
基于AI 的新零售商铺人流密度监测系统设计
2021-06-25 14:18薛云哲
软件导刊 2021年6期
张 珣,薛云哲
(杭州电子科技大学现代电路与智能信息研究所,浙江杭州 310018)
0 引言
从1852 年至今的168 年间,零售业态经历了百货商店、连锁店、大型商超、线上商店到智能新零售业态5 次变化历程。智能新零售业态是指购物行为依托现代信息技术如IOT(物联网)、虚拟现实、增强现实、混合虚拟现实、Big-Data(大数据)、AI(人工智能)、区块链等,使销售、购物、物流配送、在线支付等环节智能化,给人们带来便捷的购物体验,从而拉动购物需求,提高人们的购买力,是一种多要素、多渠道的营销手段,例如“海底捞”推出的智能点单机器人、学校和医院等出现的“自动便当机”、杭州阿里集团旗下的“智慧无人酒店”等。智能新零售业态正在不断深入人们生活的方方面面。
通过参阅以往文献,传统商铺电能消耗和人力资源消耗分别占总成本的25%和40%[1],电力浪费严重。随着大数据与人工智能时代的到来,智能零售商铺依托深度学习网络,可以有效地对各大型耗电设备进行智能自动化调控,一方面减少了能源损耗,节省了电力能源,另一方面解放了人力,降低了人力资源成本。但目前存在的问题是,大部分深度学习网络较为复杂,难以训练或训练周期长,不适应商业的快速发展,识别率也偏低,达不到预期效果。
本文基于智能组网[2]及深度学习网络建模等思想,采用端到端的网络架构,实现数据的实时有效采集与展示,辅助新零售商铺节能节电,从而降低商家运营成本。该系统还能丰富居民的购物体验,使人们真正在现实生活中感受到高科技带来的便捷与高效。
1 人流密度监测系统总体框架
本文设计一个智能商铺人流密度监测系统,以实现对商铺内拥挤的人群进行智能监测、控制等多种功能[3-7]。该智能控制系统总体框架如图1 所示。
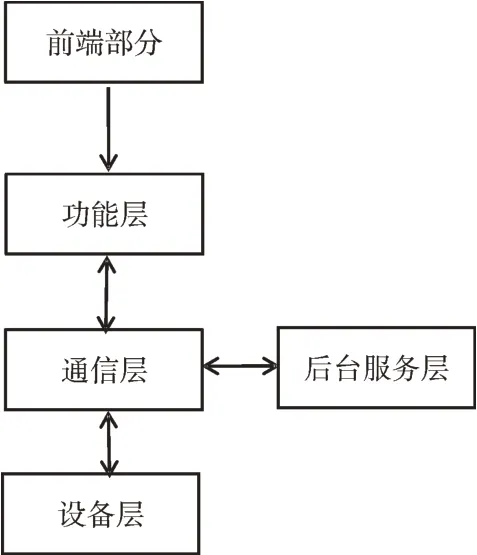
Fig.1 Overall framework of pedestrian flow density monitoring system图1 人流密度监测系统总体框架
系统主要由数据采集、数据接收、数据分析、数据展示等模块组成,数据采集自智能组网传感器,采集的数据经通信层存储到数据库端;数据分析是指通过深度学习网络进行训练,从而预测出人流密度数据,辅助管理人员进行研判;数据展示是指通过可视化手段展示数据,使数据更加直观,便于分析。经算法预测的人流量回传到前端,生成人流密度状态,判断是否需要对耗电设备采取节电措施,管理人员也可通过该系统研判是否需要采取人流密度控制措施。
其中,前端利用人流密度监测状态分类表格进行预测结果展示,本文采用10 档百分比模式进行人流密度状态控制,具体分类如表1 所示。

Table 1 Classification of passenger flow density monitoring表1 人流密度监测分类
商铺管理者可手动设定人流量最大阈值,根据网络预测出的实际人数与阈值人数比值进行百分比转化,得到人流密度状态,供管理者研判,进而对用电设备进行控制。
2 系统框架设计
2.1 数据库设计
本文使用MySQL 数据库存储算法返回的数据,根据需要设计了user、picturedata、status 3 个表格。其中,user 存储管理员信息,如管理员权限、名称与密码等;picturedata 主要包括传感器采集到的二进制图片信息,如区域标识、图片二进制字段等;status 主要包括数据经处理后生成的状态信息,如状态码、状态说明字段等。
2.2 系统前后端设计
系统后台编程语言使用Java,服务器使用轻量级服务器Tomcat,以便于环境搭建与参数配置。前端基于HTML5技术设计系统界面,利用CSS 渲染界面,以及JavaScript 语言进行数据动态展示。前后台交换报文采用JSON 格式,前台利用AJAX 技术进行数据收发,以提高页面响应速率。系统主要实现以下功能:
(1)使用Socket 网络编程接收智能组网采集系统收集的实时人流密度图片数据,后台服务端开放端口,与客户端建立连接。若连接建立成功,则可通过该通道把采集系统接收的数据按一定时间间隔发送到后台(本文每5min 接收一次数据),之后服务端传递数据到后台数据库,存储于相应字段等待处理。
(2)通过选择区域信息,动态获取该区域的人流密度监测状态和实时人流数据进行信息联动查询。利用该方式可大幅提高页面响应速率,因为不用加载全部数据,只加载需要的部分即可。
(3)内置深度学习算法进行人流密度状态监测,把深度学习网络内置到后台,数据存储到数据库后,后端系统调用算法并取出数据投入训练。算法进行最终的图像人数预测,将结果存储于数据库,供前端展示。
(4)可视化人流密度数据,利用表格和折线图等方式直观展示商铺各区域人流密度状态,帮助管理人员判断是否需要采取相应的限流、节能措施,并对算法预测数据进行统计,自动生成4 种类型的图表:①以小时为单位的人流密度走势图;②以天为单位的人流密度走势图;③以月为单位的人流密度走势图;④人流密度状态实时图,从而让商铺管理人员可以更全面地制定运营策略,令新零售商铺实现敏捷性经营。
3 基于深度学习的新零售商铺人流监测分析模型
3.1 数据选择
本文采用公开数据集ShanghaiTech dataset,分为part_A_final 和part_B_final 两个子数据集。其中,part_A_final 采用300 张图片作为训练集,182 张图片作为测试集,该部分为稠密人群数据集;part_B_final 采用400 张图片作为训练集,316 张图片作为测试集,该部分为稀疏人群数据集。数据集共有1 198 张图片,330 165 个注释头。数据样式如图2 所示。

Fig.2 Selected public data set图2 选用的公开数据集
3.2 ground-truth 值产生
由于最终决定深度学习网络模型识别准确性的标准是经算法预测的密度图计数与实际密度图计数的差值,而实际密度图计数就是ground-truth 值。将数据集中标定的人头图像转化为实际密度图的过程尤为关键,该过程生成的密度图被称为ground-truth 图。根据文献[8]中生成密度图的方法,本文将一幅标定人头的图像看作二维数值矩阵,有人头标记坐标处的值置1,其他位置的值置0,利用高斯自适应滤波核估计每个人头(置1 处)大小,即其实际占几个像素,并分别进行高斯自适应滤波处理,将结果叠加到新的对应大小的0 矩阵上,形成最终的密度图。
其中,高斯自适应滤波核定义如下:

对于每个注释头x(i人头中心坐标),本文用其最近邻k个标注头的矢量和表示,为自适应的高斯滤波核。依照文献[8]中提供的实验说明,β=0.3 且k=3 时效果最佳。本文用该自适应高斯滤波核作用于每个图片的注释头,最终叠加生成最终的密度图。
3.3 模型选择
起初研究人员采用滑动窗口[9]直接进行人群探测计数,但该方法通常只能提取较低层次的特征,所以在大规模人群计数场景下效果会明显变差。随着近年来对深度学习研究的不断深入,基于密度图并结合CNN 的深度学习网络在大规模拥挤人群计数中显示出良好效果,尤其是近年来提出的MCNN[10]网络即为其中的经典模型。该模型采用3 个深度卷积神经网络,利用不同尺寸的卷积核适应不同的人头尺寸以提取特征,并最终合并3 个网络结果生成密度图。最近提出的Switch-CNN[11]等网络都是在MCNN 网络结构基础上优化而来的,因此本文也基于part_A_final 数据集,采用经典的MCNN 进行对比试验,如表2 所示。

Table 2 Performance comparison of common deep convolution network(CNN)and MCNN表2 普通深度卷积网络(CNN)与MCNN 性能对比
表2 采用普通单列的深层CNN 网络与经典MCNN 网络进行对比,并利用MAE 指标进行评估,发现单列深层的CNN 网络表现更为出色。也即是说,MCNN 网络似乎并没有因网络冗余度增加而提高识别性能,其不同尺度的卷积网络在该数据集上的表现大致相同,另外MCNN 网络相对于单列CNN 网络更加复杂,且难以训练。本系统采用一种以VGG16[12]作为前端网络的CSRNet[13]网络,采用VGG16作为前端网络是由于其可以接收任意尺寸的图片,无需缩放输入图片而导致特征丢失,并且VGG16 可以灵活拼接后端网络产生密度图。后端网络是由多个膨胀卷积层[14-16]构成的深度学习网络,膨胀卷积层可以提取更深层次的特征信息,以弥补VGG16 池化层带来的分辨率下降与特征丢失的风险,而且其属于端到端的单列CNN 深度学习网络,易于训练。CSRNet 网络模型框架如图3 所示。
3.4 模型训练过程
CSRNet 前端网络VGG16 直接读取训练好的权重,后端网络初始化权重参数,赋随机值,把预处理后的图片投入网络进行训练,利用损失函数和随机梯度下降算法进行权重参数的迭代优化。大约进行200 批次训练后[17],调优参数变化趋于平稳,得到最终算法,可将权重参数存储起来待之后调用。
3.5 数据预处理
图片无法直接加载进算法进行训练,因此需要首先转化为矩阵数组,此时可进行归一化处理以减小计算量,并保证数据不会丢失特征维度。由于前端基于VGG16 网络,输出图片大小会缩小为原图的,所以需要进行相应预处理。

Fig.3 CSRNet network model framework图3 CSRNet 网络模型框架
4 算法原理
4.1 神经网络计算公式
神经网络由若干层组成,计算过程以输入层到输出层的顺序执行,上层输入可作为下层输出。具体公式为:

其中,z(l)为第l层神经元输出结果,W为各节点权重,b为修正常数,a(l)、z(l)为激活函数计算中间项,f为激活函数。
4.2 反向传播网络
该算法的函数设为L(W,b),计算公式如下:

输出层单元i的残差为:

第l层的第i个单元残差为:
计算L(W,b)对w和b的偏导:

最终使用SGD[18](随机梯度下降算法)对W和b更新迭代:

其中,α为学习率。
4.3 膨胀卷积层
本深度学习网络设计最重要的一环就是对后端网络膨胀卷积层[19-20]的设计,一个二维膨胀卷积定义如下:

其中,y(m,n)为卷积层的输出,ω(i,j)是长宽分别为M、N的卷积核,r为膨胀卷积的步长。
前端网络进行了3 次池化[21-22],池化的优势是可以保证数据的不变性,并抑制过拟合的发生,但也有诸多缺点,如图片的空间分辨率会下降且丢失部分空间特征信息,导致整个网络性能不佳。为解决这一问题,后端网络引入膨胀卷积的概念。膨胀卷积采用稀疏核(见图4),在不改变参数量的情况下增大感受野,以提取更多维度的图像特征信息。在膨胀卷积中,k*k 大小的卷积核在步长为r 的条件下可增大到(k+(k-1)(r-1))*(k+(k-1)(r-1)),所以膨胀卷积层可以灵活获取图像不同尺度的特征信息,同时保证不改变图像分辨率,从而提高深度学习网络识别率。

Fig.4 3 * 3 convolution kernel图4 3*3 的卷积核
4.4 评估网络模型
衡量一个预测类深度学习网络模型的标准通常是预测值是否拟合实际值,通俗讲就是网络预测是否准确。基于此,本文深度学习网络模型评估采用MAE[23]作为衡量网络模型质量的标准,具体定义如下:

其中,N为投入训练的N张图片,分别是投入训练第i张图片的实际人数和算法预测人数。
5 评估结果
根据网络输出的人流密度预测值对人流密度进行实时分类,采用表格、折线图等手段在前端进行可视化展示,让管理者通过直观的数据精准、科学地作出决策,以调控商铺人流密度,避免水电浪费。如管理者可自定义人流密度阈值,当网络预测结果高于阈值前端反馈Abnormal_higher 时,可以适度采取限流措施,增大电器用电功率;当网络预测结果低于阈值前端反馈Abnormal_lower 时,可以适度采取节能措施,降低电器能耗。该方式既不会影响顾客体验,又避免了不必要的浪费。此处对part_A_final(稠密人群数据集)中的实际值与预测值进行了对比,如图5 所示。

Fig.5 Part_ A_ final:comparison of ground truth image and prediction result图5 Part_A_final:ground-truth 图片与预测结果对比
最终,CSRNet 在part_A_final与part_B_final数据集的MAE参数如表3所示。

Table 3 MAE parameter of CSRNet in part_A_final and part_B_final表3 CSRNet 在part_A_final 与part_B_final 的MAE 参 数
从表3 可以看出,CSRNet 在稠密人群数据集中的MAE为75.3,在稀疏人群数据集中的MAE 为9.65,也即是说CSRNet 在part_A_final 中,平均每张图片与其实际值相差75.3,在part_B_final 中,平均每张图片与其实际值相差9.65。对比表2,其识别性能也优于经典的MCNN 网络与CNN 网络,且训练过程更加便捷。该网络具有实时性,即可实时传入图片数据,实时更新前端状态。此处截选几个重要时间节点的人流密度状态加以说明,如表4 所示。

Table 4 Real time status of passenger flow density表4 人流密度实时状态
根据前端显示的人流密度状态,管理者可根据实际情况对耗电设备进行调节,如处于AbNormal_Lower(21%-30%)状态时可适当减少照明功率、降低空调风速等,处于AbNormal_Heigher(71%-80%)状态时可提高空调功率、增加排风措施等,从而给顾客带来更好的购物体验。
6 结语
本文根据对CSRNet 深度学习网络算法、标定数据、智能组网的研究,给出了新零售商铺智能用电解决方案。搭建基于深度学习网络的新零售商铺人流密度分析系统,以实时采集的人流图片作为输入特征、预测人流量作为输出结果搭建模型,指导工作人员操作用电设备。该系统对传统商铺的机械性定时开关电器进行了优化,较好地解决了大型商超用电浪费等问题,符合当代新零售商铺智能、环保的要求,具有较高的研究价值。该系统仍可作进一步完善,如利用自动控制算法及组网对用电设备进行自动调节,以进一步解放人力,形成自动化系统,这是今后需要重点研究的方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
中国生殖健康(2018年1期)2018-11-06
中国生殖健康(2018年1期)2018-11-06
北京航空航天大学学报(2018年1期)2018-04-20
海军医学杂志(2015年2期)2015-02-27
中国民族民间医药·下半月(2014年4期)2014-09-26
电视技术(2014年19期)2014-03-11
