
贷款类诈骗网站识别方法研究*
2021-06-28 11:13李高翔叶宇中黄福鸿卓采标潘国良陈金林陈德兴吴雁琛
广东通信技术 2021年6期
[李高翔 叶宇中 黄福鸿 卓采标 潘国良 陈金林 陈德兴 吴雁琛]
1 引言
在信息网络快速发展的背景下,电信网络诈骗已成为当前发展最快、严重影响人民群众安全感的刑事犯罪。根据文献[1]的数据,2020 年以来,公安机关累计破获电信网络诈骗案件达25.6万,累计封堵诈骗网站网址31.6万个,由此可见目前电信网络诈骗传播的广泛性。当前电信网络诈骗手法多样,主要包括兼职诈骗、杀猪盘诈骗、贷款诈骗等。其中贷款诈骗主要是指犯罪团伙通过模仿国内知名借贷平台,如京东金融、微粒贷、百度有钱花等的官网页面搭建仿冒站点,以免息或低息为噱头诱导用户贷款并缴纳一定金额激活账号实施诈骗。由于仿冒站点的页面和正规平台的官网非常相似,所以普通民众极易受骗。与此同时,诈骗团伙通过使用多种网站模板和小众域名,可在短时间内迅速搭建一批仿冒站点,给公安机关、运营商等部门的打击防范工作带来了极大挑战。
本文旨在设计一种针对贷款类诈骗网站的识别方法,为此本文先通过对国内知名借贷平台站点官网及相关URL进行收集整理形成白名单,然后基于对公安部门积累样本的分析结果,设计了域名、网页内容、网页HTML 标签三类特征应用于分类算法,最后通过实验验证本文提出算法的有效性。本文的主要研究成果如下。
①对国内知名借贷平台及其域名等信息进行了梳理。
② 提出了一种结合基于规则和基于机器学习的贷款类诈骗网站识别框架。
③进行了多种算法的对比实验,验证结果表明本文所提方法可有效识别贷款类诈骗网站。
本文的其余章节组织如下。
第2 章 综述电信网络诈骗及网站识别的研究现状。
第3 章 介绍贷款类诈骗网站识别框架。
第4 章 实验验证算法模型。
第5 章 总结与展望。
2 研究现状
现有的网站识别方法可以分为基于规则的识别与基于机器学习的识别。基于规则的识别主要依靠黑名单和简单匹配规则对网站URL 或实时特征等进行模糊匹配。黑名单匹配能够快速且精准返回涉诈网站,但是需要对黑名单库进行定期的维护。实时特征是指IP 地址、网页端口号、存活时间、PageRank 排名等可以很好地指示一个网址的有害性,但是需要在识别中通过URL 在网络中实时搜寻的特征。基于规则的识别精度高、速度快,但可能产生一定应用成本,因此多为一些防护软件供应商等如360、腾讯等所使用。
基于机器学习的方法对未发现的有害网址泛化性更强,性能更好,在近年来受到了研究者的关注。基于机器学习的方法需要预先收集一些样本并进行标注,再利用参数模型对标注的数据进行训练,以获得泛化性能。现有的网站识别文献多采用通用分类模型如SVM、DNN 等来进行训练。如魏胜娜等利用CART 树对URL 特征进行学习,并修改代价函数为最小均方误差,成功降低了钓鱼网站的误报率[2]。杜锦波、付顺顺等利用集成算法思想,将多个fasttext弱分类器组合为一个强分类器,并利用该分类器对网站文本内容进行了分类[3,4]。毛世奇将网站URL 进行独热编码,并利用嵌入层对不同字符进行转换,最后输入到卷积神经网络中进行训练和预测[5]。左雯、张士坤等在利用字符嵌入的基础上,对不同的深度模型结构进行了实验,最后确定了卷积神经网络、门控循环单元和softmax 的组合作为最终结构,并取得了良好的效果[6,7]。
3 贷款类诈骗网站识别框架
本文提出的识别框架结合了基于规则的识别与基于机器学习的识别两种方法,先通过基于规则的白名单规则进行过滤,然后再使用机器学习方法进行识别贷款诈骗网站。算法流程图如图1 所示。

图1 算法流程图
3.1 白名单匹配过滤
作者统计了公安部门积累样本中贷款诈骗网站主要仿冒平台名称及相关信息,具体内容如表1 所示。

表1 诈骗网站主要仿冒平台相关信息
对运营商等拥有大量数据的机构而言,可先对所有要判定的网站数据进行白名单过滤,因为正规平台的访问日志较多,经过白名单过滤后可有效减小后续需处理的数据规模,节省大量计算资源。
3.2 域名特征分析
作者对大量贷款诈骗网站的URL 进行分析,发现主要有如下特点。
(1)多使用HTTP 协议传输
因为正规借贷平台站点涉及了大量资金及用户敏感信息,需考虑网络传输安全问题,多使用HTTPS 协议,如表1 中URL 全部是HTTPS。而诈骗网站主要目的是诱导欺骗,并不考虑数据安全问题,所以选择HTTP 协议,建站效率更高,成本更低。
(2)多使用小众域名
正规借贷平台站点通常会使用其主体公司域名为其背书,或使用较短的拼音、谐音域名方便推广传播。如微粒贷w.webank.com 是微众银行的子域名,人人贷www.renrendai.com 则使用了拼音。而诈骗团伙通常选择小众域名(如kfbzh.bcsbhm.bar,afdfe.545idifjf.zkakdf.txhb.mhmh9.cn 等)建站,这些域名价格便宜、数量较多,可快速进行批量替换更新,躲避监管部门追踪打击。
(3)存在使用非默认端口情况
考虑到服务器运营商可能会对站点进行安全扫描检测,而普通扫描检测工具主要覆盖常见协议及端口,如HTTP 协议的80 端口,FTP 协议的21 端口等。部分诈骗团伙为了降低被检测识别的风险,会启用非默认端口,即访问诈骗网站需指定固定端口,如81,使用默认端口80则无法访问。
(4)多使用境外单一IP
目前国内一直保持对电信网络诈骗的严打高压态势,所以诈骗团伙建站通常考虑使用境外IP,且通常将多个域名绑定在同一IP 上,方便其部署管理,并进一步缩减成本。而正规借贷平台站点多使用国内IP,且考虑到不同地区、省份的网络情况,可能会将同一域名解析到多个IP 地址,提升用户访问体验。
基于上述分析,可以对任意给定的URL 进行分析,构造如表2 的URL 相关特征。
高河瞪圆了双眼,用力摇着头:“不、不是,不是这样,他说谎。我知道,他一定会把自己做的事都推在我的头上……”
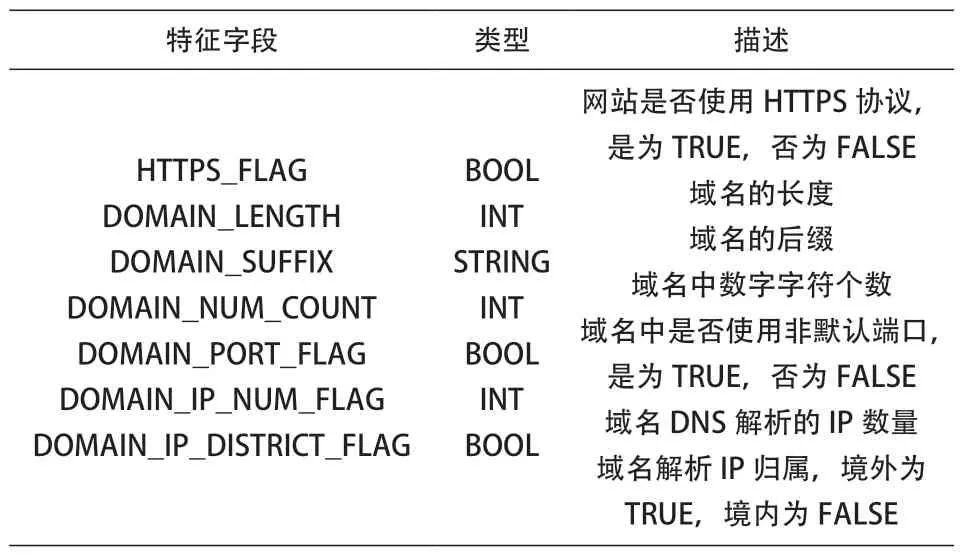
表2 域名相关特征
3.3 网页内容特征分析
大部分网页的结构如图2 所示,部分诈骗团伙为了提高网页排名,会在标题(title),关键词(keywords)和描述(description)字段部分对网页内容进行重点描述,因此需要对网页不同部分的内容分别进行分析。

图2 常见网站结构URL 相关特征
(1)网页头部字段部分关键词特征
本文定义网页的标题(title),关键词(keywords)和描述(description)字段为网页的头部字段,根据作者对大量涉诈样本的分析,诈骗团伙习惯在头部字段使用诸如“微粒贷”、“京东金融”、“极速放款”等词语进行描述。作者对收集到的正常样本和贷款诈骗网站样本进行处理,提取其标题、关键词和描述部分的内容,然后对其进行分词处理,并分别计算每个词语的TF-IDF,取权重最高的N个词作为该部分的关键。N可根据实际情况进行设定。
(2)网页主体内容关键词特征
网页主体(主要包括
标签字段的内容)的关键词提取思路和头部字段基本一致,先将网页主体中的各类HTML 标签清洗,提取其主要内容,然后进行分词,计算TF-IDF 权重并排序。因为网页主体内容较长,且样本有限,较多词的权重差别并不大,因此本文在该部分引入专家领域知识,对高权重的词进行人工二次筛选,最终确定K个词作为该部分的关键词。同样K可根据实际情况进行设定。基于上述分析,可对任意给定的URL 网页内容分析,对不同区域的内容分别进行对应关键词匹配,将词频作为其特征值。
3.4 网页HTML 标签特征分析
部分贷款诈骗网站呈现出高对抗的特点,如图3 所示,该类网站基本没有网页内容,因此3.3 节提出的关键词特征对该类样本无效。此外,许多诈骗网站多采用相似的网站模板快速建站,因此可考虑对网页源码中的HTML 标签进行特征提取。

图3 网页主体无内容的页面举例
具体操作方式为对任意给定的URL 网页内容,抽取其网页内容中的所有HTML 标签。统计分析每一种标签(如div,href 等)在该网页的出现次数,作为其特征值。同时抽取部分典型标签的值作为关键词特征,统计其在网页出现次数作为特征值。
3.5 算法分类
4 实验验证
本章节通过基于真实数据的实验评估本文提出特征的有效性,并对比分析多种算法的实验结果。
4.1 数据集描述
本文使用的数据集主要有两个来源,一个是公安部门收集到的大量贷款诈骗网站样本,另一个则是通过爬虫抓取互联网上包含3.3 节关键词的网页并进行人工标注。训练集一共有2 134 个样本,其中贷款诈骗网站有875 个,正常网站有1 259 个,测试集一共有1 423 个样本,其中贷款诈骗网站有608 个,正常网站有815 个。训练集和测试集均已通过白名单过滤。
4.2 识别评价指标
本文采用如表3 所示的混淆矩阵来评价模型的准确度。

表3 混淆矩阵
评价模型准确度的主要指标包括查准率、查全率和F1 得分,其定义如下:直观上,查准率表示模型预测贷款诈骗网站正确的精度,查全率表示模型成功预测出的实际贷款诈骗网站占比,F1 得分综合考虑查准率和查全率,提供了一种平衡型的评价打分。
4.3 识别模型评价
本文使用了4 种分类算法(包括朴素贝叶斯、逻辑回归、K 最近邻和随机森林)对本文提出的特征进行实验验证,算法结果如表4 所示。

表4 不同算法的对比结果
从表4 观察可知随机森林算法的查全率、查准率和F1 值上均取得了最好效果,其中F1 值为0.95,表明了本文所提算法可有效对贷款诈骗网站和正常网站进行较好的区分。
5 总结与展望
本文针对贷款类诈骗网站的识别问题设计了一种算法框架,该框架通过结合白名单过滤,域名、网页内容、网页HTML 标签三类特征以及机器学习分类算法可对贷款类诈骗网站进行有效识别。作者通过基于真实数据的实验验证了本文提出算法框架的有效性。后续将考虑如何将贷款类诈骗的其它环节与诈骗网站识别进行结合,形成更完整的解决方案。
猜你喜欢
中国教育网络(2018年12期)2019-01-18
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
计算机与网络(2018年10期)2018-02-15
电子制作(2017年2期)2017-05-17
中国防伪报道(2016年10期)2016-11-21
中国防伪报道(2016年10期)2016-11-21
公民与法治(2016年15期)2016-05-17
电子测试(2015年18期)2016-01-14
小说月刊(2014年10期)2014-04-23
