
采用曙光超级计算机的海冰模型并行性能调优研究
2021-06-25 14:18张玉春欣冯鲁彬梁建国
软件导刊 2021年6期
张玉春欣,冯鲁彬,梁建国
(山东科技大学计算机科学与工程学院,山东青岛 266590)
0 引言
海冰模型[1]是由美国能源部[2]的洛斯阿拉莫斯国家实验室负责开发和维护的[3],它是地球系统模型的重要组成部分。海冰是全球气候变化最敏感的部分之一,其变化对全球气候演变具有巨大影响[4]。十几年来,海冰模型一直用来定量预测海冰的演变规律,为地球系统科学中诸多分支学科的相互融合提供平台[5]。
近些年来,不少地球系统模型性能得到很大提升,但海冰模型未进行优化。因此,海冰模型性能逐渐成为制约地球系统模型性能的关键因素,所以对海冰模型进行性能调优有着重要意义[6]。在海冰模型模拟计算中,模拟规模通常会达到几百至上千年,出于对模拟计算精确性和有效性考虑,时间步长在几分钟到几小时之间,空间网格距离在几公里到几十公里不等,其计算量庞大、耗时长,对计算机软硬件是相当大的挑战[7]。如何利用超级计算机更高效地完成海冰模型的模拟计算,模拟各运行模式下的性能变化成为热点。
目前,基于多核、众核处理器技术的新型体系结构下的大型科学计算应用研究是高性能计算领域研究热点[8],目标为有效提升科学研究效率,推动其在各领域的应用发展[9-10]。
曙光超级计算机作为通用x86 体系结构的超级计算机,尤其适合海冰模型这种庞大的计算密集型程序。虽然当今新型体系结构不断出现,但是通用x86 体系结构的超级计算机依然是科研领域研究者使用最广泛的超级计算机[11],因此在曙光超级计算机上对海冰模型进行性能调优研究具有非常重要的意义。
1 相关工作
海冰模型作为一种复杂的有限差分网格点模型,由多种物理计算和动力学组成,其中包括海冰热力学、动力学、δ-爱丁顿辐射过程等[12]。Balaprakash 等[13]对海冰模型的求解方法、动力学、热力学过程的计算性能进行评估,证明海冰模型计算方法的有效性;陈宏博等[14]对CESM 中的有限差分算法采用多种方法进行优化,性能获得提升;Fu等[15-17]根据申威众核处理器的结构特点优化数据分配方式与模拟计算方程方法,对代码进行重组,提高了地球系统模型的并行性;Xiao 等[18]针对大气环流模式动力框架提出通信避免算法,不仅降低了通信频率,还实现了通信的隐藏。
以上研究都是基于系统模型具体算法或者整个模拟计算过程的并行优化,但在超级计算机下对海冰模型自身的多种运算方式进行并行性能调优的研究还存在空白。
2 研究背景
2.1 曙光超级计算机
曙光超级计算机主要由高性能计算集群系统以及虚拟化系统组成,高性能计算集群系统基于曙光TC4600E 刀片平台和W760-G20 服务器搭建完成。本文将海冰模型CICE 整体移植到曙光超级计算机上,进行相关性能调优研究。
曙光超级计算机双路刀片的双精度浮点计算能力为542.4 万亿次/s。计算刀片、登陆节点、并行存储节点之间采用100GB EDR Infiniband 高速交换网络互联,单个高频计算节点采用2 颗Intel Xeon E3-1240V5 CPU,每颗CPU4核心,主频3.5GHz;单个多核计算节点采用2 颗Intel Xeon Gold 6132 CPU,每颗CPU14 核心,主频2.6GHz。平台并行结构拓扑图如图1 所示。

Fig.1 Structural topology of“Dawning”supercomputer图1 曙光超级计算机并行结构拓扑图
2.2 海冰模型介绍
本研究选用海冰模型CICE v5.1 版本作为应用源程序。与之前版本相比,其采用了更灵活的模拟计算方法,有效提升了模拟速度、效率和精度。该版本支持独立运行和全耦合两种模拟计算方式。独立运行模式的模拟计算,是将大气与海洋的实际观测数据作为海冰模型的强迫输入,通过海冰模型相关计算步骤完成南北极中海冰区域体积、质量、热力学等变量的模拟计算。全耦合运行模式的模拟计算是在海冰模型独立运行模式基础上,通过耦合器与地球系统模式中的大气、陆地、海洋等部分进行数值传输与通信,协同完成地球系统模拟计算。
海冰模型的并行方案采用数据并行方法,不同的数据分割方法会对性能产生较大影响。7 种数据分割方法分别是:cartesian-slenderX1、cartesian-slenderX2、sectcart、cartesian-square、spacecurve、roundrobin、sectrobin[19]。
3 在曙光超级计算机上的移植与分析
3.1 在曙光超级计算机上的移植
海冰模型运行过程需要多个环境协同完成,而大部分超级计算机是没有配置这些依赖环境的,所以在曙光超级计算机上配置依赖库环境。对依赖函数库的安装顺序是zlib、HDF5、netCDF、netCDF-fortran,需按照这个顺序进行安装,否则无法成功安装上述依赖函数库。
3.2 T62 网格数据转化1 度强迫输入数据
海冰模型研究提供的开源强迫输入数据只有精确度为3度的数据,这种输入数据不仅精度低且只能运行海冰模型的3 种笛卡尔网格划分方式,不能用于运行海冰模型全部7 种网格划分方式。为对海冰模型性能进行全面调优,考虑到与大气网格数据T62 格式兼容,使用双线性插值方法对输入网格进行预处理,利用NCAR 提供的NCL 研究工具将大气网格数据T62 原始网格数据转化生成1 度强迫输入数据。
3.3 海冰模型掩码
海冰模型中新数据的更新需要依赖上一次计算的数据,因此海冰模型初始化时需要在各个进程间建立通信,用于网格之间传递数据。但在实际运算过程中许多网格单元没有海冰,更新没有海冰区域的数据是毫无意义的。因此,在CICEv5.1 中引入掩码功能,可以随时修改需要更新数据的区域,以减少更新非海冰区域的数据通信开销。图2 中白色部分为没有海冰的陆地部分,在计算时就可以通过掩码将这部分数据屏蔽,不再更新这部分数据,减少了无海冰区域更新时传递的数据量,降低了通信开销。

Fig.2 Land parts of sea ice图2 海冰中的陆地部分
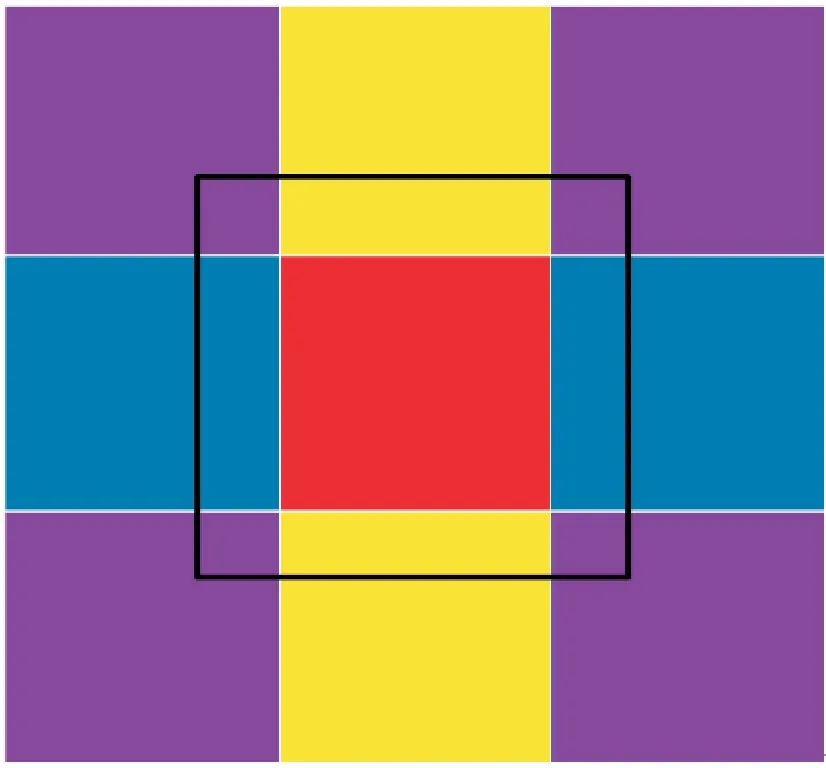
Fig.3 Schematic diagram of task block boundaries图3 任务块边界
3.4 海冰模型网格划分
3.4.1 边界数据更新原理
海冰模型中MPI 通信用于任务块边界数据的更新。为了支持有限差分计算,边界数据的更新需要传递邻居信息,每一层块除边界块外有二维水平面上相邻的8 个邻居,图3 展示了单个任务块的边界是如何与其他邻居关联的。当邻居块被分配给不同的MPI[19]进程计算时,通过MPI 消息传递方式在多个块之间进行数据通信。
3.4.2 网格划分方式
将海冰模型中的水平网格分解为二维任务块实现并行化,划分的任务块被分配给不同MPI 进程以进行计算,每个MPI 进程可以分配多个任务块。海冰模型有很多种网格划分方式,每种划分方式所需要的处理器形状和划分类型不同。在CICEv5.1 版本中网格划分的主要类型有cartesian、sectcart、spacecurve、roundrobin、sectrobin。其中cartesian 根据分布类型对处理器形状进一步细化为slenderX1、slenderX2、cartesian-square(square-ice 和square-pop)。本文讨论了7 种网格划分方式的优缺点,图4 展示了slenderX1 的划分方式。图中横坐标为i维,纵坐标为j维,不同颜色代表分配给每个任务块的MPI 进程[4]。
slenderX1 只划分i维,所以块的纵横比高、阴影区域多、通信数据量大,但邻居数量固定,负载平衡好。slenderX2 方式的划分如图5 所示。与slenderX1 类似,区别是其在j维上划分,所以j维上的长度短、阴影区小。
cartesian-square 划分方式如图6 所示。划分方式分为两种:①当j方向划分的块数大于i方向上划分的块数时,采用square-pop 的处理器形状;②当i方向上划分的块数大于j方向上划分的块数时,采用square-ice 的处理器形状。cartesian-square 对二维任务块的大小有限制,但是几个相邻块通常可以共享相同的MPI 进程。任务块的邻居少,阴影区小,有助于通信性能提升。缺点是会产生物理上紧密相连的块,这样会导致海冰的负载平衡很差。

Fig.4 SlenderX1图4 slenderX1

Fig.5 SlenderX2图5 slenderX2

Fig.6 Catesiansquare图6 catesiansquare
sectcart划分方式如图7所示,是在cartesian-square 划分方式基础上将j维度划分成二维任务块,又将每个二维任务块在j 维上平均划分成4 个小的二维任务块,并将其分配给不同的MPI 进程进行计算。此种划分方式可以将不同区域的计算任务尽可能划分给同一个MPI 进程,提高了计算性能。
图8给出spacecurve的划分方式。i、j维都划分,此种划分方式需要定义任务块大小,以保证划分后块的大小一致。将这些任务块沿着Hilbert-m-Peano-Cinco 空间曲线分配给每个进程。这种划分方式将不需要计算的无海冰区域尽可能划分给同一个进程,并且每个任务块的邻居数量尽量少。
roundrobin划分方式如图9所示。i维和j维都划分,这种划分方式在将无海冰区域的陆地部分剔除之后,以在i维轮询的方式将任务块分配给各个MPI 进程,这样会带来负载均衡,但会导致邻居任务的数量较多,通信代价高。sectrobin 划分的工作方式类似于roundrobin 划分,划分方式如图10 所示。区别在于它尽量将网格上不同位置的任务块分配到同一进程中。

Fig.7 Sectcart图7 sectcart

Fig.8 Spacecurve图8 spacecurve

Fig.9 Roundrobin图9 roundrobin

Fig.10 Sectrobin图10 sectrobin
4 基于曙光超级计算机的性能调优
基于海冰模型的7 种网格划分方式进行性能调优研究,将上述x与y维度的精确度为320×384 的1 度强迫数据作为输入,设置海冰模型迭代周期为10 天。在曙光x86 超级计算机上对海冰模型在不同进程数下对典型海冰模型划分方式slenderX2 的块大小进行调优,验证海冰模型的可靠性。参数如表1 所示,结果如图11 所示。

Table 1 The first experimental configuration of“Dawning”platform表1 曙光平台第一次实验配置
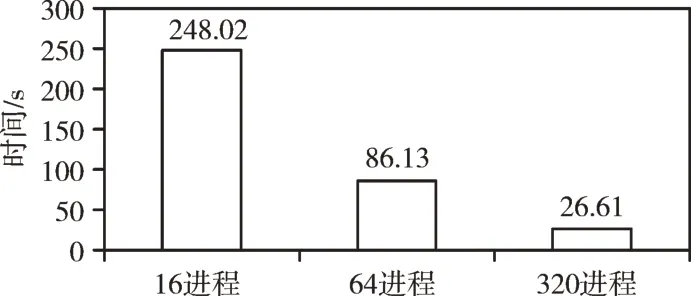
Fig.11 The first experimental test of“Dawning”platform图11 曙光平台第一次实验测试
从图11 可以看出,在曙光x86 超级计算机上海冰模型slenderX2 的划分方式在每个进程分配一个计算任务时,随着进程数的增加,划分任务块减小时运行时间持续下降,性能最高提升了8.32 倍。
继续对海冰模型性能调优,第二次试验对海冰模型7种划分方式下的性能进行更加细致的测试实验。测试进程数为320,具体参数如表2 所示,+mh 代表开启掩码(mask halo)。

Table 2 “Dawning”x86 platform second experiment configuration mode(MPI process number=320)表2 曙光x86 平台第二次实验配置方式(MPI 进程数=320)
曙光x86 平台第二次实验配置方式的运行总时间如图12 所示。
在上述实验中对海冰模型的5 个主要求解过程的时间占用情况进行统计,如图13 所示。5 个求解过程为:①海冰水平方向运动(Advectn;②海冰在厚度空间的运动(Cat Conv);③机械重分布过程(Ridging);④动力学EVP 过程(Dynamics);⑤热力学过程(Column)。

Fig.12 Schematic diagram of the total running time of the second experiment of“Dawning”x86 platform图12 曙光x86 平台第二次实验总运行时间

Fig.13 Schematic diagram of the main solution process occupation time in different experiment type图13 不同实验类型中主要求解过程占用时间
在上述实验中,掩码的开启很好地改进了海冰模型性能,每种划分方式开启掩码之后运行时间都显著降低。sectrobin(8*6)的划分方式是所有划分方式中效果最好的,在320 进程时性能达到最佳,开启掩码前执行时间为30.15s,开启掩码之后执行时间为22.41s,性能提升了25.67%。从图14 可以看出,开启掩码与不开启掩码相比,每个模块的运行时间均有降低。

Fig.14 Comparison of the occupancy time of each module between sectrobin open mask and unopen mask图14 sectrobin 开启掩码与不开启掩码各模块占用时间对比
在上述实验基础上,在320 进程下使用slenderX2 划分方式,对海冰模型任务块大小和任务数量进行调优。选择slenderX2 的原因是每个进程所要计算的任务块数量随着y维度任务块线性减小呈线性增加趋势,具体配置方式如表3 所示。

Table 3 The third experimental configuration of“Dawning”platform表3 曙光平台第3 次实验配置方式
第3 次实验总运行时间如图15 所示。
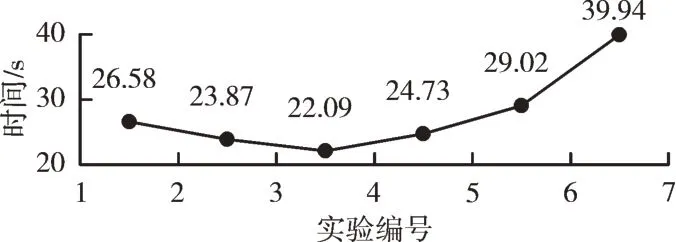
Fig.15 Schematic diagram of the total time of the third experimental experiment of the“Dawning”x86 platform图15 曙光x86 平台第3 次实验总时间
通过以上实验结果可以看出,每个MPI 进程分配4 个任务块时达到最佳性能,运行时间为22.09s。总体变化趋势为:当每个进程分配1~4 个任务时,运行时间不断减小,性能提升约为10.2%~16.7%。当每个进程分配4~32 个任务时,运行时间呈现不断增加的趋势,运行性能降低约为11.9%、31.3%、80.1%。由此可以看出,从每个进程分配4~16 个任务块的过程中,海冰模型的运算效率下降,并且当每个进程分配32 个任务块时,运行时间急剧提升。对于任何划分方式,在合适的任务块大小和计算任务分配下,通常都有一个最佳性能的分配方式。进行第4 次测试,具体配置如表4 所示。实验总时间如图16 所示。

Table 4 The fourth experimental configuration method of“Dawning”x86 platform表4 曙光x86 平台第4 次实验配置方式

Fig.16 Schematic diagram of the total time of the fourth experiment of“Dawning”x86 platform图16 曙光x86 平台第4 次实验总时间
由图16 可以看出,在进程数较低时,如16、64,即便是roundrobin 或sectrobin 的划分方式,每个进程分配8 个任务块时的性能也要优于cartesian 划分方式下的slenderX1、slenderX2 中每个进程分配1 个任务块时的性能。结合roundrobin 与sectrobin 的划分方式,分析得到此方式下进程间具有更好的负载平衡。而在进程数较高时,比如320,进程之间的通信也相应增加,边界更新时所花费的开销变大,此时在相同的任务数下,sectrobin 与slenderX1 划分方式相比,依然是sectrobin 的划分方式性能更佳,性能差别约为11%,差距逐渐缩小。因为在进程数增加的同时,进程之间的通信也在不断增大。在320 进程下,slenderX2 划分方式中开启掩码与不开启掩码对比,性能提升约为26%。
5 结语
本文在曙光超级计算机上对海冰模型优化进行了研究。在分析海冰模型计算以及网格划分、任务分配、掩码功能原理等基础上,通过对海冰模型的7 种网格划分方式分析,调整不同的MPI 进程数以及海冰模型中掩码功能的开启等,对海冰模型性能提升进行研究分析。通过性能调优,在曙光超级计算机上性能最大可提升8.32 倍。未来可以考虑将海冰模型移植到异构超算平台如CPU+GPU 架构或“神威_太湖之光”超级计算机上,实现异构并行加速。
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
海洋通报(2021年3期)2021-08-14
科技传播(2019年22期)2020-01-14
通信学报(2019年5期)2019-06-11
中国教育网络(2018年7期)2018-08-10
通信技术(2018年3期)2018-03-21
中国计算机报(2018年42期)2018-01-31
电子技术与软件工程(2016年24期)2017-02-23
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
