
Novel Complex T-Spherical Dual Hesitant Uncertain Linguistic Muirhead Mean Operators and Their Application in Decision-Making
2021-06-29 02:20ShouzhenZengZeeshanAliandTahirMahmood
Shouzhen Zeng,Zeeshan Ali and Tahir Mahmood
1School of Business,Ningbo University,Ningbo,315211,China
2College of Statistics and Mathematics,Zhejiang Gongshang University,Hangzhou,310018,China
3Department of Mathematics and Statistics,International Islamic University,Islamabad,44000,Pakistan
ABSTRACT In this manuscript,the theory of complex T-spherical dual hesitant uncertain linguistic set is discovered,which is the mixture of three different ideas like the complex T-spherical fuzzy set,dual hesitant fuzzy set,and uncertain linguistic set.The complex T-spherical dual hesitant uncertain linguistic set composes the uncertain linguistic set, truth grade, abstinence grade, and falsity grade.Whose real and imaginary parts are the subset of a unit interval,and some of their operational laws are also presented.The theory of complex T-spherical dual hesitant uncertain linguistic Muirhead mean operator, complex T-spherical dual hesitant uncertain linguistic weighted Muirhead mean operator, complex T-spherical dual hesitant uncertain linguistic dual Muirhead mean operator and complex T-spherical dual hesitant uncertain linguistic weighted dual Muirhead mean operator are discovered.Some exceptional cases of the proposed operators are also examined.A multi-attribute decision making technique is further utilized based on explored operators.Moreover,an enterprise informatization level evaluation issue is resolved by using the presented operators to verify the proficiency and capability of the discovered approaches.Finally,some comparative analysis and advantages of the explored works are further developed to express that it is more flexible and effective than the existing methods.
KEYWORDS CTSDHULSs; Muirhead mean operators; MADM; enterprise informatization level evaluation
Abbreviations
CTSFSComplex T-spherical fuzzy sets.
DHFSDual hesitant fuzzy sets.
ULSUncertain linguistic sets.
CTSDHULSComplex T-spherical dual hesitant uncertain linguistic sets.
CTSDHULMMComplex T-spherical dual hesitant uncertain linguistic Muirhead mean operator.
CTSDHULWMMComplex T-spherical dual hesitant uncertain linguistic weighted Muirhead mean operator.
CTSDHULDMMComplex T-spherical dual hesitant uncertain linguistic dual Muirhead mean operator.
CTSDHULWDMMComplex T-spherical dual hesitant uncertain linguistic weighted dual Muirhead mean operator.
MADMMulti-attribute decision making.
1 Introduction
Owing to the extensive existence of uncertain information, some practical decision-making issues are often intractable and complicated, which are very difficult for a decision-maker to cope with.For managing such kinds of issues, the theory of intuitionistic fuzzy set (IFS)was discovered by Atanassove [1].IFS is a modified version of the fuzzy set (FS)[2], composing the grade of truth and the grade of falsity with a condition that the sum of both grades’cannot exceed the unit interval.Numerous scholars have widely explored the application of the IFS theory in different fields [3–5].In general, the IFS must hold the limitation that the sum of both grades cannot exceed the unit interval.However, in awkward realistic decision issues, this limitation cannot always be held.For example, if a decision-maker provides the pairA=(0.7,0.6)for the grade of truth and the grade of falsity.As 0.7+0.6=1.3>1, thenAcannot be handled by the IFS.To extend the information space that IFS cannot describe, Yager [6] discovered the Pythagorean fuzzy set (PyFS)with a constraint that the sum of the squares of both grades is limited in the interval [0, 1].Compared to the IFS, the PyFS is more extensively proficient to handle awkward and vague information in realistic decision issues.However, there is still a problem in PyFS, i.e.,when a decision-maker provides the pairA=(0.9,0.8)for the grade of truth and the grade of falsity, thenAcannot be handled by PyFS and IFS as 0.92+0.82=0.81+0.64=1.45>1.To extend the PyFS’s information space, Yager [7] then discovered the q-rung orthopair fuzzy set(QROFS)with a constraint that the sum of the q-powers of both grades cannot exceed from [0,1].The QROFS is an useful extension of the PFS and IFS to solve the awkward and uncertain information in realistic decision issues.At present, Numerous applications of the QROFS have extensively been utilized in different fields [8–10].
There are no complications that the theory of IFS has an extensive technique to manage awkward and difficult information in real-life issues, but it still cannot precisely deal with some voting problems in reality.This category of voting divides into four parts, i.e., the vote in favor,abstinence, vote against, and refusal.For managing such kinds of problems, the theory of picture fuzzy set (PFS)was discovered by Cuong et al.[11].The PFS composes the grade of truth,abstinence, and falsity with the condition that the sum of all grades shall limit in the unit interval.Until now, it has received numerous extensions and applications in different fields [12–14].But,when a decision-maker provides the pairA=(0.6,0.5,0.3)for the grade of truth, the grade of abstinence, and the grade of falsity, the PFS cannot handle this evaluation as 0.6+0.5+0.3=1.4>1.To overcome this limitation, Mahmood et al.[15] then discovered the spherical fuzzy set(SFS)with a condition that the sum of the squares of the truth, abstinence, and falsity grades cannot exceed the unit interval.However, the SFS is useless to deal with the pairA=(0.9,0.8,0.7),wherein 0.9+0.8+0.7=2.4>1 and 0.92+0.82+0.72=0.81+0.64+0.49=1.94>1.To achieve a broader information space, Mahmood et al.[15] discovered the T-spherical fuzzy set (TSFS)with a situation that the sum of the q-powers of the truth, abstinence, and falsity grades shall list in the unit interval.Now the theory of TSFS has been extensively utilized in different areas [16–18].
The theory of complex IFS (CIFS)was discovered by Alkouri et al.[19].CIFS is a basic modified version of complex FS (CFS)[20], composed by the grade of truth and falsity in the form of a complex number with the condition that the sum of the real part (also for the imaginary part)of both grades shall not exceed the unit interval.The graphical representation of the unit circle in a complex plane is discussed in the form of Fig.1.It has attracted the attention of many researchers and has been widely utilized in various fields [21–23].The CIFS must hold the limitation that the sum of the real part (also for the imaginary part)of both grades cannot exceed the unit interval.However, in awkward realistic decision issues, this limitation cannot be always held.Afterward, Ullah et al.[24] presented the complex PFS (CPFS)with a constraint that the sum of the real part (also for the imaginary part)of the squares of both grades’cannot exceed from [0, 1].Compared with the CIFS, the CPFS is more effective to cope with awkward and vague information in realistic decision issues.Based on the CPFS, Liu et al.[25,26] developed the complex QROFS (CQROFS)with the constraint that the sum of the real part (also for the imaginary part)of the q-powers of both grades cannot exceed from [0, 1] [27–33].The geometrical interpretation of the existing notions is discussed with the help of Fig.2.
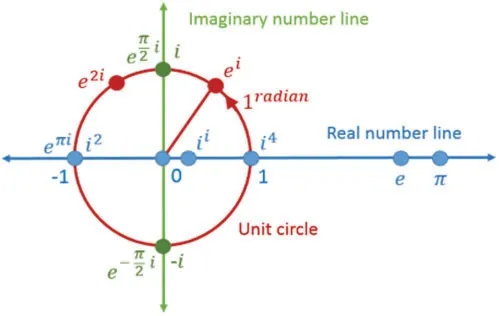
Figure 1: Geometrical representation of the unit disc
Figure 2: Graphical representation of the IFS, PFS, and QROFS
The FS utilizes just one value to express the truth grade, nonetheless, decision-makers are often hesitant among a few qualities while building up the truth grade in extensive practical MADM issues.To successfully manage decision-makers high hesitancy, Torra [34] presented the idea of a hesitant FS (HFS), which permits the truth grade to be signified by a few single values rather than just one.Inferred from its great capability of finding fuzzy data and decisionmakers hesitancy, HFS has been viewed as one of the most impressive and adaptable techniques in MADM methodology [35–37].However, the HFS is coping only with the truth level, whereas it ignores the grade of falsity.Zhu et al.[38] then presented the dual HFS (DHFS), which contains the truth grade as well as the falsity grade in the form of subsets of [0, 1].If compared with the HFS, the DHFS is more proficient and reliable to cope with complicated and awkward information in realistic decision issues.Numerous scholars have utilized the theory of DHFS in different fields [39–41].
In genuine decision-making, there are numerous complexities and difficulties which are hard to give attribute values by quantitative assessment.Nonetheless, they are anything but difficult to give the linguistic assessment.Since Zadeh [42] discovered the linguistic variable set (LVS),the exploration of multi-attribute decision-making issues based on linguistic assessment data has gotten rich accomplishments.Now and again, decision-makers do not communicate his/her feelings by choosing linguistic labels, but they can show the data by interval linguistic label, in other words, by uncertain linguistic variables (ULVs)[43,44].In certain genuine life troubles, we go over numerous circumstances where we need to measure the vulnerability existing in the information to settle on ideal choices.Data measures are significant devices for taking care of unsure data present in our day-to-day life issues.Different measures of information, such as aggregation operators,hybrid operators, and inclusion, process the inconsistent information and facilitate us to reach some conclusion.Recently, these measures have gained much attention from many authors due to their wide applications in various fields, such as decision making, pattern recognition, and multi-attribute group decision making.All the prevailing approaches of decision-making, based on information measures, in picture fuzzy set (PFS), spherical fuzzy set (SFS)and T-spherical fuzzy sets (T-SFS)theories, deal with only the grades of truth, abstinence and falsity, which are real-valued.In CTSDHULS theory, truth, abstinence, and falsity grades are complex-valued and are represented in polar coordinates, with uncertain linguistic terms.The amplitude term corresponding to truth, abstinence and falsity degrees gives the extent of membership, abstinence,and non-membership of an object, whose real and unreal parts in the form of the finite subset of the unit interval.The phase terms are novel parameters of the truth, abstinence, and falsity degrees and these are the parameters that distinguish the CTSDHULS and traditional T-spherical dual hesitant uncertain linguistic set (TSDHULS)theories.The TSDHULS theory deals with only one dimension at a time, which results in information loss in some instances.However, in real life, we come across complex natural phenomena where it becomes essential to add the second dimension to the expression of truth, abstinence, and falsity grades.By introducing this second dimension, the complete information can be projected in one set, and hence, loss of information can be avoided.To illustrate the significance of the phase term, we give an example.Assume XYZ organization chooses to set up biometric-based participation gadgets (BBPGs)in the entirety of its workplaces spread everywhere in the country.For this, the organization counsels a specialist who gives the data concerning (i)demonstrates of BBPGs and (ii)creation dates of BBPGs.The organization needs to choose the most ideal model of BBPGs with its creation date all the while.Here, the issue is two-dimensional, to be specific, the model of BBPGs and the creation date of BBPGs.This kind of issue cannot be displayed precisely utilizing the conventional TSDHULS hypothesis as the TSDHULS hypothesis cannot handle both the measurements at the same time.The most ideal approach to address the entirety of the data given by the master is by utilizing the CTSDHULS hypothesis.The sufficiency terms in CTSDHULS might be utilized to give the organization’s choice regarding the model of BBPGs and the stage terms might be utilized to address the organization’s judgment concerning the creation date of BBPGs.
Presently, aggregation operator is one of the most important technique which will help not only in comparing one data entity with other but also show the extent of association between them and their direction.Also, CTSDHULSs have a powerful ability to model the imprecise and ambiguous information in real-world applications than the existing theories such as TSDHULS, spherical dual hesitant uncertain linguistic sets (SDHULS).Based on the ULVs, the theory of complex picture dual hesitant uncertain linguistic set (CPDHULS)is proposed, which is a very proficient technique with a condition that the sum of the supremum of the real part (also for the imaginary part)of the truth, abstinence, and falsity grades cannot exceed from the unit interval, i.e., max{0.2,0.3,0.4}+ max{0.02,0.03,0.04}+max{0.1,0.2,0.3}= 0.4 + 0.04 + 0.3 = 0.74 ≤1 and max{0.1,0.2,0.3}+ max{0.01,0.02,0.03}+max{0.2,0.3} = 0.3 + 0.03 + 0.3 = 0.63 ≤1.However, there is still a problem, given the pair{{0.2,0.3,0.7}ei2π{0.1,0.8,0.3},{0.02,0.03,0.07}ei2π{0.01,0.08,0.03},{0.1,0.2,0.4}ei2π{0.2,0.3}}, for the grade of truth, abstinence, and falsity, then the CPDHULS fails to cope with it.For coping with such types of issues, the theory of complex spherical dual hesitant uncertain linguistic set (CSDHULS)is a very proficient technique with the condition that the sum of the square of the supremum of the real part (also for the imaginary part)of the truth,abstinence, and falsity grades cannot exceed from the unit interval, i.e.,(max{0.2,0.3,0.7})2+(max{0.02,0.03,0.07})2+(max{0.1,0.2,0.4})2=0.72+0.072+0.42=0.49+0.0049+0.16=0.6549 ≤1 and(max{0.1,0.8,0.3})2+(max{0.01,0.08,0.03})2+(max{0.2,0.3})2= 0.82+ 0.082+ 0.32=0.64+0.0064+0.09=0.7364 ≤1.However, there is still a problem, when a decision-maker gives the pair {{0.2,0.3,0.9}ei2π{0.1,0.8,0.3}+{0.02,0.03,0.09}ei2π{0.01,0.08,0.03},{0.1,0.2,0.8}ei2π{0.2,0.7}}, for the grade of truth, abstinence, and falsity, then the CPDHULS and CSDHULS are not able to cope with it.
For coping with such types of issues, based on the work of complex TSFS (CTSFS)[45],in this paper, we shall develop a new fuzzy tool, called the theory of complex T-spherical dual hesitant uncertain linguistic set (CTSDHULS), a very proficient technique that can effectively solve the deficiency of existing methods in describing uncertain information.The summary of the discovered theory of this manuscript is followed as:
(1)To explore the theory of CTSDHULS and their operational laws.
(2)To develop some aggregation methods for the CTSDHULS, including the CTSDHULMM operator, CTSDHULWMM operator, CTSDHULDMM operator, and CTSDHULWDMM operator, and discuss some of their cases.
(3)A MADM technique is utilized on basis of the explored operators.The enterprise informatization level evaluation issue is presented to verify the proficiency and capability of the discovered approaches.
(4)Finally, the comparative analysis and graphical expressions of the explored works are further developed to express more extensive and flexibility than the existing methods.
The purpose of this study is organized in the following ways: In Section 2, we recall the notion of ULSs, DHFSs, CTSFSs, Muirhead mean (MM)operator, Dual Muirhead mean (DMM)operator and their operational laws.In Section 3, the notion of CTSDHULS and their operational laws are discovered.In Section 4, we explore the CTSDHULMM operator, CTSDHULWMM operator, CTSDHULDMM operator, and CTSDHULWDMM operator.Additionally, the special cases of the presented work are also discussed.In Section 5, a MADM technique is constructed and applied to solve the enterprise informatization level evaluation.Finally, a deep comparative analysis is presented to verify the proficiency and capability of the discovered approaches.The conclusion of this manuscript is discussed in Section 6.
2 Preliminaries
In this study, we recall the notion of ULSs, DHFSs, CTSFSs, Muirhead mean (MM)operator,Dual Muirhead means (DMM)operator, and their operational laws which will be used fully in the next section.
Definition 1:[42] A LTS is initiated by:

wherekshould be odd, which holds the following conditions:
(1)Ifk>k′, thenLk>Lk′;
(2)The negative operatorneg(Lk)=Lk′ with a conditionk+k′=k+1;
(3)Ifk≥k′, max(Lk,Lk′)=Lk, and ifk≤k′, max(Lk,Lk′)=Lk.

then we define some operational laws, such that:
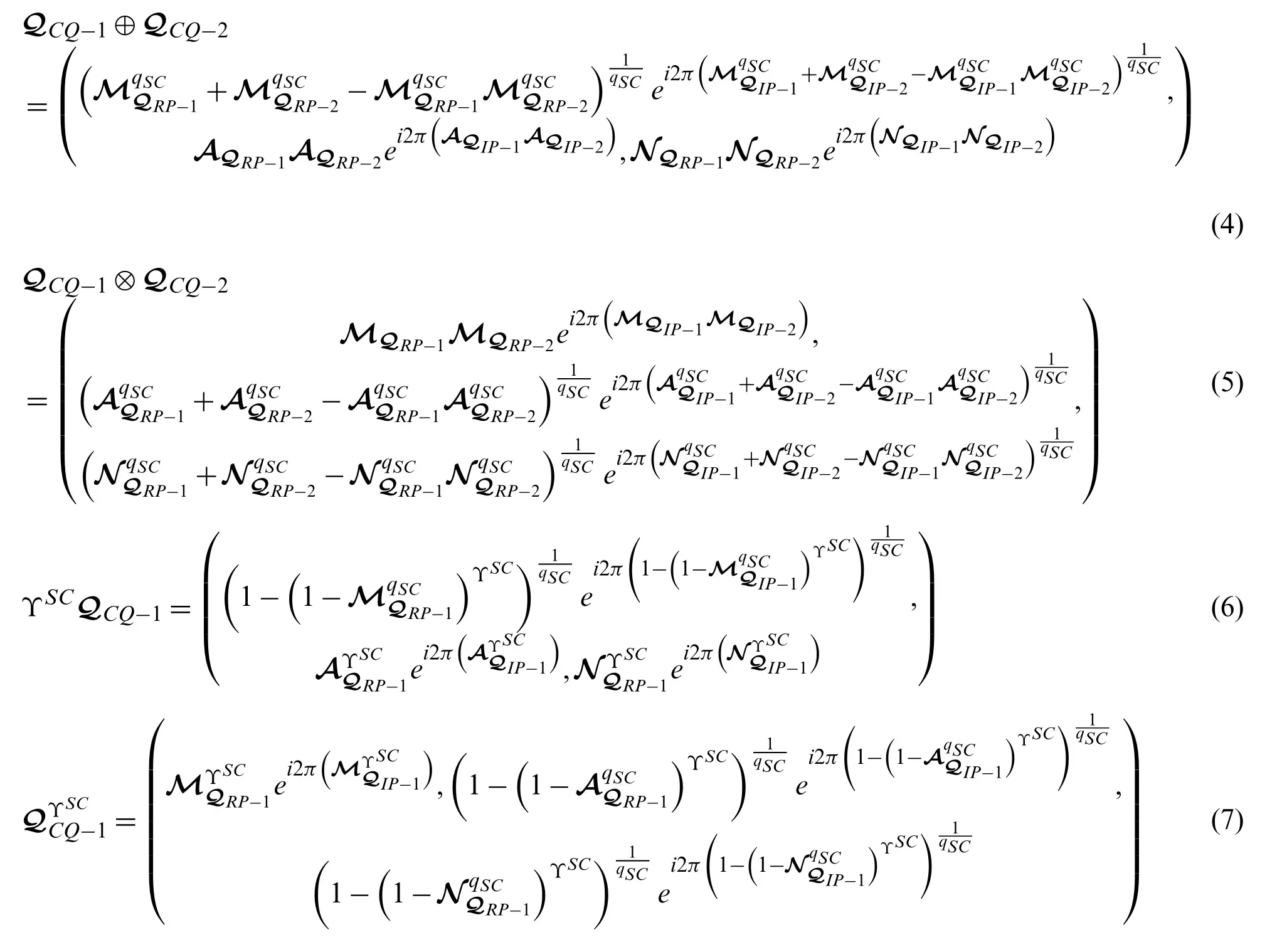
Additionally, we introduce the score function (SF)and accuracy function (AF)of the CTSFN as below:

The relationship between any two CTSFNs can be cleared with the help of the following laws:


3 Complex T-Spherical Dual Hesitant Uncertain Linguistic Sets
In this study, we discover the idea of CTSDHULSs and their basic laws which are very helpful in the next section.
Definition 6:A CTSDHULSQCDis initiated by:
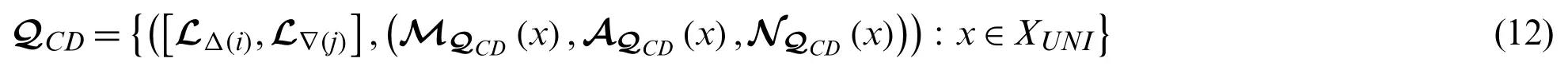
where the symbols

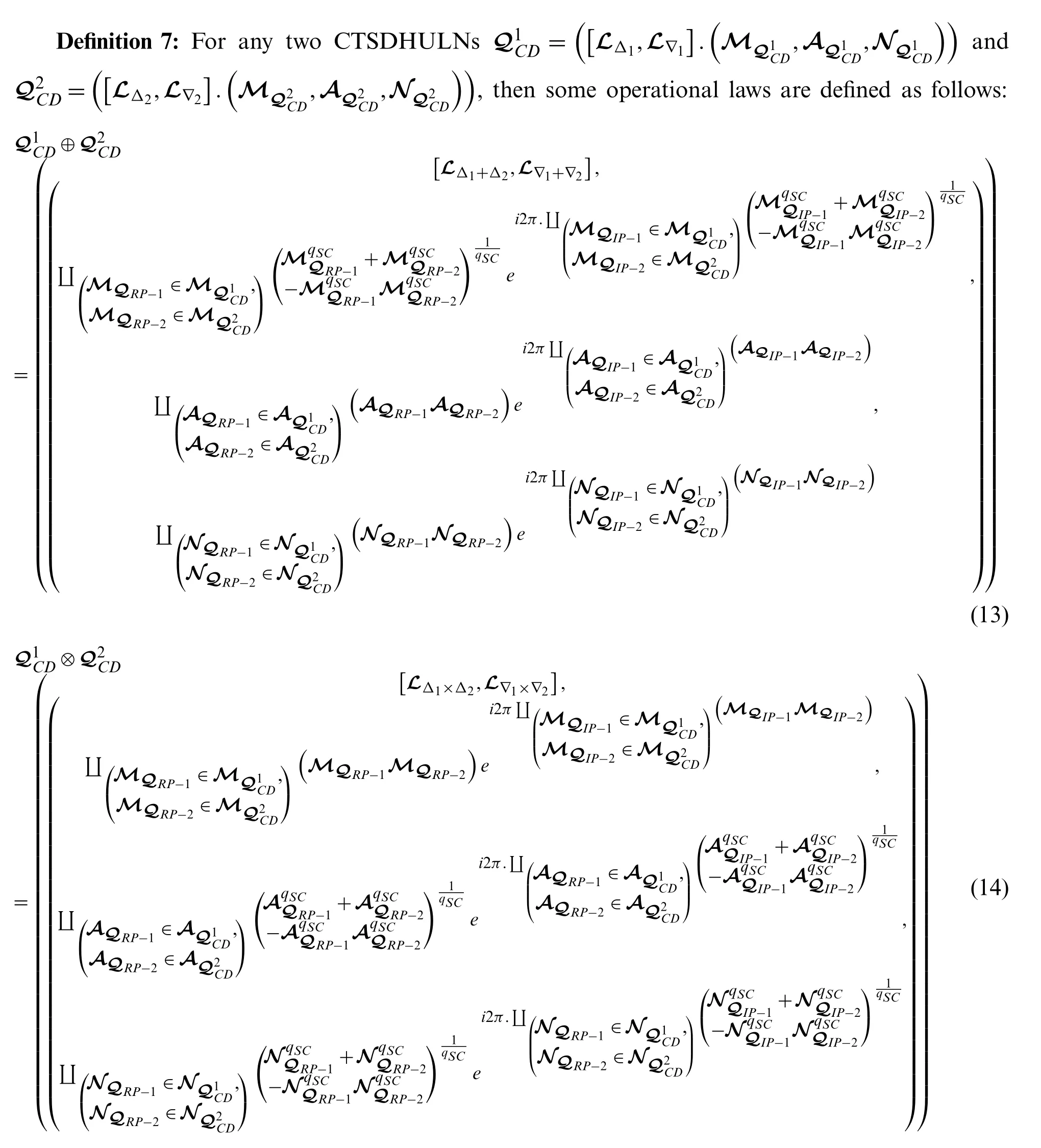

Additionally, we can examine the SF and AF of the CTSDHULN below:

For any two CTSDHULNs, we can examine their relationships with the help of the following laws:

4 Complex T-Spherical Dual Hesitant Uncertain Linguistic Aggregation Operators
In this study, we explore the CTSDHULMM operator, CTSDHULWMM operator, CQRODHULDMM operator, CQRODHULWDMM operator, and their cases.
Definition 8:For any family of CTSDHULNs=1,2,3,...,n), then the CTSDHULMM operator is initiated by:
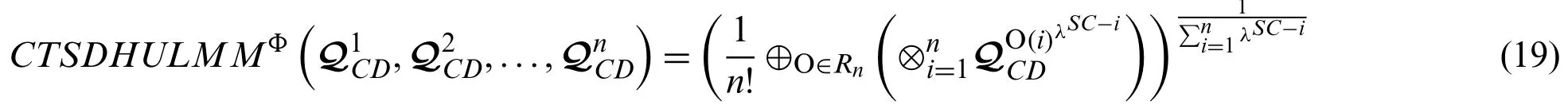
Theorem 1:For any family of CTSDHULNs=1,2,3,...,n), letλSC−n)∈Rnbe all possible permutations and O(i),i=1,2,3,...,nany one ofRn, then
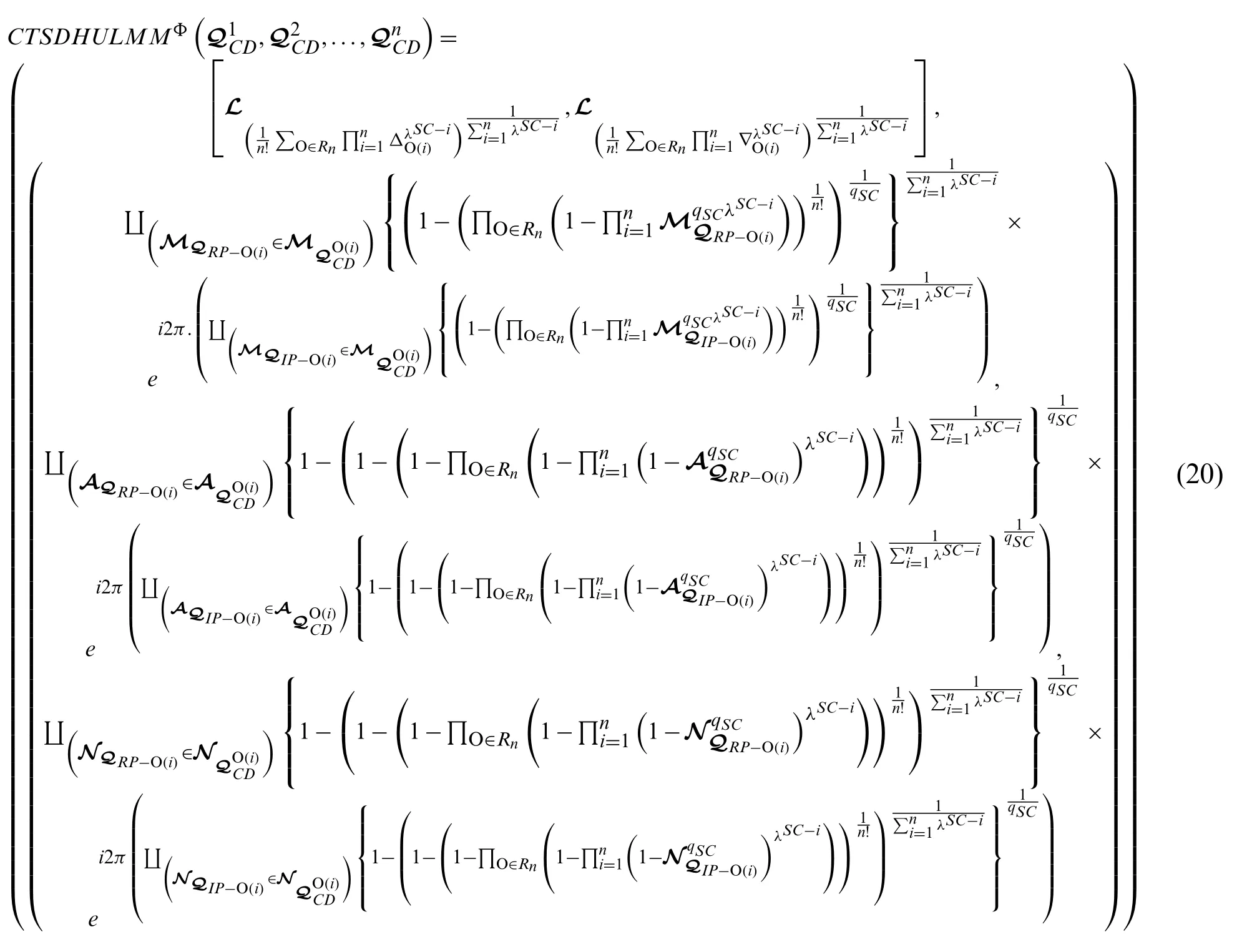
Additionally, it is easy to examine the idempotency, monotonicity, and boundedness of the explored ideas.


Moreover, by using Eq.(20), we discuss some particular cases of the explored approach,which are very beneficial for quality work.The special cases of the presented approach are discussed below:
(1)If we choose the value of the parameterΦ=(1,0,0,...,0), then Eq.(20)is converted into the complex T-spherical dual hesitant uncertain linguistic (CTSDHUL)averaging (CTSDHULA)operator, we have
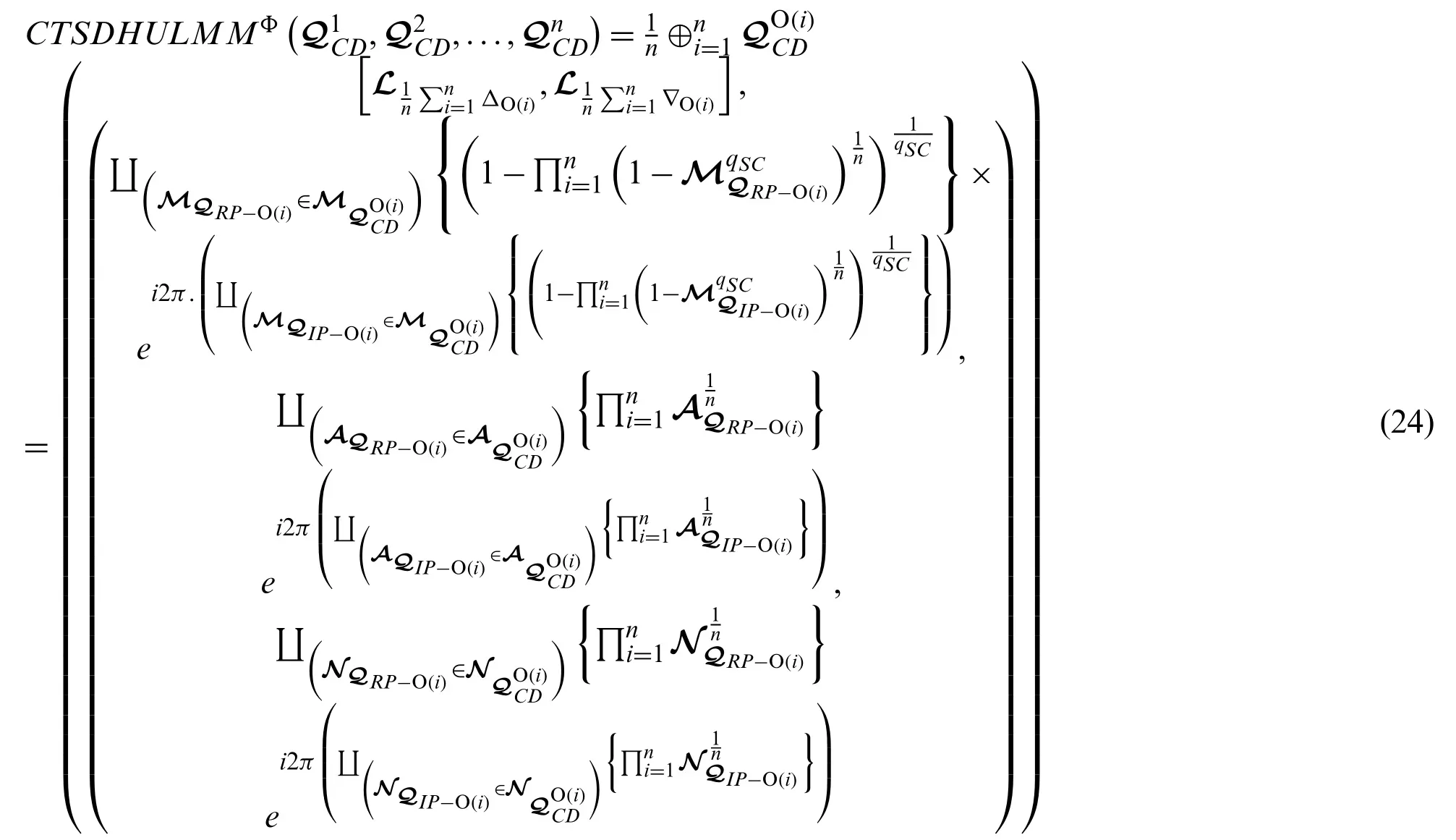
(2)If we choose the value of the parameterΦ=(1,1,0,0,...,0), then Eq.(20)is converted into the CTSDHUL Bonferroni mean (CTSDHULBM)operator:


(4)Let parameterΦ=(1,1,1,...,1), then Eq.(20)deduces to the CTSDHUL geometric mean(CTSDHULGM)operator:

By choosing the value ofqSC=1, then Eq.(20)is converted into the complex picture dual hesitant uncertain linguistic Muirhead mean operator.Similarly, letqSC= 2, then Eq.(20)is converted to the complex spherical dual hesitant uncertain linguistic Muirhead mean operator.Ifthen Eq.(20)is converted into Eq.(27).
Definition 9:For any family of CTSDHULNs=1,2,3,...,n), then the CTSDHULWMM operator is initiated by
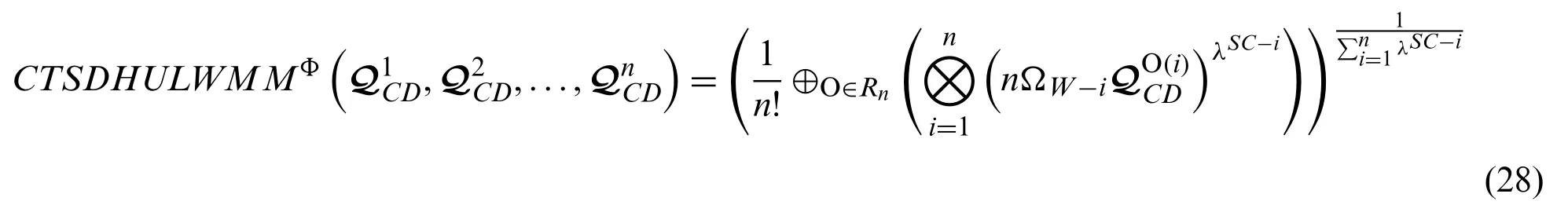

Definition 10:For any family of CTSDHULNs=1,2,3,...,n), then the CTSDHULDMM operator is initiated by

Theorem 3:For any family of CTSDHULNs=1,2,3,...,n), then

Additionally, by using Eq.(31), we can discuss some particular cases of the explored approach, which are very beneficial for quality work.
(1)If we choose the value of the parameterΦ=(1,1,0,0,....,0), then Eq.(31)is converted into the CTSDHUL geometric Bonferroni mean (CTSDHULGBM)operator:

By choosing the value ofqSC= 1, then Eq.(31)is deduced to the complex picture dual hesitant uncertain linguistic dual Muirhead mean operator.Similarly, ifqSC=2, then Eq.(31)is converted for the complex spherical dual hesitant uncertain linguistic dual Muirhead mean operator.IfΦ=then Eq.(31)is converted into Eq.(24).
Definition 11:For any family of CTSDHULNs=1,2,3,...,n), then the CTSDHULWDMM operator is initiated by
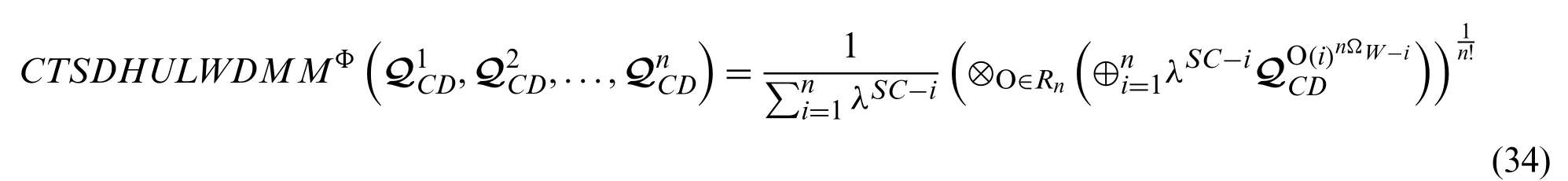
Theorem 4:For any family of CTSDHULNs=1,2,3,...,n), letΦ=λSC−n)∈Rnbe all possible permutations, then

By choosing the value ofqSC= 1, then Eq.(35)is deduced to the complex picture dual hesitant uncertain linguistic weighted dual Muirhead mean operator.Similarly, letqSC=2, then the Eq.(35)is converted to the complex spherical dual hesitant uncertain linguistic weighted dual Muirhead mean operator.
5 MADM Technique Based on CQRODHULNs

5.1 Proposed Method
In this section, we discussed the different cases of the proposed algorithm which are discussed below.
Step 1:Standardized the decision matrix in the form of CTSDHULNs by using the Eq.(36),such that
where the symbolsI1andI2represent the benefit and cost type criteria, respectively.
Step 2:Utilize the CTSDHULMM operator
or CTSDHULWMM operator
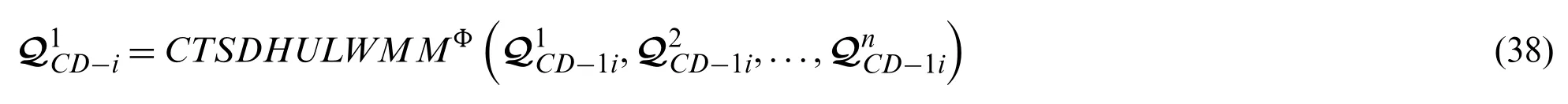
or CTSDHULDMM operator

or CTSDHULMM operator
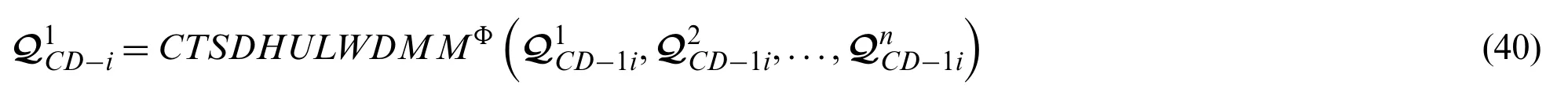
to calculate the whole evaluation of each alternative.
Step 3:Calculate the score values of the aggregated values of Step 2.
Step 4:Find the ranking values to examine the best alternative.
Step 5:The end.
5.2 Application in Enterprise Informatization Level Evaluation
Enterprise data development alludes to improving the creation and activity proficiency of ventures through the organization of PC technology, lessening operational dangers and expenses,accordingly improving the general management level and the capacity of ceaseless activity.The principle motivation behind endeavor informatization is to utilize progressed data innovation and modern executive strategies to improve and streamline the business cycle and the board level of the undertaking.In the furious homegrown and worldwide rivalry, numerous Chinese organizations are quickening the movement of informatization development.Before the development of data innovation, enterprises need to exhaustively assess the current degree of informatization from various angles.Fundamentally, the assessment of the big business informatization level is a MADM issue.A gathering needs to assess the data level of its four auxiliaries, which can be signified asX={X1,X2,X3,X4}.To make an exact assessment, the organization has welcomed various senior specialists in the field of big business data development to assess the four potential options.Considering the business conditions of the organization, the dynamic specialists assess the informatization level of the four auxiliaries from the accompanying four viewpoints, for exampleC1(endeavor scale level),C2(extent of speculation for informatization),C3(institutional norms development), andC4(consideration from pioneer).The weight vector of these qualities isΩW=(0.3,0.1,0.2,0.4)T, andL={L0,L1,L2,L3,L4,L5,L6} is an uncertain linguistic term set based on CTSDHULSsi,j=1,2,3,4.Thus, a CTSDHUL decision framework can be acquired, shown in Tab.1.

Table 1: Original decision matrix

Table 1(continued)C3 C4 X1■■[L1,L3].■ ■{0.2,0.3,0.5}ei2π{0.3,0.5},{0.02,0.03,0.05}ei2π{0.03,0.05},{0.2,0.3}ei2π{0.2,0.4}■ ■■ ■■■[L5,L7].■ ■{0.6,0.7}ei2π{0.5,0.6},{0.06,0.07}ei2π{0.05,0.06},{0.1,0.2}ei2π{0.3,0.4}■ ■■ ■X2■■[L2,L3].■ ■{0.1,0.5}ei2π{0.2,0.4,0.5},{0.01,0.05}ei2π{0.02,0.04,0.05},{0.1,0.5}ei2π{0.1,0.3}■ ■■ ■■■[L6,L7].■ ■{0.1,0.6}ei2π{0.5,0.6,0.7},{0.01,0.06}ei2π{0.05,0.06,0.07},{0.1,0.3}ei2π{0.1,0.2,0.3}■ ■■ ■X3■■[L2,L3].■ ■{0.1,0.3,0.4}ei2π{0.3,0.4},{0.01,0.03,0.04}ei2π{0.03,0.04},{0.1,0.4}ei2π{0.1,0.2,0.3}■ ■■ ■■■[L4,L7].■ ■{0.2,0.5}ei2π{0.3,0.5},{0.02,0.05}ei2π{0.03,0.05},{0.3,0.5}ei2π{0.1,0.2}■ ■■ ■X4■■[L2,L4].■ ■{0.2,0.4,0.6}ei2π{0.3,0.4},{0.02,0.04,0.06}ei2π{0.03,0.04},{0.1,0.3}ei2π{0.1,0.2,0.3}■ ■■ ■■■[L5,L6].■ ■{0.3,0.6}ei2π{0.2,0.6},{0.03,0.06}ei2π{0.02,0.06}{0.3,0.4}ei2π{0.1,0.3,0.4}■■■ ■
In the following, we utilize the proposed technique to assess the general exhibition of the four options.The detailed calculation steps are listed as follows:
Step 1:Given that all ascribes are a benefit, the first complex T-spherical dual hesitant uncertain linguistic should not be standardized.
Step 2:Utilize the CTSDHULWMM operator to total the trait esteems of each option.Without loss of over-simplification, letΦ=(1,1,1,1)andqSC=3.As the thorough assessment of each option is excessively intricate, we preclude them here to spare space in the form of Tab.2.

Table 2: Aggregated values of Tab.1
Step 3:Based on Eq.(17), we calculate the score values of the aggregated values of Step 2,such that
SSF(X1)=0.5161,SSF(X2)=0.3672,SSF(X3)=0.0606,SSF(X4)=0.1380.
Step 4:Find the ranking values to examine the best alternative.Hence, the ranking order is X1≻X2≻X4≻X3, and the optimal alternative is X1, which also illustrates thatX1has the highest informatization level.
Step 5:The end.
5.3 Validity of the Explored Approach
To find the proficiency and validity of the explored MADM model with CTSDHULNs,we choose the information which are in the form of complex spherical dual hesitant uncertain linguistic numbers and CTSDHULNs, as the complex picture dual hesitant uncertain linguistic information’s are already discussed in Example 1.The information is discussed in the form of Tab.3, and the steps of the algorithm are discussed below:
Step 1:Given that all ascribes are a benefit, the first complex T-spherical hesitant uncertain linguistic does not need to be standardized.

Table 3: Original decision matrix
Step 2:Utilize the CTSDHULWMM operator to total the trait esteems of each option.Subsequently, general assessment esteem is obtained for every option.Without loss of oversimplification, letΦ=(1,1,1,1)andqSC= 3.As the thorough assessment of each option is excessively intricate, we preclude them here to spare space in the form of Tab.4.

Table 4: Aggregated values of Tab.3
Step 3:Based on Eq.(17), we calculate the score values of the aggregated values of Step 2,such that
SSF(X1)=0.6118,SSF(X2)=0.5424,SSF(X3)=0.3069,SSF(X4)=0.3281.
Step 4:Find the ranking values to examine the best alternative.Hence, the ranking order isX1≻X2≻X4≻X3, and the optimal alternative isX1, which also illustrates thatX1has the highest informatization level.
Step 5:The end.
Additionally, next, we choose the CTSDHULNs in the form of Tab.5 and resolve it by using the explored operators.The steps of the algorithm are discussed below.
Step 1:Given that all ascribes are a benefit, the first complex T-spherical hesitant uncertain linguistic should not be standardized.
Step 2:Utilize the CTSDHULWMM operator to total trait esteems of every other option.Without loss of over-simplification, letΦ=(1,1,1,1)andqSC=6.The aggregation results are listed in Tab.6.
Step 3:Based on Eq.(17), we calculate the score values of the aggregated values of Step 2,such that
SSF(X1)=0.315,SSF(X2)=0.2816,SSF(X3)=0.07383,SSF(X4)=0.1434.
Step 4:Find the ranking values to examine the best alternative.Hence, the ranking order isX1≻X2≻X4≻X3, and the optimal alternative isX1, and thenX1has the highest informatization level.
Step 5:The end.

Table 5: Original decision matrix
5.4 Effortlessness of the Parameter
We explore the impact of the boundaries on the outcome in this section.To start with, we study the impact of the boundaryqSCon the scores and positioning requests.We use various estimations ofqSCin the CTSDHULWMM operator when totaling characteristic quality, the scores and corresponding ranking orders are listed in Tabs.7–9.Without loss of over-simplification, here we expectΦ=(1,1,1,1).

Table 7: Decision values by using different values of qSC for the information of Tab.1

Table 8: Decision values by using different values of qSC for the information of Tab.3

Table 9: Decision values by using different values of qSC for the information of Tab.5
The results in Tabs.7–9 show the same ranking order, i.e.,X1≻X2≻X4≻X3for different values of the parameterqSC.In the following, we further examine the impact of the boundary vectorΦon the outcomes.Moreover, we allocate a distinctive boundary vector toΦin the CTSDHULWMM operators and present the score esteemed in Tabs.10–12.

Table 10: Decision values by using different values of Φ for the information of Tab.1, qSC=3
5.5 Comparative Analysis
Additionally, to examine the reliability and validity of the presented approaches, we compare the explored works with some existing notions by using the evaluations of Tabs.1, 3, and 5.The information about existing works is discussed as follows: picture dual hesitant uncertain linguistic aggregation (PDHULA)operator, spherical dual hesitant uncertain linguistic aggregation (SDHULA)operator, T-spherical dual hesitant uncertain linguistic aggregation (TSDHULA)operator, complex picture dual hesitant uncertain linguistic aggregation (CPDHULA)operator,and complex spherical dual hesitant uncertain linguistic aggregation (CSDHULA)operator.The comparative analysis for Tabs.1, 3, and 5 are discussed in the form of Tabs.13–15.

Table 11: Decision values by using different values of Φ for the information of Tab.3, qSC=3

Table 12: Decision values by using different values of Φ for the information of Tab.5, qSC=6
From Tabs.13–15, it is clear that they provide the same results and the best alternative isX1.
5.6 Graphical Interpretations
Additionally, for more simplicity, we discuss the graphical representation of the explored approach and existing works to improve the quality of the presented works.For this, we choose the evaluation of Tabs.13–15, the geometrical interpretation of the presented works is discussed in the form of Figs.3–5.
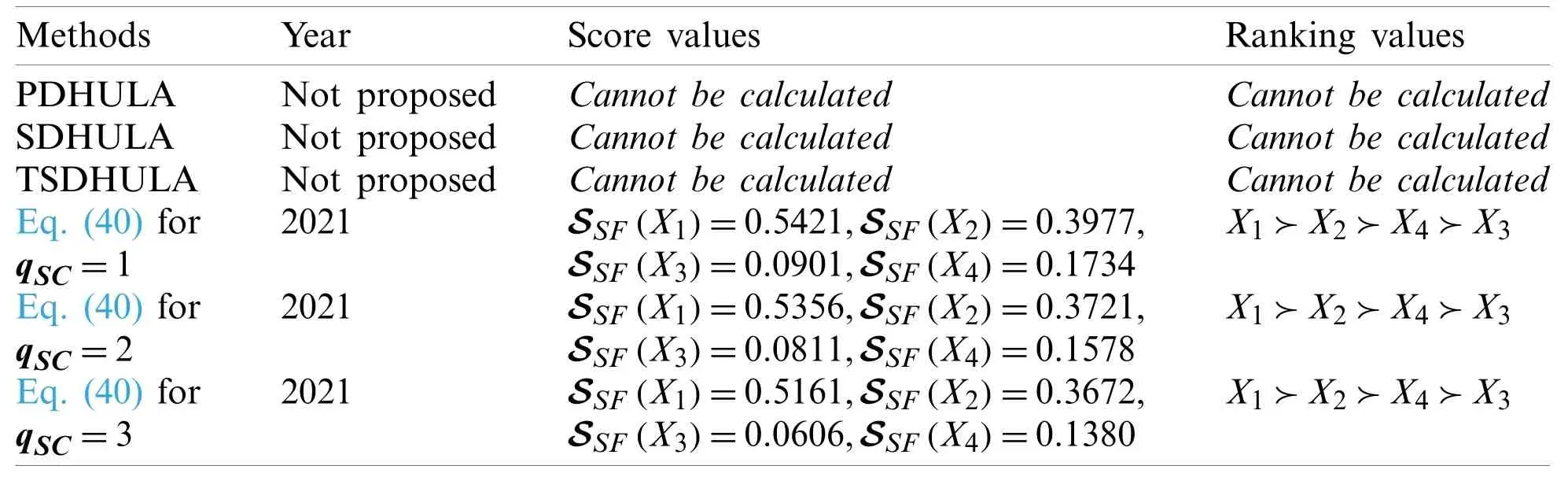
Table 13: Comparative analysis by using the information of Tab.1

Table 14: Comparative analysis by using the information of Tab.3

Table 15: Comparative analysis by using the information of Tab.5
Figs.3–5 contain four series which are expressed the family of alternatives and the graphical representations of the six different methods.For simplicity, we draw the geometrical interpretations for a reader to find the best alternative isX1.From the above analysis, we can get the result,when we choose the CPDHUL or CSDHUL to describe decision makers’preference, the explored operators are easily effective.But if we choose the explored kind of information, then the existing operators are not able to cope with it.Therefore, the presented idea is extensive, proficient, and more reliable than existing notions which are discussed in Tabs.13–15.

Figure 3: Geometrical representation by using the information’s of Tab.13
Figure 4: Geometrical representation by using the information’s of Tab.14

Figure 5: Geometrical representation by using the information’s of Tab.15
6 Conclusion
The theory of complex T-spherical fuzzy set was developed by Ali et al.[45,48] which contains the grade of truth, abstinence, and falsity in the form of complex numbers belonging to unit disc in complex plane.However, when a decision maker provides such types of information containing the triplet, whose real and imaginary parts are in the form of finite sunset of the unit interval with uncertain linguistic terms, then the existing theories cannot cope with it.For dealing with the sorts of issues, the main contribution of this manuscript is summarized in the following ways:
(1)To explore the idea of complex T-spherical dual hesitant uncertain linguistic set and their fundamental laws.
(2)To explore the CTSDHULMM operator, CTSDHULWMM operator, CTSDHULDMM operator, and CTSDHULWDMM operator are discovered in detail.
(3)A MADM technique with CTSDHULNs information is then utilized based on explored operators.The enterprise informatization level evaluation issue is provided to verify the proficiency and capability of the discovered approaches.
(4)Finally, through the comparative analysis and graphical elaboration with the existing methods, it is verified that the proposed work is extensive, flexible and can effectively overcome the current drawback.
In our future work, we will extend these approaches to complex neutrosophic sets, complex neutrosophic hesitant fuzzy sets, T-spherical hesitant fuzzy sets, and other areas [49–52].
Funding Statement:This work is supported by the the Social Sciences Planning Projects of Zhejiang (21QNYC11ZD), Major Humanities and Social Sciences Research Projects in Zhejiang Universities (2018QN058), Statistical Scientific Key Research Project of China (2021LZ33), Fundamental Research Funds for the Provincial Universities of Zhejiang (SJWZ2020002), Longyuan Construction Financial Research Project of Ningbo University (LYYB2002)and the First Class Discipline of Zhejiang-A (Zhejiang Gongshang University Statistics).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2021年11期
Computer Modeling In Engineering&Sciences2021年11期
- Computer Modeling In Engineering&Sciences的其它文章
- A Simplified Approach of Open Boundary Conditions for the Smoothed Particle Hydrodynamics Method
- Multi-Objective High-Fidelity Optimization Using NSGA-III and MO-RPSOLC
- Traffic Flow Statistics Method Based on Deep Learning and Multi-Feature Fusion
- A 3-Node Co-Rotational Triangular Finite Element for Non-Smooth,Folded and Multi-Shell Laminated Composite Structures
- Modelling of Contact Damage in Brittle Materials Based on Peridynamics
- Combinatorial Method with Static Analysis for Source Code Security in Web Applications