
基于改进编码/解码模型的中英机器翻译方法∗
2021-06-29 08:42董斌
计算机与数字工程 2021年6期
董 斌
(西北工业大学明德学院 西安 710124)
1 引言
随着我国对外开放程度的不断提高,英语已经成为对外交流场合的主要语言。传统人工翻译成本高昂,且受环境限制严重。近年来,借助于计算机的中英语言机器自动翻译成为了一个重要研究方向[1~3]。
基于规则翻译和基于例子翻译是早期机器翻译主要采用的方法,但翻译的准确性和自适应性均难以满足实际翻译需要[4]。随着机器学习技术的产生与发展,研究人员提出了基于机器学习的机器翻译模型[5]。文献[6]构建一种基于神经网络的机器翻译模型,该模型采用的端到端框架成为了后续机器翻译研究的基本结构。该框架的基本思路是采用机器学习方法搭建一个能够连接源语言序列和目标语言序列的编码/解码结构,实现两种语言之间的映射。基于编码/解码框架,支持向量机、卷积神经网络、循环神经网络等各种机器学习智能技术被用于构建机器翻译模型[7~8]。
本文基于编码-解码框架,构建了一种新的用于中英翻译的机器翻译模型。该模型采用长短时记忆循环神经网络(RNN)生成词向量,在编码阶段和解码阶段分别加入组嵌入技术和权值衰减方法,在提高机器翻译模型准确性的同事,降低了模型达到收敛的迭代次数,仿真实验结果验证了所提方法的有效性。
2 机器翻译模型
为了能够使机器自动地捕获语言特征,实现基于计算机的自然语言高效映射,首先需要建立一个能够连接两种自然语言的机器翻译模型。编码/解码结构是一种十分广泛的机器翻译模型,结构如图1所示。编码器部分接收带翻译语言的输入,输出编码序列,解码器接收编码序列,输出翻译结果。
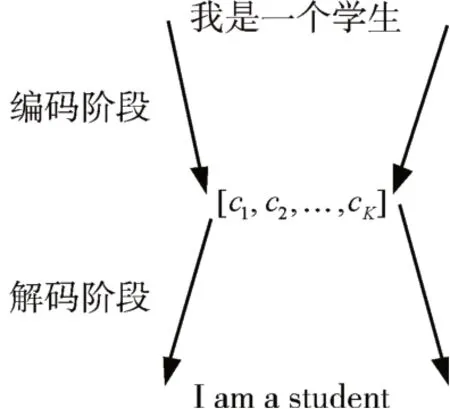
图1 编解码器结构
如图1所示,编解码器的输入是一个任意长度的源语言序列,然后利用编码器将其捕获到能够表征其句子的特征序列,最后利用解码器实现特征到语言序列的转换。因此,编码阶段是将输入源自然语言映射为一个码向量,而解码阶段是编码阶段的逆过程,将码向量映射为目标语言序列,编解码映射的理论基础是最大化预测序列概率准则。
令A={a1,a2,…,an}表示源语言的输入序列,B={b1,b2,…,bm}表示目标语言的输出序列,则目标语言编解码器生成的概率可以表示为
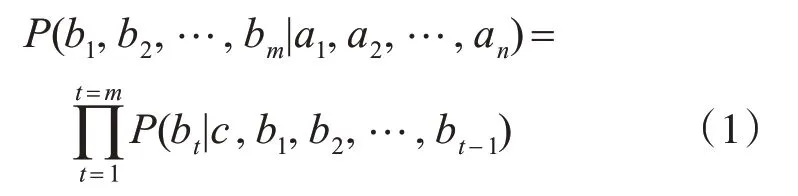
式中,c为编码器输出的编码向量,该向量能够有效表征源语言序列的特征。式(1)等号右边表示各个目标语言词汇的生成概率,计算方法为
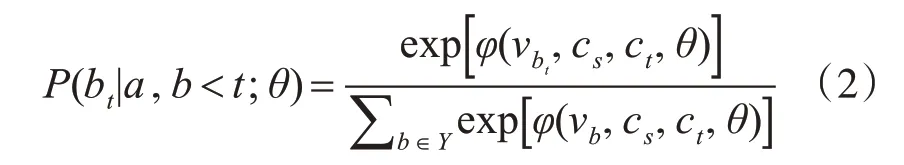
式中,φ(·)表示基于当前目标语言序列和源语言序列生成当前词向量的概率,vb为解码器输出的目标语言词向量,cs为编码器输入源语言的上下文向量,ct为解码器输出目标语言的上下文向量。综合式(1)和式(2)可知,编解码器的机器翻译就是不断利用输入源语言的和输出目标语言来对当前的词向量进行预测,最终输出预测概率最大的目标语言词向量组合。
编解码器是机器翻译的基本结构,具体实现机器翻译还需要对编解码器结构进行具体设计。文中基于编解码器机器翻译设计原则,结合当前中英机器翻译的实际需要,对机器翻译结构进行了具体设计,主要包括词向量生成、基于组嵌入的编码器和基于权值衰减的解码器。
3 词向量生成算法
基于符号的自然语言数字化表示是机器能够理解并处理自然语言的基础。自然语言符号化过程就是将自然语言自动地转化为词向量的过程,进而利用计算机的强大计算能力提取自然语言特征[9~10]。常见的词向量生成算法如One-Hot编码方法和分布式表示方法需要对自然语言词数据进行标注,不适用于当前大规模自然语言机器翻译的场合,文中采用一种基于RNN的自然语言词向量生成方法。
RNN词向量生成结构包括输入层、隐藏层和输出层,隐藏层随时间的迭代计算方式为
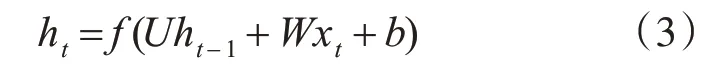
其中,xt表示t时刻输入向量,f(·)表示神经网络激活函数,U和W均为神经网络的权值矩阵,b为网络偏置向量。
传统的循环神经网络训练方法是误差反向传播算法(BP算法),但是在自然语言词向量生成过程中,面对源语言序列的长距离依赖问题,BP算法可能会出现梯度衰减或者梯度爆炸的情况,即使采用了梯度裁剪后也难以彻底解决问题。为了更好地解决源语言长距离依赖的梯度爆炸问题,本文采用长短时记忆(LSTM)神经网络。
LSTM网络的基本原理是在经过预训练的RNN上,增加LSTM记忆单元形成新的网络[11~12]。LSTM记忆单元网络结构如图2所示,共包含四个门:输入门、遗忘门、记忆细胞和输出门,各部分功能介绍如下。输入门和输出门可以有效解决RNN网络权值更新的冲突,基本属性为控制门,其中输入门负责记忆细胞的数据传入。记忆细胞能够存储网络中的内容,是LSTM的存储单元。遗忘门的作用是控制记忆细胞的状态。输出门综合当前的输入数据和记忆细胞数据给出LSTM网络的输出结果。LSTM单元的各个门均需要设置激活函数,文中输入门、遗忘门和输出门均采用Sigmoid激活函数,而记忆细胞采用Tanh激活函数。
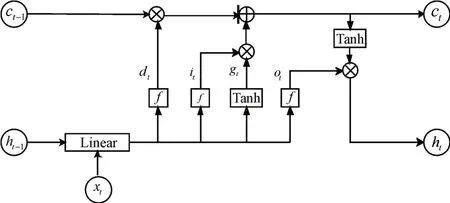
图2 LSTM单元结构
图2中LSTM单元中各个门的计算公式为
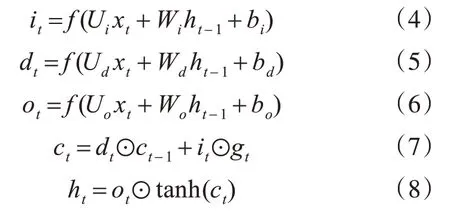
式中,⊙表示矩阵或向量的点乘运算。
LSTM计算过程表明,如果遗忘门接近于1并且输入门接近于0,此时前一时刻数据就会一直被存储在记忆细胞中,实现了源语言序列长距离依赖关系的捕获,旧状态数据能够参与到当前时刻输出门的计算中。这说明,通过遗忘门和记忆细胞能够有效融合当前输入信息和前一时刻输入信息,这样能够有效避免采用BP算法训练RNN网络的梯度衰减问题,提升机器翻译性能。
4 组嵌入编码器
传统机器翻译编码器模型的输入是经过词向量生成算法生成的词向量,只含有训练语料之内的信息,缺乏情感信息和上下文信息不能描述表征源语言序列特点。为此,本节构建了一种基于组嵌入的机器翻译编码器模型。
组嵌入的基本思想是将源语言序列中的每个词按照一种或多种方式进行分组划分,使得源语言序列中每个词对应一个或者多个分组。对于中英机器翻译模型,中英文最小单元集合可以定义为
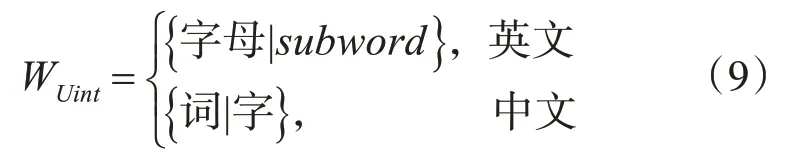
其中,subword表示在英文单词中具有单独含义的一部分,例如superman中的super。如果按照一种分组方式对源语言序列中的词进行分组,序列中所有词经过划分后将生成一个组集GUint={组 别};如果分组的方式为多种,源语言序列中的词将生成多个组。
假设输入的源语言序列S生成的词向量集合为
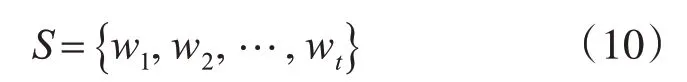
其中wi∈WUint表示经过词向量生成的词序列。假设分组划分方式为φ,则分组后的组集为
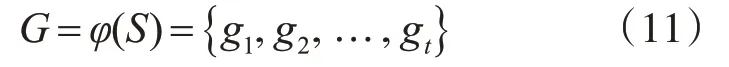
其中gi∈GUint表示经过划分后的组别。例如对于源语言序列“I am a student”,w1=I,w2=am,w3=a,w4=student,如果采用的分组方式是单词词性,则分组后为g1=pron,g2=vi,g3=art,g4=n。在中英文机器翻译组嵌入过程中,常用的划分规则包括词性、上下文语义、褒贬程度、大小写等。
源语言序列经过分组划分后,需要进行嵌入处理,具体的嵌入方式就是利用one-hot方法将分组后的词向量转化为多维连续向量。假设WUint经过one-hot嵌入生成的结果可以表示为
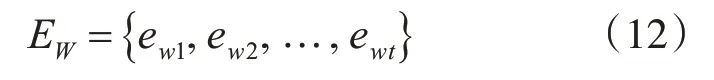
其中eWi表示嵌入后的m维向量。同理,GUint经过one-hot嵌入生成的结果可以表示为
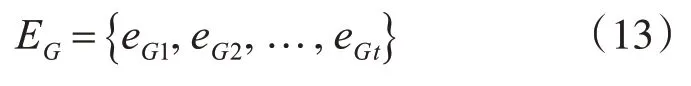
其中eGi表示嵌入后的n维向量,这个过程称为组嵌入。
相比传统嵌入模型,源语言序列经过组嵌入后,能够将多维词语属性和原始词向量一起作为编码器的输入,丰富了源语言序列输入特征,能够提高机器翻译的准确性。
5 权值衰减解码器
机器翻译过程中,源语言序列中词语对应的目标语言序列词语经常会受到前文翻译结果的影响,并且这种影响还会随着距离的长短的变化而变化。然而,传统机器翻译模型没有充分考虑大前后文词语含义的影响,容易出现前后文翻译不一致的情况,且影响机器翻译准确性。针对这个问题,本节设计了一种基于权值衰减的解码器模型。
权值衰减解码的基本思路是在机器翻译解码的过程中,给先出现的词赋予较高权值,而后出现的词赋予较低权值。这与实际翻译的过程是相符的,这是由于先出现的词会影响后续词语的翻译,而最后出现的词对整个翻译过程的影响最小,因此权值最小。
机器翻译是一种未知条件下的自动翻译,因此机器无法获取源语言序列的真实长度[13]。为此对每一句带翻译语句均首先采用最大句子长度,待检测到句尾结束符再清除空字符。整个待处理源语言序列的损失函数定义为

其中t表示待翻译语言序列的实际长度。加权后的损失函数可以表示为
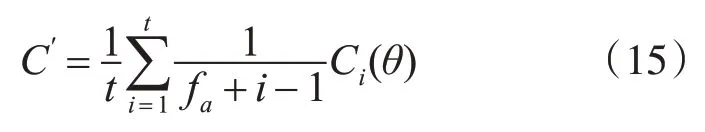
式中fa为权值衰减影响因子。经过式(15)的加权后,越是靠后的词语对整个翻译的影响就越小,实现了解码器损失函数的权值衰减,增强了机器翻译的准确性。
6 实验结果与分析
为了验证本文构建的中英机器翻译模型的性能,本节采用实验数据对其进行性能测试,并与常用机器翻译模型进行对比分析。测试数据集选取国际口语机器翻译大赛中的中英机器翻译数据,测试环境为英伟达公司的GTX1660显卡,处理器为Intel i7-9700,内存8G,操作系统为Windows7。为了达到快速检验机器翻译模型性能,实验中仅处理数据集中长度小于12的句子,且RNN模型训练的batch设置为40。
为了能够在机器翻译模型测试过程中及时有效地评价翻译性能,需要采用翻译性能自动评价指标。综合考虑已有机器翻译性能评价方法,文中选取应用较为广泛的BLEU评价方法[14~15]。BLEU评价是一种对翻译质量自动评估的方法,具体计算方式为
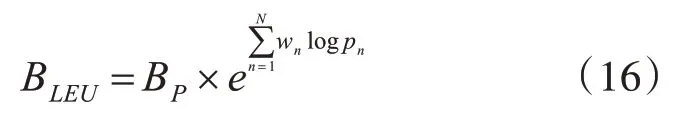
其中,BP表示一个与句子长度相关的衰减系数,wn表示翻译过程中n元词的权值,pn表示翻译模型对n元词翻译的准确率。
首先对加入权值衰减的解码器性能进行实验分析,表1为不同权值衰减影响因子对机器翻译模型BLEU指标的影响。
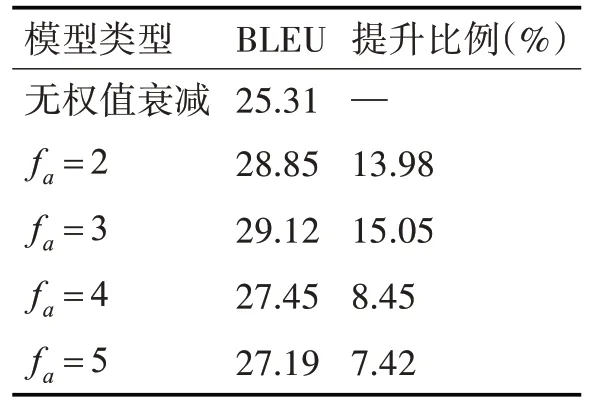
表1 不同权值衰减因子性能测试
实验结果表明,在解码器中加入权值衰减后,能够有效提升机器翻译模型的翻译性能,相比无权值衰减的模型,BLEU指标提升十分明显。这是因为通过在解码器中加入权值衰减因子,能够对源语言序列中的各个词赋予不同权重,使得越靠前翻译的词权值越高,这样能够极大地提升后续语句翻译的准确性。由表1可知,权值因子的大小对机器翻译性能具有一定影响,随着权值衰减因子的增大,解码器损失函数将会近似于各个词语的权值均相等,逐渐失去权值衰减的作用;当权值衰减因子设置过小时,机器翻译模型对排序靠前词语的权值过大,也会导致当前词语翻译不准确,影响模型翻译性能。为此,针对具体的翻译数据集,需要经过实验选取合适的权值衰减因子。
词嵌入能够有效提升机器翻译模型的准确性,且能够提高模型训练效率,表2为机器翻译模型有无组嵌入时模型的收敛速度和翻译BLEU实验结果,组嵌入为单一分组,分组方式为按照词性。实验结果表明,加入组嵌入后,不但能够有效提升机器翻译模型的训练效率,用更少的迭代次数使模型达到收敛状态,还能进一步提升翻译准确性。
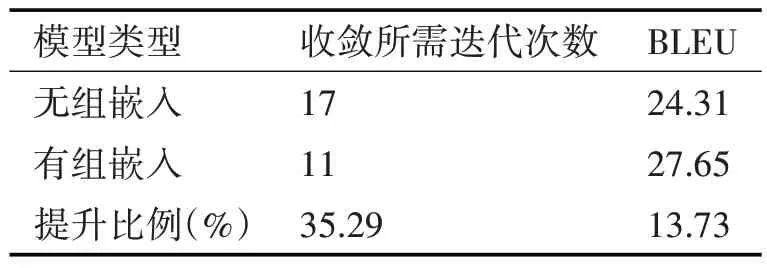
表2 组嵌入性能测试
为了进一步测试本文构建的机器翻译模型性能,采用准确率、召回率和F1对模型翻译性能进行测试,实验中权值衰减因子设置为2,组嵌入方式分别选择词性、上下文语义、褒贬程度,多分组综合三种分组方式,实验结果如表3所示。表3测试结果表明,组嵌入能够有效提升机器翻译模型翻译性能,各个角度的单一分组方式均对模型收敛速度和翻译准确性具有很大提高,并且综合多种分组方式能够进一步提高模型翻译性能。

表3 综合测试结果
7 结语
随着机器学习等人工智能技术的不断发展,机器翻译性能取得了显著提升。本文研究了基于编码解码模型的中英文机器翻译问题,提出了一种改进的机器翻译方法。该方法在编码阶段通过组嵌入提高模型收敛速度,在解码阶段通过权值衰减提高翻译准确性,实现结果验证了改进方法具有优良的收敛速度和翻译准确性。
猜你喜欢
睿士(2020年6期)2020-08-18
南方周末(2019-12-19)2019-12-19
现代信息科技(2019年18期)2019-09-10
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
科技创新与应用(2017年26期)2017-09-12
中国信息技术教育(2016年13期)2016-09-10
科技视界(2016年1期)2016-03-30
电脑爱好者(2015年24期)2015-09-10
物联网技术(2015年7期)2015-07-21
