
基于深度学习的目标检测研究*
2021-07-01 07:14帅泽群李军
汽车工程师 2021年5期
帅泽群 李军
(重庆交通大学机电与车辆工程学院)

目标检测是一个重要的计算机视觉任务,主要是处理和检测视觉上特定的类(如人、动物或标志等)在数字图像上的类别和位置分布情况。目标检测就是建立有效的计算机应用模型,提供计算机视觉所需要的最基本的信息,即什么目标类别在什么地方[1]。所以目标检测可以认为是图像识别和目标定位2个任务的结合,是其他许多计算机视觉任务的基础,比如实例分割[2]、人脸识别[3]、目标跟踪[4]等。图像识别是利用对图像的特征进行提取,从而能进行分类。目标定位是进行边界框的回归,最终能准确定位,属于回归问题[5]。对于目标检测的研究大致分为2个方向:1)针对一个固定模型下的检查来判断其能否拥有和人类一样的感受视线;2)检测特定复杂的应用场景,如遮挡物检测[6]、行人检测[7]、车辆检测[8]等等。近些年来,由于传统的目标检测算法出现的一些弊端,加上深度学习技术的出现,加速了目标检测的发展。
1 目标检测
1.1 目标检测的应用
在无人驾驶汽车领域,目标检测主要应用于行人检测、车道线检测、交通标识检测以及障碍物检测等等,根据不同的需求对特定的、复杂多变的场景进行指定目标的检测。民用运载工具数量的增长带来了更复杂的运输环境,需进一步提高该技术在工程应用上的实时性和鲁棒性。
1.2 目标检测的分类
目标检测发展的第1个阶段,即传统目标检测时期。由于当时缺乏有效的图像表示,人们不得不设计复杂的特征表示以弥补手工特征表达能力上的缺陷。这种做法不仅消耗了大量的计算资源,而且使检测的实时性变得很差。
随着深度学习的到来,目标检测发展到第2个阶段。人们发现深度学习的监督学习或无监督学习能够很好地提取图像的特征。在这个阶段,目标检测大致分为“一阶段检测”和“两阶段检测”2种检测方式。一阶段的检测器在检测的实时性上更强[9];两阶段的检测器在检测精度上更具有优势。
2 发展历史
2.1 传统检测算法
Paul Viola和Michael Jones设计了一个准确定位人脸的检测器。在当时硬件条件有限的情况下可以达到很高的精度和效率,每秒钟大概可以处理15张图像。在手动提取特征的阶段,这是目标检测技术的里程碑。为了纪念研究人员,这种能应用在实际生活中的检测器被称为Viola-Jones(VJ)检测器。
Navneet Dalal和Bill Triggs在2005年提出HOG检测器。它的核心思想是对梯度信息进行统计,因为图像的梯度信息主要存在于图像的边缘,所以图像局部目标的表象和形状能够被这些梯度信息很好的表示出来。之后再与机器学习中作为分类算法的支持向量机相结合,因此在图像识别和目标检测的领域有着很高的实用价值。目前大多数的人体或行人检测都是采用HOG+SVM的检测方式来进行检测,或者基于这样的思路来进行一些更加出色的改进。
2.2 神经网络检测算法
2012年,卷积神经网络出现在人们的视线之中[10]。卷积神经网络因其能有效地提取图像特征,在复杂场景下有很强的鲁棒性和高级特征表示,所以在目标检测上有巨大的应用价值。
RCNN[11]是典型的两阶段检测器,它的数学模型原理简单,首先利用自己设置的选择性搜索在目标图片上搜索很多的预选框,由于预选框内图片的大小不一样,直接传入网络进行特征提取很可能使得数据出现问题,所以在输入图像之前要先对预选框内的图像进行缩放处理,使它们的尺寸变得一致。最后利用分类器,如支持向量机等进行判断分类和边界框回归处理。
2014年,空间金字塔池化网络(SPPNet)被提出[12]。SPP的提出是为了解决RCNN在检测方面的一些缺陷。RCNN需在预选框内缩放图片使其产生固定尺寸的图片[13]。而SPP对输入图片的尺寸无任何要求,在结果段都能输出一样大小的特征图片,在不影响检测精度的前提下很大程度上提高了检测速度。SPP还采用了多级池化层,保留物体的最主要特征,在复杂背景和一些强干扰下有很好的鲁棒性,在各个尺度上的检测效果良好。
2015年刘伟等人提出SSD[14]算法。SSD是一种直接预测目标类别的多目标检测算法,它首先通过CNN网络模型提取特征图,再对特征图进行回归分类。同时,SSD算法增加了多尺度特征图功能,能够在不同层次的特征图上回归不同尺寸的候选框,检测不同大小的目标,提高了识别准确度。
3 YOLOv3算法
目前YOLO系列算法已经更新至第5代版本,第1代到第4代已经在市面上开源,很多深度学习框架都可以很好地实现YOLO系列算法。文章以较为经典的一阶段检测算法YOLOv3为例,详细介绍YOLO系列算法的模型原理[15]。
3.1 YOLOv3的网络架构
主干特征提取网络是YOLO算法比较核心的部分,它的主要作用就是提取图像的特征。YOLOv2算法的主干网络是一系列卷积层和池化层等组成的共19层的网络,称为Darknet-19,而YOLOv3将主干网络的层数加深至53层,它将每一层打包为一个残差模块,结构十分清晰,每个残差模块包括卷积层、激活函数层、Batch Normalization层等,以及在加深网络中起到重要作用的残差连接。残差连接中的跨层加和操作很好地解决了纯粹叠加出来的网络检测效果很差的问题。
图片在输入时像素大小调整为416×416,为了防止失真,会在图像上加上灰度条。在通过主干网络特征提取之后分成3个不同尺寸的特征图,即13×13、26×26、52×52,由于图像在多次卷积压缩之后,小物体的特征容易消失,所以52×52的图像用来检测小物体,26×26的图像用来检测中等物体,而13×13的图像用来检测大物体。每个特征图被大小相同的网络划分,每个网格点负责其右下角区域的检测,即只要物体的中心点落在这个区域,这个物体就由这个网格来确定。
3.2 YOLO输出特征图解码
从YOLO算法输出的参数并不能直接看出检测的最终结果,需要进行一定的计算解码。最终输出结果中每张图的通道数是根据具体检测的类别数而定的。预测框的位置为2轴坐标以及高宽,一共是4维,预测的置信度为1维,如果检测COCO数据的类别,那么类别数就是80维。最后的通道数就是(80+1+4)×3=255。其中,3代表预先设置好的3个不同的用来回归的初始框,也叫先验框。
3.2.1 先验框
在YOLO最初的版本中,对于预测框的回归都采用的是直接回归边界框的宽和高,这种方式导致学习的困难程度增加,且回归效果不理想。之后在YOLOv2版本中提出了先验框概念,即根据要检测的目标提前设置边界框,可以理解为开始学习时的初始值。基于先验框再进行回归操作远比毫无目的的直接回归的学习难度要小得多。YOLOv3在这个基础上又进行了改进,检测的目标尺寸有大有小,所以对先验框的尺寸进行调整,可以理解为调出较好的初始值来进行更好的训练。目前大多数论文都是利用k-means算法对数据中的真实框进行聚类,得到大中小3种先验框,又因为YOLOv3输出3个特征图,所以一共有9个先验框。另外,先验框只关心和目标物大小的匹配程度,即先验框只和预测框的宽和高有关系。
3.2.2 检验框解码
下面是检验框的解码公式:
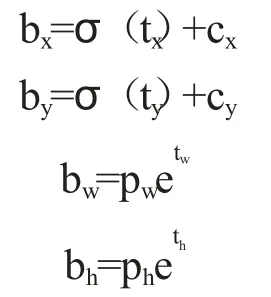
检测端输出数据是(tx,ty,tw,th),即这4个参数是已知的。而且物体的中心落在了(cx,cy)处,所以通过这个中心再加上相对于这个左上角中心的偏移量σ(tx),σ(ty)就可以求得预测框的中心坐标。pw,ph是先验框的高度,显然可以求出预测框的宽和高。这样预测框的4个值都可以解码出来,再乘以特征图的采样率就可以得到真实预测的边界框参数。
3.2.3 检测置信度与类别的解码
检测值信度的解码并不是很复杂,但十分重要。置信度的维度在所有维度中占1维,由sigmoid函数解码使数值在0~1之间。这会影响最终的检测正确率和召回率,是对检测器好坏的直接评价标准。训练和推理时的解码过程有一些小不同,在网络学习时所有的预测框都会进行损失函数的计算,进行权重的更新迭代。而在推理过程中,预测参数直接输出。
4 注意力机制与数据融合
4.1 注意力机制
当观察图像时,人的视觉会首先接受鲜明、尺寸较大的目标,而那些大面积无关主题的物体和目标就会沦为背景。注意力机制[16]就是基于这个思想,通过不断的训练学习,更新出最优的权重系数,这组权重系数可以强化之前特征提取出来的感兴趣区域,抑制与主题不相关的背景目标,这种做法会使后续的检测效果有很大提升。在计算机视觉领域运用较多的是通道域和空间域[17]。将通道注意力机制和空间注意力机制融合的研究也很多,而且实验表明将2种注意力机制串行排列效果更佳。
通道注意力机制和空间注意力机制的区别就是2个机制的关注点不同,通道注意力机制将问题聚焦在通道数上,即在通道数很多的特征图像上哪些才是真正需要、有意义的图像[18]。基于这样的设计思路,往往需要将空间信息进行压缩和聚合,采用的操作是最大池化和平均池化同时进行,得到2个同维度的张量。再将这2个张量送到由多层感知机组成的共享网络中。另外,它的一个很大的优点就是能轻易地接入其他网络中去,提高其网络的性能。空间注意力机制重点关注如何从特征图上保留更加关键的信息,这样的操作有点类似于池化层保留特征的方式,其模型的提出者认为池化层的操作太过于简单,虽然操作方便,但很容易造成特征的丢失,导致关键的信息无法识别出来。空间注意力机制的设计思路就是将原输入图片的信息转换到另一个空间中去保留起来[19]。
4.2 数据融合
数据融合[20]目前较多应用于自然语言处理的研究上,在计算机视觉和无人驾驶领域的应用主要有多传感器信息的融合[21]、遥感影像数据的融合[22]等。数据融合思想产生是因为单一数据集无法满足网络的学习和训练,通过这种属性融合加上智能化的合成,产生的数据信息源更加的稳定精确,能进行更加可靠的计算。同时数据融合在技术层面还存在许多待攻克的难题,例如提高数据的可信度、融合模型不统一导致训练结果不一样、数据融合前的预处理过程的精度也需要提高等[23]。
5 基于YOLO系列改进算法的实际应用
在实际生活中,根据场景以及目标检测物的不同,能够随时修改模型,达到实验所需。例如可以针对小尺寸目标物进行检测,也可以对多个目标物进行多尺度检测。常州大学人工智能与计算机学院提出了一种基于头部识别的安全帽佩戴检测算法,通过肤色识别和头部检测交叉识别头部区域,再使用YOLOv4目标检测网络识别安全帽,通过安全帽区域与头部区域的位置关系判断安全帽的佩戴情况[24]。江南大学的人工智能与计算机学院基于YOLO算法提出了可见光与红外光融合的行人检测算法,提出了结合注意力机制的模态加权融合层,使得对于行人的检测在夜间以及目标物被严重遮挡的情况下也能有较高的识别精度和较快的检测速度[25]。华东政法大学信息科学与技术系基于轻量级的YOLO模型改进了它的残差网络[26],提出了部分残差连接,使得模型参数进一步减少,检测的精度也能满足需求[27]。武汉科技大学汽车与交通工程学院提出了一种小型化的改进YOLOv3神经网络的实时车辆检测算法,可以满足实际无人驾驶过程中对车辆检测的精度和速度的基本条件[28]。上海电力大学电子与信息工程学院提出了一种基于轻量级网络的虹膜图像人眼定位及左右眼分类算法。利用YOLO算法结合高性能的轻量级网络模型设计EL-YOLO模型,损失函数引入广义交并比,使得网络训练可以快速收敛,且定位精度高[29]。
6 结论
文章介绍了传统的目标检测算法与基于深度学习的目标检测算法的原理和发展历史,详细介绍了YOLOv3算法的网络结构和工作原理,分析了输出值的解码过程。结果表明,YOLO系列算法在检测速度上更具优势。为进一步提高检测效率及精度,可引入注意力机制模块和数据融合技术,并在特殊复杂的检测场景中采用改进卷积神经网络或融合各类网络优势模块进行针对性训练,以提高检测器的综合性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
睿士(2020年6期)2020-08-18
南方周末(2019-12-19)2019-12-19
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
第二课堂(课外活动版)(2016年2期)2016-10-21
岁月(2016年5期)2016-08-13
