
服务器—客户端应用系统的线程模型设计
2021-06-25 14:18张雨萌
软件导刊 2021年6期
张雨萌
(上海浦东发展银行总行信息科技部,上海 200000)
0 引言
本文首先重新定义一个名词——服务。服务特指由网络实现的应用系统间的API 调用与响应过程,其中API调用和响应不局限于特定形式。
一个服务存在两个重要角色:服务调用方和服务提供方。本文将服务中发起API 调用的应用系统称之为服务调用方,将提供API 调用并作出响应的应用系统称之为服务提供方。
在网络架构中,存在着客户端、服务器之分,与之对应存在着客户端应用系统、服务器应用系统。需要强调的是,服务器应用系统一定是服务提供方,客户端应用系统一定是服务调用方。
在服务A 中,如果服务器应用系统在收到服务调用方的API 调用请求后,需要与其他服务提供方新建另一个服务B,并根据新建服务B 的响应结果完成服务A。该服务器应用系统同时具有服务提供方和服务调用方两个角色,服务A 被称为依赖型服务。如果服务器应用系统在收到服务调用方的API 调用请求后,不需要新建服务,依靠本系统即可完成服务的响应,则该服务器应用系统仅作为服务提供方角色,本文将该服务称之为独立型服务。
因承载服务类型的不同,本文将独立型服务中的服务器应用系统称为完全服务器应用系统。将依赖型服务中的服务器应用系统称为服务器—客户端应用系统。
服务器—客户端应用系统的本质依然是服务器应用系统,其与完全服务器应用系统主要差异表现在服务中所处位置不同、提供服务的基本过程不同。
完全服务器应用系统和服务器—客户端应用系统在服务中所处位置如图1 所示,完全服务器应用系统在服务中是I/O 请求数据的终点和I/O 响应数据的起点,而服务器—客户端应用系统只是I/O 数据流转的中间环节。

Fig.1 Position of total-server application system and server-client application system in the service图1 完全服务器应用系统和服务器—客户端应用系统在服务中的位置
完全服务器应用系统在服务中的基本处理流程如图2所示,服务器—客户端应用系统在服务中处理基本过程如图3 所示。通过对比发现,服务器—客户端应用系统与完全服务器应用系统的最大差异在于其将业务处理过程分成两个阶段,并在业务处理过程中新建另一个服务,其业务处理结果依赖于新建服务的响应数据。

Fig.2 Basic process of total-server application system in the service图2 完全服务器应用系统在服务中的基本处理流程
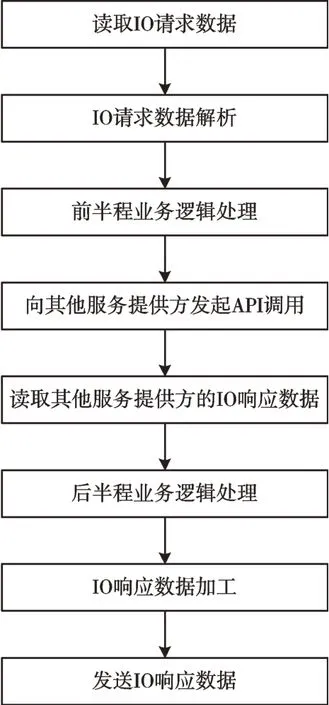
Fig.3 Basic process of server-client application system in the service图3 服务器—客户端应用系统在服务中的基本处理流程
服务器应用系统的线程模型研究较多。1999 年,为了优化网络编程的程序设计,Schmid[1]在应用架构设计层面提出了Reactor 模型,并结合Unix 网络编程技术[2]给出模型实现;针对突破单机性能局限提升应用系统的服务承载能力,Dan[3]提出了c10k 问题,并首次提出包括NIO 在内的解决方案;Doug[4]在总结应用程序线程模型基础上,结合Java NIO 技术进一步细化了Reactor 模型,提出单线程Reactor模型、线程池Reactor 模型以及多Reactor 模型。以上学者的核心思想是提高应用系统的服务承载能力,解耦I/O 事件和进程/线程资源、复用进程/线程资源以及合理的程序模型设计。在上述研究基础上,各类基于Java NIO[5-7]以及基于Reactor 模型的应用设计[8-21]得到广泛应用。
受限于当时的业务场景,关于服务器应用系统的线程模型设计多关注于解耦在服务提供方角色下的I/O 事件和进程/线程资源,并未考虑在服务调用方角色下I/O 事件和进程/线程资源的解耦方式,即相关行业实践和研究更适配于完全服务器应用系统而无法适配服务器—客户端应用系统。
为适配服务器—客户端应用系统,本文提出拓展的多Reactor 模型,在多Reactor 模型基础上增加异步回调处理机制,同时解耦服务调用方和服务提供方两个角色上的I/O事件与线程资源。
1 相关研究
1.1 经典线程模型
经典线程模型如图4 所示。服务器应用系统在收到客户端应用系统的API 调用请求后,为每个请求分配一个handler 线程,完成socket 对象的建立和业务处理,在handler 线程完成业务处理后,通过已建立的socket 对象向客户端应用系统作出响应。

Fig.4 Classic thread model图4 经典线程模型
经典线程模型存在如下缺点:①经典线程模型下,服务器应用系统承载服务的能力有限,其并发服务数受限于可用线程数;②在大量handler 线程阻塞的情况下,服务器应用系统会出现线程频繁切换、CPU 使用率增高等问题,导致系统处理能力下降。
为了优化经典线程模型,提出以I/O 多路复用技术为基础的Reactor 模型并应用于服务器系统中。
1.2 单线程Reactor 模型
单线程Reactor 模型首次将服务器应用系统在服务提供方角色下的I/O 事件与线程资源进行解耦,该模型如图5所示。
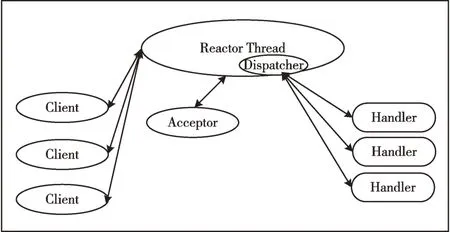
Fig.5 Basic Reactor model图5 单线程Reactor 模型
单线程Reactor 模型主要包括Reactor Thread、Acceptor以及负责业务处理的Handler 线程。
1.2.1 单线程Reactor 模型模块介绍
Reactor Thread 保存了服务器创建网络连接的必要信息以及一个I/O 多路复用器,在创建ServerSocket 对象后将ServerSocket 对象注册到I/O 多路复用器,其不断监听socket对象的可读(READABLE)、可写(WRITABLE)事件。Reactor Thread 包括一个Dispatcher 组件,在有可读(READABLE)的I/O 数据时,Dispatcher 组件将创建一个负责业务处理的Handler 线程。
Acceptor 通过Reactor Thread 中的I/O 多路复用器获取可建立连接(ACCEPTABLE)状态的I/O 请求,并创建一个已连接状态(ACCEPTED)的socket 对象,将该socket 对象注册到Reactor Thread 中的I/O 多路复用器。
Handler 线程用于具体业务处理,其由Dispatcher 组件创建,并在业务处理过程完成后销毁。
1.2.2 单线程Reactor 模型不足
从架构层面看,一个Reactor Thread 在面对高负载、多并发应用场景时,单线程Reactor 模型存在如下问题:
(1)性能问题。Reactor Thread 承担职责太多,一个Reactor Thread 同时处理上百万个通讯链路,性能上无法支撑;另外,由于业务处理线程无法重用,其每次创建的成本必然在高并发时对系统运行造成巨大压力。
(2)可靠性问题。一旦Reactor Thread 出现故障,会导致整个系统通信模块不可用,不能接收和处理I/O 数据,造成节点故障。
1.3 线程池Reactor 模型
虽然单线程Reactor 模型首次把服务器应用系统在服务提供方角色下的I/O 事件与线程资源进行了解耦,但由于业务处理线程无法重用,其每次创建的成本必然在高并发时对系统运行造成巨大压力。为改善单线程Reactor 模型业务处理线程无法重用的问题,线程池Reactor 模型应运而生。线程池Reactor 模型如图6 所示。
相较于单线程Reactor 模型,线程池Reactor 模型去除Dispatcher 组件,使用了线程池进行业务处理,此举可以避免业务处理线程不断创建、销毁。但线程池Reactor 模型仍然没有解决单线程Reactor 模型中Reactor Thread 同时处理上百万个通讯链路时的性能及可靠性问题。
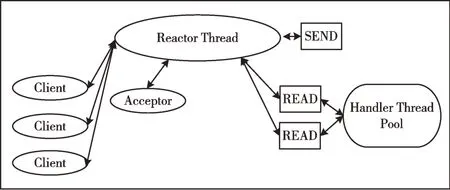
Fig.6 Thread pool Reactor model图6 线程池Reactor 模型
1.4 多Reactor 模型
作为目前主流的线程模型,多Reactor 模型成功解决了线程池Reactor 模型的性能及可靠性问题,其核心思想是将ServerSocket 对象的创建同socket 对象可读(READABLE)、可写(WRITABLE)事件的监听解耦,并将监听socket 对象可读(READABLE)、可写(WRITABLE)事件的工作放到多个线程、多个I/O 多路复用器中。
多Reactor 模型结构如图7 所示,主要包括Main Reactor、Acceptor、Sub Reactor、Handler Thread Pool 四部分。

Fig.7 Multiple Reactor model图7 多Reactor 模型
1.4.1 多Reactor 模型模块介绍
(1)Main Reactor。保存服务器创建网络连接的必要信息并创建ServerSocket 对象,将ServerSocket 对象注册到其与Acceptor 共享的一个I/O 多路复用器中,注册监听的I/O事件为可建立连接(ACCEPTABLE)状态的I/O 请求,一般由单线程完成。
(2)Acceptor。用于监听服务调用方的网络连接请求,通过其与Main Reactor 共享的I/O 多路复用器获取Server-Socket 对象,可建立连接(ACCEPTABLE)状态的I/O 请求,创建一个已连接状态(ACCEPTED)的socket 对象,并将该socket 对象注册到Sub Reactor 中的某个I/O 多路复用器中。
(3)Sub Reactor。不断监听socket 对象的可读(READABLE)、可写(WRITABLE)事件,读取可读状态下socket 对象的I/O 数据,并调用Handler Thread Pool 中的线程进行业务处理;一旦有可写状态的I/O 数据就将I/O 数据返回给客户端应用系统。采用线程池方式构建,线程池中的每个线程保存一个I/O 多路复用器。
(4)Handler Thread Pool。负责具体的业务处理,输入为Sub Reactor 读取的socket 对象I/O 数据,输出为Sub Reactor 响 应 的I/O 数 据。
1.4.2 无法适配问题
多Reactor 模型通过对模块的合理规划,解耦了Server-Socket 对象的创建,以及socket 对象可读(READABLE)、可写(WRITABLE)事件的监听,有效提升了服务器应用系统的承载能力和可靠性。
但由于在多Reactor 模型中,Handler Thread Pool 线程只用于业务处理,未考虑到依赖型服务的业务处理过程,这意味着使用多Reactor 模型的服务器—客户端应用系统在作为服务调用方时,在其他服务提供方的响应时间内业务处理线程是阻塞状态,无法承载其他服务。而如果阻塞线程过多,新服务请求的响应速度或已积压服务请求的处理速度将大幅降低,造成服务大量超时,所以多Reactor 模型有着天然无法适配服务器—客户端应用系统的问题。从这个角度看,多Reactor 模型只是一个适配完全服务器应用系统的线程模型。
2 拓展多Reactor 模型
为解耦服务器—客户端应用系统在服务调用方和服务提供方两个角色上的I/O 事件与线程资源,本文在多Reactor 模型基础上提出了一种拓展多Reactor 模型,旨在适配服务器—客户端应用系统。
拓展多Reactor 模型如图8 所示。其中,Main Reactor 的作用与多Reactor 模型中的Main Reactor 一致,保存服务器创建网络连接的必要信息并创建ServerSocket 对象,将ServerSocket 对象注册到其与Acceptor 共享的一个I/O 多路复用器中。注册监听的I/O 事件为可建立连接(ACCEPTABLE)状态的I/O 请求,由单线程完成。
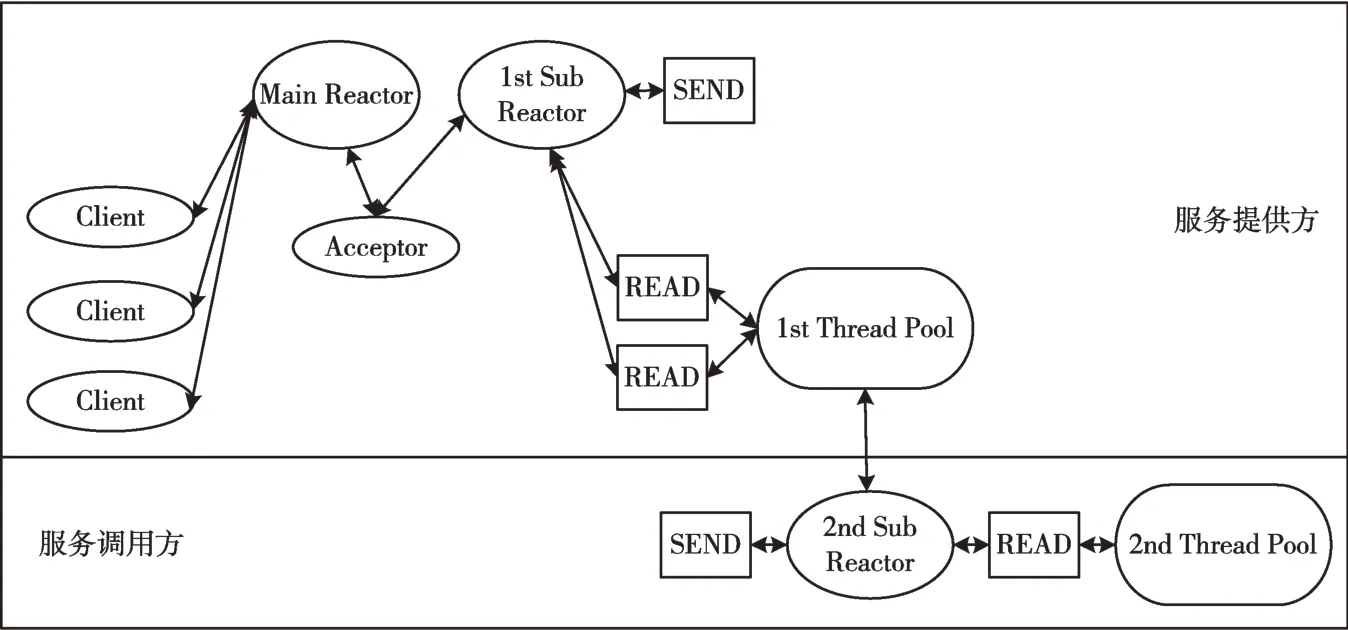
Fig.8 Extended multi-Reactor mode图8 拓展多Reactor 模型
Acceptor 用于监听服务调用方的网络连接请求,通过其与Main Reactor 共享的I/O 多路复用器获取ServerSocket对象,建立连接(ACCEPTABLE)状态的I/O 请求,创建一个已连接状态(ACCEPTED)的socket 对象,并将该socket 对象注册到1st Sub Reactor 中的某个I/O 多路复用器中。
1st Sub Reactor 不断监听socket 对象的I/O 可读(READABLE)、可写(WRITABLE)事件,读取可读状态下socket 对象的I/O 数据,同时调用1st Thread Pool 中的线程进行前半程业务处理,一旦有可写状态的I/O 数据就将I/O 数据返回给客户端应用系统。采用线程池构建,线程池中的每个线程保存一个I/O 多路复用器。
1st Thread Pool 负责执行前半程业务处理过程,通过2nd Sub Reactor 与其他服务提供方建立连接并发送I/O 请求数据。
2nd Sub Reactor 是实现服务调用方角色上解耦I/O 事件与线程资源的核心模块,主要承载服务器—客户端应用系统新建服务的工作,在其内部同样保持一个或多个I/O多路复用器,在获取到其他服务提供方的I/O 响应数据后,通过2nd Thread Pool 中的线程回调后半程的业务处理过程。
2nd Thread Pool 负责执行后半程的业务处理过程,输入为2nd Sub Reactor 获取到的I/O 响应数据。在完成后半程业务处理后,2nd Thread Pool 中的线程通过修改1st Sub Reactor 的I/O 多路复用器中的socket 监听事件为可写(WRITABLE),1st Sub Reactor 作为服务提供方角色下的响应数据返回给客户端应用系统。
拓展多Reactor 模型中线程资源、I/O 事件的时序图如图9 所示,该模型在服务调用方和服务提供方两个角色上均实现了I/O 事件与线程资源的解耦。
3 拓展多Reactor 模型性能测试
本文对拓展多Reactor 模型下的服务器—客户端应用系统和多Reactor 模型下的服务器—客户端应用系统分别进行HTTP 协议的性能测试,并比较了服务器—客户端应用系统在两个模型下的性能测试结果。
性能测试按照图1 所示的链路开展,其中客户端应用程序使用Apache Jmeter 性能测试工具,在15min 内,通过向服务器—客户端应用系统不断发送HTTP 请求以获取服务器—客户端应用系统的最高TPS 和交易失败率,其获取响应数据的超时时间为20s。完全服务器使用多Reactor 模型,业务处理过程不涉及I/O 操作,其服务响应时间设置为10s,系统可用线程数设置为150。

Fig.9 Life cycle of thread resources and I/O events in the extended multi-reactor model图9 拓展多Reactor 模型中线程资源、I/O 事件的生命周期
服务器—客户端应用系统在拓展多Reactor 模型和多Reactor 模型下都使用Apache Tomcat 作为Web 容器,通过开启Http11NioProtocol 协议实现多Reactor 模型。在此基础上,拓展多Reactor 模型下的服务器—客户端应用系统借助Servlet 3.1 中的异步处理技术以及HttpAsyncClient 工具进行构建。
服务器—客户端应用系统在拓展多Reactor 模型和多Reactor 模型下使用工具如表1 所示。

Table 1 Comparison of tools used in server-client application system under extended multi-reactor model and multiple reactor model表1 服务器—客户端应用系统在拓展多Reactor 模型和多Reactor 模型下使用工具对比
性能测试结果如表2 所示。
通过性能测试结果可以发现,在多Reactor 模型下,服务器—客户端应用系统最高的TPS 一直未超过50,且在200 和500 并发用户数时,分别出现16.78%和96.26 失败率,究其原因是由于服务器—客户端应用系统的业务处理线程大量阻塞,没有足够的线程资源处理已经积压的请求。在拓展多Reactor 模型下,服务器—客户端应用系统最高的TPS 可以突破50,在500 并发用户数时,最高TPS 可以到达200,且失败率一直保持为0%。

Table 2 Performance test results of server-client application system under extended multi-reactor model and multiple reactor model表2 服务器—客户端应用系统在拓展多Reactor 模型和多Reactor 模型下的性能测试结果
实验证明,拓展多Reactor 模型在正确率、TPS 两个方面均优于多Reactor 模型。
4 结语
本文首次从场景上将服务器应用系统细分为完全服务器应用系统和服务器—客户端应用系统,并分析了两种应用系统的差异之处,为系统设计提供了一种新的视角;本文还针对性地提出了拓展多Reactor 模型的线程设计,为服务器—客户端应用系统进一步提升服务承载能力提供了一种新的可行模型。
本文仍有不足之处,如模型的构建基于Java 语言,在Apache Tomcat 以及HttpAsyncClient 工具的支持下完成,而生产实际中存在多种语言和工具,如何构建一个轻量级的Java 工具库,以及基于其他语言构建工具库是下一步研究的方向。
猜你喜欢
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
环球市场(2017年36期)2017-03-09
信息安全研究(2016年4期)2016-12-01
计算机工程与科学(2013年2期)2013-06-07
中国信息化·学术版(2013年1期)2013-05-28
测绘科学与工程(2013年1期)2013-03-11
