
计算机视觉中对象检测技术综述
2021-06-28 05:27陈文云覃焕昌
科学与信息化 2021年17期
陈文云 覃焕昌
百色学院 信息工程学院 广西 百色 533000
引言
近三十年来,随着反向传播算法的发明[1]、卷积神经网络技术的问世[2-4]、计算机运算速度和存储技术不断深化,推动计算机视觉技术水平不断提高,对象检测技术是其最基础、最重要、最具挑战性的技术之一。对象检测技术是图像识别和理解的关键技术,其通过对图片中的各区域、各层特征的提取,通过机器学习检测出图片中各对象及其位置和关联。
对象检测技术[5]首先选定图像中某一特定位置,然后对该区域图像进行识别、分类,反复进行可以找出图像中所有对象及其位置,再对各对象的关联性进行分析,以完成对整张图像的理解。其已广泛地应用于日常生活中,譬如人脸检测与识别[6-7],行人检测[8],医学上的人体骨架检测[9],图像分类[10-11],人类行为分析[12]和自动驾驶[13-14]等。
1 传统对象检测技术
传统的对象检测技术由区域推荐、特征提取和对象分类等部分组成。
1.1 区域推荐
不同对象在图像中出现的位置不同、大小以及比例也不同,用不同大小和不同尺寸比例的候选滑动窗口去扫描图像是必要的,从而筛选出最佳的区域推荐。巨量的穷举候选滑动窗口会消耗大量的计算资源,同时会带来冗余候选窗口。如果过少的候选滑动窗口数量,可能找不到最佳滑动窗口。
1.2 特征提取
为了识别滑动窗口中的对象,必须对窗口中能代表图像的结构特征进行提取,对这些特征的表示是通过模拟外部刺激在大脑神经元中产生的激励[20]来完成的。常采用的先进特征提取技术有:比例无关的特征变换[20],方向梯度直方图HOG[21],哈尔特征Haar-like[22]等。但现实应用中对象的外观、光照条件和背景的巨大差异,通过人工找到一个完美的、适合所有场景、所有对象的特征是极其困难的。
1.3 分类
在提取的特征的基础上,需要找到一个强有力的分类器来区分在滑动窗口中的对象归属某一特定种类,常采用的分类器有:支持向量机SVM[23],AdaBoost[24],DPM[25]等。
传统的对象检测技术以滑动窗口为基础,生成冗余低效的、人工定义的、浅层局部的特征描述和浅层学习模型为主要特征,无法获取图像中对象的深层次特征并完成深层学习,很快就遇到了识别率提升的瓶颈[15]。深层神经网络DNN[11,26]通过自动提取和学习深层特征,打破了这一僵局,实现各层级特征自动提取,取消人工特征定义[27]。
2 新型对象检测技术
新型对象检测技术能在图像中定位、识别特定的一个或多个已知对象。定位可以通过边框(bounding box)来表示,识别就是对边框中对象进行分类。根据其技术特点可将其分为两类:第一种技术是基于区域推荐的对象检测,与传统的图像理解技术类似,首先进行区域推荐,再将推荐区域的图像进行识别和分类,典型代表有R-CNN[15],fast R-CNN[16],faster R-CNN[17],SPP-net[28],R-FCN[29],FPN[30]等,与传统技术主要区别是取消了特征的人工定义;第二种技术是基于回归的对象检测,它将对象检测与分类识别过程视为回归问题,采用统一的框架一并完成,这类框架主要有YOLO[18],SSD[19],YOLOv2[31],DSSD[32]等。
2.1 基于区域推荐的对象检测
基于区域推荐的对象检测技术与人脑观察物体的过程类似,先粗略扫描整个物体的概貌,再仔细关注感兴趣的区域RoI。这类框架主要有如下几种:
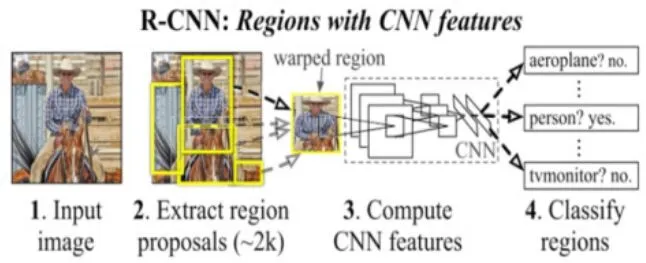
图1 R-CNN信息流图
R-CNN:通过采用选择搜索算法[33]来快速提供精确的推荐区域,并在推荐区域中应用CNN提取深层次的高维(4096维)特征表示,然后利用线性SVM分类器对区域特征打分,最后在贪婪非最大抑制算法作用下对边框BoundingBox进行回归,从而得到最优的边框[15],从而识别出图片中所有对象及其边框。对比结果显示该框架比当时mAP最好结果提高了30%左右,其信息流图如图1所示。
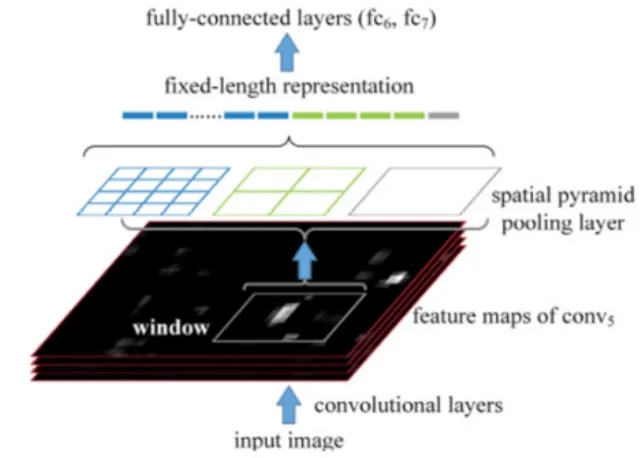
图2 SPP-net架构
SPP-net:所有CNN最后都需要全连接层来汇总所有特征图中的特征信息,而全连接层只会接收固定大小的输入,故在R-CNN模型中需要对推荐区域进行裁剪,从而会导致边框的不准确。为此,空间金字塔匹配SPM算法[34-35]被用于在卷积层和全连接层之间构建空间金字塔池化层SPP[28],从而生成全连接层所需要的输入特征尺寸大小。其提高边框预测的准确率的同时,还能提高对象检测的效率,架构如图2所示

图3 Fast R-CNN架构
Fast R-CNN:尽管SPP层能提高R-CNN的精度和效率,但是它还是采用单一管道、串行、多任务方式来完成所有处理,导致额外的内存花销而且SPP的网络微调算法不能影响到之前的卷积层。Fast R-CNN通过简化SPP层为一层,并在全连接层后引入了两个孪生的分别处理分类和边框回归的输出层,并将所有参数进行端到端多任务损失优化[16],进而进一步提高对象检测和分类的精度和效率,其架构如图3所示。

图4 RPN的架构
Faster R-CNN: 主要创新是采用了区域推荐网络RPN[17,36],RPN通过向对象检测网络分享全图像的卷积特征图来为其实现特征提取共享计算,几乎无成本的去掉了Fast R-CNN中耗时的区域推荐处理;引入k个锚框分别对应k个区域推荐,每个锚框与RPN中滑动的小网络进行卷积产生每个推荐的低维特征,以供边框分类和回归。RPN的架构图如图4所示。
R-FCN[29]:不同于faster R-CNN在于,其在最后一个卷积层就基于k*k固定大小网格为每类生成k2个得分列表,后续的RoI池化层、分类器和边框回归器都基于这个得分表来进行对象检测。FPN[30]提取各个层级(由下至上、由上至下和直接互联)的特征,在不牺牲速度和存储空间的前提下,可用于训练各种大小的图片。Mask R-CNN[37]将faster R-CNN技术扩展至对象分割,在并行的分类和边框回归的基础上增加了一个新分支:分割线掩码。
2.2 基于回归的对象检测技术
基于回归的对象检测技术只需一步就能根据输入图片计算出所有对象的边框及其类别。这类技术主要有:
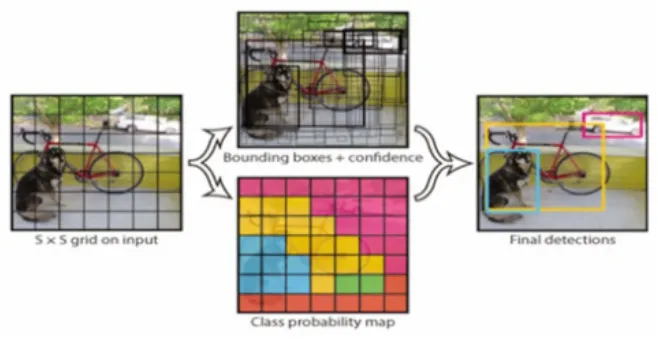
图5 YOLO的对象检测信息流图
YOLO[18]:将对象检测设计为一个回归问题,对边框和类别概率同时回归,只用一个神经网络和一次评价就可以从输入图像直接预测出边框和类别。YOLO将输入图像分割成S*S个网格,每个网格只负责检测中心落在其中的对象,预测B个边框和相应的置信得分(),此外每个网格还要给出一组所有类别的条件类别概率()。根据边框的置信得分和网格的条件类别概率,就可以计算出每个边框的类别置信得分:

其信息流图如图5所示。
由此看出YOLO在一个模型中同时考虑了边框类别、边框的位置和大小,很容易进行端到端的损失优化,从而提高了效率、运算速度和预测精度。基本型YOLO处理速度可达45fps,fast YOLO处理帧率为155fps。引入块归一化、高分辨率分类器、锚框、维数聚类、细粒度特征、直接位置预测和多尺度训练等新技术的YOLO称为YOLOv2。
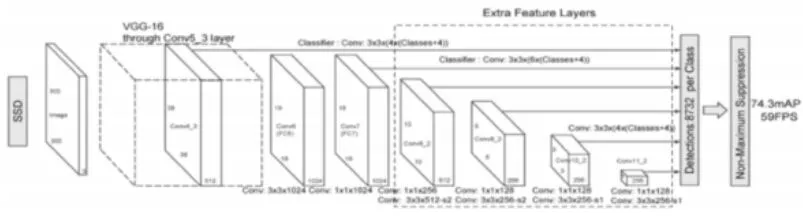
图6 SSD的网络架构
SSD[19]:是在受到锚框、区域推荐网RPN和多尺度表示技术的启发下提出的,为了解决其他技术在检测小尺寸对象时碰到的困难。它以VGG16的网络结构为基础,在后面增加了几个特征层来预测不同尺度和比例的对象的偏移量机器置信得分,从而使对象检测时融合了不同分辨率的特征图中的预测信息,而非基于单一分辨率的特征图,最后在非最大抑制算法的作用下得到最佳对象预测结果。其架构图如图6。
2.3 性能比较

Faster R-CNN YOLO SSD速度(fps) 7 45 59 mAP(%) 63.4 73.2 74.3
通过比较SSD、YOLO和faster R-CNN在PASCAL VOC和Microsoft COCO数据集的测试表现,得到如左表结果,结果表明SSD无论在速度(59fps),或是精度(74.3%)都是目前最好的对象检测技术。
3 后续工作展望
对象识别技术近些虽然年取得了突飞猛进的发展,但仍然还有很多问题亟待攻克。其一,小尺寸对象(尤其是在局部遮挡情况下)的识别;其二,如何减少人工介入(打标签等),提高对象检测的自主化;其三,如何提高对象检测的速度实现实时化,尤其对大尺寸图片;其四,如何实现三维对象的检测,甚至视频对象检测。
猜你喜欢
钢管(2022年2期)2022-11-28
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2019年10期)2019-06-17
意林(绘英语)(2018年1期)2018-04-28
北京航空航天大学学报(2018年1期)2018-04-20
小雪花·成长指南(2016年9期)2016-10-12
消费电子(2015年7期)2015-12-11
汽车与新动力(2015年1期)2015-02-27
