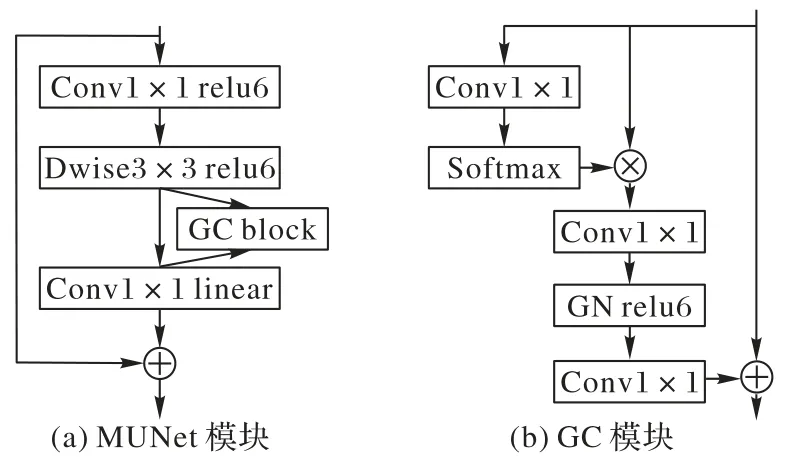
图5 MUNet中使用的GC模块结构Fig.5 GC block structure used in MUNet
GC 模块主要分为三部分:第一部分使用1×1 卷积以及Softmax 函数来进行全局上下文建模;第二部分使用类似SE模块的设计来捕捉通道依赖;第三部分是将第二部分得到的结果与模块原始输入进行通道级融合,聚合全局上下文信息到具体特征中。
2.4 组归一化
针对BN 在batch size 较小时其结果反而不是很好的问题,本文选择使用GN 来有效替代BN。GN 按组划分输入通道,对每组计算均值以及方差来进行归一化,其计算独立于batch size,因此和BN 相比,更适合于batch size 较小的归一化情况。GN归一化方式和BN之间的对比如图6所示,图中的C表示通道维度,N表示batch size,阴影部分的像素表示通过这部分像素值聚合得到的均值以及方差来进行归一化。

图6 归一化方式比较Fig.6 Comparison of normalization modes
3 实验结果
3.1 实验设置
实验在一台CPU 为Intel Core i7、GPU 为GTX 1080、内存大小为64 GB 的计算机上运行,实验环境具体采用操作系统Ubuntu 16.04,编程语言python3.7.6,深度学习框架tensorflow-gpu1.14.0,GPU加速工具CUDA10.0以及cuDNN 7.6.4。
实验用的数据集是剑桥驾驶场景标注视频数据集(Cambridge-driving Labeled Video Database,CamVid)[37],是第1 个从驾驶汽车的角度拍摄,具有目标类别语义标签的道路场景视频图像集合。主要提供32 个精细标注语义标签,实际上训练集图像只有421 张,测试集图像168 张,原始训练图像大小都为960×720。为了使网络能够正常训练这些数据,在训练时将图像裁剪成512×512 大小,同时进行水平翻转以及垂直翻转来进行数据增强。
MUNet 网络训练时batch size 由于硬件限制设置为1,优化算法使用均方根传递(Root Mean Square prop,RMSProp)算法,初始学习率(learning rate)设置为0.000 1,使用交叉熵函数作为损失函数,relu、relu6以及h-swish交替作为激活函数。
实验采用的评估指标是平均交并比(Mean Intersection over Union,MIoU)、总的模型参数量以及模型计算量(FLoating Point Operations,FLOPs)。MIoU 主要是用来评估模型分割结果,计算预测值和真实值重叠的比例。参数量计算模型总的可训练参数量,主要评估模型的空间复杂度;FLOPs指的是浮点运算数,可以用来评估模型的时间复杂度。
3.2 对比实验
为了验证稀疏短距离连接、注意力机制GC模块以及组归一化GN 方法的有效性,本文在CamVid 数据集上进行了对比实验,测试图像也同样裁剪成了512×512 大小。具体实验设计以及结果如表1所示。
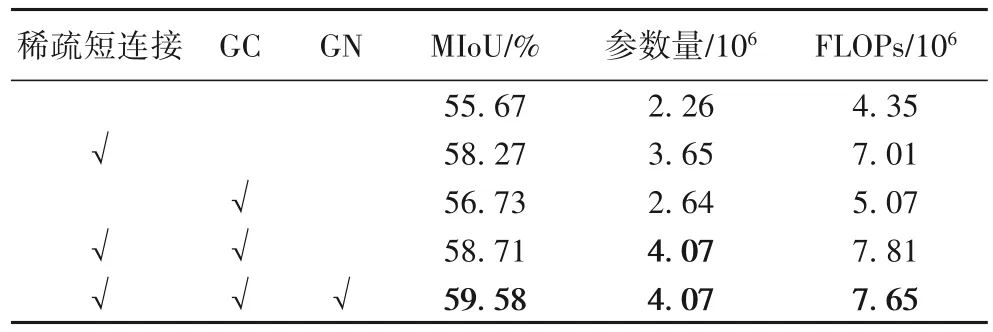
表1 MUNet在CamVid数据集上的对比实验结果Tab.1 Comparison of experimental results of MUNet on CamVid dataset
在表1 中,只使用深度可分离卷积构建的U 型编码器-解码器网络原始模型得到的MIoU 为55.67%。与原始的MUNet相比,仅加入稀疏短连接后的模型分割结果MIoU 增加了2.60 个百分点;仅加入GC 注意力机制后的模型分割结果MIoU 增加了1.06 个百分点;加入稀疏短连接以及GC 后的MUNet 模型分割结果MIoU 增加了3.04 个百分点;在上面的网络中将GN 替代BN 对网络层进行有效的归一化,最后得到的分割结果MIoU增加了3.91个百分点。
为了对比其他注意力机制对MUNet 的影响,本文还设计了在原始MUNet 中融合另外两种不同注意力机制SE block[21]以及CBAM[15]的对比实验,实验结果如表2所示。

表2 不同注意力机制对比实验结果Tab.2 Comparison of experimental results of different attention mechanisms
分别增加了GC 注意力机制和SE注意力机制的网络和原网络相比,参数量和FLOPs 的增加都非常小。在表2 中参数量和计算量按照科学计数法表示,相应结果乘以106,折算下来两种注意力机制在参数量和计算量上的差别微乎其微,但使用GC block的网络MIoU会更高。CBAM注意力机制较为复杂,所以在MUNet中增加少量的CBAM 模块得到的MIoU比未加之前更差,同时CBAM所增加的参数量和计算量也是这三种注意力机制中最多的,这样的CBAM并不适合在设计轻量级网络的情况下使用。对比其他两种注意力机制,使用GC注意力模块后的模型分割结果是最好的,增加的参数量以及计算量相对较少,在模型分割结果和复杂度之间是最好的折中。
3.3 结果与分析
在1 000 轮训练下,当测试图像都裁剪为512×512 大小时,MUNet和其他现存的图像语义分割模型在CamVid数据集上的对比实验结果如表3所示。

表3 图像语义分割模型实验结果Tab.3 Experimental results of image semantic segmentation models
在表3 中,本文提出的MUNet 模型在参数量和计算量都很少的情况下,分割结果MIoU 高于使用ResNet101[38]作为基准网络来提取特征的PSPNet、DeepLabv3+、GCN、RefineNet[39]图像语义分割网络。而MUNet 和其他轻量级语义分割模型在CamVid数据集上的对比实验结果如表4所示。
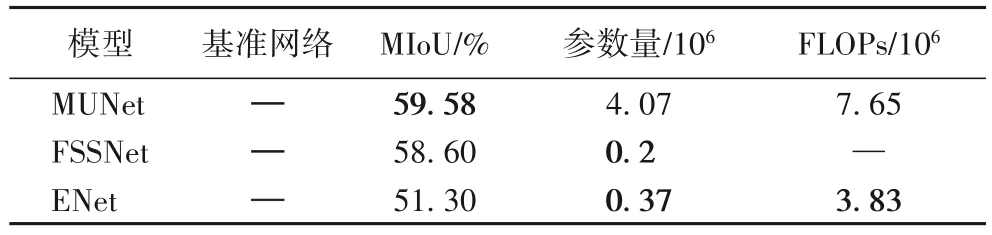
表4 轻量级语义分割模型实验结果Tab.4 Experimental results of light-weighted semantic segmentation models
和属于轻量级网络的快速语义分割模型(Fast Semantic Segmentation Network,FSSNet)[2]以及高效神经网络(Efficient neural Network,ENet)[40]比较,MUNet 的参数量会多一些,但分割效果更好,其MIoU 比FSSNet 网络的MIoU 高约1 个百分点左右,比ENet网络的MIoU高8.28个百分点,是模型参数量以及计算量和模型分割精度之间相对较好的折中。FSSNet原文没有给出计算量指标,因此两者在计算量维度上无法进行比较。
由于硬件限制,对于分辨率为960×780 大小的原始输入图像,将其裁剪为512×512 大小进行训练。测试的时候,对于不同分辨率大小的测试图像,模型分割结果是不一样的,如表5所示。

表5 MUNet对不同分辨率图像的分割结果Tab.5 Segmentation results of MUNet for different resolution images
模型针对分辨率稍大一些的测试图像,能获得更多的细节信息,分割结果也相应地会更好。在表5 中当测试图像分辨率为720×720 时,MUNet 模型分割结果是最好的,其MIoU达到了61.92%。模型具体分割结果对比如图7所示。在图7中,主要选取了CamVid 数据集中比较典型的4 种道路场景,涵盖了行人、车辆、路灯、车道线以及小动物等不同类别,这些类别在道路场景中大小不一。为了更好地展示网络分割效果,图7中的所有图都被裁剪为512×512,由于篇幅的限制,在结果图显示中只选取了具有代表性的PSPNet 以及RefineNet和MUNet模型分割结果图进行比较。
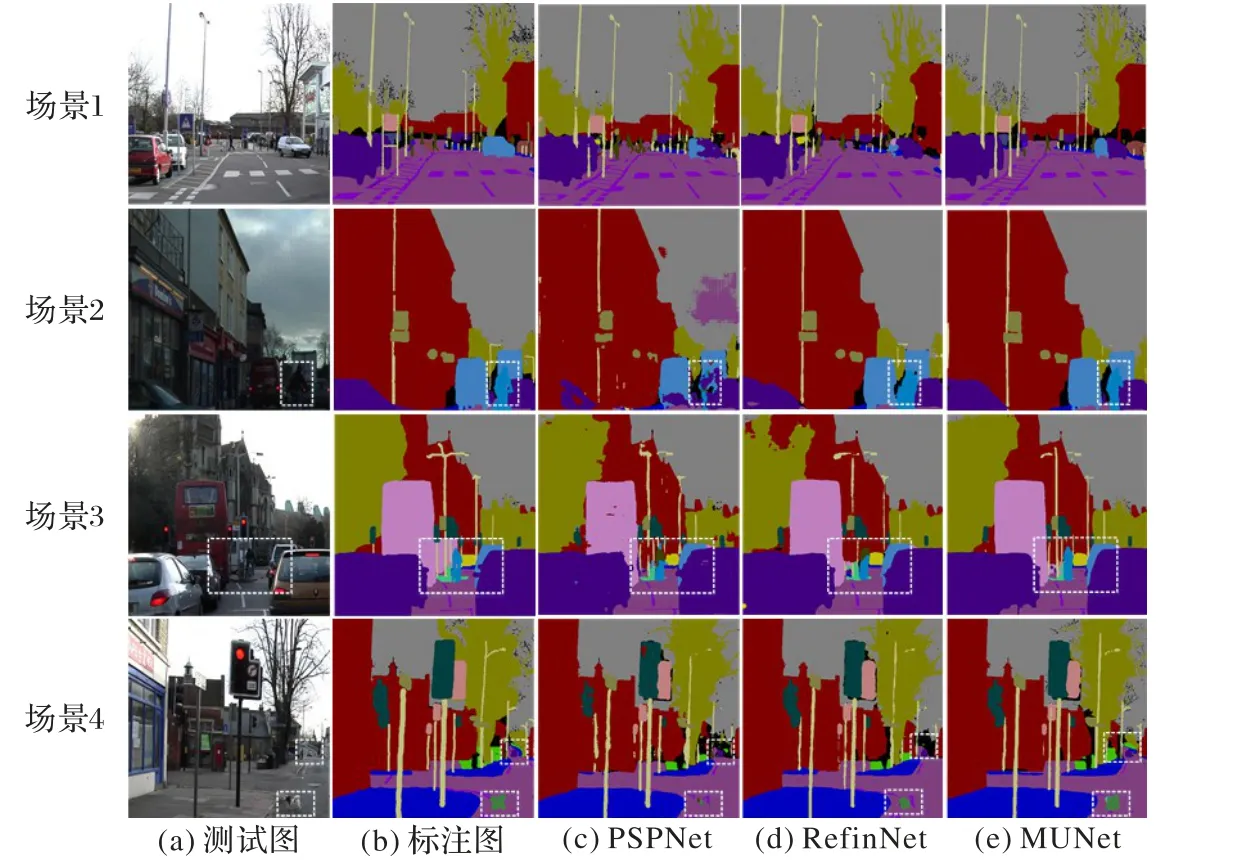
图7 测试图像、精细标注以及分割结果Fig.7 Test images,accurate labeling and segmentation results
场景1 中,道路上视野远处车辆少而行人较多,难点在于视线正前方远处这块人流聚集区域的识别与分割;而场景2和场景3 属于在城市道路场景中人车交汇比较复杂的场景,虚线框处的骑着自行车的行人和视线远处紧挨着大型公交车的行人在车流中不容易被识别出来,但是这些类别却是真实驾驶场景中最应该注意分割的类别;场景4 中如图中虚线框所示,视线远处的车辆行人和红绿灯下的狗都是需要特别注意的分割重点,因此在分割中应该要能把这些类别都清晰地分割出来。综合比较三种网络在这四种场景下的分割结果图,MUNet 是最能将上述四种场景中的难重点完整分割出来的网络,其他两种网络的分割结果都存在着不同程度的变形。
实验结果表明,本文提出的MUNet 模型能够较好地适应不同的道路场景,对于简单一点的场景,不管地面交通标记还是正在行驶中的车辆行人,模型的分割结果和精细标注非常接近。然而对于复杂情况,由于复杂道路场景中细节过多,模型无法很好地对远处微小物体以及多种目标混合区域进行完美的分割,比如在图7 最后一个场景中,对于视野远处的道路栅栏和车道线,容易出现分割不完整或者是没有分割到的情况。
4 结语
本文基于深度可分离卷积,设计出一种对称U型编码器-解码器式轻量级图像语义分割网络MUNet,并在其中加入稀疏短连接设计、注意力机制以及组归一化方法,在极大地减少网络模型参数量以及计算量的同时,较好地提升网络分割性能。和其他轻量级网络相比,文章提出的MUNet 虽然在分割性能上表现较好,但在参数量和计算量方面仍需继续改进。
本文实验过程中设计了不同分辨率测试图像的对比实验,而这也给之后的工作带来一些启发,尝试加入多尺度输入图像去获得更精细的分割结果。由于硬件限制,本文实验仅使用小数据集训练1 000轮得到接近收敛的模型,在硬件设施允许的情况下,其实可以使用大数据集得到更优的分割结果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2015年1期)2015-02-27
中学英语之友·高一版(2008年10期)2008-12-11
