
基于对抗机制的RGBD语义分割半监督方法研究∗
2021-06-29 08:42尹四清崔建功梁昊然
计算机与数字工程 2021年6期
程 鑫 尹四清,2 崔建功 梁昊然
(1.中北大学软件学院 太原 030051)(2.山西省军民融合软件工程技术研究中心 太原 030051)
(3.中北大学动态测试省部共建实验室 太原 030051)
1 引言
图像语义分割是将图像中每个像素按照语义信息划分类别的技术,是计算机视觉中重要的课题之一。在无人驾驶,室内导航,增强现实等领域具有广泛的应用场景。在室内场景图像语义分割领域中,由于室内场景中颜色和纹理特征差别较小、光照较差、遮挡严重、存在着交错复杂的物体等具有挑战性的问题。因此,RGB-D语义分割得到研究者们的广泛关注。
在最近几年,基于超像素分割的RGB-D图像语义分割一直是关注的焦点[1~2],然而这种方法使用的是手工制作的特征输入到分类器中来标记每个区域。此方法步骤繁多,在计算和时间上都是密集的。基于上述的局限性以及深度学习的成功引入。尤其是基于FuseNet[3]的室内场景语义分割方法,在网络的编码器分支中,对深度通道的中间特征图与RGB通道的中间特征图进行元素求和。在编码器-解码器中使用不同策略的融合方式,例如早期融合[4],后期融合[5],将RGB图和深度几何信息图进行融合后作为输入。深度网络模型有助于提取低、中、高级特征。这些方法通常使用的是监督机制,需要大量的标注数据,才能正确分割。
在最近的五年中,生成式对抗网络在图像合成和图像分割的方面效果显著。随着技术的不断更新,已经有研究者提出了使用对抗网络的半监督学习方法来提高图像语义分割的分割精度[6~7]。然而就我们统计所知,以前没有任何研究使用生成式对抗网络和半监督学习机制来研究室内场景语义分割。
在这项研究中,我们提出了一种基于生成式对抗网络的半监督语义分割方法,该方法使用一定数量的标签数据和一定数量的无标签数据。我们还提出了新的损失函数,是基于距离变换和逐像素交叉熵的损失项[8],来改善有监督阶段的分割结果。该损失函数用于对抗式生成网络的预训练分割网络中,在训练过程中分割网络充当生成网络,鉴别网络通过生成置信图来帮助分割网络产生更好的分割效果。并且我们采用稀疏融合的思想,在分割网络中融入深度几何信息分支,来降低类感染。
2 相关工作
2.1 基于生成式对抗网络的图像语义分割
将生成对抗网络首次应用在图像语义分割是在2016年[9],训练一个卷积神经网络进行图像分割,在网络里充当生成器,鉴别器来判断分割结果是来自生成器还是来自真实的标签,并证明了这种对抗性方法可以减少训练中的过度适应。在2018年,W.C.Hung等[10]研究出一个新的鉴别器,利用图像的分辨率判断图像的真假性,为了减少训练时需要的标签数据量,引入了半监督机制;文献[11]提出了一种基于GAN的半监督学习模型,他们的创新点在于生成了额外的训练数据和一个鉴别器,鉴别器在类成员之间和生成器图像中进行图像分类,此方法生成的图像仍然建立在像素强度上。文献[12]中提到像素强度并不总是与对象结构的特性相关联。综上所述,基于生成式对抗网络的半监督方法研究已经逐步拓展。
2.2 RGB-D稀疏融合方法
由Caner Hazirbas等[3]提出了两种融合策略,稀疏融合策略和密集融合策略。通过研究者的实验证明提出的两个融合策略均优于当时已有的大多数方法,由于本文采用DeepLabv3网络作为分割网络,其网络属于深度网络结构,为了提高运算速度和减少数据量,所以本文引用稀疏融合的方法策略。
在FuseNet网络中,称卷积层(Convolutional layer,Conv)和激活函数(ReLu),批标准化规则(Batch Normalization,BN)的组合为CBR块。并在CBR块与池化层(Pooling)之间插入融合层(Fu⁃sion)称之为稀疏融合。如图1所示。通过融合,将深度几何特征图不连续的加入RGB的分支中,以增强RGB特征图。经过研究者们的证明,颜色域和几何域中的特征是互补的,可有效地通过其结构来区分无纹理区域,通过其颜色区分无结构区域。
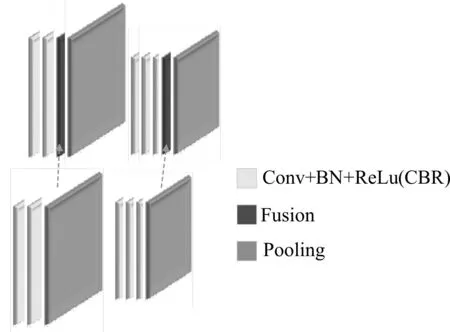
图1 稀疏融合框架图
3 结合稀疏融合的半监督分割鉴别网络框架
3.1 算法概述
在本文室内场景分割算法中包括语义分割器网络和鉴别器网络,其中分割器是基于DeepLabv3网络的两个分支网络,分别输入RGB图像和深度几何信息,随着卷积层不断提取特征,将提取的几何特征信息融入到RGB特征中,最后结合使用不同学习率的多尺度空洞卷积来扩大感受野;鉴别器是基于全卷积网络,相比传统GAN网络,本文的鉴别器输入图片尺寸不受限制。
首先向两个分支的分割网络分别输入一组尺寸为H×W×3的RGB图和深度几何图,鉴别网络接收从分割网络或真值标签获得类别概率图作为输入,输出概率图的尺寸大小为H×W×1。在训练期间,带标签和无标签的数据都在半监督设置下使用,具有不同的损失函数。当使用带标签的数据时,训练由带有真值标签的距离图损失项和对抗性损失来监督;对于未标记的数据,从分割网络中得到分割预测后,通过分割预测来计算置信图,该置信图用作一个监督信号来训练具有掩膜交叉损失。其中置信度表示分割的质量,所以置信图有助于训练期间可信区域的位置。
3.2 网络结构
本文所述网络总结构图如图2所示,在训练过程中使用三个损失函数对分割网络进行优化:距离图损失惩罚项Lpm(距离图是从真值和预测图之间的距离,并从ground truth mask中得到),对抗损失Ladv来愚弄鉴别器;半监督损失Lsemi是基于鉴别器网络输出的置信图的损失。其中利用鉴别器损失LD训练鉴别器网络。分割网络与鉴别网络每层参数如表1和表2所示。

表1 分割网络每层参数

表2 鉴别网络每层参数

图2 基于GAN的总体结构
3.3 几何信息的融合
传统的室内场景中通过目标的颜色和纹理特性来识别,从分割效果上来看,相同纹理或相同颜色的目标出现边界感染,文献[13]中,研究者通过多次实验观察到,深度图像中存在着对象大量的几何信息,利用这些几何信息对具有相似纹理,颜色,特征,位置进行语义分割精度有了很大的提高。
结合上面问题,本文中受到稀疏融合思想的启发,在分割网络中,将给出两个分支,同时提取RGB图片特征和几何信息特征,并分别在四个残差块的最后一个CBL块(卷积层(Conv)、批处理规范化(BN)、带泄露修正线性单元(Leaky-ReLU))后插入深度信息的浅层特征,给出block1中结构,如图3所示。其余三个残差块与此结构相同。将在空间金字塔池化ASPP(Atrous Spatial Pyramid Pooling)后加入CBL块,块后也同样融入深度信息特征到RGB通道。以这种方式将深度图像上得到的特征映射不连续的加入到RGB分支中,来增强RGB的特征映射。由于颜色特征会被深度特征覆盖,所以加入BN层来减少内部变量的移位来解决这个问题。将其融合后,在基础网络的最后一层加入dropout层来进一步提高性能。最后,我们利用上采样层和softmax函数来匹配输入图像的大小。
本文中使用的鉴别器网络是受到全卷积网络和文献[14]中鉴别器的结构启示。由5个卷积层组成,其中kernel size=4,filter=(64,128,256,512,1)。stride1,2,3,4=2,stride5=1(stride表示第i层卷积层的步数,i=1,2,3,4,5)。并在每层后应用Leaky-ReLu激活函数。最后增加一层上采样层,将图像恢复原尺寸大小。
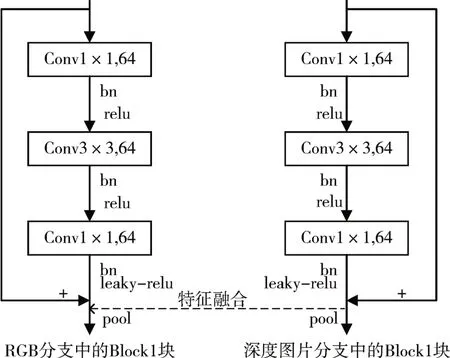
图3 残差块1中稀疏融合结构图
3.4 改进后的损失函数
输入给定大小的图像Xn:H×W×3,Yn为真值标签图。分割网络表示为S(•),图像Xn经过分割网络后的输出表示为S(Xn):H×W×C,这里C为类别数,由于本文中室内场景分为14类,所以在这里C取值为14。鉴别器网络表示为D(•),它输入尺寸为H×W×14的分类概率图,输出尺寸为H×W×1的可信度区域图。
3.4.1 鉴别器网络
在训练鉴别器网络时,只使用带有标记的数据。鉴别器网络输出两个结果,判断是否来自于真值。鉴别网络损失定义如下:

式(1)中:D(Xn)(h,w)表示输出Xn在位置(h,w)处的可信度区域图;D(Yn)(h,w)表示输出Yn在位置(h,w)处的可信度区域图;当p=0时,说明结果来自于分割网络输出的预测图像;当p=1时,说明结果来自于热编码后的真值标签图。
3.4.2 分割器网络
在训练分割器网络时,采用多项损失和约束分割网络,并使其最小化进行调优。分割网络损失函数如下:
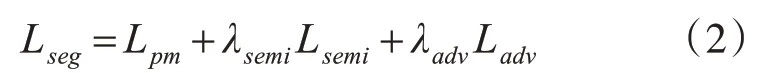
式(2)中:Lpm为距离图损失惩罚项;Lsemi为基于鉴别器网络输出的置信图的损失;Ladv为对抗损失;超参数λadv和λsemi是为了调优分割网络交叉熵的重要因子。由于对抗性损失为了接近地面真值而过度校正预测值,交叉熵损失逐步减小,会选择一个比标记数据的λadv小的数值,对于我们所提出的方法中的超参数。λadv设置为0.01,λsemi设置为0.1。
距离图损失惩罚项(Distance map loss penalty term),引入此损失项是为了提高RGB图像中对象的分割边界的精度。利用基于真值距离变换的损失函数来惩罚过度分割和稍欠分割。距离变换允许插值每个像素之间的2D距离到地面真值分割。其定义为

式(3)中:Lpm为距离图损失惩罚项,表示预测标签和真值标签之间的像素交叉熵;N=H×W;y表示真值,y表示预测标签;y在坐标位置为(h,w)处的像素值为y(h,w);y在坐标位置为(h,w)处的像素值为y(h,w)。C表示类别数目;⊙ 表示哈达玛积;ϕ表示距离图惩罚项。为了计算ϕ,首先计算真值的倒数的距离变换,然后将其反转促使像素更接近边界,变量γ控制与分类对象边界的拟合。在这项研究中,将γ设置为20。然后计算距离变换的真值,得到分类对象的距离图。
通过鉴别网络与分割网络来进行对抗学习,则得到对抗损失,其定义为
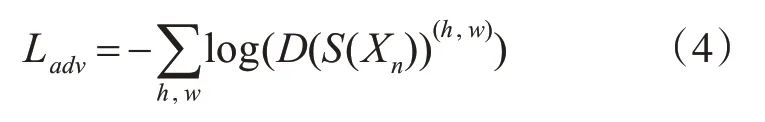
式(4)中:D(S(Xn))(h,w)表示由分割网络输出结果S(Xn)在位置(h,w)处的可信度区域图。对抗性损失用于训练分割网络,使分割预测结果更加接近真值,来欺骗鉴别器。
使用未标记的数据训练时,半监督环境下进行对抗性训练,由于此时没有标签数据,则不使用Lpm,但是对抗性损失仍然适用,因为它只需要鉴别器D(•)。应该注意的是,鉴别器网络已经被训练过了,此时可以产生置信图D(S(Xn)),用来描述与真值分布足够接近的区域。其定义为
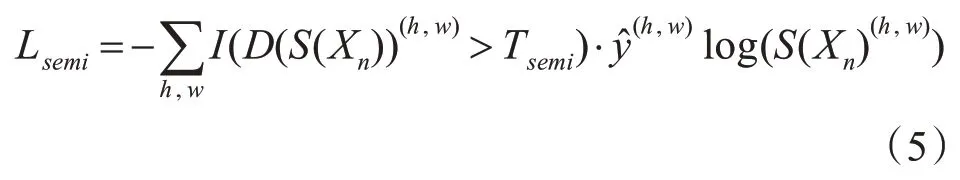
式(5)中:Tsemi是置信图上的阈值,以突出可信区域;当D(S(Xn))(h,w)>Tsemi时,I(x)=1,否者I(x)=0。在本文中将Tsemi设置为0.2,低于此阈值时,产生的可信度区域小,无法在半监督的环境下正确改进分割。
4 实验与结果
4.1 数据集
NYU-DepthV2室内场景RGB-D数据集[15],该数据集包含646个不同场景和26种不同场景类型的图。其中包含有1449个RGB和深度图像,这些图像被分成795个训练图像和654个测试图像,分辨率为640×480。Gupta S等[16]将这4个类标签(ground,permanent structures,furniture,props)映射到40个类标签。本文中是将4分类标签映射到14个结构化类标签进行实验。语义类别为Bed,Books,Ceiling,Chair,Floor,Furniture,Objects,Pic⁃ture,Sofa,Table,Tv,Wall,Window,uknw。
4.2 实验环境
实验方法是采用Pytorch框架实现的,采用的Pytorch的版本为0.4.1,CUDA9.0,GTX1080ti。选用的优化分割网络参数的方法为mini-batch梯度下降算法,输入图像的批次batch_size设为2,设置学习率为0.0007,由于过拟合现象,我们选用权重衰减率设为0.0005。选用优化鉴别网络的方法是使用Adam优化器,设置学习率为0.001。最大迭代次数为20K。
4.3 评估指标
像素精度也称为全局精度,是真实分类预测概率。定义为

平均像素精度表示每个类别的精准度平均值,也称为标准化混淆矩阵的平均值。定义为
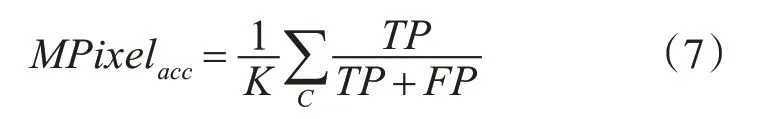
对于没有“void”或“background”标签或者少量像素属于这些类的数据集,这还是一个不错的评价标准。
联合交并比是预测值和真值的交集在他们的并集上的平均值,定义为
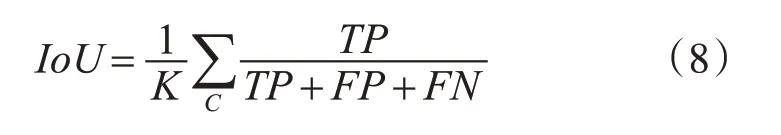
4.4 超参数的选取
在本文中有三项超参数,其中是λadv和λsemi用于对多项任务学习的平衡,Tsemi用于衡量半监督学习的敏感度。通过实验对比,在表3中列举出超参数的实验数据,以联合交并比最优供算法选择。实验时使用1/8的数据量。首先设置相同λsemi条件下,对比不同的λadv,可以看到当λadv=0.01时,IoU的值最高。接下来验证在λadv=0.01时,对Tsemi和λsemi的不同取值进行对比,得到当Tsemi=0.2,λsemi=0.1时,得到最佳的IoU数值。

表3 超参数分析表
4.5 结果分析
为了有效评估本文算法的良好特性,通过与基于CNN的FuseNet网络、文献[17]和本文所提出的语义分割方法进行结果对比,采用NYU-DepthV2的验证集来验证实验结果,实验结果如图4所示。

图4 NYUDepth V2数据集上的语义分割结果(迭代次数20K)
图4(g)与图4(d)、(e)相比,在视觉效果上逐步有了明显的提升,是由于引入几何深度信息以及基于分割鉴别网络的对抗性,使得性能有很大的提升。图4(f)是使用本文方法没有加入深度信息的纯RGB图语义分割,相比于带有标签图4(c)中,床头灯周边区域光照强,亮灯部分的轮廓和纹理信息丢失严重,提供了弱边界信息;而加入深度几何信息后,可以为场景中提供更多的语义标签上下文信息。综上比较看来,在文本框架结构中融合几何深度信息的半监督技术,可以带来更具有鲁棒性、判别力强的上下文约束,有更好的视觉效果。
本文网络在14分类映射的NYUDepth V2数据集上做20K次迭代次数的实验结果,并与FuseNet网络方法、Multiscale+depth Convet方法[19]以及其他方法进行对比,结果如表4所示。通过对比发现本文提出的网络模型比FuseNet的IoU提高了3.52%MPixelacc提高了5.25%。与文献[18]的方法相比,Pixelacc提高了1.95%。与文献[19]中提出的融合超像素MRF的方法相比,MPixelacc有了明显的提高。实验证明本文提出的模型对语义分割具有良好的鲁棒性。在本文中只复现了基于CNN的FuseNet网络,把原来作者的数据集更换为本次使用的数据集,其原理没有发生改变,并且输入的批次以及迭代次数和显卡运算有关,复现中最好的结果是36.61%的IoU,比FuseNet中的37.76%的IoU低。

表4 算法比较实验数据表
5 结语
本文提出了一种基于GAN网络并融合深度几何信息的半监督学习方法。这种方法有利于加强对象边界信息内容。我们基于距离变换的新损失函数在训练阶段惩罚了错误的预测,并帮助分割网络在半监督学习的阶段对未标注的图像进行更精确的分割。通过实验表明,使用有限数量的注释数据,可以获得准确的室内对象分割。但是,该模型非常依赖图像质量分布。为了进行有效训练,它需要在训练集中充分地平衡好标签图像和不同图像的质量,才能准确预测图像的语义分割。下一步我们将这项工作扩展到三维图形语义分割,将半监督的技术逐步扩展到弱监督,利用少量标签图来做训练。
猜你喜欢
今日农业(2022年15期)2022-09-20
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
小天使·二年级语数英综合(2019年10期)2019-11-08
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
读者·校园版(2015年19期)2015-05-14
长江学术(2015年1期)2015-02-27
海外英语(2013年8期)2013-11-22
数码影像时代(2006年5期)2006-05-29
